 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continuation of Famous Art with AI: A Conditional Adversarial Network Inpainting Approach
Oct 18, 2021


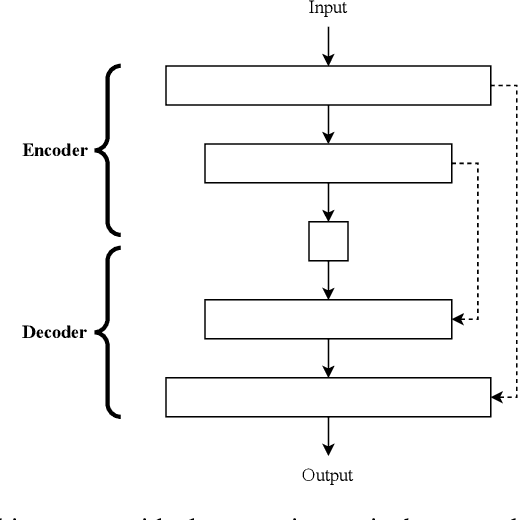
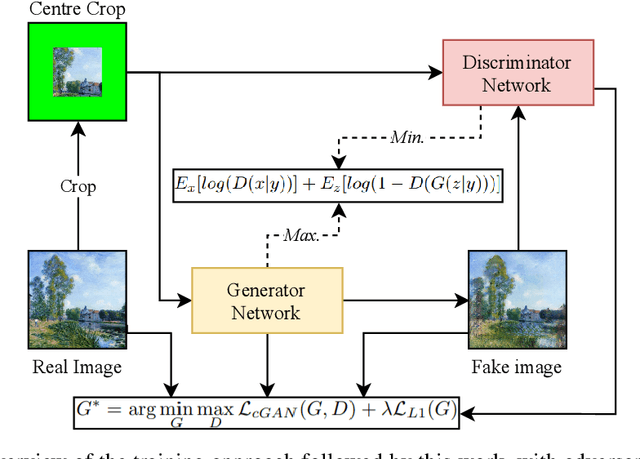
Much of the state-of-the-art in image synthesis inspired by real artwork are either entirely generative by filtered random noise or inspired by the transfer of style. This work explores the application of image inpainting to continue famous artworks and produce generative art with a Conditional GAN. During the training stage of the process, the borders of images are cropped, leaving only the centre. An inpainting GAN is then tasked with learning to reconstruct the original image from the centre crop by way of minimising both adversarial and absolute difference losses. Once the network is trained, images are then resized rather than cropped and presented as input to the generator. Following the learning process, the generator then creates new images by continuing from the edges of the original piece. Three experiments are performed with datasets of 4766 landscape paintings (impressionism and romanticism), 1167 Ukiyo-e works from the Japanese Edo period, and 4968 abstract artworks. Results show that geometry and texture (including canvas and paint) as well as scenery such as sky, clouds, water, land (including hills and mountains), grass, and flowers are implemented by the generator when extending real artworks. In the Ukiyo-e experiments, it was observed that features such as written text were generated even in cases where the original image did not have any, due to the presence of an unpainted border within the input image.
SketchyCOCO: Image Generation from Freehand Scene Sketches
Apr 07, 2020
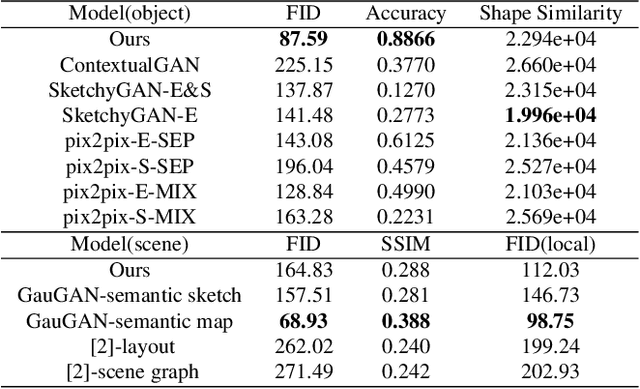
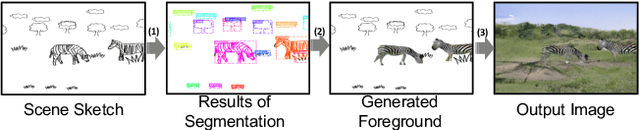
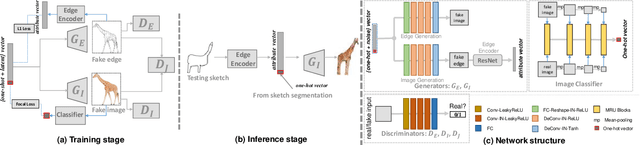
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged Generative Adversarial Network called EdgeGAN, which supports high visual-quality object-level image content generation without using freehand sketches as training data. We have built a large-scale composite dataset called SketchyCOCO to support and evaluate the solution. We validate our approach on the tasks of both object-level and scene-level image generation on SketchyCOCO. Through quantitative, qualitative results, human evaluation and ablation studies, we demonstrate the method's capacity to generate realistic complex scene-level images from various freehand sketches.
