 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Selective Information Passing for MR/CT Image Segmentation
Oct 10, 2020
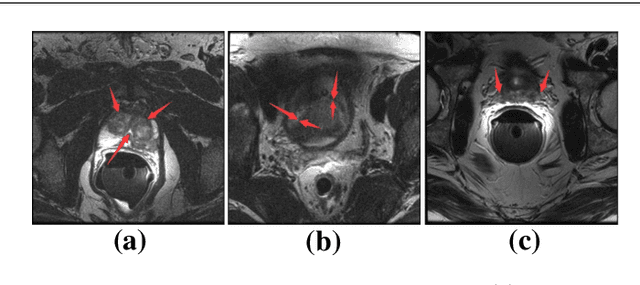
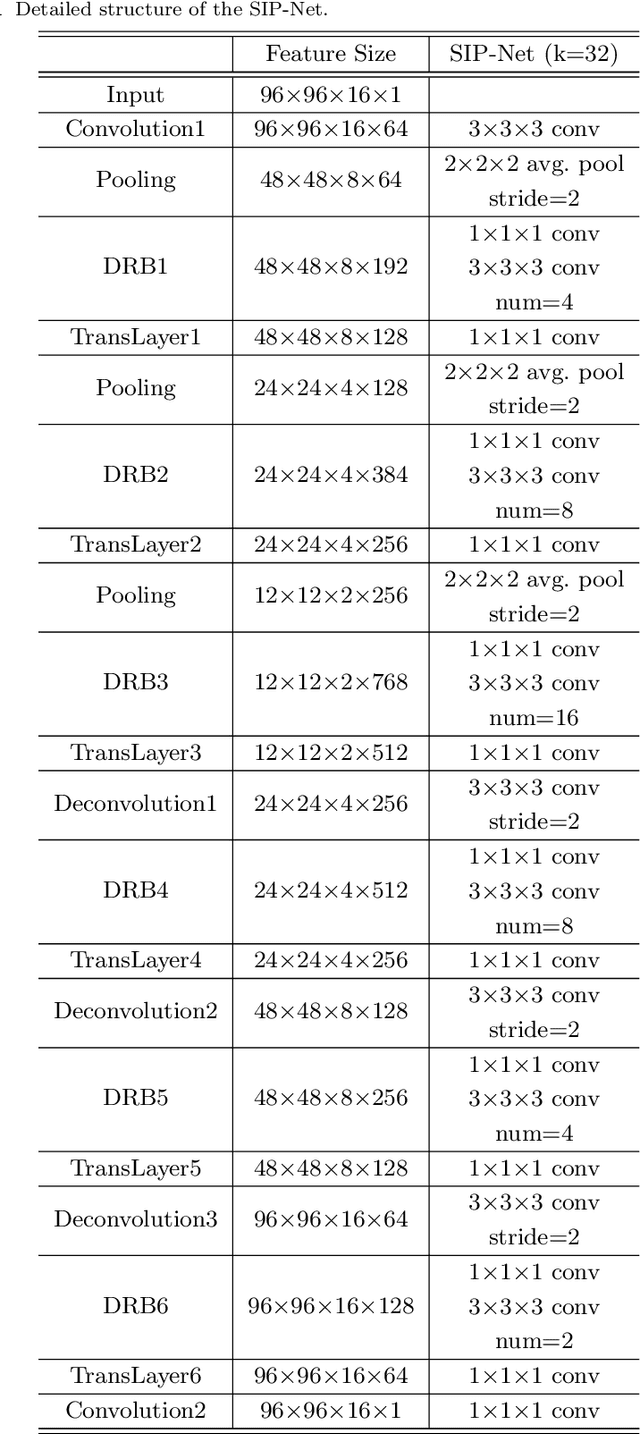
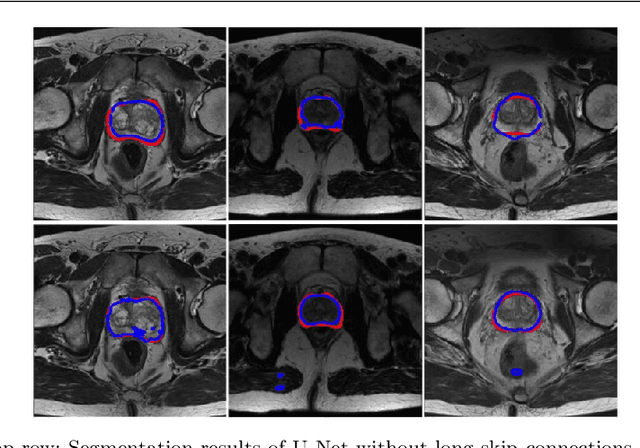
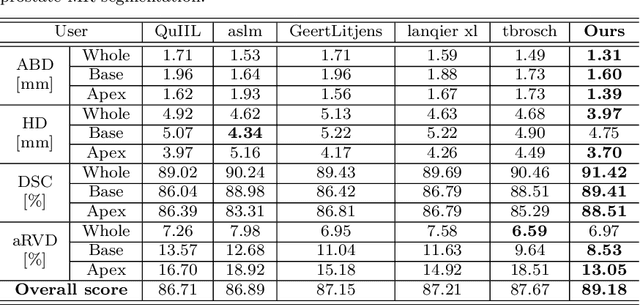
Automated medical image segmentation plays an important role in many clinical applications, which however is a very challenging task, due to complex background texture, lack of clear boundary and significant shape and texture variation between images. Many researchers proposed an encoder-decoder architecture with skip connections to combine low-level feature maps from the encoder path with high-level feature maps from the decoder path for automatically segmenting medical images. The skip connections have been shown to be effective in recovering fine-grained details of the target objects and may facilitate the gradient back-propagation. However, not all the feature maps transmitted by those connections contribute positively to the network performance. In this paper, to adaptively select useful information to pass through those skip connections, we propose a novel 3D network with self-supervised function, named selective information passing network (SIP-Net). We evaluate our proposed model on the MICCAI Prostate MR Image Segmentation 2012 Grant Challenge dataset, TCIA Pancreas CT-82 and MICCAI 2017 Liver Tumor Segmentation (LiTS) Challenge dataset. The experimental results across these data sets show that our model achieved improved segmentation results and outperformed other state-of-the-art methods. The source code of this work is available at https://github.com/ahukui/SIPNet.
Generating Quality Grasp Rectangle using Pix2Pix GAN for Intelligent Robot Grasping
