 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
Nov 16, 2021

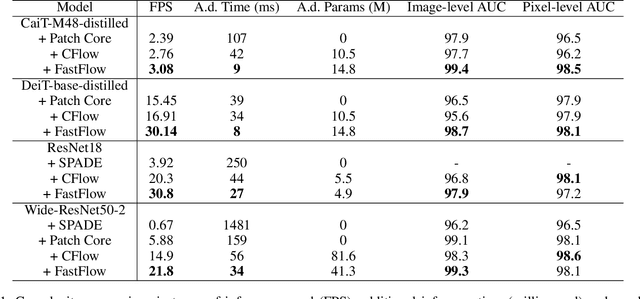
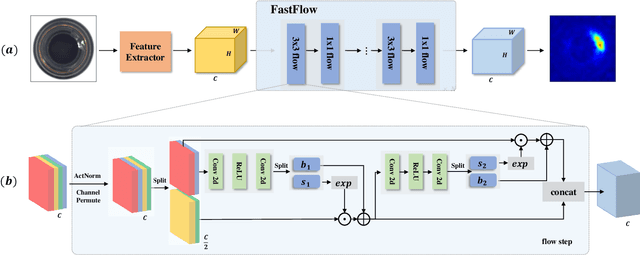

Unsupervised anomaly detection and localization is crucial to the practical application when collecting and labeling sufficient anomaly data is infeasible. Most existing representation-based approaches extract normal image features with a deep convolutional neural network and characterize the corresponding distribution through non-parametric distribution estimation methods. The anomaly score is calculated by measuring the distance between the feature of the test image and the estimated distribution. However, current methods can not effectively map image features to a tractable base distribution and ignore the relationship between local and global features which are important to identify anomalies. To this end, we propose FastFlow implemented with 2D normalizing flows and use it as the probability distribution estimator. Our FastFlow can be used as a plug-in module with arbitrary deep feature extractors such as ResNet and vision transformer for unsupervised anomaly detection and localization. In training phase, FastFlow learns to transform the input visual feature into a tractable distribution and obtains the likelihood to recognize anomalies in inference phase. Extensive experimental results on the MVTec AD dataset show that FastFlow surpasses previous state-of-the-art methods in terms of accuracy and inference efficiency with various backbone networks. Our approach achieves 99.4% AUC in anomaly detection with high inference efficiency.
3D-Aware Semantic-Guided Generative Model for Human Synthesis
Dec 02, 2021
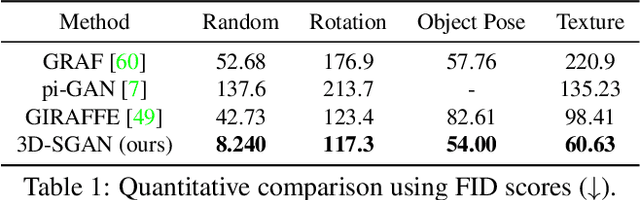
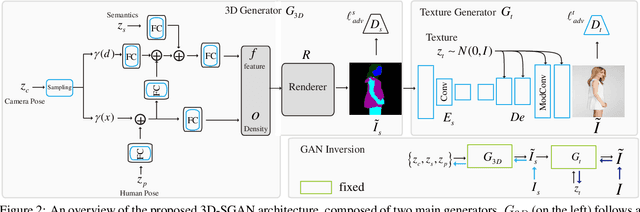
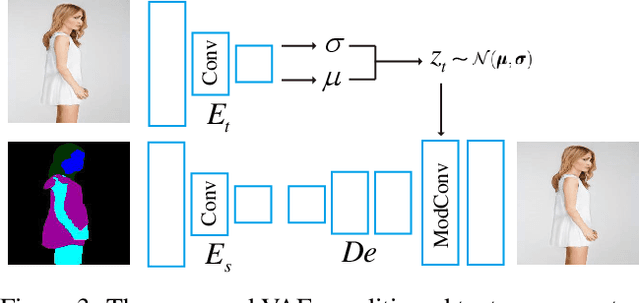
Generative Neural Radiance Field (GNeRF) models, which extract implicit 3D representations from 2D images, have recently been shown to produce realistic images representing rigid objects, such as human faces or cars. However, they usually struggle to generate high-quality images representing non-rigid objects, such as the human body, which is of a great interest for many computer graphics applications. This paper proposes a 3D-aware Semantic-Guided Generative Model (3D-SGAN) for human image synthesis, which integrates a GNeRF and a texture generator. The former learns an implicit 3D representation of the human body and outputs a set of 2D semantic segmentation masks. The latter transforms these semantic masks into a real image, adding a realistic texture to the human appearance. Without requiring additional 3D information, our model can learn 3D human representations with a photo-realistic controllable generation. Our experiments on the DeepFashion dataset show that 3D-SGAN significantly outperforms the most recent baselines.
