 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts
Feb 14, 2022


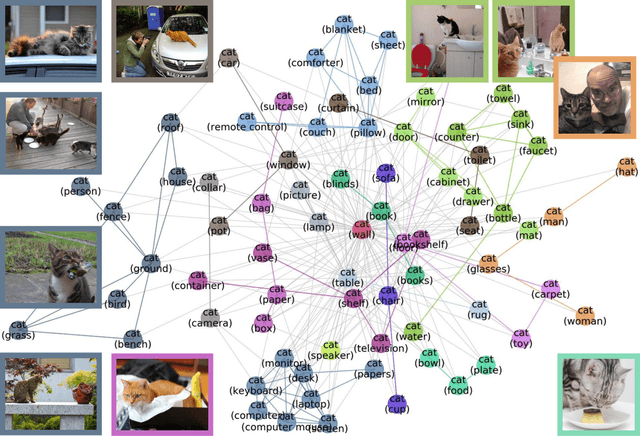
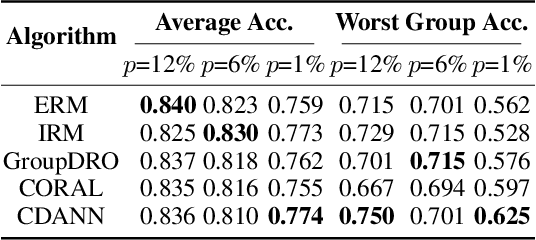
Understanding the performance of machine learning models across diverse data distributions is critically important for reliable applications. Motivated by this, there is a growing focus on curating benchmark datasets that capture distribution shifts. While valuable, the existing benchmarks are limited in that many of them only contain a small number of shifts and they lack systematic annotation about what is different across different shifts. We present MetaShift--a collection of 12,868 sets of natural images across 410 classes--to address this challenge. We leverage the natural heterogeneity of Visual Genome and its annotations to construct MetaShift. The key construction idea is to cluster images using its metadata, which provides context for each image (e.g. "cats with cars" or "cats in bathroom") that represent distinct data distributions. MetaShift has two important benefits: first, it contains orders of magnitude more natural data shifts than previously available. Second, it provides explicit explanations of what is unique about each of its data sets and a distance score that measures the amount of distribution shift between any two of its data sets. We demonstrate the utility of MetaShift in benchmarking several recent proposals for training models to be robust to data shifts. We find that the simple empirical risk minimization performs the best when shifts are moderate and no method had a systematic advantage for large shifts. We also show how MetaShift can help to visualize conflicts between data subsets during model training.
Investigating underdiagnosis of AI algorithms in the presence of multiple sources of dataset bias
Jan 19, 2022Deep learning models have shown great potential for image-based diagnosis assisting clinical decision making. At the same time, an increasing number of reports raise concerns about the potential risk that machine learning could amplify existing health disparities due to human biases that are embedded in the training data. It is of great importance to carefully investigate the extent to which biases may be reproduced or even amplified if we wish to build fair artificial intelligence systems. Seyyed-Kalantari et al. advance this conversation by analysing the performance of a disease classifier across population subgroups. They raise performance disparities related to underdiagnosis as a point of concern; we identify areas from this analysis which we believe deserve additional attention. Specifically, we wish to highlight some theoretical and practical difficulties associated with assessing model fairness through testing on data drawn from the same biased distribution as the training data, especially when the sources and amount of biases are unknown.
