 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automatic Segmentation of Left Ventricle in Cardiac Magnetic Resonance Images
Jan 30, 2022
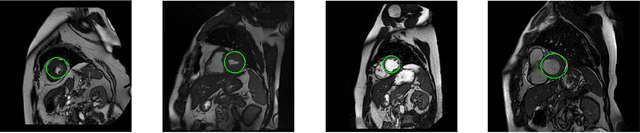
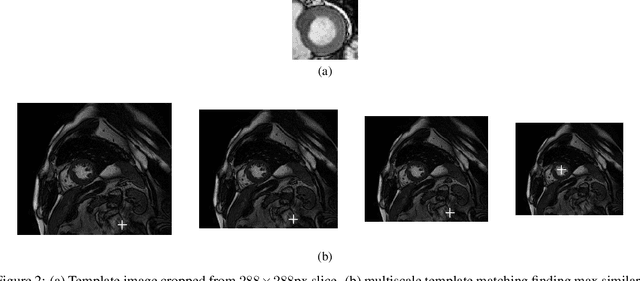

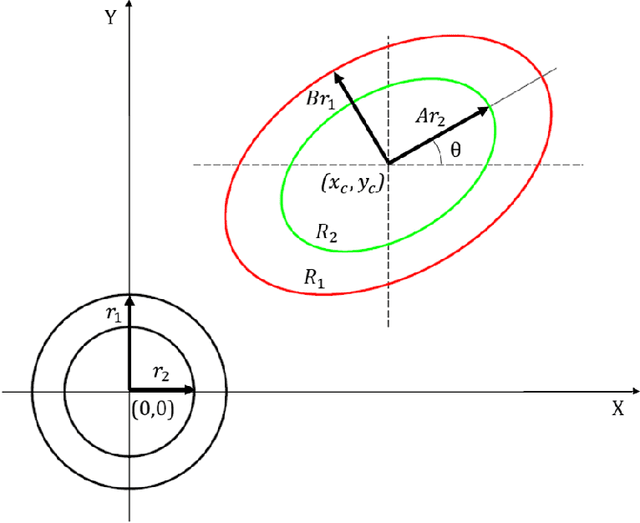
Segmentation of the left ventricle in cardiac magnetic resonance imaging MRI scans enables cardiologists to calculate the volume of the left ventricle and subsequently its ejection fraction. The ejection fraction is a measurement that expresses the percentage of blood leaving the heart with each contraction. Cardiologists often use ejection fraction to determine one's cardiac function. We propose multiscale template matching technique for detection and an elliptical active disc for automated segmentation of the left ventricle in MR images. The elliptical active disc optimizes the local energy function with respect to its five free parameters which define the disc. Gradient descent is used to minimize the energy function along with Green's theorem to optimize the computation expenses. We report validations on 320 scans containing 5,273 annotated slices which are publicly available through the Multi-Centre, Multi-Vendor, and Multi-Disease Cardiac Segmentation (M&Ms) Challenge. We achieved successful localization of the left ventricle in 89.63% of the cases and a Dice coefficient of 0.873 on diastole slices and 0.770 on systole slices. The proposed technique is based on traditional image processing techniques with a performance on par with the deep learning techniques.
