 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Random Ferns for Semantic Segmentation of PolSAR Images
Feb 07, 2022
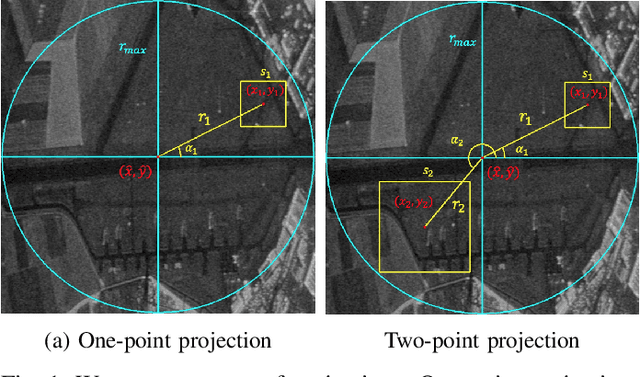
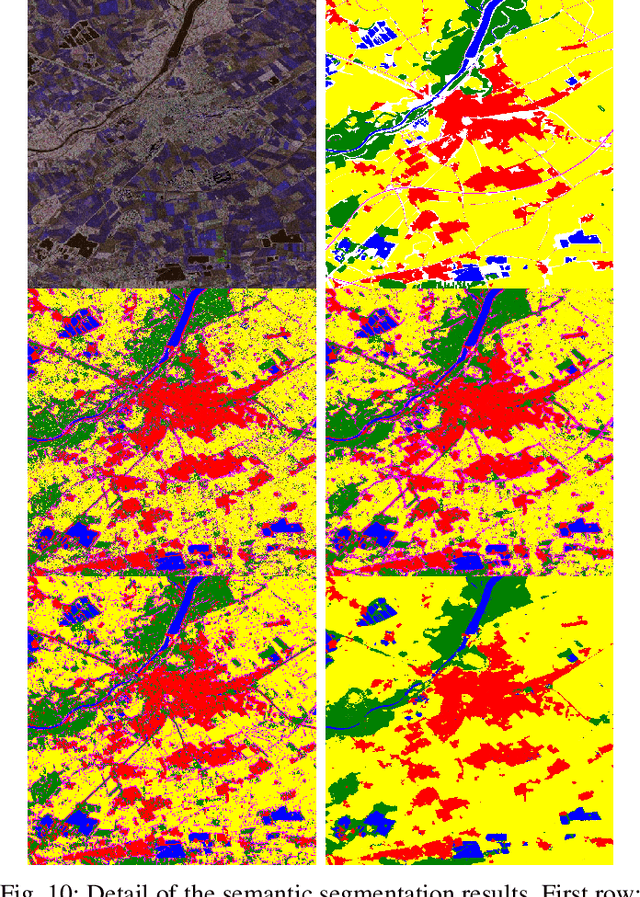
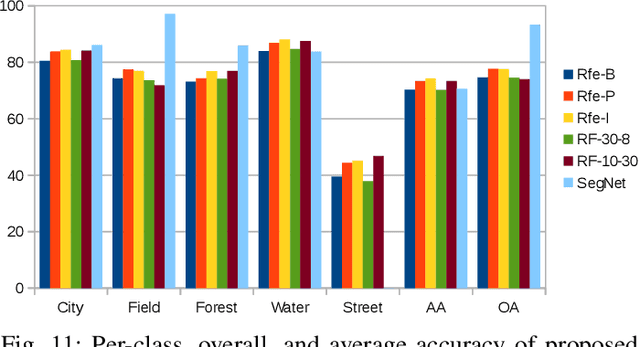
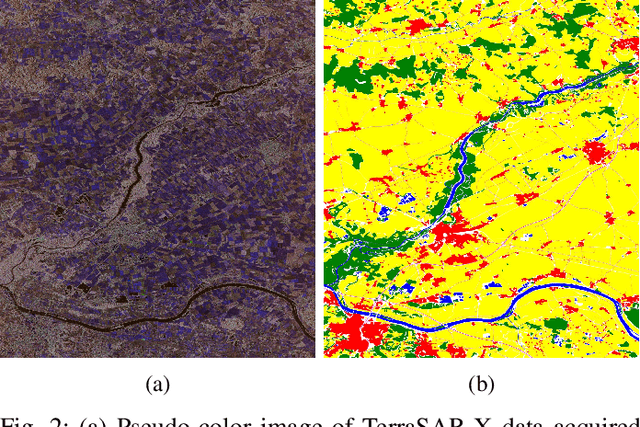
Random Ferns -- as a less known example of Ensemble Learning -- have been successfully applied in many Computer Vision applications ranging from keypoint matching to object detection. This paper extends the Random Fern framework to the semantic segmentation of polarimetric synthetic aperture radar images. By using internal projections that are defined over the space of Hermitian matrices, the proposed classifier can be directly applied to the polarimetric covariance matrices without the need to explicitly compute predefined image features. Furthermore, two distinct optimization strategies are proposed: The first based on pre-selection and grouping of internal binary features before the creation of the classifier; and the second based on iteratively improving the properties of a given Random Fern. Both strategies are able to boost the performance by filtering features that are either redundant or have a low information content and by grouping correlated features to best fulfill the independence assumptions made by the Random Fern classifier. Experiments show that results can be achieved that are similar to a more complex Random Forest model and competitive to a deep learning baseline.