Panoptic Segmentation: A Review
Nov 19, 2021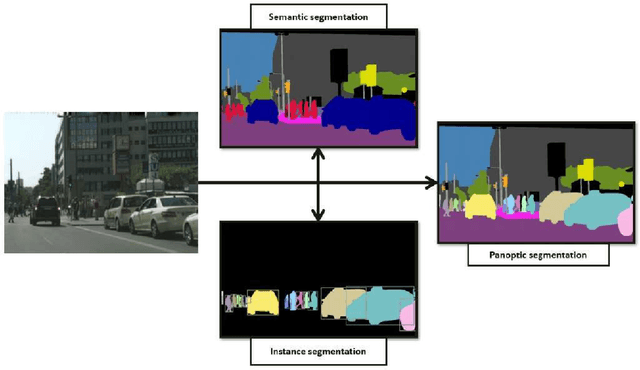
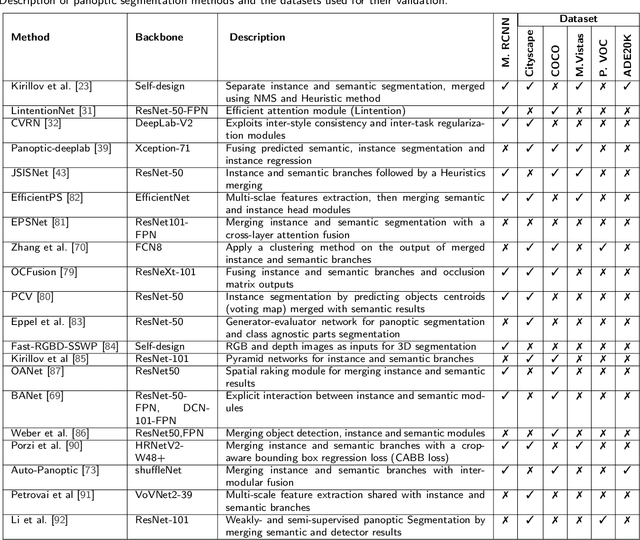
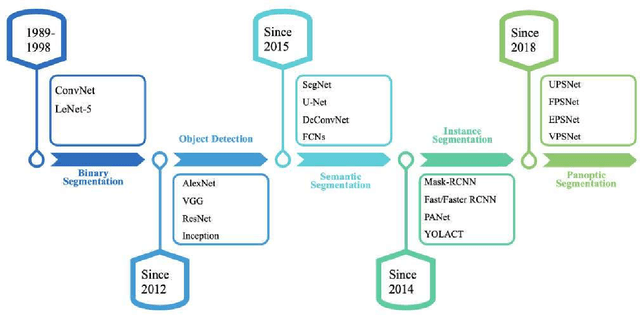
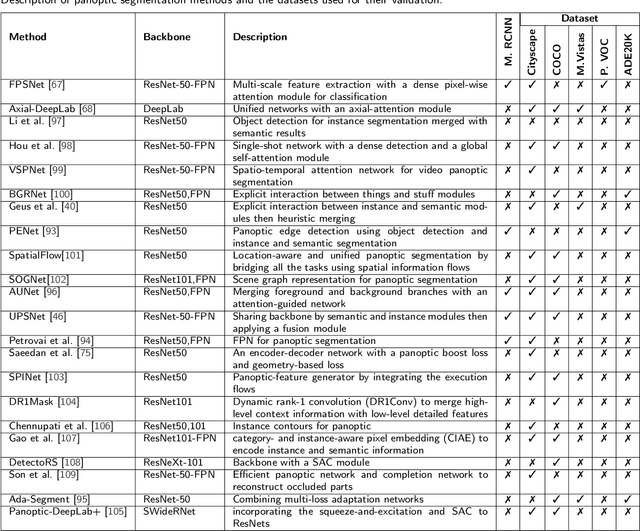
Image segmentation for video analysis plays an essential role in different research fields such as smart city, healthcare, computer vision and geoscience, and remote sensing applications. In this regard, a significant effort has been devoted recently to developing novel segmentation strategies; one of the latest outstanding achievements is panoptic segmentation. The latter has resulted from the fusion of semantic and instance segmentation. Explicitly, panoptic segmentation is currently under study to help gain a more nuanced knowledge of the image scenes for video surveillance, crowd counting, self-autonomous driving, medical image analysis, and a deeper understanding of the scenes in general. To that end, we present in this paper the first comprehensive review of existing panoptic segmentation methods to the best of the authors' knowledge. Accordingly, a well-defined taxonomy of existing panoptic techniques is performed based on the nature of the adopted algorithms, application scenarios, and primary objectives. Moreover, the use of panoptic segmentation for annotating new datasets by pseudo-labeling is discussed. Moving on, ablation studies are carried out to understand the panoptic methods from different perspectives. Moreover, evaluation metrics suitable for panoptic segmentation are discussed, and a comparison of the performance of existing solutions is provided to inform the state-of-the-art and identify their limitations and strengths. Lastly, the current challenges the subject technology faces and the future trends attracting considerable interest in the near future are elaborated, which can be a starting point for the upcoming research studies. The papers provided with code are available at: https://github.com/elharroussomar/Awesome-Panoptic-Segmentation