Feb 20, 2022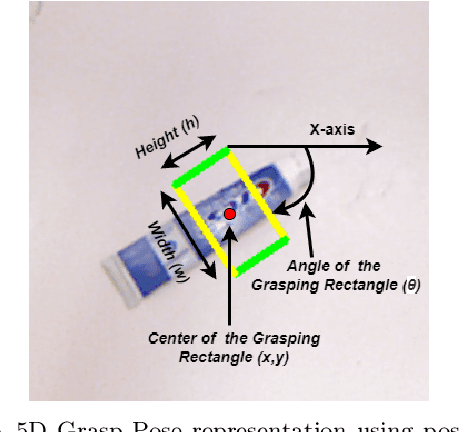
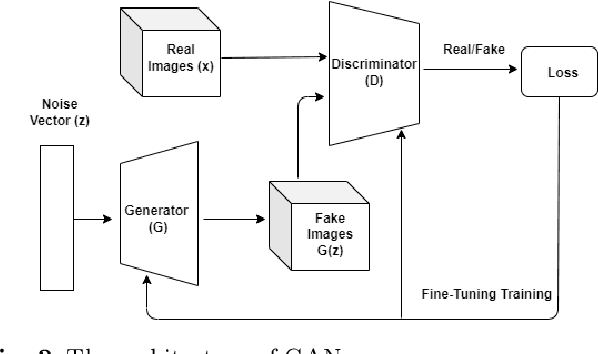
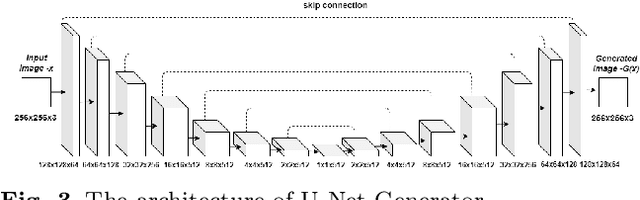
Intelligent robot grasping is a very challenging task due to its inherent complexity and non availability of sufficient labelled data. Since making suitable labelled data available for effective training for any deep learning based model including deep reinforcement learning is so crucial for successful grasp learning, in this paper we propose to solve the problem of generating grasping Poses/Rectangles using a Pix2Pix Generative Adversarial Network (Pix2Pix GAN), which takes an image of an object as input and produces the grasping rectangle tagged with the object as output. Here, we have proposed an end-to-end grasping rectangle generating methodology and embedding it to an appropriate place of an object to be grasped. We have developed two modules to obtain an optimal grasping rectangle. With the help of the first module, the pose (position and orientation) of the generated grasping rectangle is extracted from the output of Pix2Pix GAN, and then the extracted grasp pose is translated to the centroid of the object, since here we hypothesize that like the human way of grasping of regular shaped objects, the center of mass/centroids are the best places for stable grasping. For other irregular shaped objects, we allow the generated grasping rectangles as it is to be fed to the robot for grasp execution. The accuracy has significantly improved for generating the grasping rectangle with limited number of Cornell Grasping Dataset augmented by our proposed approach to the extent of 87.79%. Experiments show that our proposed generative model based approach gives the promising results in terms of executing successful grasps for seen as well as unseen objects.
