 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
You Only Look Yourself: Unsupervised and Untrained Single Image Dehazing Neural Network
Jun 30, 2020

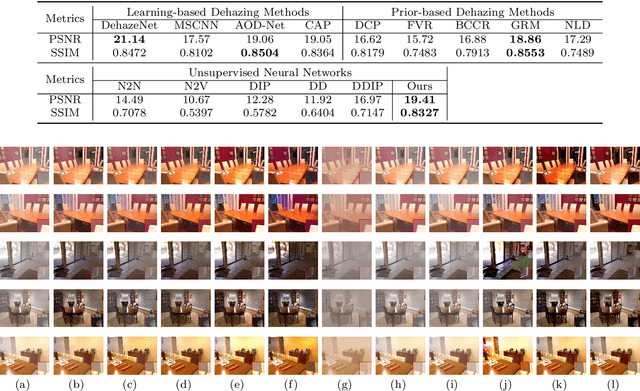
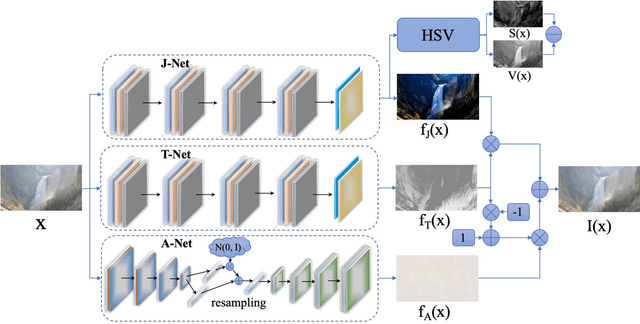
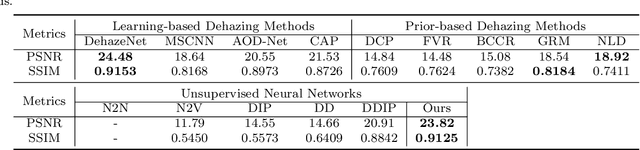
In this paper, we study two challenging and less-touched problems in single image dehazing, namely, how to make deep learning achieve image dehazing without training on the ground-truth clean image (unsupervised) and a image collection (untrained). An unsupervised neural network will avoid the intensive labor collection of hazy-clean image pairs, and an untrained model is a ``real'' single image dehazing approach which could remove haze based on only the observed hazy image itself and no extra images is used. Motivated by the layer disentanglement idea, we propose a novel method, called you only look yourself (\textbf{YOLY}) which could be one of the first unsupervised and untrained neural networks for image dehazing. In brief, YOLY employs three jointly subnetworks to separate the observed hazy image into several latent layers, \textit{i.e.}, scene radiance layer, transmission map layer, and atmospheric light layer. After that, these three layers are further composed to the hazy image in a self-supervised manner. Thanks to the unsupervised and untrained characteristics of YOLY, our method bypasses the conventional training paradigm of deep models on hazy-clean pairs or a large scale dataset, thus avoids the labor-intensive data collection and the domain shift issue. Besides, our method also provides an effective learning-based haze transfer solution thanks to its layer disentanglement mechanism. Extensive experiments show the promising performance of our method in image dehazing compared with 14 methods on four databases.