Predicting 4D Liver MRI for MR-guided Interventions
Feb 25, 2022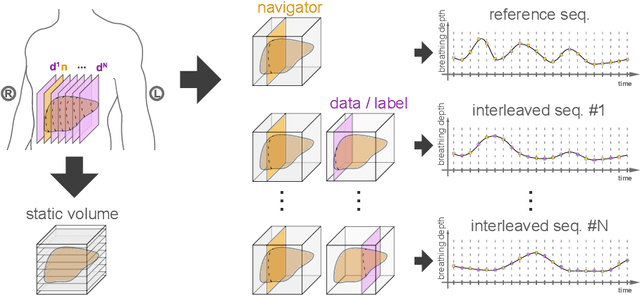


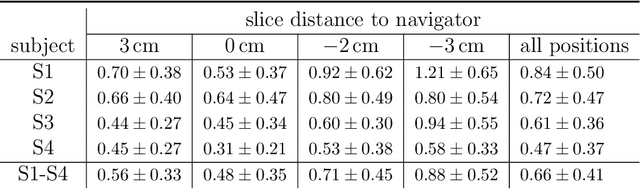
Organ motion poses an unresolved challenge in image-guided interventions. In the pursuit of solving this problem, the research field of time-resolved volumetric magnetic resonance imaging (4D MRI) has evolved. However, current techniques are unsuitable for most interventional settings because they lack sufficient temporal and/or spatial resolution or have long acquisition times. In this work, we propose a novel approach for real-time, high-resolution 4D MRI with large fields of view for MR-guided interventions. To this end, we trained a convolutional neural network (CNN) end-to-end to predict a 3D liver MRI that correctly predicts the liver's respiratory state from a live 2D navigator MRI of a subject. Our method can be used in two ways: First, it can reconstruct near real-time 4D MRI with high quality and high resolution (209x128x128 matrix size with isotropic 1.8mm voxel size and 0.6s/volume) given a dynamic interventional 2D navigator slice for guidance during an intervention. Second, it can be used for retrospective 4D reconstruction with a temporal resolution of below 0.2s/volume for motion analysis and use in radiation therapy. We report a mean target registration error (TRE) of 1.19 $\pm$0.74mm, which is below voxel size. We compare our results with a state-of-the-art retrospective 4D MRI reconstruction. Visual evaluation shows comparable quality. We show that small training sizes with short acquisition times down to 2min can already achieve promising results and 24min are sufficient for high quality results. Because our method can be readily combined with earlier methods, acquisition time can be further decreased while also limiting quality loss. We show that an end-to-end, deep learning formulation is highly promising for 4D MRI reconstruction.