A Novel Plug-in Module for Fine-Grained Visual Classification
Feb 08, 2022
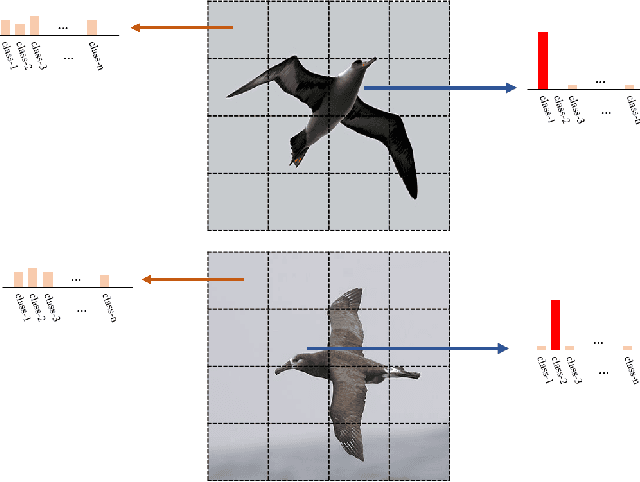
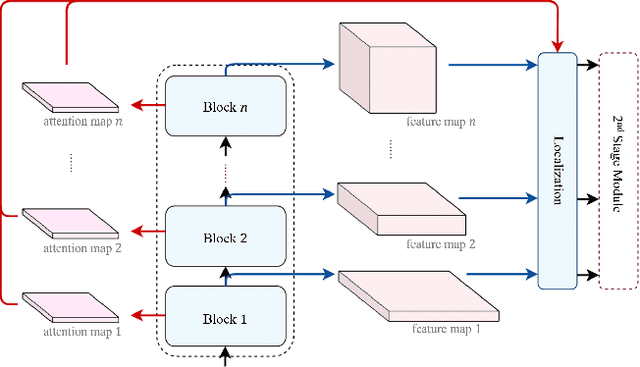
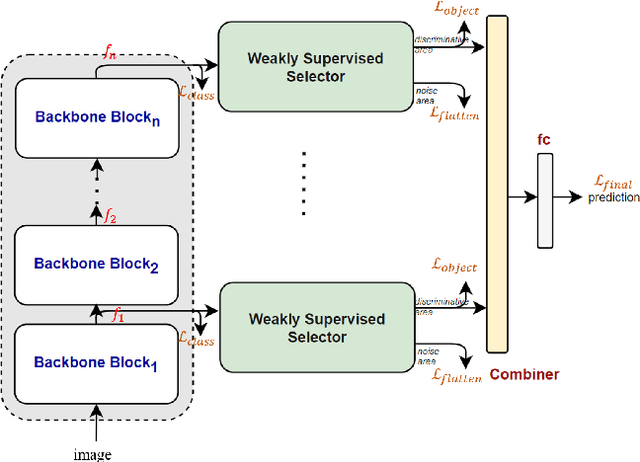
Visual classification can be divided into coarse-grained and fine-grained classification. Coarse-grained classification represents categories with a large degree of dissimilarity, such as the classification of cats and dogs, while fine-grained classification represents classifications with a large degree of similarity, such as cat species, bird species, and the makes or models of vehicles. Unlike coarse-grained visual classification, fine-grained visual classification often requires professional experts to label data, which makes data more expensive. To meet this challenge, many approaches propose to automatically find the most discriminative regions and use local features to provide more precise features. These approaches only require image-level annotations, thereby reducing the cost of annotation. However, most of these methods require two- or multi-stage architectures and cannot be trained end-to-end. Therefore, we propose a novel plug-in module that can be integrated to many common backbones, including CNN-based or Transformer-based networks to provide strongly discriminative regions. The plugin module can output pixel-level feature maps and fuse filtered features to enhance fine-grained visual classification. Experimental results show that the proposed plugin module outperforms state-of-the-art approaches and significantly improves the accuracy to 92.77\% and 92.83\% on CUB200-2011 and NABirds, respectively. We have released our source code in Github https://github.com/chou141253/FGVC-PIM.git.
