 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards a Unified Foundation Model: Jointly Pre-Training Transformers on Unpaired Images and Text
Dec 14, 2021




In this paper, we explore the possibility of building a unified foundation model that can be adapted to both vision-only and text-only tasks. Starting from BERT and ViT, we design a unified transformer consisting of modality-specific tokenizers, a shared transformer encoder, and task-specific output heads. To efficiently pre-train the proposed model jointly on unpaired images and text, we propose two novel techniques: (i) We employ the separately-trained BERT and ViT models as teachers and apply knowledge distillation to provide additional, accurate supervision signals for the joint training; (ii) We propose a novel gradient masking strategy to balance the parameter updates from the image and text pre-training losses. We evaluate the jointly pre-trained transformer by fine-tuning it on image classification tasks and natural language understanding tasks, respectively. The experiments show that the resultant unified foundation transformer works surprisingly well on both the vision-only and text-only tasks, and the proposed knowledge distillation and gradient masking strategy can effectively lift the performance to approach the level of separately-trained models.
Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy
Dec 29, 2020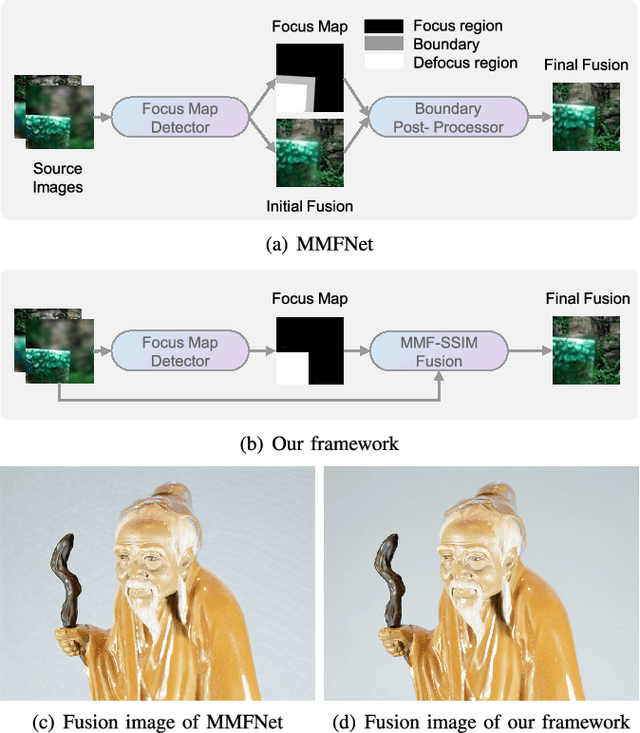
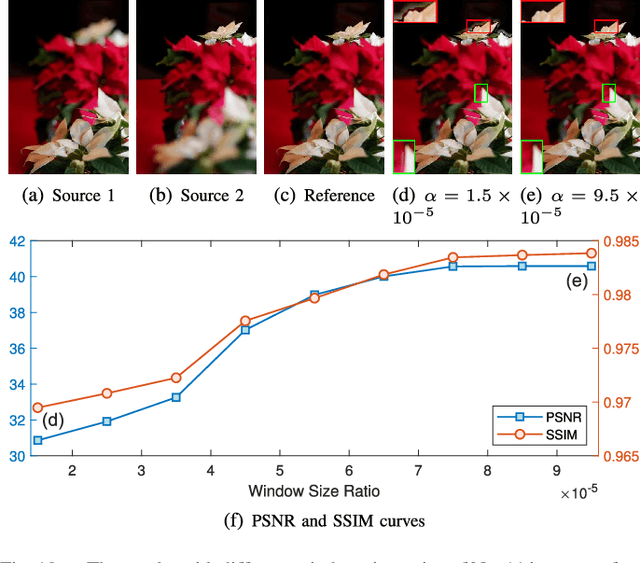


Multi-focus image fusion (MFF) is a popular technique to generate an all-in-focus image, where all objects in the scene are sharp. However, existing methods pay little attention to defocus spread effects of the real-world multi-focus images. Consequently, most of the methods perform badly in the areas near focus map boundaries. According to the idea that each local region in the fused image should be similar to the sharpest one among source images, this paper presents an optimization-based approach to reduce defocus spread effects. Firstly, a new MFF assessmentmetric is presented by combining the principle of structure similarity and detected focus maps. Then, MFF problem is cast into maximizing this metric. The optimization is solved by gradient ascent. Experiments conducted on the real-world dataset verify superiority of the proposed model. The codes are available at https://github.com/xsxjtu/MFF-SSIM.