Region Semantically Aligned Network for Zero-Shot Learning
Oct 14, 2021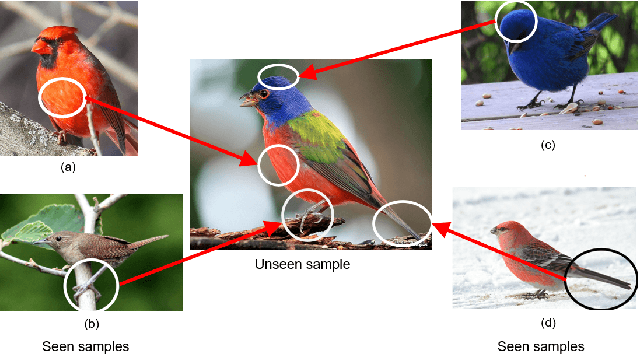

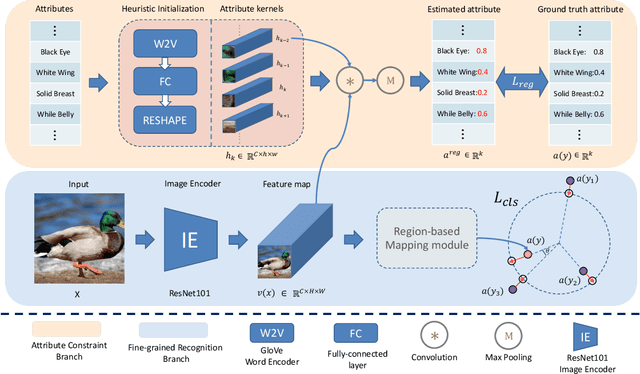
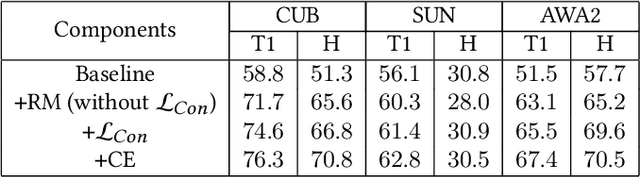
Zero-shot learning (ZSL) aims to recognize unseen classes based on the knowledge of seen classes. Previous methods focused on learning direct embeddings from global features to the semantic space in hope of knowledge transfer from seen classes to unseen classes. However, an unseen class shares local visual features with a set of seen classes and leveraging global visual features makes the knowledge transfer ineffective. To tackle this problem, we propose a Region Semantically Aligned Network (RSAN), which maps local features of unseen classes to their semantic attributes. Instead of using global features which are obtained by an average pooling layer after an image encoder, we directly utilize the output of the image encoder which maintains local information of the image. Concretely, we obtain each attribute from a specific region of the output and exploit these attributes for recognition. As a result, the knowledge of seen classes can be successfully transferred to unseen classes in a region-bases manner. In addition, we regularize the image encoder through attribute regression with a semantic knowledge to extract robust and attribute-related visual features. Experiments on several standard ZSL datasets reveal the benefit of the proposed RSAN method, outperforming state-of-the-art methods.
iCap: Interative Image Captioning with Predictive Text
Feb 04, 2020

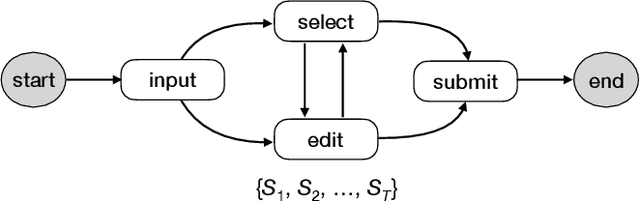

In this paper we study a brand new topic of interactive image captioning with human in the loop. Different from automated image captioning where a given test image is the sole input in the inference stage, we have access to both the test image and a sequence of (incomplete) user-input sentences in the interactive scenario. We formulate the problem as Visually Conditioned Sentence Completion (VCSC). For VCSC, we propose asynchronous bidirectional decoding for image caption completion (ABD-Cap). With ABD-Cap as the core module, we build iCap, a web-based interactive image captioning system capable of predicting new text with respect to live input from a user. A number of experiments covering both automated evaluations and real user studies show the viability of our proposals.