Multi-Class Micro-CT Image Segmentation Using Sparse Regularized Deep Networks
Apr 21, 2021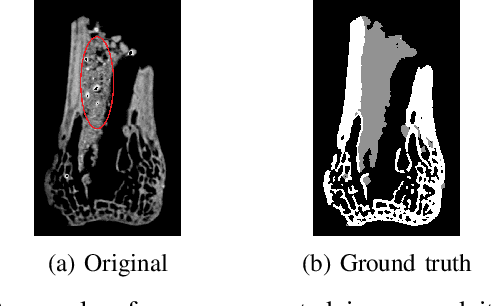

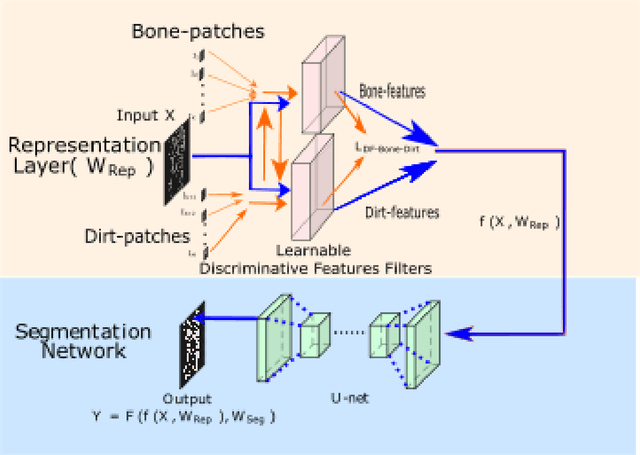
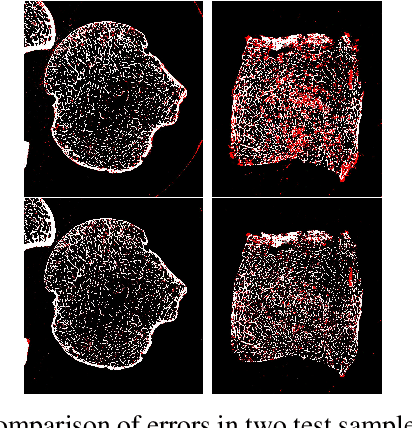
It is common in anthropology and paleontology to address questions about extant and extinct species through the quantification of osteological features observable in micro-computed tomographic (micro-CT) scans. In cases where remains were buried, the grey values present in these scans may be classified as belonging to air, dirt, or bone. While various intensity-based methods have been proposed to segment scans into these classes, it is often the case that intensity values for dirt and bone are nearly indistinguishable. In these instances, scientists resort to laborious manual segmentation, which does not scale well in practice when a large number of scans are to be analyzed. Here we present a new domain-enriched network for three-class image segmentation, which utilizes the domain knowledge of experts familiar with manually segmenting bone and dirt structures. More precisely, our novel structure consists of two components: 1) a representation network trained on special samples based on newly designed custom loss terms, which extracts discriminative bone and dirt features, 2) and a segmentation network that leverages these extracted discriminative features. These two parts are jointly trained in order to optimize the segmentation performance. A comparison of our network to that of the current state-of-the-art U-NETs demonstrates the benefits of our proposal, particularly when the number of labeled training images are limited, which is invariably the case for micro-CT segmentation.
