 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Lifelong Self-Supervision For Unpaired Image-to-Image Translation
Mar 31, 2020
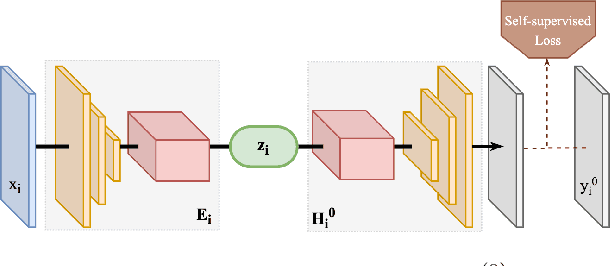
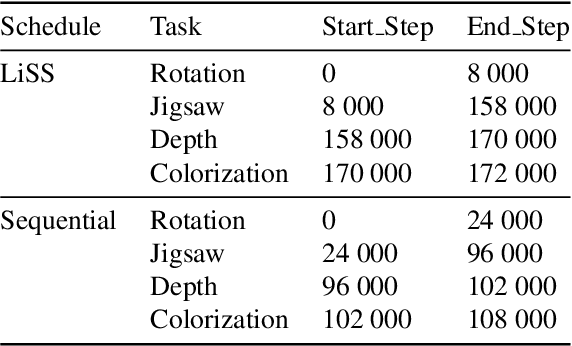
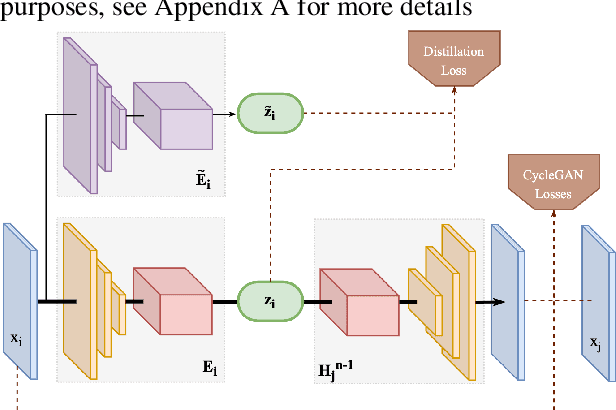
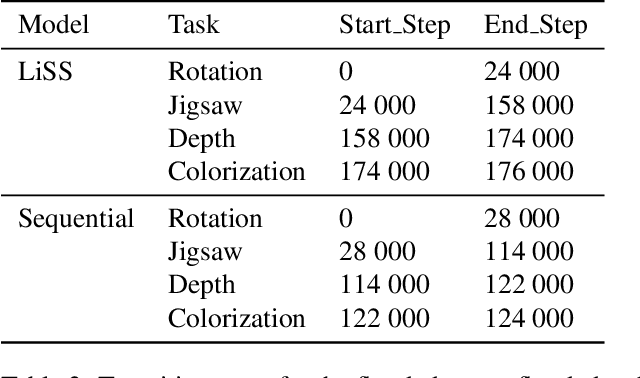
Unpaired Image-to-Image Translation (I2IT) tasks often suffer from lack of data, a problem which self-supervised learning (SSL) has recently been very popular and successful at tackling. Leveraging auxiliary tasks such as rotation prediction or generative colorization, SSL can produce better and more robust representations in a low data regime. Training such tasks along an I2IT task is however computationally intractable as model size and the number of task grow. On the other hand, learning sequentially could incur catastrophic forgetting of previously learned tasks. To alleviate this, we introduce Lifelong Self-Supervision (LiSS) as a way to pre-train an I2IT model (e.g., CycleGAN) on a set of self-supervised auxiliary tasks. By keeping an exponential moving average of past encoders and distilling the accumulated knowledge, we are able to maintain the network's validation performance on a number of tasks without any form of replay, parameter isolation or retraining techniques typically used in continual learning. We show that models trained with LiSS perform better on past tasks, while also being more robust than the CycleGAN baseline to color bias and entity entanglement (when two entities are very close).
