 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Wide Color Gamut Image Content Characterization: Method, Evaluation, and Applications
Jan 19, 2021
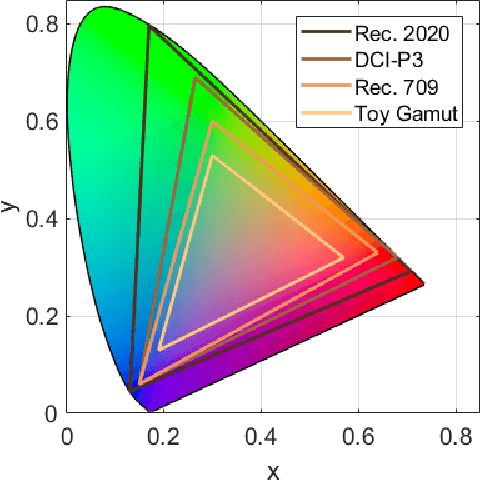
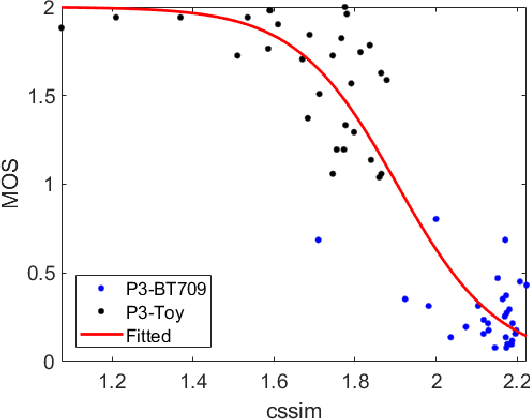
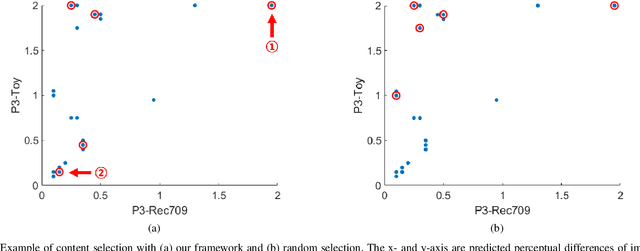

In this paper, we propose a novel framework to characterize a wide color gamut image content based on perceived quality due to the processes that change color gamut, and demonstrate two practical use cases where the framework can be applied. We first introduce the main framework and implementation details. Then, we provide analysis for understanding of existing wide color gamut datasets with quantitative characterization criteria on their characteristics, where four criteria, i.e., coverage, total coverage, uniformity, and total uniformity, are proposed. Finally, the framework is applied to content selection in a gamut mapping evaluation scenario in order to enhance reliability and robustness of the evaluation results. As a result, the framework fulfils content characterization for studies where quality of experience of wide color gamut stimuli is involved.
A Survey on Deep Learning Methods for Semantic Image Segmentation in Real-Time
Sep 27, 2020
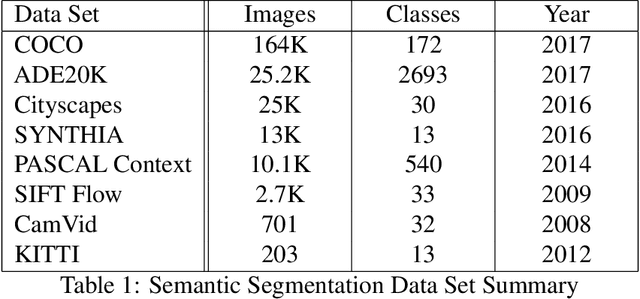
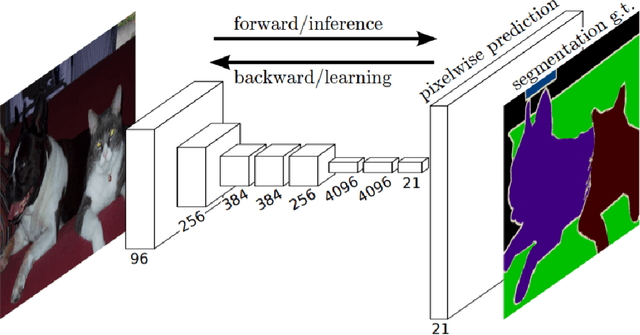
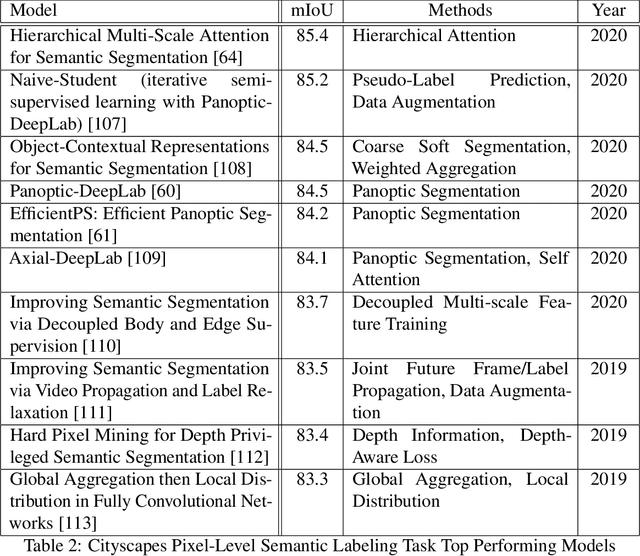
Semantic image segmentation is one of fastest growing areas in computer vision with a variety of applications. In many areas, such as robotics and autonomous vehicles, semantic image segmentation is crucial, since it provides the necessary context for actions to be taken based on a scene understanding at the pixel level. Moreover, the success of medical diagnosis and treatment relies on the extremely accurate understanding of the data under consideration and semantic image segmentation