Metastatic Cancer Image Classification Based On Deep Learning Method
Nov 13, 2020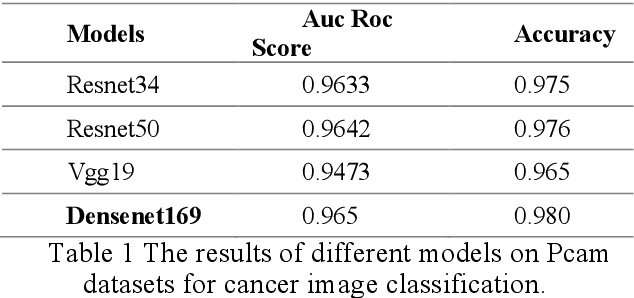
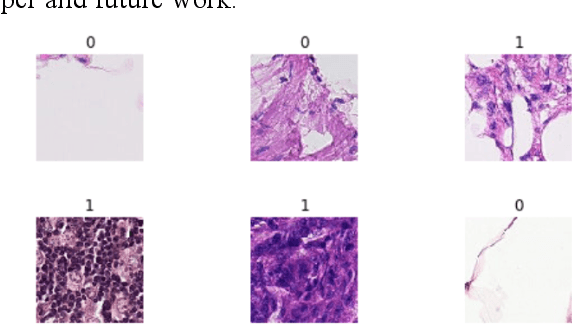
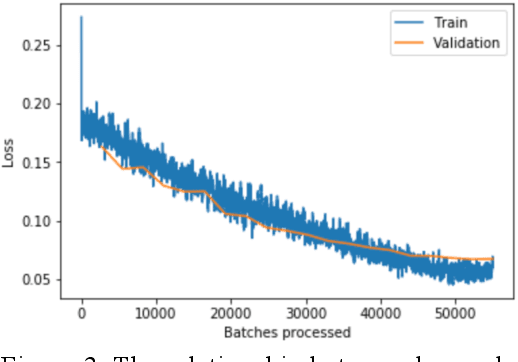
Using histopathological images to automatically classify cancer is a difficult task for accurately detecting cancer, especially to identify metastatic cancer in small image patches obtained from larger digital pathology scans. Computer diagnosis technology has attracted wide attention from researchers. In this paper, we propose a noval method which combines the deep learning algorithm in image classification, the DenseNet169 framework and Rectified Adam optimization algorithm. The connectivity pattern of DenseNet is direct connections from any layer to all consecutive layers, which can effectively improve the information flow between different layers. With the fact that RAdam is not easy to fall into a local optimal solution, and it can converge quickly in model training. The experimental results shows that our model achieves superior performance over the other classical convolutional neural networks approaches, such as Vgg19, Resnet34, Resnet50. In particular, the Auc-Roc score of our DenseNet169 model is 1.77% higher than Vgg19 model, and the Accuracy score is 1.50% higher. Moreover, we also study the relationship between loss value and batches processed during the training stage and validation stage, and obtain some important and interesting findings.