CTRL-C: Camera calibration TRansformer with Line-Classification
Sep 06, 2021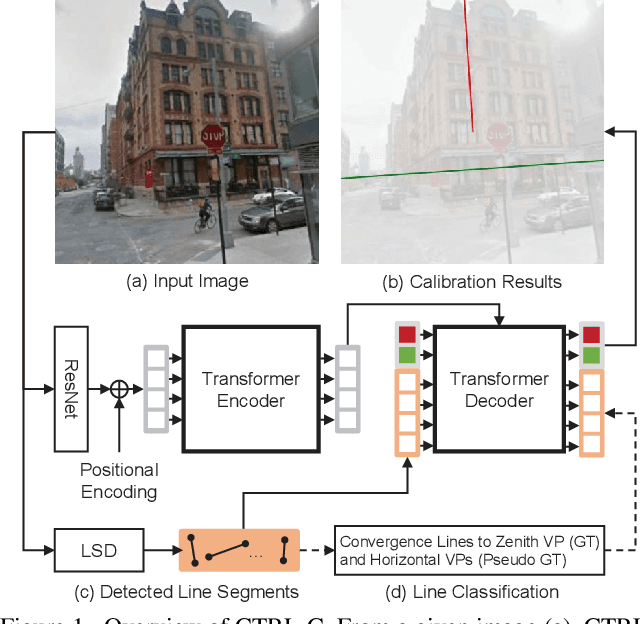
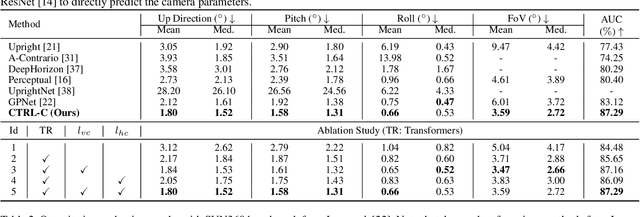
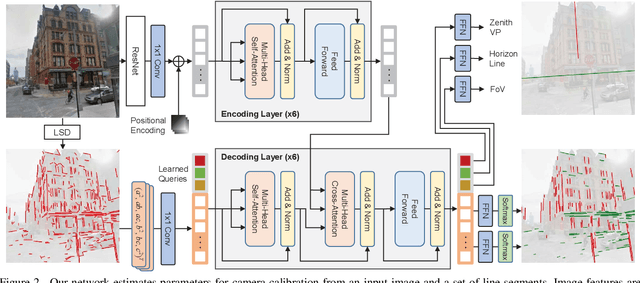
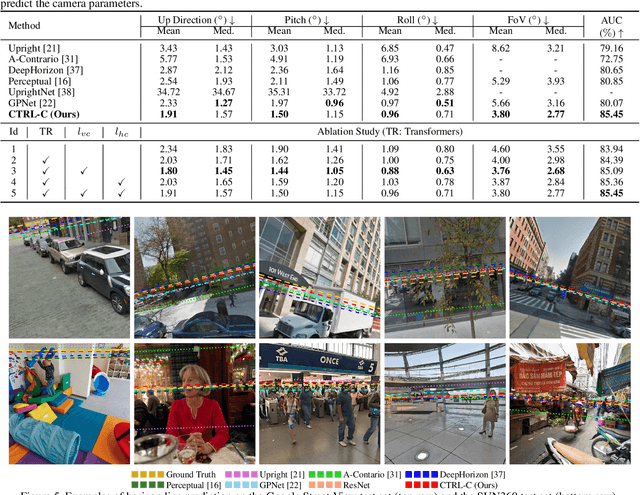
Single image camera calibration is the task of estimating the camera parameters from a single input image, such as the vanishing points, focal length, and horizon line. In this work, we propose Camera calibration TRansformer with Line-Classification (CTRL-C), an end-to-end neural network-based approach to single image camera calibration, which directly estimates the camera parameters from an image and a set of line segments. Our network adopts the transformer architecture to capture the global structure of an image with multi-modal inputs in an end-to-end manner. We also propose an auxiliary task of line classification to train the network to extract the global geometric information from lines effectively. Our experiments demonstrate that CTRL-C outperforms the previous state-of-the-art methods on the Google Street View and SUN360 benchmark datasets.
