 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Achieving Human Parity on Visual Question Answering
Nov 19, 2021

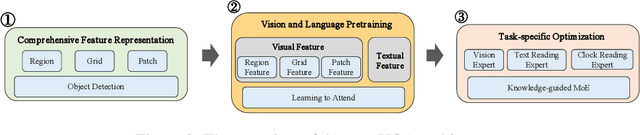
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.
Signature-Graph Networks
Oct 22, 2021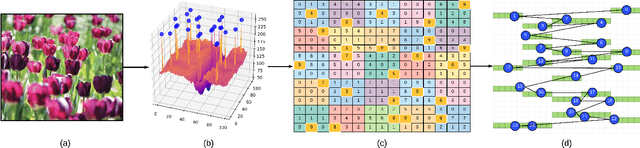
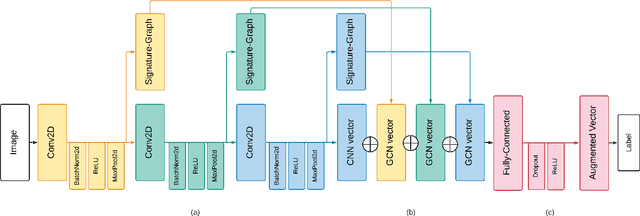
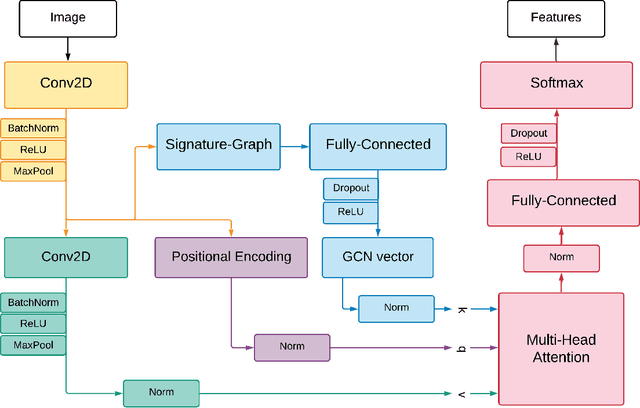
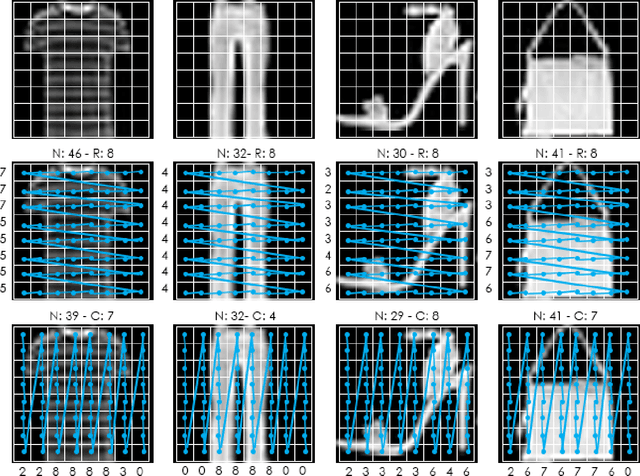
We propose a novel approach for visual representation learning called Signature-Graph Neural Networks (SGN). SGN learns latent global structures that augment the feature representation of Convolutional Neural Networks (CNN). SGN constructs unique undirected graphs for each image based on the CNN feature maps. The feature maps are partitioned into a set of equal and non-overlapping patches. The graph nodes are located on high-contrast sharp convolution features with the local maxima or minima in these patches. The node embeddings are aggregated through novel Signature-Graphs based on horizontal and vertical edge connections. The representation vectors are then computed based on the spectral Laplacian eigenvalues of the graphs. SGN outperforms existing methods of recent graph convolutional networks, generative adversarial networks, and auto-encoders with image classification accuracy of 99.65% on ASIRRA, 99.91% on MNIST, 98.55% on Fashion-MNIST, 96.18% on CIFAR-10, 84.71% on CIFAR-100, 94.36% on STL10, and 95.86% on SVHN datasets. We also introduce a novel implementation of the state-of-the-art multi-head attention (MHA) on top of the proposed SGN. Adding SGN to MHA improved the image classification accuracy from 86.92% to 94.36% on the STL10 dataset
Quantised Transforming Auto-Encoders: Achieving Equivariance to Arbitrary Transformations in Deep Networks
Nov 25, 2021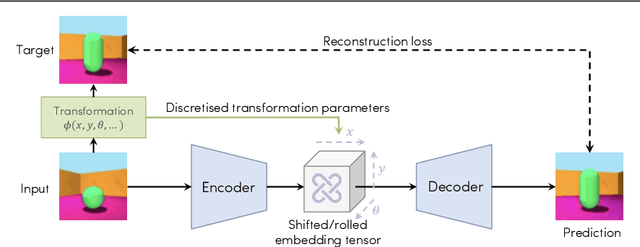