Neural Geometric Parser for Single Image Camera Calibration
Jul 23, 2020
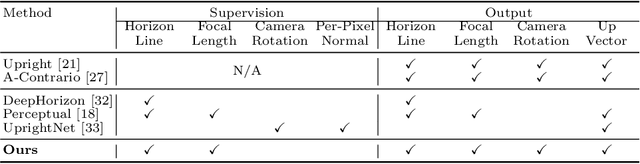
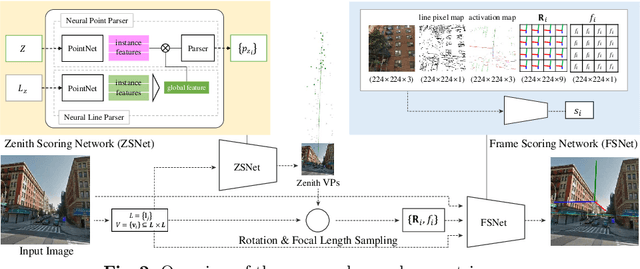
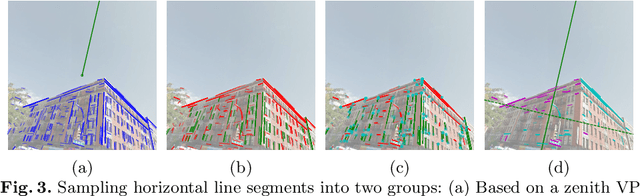
We propose a neural geometric parser learning single image camera calibration for man-made scenes. Unlike previous neural approaches that rely only on semantic cues obtained from neural networks, our approach considers both semantic and geometric cues, resulting in significant accuracy improvement. The proposed framework consists of two networks. Using line segments of an image as geometric cues, the first network estimates the zenith vanishing point and generates several candidates consisting of the camera rotation and focal length. The second network evaluates each candidate based on the given image and the geometric cues, where prior knowledge of man-made scenes is used for the evaluation. With the supervision of datasets consisting of the horizontal line and focal length of the images, our networks can be trained to estimate the same camera parameters. Based on the Manhattan world assumption, we can further estimate the camera rotation and focal length in a weakly supervised manner. The experimental results reveal that the performance of our neural approach is significantly higher than that of existing state-of-the-art camera calibration techniques for single images of indoor and outdoor scenes.