DriveGuard: Robustification of Automated Driving Systems with Deep Spatio-Temporal Convolutional Autoencoder
Nov 05, 2021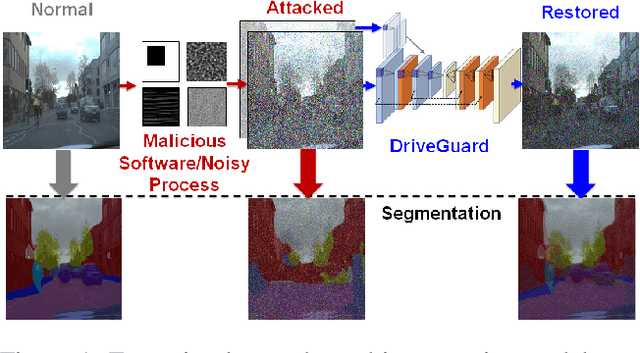
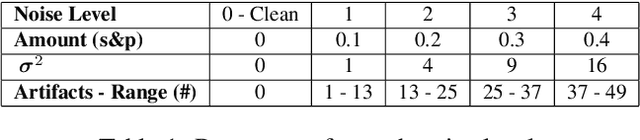
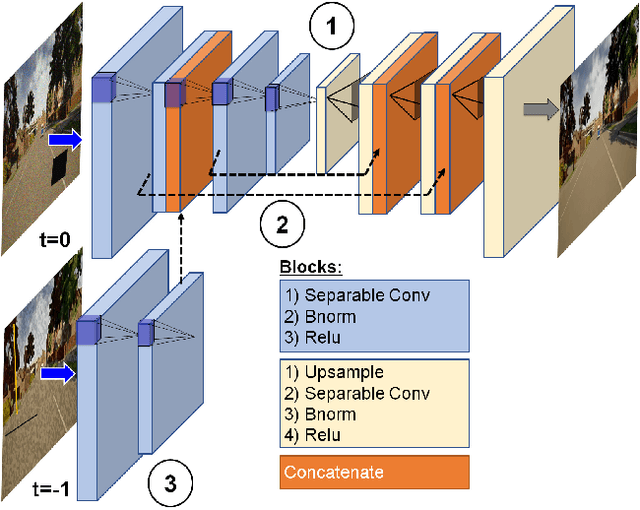

Autonomous vehicles increasingly rely on cameras to provide the input for perception and scene understanding and the ability of these models to classify their environment and objects, under adverse conditions and image noise is crucial. When the input is, either unintentionally or through targeted attacks, deteriorated, the reliability of autonomous vehicle is compromised. In order to mitigate such phenomena, we propose DriveGuard, a lightweight spatio-temporal autoencoder, as a solution to robustify the image segmentation process for autonomous vehicles. By first processing camera images with DriveGuard, we offer a more universal solution than having to re-train each perception model with noisy input. We explore the space of different autoencoder architectures and evaluate them on a diverse dataset created with real and synthetic images demonstrating that by exploiting spatio-temporal information combined with multi-component loss we significantly increase robustness against adverse image effects reaching within 5-6% of that of the original model on clean images.
