 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient and Robust Classification for Sparse Attacks
Jan 23, 2022
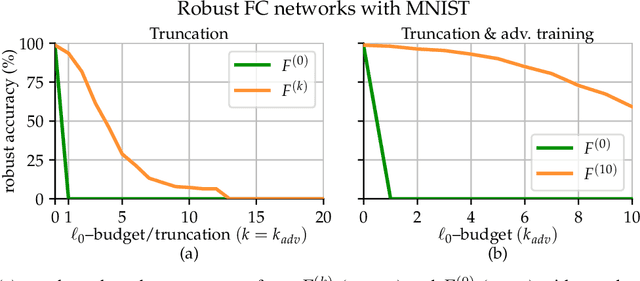
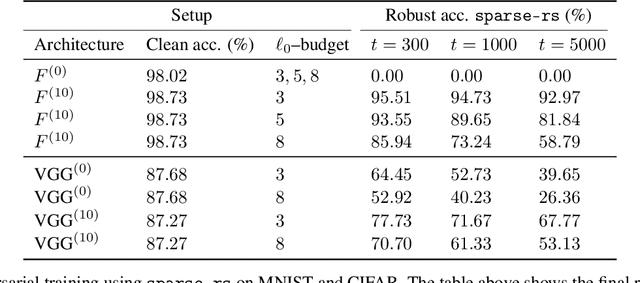
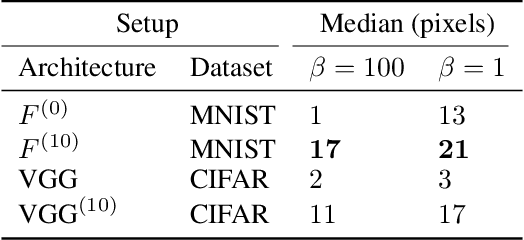

In the past two decades we have seen the popularity of neural networks increase in conjunction with their classification accuracy. Parallel to this, we have also witnessed how fragile the very same prediction models are: tiny perturbations to the inputs can cause misclassification errors throughout entire datasets. In this paper, we consider perturbations bounded by the $\ell_0$--norm, which have been shown as effective attacks in the domains of image-recognition, natural language processing, and malware-detection. To this end, we propose a novel defense method that consists of "truncation" and "adversarial training". We then theoretically study the Gaussian mixture setting and prove the asymptotic optimality of our proposed classifier. Motivated by the insights we obtain, we extend these components to neural network classifiers. We conduct numerical experiments in the domain of computer vision using the MNIST and CIFAR datasets, demonstrating significant improvement for the robust classification error of neural networks.
Semantic-aware Image Deblurring
Oct 09, 2019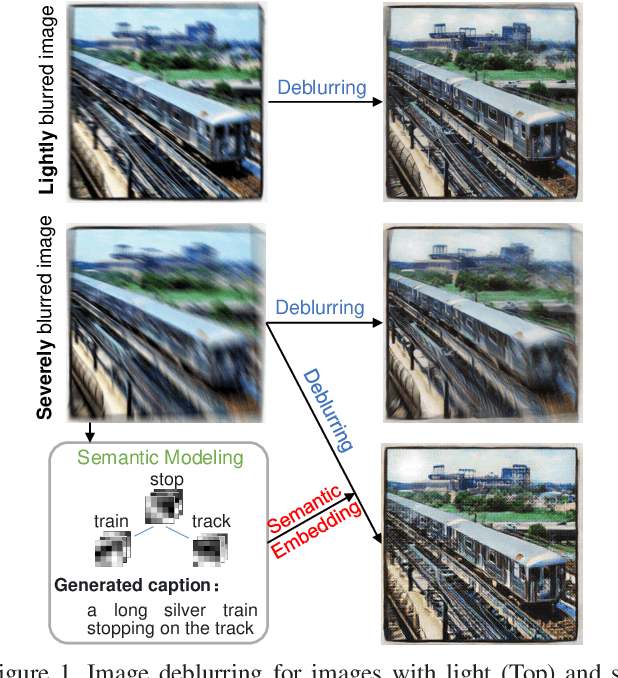

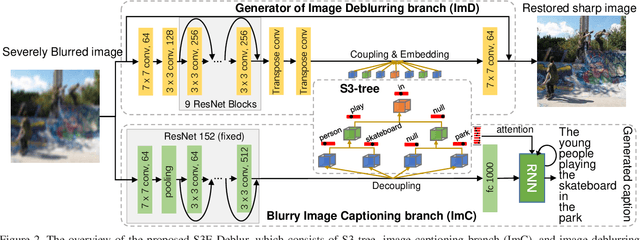

Image deblurring has achieved exciting progress in recent years. However, traditional methods fail to deblur severely blurred images, where semantic contents appears ambiguously. In this paper, we conduct image deblurring guided by the semantic contents inferred from image captioning. Specially, we propose a novel Structured-Spatial Semantic Embedding model for image deblurring (termed S3E-Deblur), which introduces a novel Structured-Spatial Semantic tree model (S3-tree) to bridge two basic tasks in computer vision: image deblurring (ImD) and image captioning (ImC). In particular, S3-tree captures and represents the semantic contents in