Integrating Visuospatial, Linguistic and Commonsense Structure into Story Visualization
Oct 21, 2021

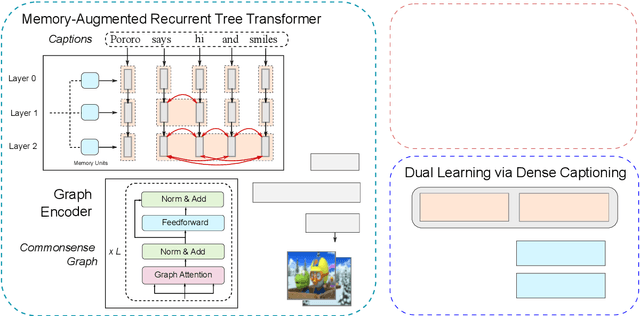
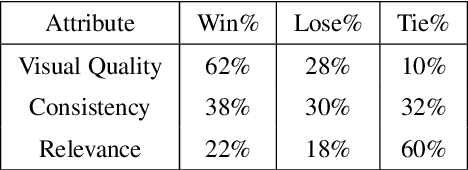
While much research has been done in text-to-image synthesis, little work has been done to explore the usage of linguistic structure of the input text. Such information is even more important for story visualization since its inputs have an explicit narrative structure that needs to be translated into an image sequence (or visual story). Prior work in this domain has shown that there is ample room for improvement in the generated image sequence in terms of visual quality, consistency and relevance. In this paper, we first explore the use of constituency parse trees using a Transformer-based recurrent architecture for encoding structured input. Second, we augment the structured input with commonsense information and study the impact of this external knowledge on the generation of visual story. Third, we also incorporate visual structure via bounding boxes and dense captioning to provide feedback about the characters/objects in generated images within a dual learning setup. We show that off-the-shelf dense-captioning models trained on Visual Genome can improve the spatial structure of images from a different target domain without needing fine-tuning. We train the model end-to-end using intra-story contrastive loss (between words and image sub-regions) and show significant improvements in several metrics (and human evaluation) for multiple datasets. Finally, we provide an analysis of the linguistic and visuo-spatial information. Code and data: https://github.com/adymaharana/VLCStoryGan.
GTrans: Spatiotemporal Autoregressive Transformer with Graph Embeddings for Nowcasting Extreme Events
Jan 18, 2022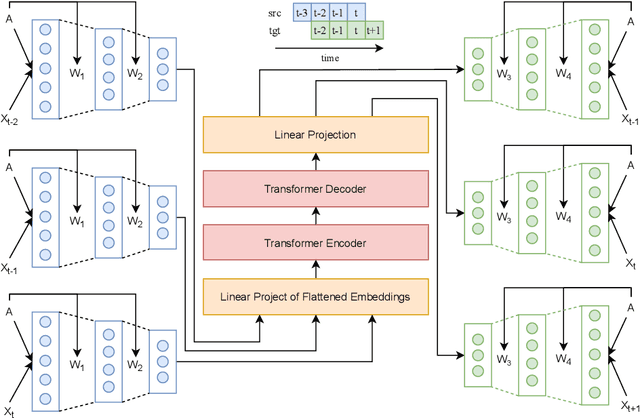

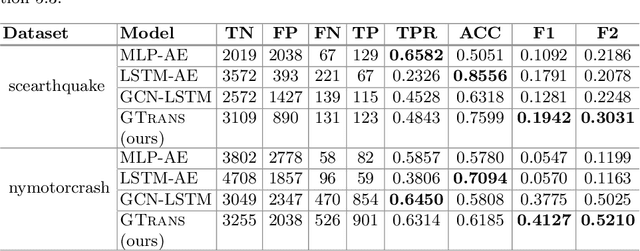
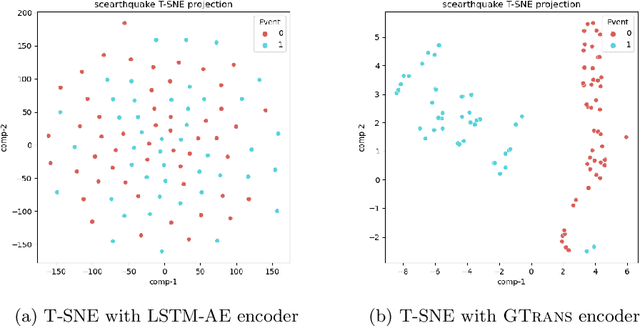
Spatiotemporal time series nowcasting should preserve temporal and spatial dynamics in the sense that generated new sequences from models respect the covariance relationship from history. Conventional feature extractors are built with deep convolutional neural networks (CNN). However, CNN models have limits to image-like applications where data can be formed with high-dimensional arrays. In contrast, applications in social networks, road traffic, physics, and chemical property prediction where data features can be organized with nodes and edges of graphs. Transformer architecture is an emerging method for predictive models, bringing high accuracy and efficiency due to attention mechanism design. This paper proposes a spatiotemporal model, namely GTrans, that transforms data features into graph embeddings and predicts temporal dynamics with a transformer model. According to our experiments, we demonstrate that GTrans can model spatial and temporal dynamics and nowcasts extreme events for datasets. Furthermore, in all the experiments, GTrans can achieve the highest F1 and F2 scores in binary-class prediction tests than the baseline models.