Auto-Transfer: Learning to Route Transferrable Representations
Feb 04, 2022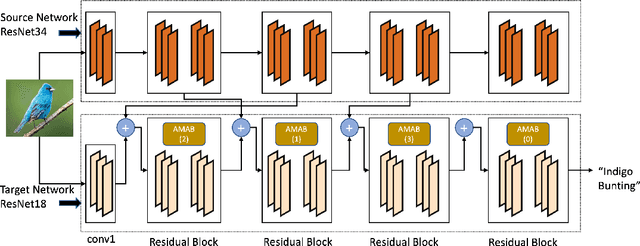
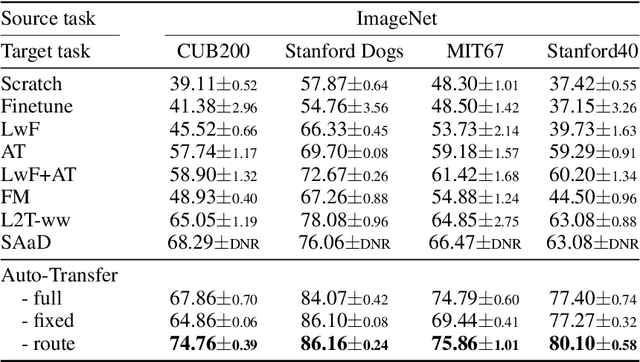
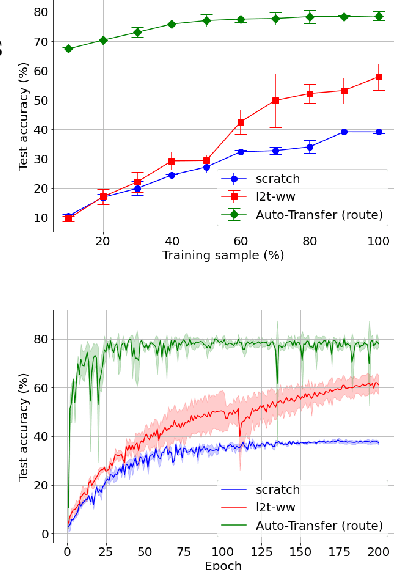

Knowledge transfer between heterogeneous source and target networks and tasks has received a lot of attention in recent times as large amounts of quality labelled data can be difficult to obtain in many applications. Existing approaches typically constrain the target deep neural network (DNN) feature representations to be close to the source DNNs feature representations, which can be limiting. We, in this paper, propose a novel adversarial multi-armed bandit approach which automatically learns to route source representations to appropriate target representations following which they are combined in meaningful ways to produce accurate target models. We see upwards of 5% accuracy improvements compared with the state-of-the-art knowledge transfer methods on four benchmark (target) image datasets CUB200, Stanford Dogs, MIT67, and Stanford40 where the source dataset is ImageNet. We qualitatively analyze the goodness of our transfer scheme by showing individual examples of the important features our target network focuses on in different layers compared with the (closest) competitors. We also observe that our improvement over other methods is higher for smaller target datasets making it an effective tool for small data applications that may benefit from transfer learning.
Dynamic Sampling Rate: Harnessing Frame Coherence in Graphics Applications for Energy-Efficient GPUs
Feb 21, 2022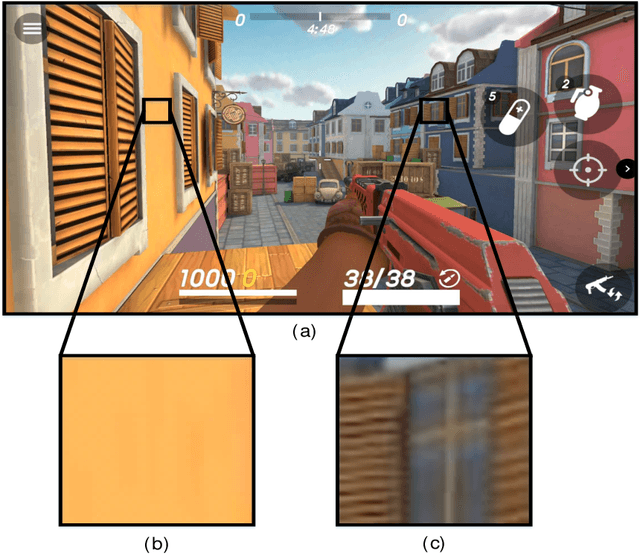
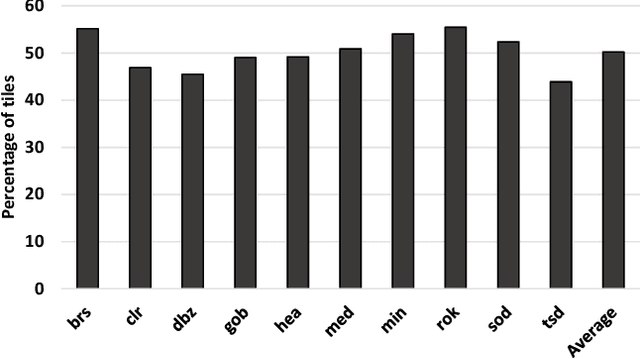
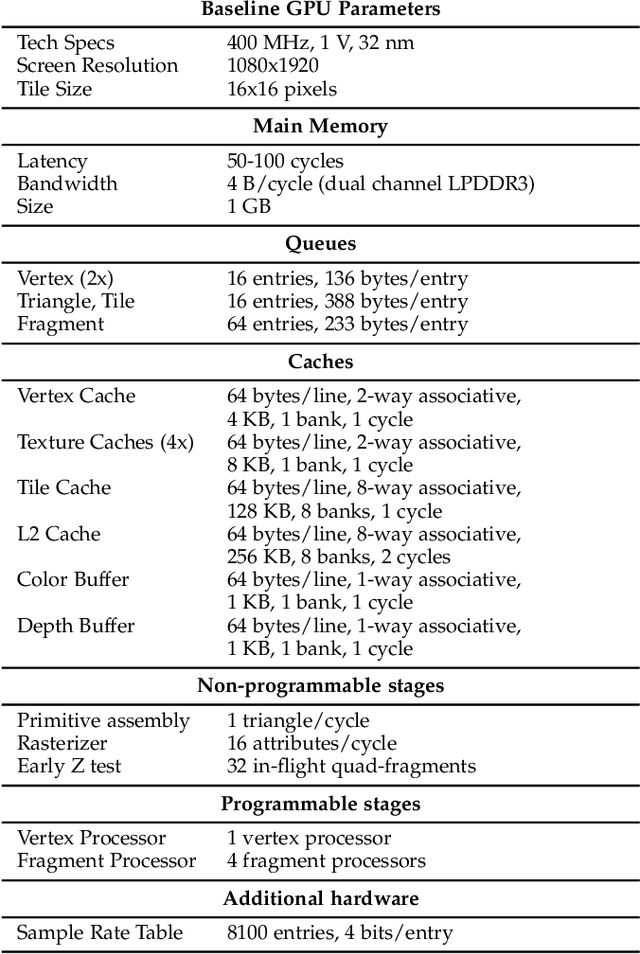
In real-time rendering, a 3D scene is modelled with meshes of triangles that the GPU projects to the screen. They are discretized by sampling each triangle at regular space intervals to generate fragments which are then added texture and lighting effects by a shader program. Realistic scenes require detailed geometric models, complex shaders, high-resolution displays and high screen refreshing rates, which