structured spatial features in ImC, and then embeds the spatial features of the tree nodes into GAN based ImD. Co-training on S3-tree, ImC, and ImD is conducted to optimize the overall model in a multi-task end-to-end manner. Extensive experiments on severely blurred MSCOCO and GoPro datasets demonstrate the significant superiority of S3E-Deblur compared to the state-of-the-arts on both ImD and ImC tasks.
Algorithm for recognizing the contour of a honeycomb block
Dec 27, 2021The article discusses an algorithm for recognizing the contour of fragments of a honeycomb block. The inapplicability of ready-made functions of the OpenCV library is shown. Two proposed algorithms are considered. The direct scanning algorithm finds the extreme white pixels in the binarized image, it works adequately on convex shapes of products, but does not find a contour on concave areas and in cavities of products. To solve this problem, a scanning algorithm using a sliding matrix is proposed, which works correctly on products of any shape.
Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
Jan 04, 2022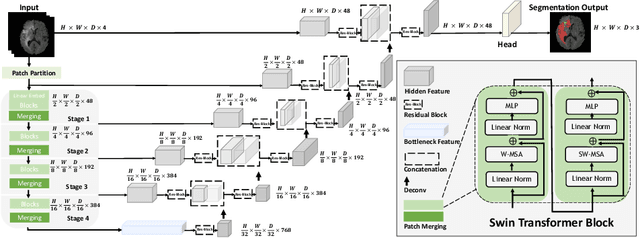

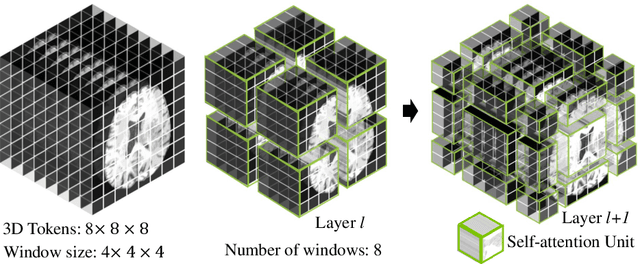
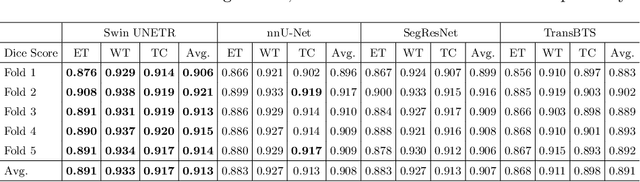
Semantic segmentation of brain tumors is a fundamental medical image analysis task involving multiple MRI imaging modalities that can assist clinicians in diagnosing the patient and successively studying the progression of the malignant entity. In recent years, Fully Convolutional Neural Networks (FCNNs) approaches have become the de facto standard for 3D medical image segmentation. The popular "U-shaped" network architecture has achieved state-of-the-art performance benchmarks on different 2D and 3D semantic segmentation tasks and across various imaging modalities. However, due to the limited kernel size of convolution layers in FCNNs, their performance of modeling long-range information is sub-optimal, and this can lead to deficiencies in the segmentation of tumors with variable sizes. On the other hand, transformer models