Out of distribution detection for skin and malaria images
Nov 02, 2021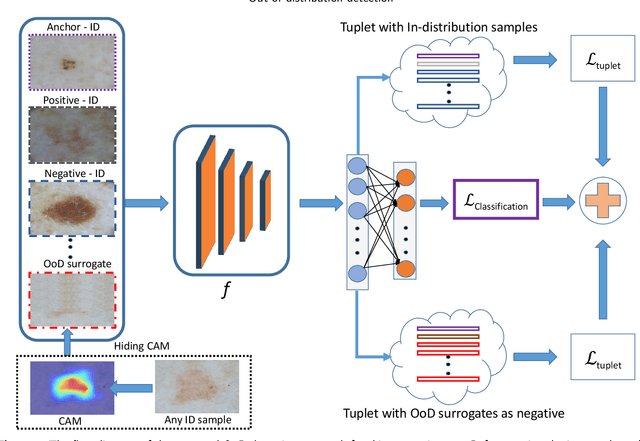
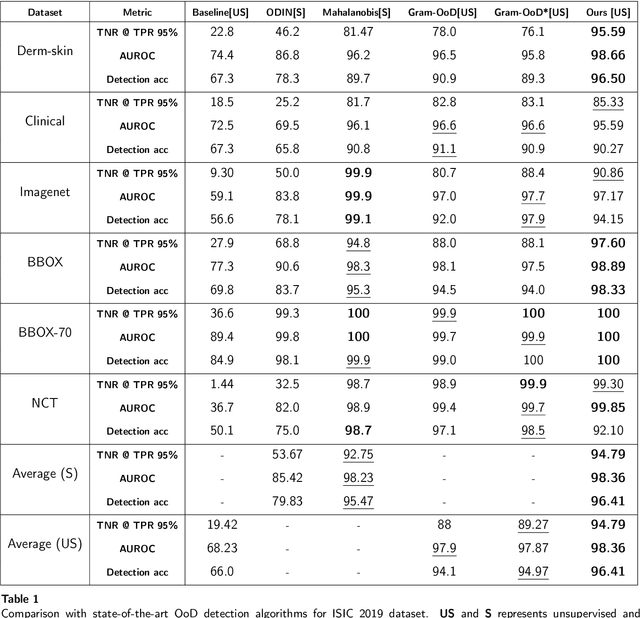
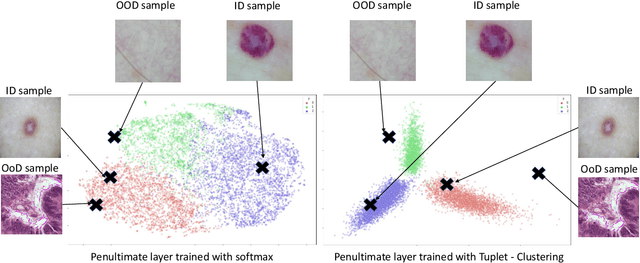
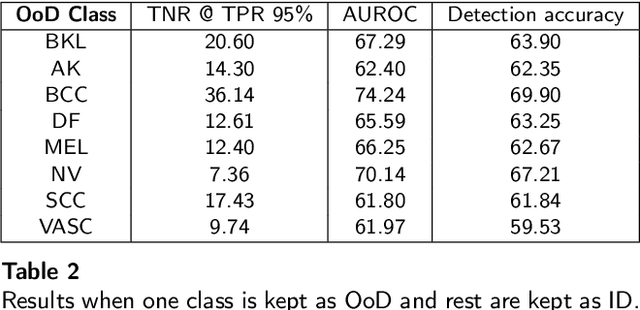
Deep neural networks have shown promising results in disease detection and classification using medical image data. However, they still suffer from the challenges of handling real-world scenarios especially reliably detecting out-of-distribution (OoD) samples. We propose an approach to robustly classify OoD samples in skin and malaria images without the need to access labeled OoD samples during training. Specifically, we use metric learning along with logistic regression to force the deep networks to learn much rich class representative features. To guide the learning process against the OoD examples, we generate ID similar-looking examples by either removing class-specific salient regions in the image or permuting image parts and distancing them away from in-distribution samples. During inference time, the K-reciprocal nearest neighbor is employed to detect out-of-distribution samples. For skin cancer OoD detection, we employ two standard benchmark skin cancer ISIC datasets as ID, and six different datasets with varying difficulty levels were taken as out of distribution. For malaria OoD detection, we use the BBBC041 malaria dataset as ID and five different challenging datasets as out of distribution. We achieved state-of-the-art results, improving 5% and 4% in TNR@TPR95% over the previous state-of-the-art for skin cancer and malaria OoD detection respectively.
