 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pose Randomization for Weakly Paired Image Style Translation
Oct 31, 2020

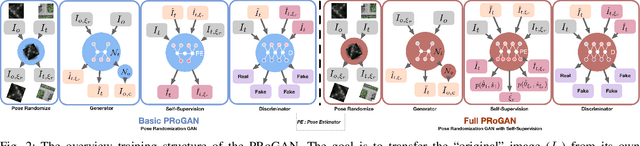


Utilizing the trained model under different conditions without data annotation is attractive for robot applications. Towards this goal, one class of methods is to translate the image style from the training environment to the current one. Conventional studies on image style translation mainly focus on two settings: paired data on images from two domains with exactly aligned content, and unpaired data, with independent content. In this paper, we would like to propose a new setting, where the content in the two images is aligned with error in poses. We consider that this setting is more practical since robots with various sensors are able to align the data up to some error level, even with different styles. To solve this problem, we propose PRoGAN to learn a style translator by intentionally transforming the original domain images with a noisy pose, then matching the distribution of translated transformed images and the distribution of the target domain images. The adversarial training enforces the network to learn the style translation, avoiding being entangled with other variations. In addition, we propose two pose estimation based self-supervised tasks to further improve the performance. Finally, PRoGAN is validated on both simulated and real-world collected data to show the effectiveness. Results on down-stream tasks, classification, road segmentation, object detection, and feature matching show its potential for real applications. https://github.com/wrld/PRoGAN .
Towards better understanding and better generalization of few-shot classification in histology images with contrastive learning
Feb 18, 2022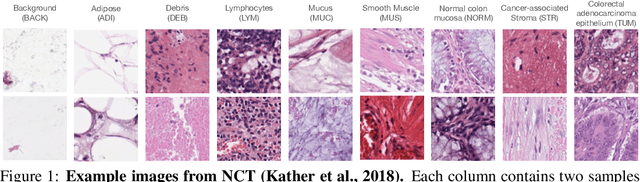
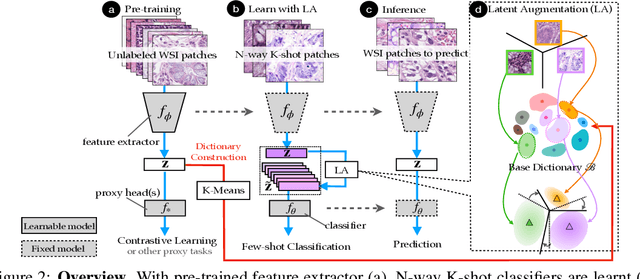