RegNet: Self-Regulated Network for Image Classification
Jan 03, 2021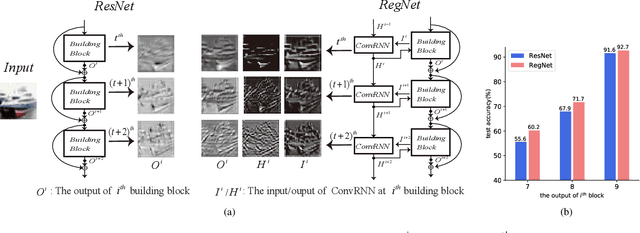
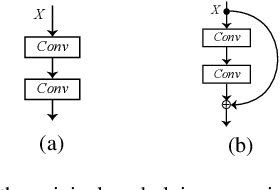
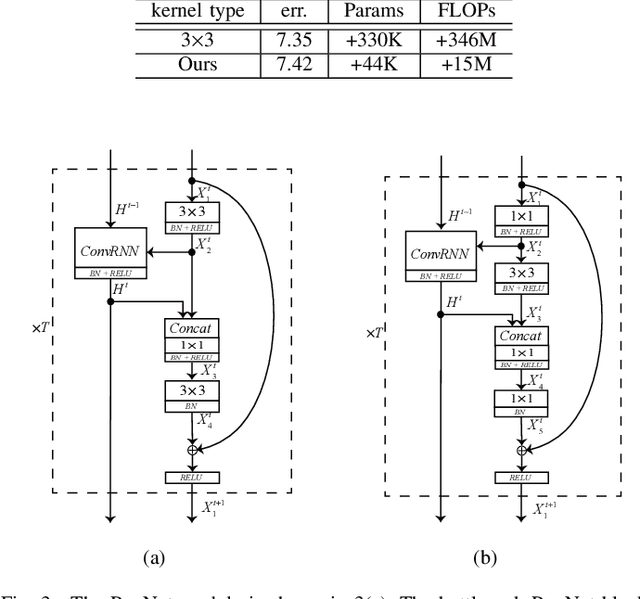
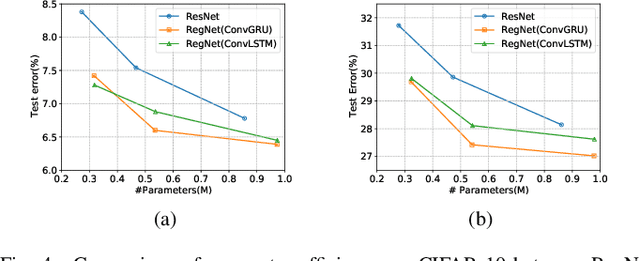
The ResNet and its variants have achieved remarkable successes in various computer vision tasks. Despite its success in making gradient flow through building blocks, the simple shortcut connection mechanism limits the ability of re-exploring new potentially complementary features due to the additive function. To address this issue, in this paper, we propose to introduce a regulator module as a memory mechanism to extract complementary features, which are further fed to the ResNet. In particular, the regulator module is composed of convolutional RNNs (e.g., Convolutional LSTMs or Convolutional GRUs), which are shown to be good at extracting Spatio-temporal information. We named the new regulated networks as RegNet. The regulator module can be easily implemented and appended to any ResNet architecture. We also apply the regulator module for improving the Squeeze-and-Excitation ResNet to show the generalization ability of our method. Experimental results on three image classification datasets have demonstrated the promising performance of the proposed architecture compared with the standard ResNet, SE-ResNet, and other state-of-the-art architectures.