is one of the important tools in many cases. Recent developments in deep learning have provided a host of tools to tackle this problem efficiently and with increased accuracy. This work provides a comprehensive analysis of state-of-the-art deep learning architectures in image segmentation and, more importantly, an extensive list of techniques to achieve fast inference and computational efficiency. The origins of these techniques as well as their strengths and trade-offs are discussed with an in-depth analysis of their impact in the area. The best-performing architectures are summarized with a list of methods used to achieve these state-of-the-art results.
Delta-GAN-Encoder: Encoding Semantic Changes for Explicit Image Editing, using Few Synthetic Samples
Nov 17, 2021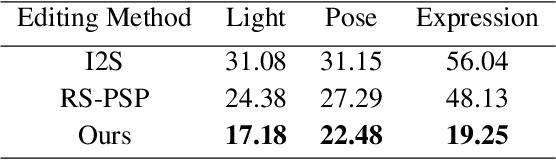

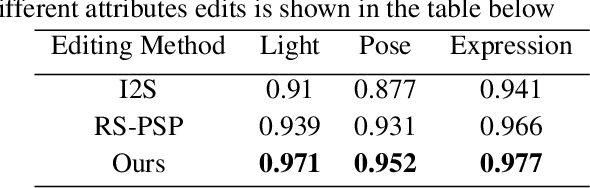
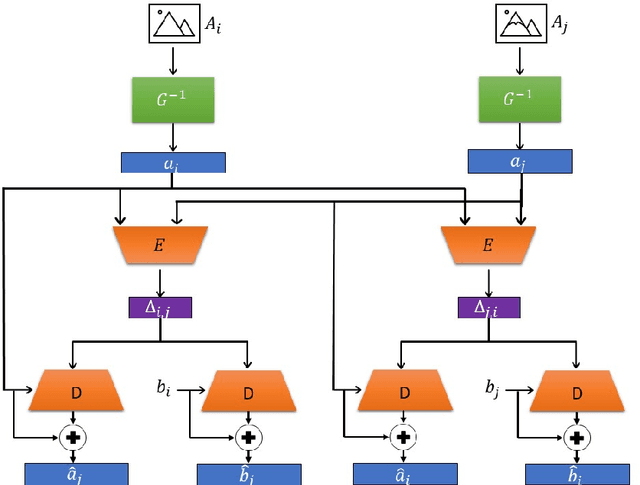
Understating and controlling generative models' latent space is a complex task. In this paper, we propose a novel method for learning to control any desired attribute in a pre-trained GAN's latent space, for the purpose of editing synthesized and real-world data samples accordingly. We perform Sim2Real learning, relying on minimal samples to achieve an unlimited amount of continuous precise edits. We present an Autoencoder-based model that learns to encode the semantics of changes between images as a basis for editing new samples later on, achieving precise desired results - example shown in Fig. 1. While previous editing methods rely on a known structure of latent spaces (e.g., linearity of some semantics in StyleGAN), our method inherently does not require any structural constraints. We demonstrate our method in the domain of facial imagery: editing different expressions, poses, and lighting attributes, achieving state-of-the-art results.