HDR Imaging with Quanta Image Sensors: Theoretical Limits and Optimal Reconstruction
Nov 06, 2020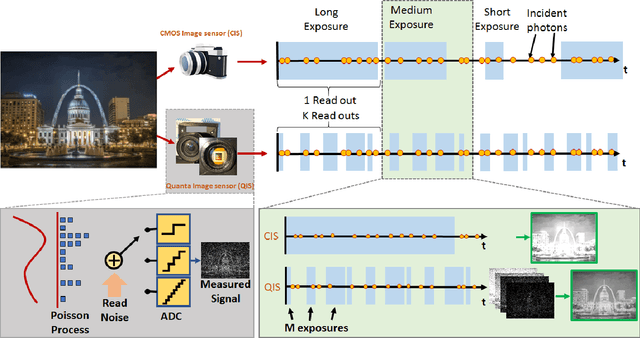
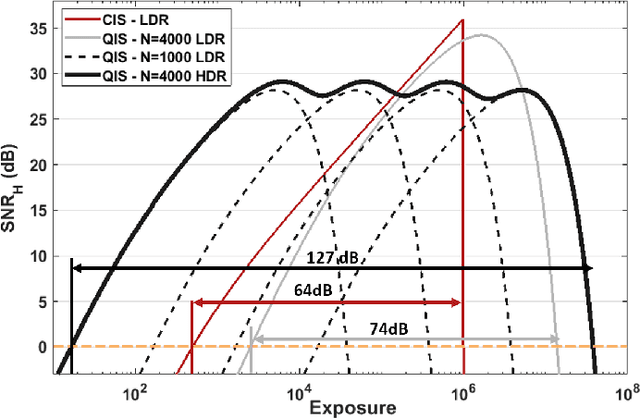

High dynamic range (HDR) imaging is one of the biggest achievements in modern photography. Traditional solutions to HDR imaging are designed for and applied to CMOS image sensors (CIS). However, the mainstream one-micron CIS cameras today generally have a high read noise and low frame-rate. These, in turn, limit the acquisition speed and quality, making the cameras slow in the HDR mode. In this paper, we propose a new computational photography technique for HDR imaging. Recognizing the limitations of CIS, we use the Quanta Image Sensor (QIS) to trade the spatial-temporal resolution with bit-depth. QIS is a single-photon image sensor that has comparable pixel pitch to CIS but substantially lower dark current and read noise. We provide a complete theoretical characterization of the sensor in the context of HDR imaging, by proving the fundamental limits in the dynamic range that QIS can offer and the trade-offs with noise and speed. In addition, we derive an optimal reconstruction algorithm for single-bit and multi-bit QIS. Our algorithm is theoretically optimal for \emph{all} linear reconstruction schemes based on exposure bracketing. Experimental results confirm the validity of the theory and algorithm, based on synthetic and real QIS data.