An Efficient Polyp Segmentation Network
Mar 08, 2022Cancer is a disease that occurs as a result of uncontrolled division and proliferation of cells. The number of cancer cases has been on the rise over the recent years.. Colon cancer is one of the most common types of cancer in the world. Polyps that can be seen in the large intestine can cause cancer if not removed with early intervention. Deep learning and image segmentation techniques are used to minimize the number of polyps that goes unnoticed by the experts during the diagnosis. Although these techniques give good results, they require too many parameters. We propose a new model to solve this problem. Our proposed model includes less parameters as well as outperforming the success of the state of the art models. In the proposed model, a partial decoder is used to reduce the number of parameters while maintaning success. EfficientNetB0, which gives successfull results as well as requiring few parameters, is used in the encoder part. Since polyps have variable aspect and aspect ratios, an asymetric convolution block was used instead of using classic convolution block. Kvasir and CVC-ClinicDB datasets were seperated as training, validation and testing, and CVC-ColonDB, ETIS and Endoscene datasets were used for testing. According to the dice metric, our model had the best results with %71.8 in the ColonDB test dataset, %89.3 in the EndoScene test dataset and %74.8 in the ETIS test dataset. Our model requires a total of 2.626.337 parameters. When we compare it in the literature, according to similar studies, the model that requires the least parameters is U-Net++ with 9.042.177 parameters.
To what extent can Plug-and-Play methods outperform neural networks alone in low-dose CT reconstruction
Feb 15, 2022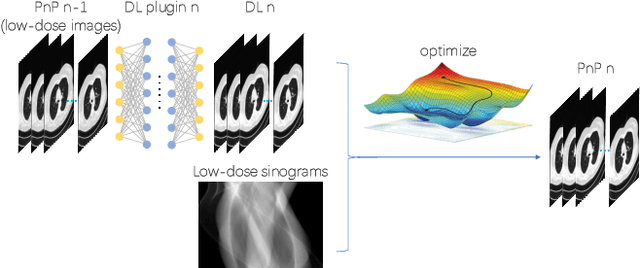
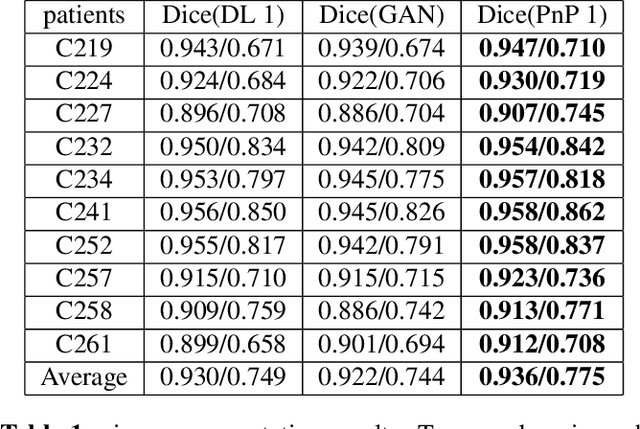
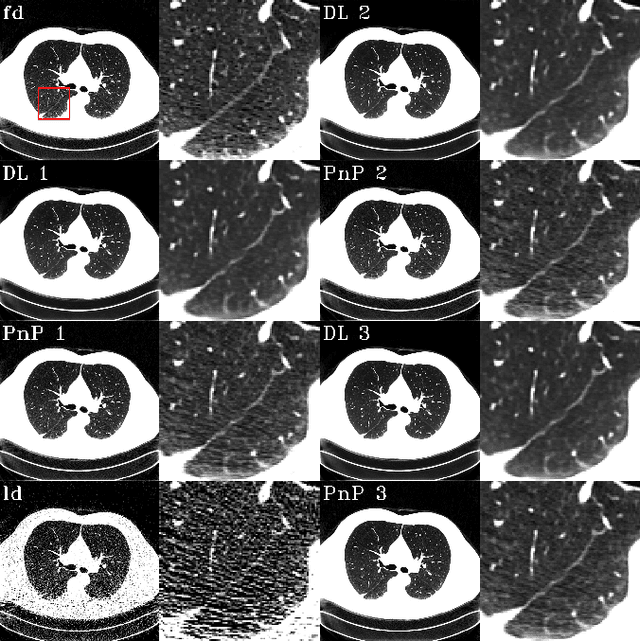
The Plug-and-Play (PnP) framework was recently introduced for low-dose CT reconstruction to leverage the interpretability and the flexibility of model-based methods to incorporate various plugins, such as trained deep learning (DL) neural networks. However, the benefits of PnP vs. state-of-the-art DL methods have not been clearly demonstrated. In this work, we proposed an improved PnP framework to address the previous limitations and develop clinical-relevant segmentation metrics for quantitative result assessment. Compared with the DL alone methods, our proposed PnP framework was slightly inferior in MSE and PSNR. However, the power spectrum of the resulting images better matched that of full-dose images than that of DL denoised images. The resulting images supported higher accuracy in airway segmentation than DL denoised images for all the ten patients in the test set, more substantially on the airways with a cross-section smaller than 0.61cm$^2$, and outperformed the DL denoised images for 45 out of 50 lung lobes in lobar segmentation. Our PnP method proved to be significantly better at preserving the image texture, which translated to task-specific benefits in automated structure segmentation and detection.