PeaceGAN: A GAN-based Multi-Task Learning Method for SAR Target Image Generation with a Pose Estimator and an Auxiliary Classifier
Mar 29, 2021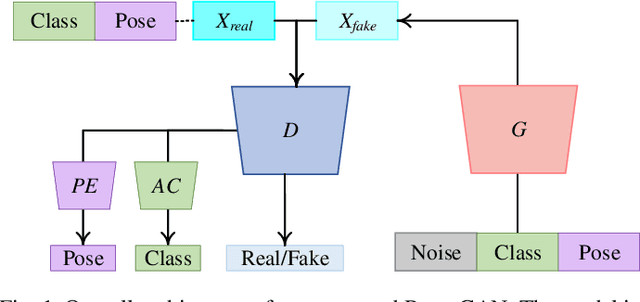
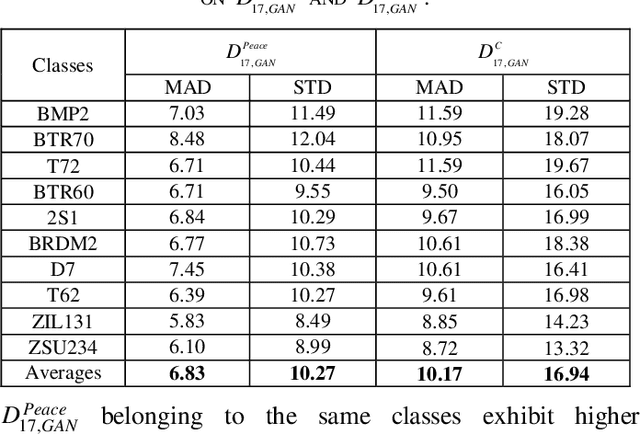
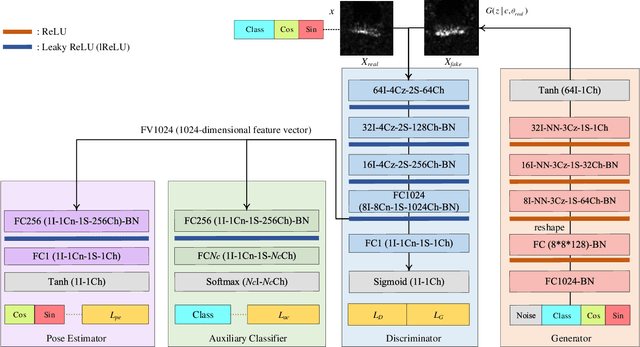
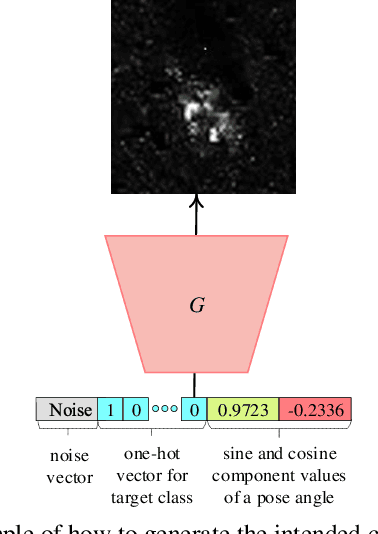
Although Generative Adversarial Networks (GANs) are successfully applied to diverse fields, training GANs on synthetic aperture radar (SAR) data is a challenging task mostly due to speckle noise. On the one hands, in a learning perspective of human's perception, it is natural to learn a task by using various information from multiple sources. However, in the previous GAN works on SAR target image generation, the information on target classes has only been used. Due to the backscattering characteristics of SAR image signals, the shapes and structures of SAR target images are strongly dependent on their pose angles. Nevertheless, the pose angle information has not been incorporated into such generative models for SAR target images. In this paper, we firstly propose a novel GAN-based multi-task learning (MTL) method for SAR target image generation, called PeaceGAN that uses both pose angle and target class information, which makes it possible to produce SAR target images of desired target classes at intended pose angles. For this, the PeaceGAN has two additional structures, a pose estimator and an auxiliary classifier, at the side of its discriminator to combine the pose and class information more efficiently. In addition, the PeaceGAN is jointly learned in an end-to-end manner as MTL with both pose angle and target class information, thus enhancing the diversity and quality of generated SAR target images The extensive experiments show that taking an advantage of both pose angle and target class learning by the proposed pose estimator and auxiliary classifier can help the PeaceGAN's generator effectively learn the distributions of SAR target images in the MTL framework, so that it can better generate the SAR target images more flexibly and faithfully at intended pose angles for desired target classes compared to the recent state-of-the-art methods.