AugLy: Data Augmentations for Robustness
Jan 17, 2022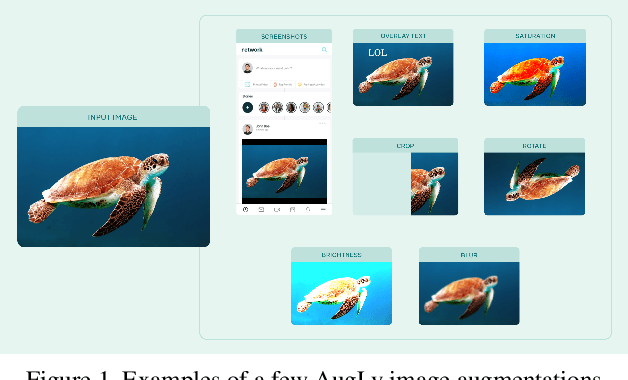
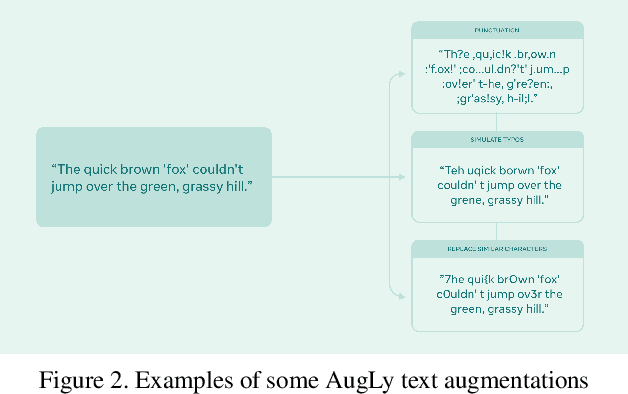
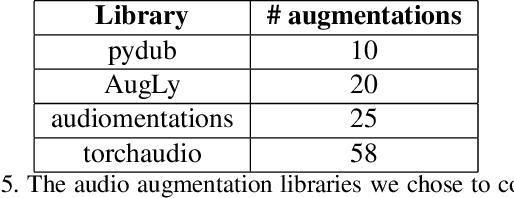
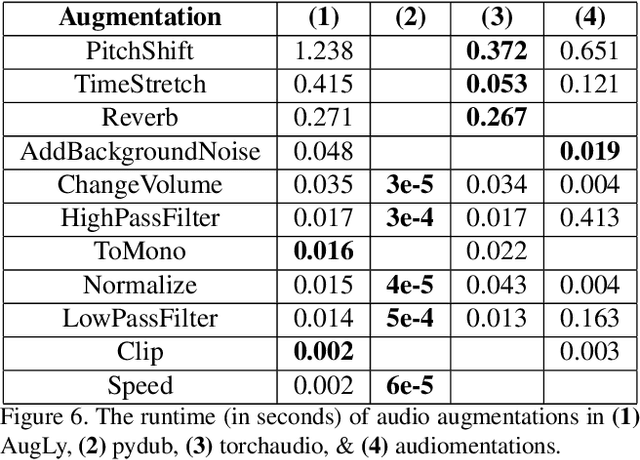
We introduce AugLy, a data augmentation library with a focus on adversarial robustness. AugLy provides a wide array of augmentations for multiple modalities (audio, image, text, & video). These augmentations were inspired by those that real users perform on social media platforms, some of which were not already supported by existing data augmentation libraries. AugLy can be used for any purpose where data augmentations are useful, but it is particularly well-suited for evaluating robustness and systematically generating adversarial attacks. In this paper we present how AugLy works, benchmark it compared against existing libraries, and use it to evaluate the robustness of various state-of-the-art models to showcase AugLy's utility. The AugLy repository can be found at https://github.com/facebookresearch/AugLy.