Can We Find Neurons that Cause Unrealistic Images in Deep Generative Networks?
Jan 17, 2022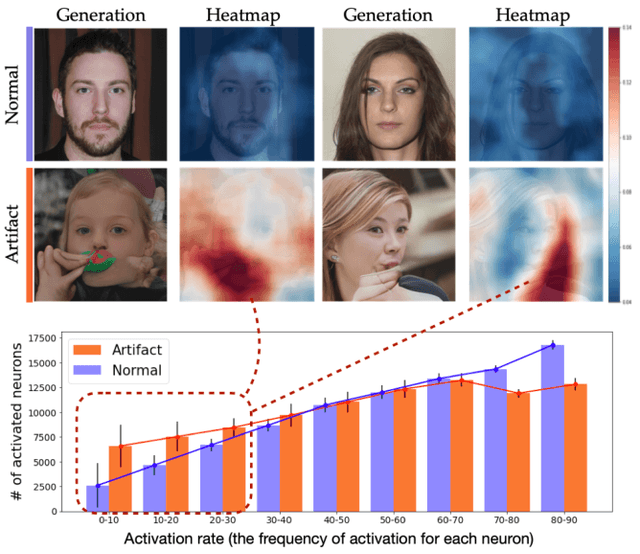
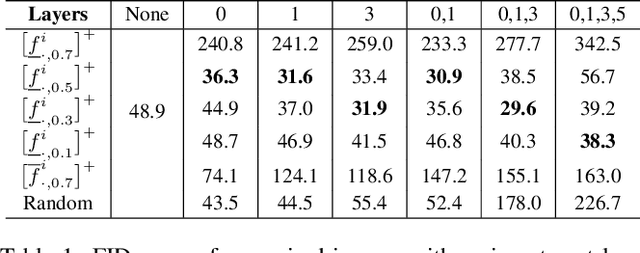
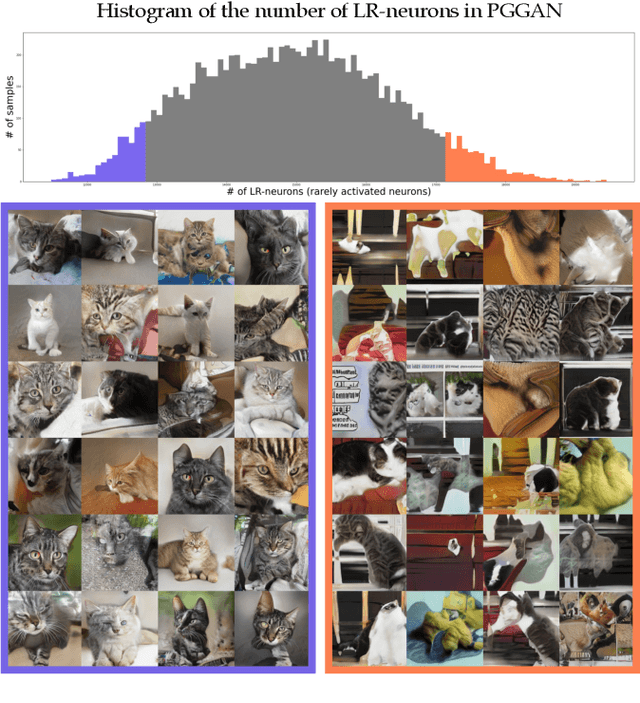
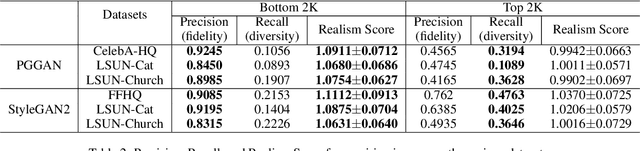
Even though image generation with Generative Adversarial Networks has been showing remarkable ability to generate high-quality images, GANs do not always guarantee photorealistic images will be generated. Sometimes they generate images that have defective or unnatural objects, which are referred to as 'artifacts'. Research to determine why the artifacts emerge and how they can be detected and removed has not been sufficiently carried out. To analyze this, we first hypothesize that rarely activated neurons and frequently activated neurons have different purposes and responsibilities for the progress of generating images. By analyzing the statistics and the roles for those neurons, we empirically show that rarely activated neurons are related to failed results of making diverse objects and lead to artifacts. In addition, we suggest a correction method, called 'sequential ablation', to repair the defective part of the generated images without complex computational cost and manual efforts.