EMT-NET: Efficient multitask network for computer-aided diagnosis of breast cancer
Jan 13, 2022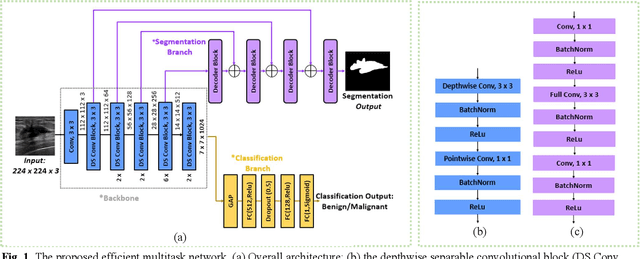
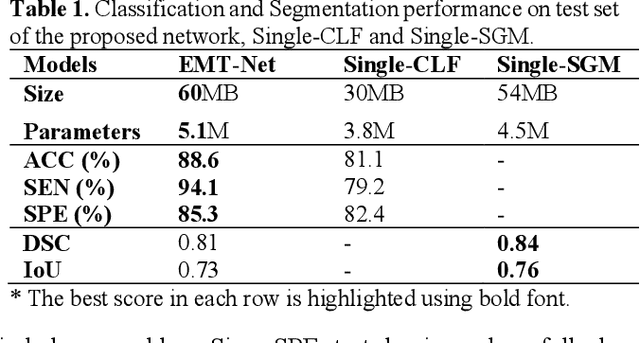
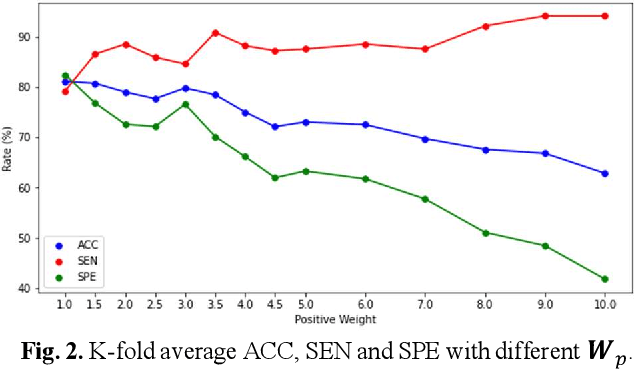
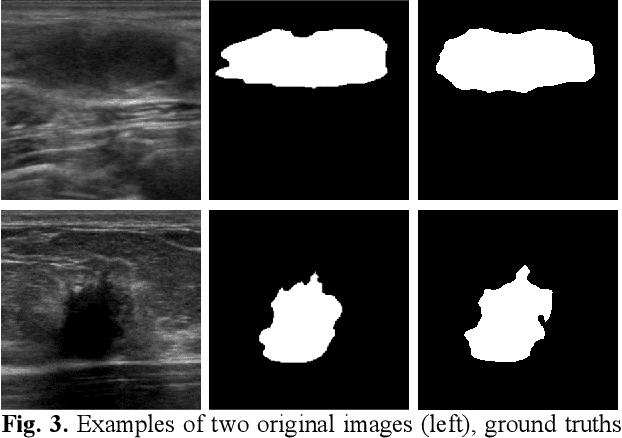
Deep learning-based computer-aided diagnosis has achieved unprecedented performance in breast cancer detection. However, most approaches are computationally intensive, which impedes their broader dissemination in real-world applications. In this work, we propose an efficient and light-weighted multitask learning architecture to classify and segment breast tumors simultaneously. We incorporate a segmentation task into a tumor classification network, which makes the backbone network learn representations focused on tumor regions. Moreover, we propose a new numerically stable loss function that easily controls the balance between the sensitivity and specificity of cancer detection. The proposed approach is evaluated using a breast ultrasound dataset with 1,511 images. The accuracy, sensitivity, and specificity of tumor classification is 88.6%, 94.1%, and 85.3%, respectively. We validate the model using a virtual mobile device, and the average inference time is 0.35 seconds per image.