SwitchHit: A Probabilistic, Complementarity-Based Switching System for Improved Visual Place Recognition in Changing Environments
Mar 01, 2022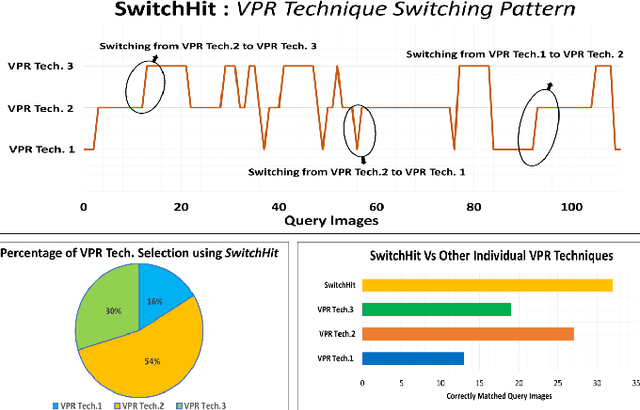
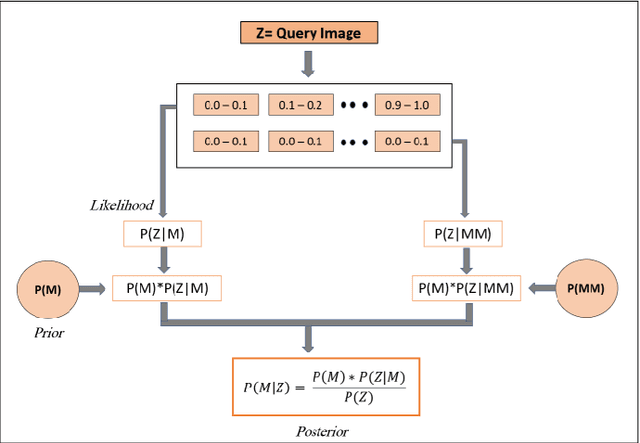
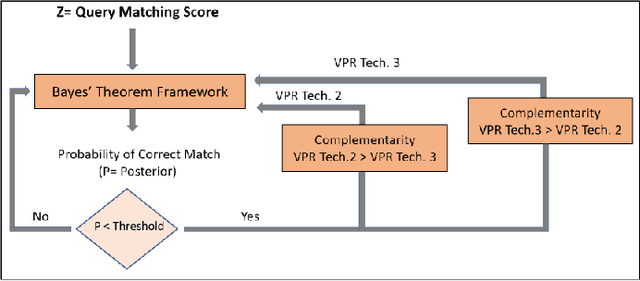
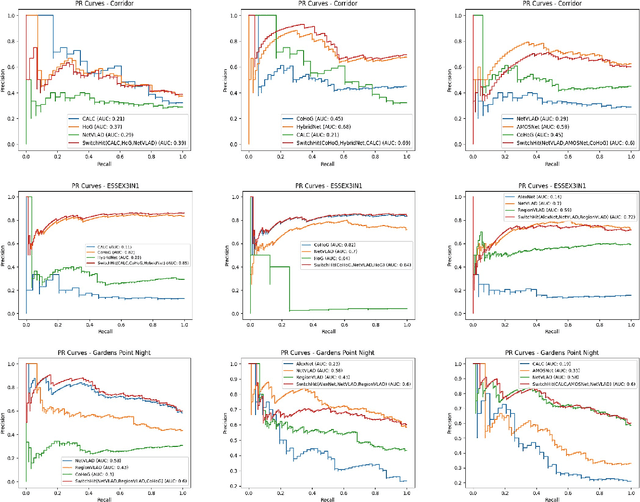
Visual place recognition (VPR), a fundamental task in computer vision and robotics, is the problem of identifying a place mainly based on visual information. Viewpoint and appearance changes, such as due to weather and seasonal variations, make this task challenging. Currently, there is no universal VPR technique that can work in all types of environments, on a variety of robotic platforms, and under a wide range of viewpoint and appearance changes. Recent work has shown the potential of combining different VPR methods intelligently by evaluating complementarity for some specific VPR datasets to achieve better performance. This, however, requires ground truth information (correct matches) which is not available when a robot is deployed in a real-world scenario. Moreover, running multiple VPR techniques in parallel may be prohibitive for resource-constrained embedded platforms. To overcome these limitations, this paper presents a probabilistic complementarity based switching VPR system, SwitchHit. Our proposed system consists of multiple VPR techniques, however, it does not simply run all techniques at once, rather predicts the probability of correct match for an incoming query image and dynamically switches to another complementary technique if the probability of correctly matching the query is below a certain threshold. This innovative use of multiple VPR techniques allow our system to be more efficient and robust than other combined VPR approaches employing brute force and running multiple VPR techniques at once. Thus making it more suitable for resource constrained embedded systems and achieving an overall superior performance from what any individual VPR method in the system could have by achieved running independently.
NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy
Feb 11, 2022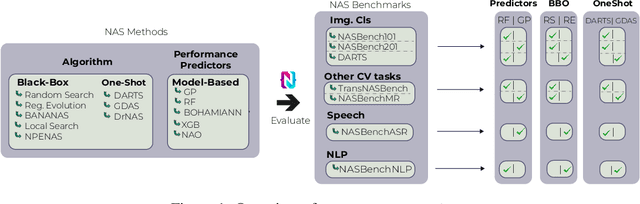
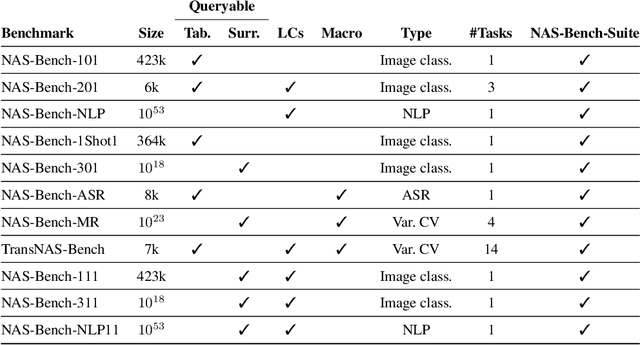
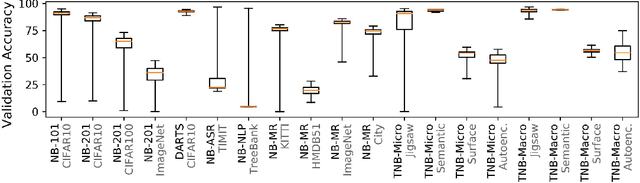
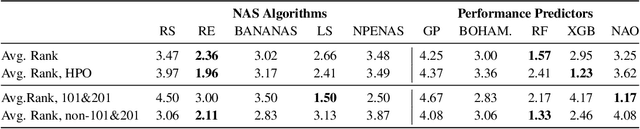
The release of tabular benchmarks, such as NAS-Bench-101 and NAS-Bench-201, has significantly lowered the computational overhead for conducting scientific research in neural architecture search (NAS). Although they have been widely adopted and used to tune real-world NAS algorithms, these benchmarks are limited to small search spaces and focus solely on image classification. Recently, several new NAS benchmarks have been introduced that cover significantly larger search spaces over a wide range of tasks, including object detection, speech recognition, and natural language processing. However, substantial differences among these NAS benchmarks have so far prevented their widespread adoption, limiting researchers to using just a few benchmarks. In this work, we present an in-depth analysis of popular NAS algorithms and performance prediction methods across 25 different combinations of search spaces and datasets, finding that many conclusions drawn from a few NAS benchmarks do not generalize to other benchmarks. To help remedy this problem, we introduce NAS-Bench-Suite, a comprehensive and extensible collection of NAS benchmarks, accessible through a unified interface, created with the aim to facilitate reproducible, generalizable, and rapid NAS research. Our code is available at https://github.com/automl/naslib.