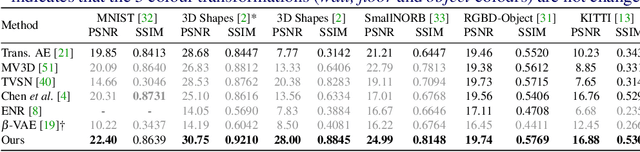

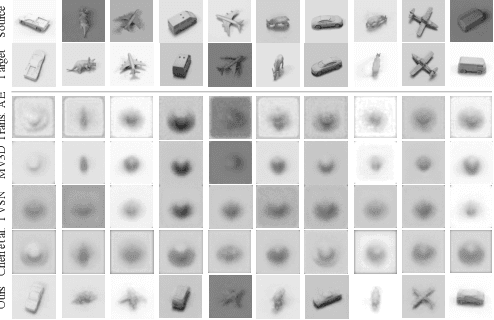
In this work we investigate how to achieve equivariance to input transformations in deep networks, purely from data, without being given a model of those transformations. Convolutional Neural Networks (CNNs), for example, are equivariant to image translation, a transformation that can be easily modelled (by shifting the pixels vertically or horizontally). Other transformations, such as out-of-plane rotations, do not admit a simple analytic model. We propose an auto-encoder architecture whose embedding obeys an arbitrary set of equivariance relations simultaneously, such as translation, rotation, colour changes, and many others. This means that it can take an input image, and produce versions transformed by a given amount that were not observed before (e.g. a different point of view of the same object, or a colour variation). Despite extending to many (even non-geometric) transformations, our model reduces exactly to a CNN in the special case of translation-equivariance. Equivariances are important for the interpretability and robustness of deep networks, and we demonstrate results of successful re-rendering of transformed versions of input images on several synthetic and real datasets, as well as results on object pose estimation.
Cross-Domain Medical Image Translation by Shared Latent Gaussian Mixture Model
Jul 14, 2020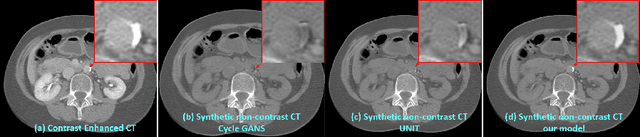
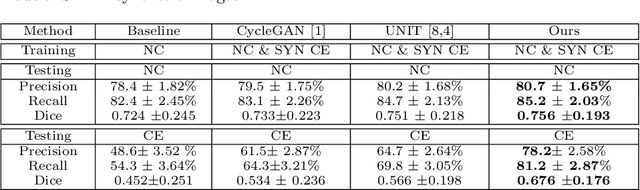
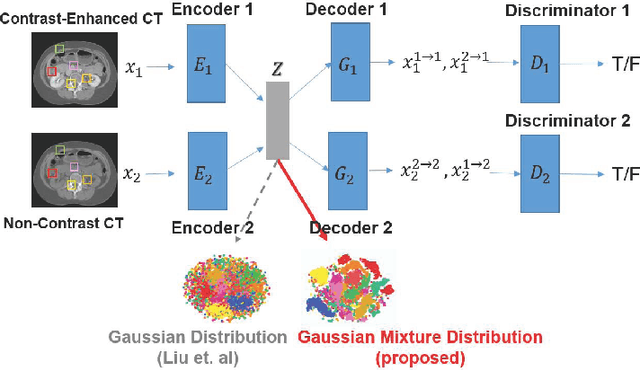
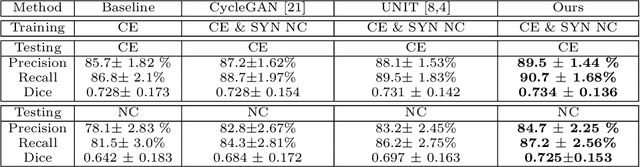
Current deep learning based segmentation models often generalize poorly between domains due to insufficient training data. In real-world clinical applications, cross-domain image analysis tools are in high demand since medical images from different domains are often needed to achieve a