RATT: Recurrent Attention to Transient Tasks for Continual Image Captioning
Jul 13, 2020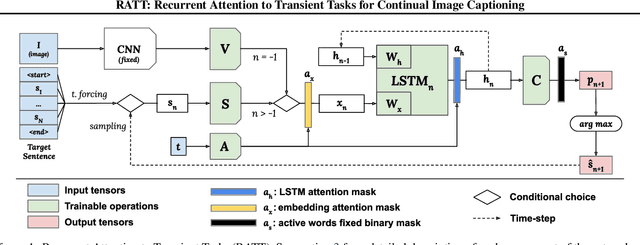
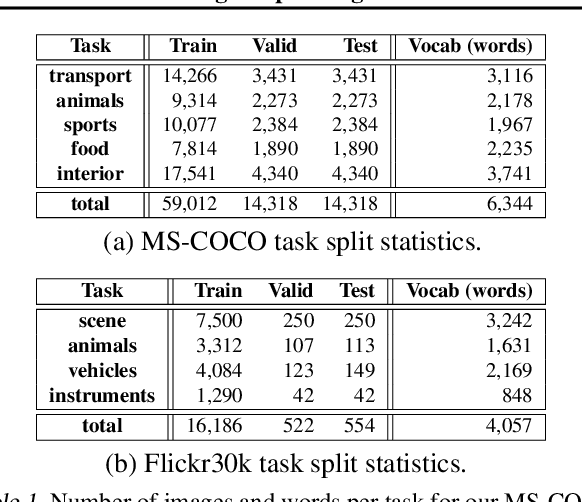
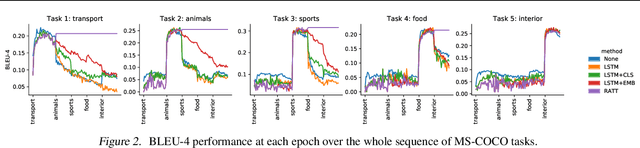
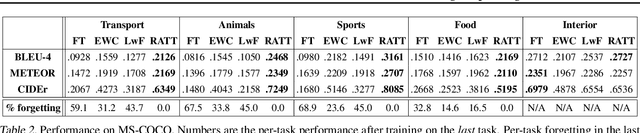
Research on continual learning has led to a variety of approaches to mitigating catastrophic forgetting in feed-forward classification networks. Until now surprisingly little attention has been focused on continual learning of recurrent models applied to problems like image captioning. In this paper we take a systematic look at continual learning of LSTM-based models for image captioning. We propose an attention-based approach that explicitly accommodates the transient nature of vocabularies in continual image captioning tasks -- i.e. that task vocabularies are not disjoint. We call our method Recurrent Attention to Transient Tasks (RATT), and also show how to adapt continual learning approaches based on weight egularization and knowledge distillation to recurrent continual learning problems. We apply our approaches to incremental image captioning problem on two new continual learning benchmarks we define using the MS-COCO and Flickr30 datasets. Our results demonstrate that RATT is able to sequentially learn five captioning tasks while incurring no forgetting of previously learned ones.