StratDef: a strategic defense against adversarial attacks in malware detection
Feb 15, 2022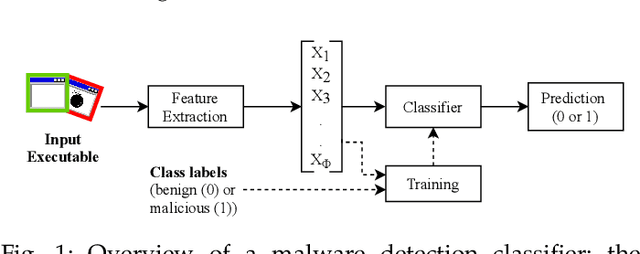

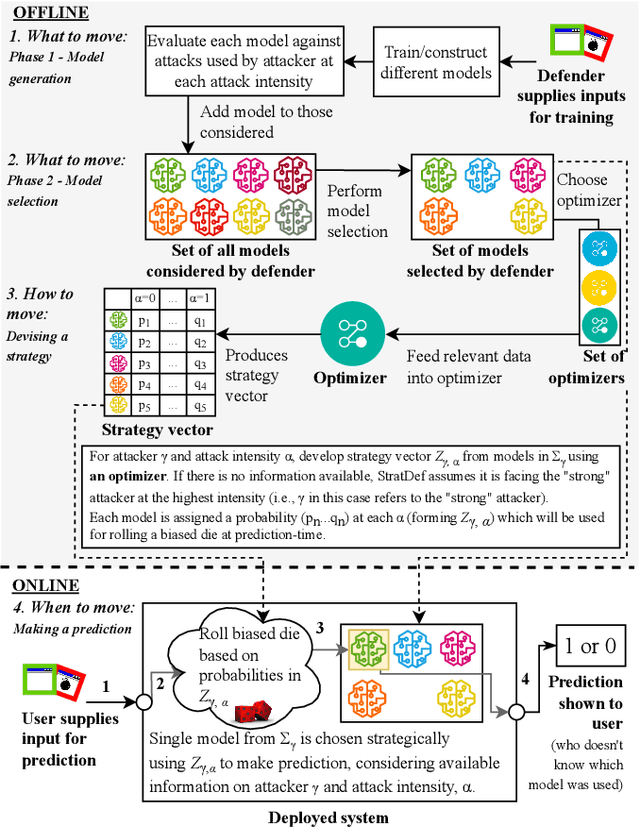

Over the years, most research towards defenses against adversarial attacks on machine learning models has been in the image processing domain. The malware detection domain has received less attention despite its importance. Moreover, most work exploring defenses focuses on feature-based, gradient-based or randomized methods but with no strategy when applying them. In this paper, we introduce StratDef, which is a strategic defense system tailored for the malware detection domain based on a Moving Target Defense and Game Theory approach. We overcome challenges related to the systematic construction, selection and strategic use of models to maximize adversarial robustness. StratDef dynamically and strategically chooses the best models to increase the uncertainty for the attacker, whilst minimizing critical aspects in the adversarial ML domain like attack transferability. We provide the first comprehensive evaluation of defenses against adversarial attacks on machine learning for malware detection, where our threat model explores different levels of threat, attacker knowledge, capabilities, and attack intensities. We show that StratDef performs better than other defenses even when facing the peak adversarial threat. We also show that, from the existing defenses, only a few adversarially-trained models provide substantially better protection than just using vanilla models but are still outperformed by StratDef.