Beyond Visual Attractiveness: Physically Plausible Single Image HDR Reconstruction for Spherical Panoramas
Mar 24, 2021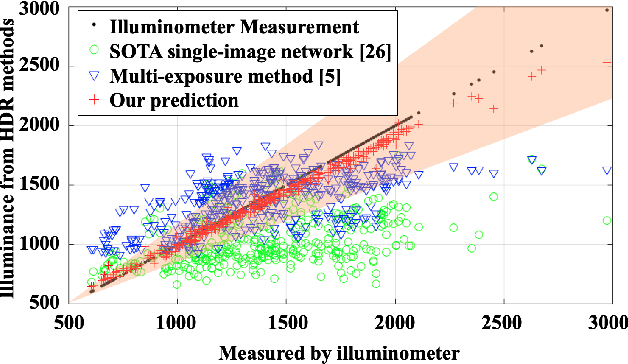
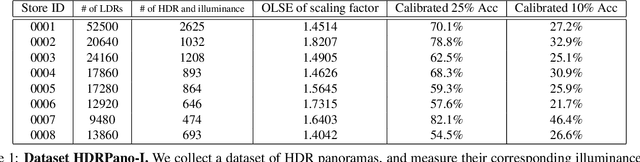
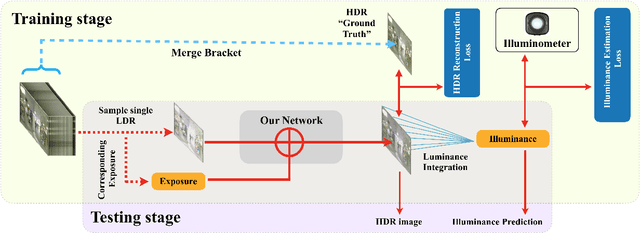
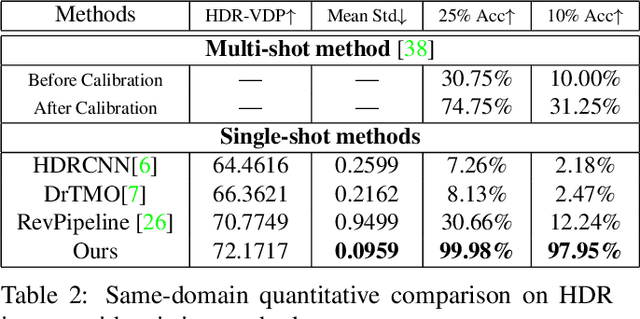
HDR reconstruction is an important task in computer vision with many industrial needs. The traditional approaches merge multiple exposure shots to generate HDRs that correspond to the physical quantity of illuminance of the scene. However, the tedious capturing process makes such multi-shot approaches inconvenient in practice. In contrast, recent single-shot methods predict a visually appealing HDR from a single LDR image through deep learning. But it is not clear whether the previously mentioned physical properties would still hold, without training the network to explicitly model them. In this paper, we introduce the physical illuminance constraints to our single-shot HDR reconstruction framework, with a focus on spherical panoramas. By the proposed physical regularization, our method can generate HDRs which are not only visually appealing but also physically plausible. For evaluation, we collect a large dataset of LDR and HDR images with ground truth illuminance measures. Extensive experiments show that our HDR images not only maintain high visual quality but also top all baseline methods in illuminance prediction accuracy.