all come at a great compute time and energy cost. This cost is often dominated by the fragment shader, which runs for each sampled fragment. Conventional GPUs sample the triangles once per pixel, however, there are many screen regions containing low variation that produce identical fragments and could be sampled at lower than pixel-rate with no loss in quality. Additionally, as temporal frame coherence makes consecutive frames very similar, such variations are usually maintained from frame to frame. This work proposes Dynamic Sampling Rate (DSR), a novel hardware mechanism to reduce redundancy and improve the energy efficiency in graphics applications. DSR analyzes the spatial frequencies of the scene once it has been rendered. Then, it leverages the temporal coherence in consecutive frames to decide, for each region of the screen, the lowest sampling rate to employ in the next frame that maintains image quality. We evaluate the performance of a state-of-the-art mobile GPU architecture extended with DSR for a wide variety of applications. Experimental results show that DSR is able to remove most of the redundancy inherent in the color computations at fragment granularity, which brings average speedups of 1.68x and energy savings of 40%.
Underwater Image Enhancement Based on Structure-Texture Reconstruction
Apr 11, 2020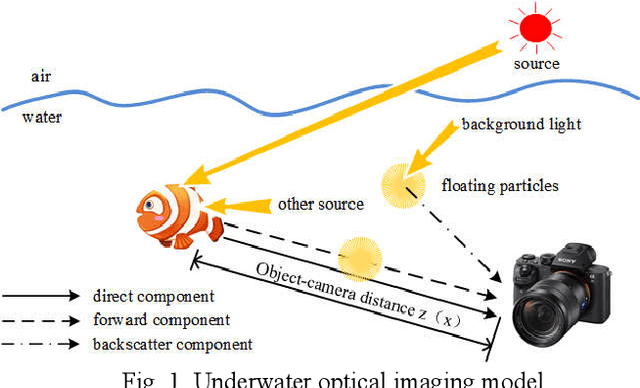

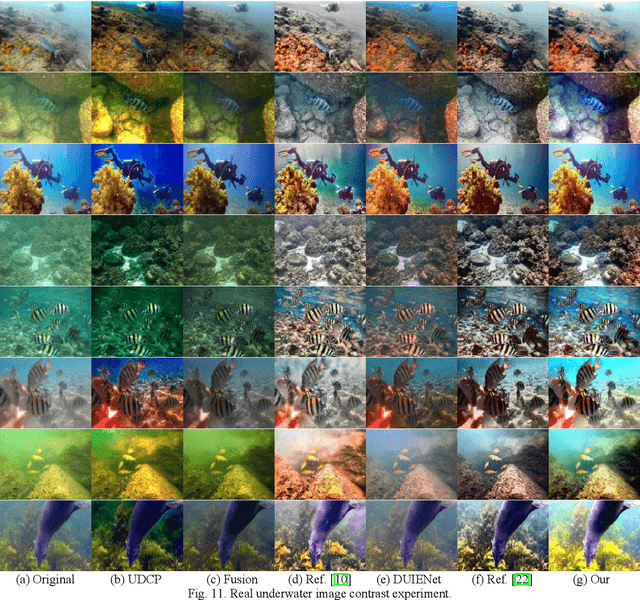

Aiming at the problems of color distortion, blur and excessive noise of underwater image, an underwater image enhancement algorithm based on structure-texture reconstruction is proposed. Firstly, the color equalization of the degraded image is realized by the automatic color enhancement algorithm; Secondly, the relative total variation is introduced to decompose the image into the structure layer and texture layer; Then, the best background light point is selected based on brightness, gradient discrimination, and hue judgment, the transmittance of the backscatter component is obtained by the red dark channel prior, which is substituted into the imaging model to remove the fogging phenomenon