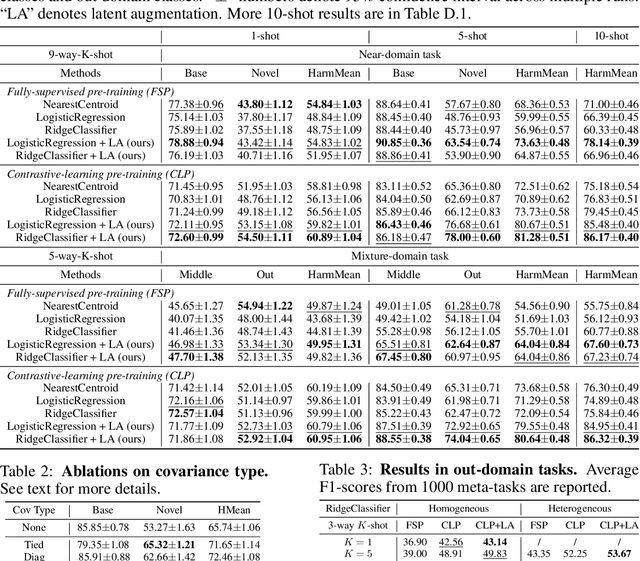
Few-shot learning is an established topic in natural images for years, but few work is attended to histology images, which is of high clinical value since well-labeled datasets and rare abnormal samples are expensive to collect. Here, we facilitate the study of few-shot learning in histology images by setting up three cross-domain tasks that simulate real clinics problems. To enable label-efficient learning and better generalizability, we propose to incorporate contrastive learning (CL) with latent augmentation (LA) to build a few-shot system. CL learns useful representations without manual labels, while LA transfers semantic variations of the base dataset in an unsupervised way. These two components fully exploit unlabeled training data and can scale gracefully to other label-hungry problems. In experiments, we find i) models learned by CL generalize better than supervised learning for histology images in unseen classes, and ii) LA brings consistent gains over baselines. Prior studies of self-supervised learning mainly focus on ImageNet-like images, which only present a dominant object in their centers. Recent attention has been paid to images with multi-objects and multi-textures. Histology images are a natural choice for such a study. We show the superiority of CL over supervised learning in terms of generalization for such data and provide our empirical understanding for this observation. The findings in this work could contribute to understanding how the model generalizes in the context of both representation learning and histological image analysis. Code is available.
Pose Guided Person Image Generation with Hidden p-Norm Regression
Feb 19, 2021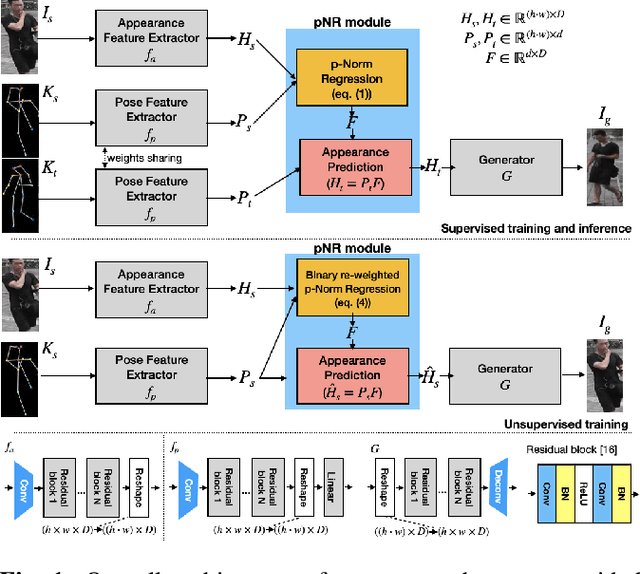
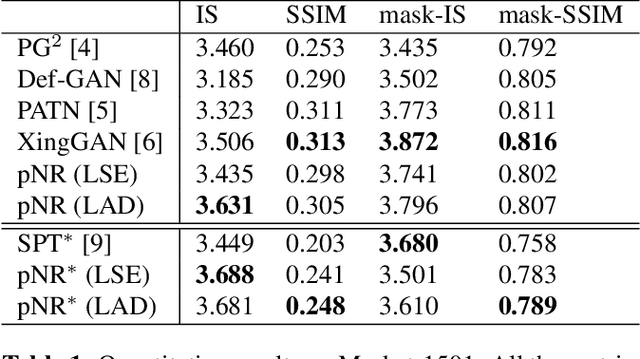

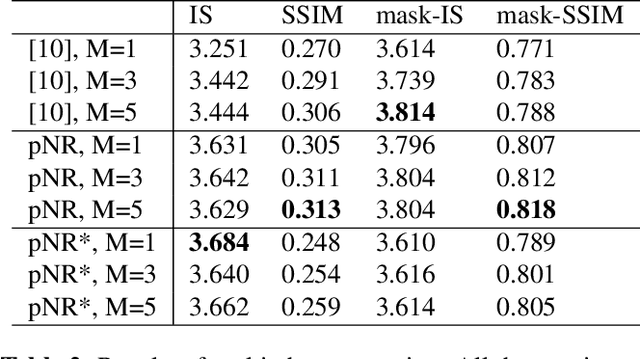
In this paper, we propose a novel approach to solve the pose guided person image generation task. We assume that the relation between pose and appearance information can be described by a simple matrix operation in hidden space. Based on this assumption, our method estimates a pose-invariant feature matrix for each identity, and uses it to predict the target appearance conditioned on the target pose. The estimation process is formulated as a p-norm regression problem in hidden space. By utilizing the differentiation of the solution of this regression problem, the parameters of the whole framework can be trained in an end-to-end manner. While most previous works are only applicable to the supervised training and single-shot generation scenario, our method can be easily adapted to unsupervised training and multi-shot generation. Extensive experiments on the challenging Market-1501 dataset show that our method yields competitive performance in all the aforementioned variant scenarios.
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds
Dec 14, 2021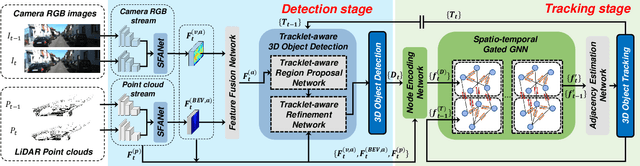