Unified Image and Video Saliency Modeling
Mar 11, 2020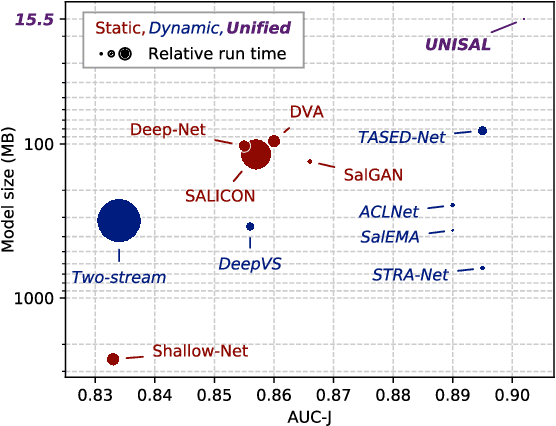

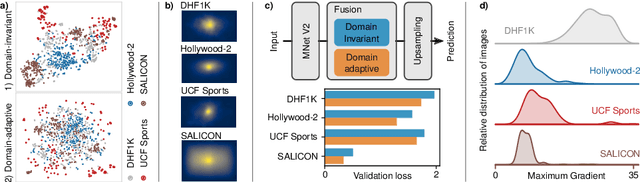
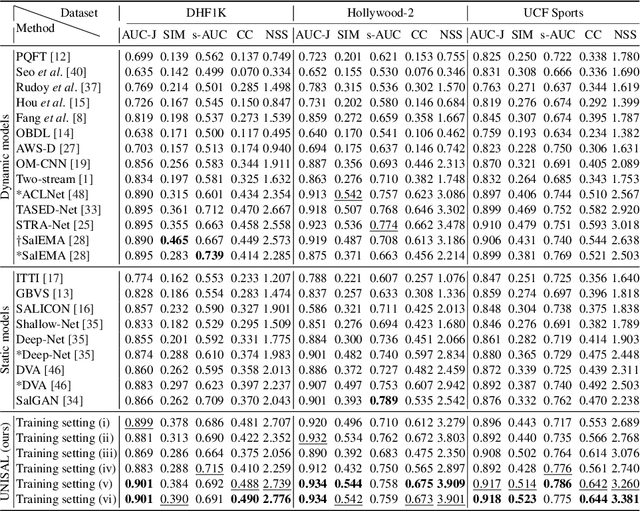
Visual saliency modeling for images and videos is treated as two independent tasks in recent computer vision literature. On the one hand, image saliency modeling is a well-studied problem and progress on benchmarks like \mbox{SALICON} and MIT300 is slowing. For video saliency prediction on the other hand, rapid gains have been achieved on the recent DHF1K benchmark through network architectures that are optimized for this task. Here, we take a step back and ask: Can image and video saliency modeling be approached via a unified model, with mutual benefit? We find that it is crucial to model the domain shift between image and video saliency data and between different video saliency datasets for effective joint modeling. We identify different sources of domain shift and address them through four novel domain adaptation techniques - Domain-Adaptive Priors, Domain-Adaptive Fusion, Domain-Adaptive Smoothing and Bypass-RNN - in addition to an improved formulation of learned Gaussian priors. We integrate these techniques into a simple and lightweight encoder-RNN-decoder-style network, UNISAL, and train the entire network simultaneously with image and video saliency data. We evaluate our method on the video saliency datasets DHF1K, Hollywood-2 and UCF-Sports, as well as the image saliency datasets SALICON and MIT300. With one set of parameters, our method achieves state-of-the-art performance on all video saliency datasets and is on par with the state-of-the-art for image saliency prediction, despite a 5 to 20-fold reduction in model size and the fastest runtime among all competing deep models. We provide retrospective analyses and ablation studies which demonstrate the importance of the domain shift modeling. The code is available at https://github.com/rdroste/unisal.
Robust Wavelet-based Assessment of Scaling with Applications
Jan 23, 2022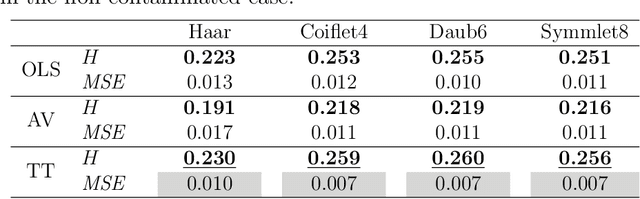
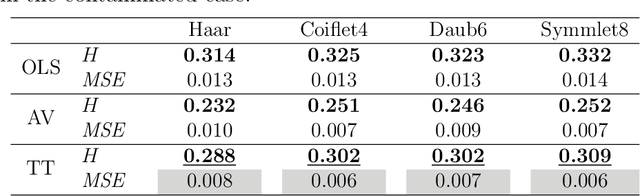
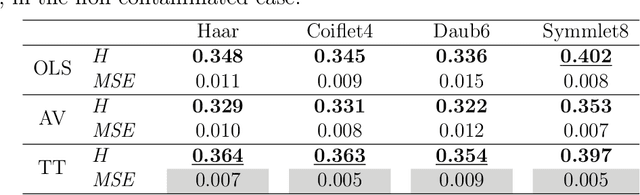
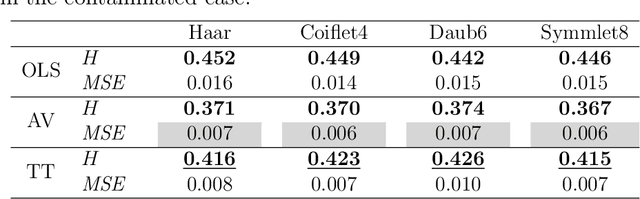
A number of approaches have dealt with statistical assessment of self-similarity, and many of those are based on multiscale concepts. Most rely on certain distributional assumptions which are usually violated by real data traces, often characterized by large temporal or spatial mean level shifts, missing values or extreme observations. A novel, robust approach based on Theil-type weighted regression is proposed for estimating self-similarity in two-dimensional data (images). The method is compared to two traditional estimation techniques that use wavelet decompositions; ordinary least squares (OLS) and Abry-Veitch bias correcting estimator (AV). As an application, the suitability of the self-similarity estimate resulting from the the robust approach is illustrated as a predictive feature in the classification of digitized mammogram images as cancerous or non-cancerous. The diagnostic employed here is based on the properties of image backgrounds, which is typically an unused modality in breast cancer screening. Classification results show nearly 68% accuracy, varying slightly with the choice of wavelet basis, and the range of multiresolution levels used.
