 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pose Guided Person Image Generation with Hidden p-Norm Regression
Feb 19, 2021
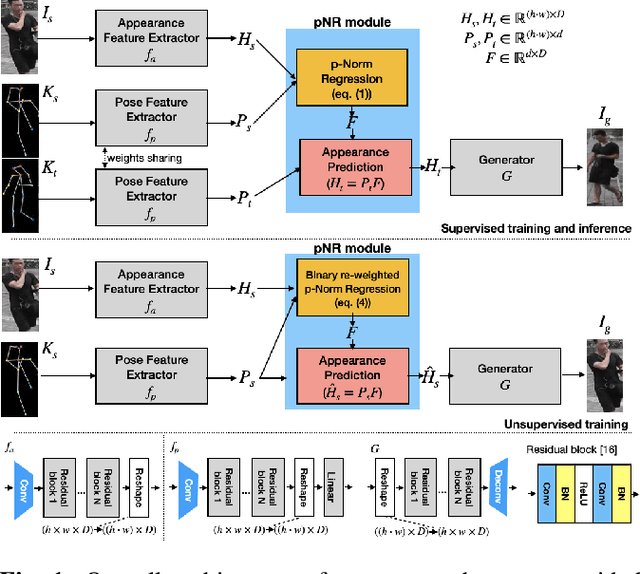
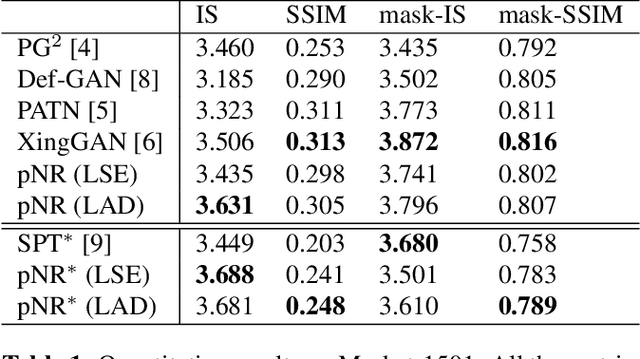

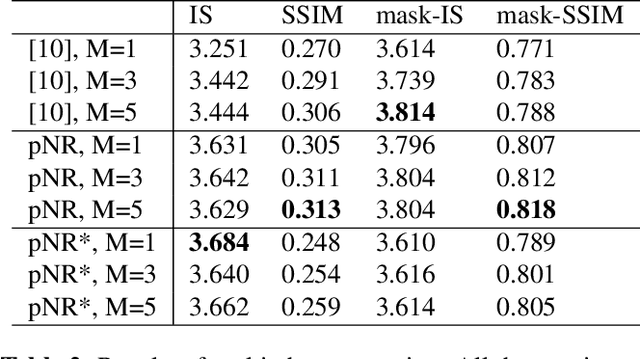
In this paper, we propose a novel approach to solve the pose guided person image generation task. We assume that the relation between pose and appearance information can be described by a simple matrix operation in hidden space. Based on this assumption, our method estimates a pose-invariant feature matrix for each identity, and uses it to predict the target appearance conditioned on the target pose. The estimation process is formulated as a p-norm regression problem in hidden space. By utilizing the differentiation of the solution of this regression problem, the parameters of the whole framework can be trained in an end-to-end manner. While most previous works are only applicable to the supervised training and single-shot generation scenario, our method can be easily adapted to unsupervised training and multi-shot generation. Extensive experiments on the challenging Market-1501 dataset show that our method yields competitive performance in all the aforementioned variant scenarios.