Representing 3D Shapes with Probabilistic Directed Distance Fields
Dec 10, 2021
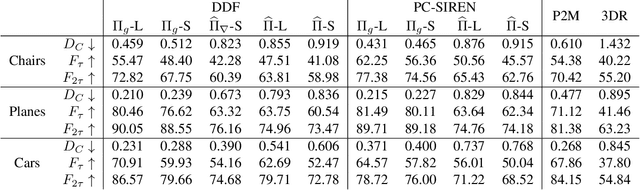
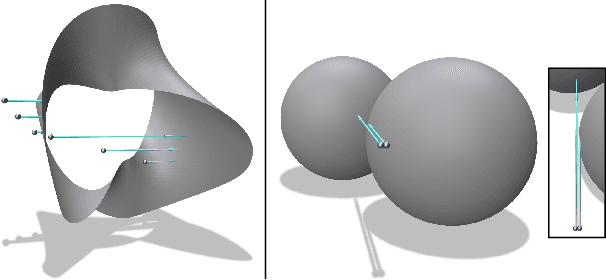
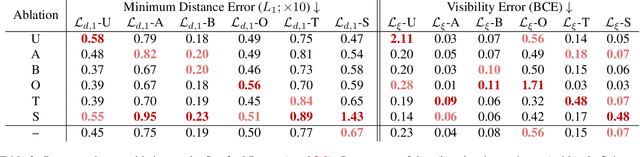
Differentiable rendering is an essential operation in modern vision, allowing inverse graphics approaches to 3D understanding to be utilized in modern machine learning frameworks. Explicit shape representations (voxels, point clouds, or meshes), while relatively easily rendered, often suffer from limited geometric fidelity or topological constraints. On the other hand, implicit representations (occupancy, distance, or radiance fields) preserve greater fidelity, but suffer from complex or inefficient rendering processes, limiting scalability. In this work, we endeavour to address both shortcomings with a novel shape representation that allows fast differentiable rendering within an implicit architecture. Building on implicit distance representations, we define Directed Distance Fields (DDFs), which map an oriented point (position and direction) to surface visibility and depth. Such a field can render a depth map with a single forward pass per pixel, enable differential surface geometry extraction (e.g., surface normals and curvatures) via network derivatives, be easily composed, and permit extraction of classical unsigned distance fields. Using probabilistic DDFs (PDDFs), we show how to model inherent discontinuities in the underlying field. Finally, we apply our method to fitting single shapes, unpaired 3D-aware generative image modelling, and single-image 3D reconstruction tasks, showcasing strong performance with simple architectural components via the versatility of our representation.