precise diagnosis. An important example in radiology is generalizing from non-contrast CT to contrast enhanced CTs. Contrast enhanced CT scans at different phases are used to enhance certain pathologies or organs. Many existing cross-domain image-to-image translation models have been shown to improve cross-domain segmentation of large organs. However, such models lack the ability to preserve fine structures during the translation process, which is significant for many clinical applications, such as segmenting small calcified plaques in the aorta and pelvic arteries. In order to preserve fine structures during medical image translation, we propose a patch-based model using shared latent variables from a Gaussian mixture model. We compare our image translation framework to several state-of-the-art methods on cross-domain image translation and show our model does a better job preserving fine structures. The superior performance of our model is verified by performing two tasks with the translated images - detection and segmentation of aortic plaques and pancreas segmentation. We expect the utility of our framework will extend to other problems beyond segmentation due to the improved quality of the generated images and enhanced ability to preserve small structures.
Sample Efficient Learning of Image-Based Diagnostic Classifiers Using Probabilistic Labels
Feb 11, 2021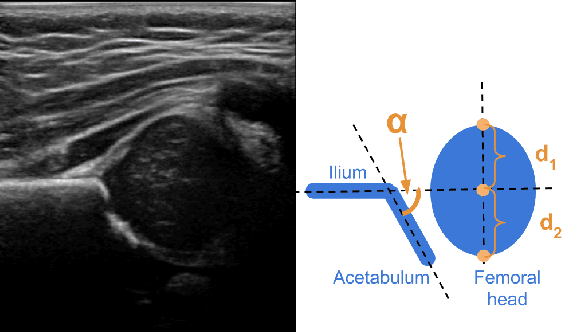
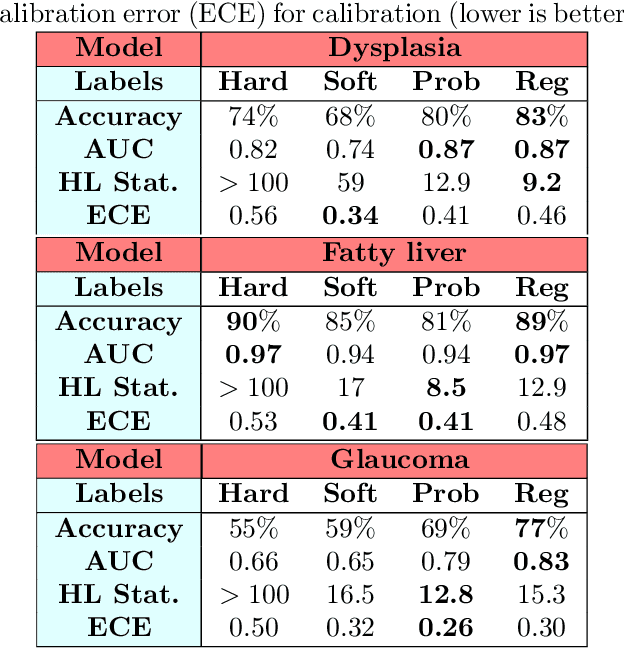
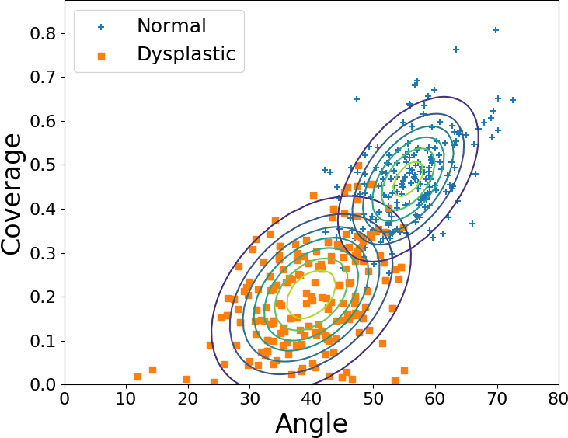
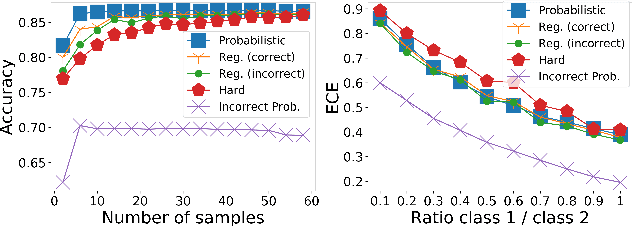
Deep learning approaches often require huge datasets to achieve good generalization. This complicates its use in tasks like image-based medical diagnosis, where the small training datasets are usually insufficient to learn appropriate data representations. For such sensitive tasks it is also important to provide the