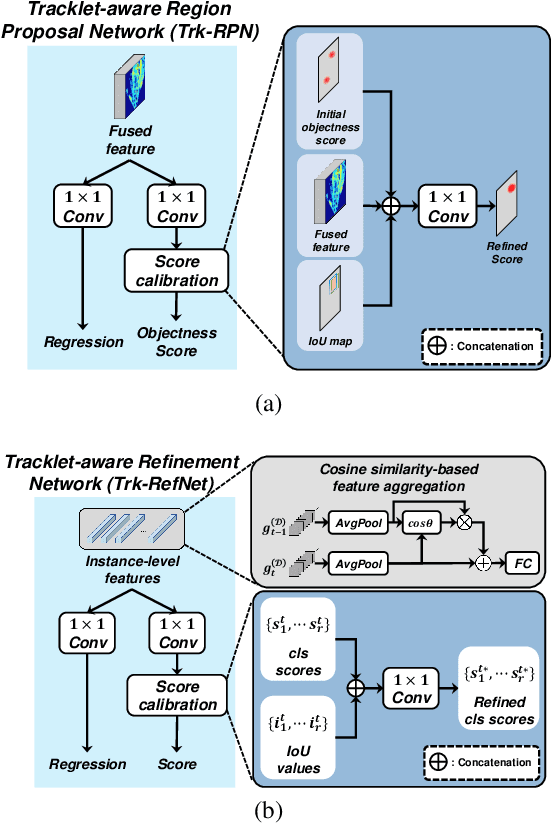

In this paper, we propose a new joint object detection and tracking (JoDT) framework for 3D object detection and tracking based on camera and LiDAR sensors. The proposed method, referred to as 3D DetecTrack, enables the detector and tracker to cooperate to generate a spatio-temporal representation of the camera and LiDAR data, with which 3D object detection and tracking are then performed. The detector constructs the spatio-temporal features via the weighted temporal aggregation of the spatial features obtained by the camera and LiDAR fusion. Then, the detector reconfigures the initial detection results using information from the tracklets maintained up to the previous time step. Based on the spatio-temporal features generated by the detector, the tracker associates the detected objects with previously tracked objects using a graph neural network (GNN). We devise a fully-connected GNN facilitated by a combination of rule-based edge pruning and attention-based edge gating, which exploits both spatial and temporal object contexts to improve tracking performance. The experiments conducted on both KITTI and nuScenes benchmarks demonstrate that the proposed 3D DetecTrack achieves significant improvements in both detection and tracking performances over baseline methods and achieves state-of-the-art performance among existing methods through collaboration between the detector and tracker.
TinyM$^2$Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices
Feb 09, 2022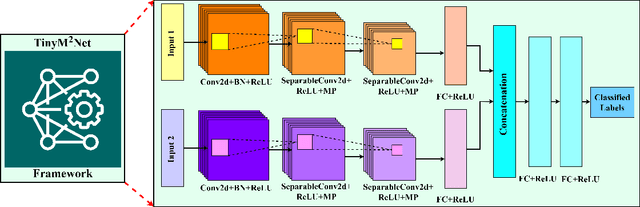