The Power of Proxy Data and Proxy Networks for Hyper-Parameter Optimization in Medical Image Segmentation
Jul 12, 2021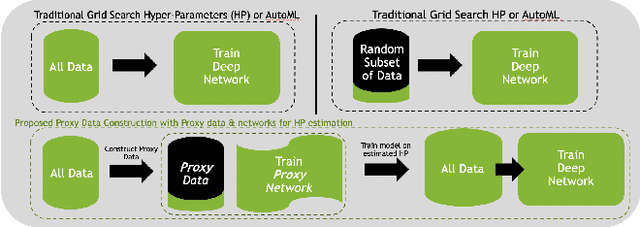
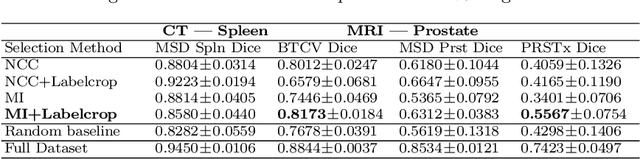
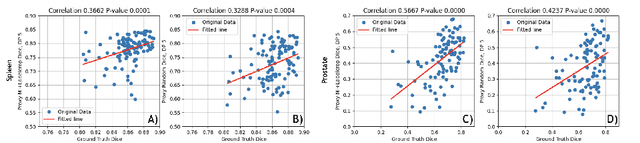
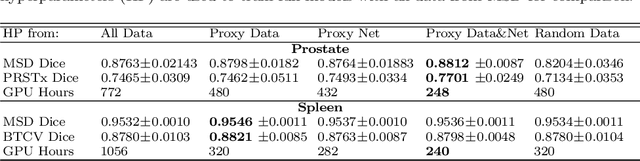
Deep learning models for medical image segmentation are primarily data-driven. Models trained with more data lead to improved performance and generalizability. However, training is a computationally expensive process because multiple hyper-parameters need to be tested to find the optimal setting for best performance. In this work, we focus on accelerating the estimation of hyper-parameters by proposing two novel methodologies: proxy data and proxy networks. Both can be useful for estimating hyper-parameters more efficiently. We test the proposed techniques on CT and MR imaging modalities using well-known public datasets. In both cases using one dataset for building proxy data and another data source for external evaluation. For CT, the approach is tested on spleen segmentation with two datasets. The first dataset is from the medical segmentation decathlon (MSD), where the proxy data is constructed, the secondary dataset is utilized as an external validation dataset. Similarly, for MR, the approach is evaluated on prostate segmentation where the first dataset is from MSD and the second dataset is PROSTATEx. First, we show higher correlation to using full data for training when testing on the external validation set using smaller proxy data than a random selection of the proxy data. Second, we show that a high correlation exists for proxy networks when compared with the full network on validation Dice score. Third, we show that the proposed approach of utilizing a proxy network can speed up an AutoML framework for hyper-parameter search by 3.3x, and by 4.4x if proxy data and proxy network are utilized together.