confidence in the predictions. Here, we propose a way to learn and use probabilistic labels to train accurate and calibrated deep networks from relatively small datasets. We observe gains of up to 22% in the accuracy of models trained with these labels, as compared with traditional approaches, in three classification tasks: diagnosis of hip dysplasia, fatty liver, and glaucoma. The outputs of models trained with probabilistic labels are calibrated, allowing the interpretation of its predictions as proper probabilities. We anticipate this approach will apply to other tasks where few training instances are available and expert knowledge can be encoded as probabilities.
Nonlocal Adaptive Direction-Guided Structure Tensor Total Variation For Image Recovery
Aug 28, 2020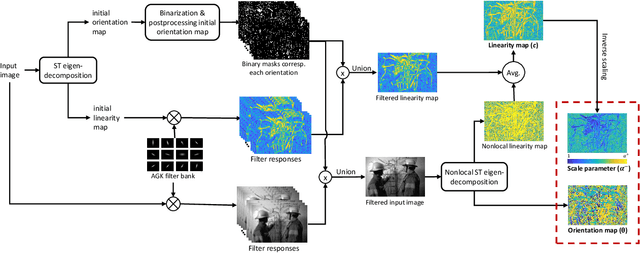
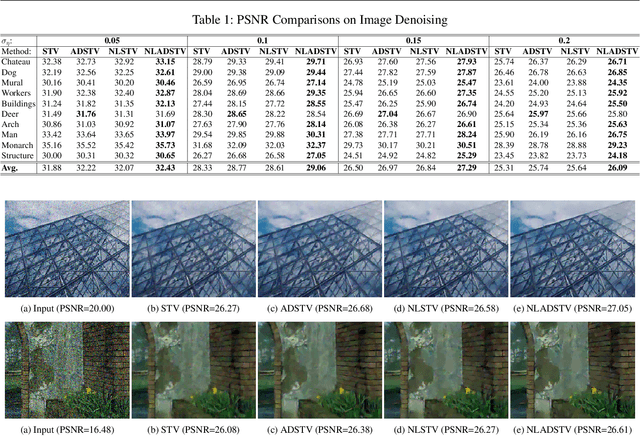

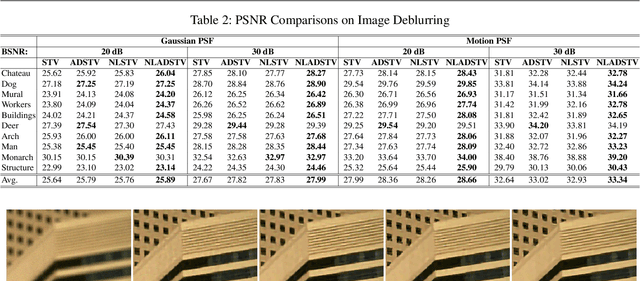
A common strategy in variational image recovery is utilizing the nonlocal self-similarity (NSS) property, when designing energy functionals. One such contribution is nonlocal structure tensor total variation (NLSTV), which lies at the core of this study. This paper is concerned with boosting the NLSTV regularization term through the use of directional priors. More specifically, NLSTV is leveraged so that, at each image point, it gains more sensitivity in the direction that is presumed to have the minimum local variation. The actual difficulty here is capturing this directional information from the corrupted image. In this regard, we propose a method that employs anisotropic Gaussian kernels to estimate directional features to be later used by our proposed model. The experiments validate that our entire two-stage framework achieves better results than the NLSTV model and two other competing local models, in terms of visual and quantitative evaluation.