Geometrically Matched Multi-source Microscopic Image Synthesis Using Bidirectional Adversarial Networks
Oct 26, 2020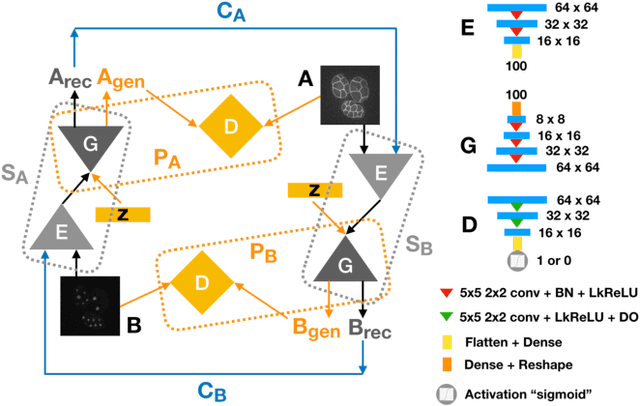

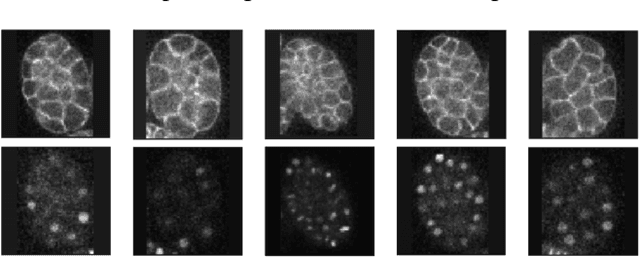
Microscopic images from different modality can provide more complete experimental information. In practice, biological and physical limitations may prohibit the acquisition of enough microscopic images at a given observation period. Image synthesis is one promising solution. However, most existing data synthesis methods only translate the image from a source domain to a target domain without strong geometric correlations. To address this issue, we propose a novel model to synthesize diversified microscopic images from multi-sources with different geometric features. The application of our model to a 3D live time-lapse embryonic images of C. elegans presents favorable results. To the best of our knowledge, it is the first effort to synthesize microscopic images with strong underlie geometric correlations from multi-source domains that of entirely separated spatial features.
Enhancement of Anime Imaging Enlargement using Modified Super-Resolution CNN
Oct 05, 2021
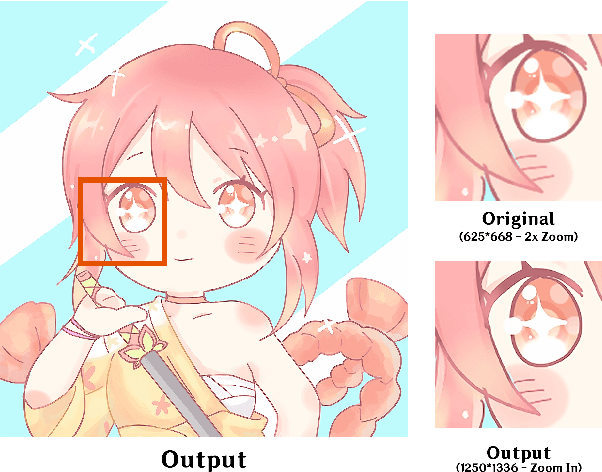

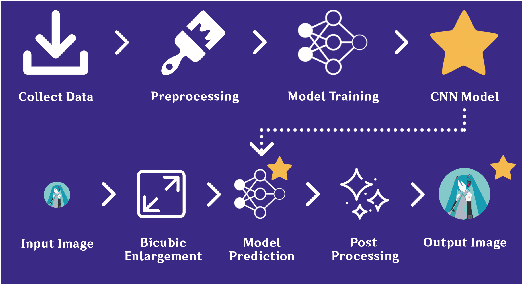
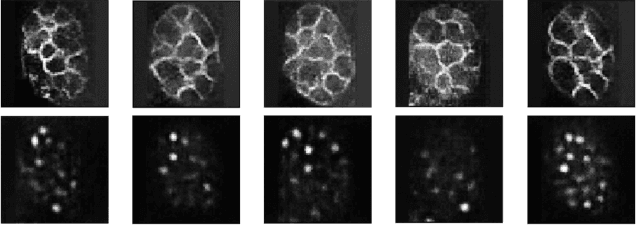
Anime is a storytelling medium similar to movies and books. Anime images are a kind of artworks, which are almost entirely drawn by hand. Hence, reproducing existing Anime with larger sizes and higher quality images is expensive. Therefore, we proposed a model based on convolutional neural networks to extract outstanding features of images, enlarge those images, and enhance the quality of Anime images. We trained the model with a training set of 160 images and a validation set of 20 images. We tested the trained model with a testing set of 20 images. The experimental results indicated that our model successfully enhanced the image quality with a larger image-size when compared with the common existing image enlargement and the original SRCNN method.