3D-Aware Indoor Scene Synthesis with Depth Priors
Feb 18, 2022
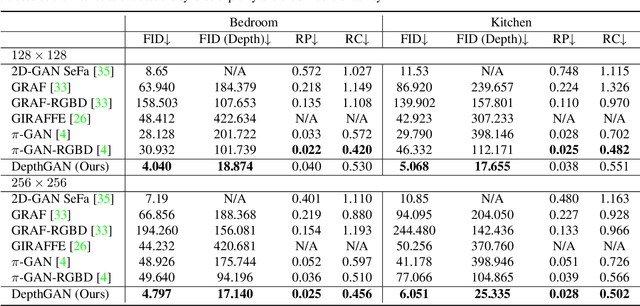
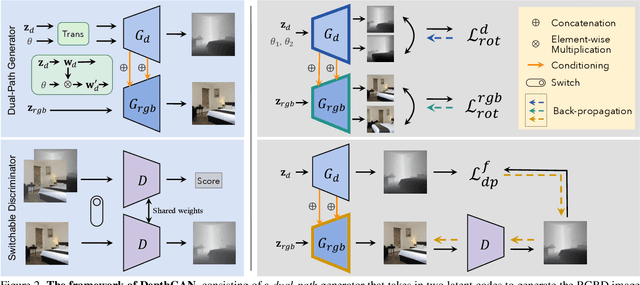
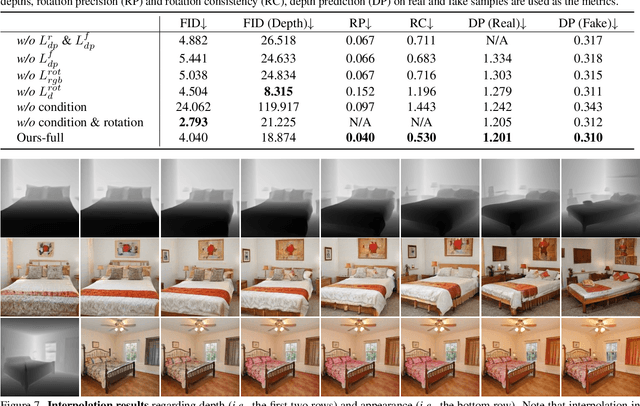
Despite the recent advancement of Generative Adversarial Networks (GANs) in learning 3D-aware image synthesis from 2D data, existing methods fail to model indoor scenes due to the large diversity of room layouts and the objects inside. We argue that indoor scenes do not have a shared intrinsic structure, and hence only using 2D images cannot adequately guide the model with the 3D geometry. In this work, we fill in this gap by introducing depth as a 3D prior. Compared with other 3D data formats, depth better fits the convolution-based generation mechanism and is more easily accessible in practice. Specifically, we propose a dual-path generator, where one path is responsible for depth generation, whose intermediate features are injected into the other path as the condition for appearance rendering. Such a design eases the 3D-aware synthesis with explicit geometry information. Meanwhile, we introduce a switchable discriminator both to differentiate real v.s. fake domains and to predict the depth from a given input. In this way, the discriminator can take the spatial arrangement into account and advise the generator to learn an appropriate depth condition. Extensive experimental results suggest that our approach is capable of synthesizing indoor scenes with impressively good quality and 3D consistency, significantly outperforming state-of-the-art alternatives.