Deep Auto-encoder with Neural Response
Nov 30, 2021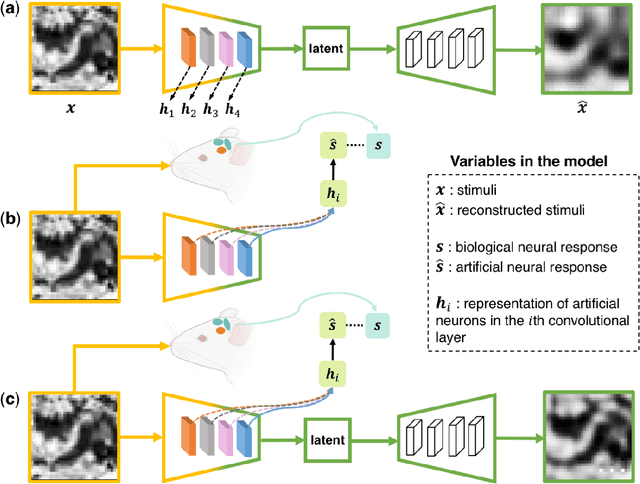
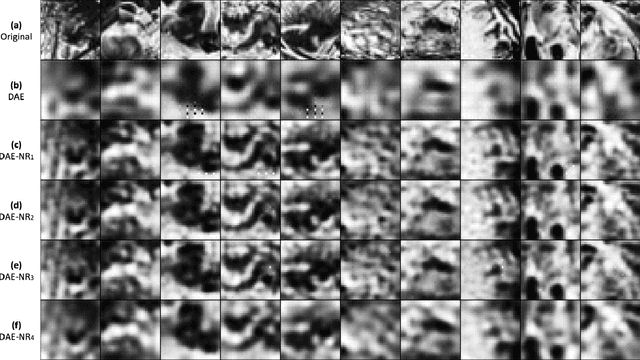
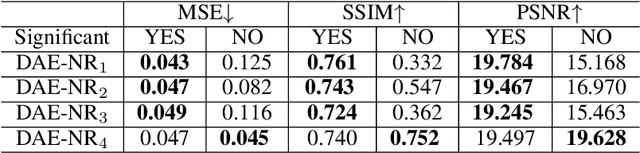
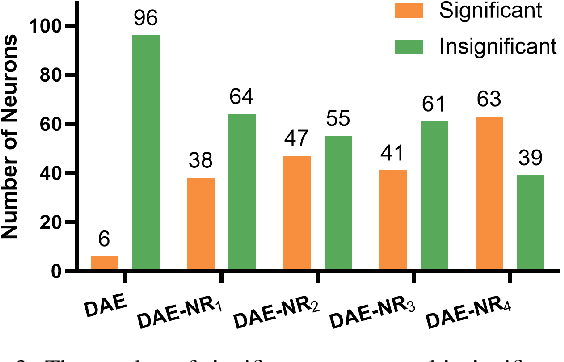
Artificial intelligence and neuroscience are deeply interactive. Artificial neural networks (ANNs) have been a versatile tool to study the neural representation in the ventral visual stream, and the knowledge in neuroscience in return inspires ANN models to improve performance in the task. However, how to merge these two directions into a unified model has less studied. Here, we propose a hybrid model, called deep auto-encoder with the neural response (DAE-NR), which incorporates the information from the visual cortex into ANNs to achieve better image reconstruction and higher neural representation similarity between biological and artificial neurons. Specifically, the same visual stimuli (i.e., natural images) are input to both the mice brain and DAE-NR. The DAE-NR jointly learns to map a specific layer of the encoder network to the biological neural responses in the ventral visual stream by a mapping function and to reconstruct the visual input by the decoder. Our experiments demonstrate that if and only if with the joint learning, DAE-NRs can (i) improve the performance of image reconstruction and (ii) increase the representational similarity between biological neurons and artificial neurons. The DAE-NR offers a new perspective on the integration of computer vision and visual neuroscience.