Channel-wise Autoregressive Entropy Models for Learned Image Compression
Jul 17, 2020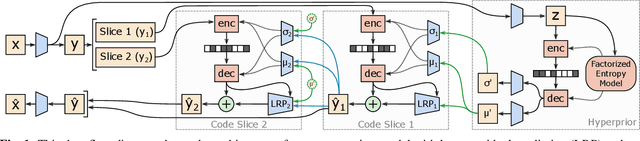

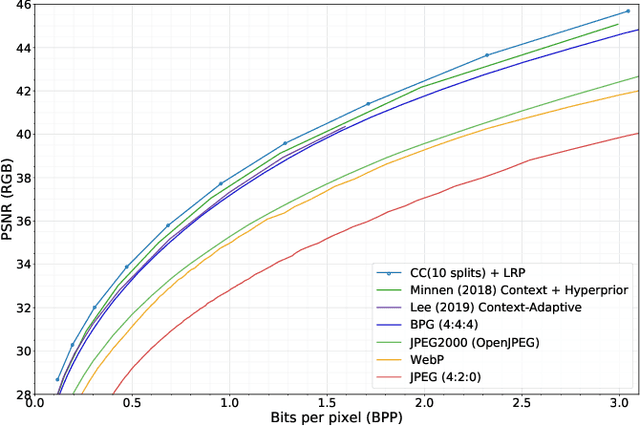
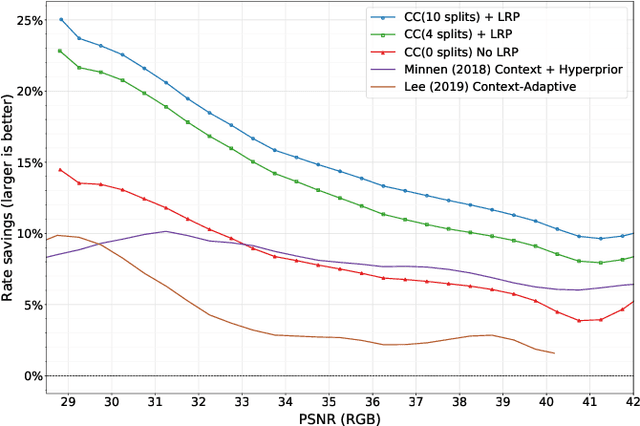
In learning-based approaches to image compression, codecs are developed by optimizing a computational model to minimize a rate-distortion objective. Currently, the most effective learned image codecs take the form of an entropy-constrained autoencoder with an entropy model that uses both forward and backward adaptation. Forward adaptation makes use of side information and can be efficiently integrated into a deep neural network. In contrast, backward adaptation typically makes predictions based on the causal context of each symbol, which requires serial processing that prevents efficient GPU / TPU utilization. We introduce two enhancements, channel-conditioning and latent residual prediction, that lead to network architectures with better rate-distortion performance than existing context-adaptive models while minimizing serial processing. Empirically, we see an average rate savings of 6.7% on the Kodak image set and 11.4% on the Tecnick image set compared to a context-adaptive baseline model. At low bit rates, where the improvements are most effective, our model saves up to 18% over the baseline and outperforms hand-engineered codecs like BPG by up to 25%.