SAGAN: Adversarial Spatial-asymmetric Attention for Noisy Nona-Bayer Reconstruction
Oct 19, 2021
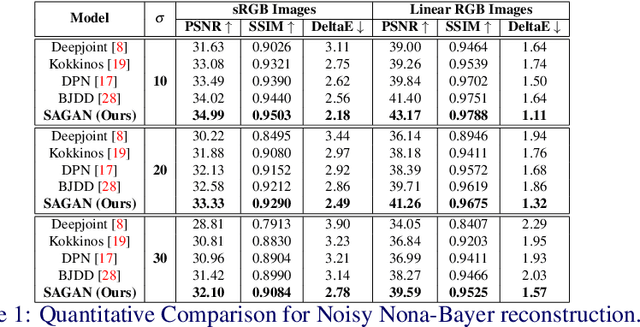

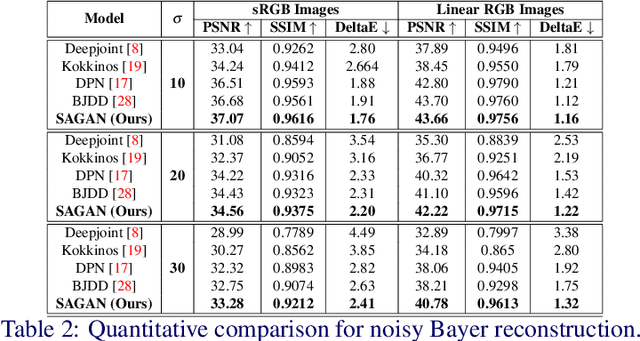
Nona-Bayer colour filter array (CFA) pattern is considered one of the most viable alternatives to traditional Bayer patterns. Despite the substantial advantages, such non-Bayer CFA patterns are susceptible to produce visual artefacts while reconstructing RGB images from noisy sensor data. This study addresses the challenges of learning RGB image reconstruction from noisy Nona-Bayer CFA comprehensively. We propose a novel spatial-asymmetric attention module to jointly learn bi-direction transformation and large-kernel global attention to reduce the visual artefacts. We combine our proposed module with adversarial learning to produce plausible images from Nona-Bayer CFA. The feasibility of the proposed method has been verified and compared with the state-of-the-art image reconstruction method. The experiments reveal that the proposed method can reconstruct RGB images from noisy Nona-Bayer CFA without producing any visually disturbing artefacts. Also, it can outperform the state-of-the-art image reconstruction method in both qualitative and quantitative comparison. Code available: https://github.com/sharif-apu/SAGAN_BMVC21.
Learning to Bootstrap for Combating Label Noise
Feb 09, 2022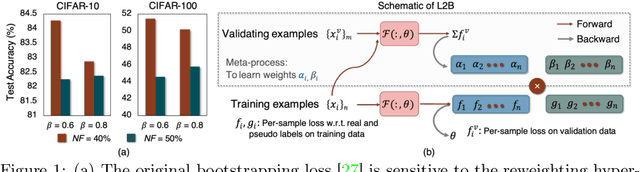
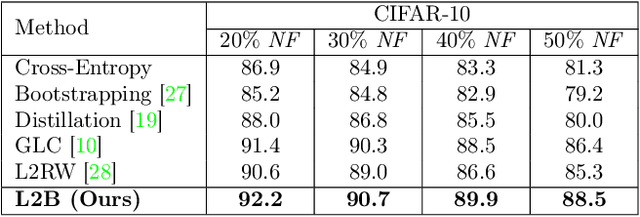
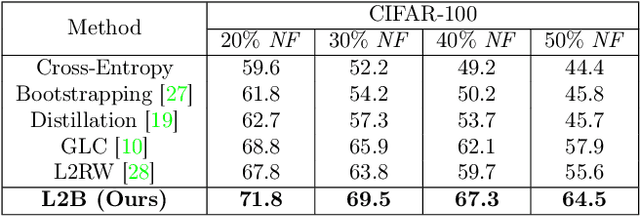
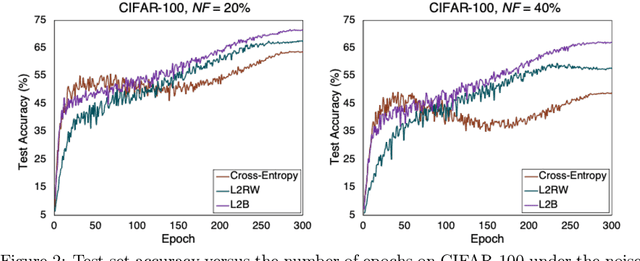
Deep neural networks are powerful tools for representation learning, but can easily overfit to noisy labels which are prevalent in many real-world scenarios. Generally, noisy supervision could stem from variation among labelers, label corruption by adversaries, etc. To combat such label noises, one popular line of approach is to apply customized weights to the training instances, so that the corrupted examples contribute less to the model learning. However, such learning mechanisms potentially erase important information about the data distribution and therefore yield suboptimal results. To leverage useful information from the corrupted instances, an alternative is the bootstrapping loss, which reconstructs new training targets on-the-fly by incorporating the network's own predictions (i.e., pseudo-labels). In this paper, we propose a more generic learnable loss objective which enables a joint reweighting of instances and labels at once. Specifically, our method dynamically adjusts the per-sample importance weight between the real observed labels and pseudo-labels, where the weights are efficiently determined in a meta process. Compared to the previous instance reweighting methods, our approach concurrently conducts implicit relabeling, and thereby yield substantial improvements with almost no extra cost. Extensive experimental results demonstrated the strengths of our approach over existing methods on multiple natural and medical image benchmark datasets, including CIFAR-10, CIFAR-100, ISIC2019 and Clothing 1M. The code is publicly available at https://github.com/yuyinzhou/L2B.