Drone Object Detection Using RGB/IR Fusion
Jan 11, 2022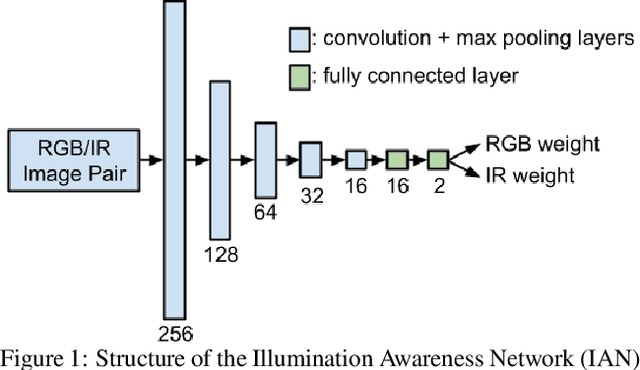
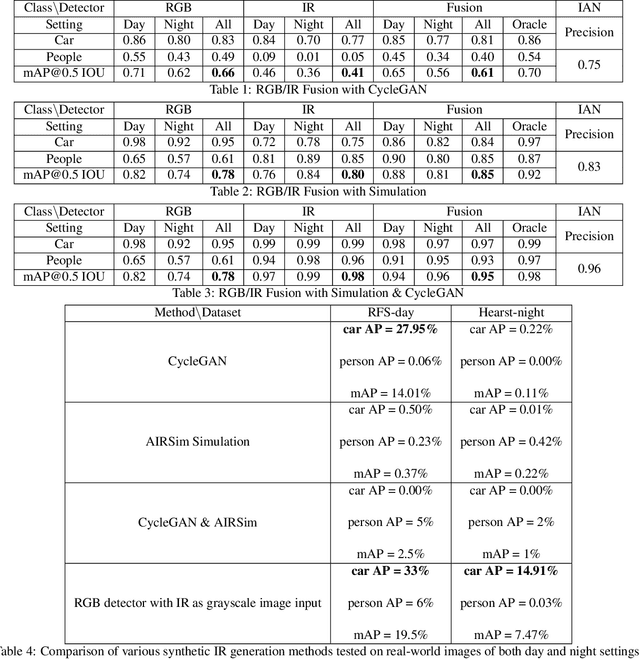
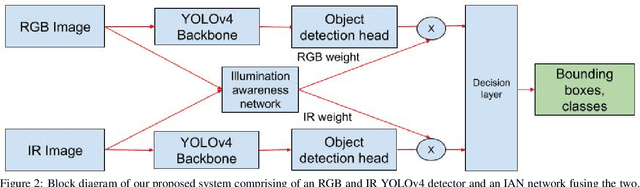

Object detection using aerial drone imagery has received a great deal of attention in recent years. While visible light images are adequate for detecting objects in most scenarios, thermal cameras can extend the capabilities of object detection to night-time or occluded objects. As such, RGB and Infrared (IR) fusion methods for object detection are useful and important. One of the biggest challenges in applying deep learning methods to RGB/IR object detection is the lack of available training data for drone IR imagery, especially at night. In this paper, we develop several strategies for creating synthetic IR images using the AIRSim simulation engine and CycleGAN. Furthermore, we utilize an illumination-aware fusion framework to fuse RGB and IR images for object detection on the ground. We characterize and test our methods for both simulated and actual data. Our solution is implemented on an NVIDIA Jetson Xavier running on an actual drone, requiring about 28 milliseconds of processing per RGB/IR image pair.