in the structure layer. Enhancement of effective details in the texture layer by multi scale detail enhancement algorithm and binary mask; Finally, the structure layer and texture layer are reconstructed to get the final image. The experimental results show that the algorithm can effectively balance the hue, saturation, and clarity of underwater image, and has good performance in different underwater environments.
UXNet: Searching Multi-level Feature Aggregation for 3D Medical Image Segmentation
Sep 16, 2020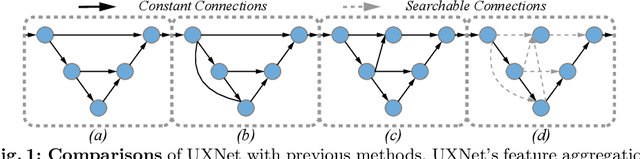
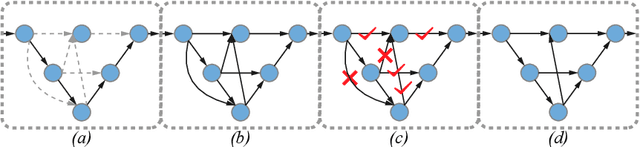
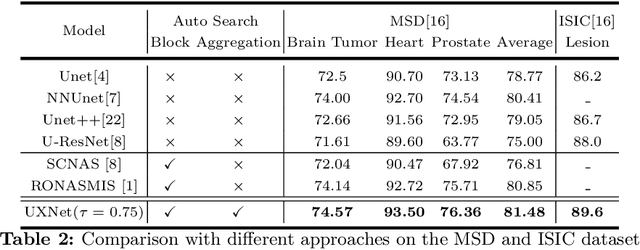
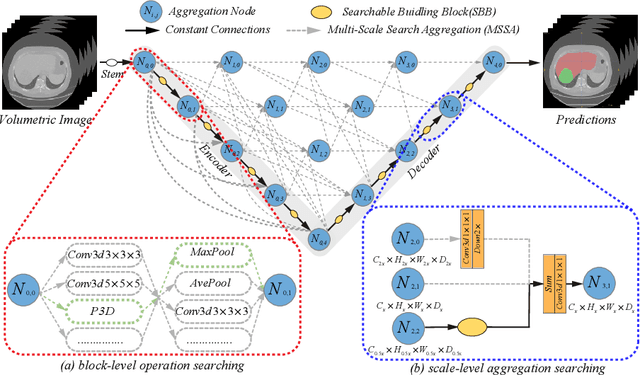
Aggregating multi-level feature representation plays a critical role in achieving robust volumetric medical image segmentation, which is important for the auxiliary diagnosis and treatment. Unlike the recent neural architecture search (NAS) methods that typically searched the optimal operators in each network layer, but missed a good strategy to search for feature aggregations, this paper proposes a novel NAS method for 3D medical image segmentation, named UXNet, which searches both the scale-wise feature aggregation strategies as well as the block-wise operators in the encoder-decoder network. UXNet has several appealing benefits. (1) It significantly improves flexibility of the classical UNet architecture, which only aggregates feature representations of encoder and decoder in equivalent resolution. (2) A continuous relaxation of UXNet is carefully designed, enabling its searching scheme performed in an efficient differentiable manner. (3) Extensive experiments demonstrate the effectiveness of UXNet compared with recent NAS methods for medical image segmentation. The architecture discovered by UXNet outperforms existing state-of-the-art models in terms of Dice on several public 3D medical image segmentation benchmarks, especially for the boundary locations and tiny tissues. The searching computational complexity of UXNet is cheap, enabling to search a network with the best performance less than 1.5 days on two TitanXP GPUs.