Real Time Integration Centre of Mass (riCOM) Reconstruction for 4D-STEM
Dec 14, 2021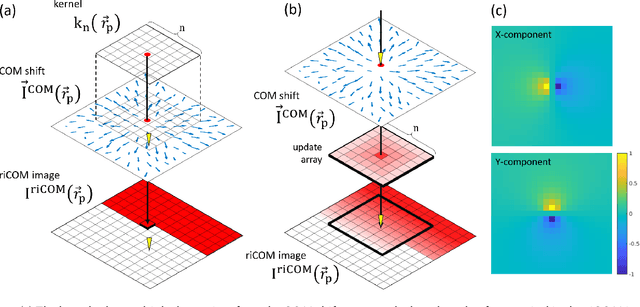
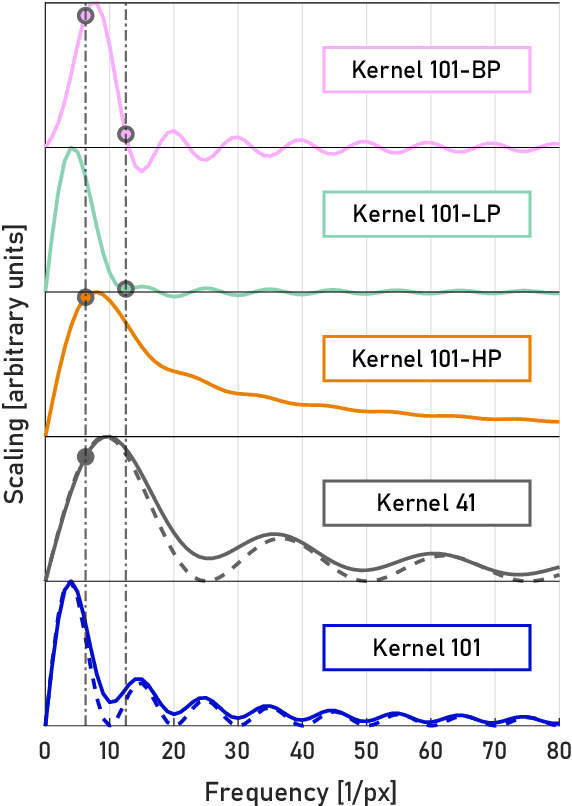
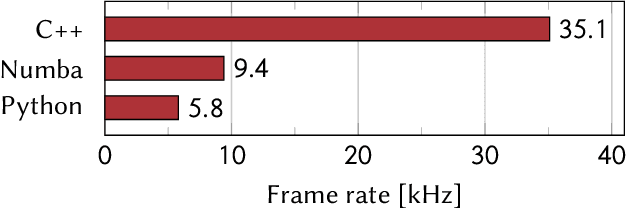
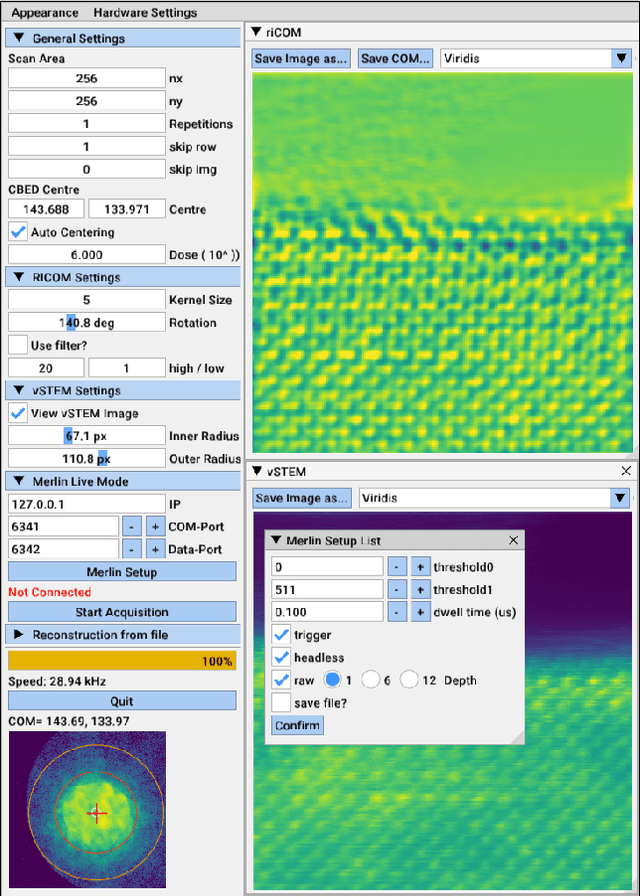
A real-time image reconstruction method for scanning transmission electron microscopy (STEM) is proposed. With an algorithm requiring only the center of mass (COM) of the diffraction pattern at one probe position at a time, it is able to update the resulting image each time a new probe position is visited without storing any intermediate diffraction patterns. The results show clear features at higher spatial frequency, such as atomic column positions. It is also demonstrated that some common post processing methods, such as band pass filtering, can be directly integrated in the real time processing flow. Compared with other reconstruction methods, the proposed method produces high quality reconstructions with good noise robustness at extremely low memory and computational requirements. An efficient, interactive open source implementation of the concept is further presented, which is compatible with frame-based, as well as event-based camera/file types. This method provides the attractive feature of immediate feedback that microscope operators have become used to, e.g. conventional high angle annular dark field STEM imaging, allowing for rapid decision making and fine tuning to obtain the best possible images for beam sensitive samples at the lowest possible dose.