Deep Image Clustering with Category-Style Representation
Jul 20, 2020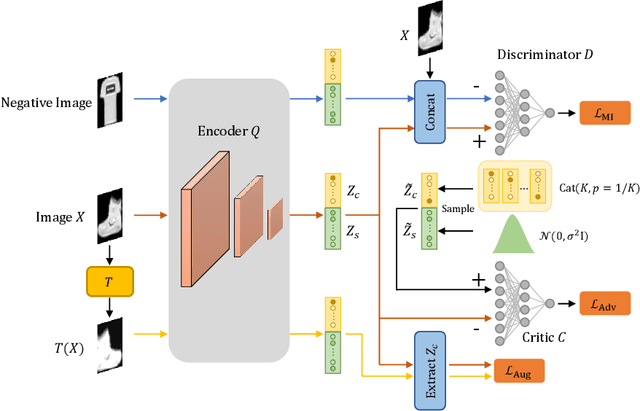

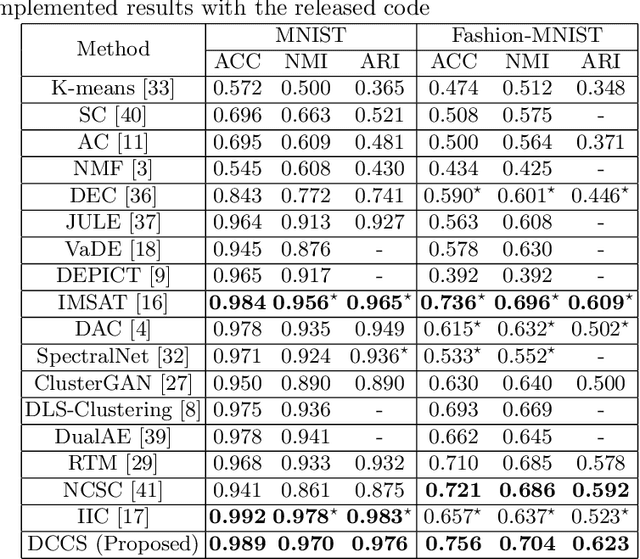
Deep clustering which adopts deep neural networks to obtain optimal representations for clustering has been widely studied recently. In this paper, we propose a novel deep image clustering framework to learn a category-style latent representation in which the category information is disentangled from image style and can be directly used as the cluster assignment. To achieve this goal, mutual information maximization is applied to embed relevant information in the latent representation. Moreover, augmentation-invariant loss is employed to disentangle the representation into category part and style part. Last but not least, a prior distribution is imposed on the latent representation to ensure the elements of the category vector can be used as the probabilities over clusters. Comprehensive experiments demonstrate that the proposed approach outperforms state-of-the-art methods significantly on five public datasets.
Multimodal Fake News Detection
Dec 09, 2021
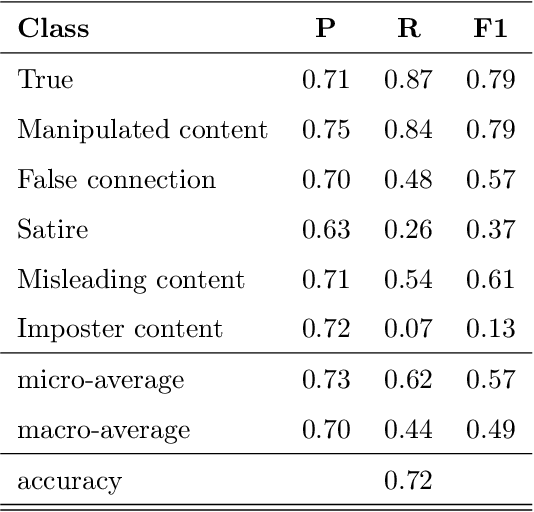
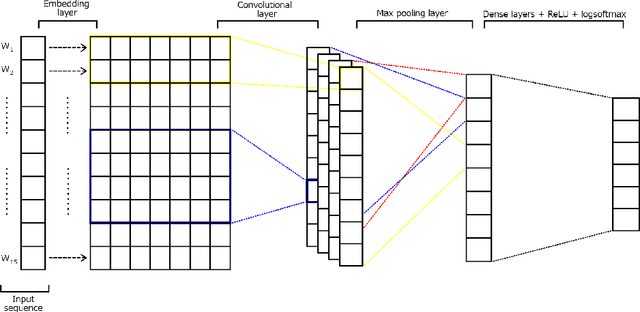
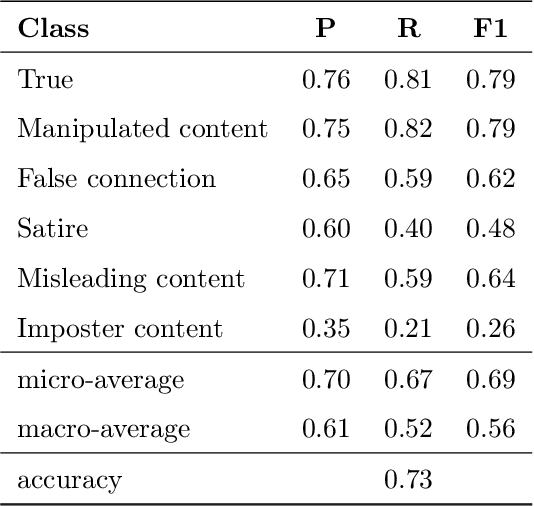
Over the last years, there has been an unprecedented proliferation of fake news. As a consequence, we are more susceptible to the pernicious impact that misinformation and disinformation spreading can have in different segments of our society. Thus, the development of tools for automatic detection of fake news plays and important role in the prevention of its negative effects. Most attempts to detect and classify false content focus only on using textual information. Multimodal approaches are less frequent and they typically classify news