An Ultra Fast Low Power Convolutional Neural Network Image Sensor with Pixel-level Computing
Jan 09, 2021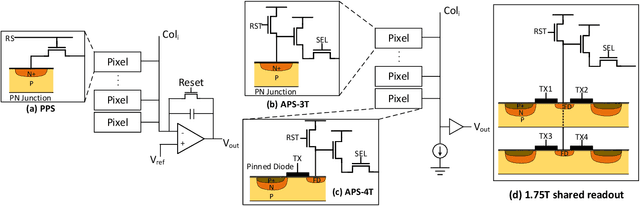
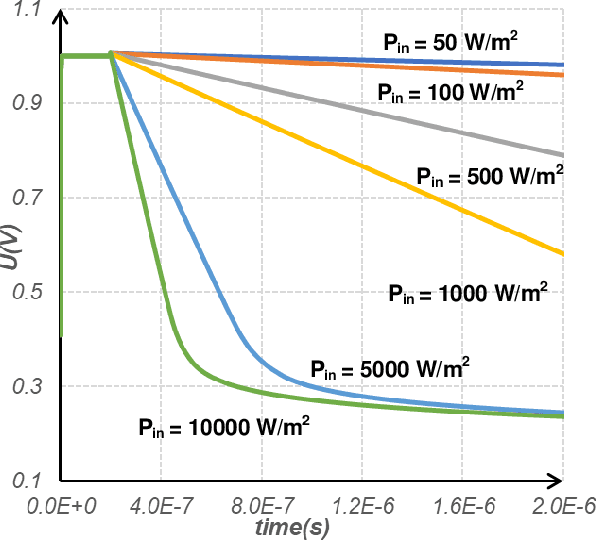
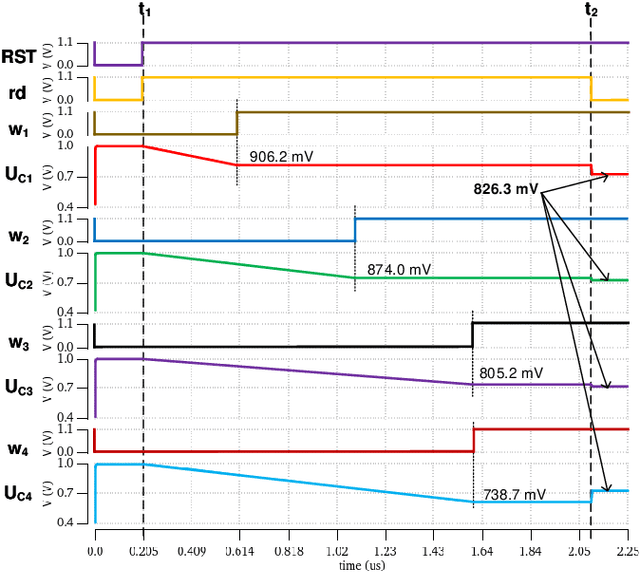
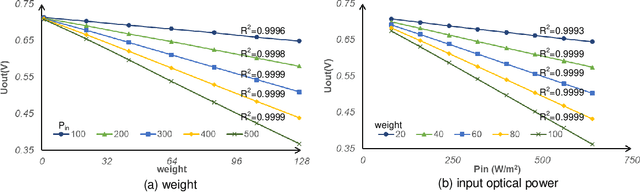
The separation of the data capture and analysis in modern vision systems has led to a massive amount of data transfer between the end devices and cloud computers, resulting in long latency, slow response, and high power consumption. Efficient hardware architectures are under focused development to enable Artificial Intelligence (AI) at the resource-limited end sensing devices. This paper proposes a Processing-In-Pixel (PIP) CMOS sensor architecture, which allows convolution operation before the column readout circuit to significantly improve the image reading speed with much lower power consumption. The simulation results show that the proposed architecture enables convolution operation (kernel size=3*3, stride=2, input channel=3, output channel=64) in a 1080P image sensor array with only 22.62 mW power consumption. In other words, the computational efficiency is 4.75 TOPS/w, which is about 3.6 times as higher as the state-of-the-art.