Towards General Deep Leakage in Federated Learning
Oct 18, 2021

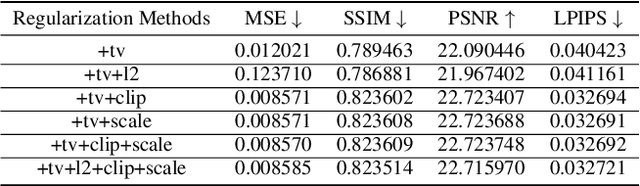
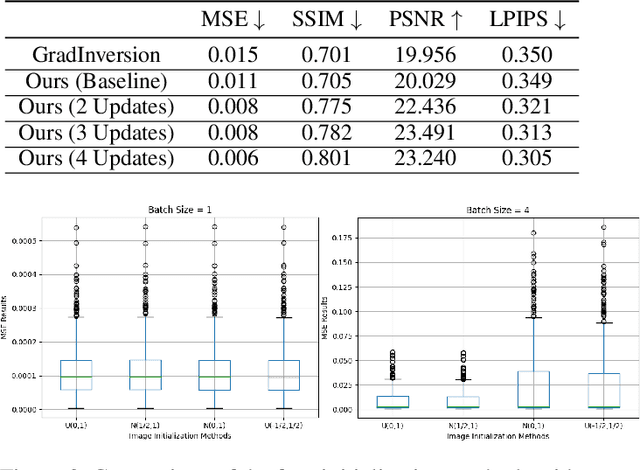
Unlike traditional central training, federated learning (FL) improves the performance of the global model by sharing and aggregating local models rather than local data to protect the users' privacy. Although this training approach appears secure, some research has demonstrated that an attacker can still recover private data based on the shared gradient information. This on-the-fly reconstruction attack deserves to be studied in depth because it can occur at any stage of training, whether at the beginning or at the end of model training; no relevant dataset is required and no additional models need to be trained. We break through some unrealistic assumptions and limitations to apply this reconstruction attack in a broader range of scenarios. We propose methods that can reconstruct the training data from shared gradients or weights, corresponding to the FedSGD and FedAvg usage scenarios, respectively. We propose a zero-shot approach to restore labels even if there are duplicate labels in the batch. We study the relationship between the label and image restoration. We find that image restoration fails even if there is only one incorrectly inferred label in the batch; we also find that when batch images have the same label, the corresponding image is restored as a fusion of that class of images. Our approaches are evaluated on classic image benchmarks, including CIFAR-10 and ImageNet. The batch size, image quality, and the adaptability of the label distribution of our approach exceed those of GradInversion, the state-of-the-art.
Explainable COVID-19 Infections Identification and Delineation Using Calibrated Pseudo Labels
Feb 11, 2022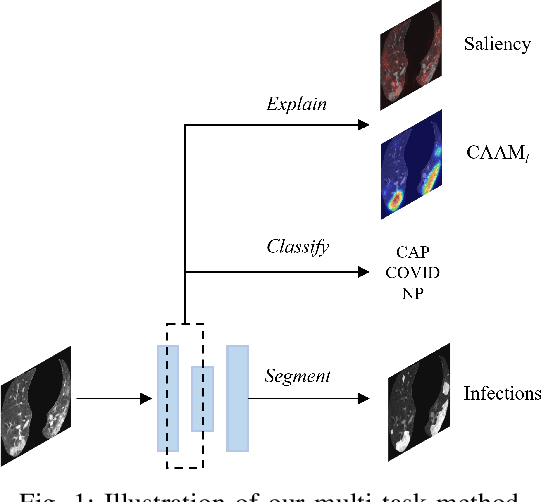
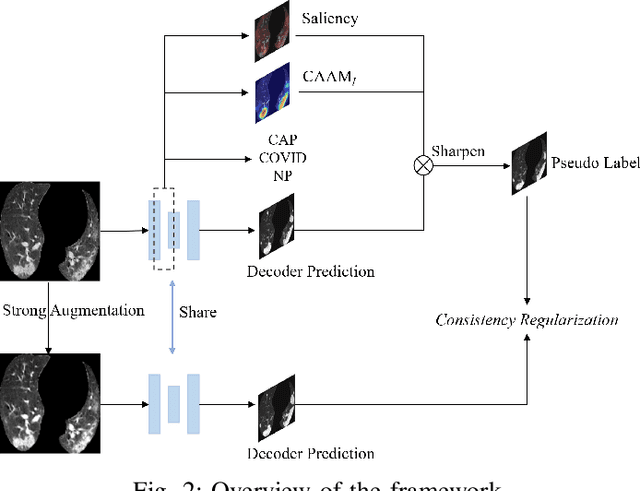
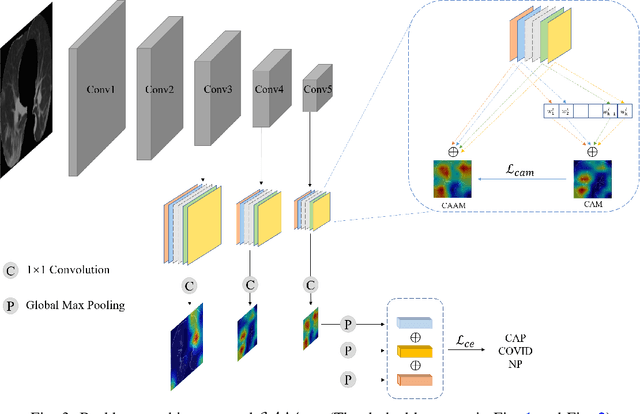
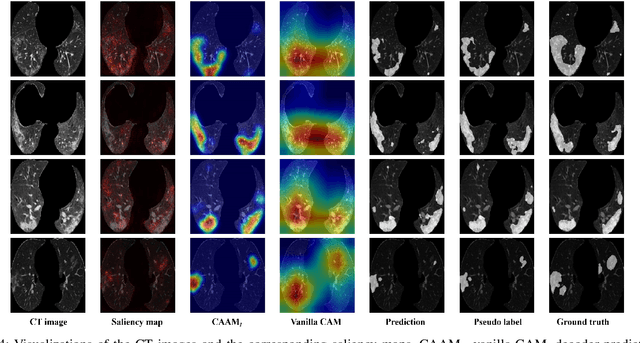
