 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Captioning with Attention for Smart Local Tourism using EfficientNet
Sep 18, 2020

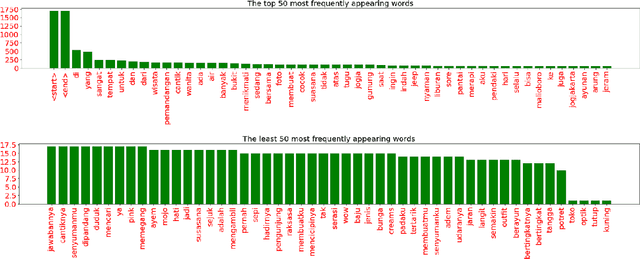
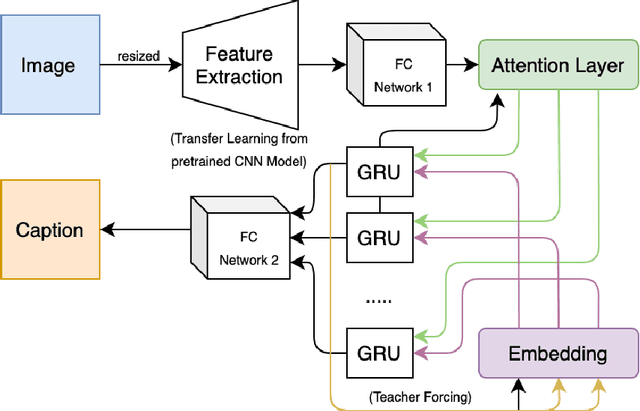
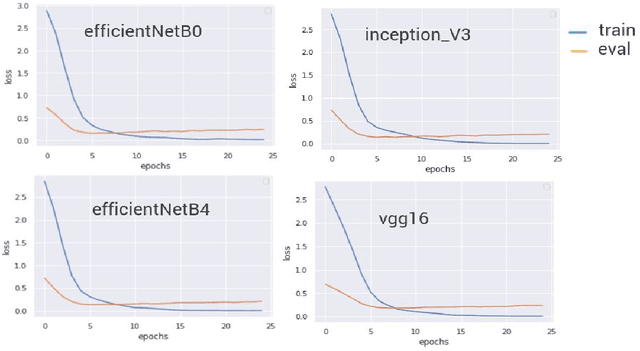
Smart systems have been massively developed to help humans in various tasks. Deep Learning technologies push even further in creating accurate assistant systems due to the explosion of data lakes. One of the smart system tasks is to disseminate users needed information. This is crucial in the tourism sector to promote local tourism destinations. In this research, we design a model of local tourism specific image captioning, which later will support the development of AI-powered systems that assist various users. The model is developed using a visual Attention mechanism and uses the state-of-the-art feature extractor architecture EfficientNet. A local tourism dataset is collected and is used in the research, along with two different kinds of captions. Captions that describe the image literally and captions that represent human logical responses when seeing the image. This is done to make the captioning model more humane when implemented in the assistance system. We compared the performance of two different models using EfficientNet architectures (B0 and B4) with other well known VGG16 and InceptionV3. The best BLEU scores we get are 73.39 and 24.51 for the training set and the validation set respectively, using EfficientNetB0. The captioning result using the developed model shows that the model can produce logical caption for local tourism-related images
Unsupervised deep learning techniques for powdery mildew recognition based on multispectral imaging
Dec 20, 2021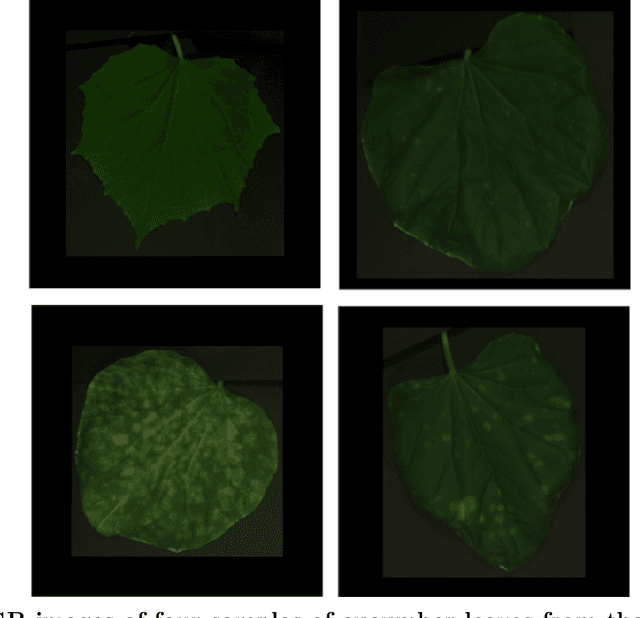
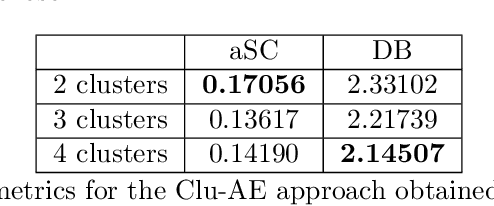
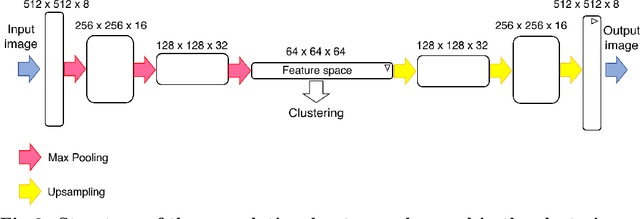
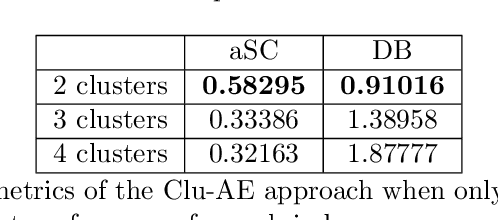
Objectives. Sustainable management of plant diseases is an open challenge which has relevant economic and environmental impact. Optimal strategies rely on human expertise for field scouting under favourable conditions to assess the current presence and extent of disease symptoms. This labor-intensive task is complicated by the large field area to be scouted, combined with the millimeter-scale size of the early symptoms to be detected. In view of this, image-based detection of early disease symptoms is an attractive approach to automate this