URIE: Universal Image Enhancement for Visual Recognition in the Wild
Jul 17, 2020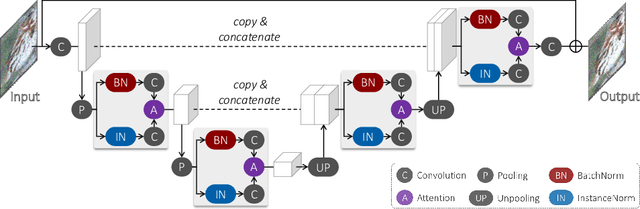

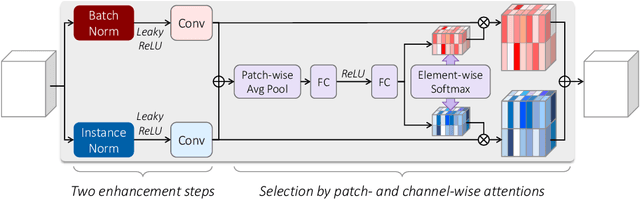

Despite the great advances in visual recognition, it has been witnessed that recognition models trained on clean images of common datasets are not robust against distorted images in the real world. To tackle this issue, we present a Universal and Recognition-friendly Image Enhancement network, dubbed URIE, which is attached in front of existing recognition models and enhances distorted input to improve their performance without retraining them. URIE is universal in that it aims to handle various factors of image degradation and to be incorporated with any arbitrary recognition models. Also, it is recognition-friendly since it is optimized to improve the robustness of following recognition models, instead of perceptual quality of output image. Our experiments demonstrate that URIE can handle various and latent image distortions and improve the performance of existing models for five diverse recognition tasks when input images are degraded.
Panoptic Segmentation Meets Remote Sensing
Nov 23, 2021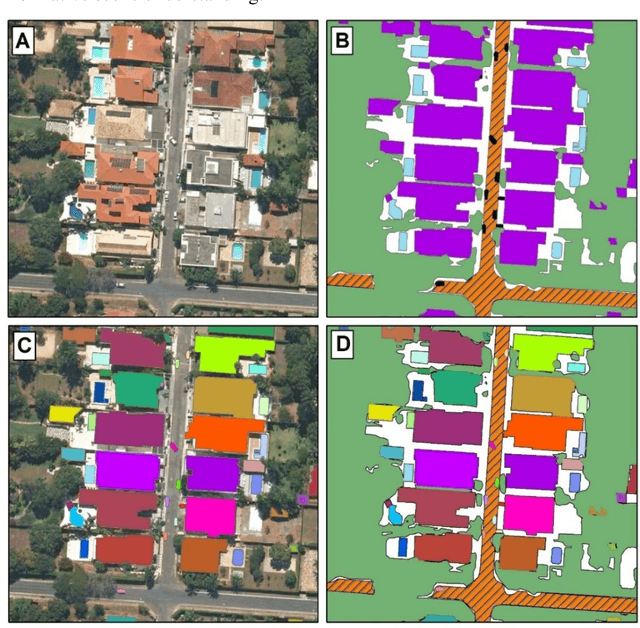
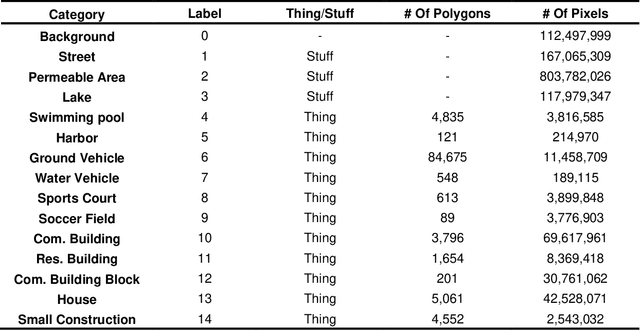
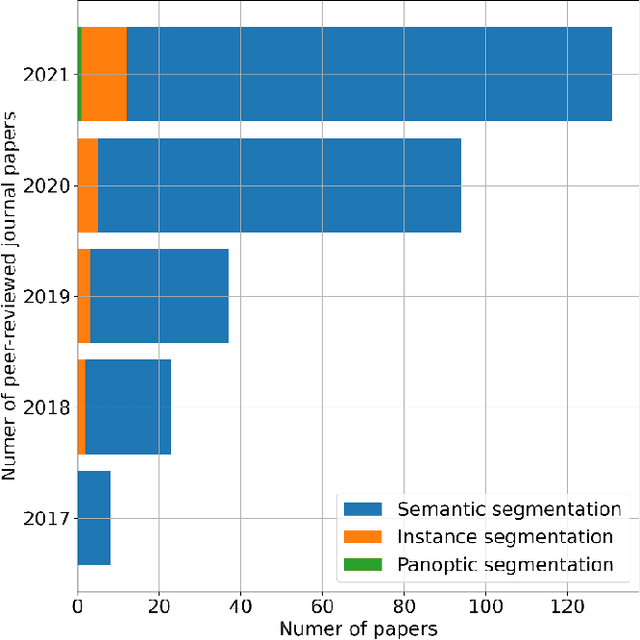

Panoptic segmentation combines instance and semantic predictions, allowing the detection of "things" and "stuff" simultaneously. Effectively approaching panoptic segmentation in remotely sensed data can be auspicious in many challenging problems since it allows continuous mapping and specific target counting. Several difficulties have prevented the growth of this task in remote sensing: (a) most algorithms are designed for traditional images, (b) image labelling must encompass "things" and "stuff" classes, and (c) the annotation format is complex. Thus, aiming to solve and increase the operability of panoptic