Closed-loop Feedback Registration for Consecutive Images of Moving Flexible Targets
Oct 20, 2021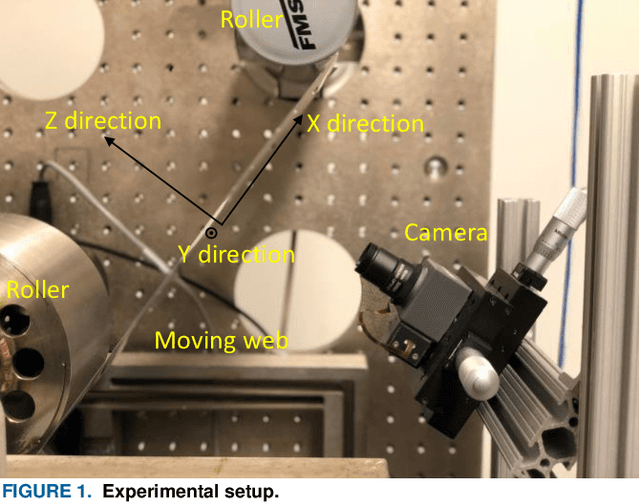

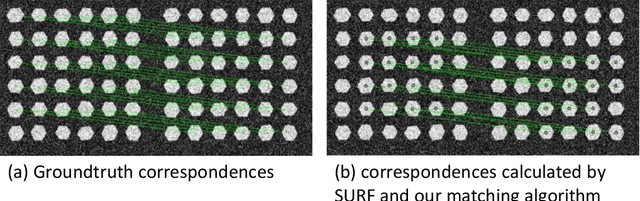
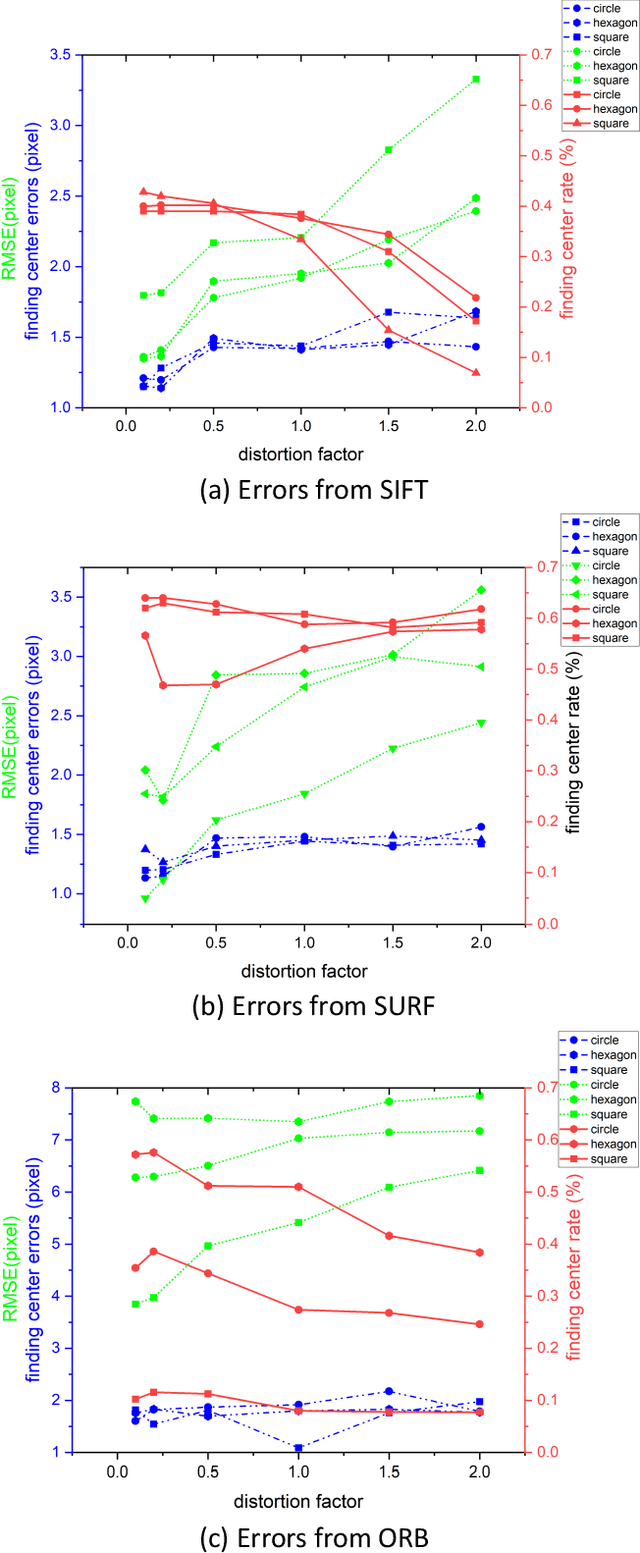
Advancement of imaging techniques enables consecutive image sequences to be acquired for quality monitoring of manufacturing production lines. Registration for these image sequences is essential for in-line pattern inspection and metrology, e.g., in the printing process of flexible electronics. However, conventional image registration algorithms cannot produce accurate results when the images contain many similar and deformable patterns in the manufacturing process. Such a failure originates from a fact that the conventional algorithms only use the spatial and pixel intensity information for registration. Considering the nature of temporal continuity and consecution of the product images, in this paper, we propose a closed-loop feedback registration algorithm for matching and stitching the deformable printed patterns on a moving flexible substrate. The algorithm leverages the temporal and spatial relationships of the consecutive images and the continuity of the image sequence for fast, accurate, and robust point matching. Our experimental results show that our algorithm can find more matching point pairs with a lower root mean squared error (RMSE) compared to other state-of-the-art algorithms while offering significant improvements to running time.