have demonstrated excellent capabilities in capturing such long-range information in multiple domains, including natural language processing and computer vision. Inspired by the success of vision transformers and their variants, we propose a novel segmentation model termed Swin UNEt TRansformers (Swin UNETR). Specifically, the task of 3D brain tumor semantic segmentation is reformulated as a sequence to sequence prediction problem wherein multi-modal input data is projected into a 1D sequence of embedding and used as an input to a hierarchical Swin transformer as the encoder. The swin transformer encoder extracts features at five different resolutions by utilizing shifted windows for computing self-attention and is connected to an FCNN-based decoder at each resolution via skip connections. We have participated in BraTS 2021 segmentation challenge, and our proposed model ranks among the top-performing approaches in the validation phase. Code: https://monai.io/research/swin-unetr
Synthesizing Machine Learning Programs with PAC Guarantees via Statistical Sketching
Oct 11, 2021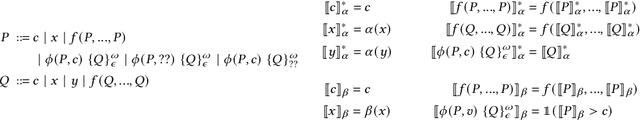
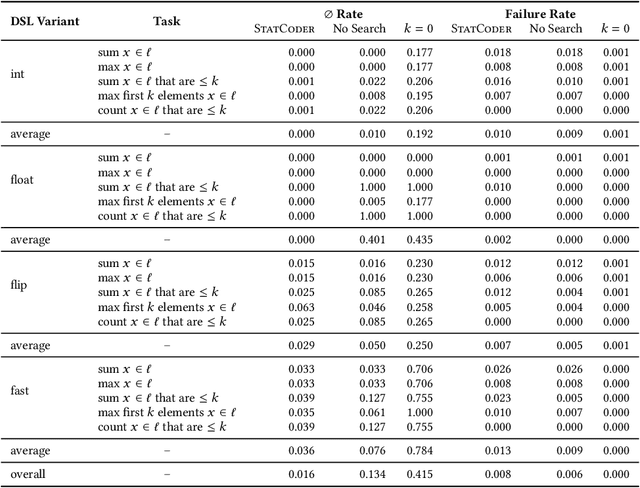
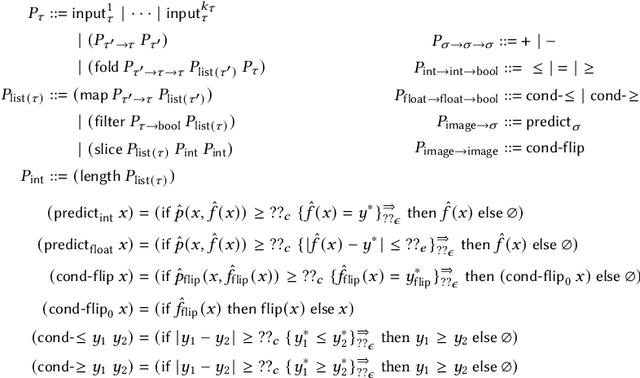
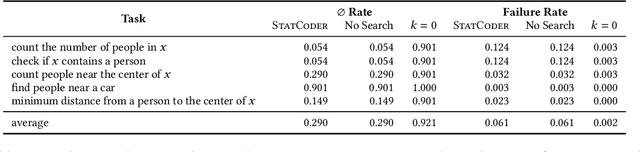
We study the problem of synthesizing programs that include machine learning components such as deep neural networks (DNNs). We focus on statistical properties, which are properties expected to hold with high probability -- e.g., that an image classification model correctly identifies people in images with high probability. We propose novel algorithms for sketching and synthesizing such programs by leveraging ideas from statistical learning theory to provide statistical soundness guarantees. We evaluate our approach on synthesizing list processing programs that include DNN components used to process image inputs, as well as case studies on image classification and on precision medicine. Our results demonstrate that our approach can be used to synthesize programs with probabilistic guarantees.
RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
Aug 20, 2019
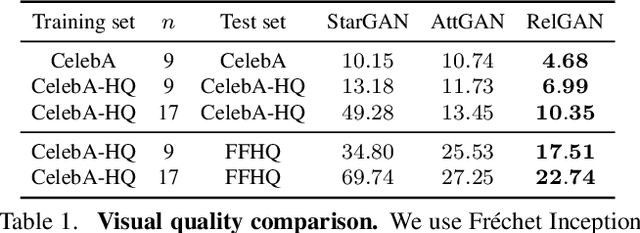
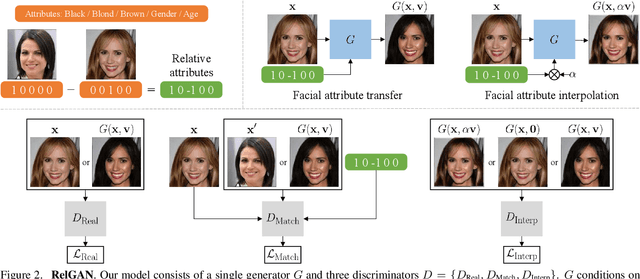
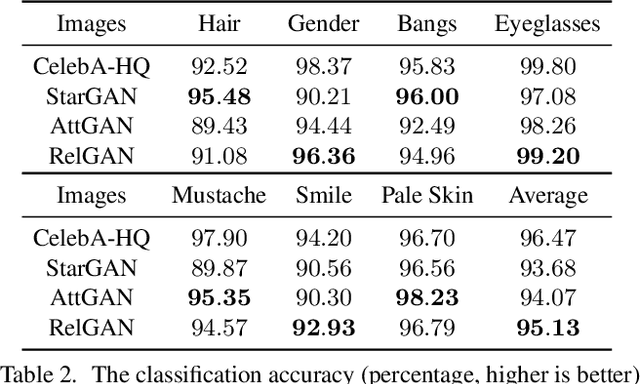
Multi-domain image-to-image translation has gained increasing attention recently. Previous methods take an image and some target attributes as inputs and generate an output image with the desired attributes. However, such methods have two limitations. First, these methods assume binary-valued attributes and thus cannot yield satisfactory results for fine-grained control. Second, these methods require specifying the entire set of target attributes, even if most of the attributes would not be changed. To address these limitations, we propose RelGAN, a new method for multi-domain image-to-image translation. The key idea is to use relative attributes, which describes the desired change on selected attributes. Our method is capable of modifying images by changing particular attributes of interest in a continuous manner while preserving the other attributes. Experimental results demonstrate both the quantitative and qualitative effectiveness of our method on the tasks of facial attribute transfer and interpolation.