The upheaval brought by the arrival of the COVID-19 pandemic has continued to bring fresh challenges over the past two years. During this COVID-19 pandemic, there has been a need for rapid identification of infected patients and specific delineation of infection areas in computed tomography (CT) images. Although deep supervised learning methods have been established quickly, the scarcity of both image-level and pixellevel labels as well as the lack of explainable transparency still hinder the applicability of AI. Can we identify infected patients and delineate the infections with extreme minimal supervision? Semi-supervised learning (SSL) has demonstrated promising performance under limited labelled data and sufficient unlabelled data. Inspired by SSL, we propose a model-agnostic calibrated pseudo-labelling strategy and apply it under a consistency regularization framework to generate explainable identification and delineation results. We demonstrate the effectiveness of our model with the combination of limited labelled data and sufficient unlabelled data or weakly-labelled data. Extensive experiments have shown that our model can efficiently utilize limited labelled data and provide explainable classification and segmentation results for decision-making in clinical routine.
URIE: Universal Image Enhancement for Visual Recognition in the Wild
Jul 24, 2020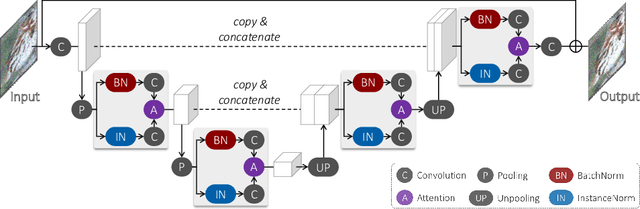

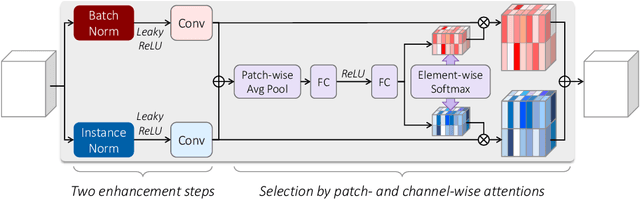

Despite the great advances in visual recognition, it has been witnessed that recognition models trained on clean images of common datasets are not robust against distorted images in the real world. To tackle this issue, we present a Universal and Recognition-friendly Image Enhancement network, dubbed URIE, which is attached in front of existing recognition models and enhances distorted input to improve their performance without retraining them. URIE is universal in that it aims to handle various factors of image degradation and to be incorporated with any arbitrary recognition models. Also, it is recognition-friendly since it is optimized to improve the robustness of following recognition models, instead of perceptual quality of output image. Our experiments demonstrate that URIE can handle various and latent image distortions and improve the performance of existing models for five diverse recognition tasks when input images are degraded.