Detecting Human-to-Human-or-Object (H2O) Interactions with DIABOLO
Jan 07, 2022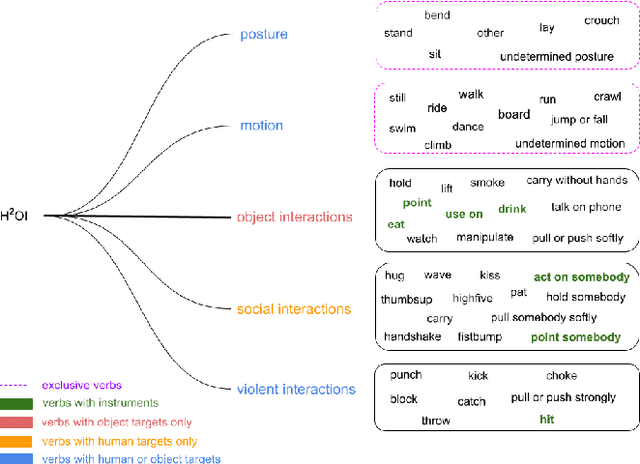

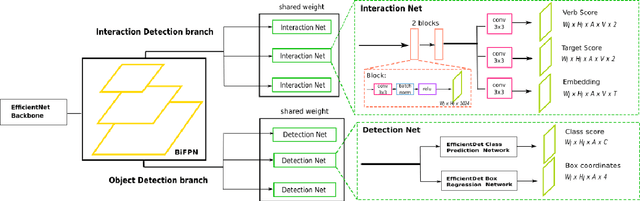

Detecting human interactions is crucial for human behavior analysis. Many methods have been proposed to deal with Human-to-Object Interaction (HOI) detection, i.e., detecting in an image which person and object interact together and classifying the type of interaction. However, Human-to-Human Interactions, such as social and violent interactions, are generally not considered in available HOI training datasets. As we think these types of interactions cannot be ignored and decorrelated from HOI when analyzing human behavior, we propose a new interaction dataset to deal with both types of human interactions: Human-to-Human-or-Object (H2O). In addition, we introduce a novel taxonomy of verbs, intended to be closer to a description of human body attitude in relation to the surrounding targets of interaction, and more independent of the environment. Unlike some existing datasets, we strive to avoid defining synonymous verbs when their use highly depends on the target type or requires a high level of semantic interpretation. As H2O dataset includes V-COCO images annotated with this new taxonomy, images obviously contain more interactions. This can be an issue for HOI detection methods whose complexity depends on the number of people, targets or interactions. Thus, we propose DIABOLO (Detecting InterActions By Only Looking Once), an efficient subject-centric single-shot method to detect all interactions in one forward pass, with constant inference time independent of image content. In addition, this multi-task network simultaneously detects all people and objects. We show how sharing a network for these tasks does not only save computation resource but also improves performance collaboratively. Finally, DIABOLO is a strong baseline for the new proposed challenge of H2O Interaction detection, as it outperforms all state-of-the-art methods when trained and evaluated on HOI dataset V-COCO.
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds
Dec 15, 2021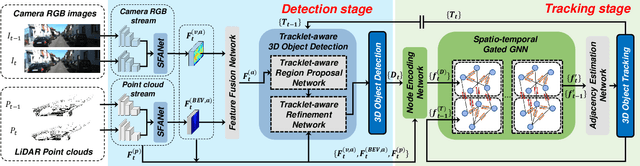

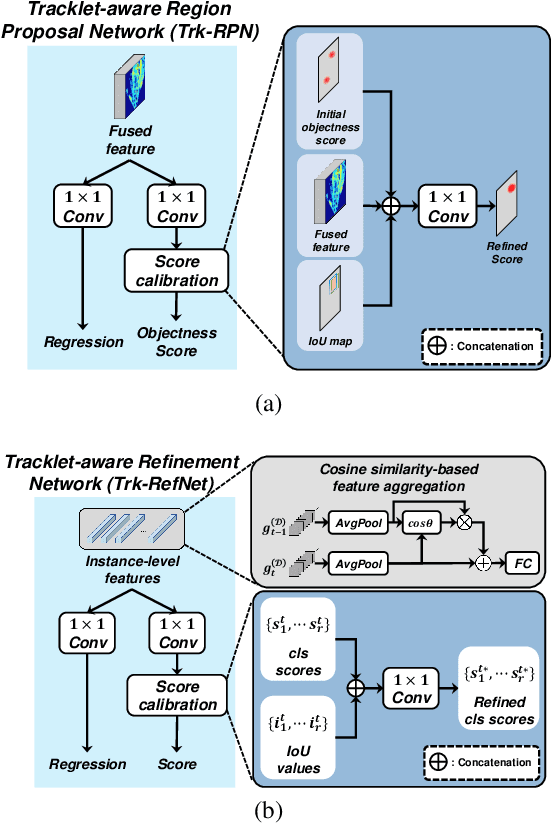

In this paper, we propose a new joint object detection and tracking (JoDT) framework for 3D object detection and tracking based on camera and LiDAR sensors. The proposed method, referred to as 3D DetecTrack, enables the detector and tracker to cooperate to generate a spatio-temporal representation of the camera and LiDAR data, with which 3D object detection and tracking are then performed. The detector constructs the spatio-temporal features via the weighted temporal aggregation of the spatial features obtained by the camera and LiDAR fusion. Then, the detector reconfigures the initial detection results using information from the tracklets maintained up to the previous time step. Based on the spatio-temporal features generated by the detector, the tracker associates the detected objects with previously tracked objects using a graph neural network (GNN). We devise a fully-connected GNN facilitated by a combination of rule-based edge pruning and attention-based edge gating, which exploits both spatial and temporal object contexts to improve tracking performance. The experiments conducted on both KITTI and nuScenes benchmarks demonstrate that the proposed 3D DetecTrack achieves significant improvements in both detection and tracking performances over baseline methods and achieves state-of-the-art performance among existing methods through collaboration between the detector and tracker.