Do 2D GANs Know 3D Shape? Unsupervised 3D shape reconstruction from 2D Image GANs
Nov 02, 2020

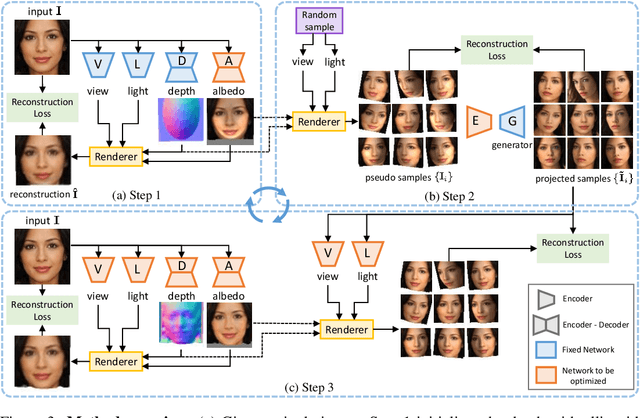

Natural images are projections of 3D objects on a 2D image plane. While state-of-the-art 2D generative models like GANs show unprecedented quality in modeling the natural image manifold, it is unclear whether they implicitly capture the underlying 3D object structures. And if so, how could we exploit such knowledge to recover the 3D shapes of objects in the images? To answer these questions, in this work, we present the first attempt to directly mine 3D geometric clues from an off-the-shelf 2D GAN that is trained on RGB images only. Through our investigation, we found that such a pre-trained GAN indeed contains rich 3D knowledge and thus can be used to recover 3D shape from a single 2D image in an unsupervised manner. The core of our framework is an iterative strategy that explores and exploits diverse viewpoint and lighting variations in the GAN image manifold. The framework does not require 2D keypoint or 3D annotations, or strong assumptions on object shapes (e.g. shapes are symmetric), yet it successfully recovers 3D shapes with high precision for human faces, cats, cars, and buildings. The recovered 3D shapes immediately allow high-quality image editing like relighting and object rotation. We quantitatively demonstrate the effectiveness of our approach compared to previous methods in both 3D shape reconstruction and face rotation. Our code and models will be released at https://github.com/XingangPan/GAN2Shape.