process, enabling a potential high throughput monitoring at sustainable costs. Methods. Deep learning has been successfully applied in various domains to obtain an automatic selection of the relevant image features by learning filters via a training procedure. Deep learning has recently entered also the domain of plant disease detection: following this idea, in this work we present a deep learning approach to automatically recognize powdery mildew on cucumber leaves. We focus on unsupervised deep learning techniques applied to multispectral imaging data and we propose the use of autoencoder architectures to investigate two strategies for disease detection: i) clusterization of features in a compressed space; ii) anomaly detection. Results. The two proposed approaches have been assessed by quantitative indices. The clusterization approach is not fully capable by itself to provide accurate predictions but it does cater relevant information. Anomaly detection has instead a significant potential of resolution which could be further exploited as a prior for supervised architectures with a very limited number of labeled samples.
CheXstray: Real-time Multi-Modal Data Concordance for Drift Detection in Medical Imaging AI
Feb 06, 2022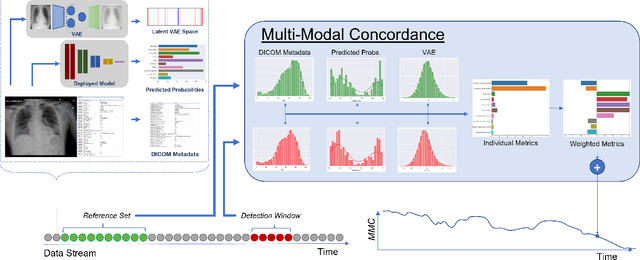
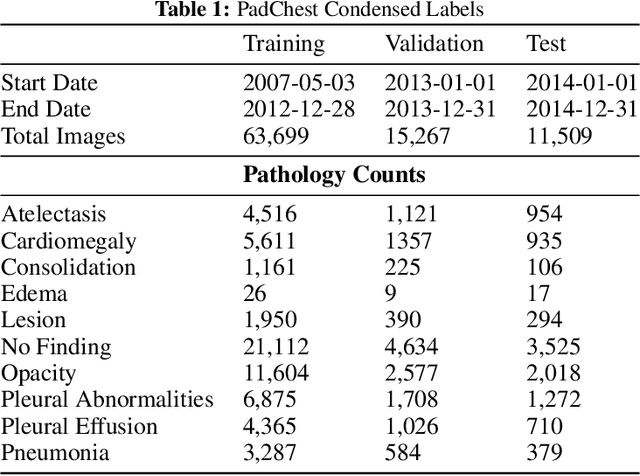

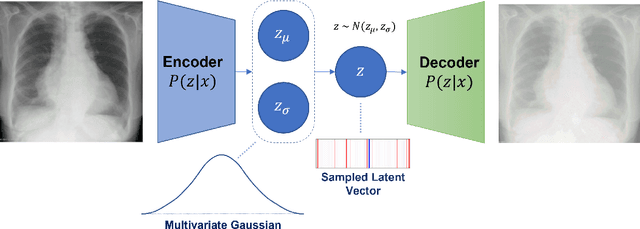
Rapidly expanding Clinical AI applications worldwide have the potential to impact to all areas of medical practice. Medical imaging applications constitute a vast majority of approved clinical AI applications. Though healthcare systems are eager to adopt AI solutions a fundamental question remains: \textit{what happens after the AI model goes into production?} We use the CheXpert and PadChest public datasets to build and test a medical imaging AI drift monitoring workflow that tracks data and model drift without contemporaneous ground truth. We simulate drift in multiple experiments to compare model performance with our novel multi-modal drift metric, which uses DICOM metadata, image appearance representation from a variational autoencoder (VAE), and model output probabilities as input. Through experimentation, we demonstrate a strong proxy for ground truth performance using unsupervised distributional shifts in relevant metadata, predicted probabilities, and VAE latent representation. Our key contributions include (1) proof-of-concept for medical imaging drift detection