Multi-focus Image Fusion: A Benchmark
May 03, 2020



Multi-focus image fusion (MFIF) has attracted considerable interests due to its numerous applications. While much progress has been made in recent years with efforts on developing various MFIF algorithms, some issues significantly hinder the fair and comprehensive performance comparison of MFIF methods, such as the lack of large-scale test set and the random choices of objective evaluation metrics in the literature. To solve these issues, this paper presents a multi-focus image fusion benchmark (MFIFB) which consists a test set of 105 image pairs, a code library of 30 MFIF algorithms, and 20 evaluation metrics. MFIFB is the first benchmark in the field of MFIF and provides the community a platform to compare MFIF algorithms fairly and comprehensively. Extensive experiments have been conducted using the proposed MFIFB to understand the performance of these algorithms. By analyzing the experimental results, effective MFIF algorithms are identified. More importantly, some observations on the status of the MFIF field are given, which can help to understand this field better.
Unified Multimodal Pre-training and Prompt-based Tuning for Vision-Language Understanding and Generation
Dec 15, 2021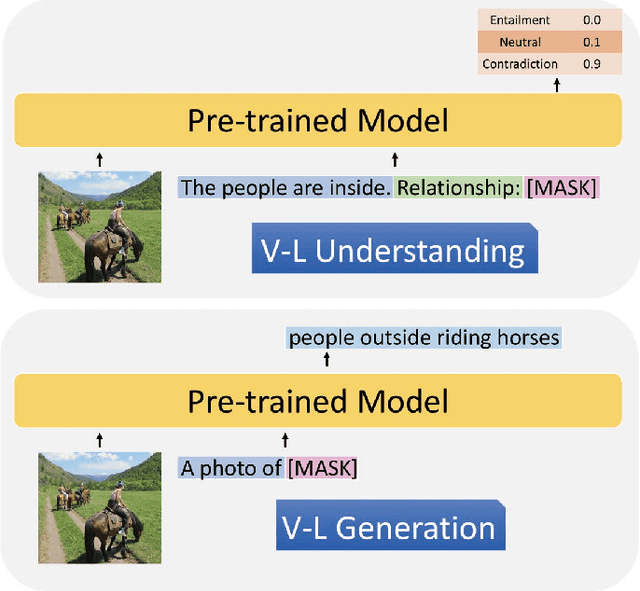
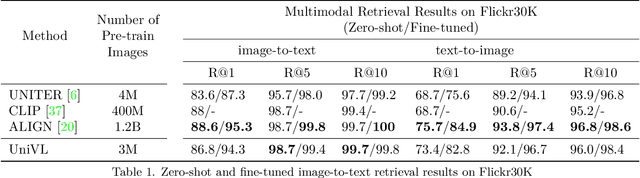
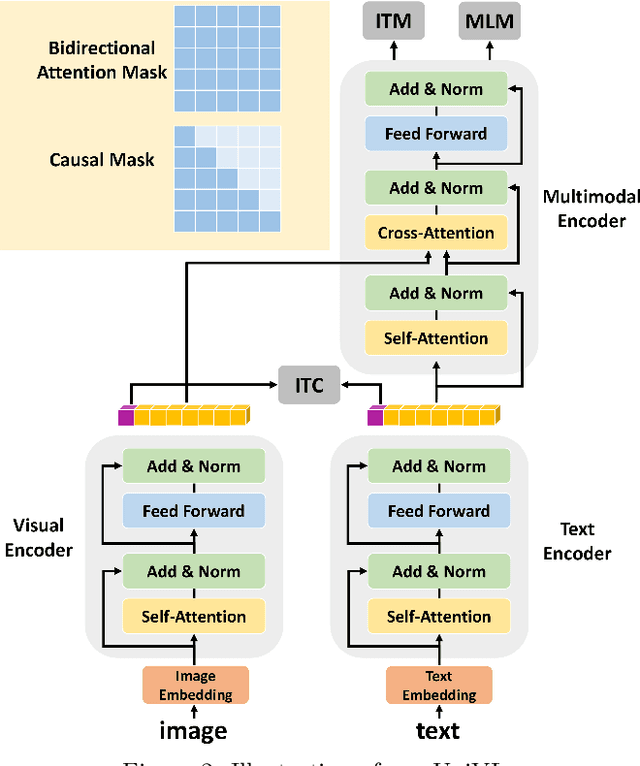
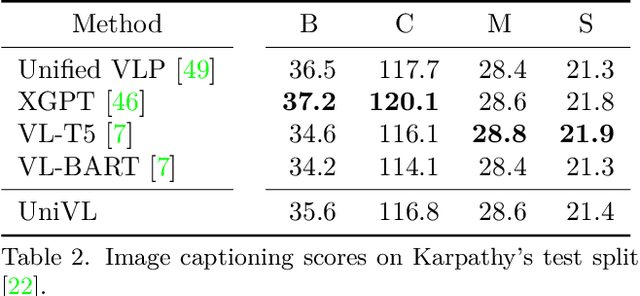
Most existing vision-language pre-training methods focus on understanding tasks and use BERT-like objectives (masked language modeling and image-text matching) during pretraining. Although they perform well in many understanding downstream tasks, e.g., visual question answering, image-text retrieval and visual entailment, they do not possess the ability to generate. To tackle this problem, we propose Unified multimodal pre-training for both Vision-Language understanding and generation (UniVL). The proposed UniVL is capable of