Multimodal Dialogue Response Generation
Oct 16, 2021
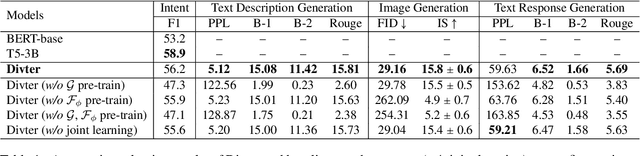
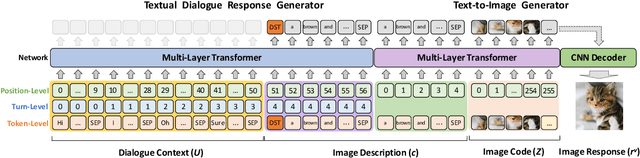
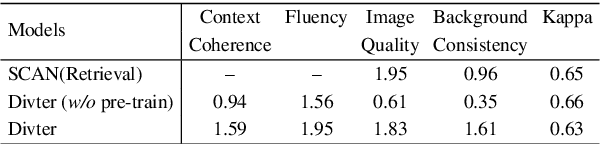
Responsing with image has been recognized as an important capability for an intelligent conversational agent. Yet existing works only focus on exploring the multimodal dialogue models which depend on retrieval-based methods, but neglecting generation methods. To fill in the gaps, we first present a multimodal dialogue generation model, which takes the dialogue history as input, then generates a textual sequence or an image as response. Learning such a model often requires multimodal dialogues containing both texts and images which are difficult to obtain. Motivated by the challenge in practice, we consider multimodal dialogue generation under a natural assumption that only limited training examples are available. In such a low-resource setting, we devise a novel conversational agent, Divter, in order to isolate parameters that depend on multimodal dialogues from the entire generation model. By this means, the major part of the model can be learned from a large number of text-only dialogues and text-image pairs respectively, then the whole parameters can be well fitted using the limited training examples. Extensive experiments demonstrate our method achieves state-of-the-art results in both automatic and human evaluation, and can generate informative text and high-resolution image responses.
Bubble identification from images with machine learning methods
Feb 07, 2022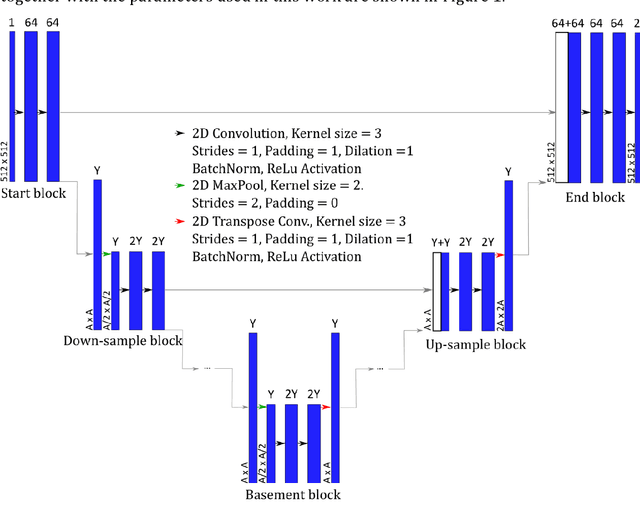
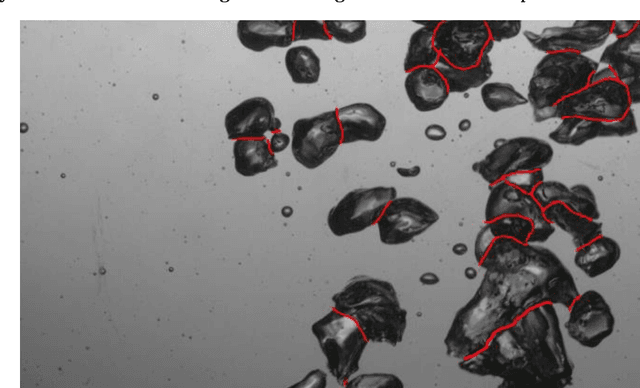
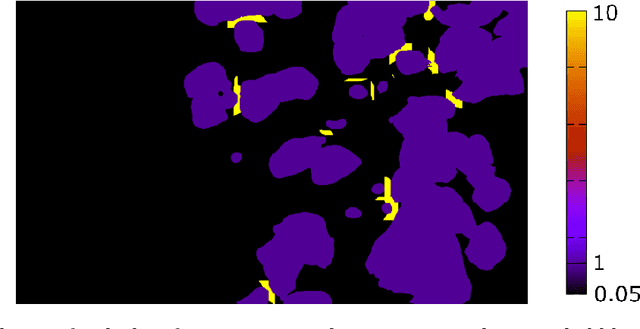