Watermarking Pre-trained Encoders in Contrastive Learning
Jan 20, 2022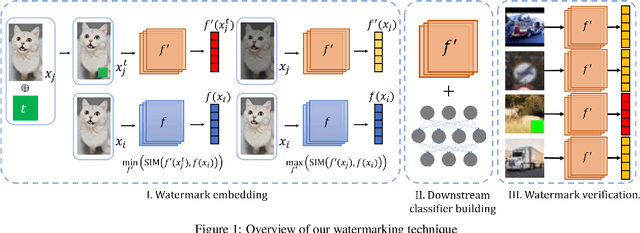
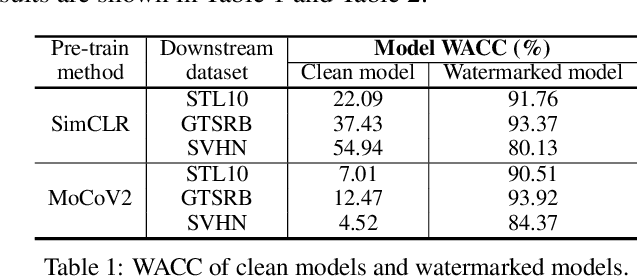

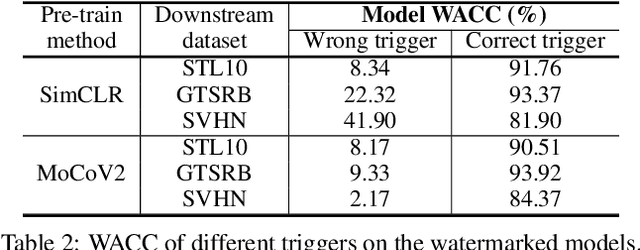
Contrastive learning has become a popular technique to pre-train image encoders, which could be used to build various downstream classification models in an efficient way. This process requires a large amount of data and computation resources. Hence, the pre-trained encoders are an important intellectual property that needs to be carefully protected. It is challenging to migrate existing watermarking techniques from the classification tasks to the contrastive learning scenario, as the owner of the encoder lacks the knowledge of the downstream tasks which will be developed from the encoder in the future. We propose the \textit{first} watermarking methodology for the pre-trained encoders. We introduce a task-agnostic loss function to effectively embed into the encoder a backdoor as the watermark. This backdoor can still exist in any downstream models transferred from the encoder. Extensive evaluations over different contrastive learning algorithms, datasets, and downstream tasks indicate our watermarks exhibit high effectiveness and robustness against different adversarial operations.
Region Semantically Aligned Network for Zero-Shot Learning
Oct 14, 2021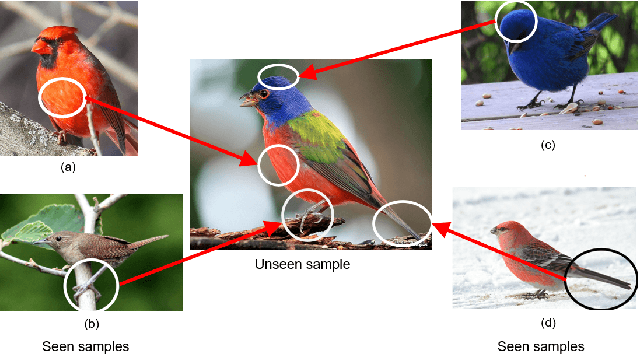

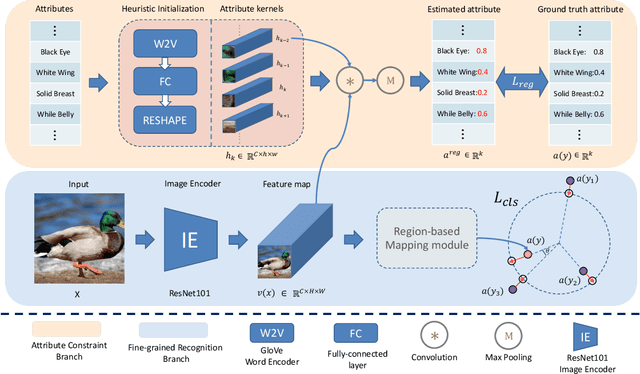
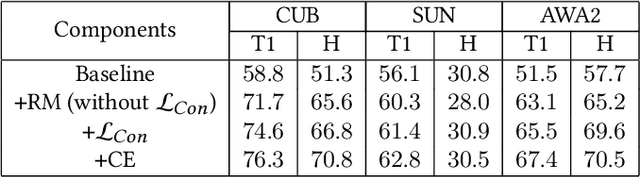
Zero-shot learning (ZSL) aims to recognize unseen classes based on the knowledge of seen classes. Previous methods focused on learning direct embeddings from global features to the semantic space in hope of knowledge transfer from seen classes to unseen classes. However, an unseen class shares local visual features with a set of seen classes and leveraging global visual features makes the knowledge transfer ineffective. To tackle this problem, we propose a Region Semantically Aligned Network (RSAN), which maps local features of unseen classes to their semantic attributes. Instead of using global features which are obtained by an average pooling layer after an image encoder, we directly utilize the output of the image encoder which maintains local information of the image. Concretely, we obtain each attribute from a specific region of the output and exploit these attributes for recognition. As a result, the knowledge of seen classes can be successfully transferred to unseen classes in a region-bases manner. In addition, we regularize the image encoder through attribute regression with a semantic knowledge to extract robust and attribute-related visual features. Experiments on several standard ZSL datasets reveal the benefit of the proposed RSAN method, outperforming state-of-the-art methods.