Perceptual underwater image enhancement with deep learning and physical priors
Sep 26, 2020
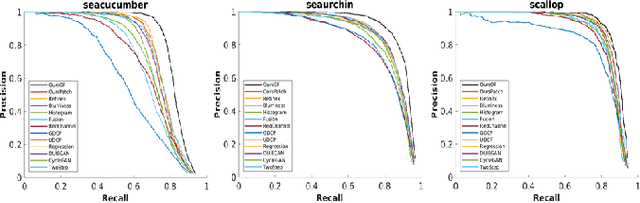
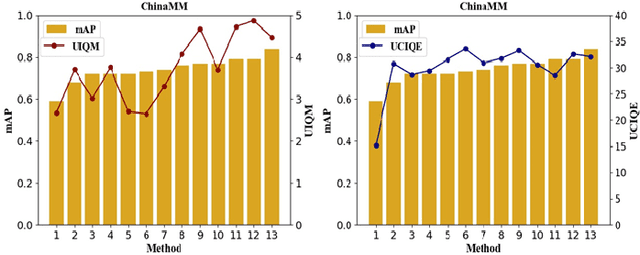
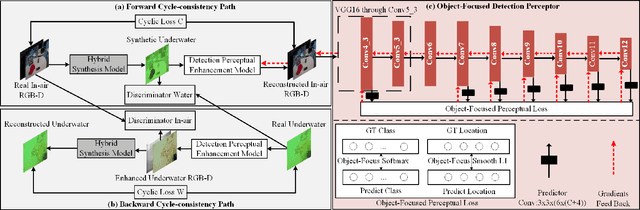
Underwater image enhancement, as a pre-processing step to improve the accuracy of the following object detection task, has drawn considerable attention in the field of underwater navigation and ocean exploration. However, most of the existing underwater image enhancement strategies tend to consider enhancement and detection as two independent modules with no interaction, and the practice of separate optimization does not always help the underwater object detection task. In this paper, we propose two perceptual enhancement models, each of which uses a deep enhancement model with a detection perceptor. The detection perceptor provides coherent information in the form of gradients to the enhancement model, guiding the enhancement model to generate patch level visually pleasing images or detection favourable images. In addition, due to the lack of training data, a hybrid underwater image synthesis model, which fuses physical priors and data-driven cues, is proposed to synthesize training data and generalise our enhancement model for real-world underwater images. Experimental results show the superiority of our proposed method over several state-of-the-art methods on both real-world and synthetic underwater datasets.
Incremental Meta-Learning via Episodic Replay Distillation for Few-Shot Image Recognition
Nov 11, 2021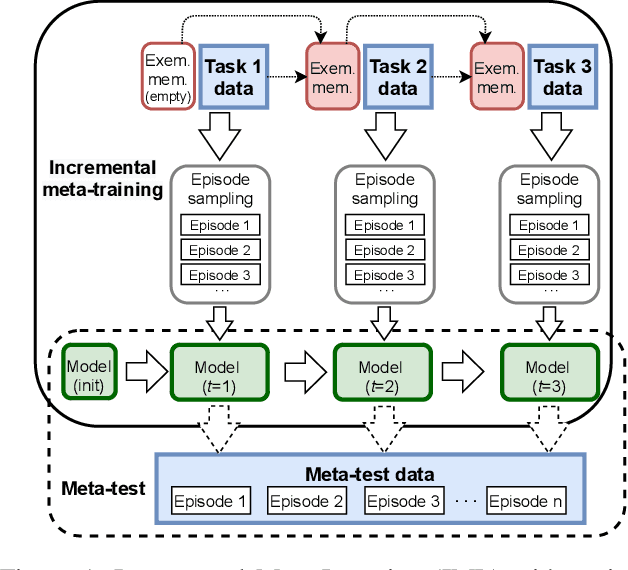
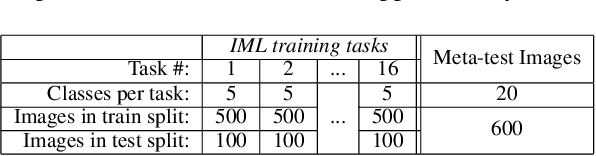
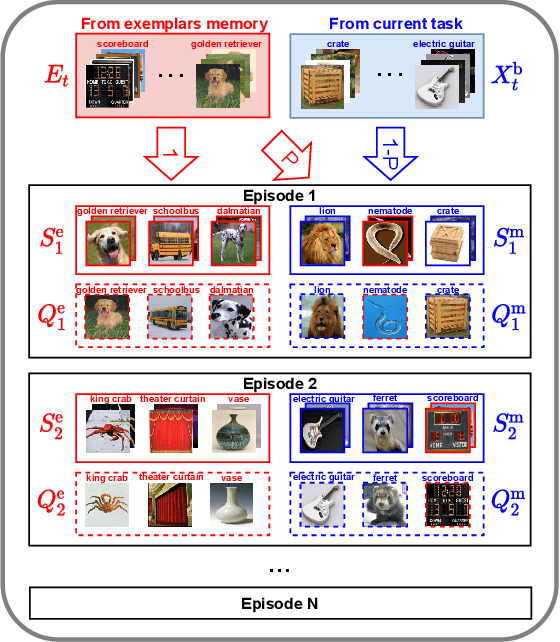
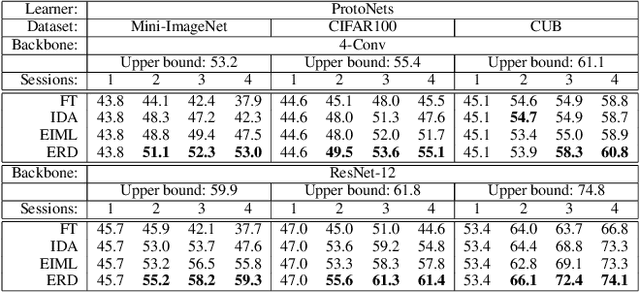
Most meta-learning approaches assume the existence of a very large set of labeled data available for episodic meta-learning of base knowledge. This contrasts with the more realistic continual learning paradigm in which data arrives incrementally in the form of tasks containing disjoint classes. In this paper we consider this problem of Incremental Meta-Learning (IML) in which classes are presented incrementally in discrete tasks. We