handling both understanding tasks and generative tasks. We augment existing pretraining paradigms that only use random masks with causal masks, i.e., triangular masks that mask out future tokens, such that the pre-trained models can have autoregressive generation abilities by design. We formulate several previous understanding tasks as a text generation task and propose to use prompt-based method for fine-tuning on different downstream tasks. Our experiments show that there is a trade-off between understanding tasks and generation tasks while using the same model, and a feasible way to improve both tasks is to use more data. Our UniVL framework attains comparable performance to recent vision-language pre-training methods on both understanding tasks and generation tasks. Moreover, we demostrate that prompt-based finetuning is more data-efficient - it outperforms discriminative methods in few-shot scenarios.
csBoundary: City-scale Road-boundary Detection in Aerial Images for High-definition Maps
Nov 11, 2021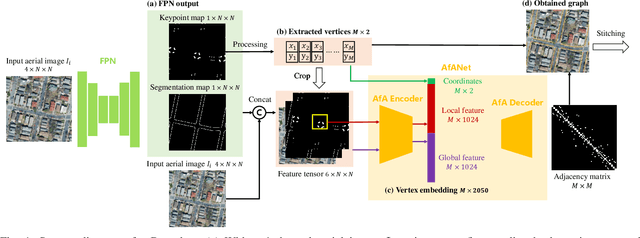
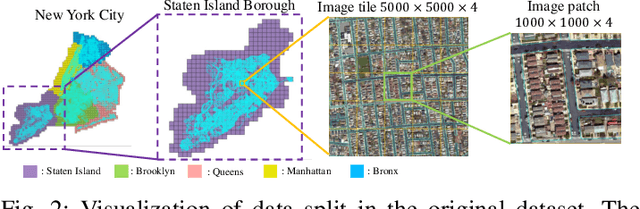
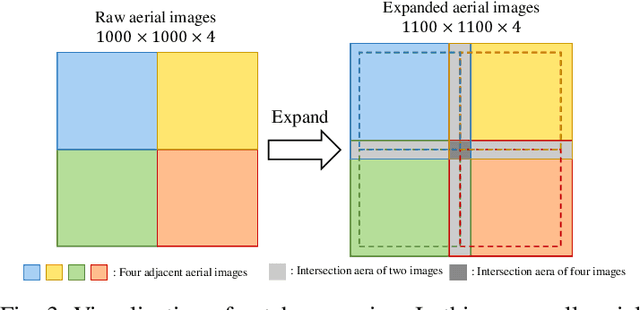
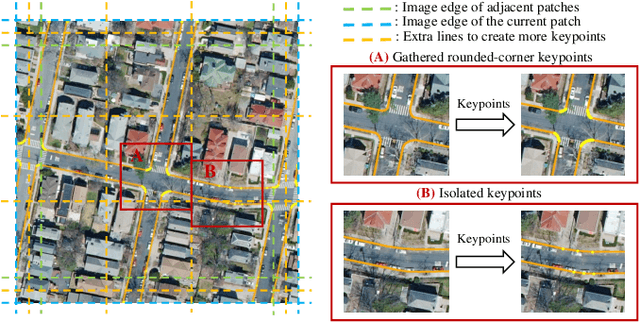
High-Definition (HD) maps can provide precise geometric and semantic information of static traffic environments for autonomous driving. Road-boundary is one of the most important information contained in HD maps since it distinguishes between road areas and off-road areas, which can guide vehicles to drive within road areas. But it is labor-intensive to annotate road boundaries for HD maps at the city scale. To enable automatic HD map annotation, current work uses semantic segmentation or iterative graph growing for road-boundary detection. However, the former could not ensure topological correctness since it works at the pixel level, while the latter suffers from inefficiency and drifting issues. To provide a solution to the aforementioned problems, in this