Reward-Based Environment States for Robot Manipulation Policy Learning
Dec 10, 2021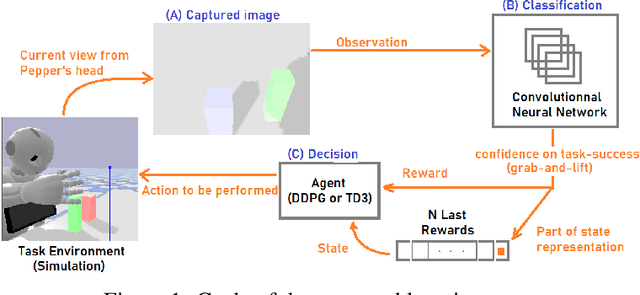
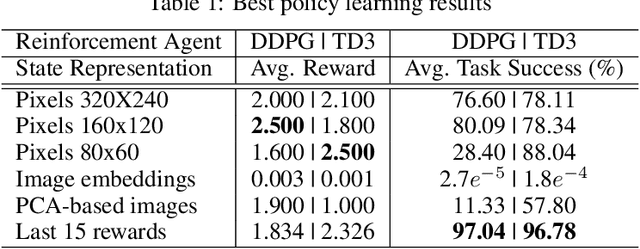
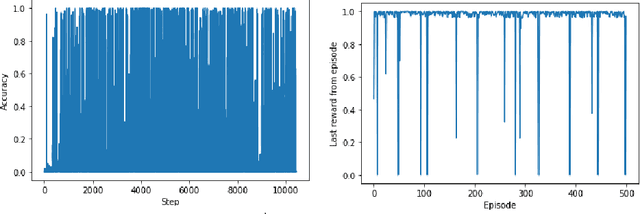

Training robot manipulation policies is a challenging and open problem in robotics and artificial intelligence. In this paper we propose a novel and compact state representation based on the rewards predicted from an image-based task success classifier. Our experiments, using the Pepper robot in simulation with two deep reinforcement learning algorithms on a grab-and-lift task, reveal that our proposed state representation can achieve up to 97% task success using our best policies.