Sketching Image Gist: Human-Mimetic Hierarchical Scene Graph Generation
Jul 17, 2020
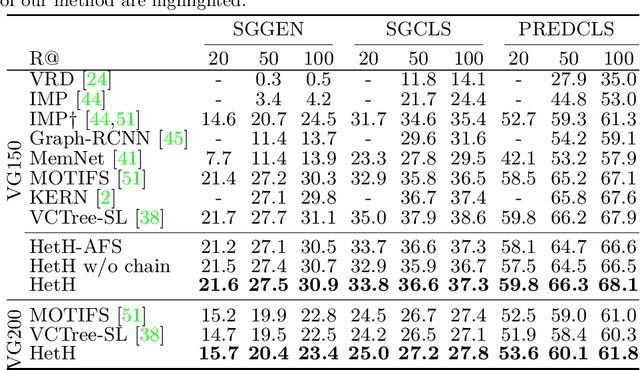
Scene graph aims to faithfully reveal humans' perception of image content. When humans analyze a scene, they usually prefer to describe image gist first, namely major objects and key relations in a scene graph. This humans' inherent perceptive habit implies that there exists a hierarchical structure about humans' preference during the scene parsing procedure. Therefore, we argue that a desirable scene graph should be also hierarchically constructed, and introduce a new scheme for modeling scene graph. Concretely, a scene is represented by a human-mimetic Hierarchical Entity Tree (HET) consisting of a series of image regions. To generate a scene graph based on HET, we parse HET with a Hybrid Long Short-Term Memory (Hybrid-LSTM) which specifically encodes hierarchy and siblings context to capture the structured information embedded in HET. To further prioritize key relations in the scene graph, we devise a Relation Ranking Module (RRM) to dynamically adjust their rankings by learning to capture humans' subjective perceptive habits from objective entity saliency and size. Experiments indicate that our method not only achieves state-of-the-art performances for scene graph generation, but also is expert in mining image-specific relations which play a great role in serving downstream tasks.
LC-GAN: Image-to-image Translation Based on Generative Adversarial Network for Endoscopic Images
Mar 10, 2020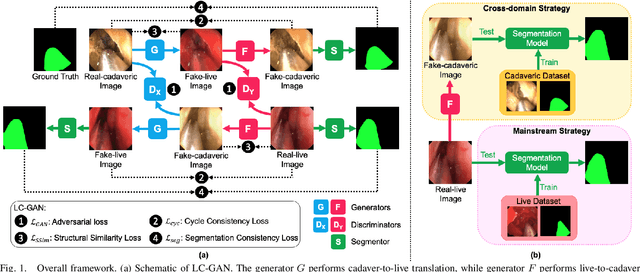
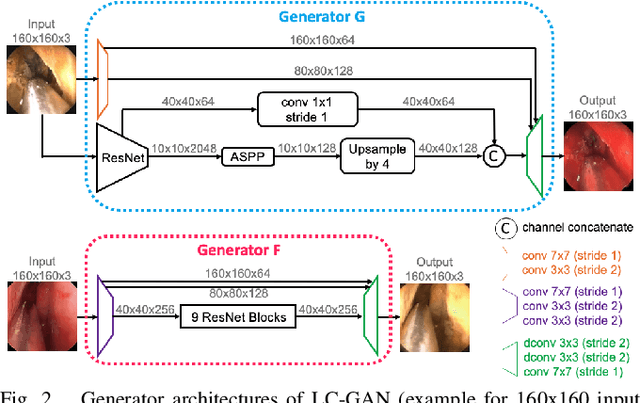

The intelligent perception of endoscopic vision is appealing in many computer-assisted and robotic surgeries. Achieving good vision-based analysis with deep learning techniques requires large labeled datasets, but manual data labeling is expensive and time-consuming in medical problems. When applying a trained model to a different but relevant dataset, a new labeled dataset may be required for training to avoid performance degradation. In this work, we investigate a novel cross-domain strategy to reduce