letter, we propose a novel system termed csBoundary to automatically detect road boundaries at the city scale for HD map annotation. Our network takes as input an aerial image patch, and directly infers the continuous road-boundary graph (i.e., vertices and edges) from this image. To generate the city-scale road-boundary graph, we stitch the obtained graphs from all the image patches. Our csBoundary is evaluated and compared on a public benchmark dataset. The results demonstrate our superiority. The accompanied demonstration video is available at our project page \url{https://sites.google.com/view/csboundary/}.
Attention-Driven Dynamic Graph Convolutional Network for Multi-Label Image Recognition
Dec 05, 2020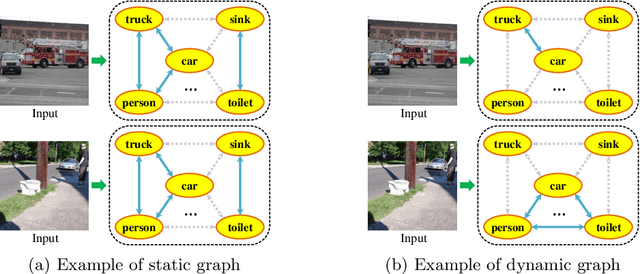

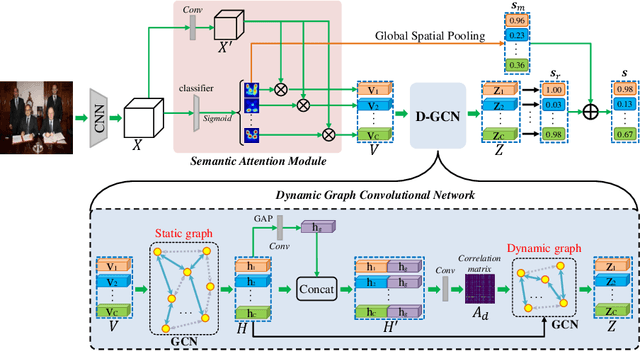
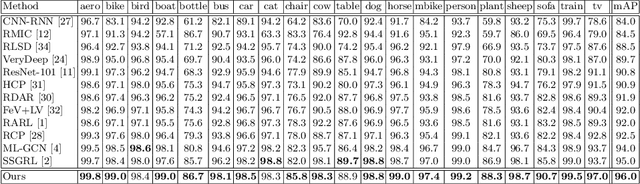
Recent studies often exploit Graph Convolutional Network (GCN) to model label dependencies to improve recognition accuracy for multi-label image recognition. However, constructing a graph by counting the label co-occurrence possibilities of the training data may degrade model generalizability, especially when there exist occasional co-occurrence objects in test images. Our goal is to eliminate such bias and enhance the robustness of the learnt features. To this end, we propose an Attention-Driven Dynamic Graph Convolutional Network (ADD-GCN) to dynamically generate a specific graph for each image. ADD-GCN adopts a Dynamic Graph Convolutional Network (D-GCN) to model the relation of content-aware category representations that are generated by a Semantic Attention Module (SAM). Extensive experiments on public multi-label benchmarks demonstrate the effectiveness of our method, which achieves mAPs of 85.2%, 96.0%, and 95.5% on MS-COCO, VOC2007, and VOC2012, respectively, and outperforms current state-of-the-art methods with a clear margin. All codes can be found at https://github.com/Yejin0111/ADD-GCN.