propose an approach to IML, which we call Episodic Replay Distillation (ERD), that mixes classes from the current task with class exemplars from previous tasks when sampling episodes for meta-learning. These episodes are then used for knowledge distillation to minimize catastrophic forgetting. Experiments on four datasets demonstrate that ERD surpasses the state-of-the-art. In particular, on the more challenging one-shot, long task sequence incremental meta-learning scenarios, we reduce the gap between IML and the joint-training upper bound from 3.5% / 10.1% / 13.4% with the current state-of-the-art to 2.6% / 2.9% / 5.0% with our method on Tiered-ImageNet / Mini-ImageNet / CIFAR100, respectively.
Enhanced Frame and Event-Based Simulator and Event-Based Video Interpolation Network
Dec 17, 2021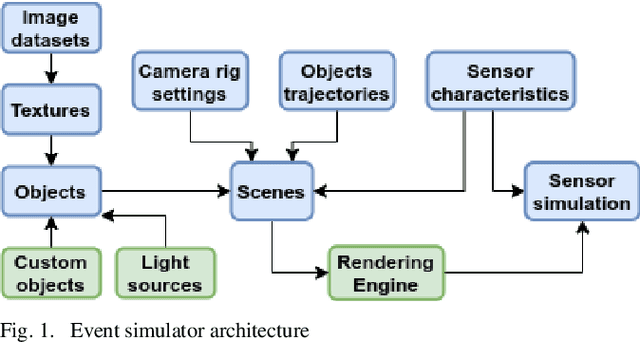
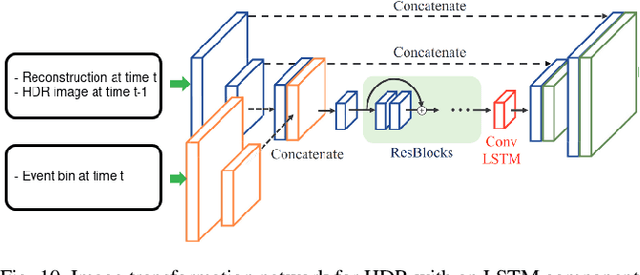
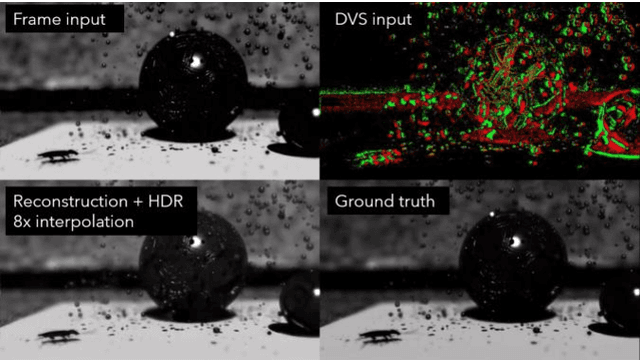

Fast neuromorphic event-based vision sensors (Dynamic Vision Sensor, DVS) can be combined with slower conventional frame-based sensors to enable higher-quality inter-frame interpolation than traditional methods relying on fixed motion approximations using e.g. optical flow. In this work we present a new, advanced event simulator that can produce realistic scenes recorded by a camera rig with an arbitrary number of sensors located at fixed offsets. It includes a new configurable frame-based image sensor model with realistic image quality reduction effects, and an extended DVS model with more accurate characteristics. We use our simulator to train a novel reconstruction model designed for end-to-end reconstruction of high-fps video. Unlike previously published methods, our method does not require the frame and DVS cameras to have the same optics, positions, or camera resolutions. It is also not limited to objects a fixed distance from the sensor. We show that data generated by our simulator can be used to train our new model, leading to reconstructed images on public datasets of equivalent or better quality than the state of the art. We also show our sensor generalizing to data recorded by real sensors.