segmentation in remote sensing, this study has five objectives: (1) create a novel data preparation pipeline for panoptic segmentation, (2) propose an annotation conversion software to generate panoptic annotations; (3) propose a novel dataset on urban areas, (4) modify the Detectron2 for the task, and (5) evaluate difficulties of this task in the urban setting. We used an aerial image with a 0,24-meter spatial resolution considering 14 classes. Our pipeline considers three image inputs, and the proposed software uses point shapefiles for creating samples in the COCO format. Our study generated 3,400 samples with 512x512 pixel dimensions. We used the Panoptic-FPN with two backbones (ResNet-50 and ResNet-101), and the model evaluation considered semantic instance and panoptic metrics. We obtained 93.9, 47.7, and 64.9 for the mean IoU, box AP, and PQ. Our study presents the first effective pipeline for panoptic segmentation and an extensive database for other researchers to use and deal with other data or related problems requiring a thorough scene understanding.
SketchyCOCO: Image Generation from Freehand Scene Sketches
Mar 31, 2020
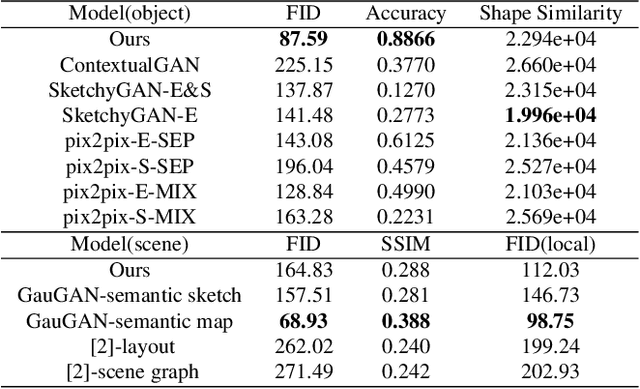
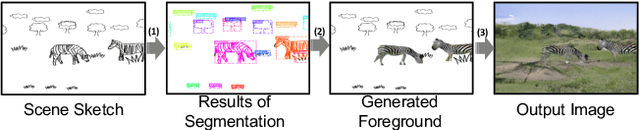
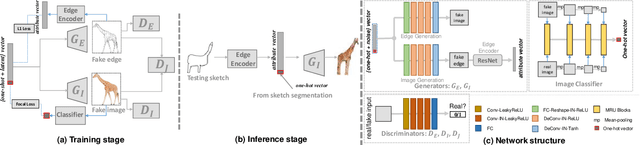
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged Generative Adversarial Network called EdgeGAN, which supports high visual-quality object-level image content generation without using freehand sketches as training data. We have built a large-scale composite dataset called SketchyCOCO to support and evaluate the solution. We validate our approach on the tasks of both object-level and scene-level image generation on SketchyCOCO. Through quantitative, qualitative results, human evaluation and ablation studies, we demonstrate the method's capacity to generate realistic complex scene-level images from various freehand sketches.