CSformer: Bridging Convolution and Transformer for Compressive Sensing
Dec 31, 2021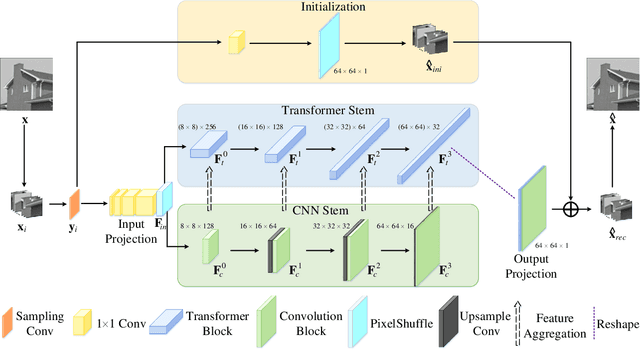
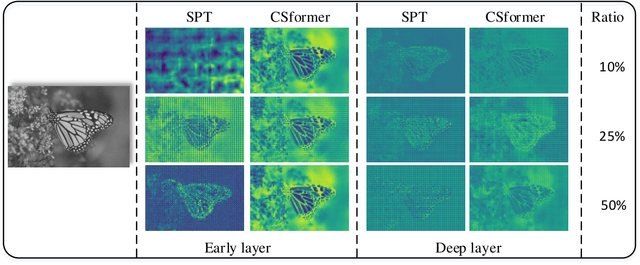
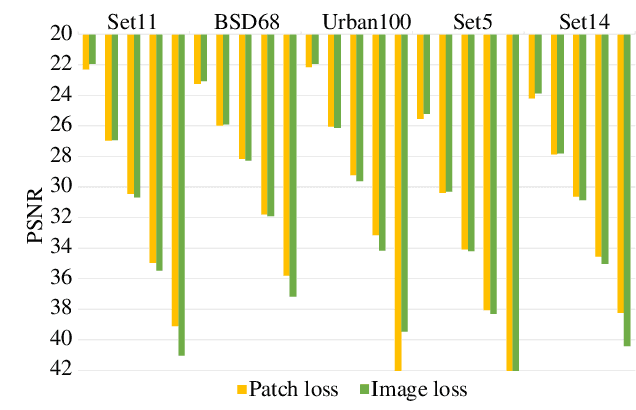
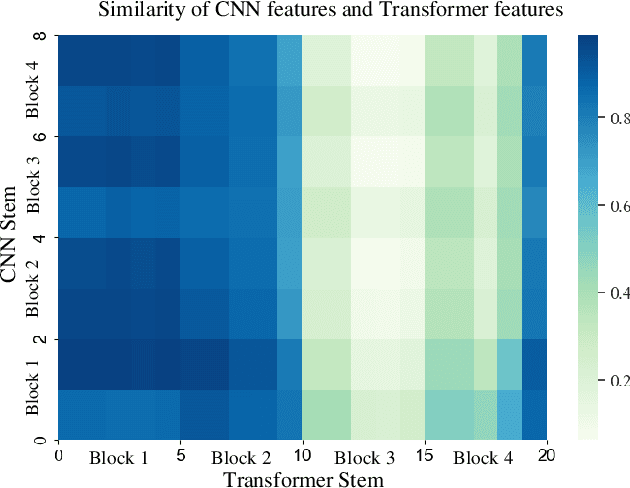
Convolution neural networks (CNNs) have succeeded in compressive image sensing. However, due to the inductive bias of locality and weight sharing, the convolution operations demonstrate the intrinsic limitations in modeling the long-range dependency. Transformer, designed initially as a sequence-to-sequence model, excels at capturing global contexts due to the self-attention-based architectures even though it may be equipped with limited localization abilities. This paper proposes CSformer, a hybrid framework that integrates the advantages of leveraging both detailed spatial information from CNN and the global context provided by transformer for enhanced representation learning. The proposed approach is an end-to-end compressive image sensing method, composed of adaptive sampling and recovery. In the sampling module, images are measured block-by-block by the learned sampling matrix. In the reconstruction stage, the measurement is projected into dual stems. One is the CNN stem for modeling the neighborhood relationships by convolution, and the other is the transformer stem for adopting global self-attention mechanism. The dual branches structure is concurrent, and the local features and global representations are fused under different resolutions to maximize the complementary of features. Furthermore, we explore a progressive strategy and window-based transformer block to reduce the parameter and computational complexity. The experimental results demonstrate the effectiveness of the dedicated transformer-based architecture for compressive sensing, which achieves superior performance compared to state-of-the-art methods on different datasets.