including use of VAE and domain specific statistical methods (2) a multi-modal methodology for measuring and unifying drift metrics (3) new insights into the challenges and solutions for observing deployed medical imaging AI (4) creation of open-source tools enabling others to easily run their own workflows or scenarios. This work has important implications for addressing the translation gap related to continuous medical imaging AI model monitoring in dynamic healthcare environments.
Multimodal Image Synthesis with Conditional Implicit Maximum Likelihood Estimation
Apr 07, 2020



Many tasks in computer vision and graphics fall within the framework of conditional image synthesis. In recent years, generative adversarial nets (GANs) have delivered impressive advances in quality of synthesized images. However, it remains a challenge to generate both diverse and plausible images for the same input, due to the problem of mode collapse. In this paper, we develop a new generic multimodal conditional image synthesis method based on Implicit Maximum Likelihood Estimation (IMLE) and demonstrate improved multimodal image synthesis performance on two tasks, single image super-resolution and image synthesis from scene layouts. We make our implementation publicly available.
Single-Stage Semantic Segmentation from Image Labels
May 16, 2020
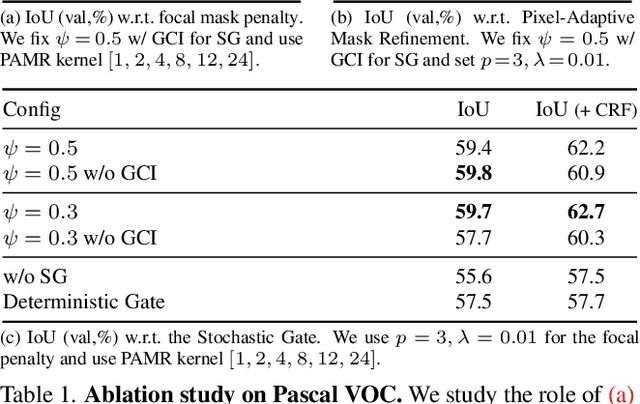

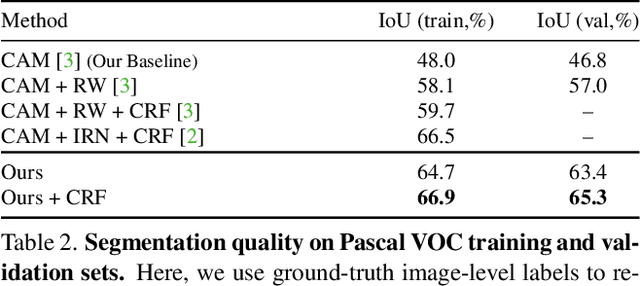
Recent years have seen a rapid growth in new approaches improving the accuracy of semantic segmentation in a weakly supervised setting, i.e. with only image-level labels available for training. However, this has come at the cost of increased model complexity and sophisticated multi-stage training procedures. This is in contrast to earlier work that used only a single stage $-$ training one segmentation network on image labels $-$ which was abandoned due to inferior segmentation accuracy. In this work, we first define three desirable properties of a weakly supervised method: local consistency, semantic fidelity, and completeness. Using these properties as guidelines, we then develop a segmentation-based network model and a self-supervised training scheme to train for semantic masks from image-level annotations in a single stage. We show that despite its simplicity, our method achieves results that are competitive with significantly more complex pipelines, substantially outperforming earlier single-stage methods.