either as true or fake. In this work, we perform a fine-grained classification of fake news on the Fakeddit dataset, using both unimodal and multimodal approaches. Our experiments show that the multimodal approach based on a Convolutional Neural Network (CNN) architecture combining text and image data achieves the best results, with an accuracy of 87%. Some fake news categories such as Manipulated content, Satire or False connection strongly benefit from the use of images. Using images also improves the results of the other categories, but with less impact. Regarding the unimodal approaches using only text, Bidirectional Encoder Representations from Transformers (BERT) is the best model with an accuracy of 78%. Therefore, exploiting both text and image data significantly improves the performance of fake news detection.
Multi-Grid Redundant Bounding Box Annotation for Accurate Object Detection
Jan 05, 2022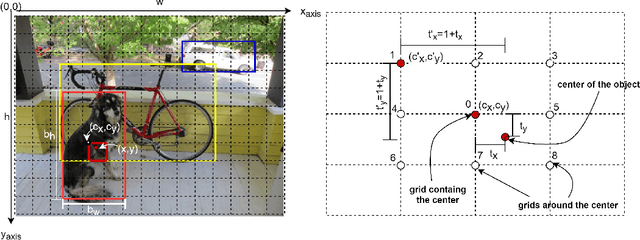
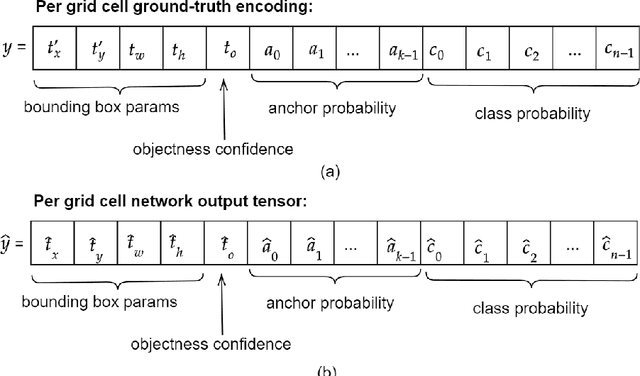
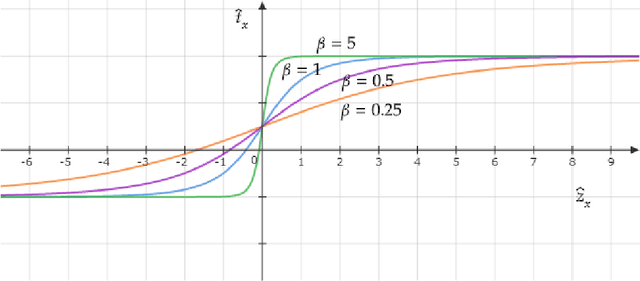

Modern leading object detectors are either two-stage or one-stage networks repurposed from a deep CNN-based backbone classifier network. YOLOv3 is one such very-well known state-of-the-art one-shot detector that takes in an input image and divides it into an equal-sized grid matrix. The grid cell having the center of an object is the one responsible for detecting the particular object. This paper presents a new mathematical approach that assigns multiple grids per object for accurately tight-fit bounding box prediction. We also propose an effective offline copy-paste data augmentation for object detection. Our proposed method significantly outperforms some current state-of-the-art object detectors with a prospect for further better performance.