the need for manual data labeling by proposing an image-to-image translation model called live-cadaver GAN (LC-GAN) based on generative adversarial networks (GANs). More specifically, we consider a situation when a labeled cadaveric surgery dataset is available while the task is instrument segmentation on a live surgery dataset. We train LC-GAN to learn the mappings between the cadaveric and live datasets. To achieve instrument segmentation on live images, we can first translate the live images to fake-cadaveric images with LC-GAN, and then perform segmentation on the fake-cadaveric images with models trained on the real cadaveric dataset. With this cross-domain strategy, we fully leverage the labeled cadaveric dataset for segmentation on live images without the need to label the live dataset again. Two generators with different architectures are designed for LC-GAN to make use of the deep feature representation learned from the cadaveric image based instrument segmentation task. Moreover, we propose structural similarity loss and segmentation consistency loss to improve the semantic consistency during translation. The results demonstrate that LC-GAN achieves better image-to-image translation results, and leads to improved segmentation performance in the proposed cross-domain segmentation task.
Heed the Noise in Performance Evaluations in Neural Architecture Search
Feb 04, 2022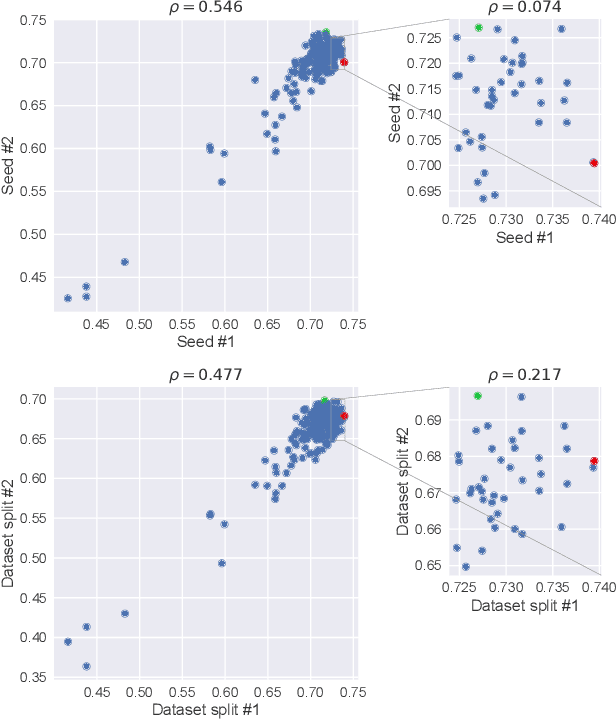
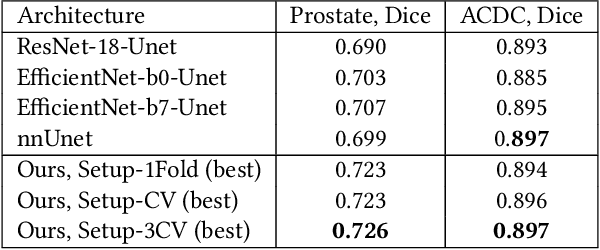
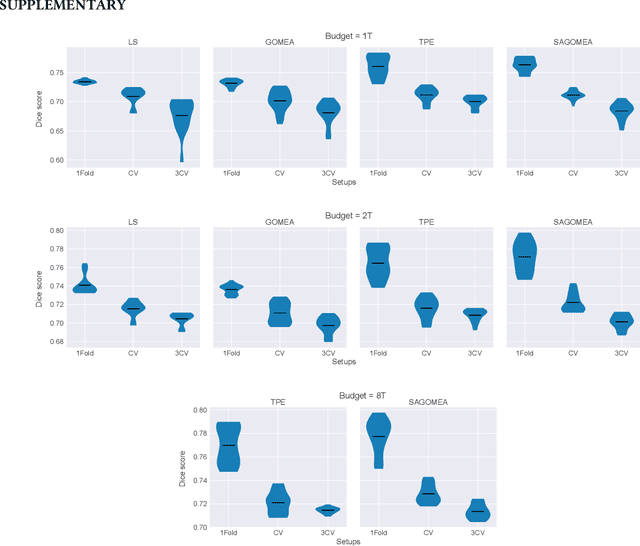
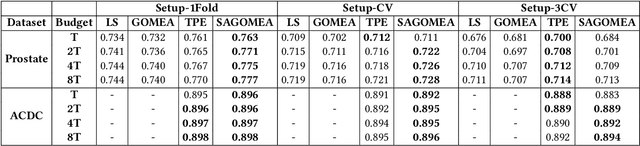
Neural Architecture Search (NAS) has recently become a topic of great interest. However, there is a potentially impactful issue within NAS that remains largely unrecognized: noise. Due to stochastic factors in neural network initialization, training, and the chosen train/validation dataset split, the performance evaluation of a neural network architecture, which is often based on a single learning run, is also stochastic. This may have a particularly large impact if a dataset is small. We therefore propose to reduce the noise by having architecture evaluations