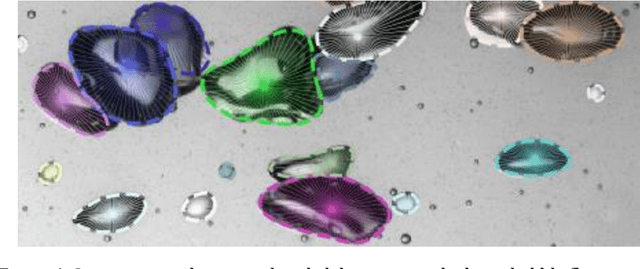
An automated and reliable processing of bubbly flow images is highly needed to analyse large data sets of comprehensive experimental series. A particular difficulty arises due to overlapping bubble projections in recorded images, which highly complicates the identification of individual bubbles. Recent approaches focus on the use of deep learning algorithms for this task and have already proven the high potential of such techniques. The main difficulties are the capability to handle different image conditions, higher gas volume fractions and a proper reconstruction of the hidden segment of a partly occluded bubble. In the present work, we try to tackle these points by testing three different methods based on Convolutional Neural Networks (CNNs) for the two former and two individual approaches that can be used subsequently to address the latter. To validate our methodology, we created test data sets with synthetic images that further demonstrate the capabilities as well as limitations of our combined approach. The generated data, code and trained models are made accessible to facilitate the use as well as further developments in the research field of bubble recognition in experimental images.
AI-Based Detection, Classification and Prediction/Prognosis in Medical Imaging: Towards Radiophenomics
Nov 01, 2021
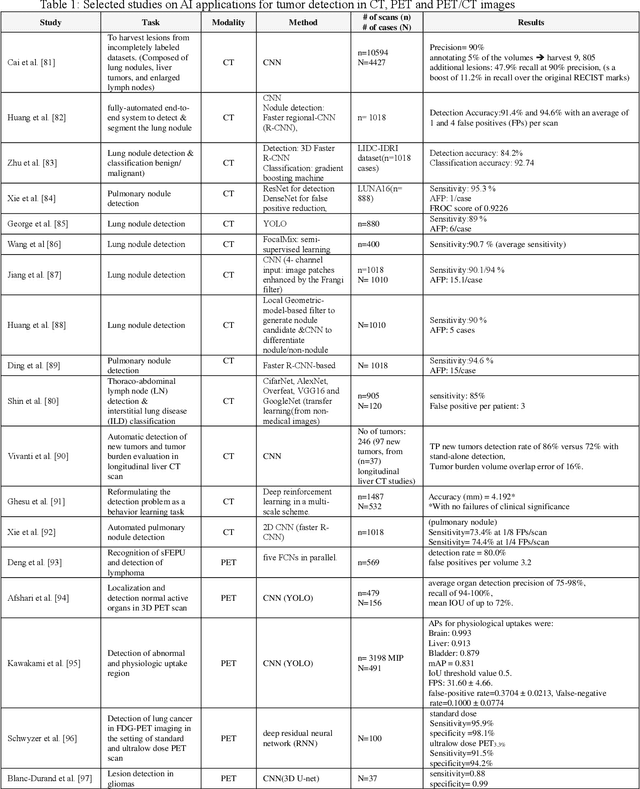

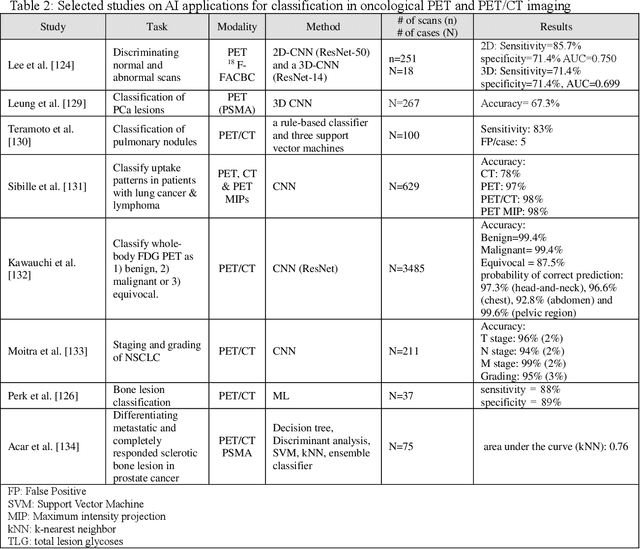