IGLUE: A Benchmark for Transfer Learning across Modalities, Tasks, and Languages
Jan 27, 2022
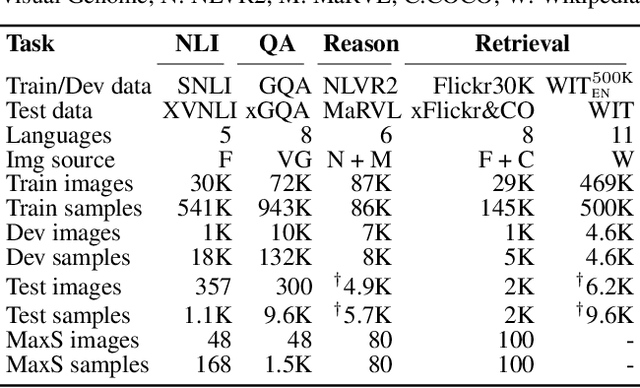
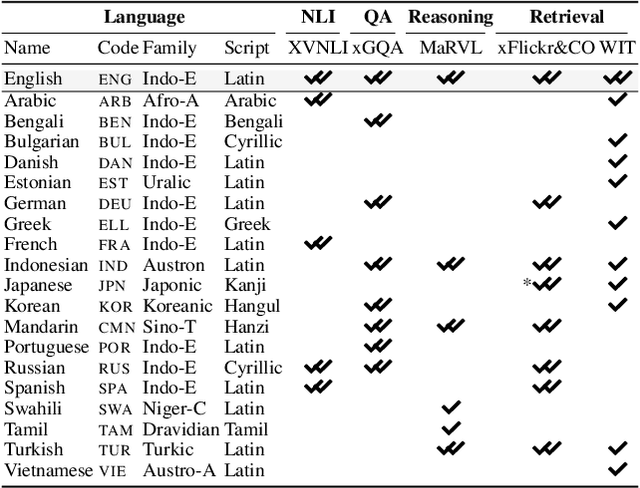
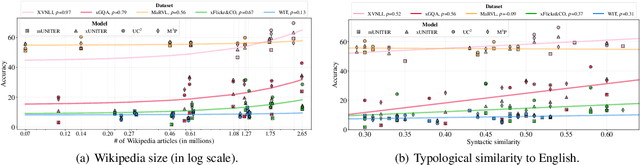
Reliable evaluation benchmarks designed for replicability and comprehensiveness have driven progress in machine learning. Due to the lack of a multilingual benchmark, however, vision-and-language research has mostly focused on English language tasks. To fill this gap, we introduce the Image-Grounded Language Understanding Evaluation benchmark. IGLUE brings together - by both aggregating pre-existing datasets and creating new ones - visual question answering, cross-modal retrieval, grounded reasoning, and grounded entailment tasks across 20 diverse languages. Our benchmark enables the evaluation of multilingual multimodal models for transfer learning, not only in a zero-shot setting, but also in newly defined few-shot learning setups. Based on the evaluation of the available state-of-the-art models, we find that translate-test transfer is superior to zero-shot transfer and that few-shot learning is hard to harness for many tasks. Moreover, downstream performance is partially explained by the amount of available unlabelled textual data for pretraining, and only weakly by the typological distance of target-source languages. We hope to encourage future research efforts in this area by releasing the benchmark to the community.