comprise averaging of scores over multiple network training runs using different random seeds and cross-validation. We perform experiments for a combinatorial optimization formulation of NAS in which we vary noise reduction levels. We use the same computational budget for each noise level in terms of network training runs, i.e., we allow less architecture evaluations when averaging over more training runs. Multiple search algorithms are considered, including evolutionary algorithms which generally perform well for NAS. We use two publicly available datasets from the medical image segmentation domain where datasets are often limited and variability among samples is often high. Our results show that reducing noise in architecture evaluations enables finding better architectures by all considered search algorithms.
STEEX: Steering Counterfactual Explanations with Semantics
Nov 17, 2021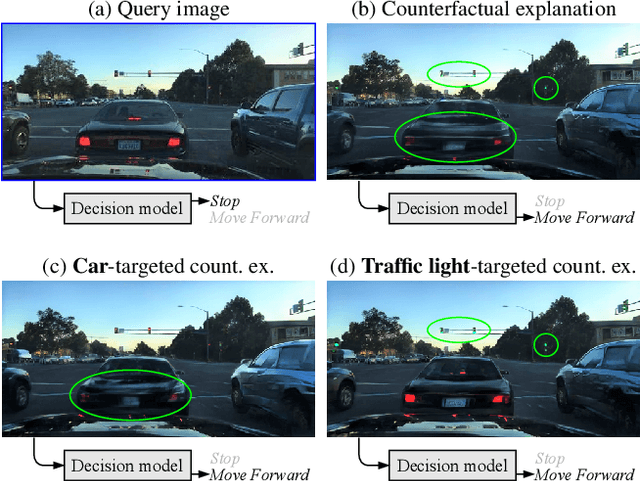
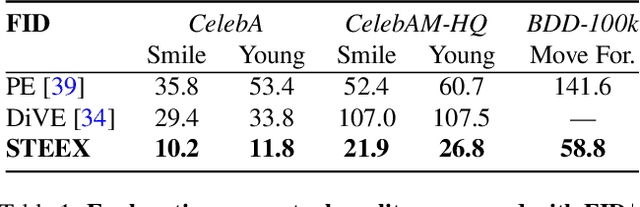
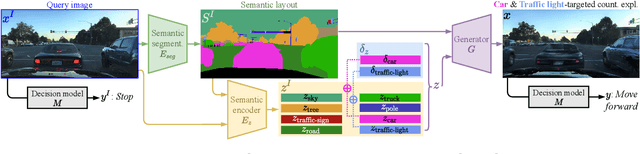
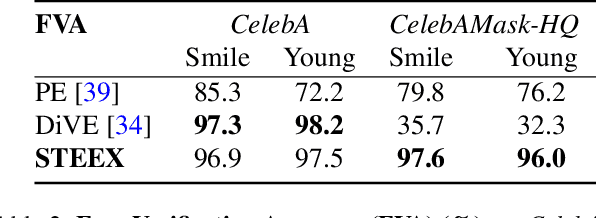
As deep learning models are increasingly used in safety-critical applications, explainability and trustworthiness become major concerns. For simple images, such as low-resolution face portraits, synthesizing visual counterfactual explanations has recently been proposed as a way to uncover the decision mechanisms of a trained classification model. In this work, we address the problem of producing counterfactual explanations for high-quality images and complex scenes. Leveraging recent semantic-to-image models, we propose a new generative counterfactual explanation framework that produces plausible and sparse modifications which preserve the overall scene structure. Furthermore, we introduce the concept of "region-targeted counterfactual explanations", and a corresponding framework, where users can guide the generation of counterfactuals by specifying a set of semantic regions of the query image the explanation must be about. Extensive experiments are conducted on challenging datasets including high-quality portraits (CelebAMask-HQ) and driving scenes (BDD100k).