Bridging the Gap: Point Clouds for Merging Neurons in Connectomics
Dec 03, 2021
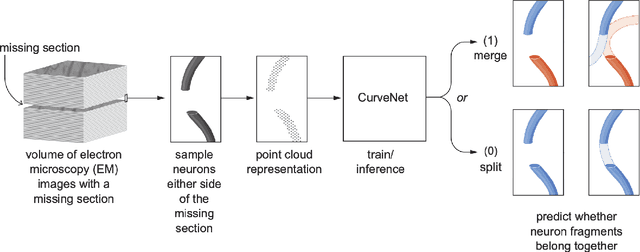

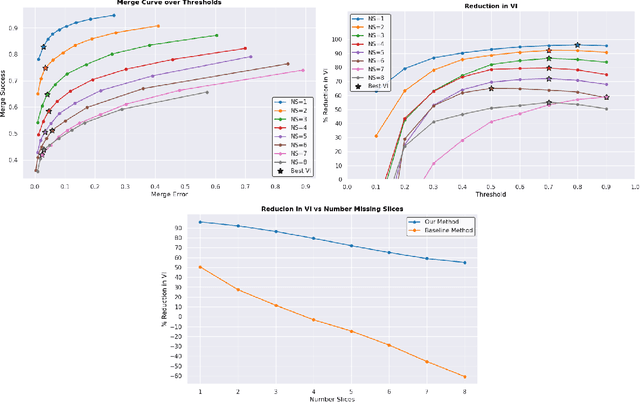
In the field of Connectomics, a primary problem is that of 3D neuron segmentation. Although Deep Learning based methods have achieved remarkable accuracy, errors still exist, especially in regions with image defects. One common type of defect is that of consecutive missing image sections. Here data is lost along some axis, and the resulting neuron segmentations are split across the gap. To address this problem, we propose a novel method based on point cloud representations of neurons. We formulate this as a classification problem and train CurveNet, a state-of-the-art point cloud classification model, to identify which neurons should be merged. We show that our method not only performs strongly but scales reasonably to gaps well beyond what other methods have attempted to address. Additionally, our point cloud representations are highly efficient in terms of data, maintaining high performance with an amount of data that would be unfeasible for other methods. We believe that this is an indicator of the viability of using point clouds representations for other proofreading tasks.
A survey of top-down approaches for human pose estimation
Feb 05, 2022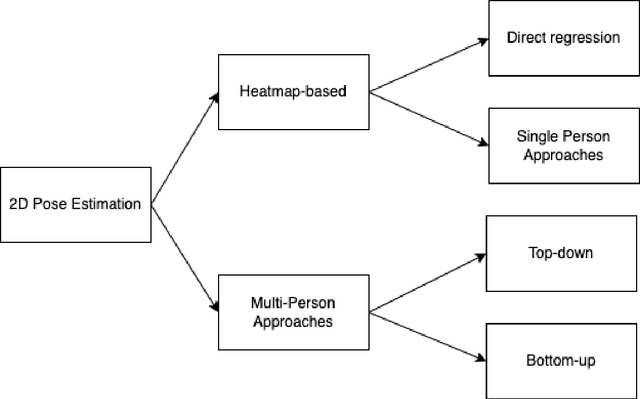

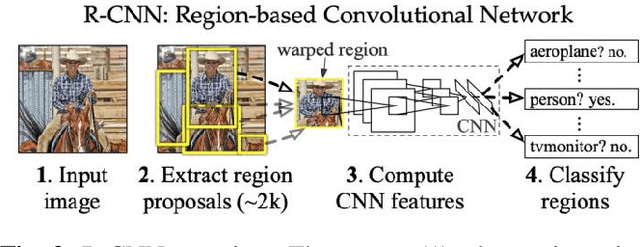
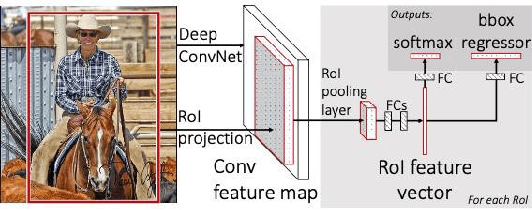
Human pose estimation in two-dimensional images videos has been a hot topic in the computer vision problem recently due to its vast benefits and potential applications for improving human life, such as behaviors recognition, motion capture and augmented reality, training robots, and movement tracking. Many state-of-the-art methods implemented with Deep Learning have addressed several challenges and brought tremendous remarkable results in the field of