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021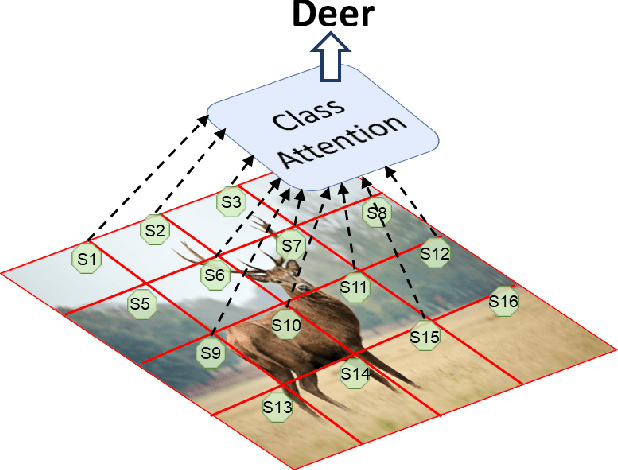
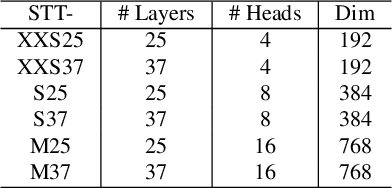
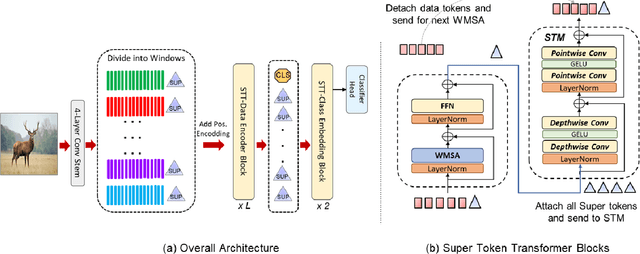
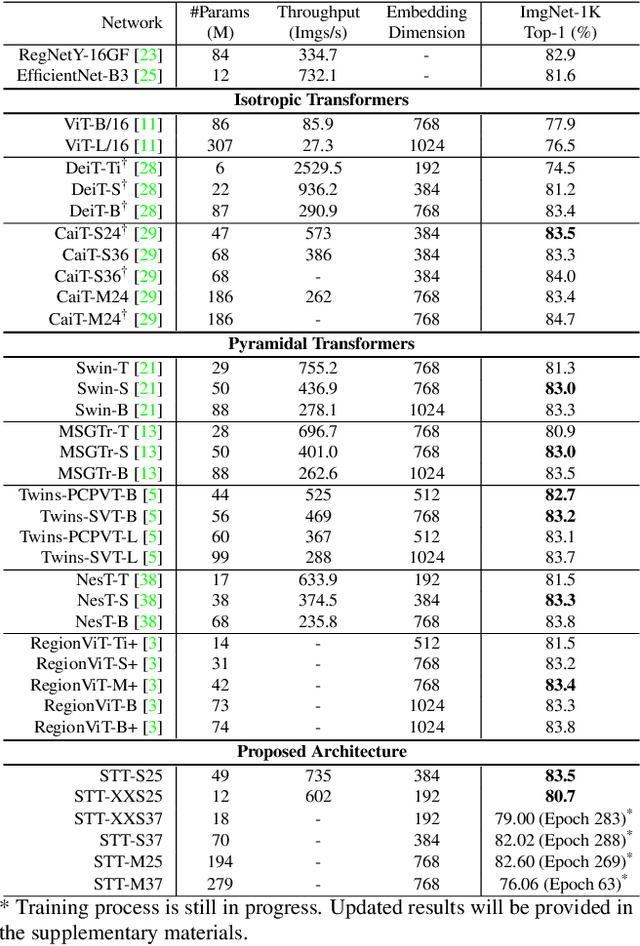
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
Fast Convex Optimization for Two-Layer ReLU Networks: Equivalent Model Classes and Cone Decompositions
Feb 05, 2022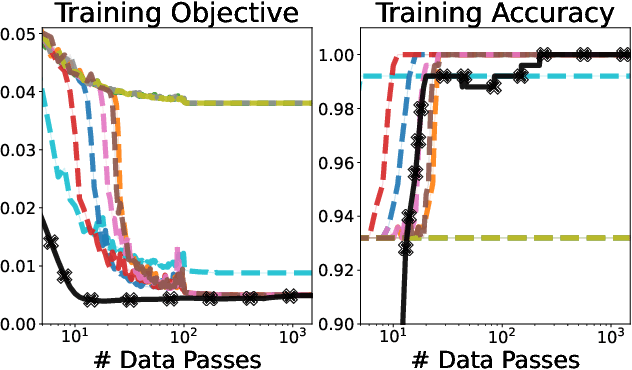
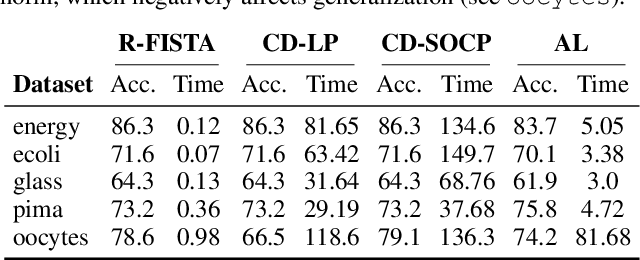
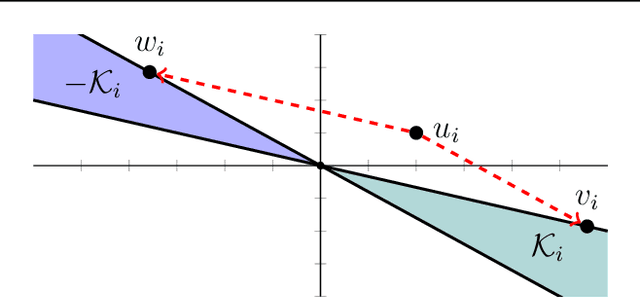
We develop fast algorithms and robust software for convex optimization of two-layer neural networks with ReLU activation functions. Our work leverages a convex reformulation of the standard weight-decay penalized training problem as a set of group-$\ell_1$-regularized data-local models, where locality is enforced by polyhedral cone constraints. In the special case of zero-regularization, we show that this problem is exactly equivalent to unconstrained optimization of a convex "gated ReLU" network. For problems with non-zero regularization, we show that convex gated ReLU models obtain data-dependent approximation bounds for the ReLU training problem. To optimize the convex reformulations, we develop an accelerated proximal gradient method and a practical augmented Lagrangian solver. We show that these approaches are faster than standard training heuristics for the non-convex problem, such as SGD, and outperform commercial interior-point solvers. Experimentally, we verify our theoretical results, explore the group-$\ell_1$ regularization path, and scale convex optimization for neural networks to image classification on MNIST and CIFAR-10.