Artificial intelligence (AI) techniques have significant potential to enable effective, robust and automated image phenotyping including identification of subtle patterns. AI-based detection searches the image space to find the regions of interest based on patterns and features. There is a spectrum of tumor histologies from benign to malignant that can be identified by AI-based classification approaches using image features. The extraction of minable information from images gives way to the field of radiomics and can be explored via explicit (handcrafted/engineered) and deep radiomics frameworks. Radiomics analysis has the potential to be utilized as a noninvasive technique for the accurate characterization of tumors to improve diagnosis and treatment monitoring. This work reviews AI-based techniques, with a special focus on oncological PET and PET/CT imaging, for different detection, classification, and prediction/prognosis tasks. We also discuss needed efforts to enable the translation of AI techniques to routine clinical workflows, and potential improvements and complementary techniques such as the use of natural language processing on electronic health records and neuro-symbolic AI techniques.
Introduction to Medical Image Registration with DeepReg, Between Old and New
Sep 07, 2020
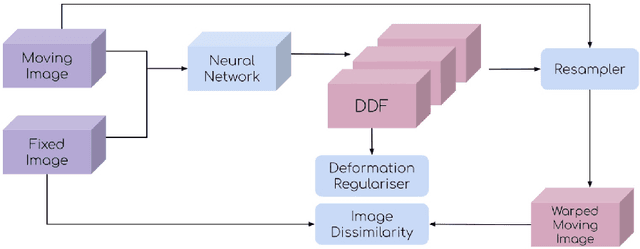
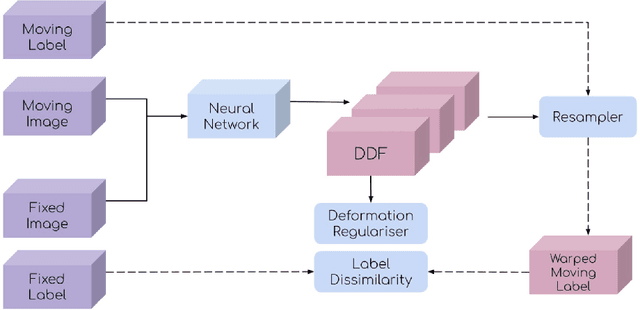
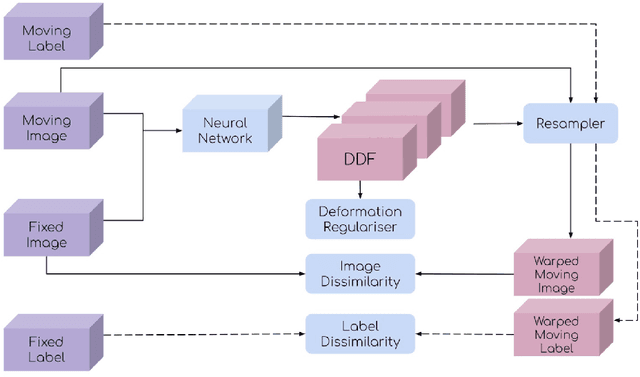
This document outlines a tutorial to get started with medical image registration using the open-source package DeepReg. The basic concepts of medical image registration are discussed, linking classical methods to newer methods using deep learning. Two iterative, classical algorithms using optimisation and one learning-based algorithm using deep learning are coded step-by-step using DeepReg utilities, all with real, open-accessible, medical data.