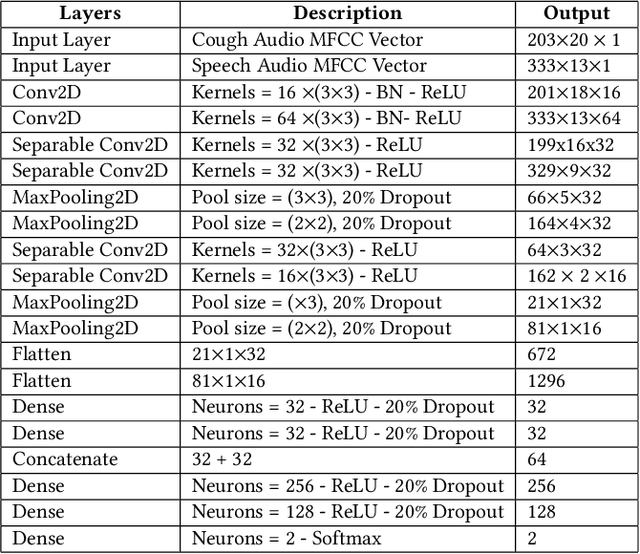
With the emergence of Artificial Intelligence (AI), new attention has been given to implement AI algorithms on resource constrained tiny devices to expand the application domain of IoT. Multimodal Learning has recently become very popular with the classification task due to its impressive performance for both image and audio event classification. This paper presents TinyM$^2$Net -- a flexible system algorithm co-designed multimodal learning framework for resource constrained tiny devices. The framework was designed to be evaluated on two different case-studies: COVID-19 detection from multimodal audio recordings and battle field object detection from multimodal images and audios. In order to compress the model to implement on tiny devices, substantial network architecture optimization and mixed precision quantization were performed (mixed 8-bit and 4-bit). TinyM$^2$Net shows that even a tiny multimodal learning model can improve the classification performance than that of any unimodal frameworks. The most compressed TinyM$^2$Net achieves 88.4% COVID-19 detection accuracy (14.5% improvement from unimodal base model) and 96.8\% battle field object detection accuracy (3.9% improvement from unimodal base model). Finally, we test our TinyM$^2$Net models on a Raspberry Pi 4 to see how they perform when deployed to a resource constrained tiny device.
ADOP: Approximate Differentiable One-Pixel Point Rendering
Oct 13, 2021



We present a novel point-based, differentiable neural rendering pipeline for scene refinement and novel view synthesis. The input are an initial estimate of the point cloud and the camera parameters. The output are synthesized images from arbitrary camera poses. The point cloud rendering is performed by a differentiable renderer using multi-resolution one-pixel point rasterization. Spatial gradients of the discrete rasterization are approximated by the novel concept of ghost geometry. After rendering, the neural image pyramid is passed through a deep neural network for shading calculations and hole-filling. A differentiable, physically-based tonemapper then converts the intermediate output to the target image. Since all stages of the pipeline are differentiable, we optimize all of the scene's parameters i.e. camera model, camera pose, point position, point color, environment map, rendering network weights, vignetting, camera response function, per image exposure, and per image white balance. We show that our system is able to synthesize sharper and more consistent novel views than existing approaches because the initial reconstruction is refined during training. The efficient one-pixel point rasterization allows us to use arbitrary camera models and display scenes with well over 100M points in real time.
Auto-Transfer: Learning to Route Transferrable Representations
Feb 04, 2022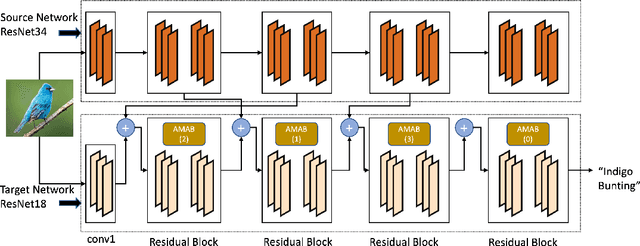
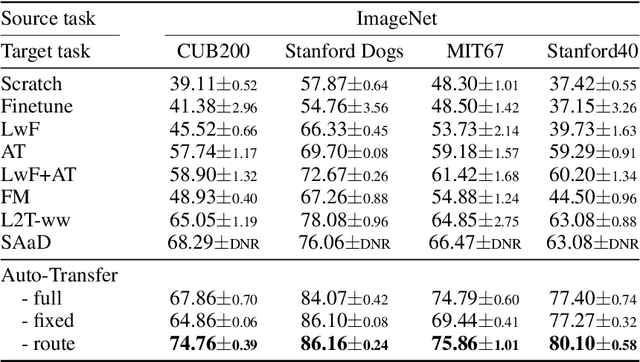
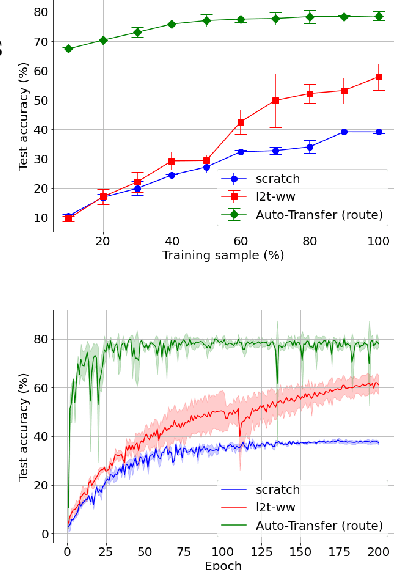