Mining the manifolds of deep generative models for multiple data-consistent solutions of ill-posed tomographic imaging problems
Feb 10, 2022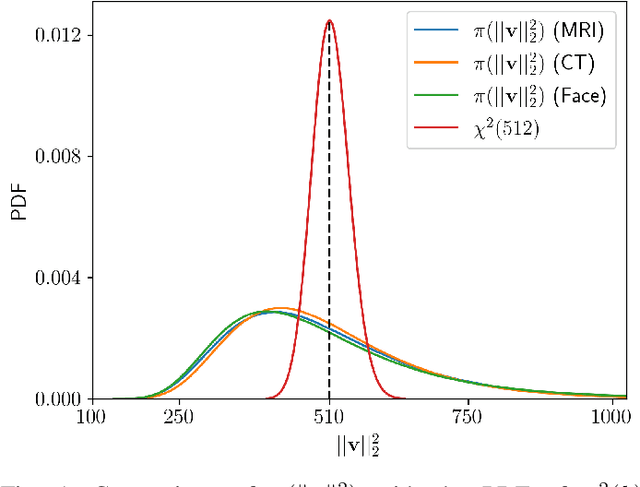
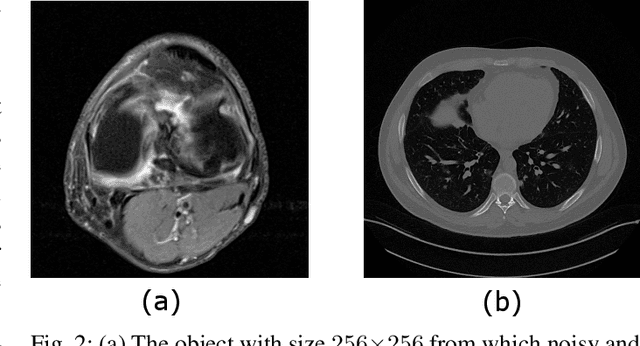
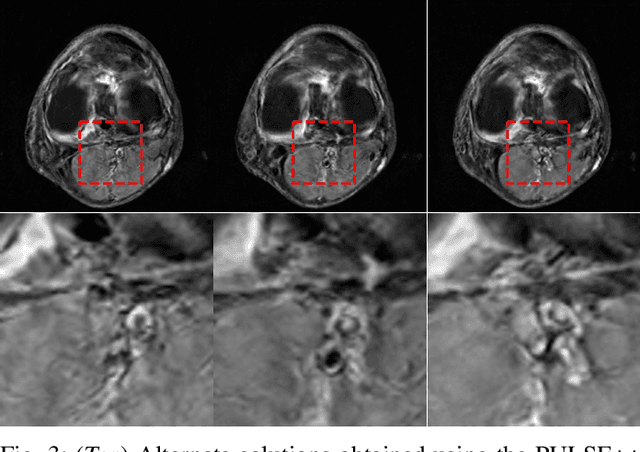
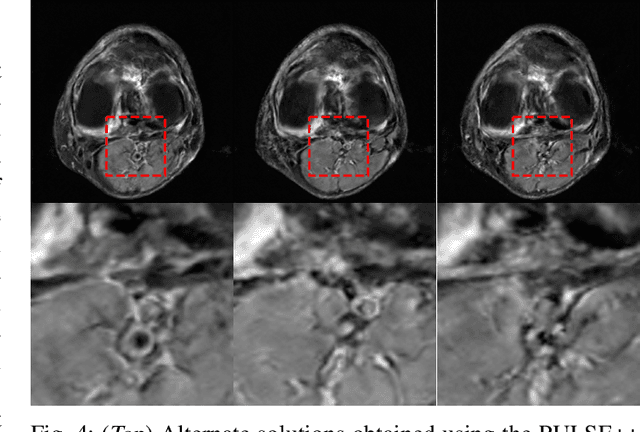
Tomographic imaging is in general an ill-posed inverse problem. Typically, a single regularized image estimate of the sought-after object is obtained from tomographic measurements. However, there may be multiple objects that are all consistent with the same measurement data. The ability to generate such alternate solutions is important because it may enable new assessments of imaging systems. In principle, this can be achieved by means of posterior sampling methods. In recent years, deep neural networks have been employed for posterior sampling with promising results. However, such methods are not yet for use with large-scale tomographic imaging applications. On the other hand, empirical sampling methods may be computationally feasible for large-scale imaging systems and enable uncertainty quantification for practical applications. Empirical sampling involves solving a regularized inverse problem within a stochastic optimization framework in order to obtain alternate data-consistent solutions. In this work, we propose a new empirical sampling method that computes multiple solutions of a tomographic inverse problem that are consistent with the same acquired measurement data. The method operates by repeatedly solving an optimization problem in the latent space of a style-based generative adversarial network (StyleGAN), and was inspired by the Photo Upsampling via Latent Space Exploration (PULSE) method that was developed for super-resolution tasks. The proposed method is demonstrated and analyzed via numerical studies that involve two stylized tomographic imaging modalities. These studies establish the ability of the method to perform efficient empirical sampling and uncertainty quantification.