Every Corporation Owns Its Image: Corporate Credit Ratings via Convolutional Neural Networks
Dec 03, 2020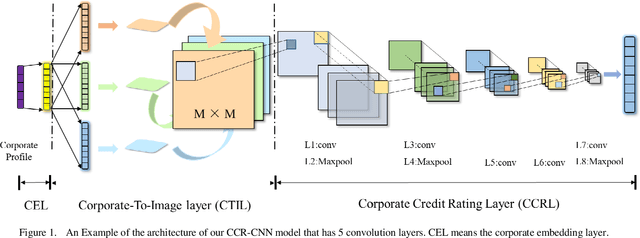
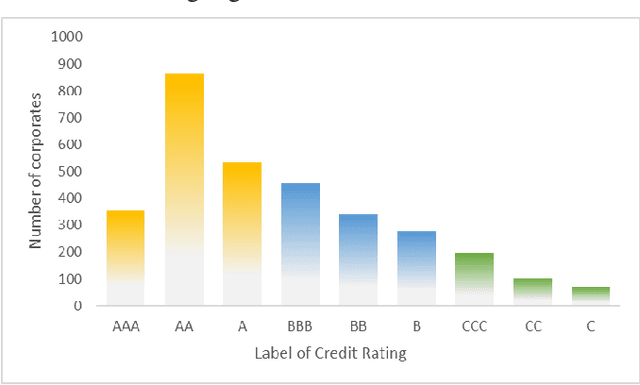
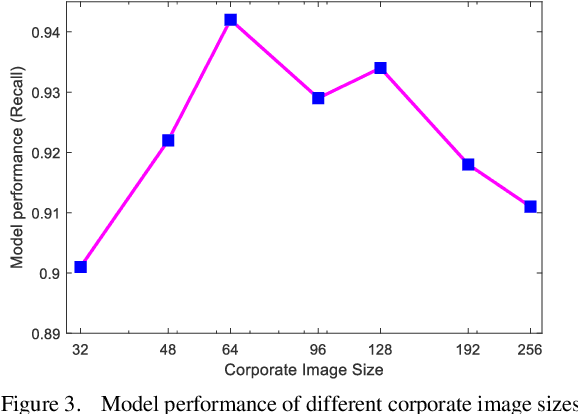
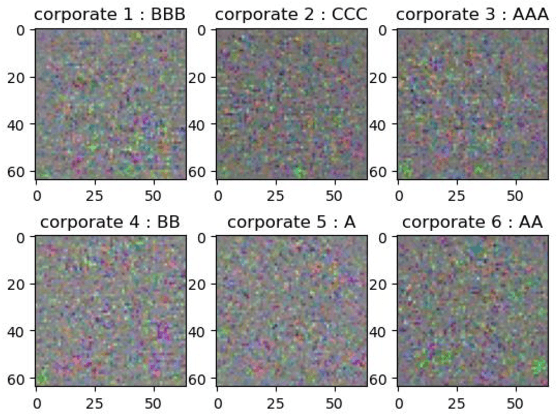
Credit rating is an analysis of the credit risks associated with a corporation, which reflect the level of the riskiness and reliability in investing. There have emerged many studies that implement machine learning techniques to deal with corporate credit rating. However, the ability of these models is limited by enormous amounts of data from financial statement reports. In this work, we analyze the performance of traditional machine learning models in predicting corporate credit rating. For utilizing the powerful convolutional neural networks and enormous financial data, we propose a novel end-to-end method, Corporate Credit Ratings via Convolutional Neural Networks, CCR-CNN for brevity. In the proposed model, each corporation is transformed into an image. Based on this image, CNN can capture complex feature interactions of data, which are difficult to be revealed by previous machine learning models. Extensive experiments conducted on the Chinese public-listed corporate rating dataset which we build, prove that CCR-CNN outperforms the state-of-the-art methods consistently.