Unsupervised Real Image Super-Resolution via Generative Variational AutoEncoder
Apr 27, 2020
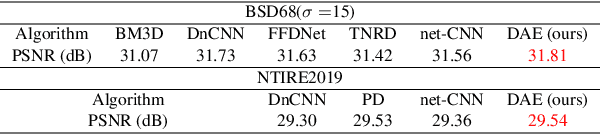
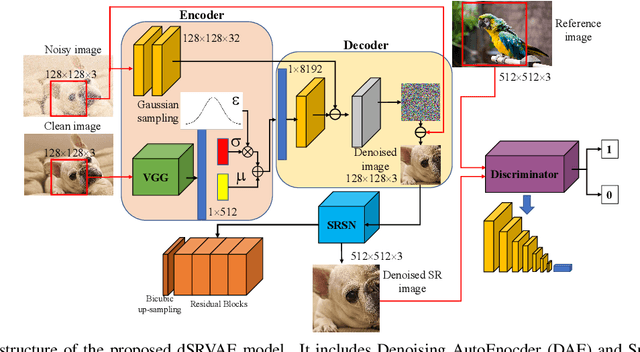
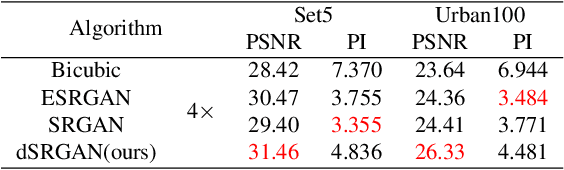
Benefited from the deep learning, image Super-Resolution has been one of the most developing research fields in computer vision. Depending upon whether using a discriminator or not, a deep convolutional neural network can provide an image with high fidelity or better perceptual quality. Due to the lack of ground truth images in real life, people prefer a photo-realistic image with low fidelity to a blurry image with high fidelity. In this paper, we revisit the classic example based image super-resolution approaches and come up with a novel generative model for perceptual image super-resolution. Given that real images contain various noise and artifacts, we propose a joint image denoising and super-resolution model via Variational AutoEncoder. We come up with a conditional variational autoencoder to encode the reference for dense feature vector which can then be transferred to the decoder for target image denoising. With the aid of the discriminator, an additional overhead of super-resolution subnetwork is attached to super-resolve the denoised image with photo-realistic visual quality. We participated the NTIRE2020 Real Image Super-Resolution Challenge. Experimental results show that by using the proposed approach, we can obtain enlarged images with clean and pleasant features compared to other supervised methods. We also compared our approach with state-of-the-art methods on various datasets to demonstrate the efficiency of our proposed unsupervised super-resolution model.