Context Aware Image Annotation in Active Learning
Feb 06, 2020
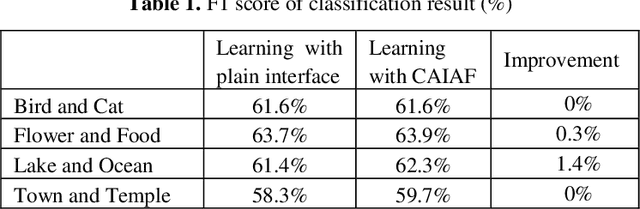

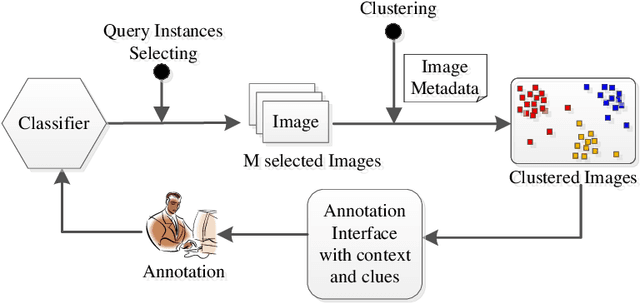
Image annotation for active learning is labor-intensive. Various automatic and semi-automatic labeling methods are proposed to save the labeling cost, but a reduction in the number of labeled instances does not guarantee a reduction in cost because the queries that are most valuable to the learner may be the most difficult or ambiguous cases, and therefore the most expensive for an oracle to label accurately. In this paper, we try to solve this problem by using image metadata to offer the oracle more clues about the image during annotation process. We propose a Context Aware Image Annotation Framework (CAIAF) that uses image metadata as similarity metric to cluster images into groups for annotation. We also present useful metadata information as context for each image on the annotation interface. Experiments show that it reduces that annotation cost with CAIAF compared to the conventional framework, while maintaining a high classification performance.
* arXiv admin note: text overlap with arXiv:1508.07647, arXiv:1207.3809 by other authors
Deep Video Prior for Video Consistency and Propagation
Jan 27, 2022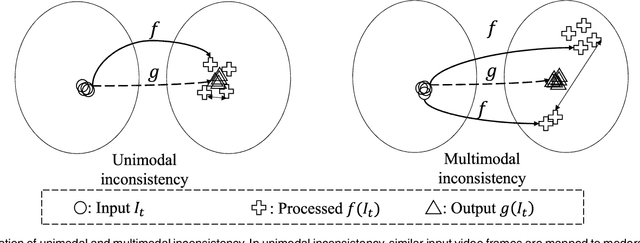
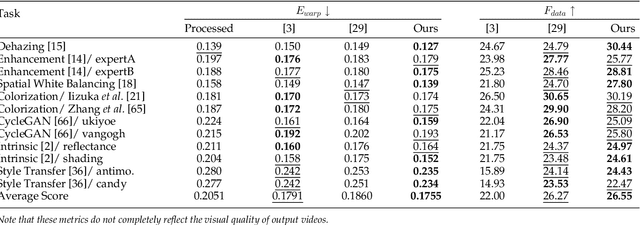
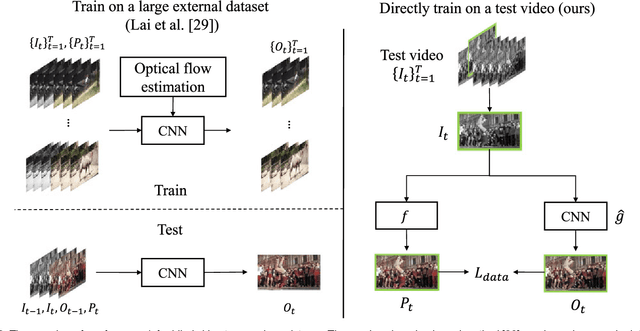
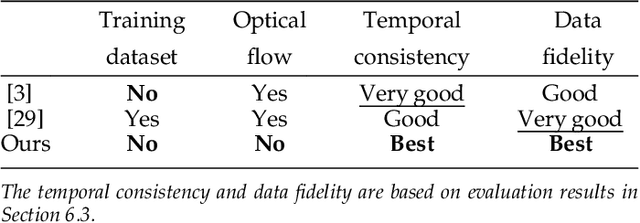
Applying an image processing algorithm independently to each video frame often leads to temporal inconsistency in the resulting video. To address this issue, we present a novel and general approach for blind video temporal consistency. Our method is only trained on a pair of original and processed videos directly instead of a large dataset. Unlike most previous methods that enforce temporal consistency with optical flow, we show that temporal consistency can be achieved by training a convolutional neural network on a video with Deep Video Prior (DVP). Moreover, a carefully designed iteratively reweighted training strategy is proposed