Deep Models for Visual Sentiment Analysis of Disaster-related Multimedia Content
Nov 30, 2021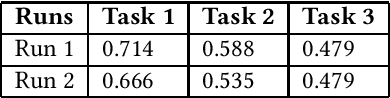
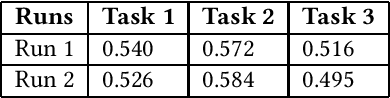
This paper presents a solutions for the MediaEval 2021 task namely "Visual Sentiment Analysis: A Natural Disaster Use-case". The task aims to extract and classify sentiments perceived by viewers and the emotional message conveyed by natural disaster-related images shared on social media. The task is composed of three sub-tasks including, one single label multi-class image classification task, and, two multi-label multi-class image classification tasks, with different sets of labels. In our proposed solutions, we rely mainly on two different state-of-the-art models namely, Inception-v3 and VggNet-19, pre-trained on ImageNet, which are fine-tuned for each of the three task using different strategies. Overall encouraging results are obtained on all the three tasks. On the single-label classification task (i.e. Task 1), we obtained the weighted average F1-scores of 0.540 and 0.526 for the Inception-v3 and VggNet-19 based solutions, respectively. On the multi-label classification i.e., Task 2 and Task 3, the weighted F1-score of our Inception-v3 based solutions was 0.572 and 0.516, respectively. Similarly, the weighted F1-score of our VggNet-19 based solution on Task 2 and Task 3 was 0.584 and 0.495, respectively.
MoCap-less Quantitative Evaluation of Ego-Pose Estimation Without Ground Truth Measurements
Feb 01, 2022
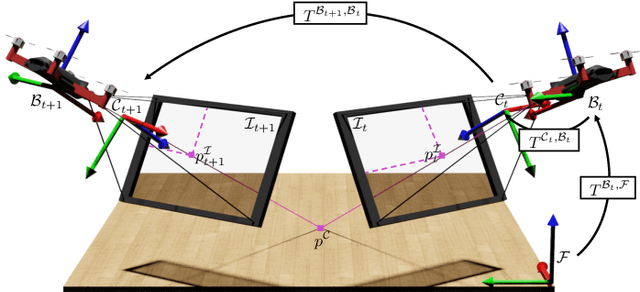

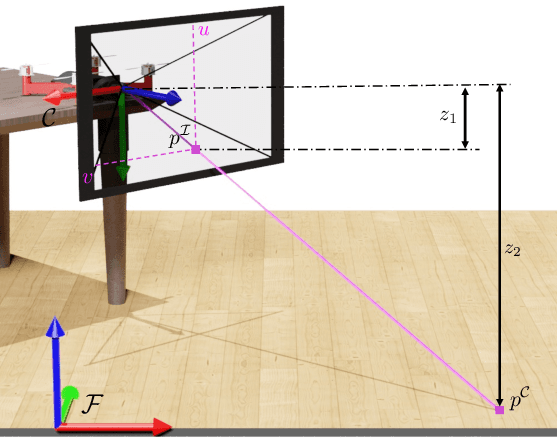
The emergence of data-driven approaches for control and planning in robotics have highlighted the need for developing experimental robotic platforms for data collection. However, their implementation is often complex and expensive, in particular for flying and terrestrial robots where the precise estimation of the position requires motion capture devices (MoCap) or Lidar. In order to simplify the use of a robotic platform dedicated to research on a wide range of indoor and outdoor environments, we present a data validation tool for ego-pose estimation that does not require any equipment other than the on-board camera. The method and tool allow a rapid, visual and quantitative evaluation of the quality of ego-pose sensors and are sensitive to different sources of flaws in the acquisition chain, ranging from desynchronization of the sensor flows to misevaluation of the geometric parameters of the robotic platform. Using computer vision, the information from the sensors is used to calculate the motion of a semantic scene point through its projection to the 2D image space of the on-board camera. The deviations of these keypoints from references created with a semi-automatic tool allow rapid and simple quality assessment of the data collected on the platform. To demonstrate the performance of our method, we evaluate it on two challenging standard UAV datasets as well as one dataset taken from a terrestrial robot.