human pose estimation. Approaches are classified into two kinds: the two-step framework (top-down approach) and the part-based framework (bottom-up approach). While the two-step framework first incorporates a person detector and then estimates the pose within each box independently, detecting all body parts in the image and associating parts belonging to distinct persons is conducted in the part-based framework. This paper aims to provide newcomers with an extensive review of deep learning methods-based 2D images for recognizing the pose of people, which only focuses on top-down approaches since 2016. The discussion through this paper presents significant detectors and estimators depending on mathematical background, the challenges and limitations, benchmark datasets, evaluation metrics, and comparison between methods.
PIC-Net: Point Cloud and Image Collaboration Network for Large-Scale Place Recognition
Aug 03, 2020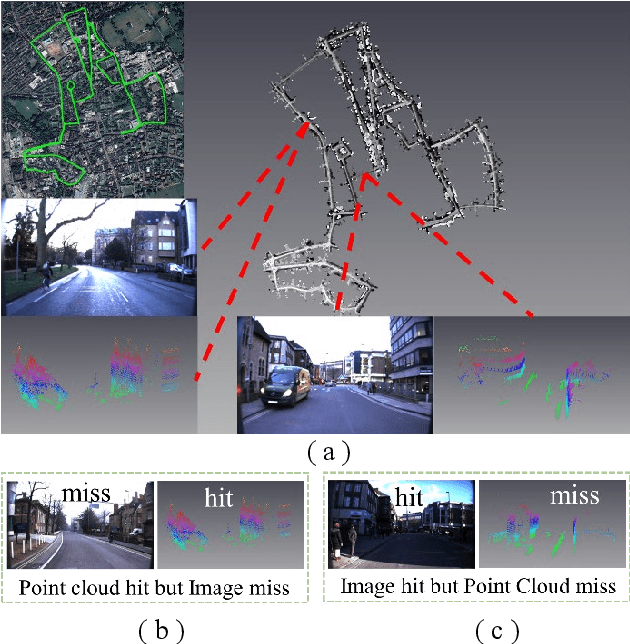

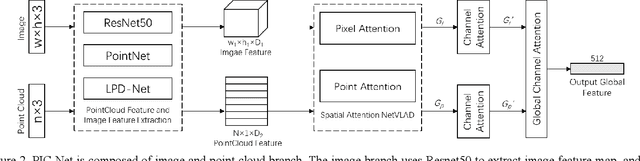
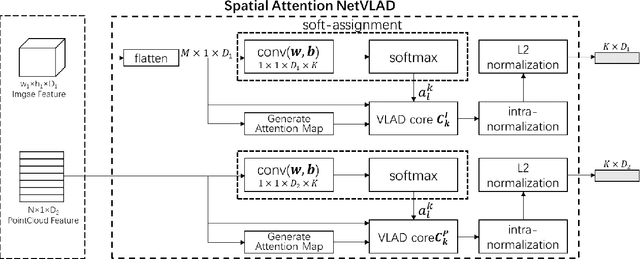
Place recognition is one of the hot research fields in automation technology and is still an open issue, Camera and Lidar are two mainstream sensors used in this task, Camera-based methods are easily affected by illumination and season changes, LIDAR cannot get the rich data as the image could , In this paper, we propose the PIC-Net (Point cloud and Image Collaboration Network), which use attention mechanism to fuse the features of image and point cloud, and mine the complementary information between the two. Furthermore, in order to improve the recognition performance at night, we transform the night image into the daytime style. Comparison results show that the collaboration of image and point cloud outperform both image-based and point cloud-based method, the attention strategy and day-night-transform could further improve the performance.