to address the challenging multimodal inconsistency problem. We demonstrate the effectiveness of our approach on 7 computer vision tasks on videos. Extensive quantitative and perceptual experiments show that our approach obtains superior performance than state-of-the-art methods on blind video temporal consistency. We further extend DVP to video propagation and demonstrate its effectiveness in propagating three different types of information (color, artistic style, and object segmentation). A progressive propagation strategy with pseudo labels is also proposed to enhance DVP's performance on video propagation. Our source codes are publicly available at https://github.com/ChenyangLEI/deep-video-prior.
End-to-end optimized image compression for machines, a study
Nov 10, 2020

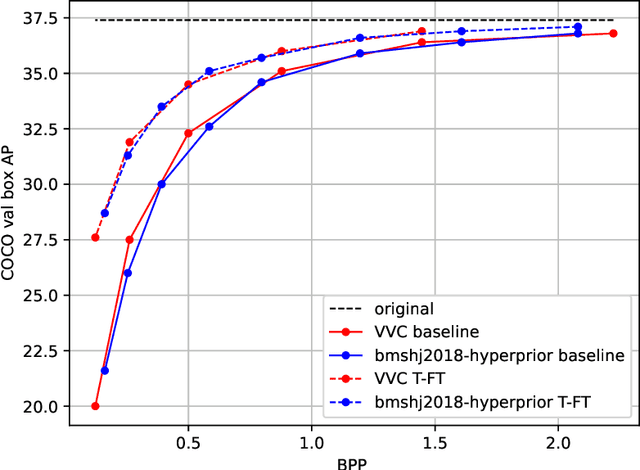
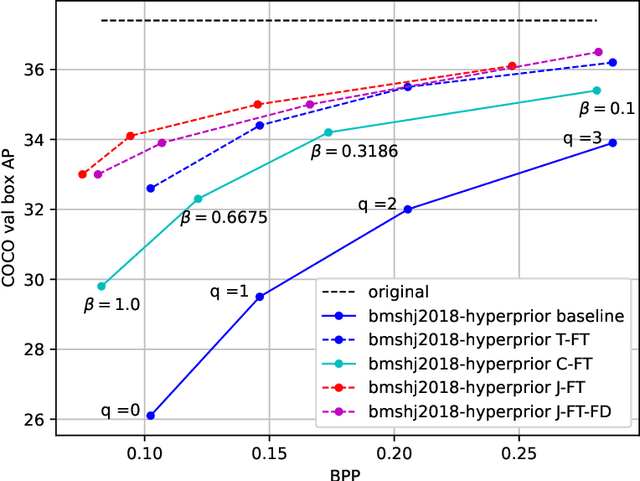
An increasing share of image and video content is analyzed by machines rather than viewed by humans, and therefore it becomes relevant to optimize codecs for such applications where the analysis is performed remotely. Unfortunately, conventional coding tools are challenging to specialize for machine tasks as they were originally designed for human perception. However, neural network based codecs can be jointly trained end-to-end with any convolutional neural network (CNN)-based task model. In this paper, we propose to study an end-to-end framework enabling efficient image compression for remote machine task analysis, using a chain composed of a compression module and a task algorithm that can be optimized end-to-end. We show that it is possible to significantly improve the task accuracy when fine-tuning jointly the codec and the task networks, especially at low bit-rates. Depending on training or deployment constraints, selective fine-tuning can be applied only on the encoder, decoder or task network and still achieve rate-accuracy improvements over an off-the-shelf codec and task network. Our results also demonstrate the flexibility of end-to-end pipelines for practical applications.