* 9 pages, 7 figures, CVPR2020 NTIRE2020 Real Image Super-Resolution Challenge
Lattice Fusion Networks for Image Denoising
Nov 28, 2020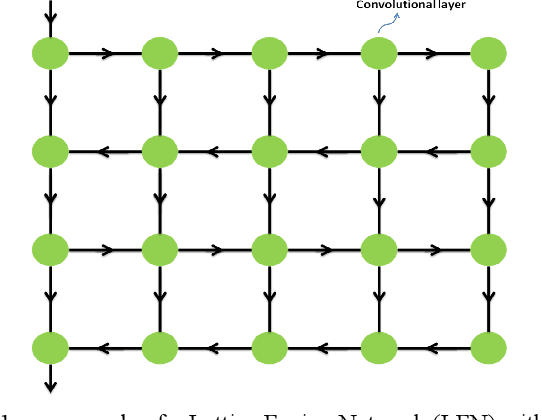

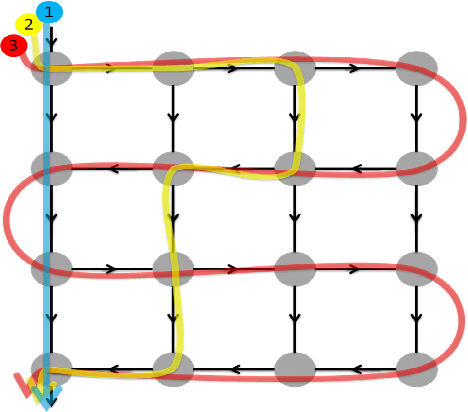
A novel method for feature fusion in convolutional neural networks is proposed in this work. Different feature fusion techniques are suggested to facilitate the flow of information and improve the training of deep neural networks. Some of these techniques as well as the proposed model can be considered a type of Directed Acyclic Graph (DAG) Network, where a layer can receive inputs from other layers and have outputs to other layers. In the proposed general framework of Lattice Fusion Network (LFN), feature maps of each convolutional layer are passed to other layers based on a lattice graph structure, where nodes are convolutional layers. To investigate the performance of the model, a specific design based on the general framework of LFN is implemented for image denoising. Results are compared with state of the art methods. The proposed model produced competitive results with far fewer learnable parameters, which shows the effectiveness of LFNs for training of deep neural networks
Wise-SrNet: A Novel Architecture for Enhancing Image Classification by Learning Spatial Resolution of Feature Maps
Apr 26, 2021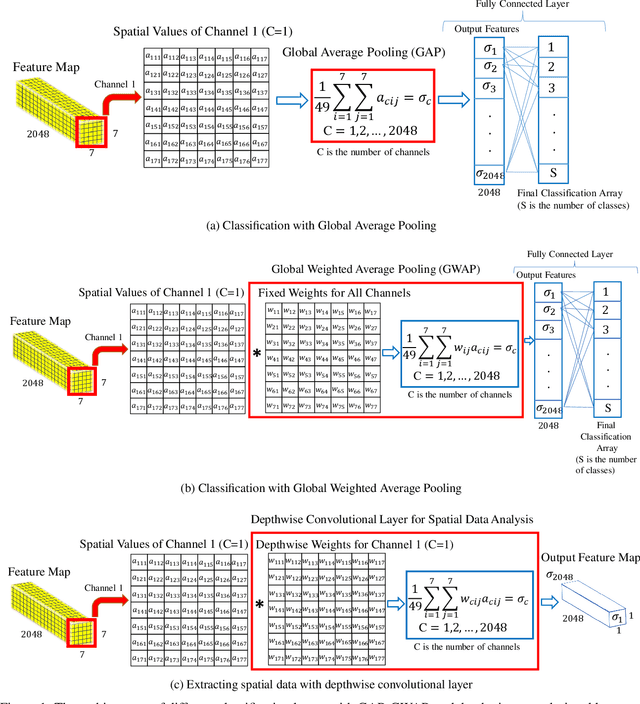
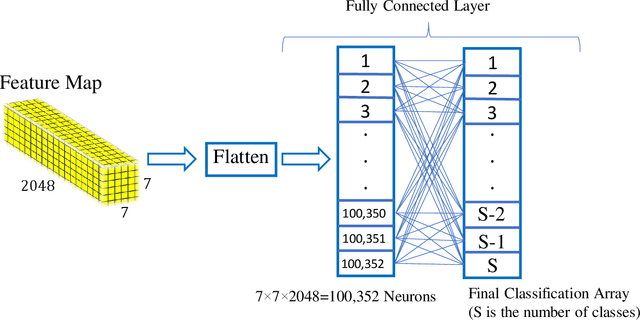

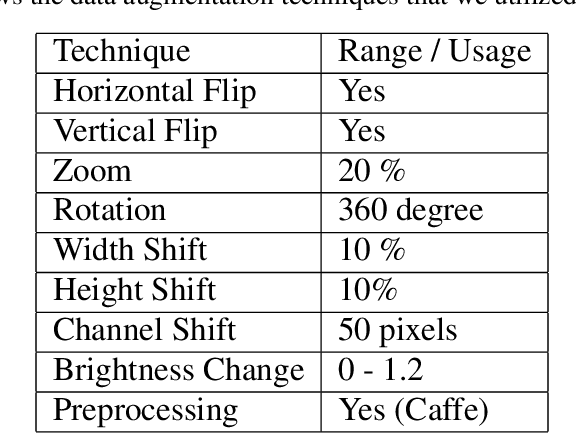
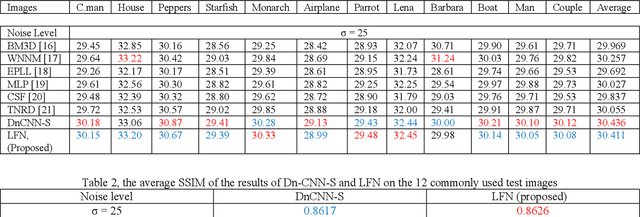
One of the main challenges since the advancement of convolutional neural networks is how to connect the extracted feature map to the final classification layer. VGG models used two sets of fully connected layers for the classification part of their architectures, which significantly increases the number of models' weights. ResNet and next deep convolutional models used the Global Average Pooling (GAP) layer to compress the feature map and feed it to the classification layer. Although using the GAP layer reduces the computational cost, but also causes losing spatial resolution of the feature map, which results in decreasing learning efficiency. In this paper, we aim to tackle this problem by replacing the GAP layer with a new architecture called Wise-SrNet. It is inspired by the depthwise convolutional idea and is designed for processing