Knowledge transfer between heterogeneous source and target networks and tasks has received a lot of attention in recent times as large amounts of quality labelled data can be difficult to obtain in many applications. Existing approaches typically constrain the target deep neural network (DNN) feature representations to be close to the source DNNs feature representations, which can be limiting. We, in this paper, propose a novel adversarial multi-armed bandit approach which automatically learns to route source representations to appropriate target representations following which they are combined in meaningful ways to produce accurate target models. We see upwards of 5% accuracy improvements compared with the state-of-the-art knowledge transfer methods on four benchmark (target) image datasets CUB200, Stanford Dogs, MIT67, and Stanford40 where the source dataset is ImageNet. We qualitatively analyze the goodness of our transfer scheme by showing individual examples of the important features our target network focuses on in different layers compared with the (closest) competitors. We also observe that our improvement over other methods is higher for smaller target datasets making it an effective tool for small data applications that may benefit from transfer learning.
Image Classification via Quantum Machine Learning
Nov 03, 2020

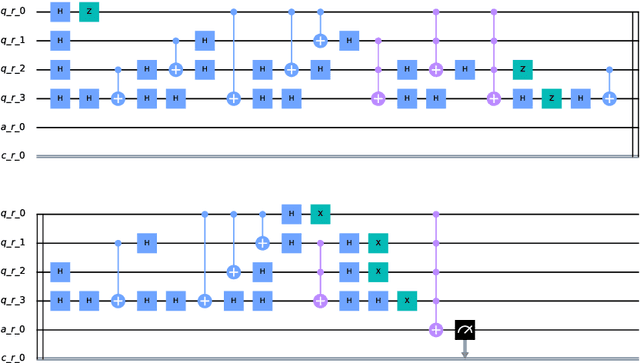
Quantum Computing and especially Quantum Machine Learning, in a short period of time, has gained a lot of interest through research groups around the world. This can be seen in the increasing number of proposed models for pattern classification applying quantum principles to a certain degree. Despise the increasing volume of models, there is a void in testing these models on real datasets and not only on synthetic ones. The objective of this work is to classify patterns with binary attributes using a quantum classifier. Specially, we show results of a complete quantum classifier applied to image datasets. The experiments show favorable output while dealing with balanced classification problems as well as with imbalanced classes where the minority class is the most relevant. This is promising in medical areas, where usually the important class is also the minority class.
Separating Sounds from a Single Image
Jul 15, 2020