Cross-domain Correspondence Learning for Exemplar-based Image Translation
Apr 12, 2020
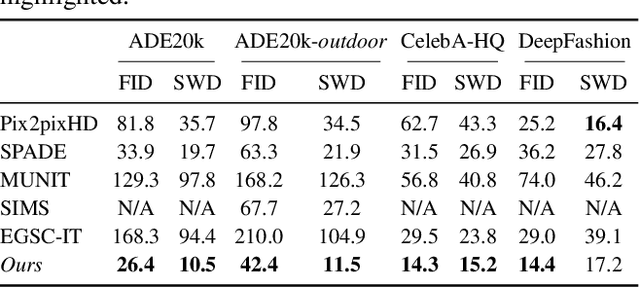
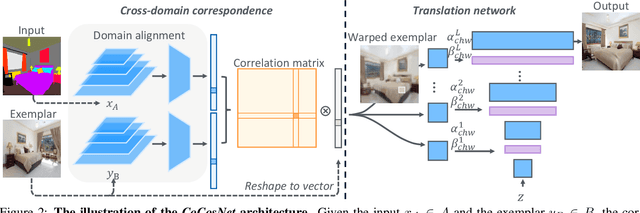
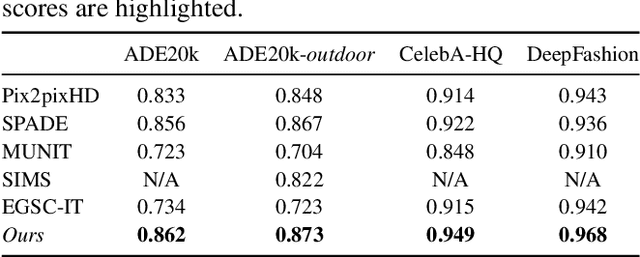
We present a general framework for exemplar-based image translation, which synthesizes a photo-realistic image from the input in a distinct domain (e.g., semantic segmentation mask, or edge map, or pose keypoints), given an exemplar image. The output has the style (e.g., color, texture) in consistency with the semantically corresponding objects in the exemplar. We propose to jointly learn the crossdomain correspondence and the image translation, where both tasks facilitate each other and thus can be learned with weak supervision. The images from distinct domains are first aligned to an intermediate domain where dense correspondence is established. Then, the network synthesizes images based on the appearance of semantically corresponding patches in the exemplar. We demonstrate the effectiveness of our approach in several image translation tasks. Our method is superior to state-of-the-art methods in terms of image quality significantly, with the image style faithful to the exemplar with semantic consistency. Moreover, we show the utility of our method for several applications
* Accepted as a CVPR 2020 oral paper
Person image generation with semantic attention network for person re-identification
Aug 18, 2020
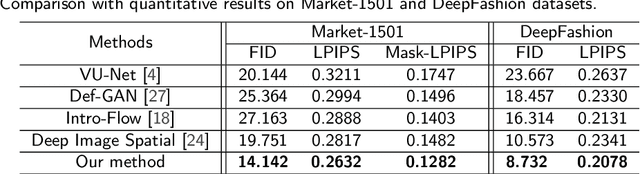
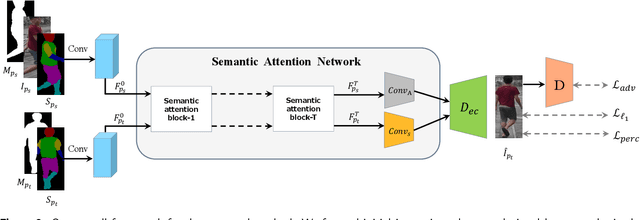
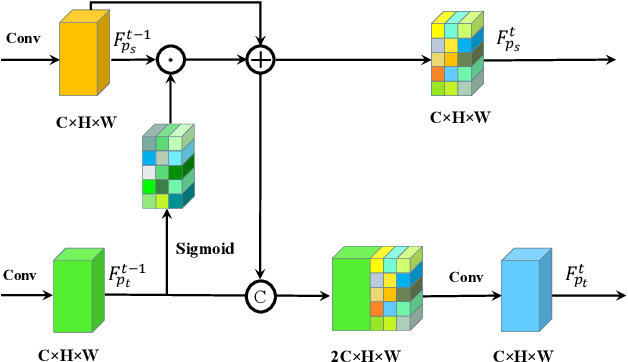
Pose variation is one of the key factors which prevents the network from learning a robust person re-identification (Re-ID) model. To address this issue, we propose a novel person pose-guided image generation method, which is called the semantic attention network. The network consists of several semantic attention blocks, where each block attends to preserve and update the pose code and the clothing textures. The introduction of the binary segmentation mask and the semantic parsing is important for seamlessly stitching foreground and background in the pose-guided image generation. Compared with other methods, our network can characterize better body shape and keep clothing attributes, simultaneously. Our synthesized image can obtain better appearance and shape consistency related to the original image. Experimental results show that our approach is competitive with respect to both quantitative and qualitative results on Market-1501 and DeepFashion. Furthermore, we conduct extensive evaluations by using person re-identification (Re-ID) systems trained with the pose-transferred person based augmented data. The experiment shows that our approach can significantly enhance the person Re-ID accuracy.