spatial resolution and also not increasing computational cost. We have evaluated our method using three different datasets: Intel Image Classification Challenge, MIT Indoors Scenes, and a part of the ImageNet dataset. We investigated the implementation of our architecture on several models of Inception, ResNet and DensNet families. Applying our architecture has revealed a significant effect on increasing convergence speed and accuracy. Our Experiments on images with 224x224 resolution increased the Top-1 accuracy between 2% to 8% on different datasets and models. Running our models on 512x512 resolution images of the MIT Indoors Scenes dataset showed a notable result of improving the Top-1 accuracy within 3% to 26%. We will also demonstrate the GAP layer's disadvantage when the input images are large and the number of classes is not few. In this circumstance, our proposed architecture can do a great help in enhancing classification results. The code is shared at https://github.com/mr7495/image-classification-spatial.
Generalisable Cardiac Structure Segmentation via Attentional and Stacked Image Adaptation
Sep 15, 2020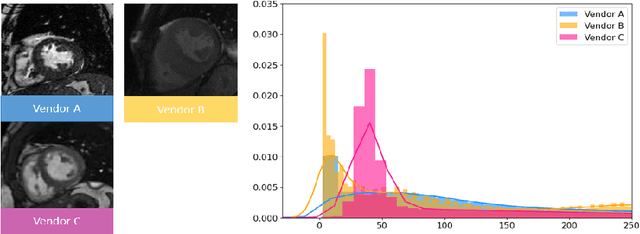

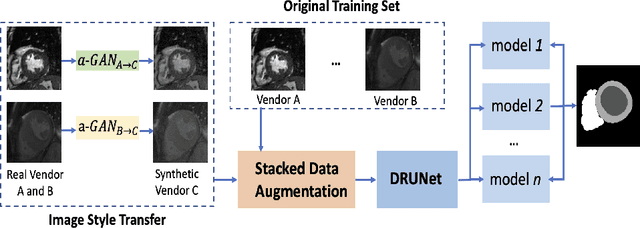

Tackling domain shifts in multi-centre and multi-vendor data sets remains challenging for cardiac image segmentation. In this paper, we propose a generalisable segmentation framework for cardiac image segmentation in which multi-centre, multi-vendor, multi-disease datasets are involved. A generative adversarial networks with an attention loss was proposed to translate the images from existing source domains to a target domain, thus to generate good-quality synthetic cardiac structure and enlarge the training set. A stack of data augmentation techniques was further used to simulate real-world transformation to boost the segmentation performance for unseen domains.We achieved an average Dice score of 90.3% for the left ventricle, 85.9% for the myocardium, and 86.5% for the right ventricle on the hidden validation set across four vendors. We show that the domain shifts in heterogeneous cardiac imaging datasets can be drastically reduced by two aspects: 1) good-quality synthetic data by learning the underlying target domain distribution, and 2) stacked classical image processing techniques for data augmentation.