Unimodal Face Classification with Multimodal Training
Dec 08, 2021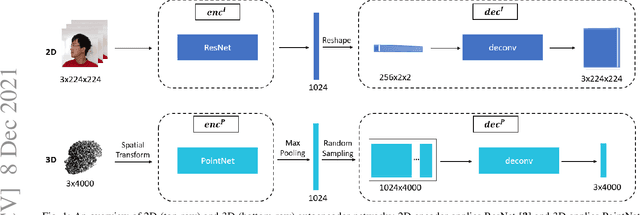
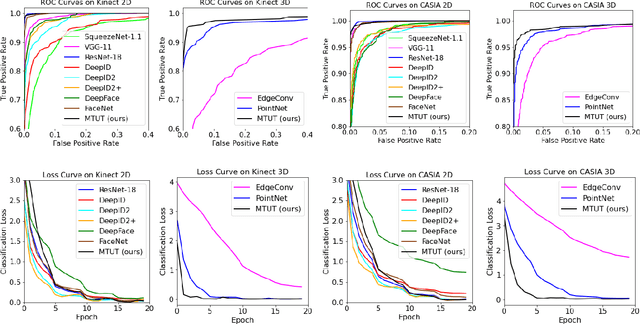
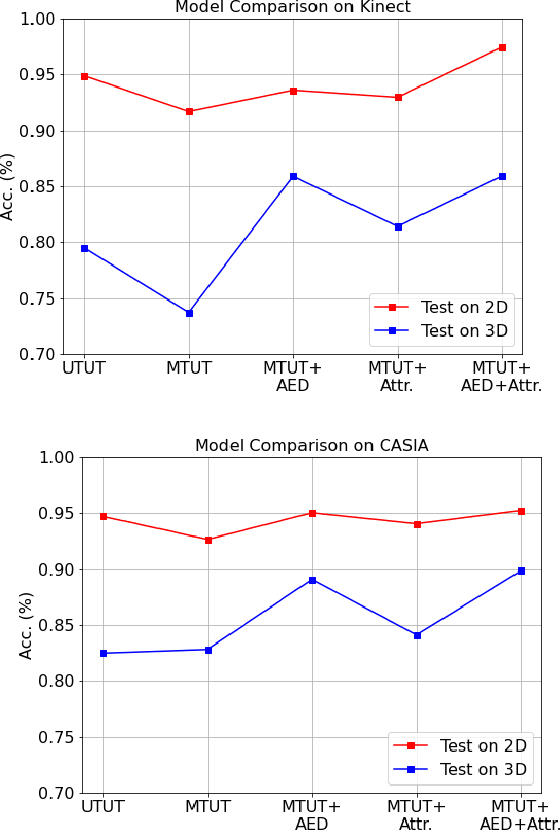
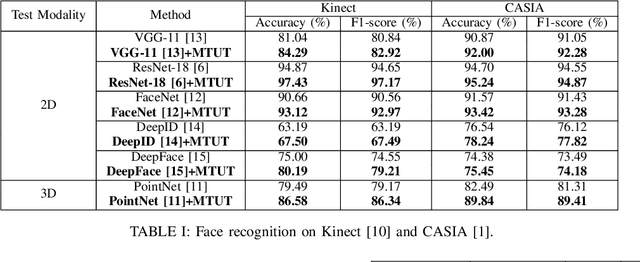
Face recognition is a crucial task in various multimedia applications such as security check, credential access and motion sensing games. However, the task is challenging when an input face is noisy (e.g. poor-condition RGB image) or lacks certain information (e.g. 3D face without color). In this work, we propose a Multimodal Training Unimodal Test (MTUT) framework for robust face classification, which exploits the cross-modality relationship during training and applies it as a complementary of the imperfect single modality input during testing. Technically, during training, the framework (1) builds both intra-modality and cross-modality autoencoders with the aid of facial attributes to learn latent embeddings as multimodal descriptors, (2) proposes a novel multimodal embedding divergence loss to align the heterogeneous features from different modalities, which also adaptively avoids the useless modality (if any) from confusing the model. This way, the learned autoencoders can generate robust embeddings in single-modality face classification on test stage. We evaluate our framework in two face classification datasets and two kinds of testing input: (1) poor-condition image and (2) point cloud or 3D face mesh, when both 2D and 3D modalities are available for training. We experimentally show that our MTUT framework consistently outperforms ten baselines on 2D and 3D settings of both datasets.