Low-Interception Waveform: To Prevent the Recognition of Spectrum Waveform Modulation via Adversarial Examples
Jan 20, 2022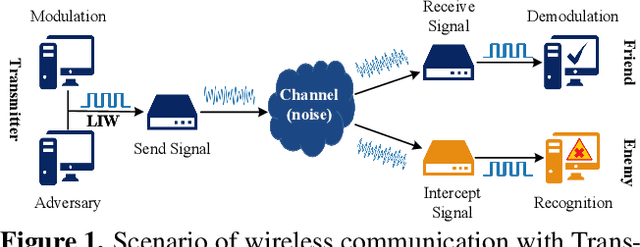
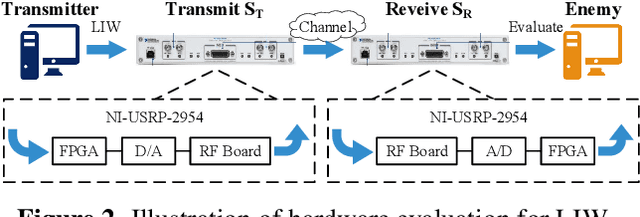
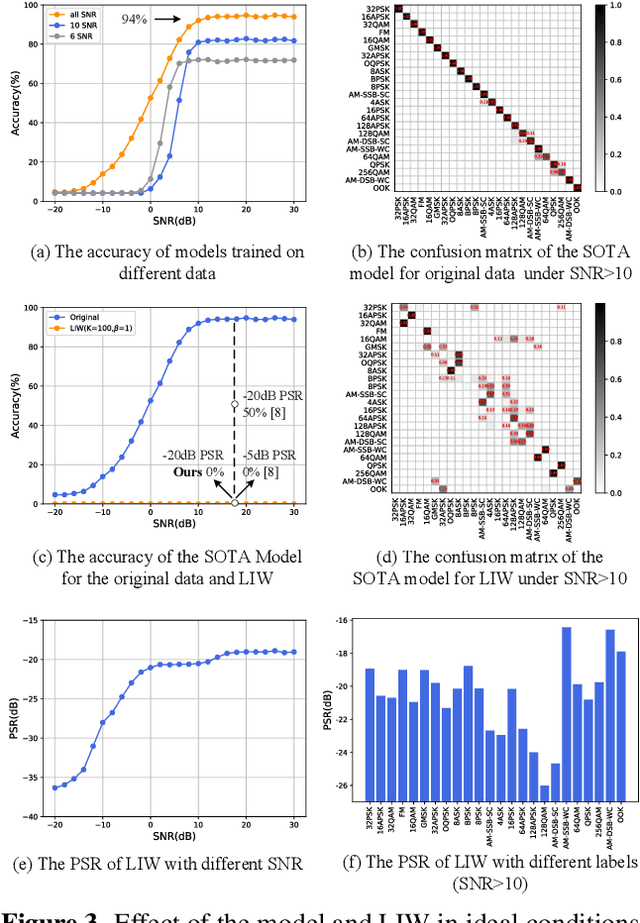
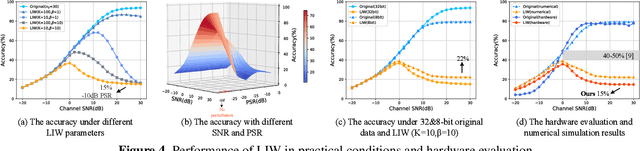
Deep learning is applied to many complex tasks in the field of wireless communication, such as modulation recognition of spectrum waveforms, because of its convenience and efficiency. This leads to the problem of a malicious third party using a deep learning model to easily recognize the modulation format of the transmitted waveform. Some existing works address this problem directly using the concept of adversarial examples in the image domain without fully considering the characteristics of the waveform transmission in the physical world. Therefore, we propose a low-intercept waveform~(LIW) generation method that can reduce the probability of the modulation being recognized by a third party without affecting the reliable communication of the friendly party. Our LIW exhibits significant low-interception performance even in the physical hardware experiment, decreasing the accuracy of the state of the art model to approximately $15\%$ with small perturbations.
* 4 pages, 4 figures, published in 2021 34th General Assembly and Scientific Symposium of the International Union of Radio Science, URSI GASS 2021