An Automated and Robust Image Watermarking Scheme Based on Deep Neural Networks
Jul 05, 2020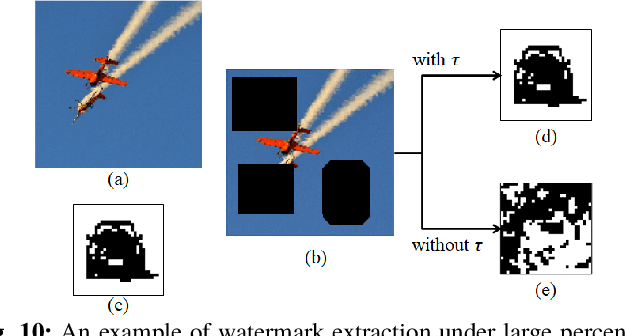
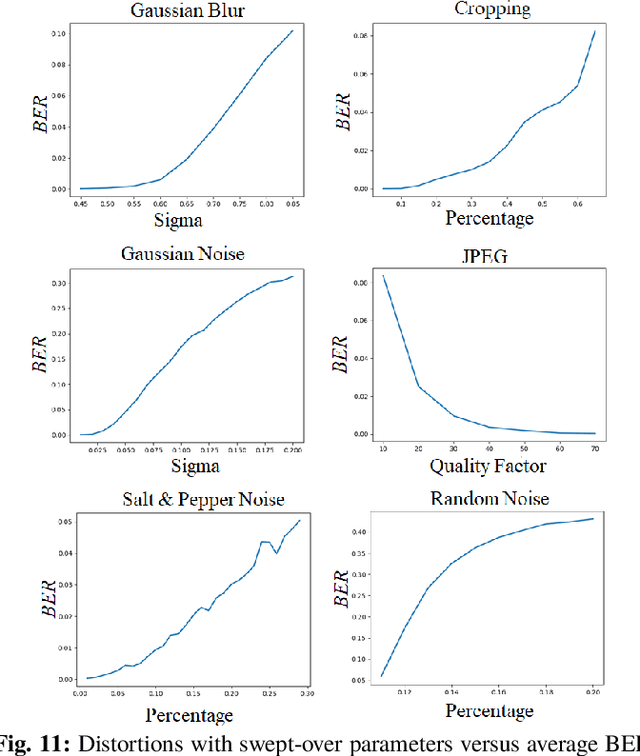

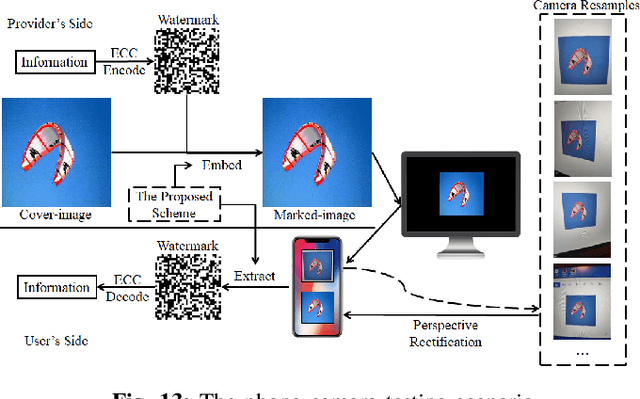
Digital image watermarking is the process of embedding and extracting a watermark covertly on a cover-image. To dynamically adapt image watermarking algorithms, deep learning-based image watermarking schemes have attracted increased attention during recent years. However, existing deep learning-based watermarking methods neither fully apply the fitting ability to learn and automate the embedding and extracting algorithms, nor achieve the properties of robustness and blindness simultaneously. In this paper, a robust and blind image watermarking scheme based on deep learning neural networks is proposed. To minimize the requirement of domain knowledge, the fitting ability of deep neural networks is exploited to learn and generalize an automated image watermarking algorithm. A deep learning architecture is specially designed for image watermarking tasks, which will be trained in an unsupervised manner to avoid human intervention and annotation. To facilitate flexible applications, the robustness of the proposed scheme is achieved without requiring any prior knowledge or adversarial examples of possible attacks. A challenging case of watermark extraction from phone camera-captured images demonstrates the robustness and practicality of the proposal. The experiments, evaluation, and application cases confirm the superiority of the proposed scheme.