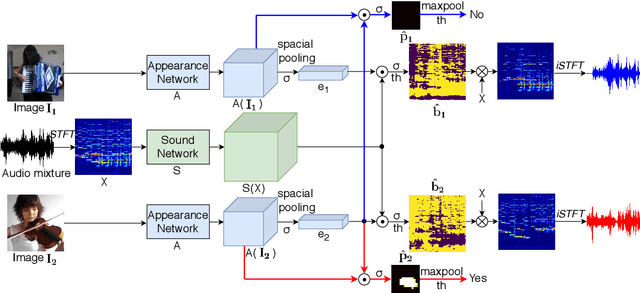
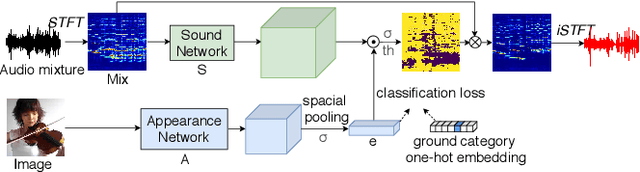
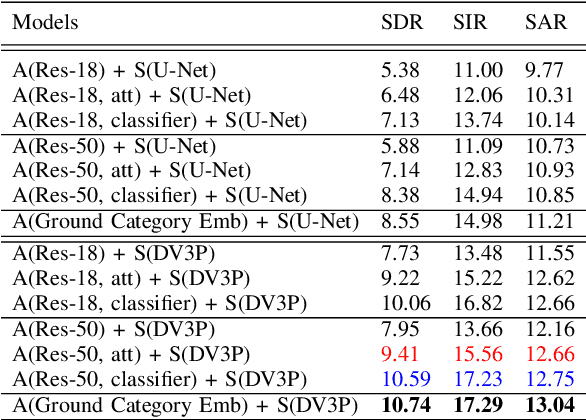
Recently, visual information has been widely used to aid the sound source separation tasks. It aims at identifying sound components from a given sound mixture with the presence of visual information. Especially, the appearance cues play an important role on separating sounds. However, the capacity of how well the network processes each modality is often ignored. In this paper, we investigate the performance of appearance information, extracted from a single image, in the task of recovering the original component signals from a mixture audio. An efficient appearance attention module is introduced to improve the sound separation performance by enhancing the distinction of the predicted semantic representations, and to precisely locate sound sources without extra computation. Moreover, we utilize the ground category information to study the capacity of each sub-network. We compare the proposed methods with recent baselines on the MUSIC dataset. Project page: https://ly-zhu.github.io/separating-sounds-from-single-image
Semantic-aware Image Deblurring
Oct 09, 2019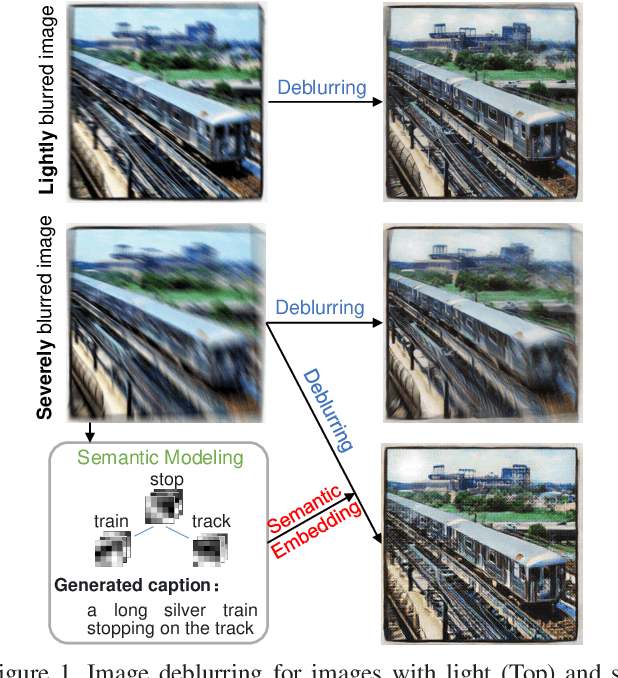

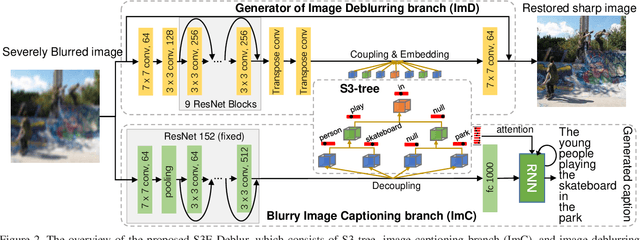

Image deblurring has achieved exciting progress in recent years. However, traditional methods fail to deblur severely blurred images, where semantic contents appears ambiguously. In this paper, we conduct image deblurring guided by the semantic contents inferred from image captioning. Specially, we propose a novel Structured-Spatial Semantic Embedding model for image deblurring (termed S3E-Deblur), which introduces a novel Structured-Spatial Semantic tree model (S3-tree) to bridge two basic tasks in computer vision: image deblurring (ImD) and image captioning (ImC). In particular, S3-tree captures and represents the semantic contents in structured spatial features in ImC, and then embeds the spatial features of the tree nodes into GAN based ImD. Co-training on S3-tree, ImC, and ImD is conducted to optimize the overall model in a multi-task end-to-end manner. Extensive experiments on severely blurred MSCOCO and GoPro datasets demonstrate the significant superiority of S3E-Deblur compared to the state-of-the-arts on both ImD and ImC tasks.