SDT-DCSCN for Simultaneous Super-Resolution and Deblurring of Text Images
Jan 15, 2022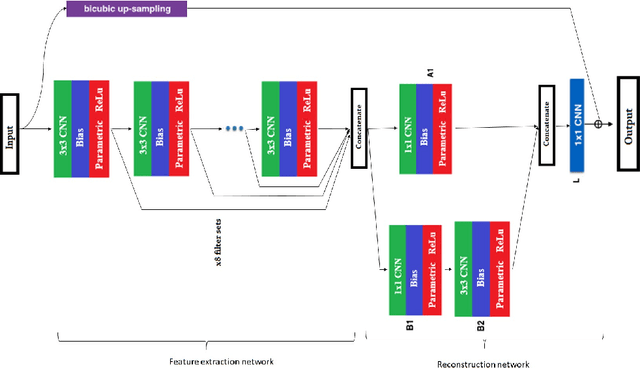
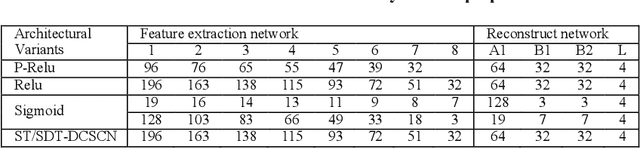
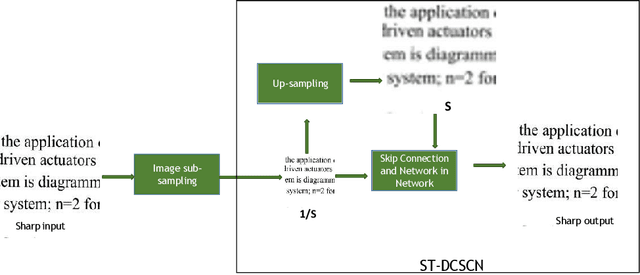
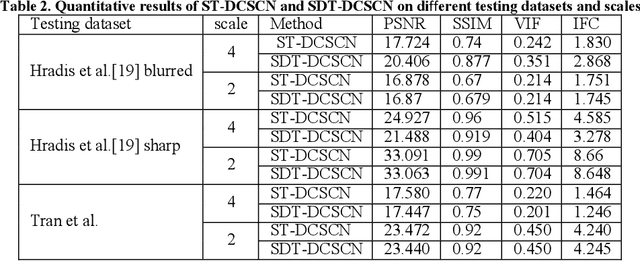
Deep convolutional neural networks (Deep CNN) have achieved hopeful performance for single image super-resolution. In particular, the Deep CNN skip Connection and Network in Network (DCSCN) architecture has been successfully applied to natural images super-resolution. In this work we propose an approach called SDT-DCSCN that jointly performs super-resolution and deblurring of low-resolution blurry text images based on DCSCN. Our approach uses subsampled blurry images in the input and original sharp images as ground truth. The used architecture is consists of a higher number of filters in the input CNN layer to a better analysis of the text details. The quantitative and qualitative evaluation on different datasets prove the high performance of our model to reconstruct high-resolution and sharp text images. In addition, in terms of computational time, our proposed method gives competitive performance compared to state of the art methods.