Multimodal Image Synthesis with Conditional Implicit Maximum Likelihood Estimation
Apr 07, 2020



Many tasks in computer vision and graphics fall within the framework of conditional image synthesis. In recent years, generative adversarial nets (GANs) have delivered impressive advances in quality of synthesized images. However, it remains a challenge to generate both diverse and plausible images for the same input, due to the problem of mode collapse. In this paper, we develop a new generic multimodal conditional image synthesis method based on Implicit Maximum Likelihood Estimation (IMLE) and demonstrate improved multimodal image synthesis performance on two tasks, single image super-resolution and image synthesis from scene layouts. We make our implementation publicly available.
Learning from Mistakes based on Class Weighting with Application to Neural Architecture Search
Dec 01, 2021

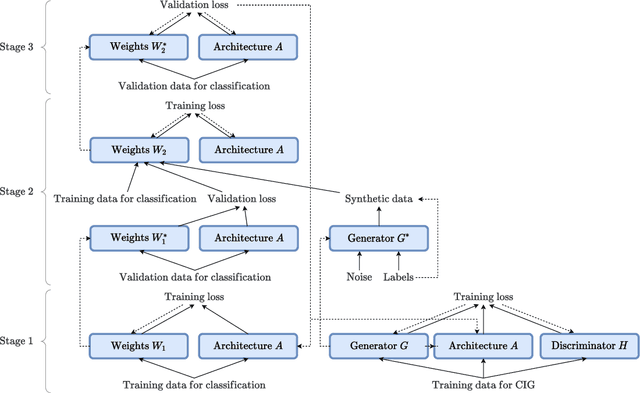
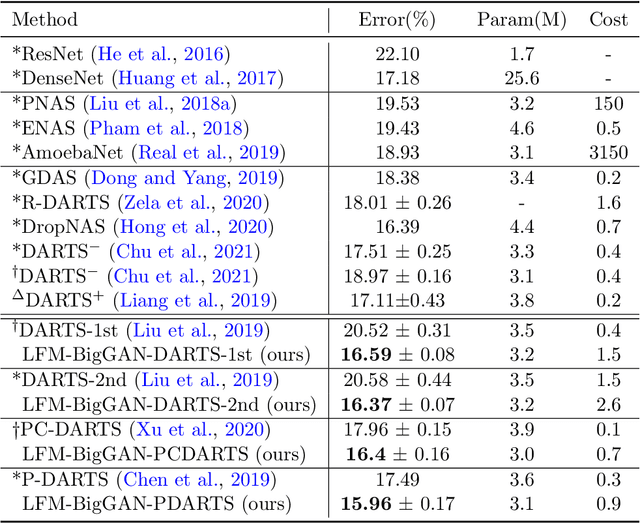
Learning from mistakes is an effective learning approach widely used in human learning, where a learner pays greater focus on mistakes to circumvent them in the future. It aids in improving the overall learning outcomes. In this work, we aim to investigate how effectively this exceptional learning ability can be used to improve machine learning models as well. We propose a simple and effective multi-level optimization framework called learning from mistakes (LFM), inspired by mistake-driven learning to train better machine learning models. Our LFM framework consists of a formulation involving three learning stages. The primary objective is to train a model to perform effectively on target tasks by using a re-weighting technique to prevent similar mistakes in the future. In this formulation, we learn the class weights by minimizing the validation loss of the model and re-train the model with the synthetic data from the image generator weighted by class-wise performance and real data. We apply our LFM framework for differential architecture search methods on image classification datasets such as CIFAR and ImageNet, where the results demonstrate the effectiveness of our proposed strategy.