Siamese Network Features for Endoscopy Image and Video Localization
Mar 15, 2021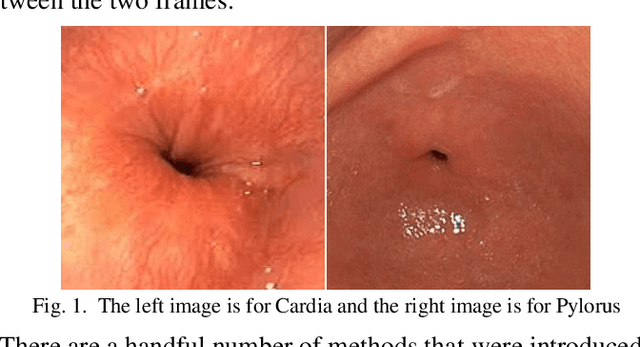
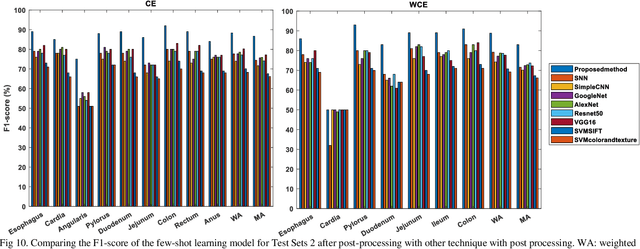
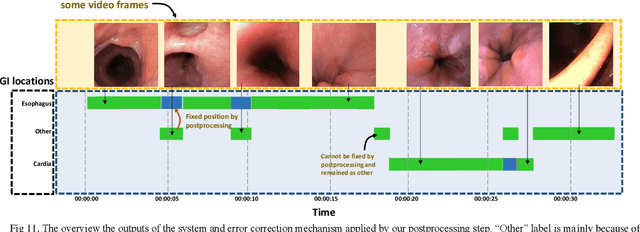
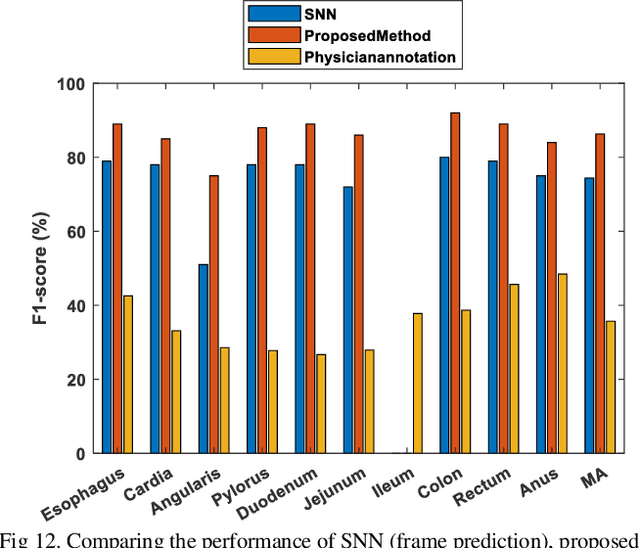
Conventional Endoscopy (CE) and Wireless Capsule Endoscopy (WCE) are known tools for diagnosing gastrointestinal (GI) tract disorders. Localizing frames provide valuable information about the anomaly location and also can help clinicians determine a more appropriate treatment plan. There are many automated algorithms to detect the anomaly. However, very few of the existing works address the issue of localization. In this study, we present a combination of meta-learning and deep learning for localizing both endoscopy images and video. A dataset is collected from 10 different anatomical positions of human GI tract. In the meta-learning section, the system was trained using 78 CE and 27 WCE annotated frames with a modified Siamese Neural Network (SNN) to predict the location of one single image/frame. Then, a postprocessing section using bidirectional long short-term memory is proposed for localizing a sequence of frames. Here, we have employed feature vector, distance and predicted location obtained from a trained SNN. The postprocessing section is trained and tested on 1,028 and 365 seconds of CE and WCE videos using hold-out validation (50%), and achieved F1-score of 86.3% and 83.0%, respectively. In addition, we performed subjective evaluation using nine gastroenterologists. The results show that the computer-aided methods can outperform gastroenterologists assessment of localization. The proposed method is compared with various approaches, such as support vector machine with hand-crafted features, convolutional neural network and the transfer learning-based methods, and showed better results. Therefore, it can be used in frame localization, which can help in video summarization and anomaly detection.