Adversarial Robustness in Deep Learning: Attacks on Fragile Neurons
Jan 31, 2022We identify fragile and robust neurons of deep learning architectures using nodal dropouts of the first convolutional layer. Using an adversarial targeting algorithm, we correlate these neurons with the distribution of adversarial attacks on the network. Adversarial robustness of neural networks has gained significant attention in recent times and highlights intrinsic weaknesses of deep learning networks against carefully constructed distortion applied to input images. In this paper, we evaluate the robustness of state-of-the-art image classification models trained on the MNIST and CIFAR10 datasets against the fast gradient sign method attack, a simple yet effective method of deceiving neural networks. Our method identifies the specific neurons of a network that are most affected by the adversarial attack being applied. We, therefore, propose to make fragile neurons more robust against these attacks by compressing features within robust neurons and amplifying the fragile neurons proportionally.
Lightweight Jet Reconstruction and Identification as an Object Detection Task
Feb 09, 2022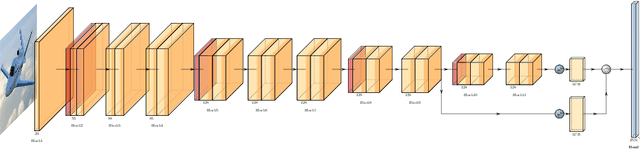
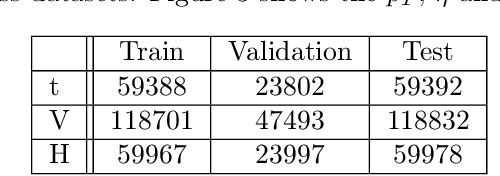
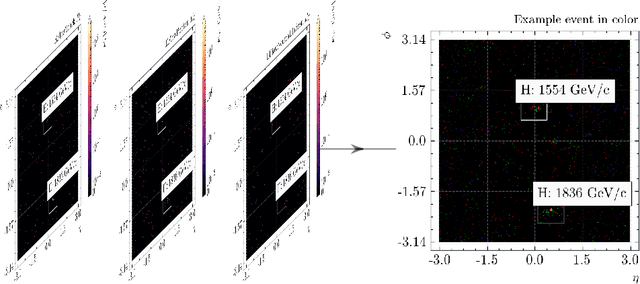
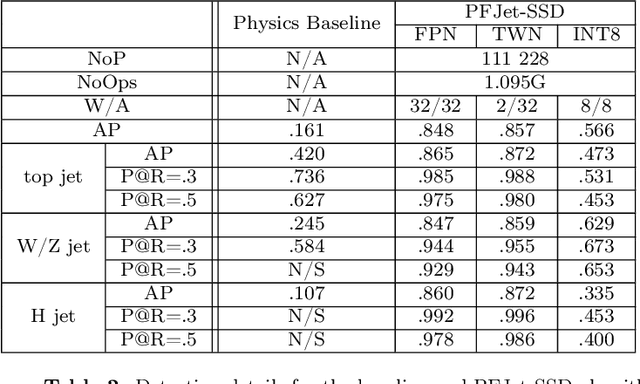
We apply object detection techniques based on deep convolutional blocks to end-to-end jet identification and reconstruction tasks encountered at the CERN Large Hadron Collider (LHC). Collision events produced at the LHC and represented as an image composed of calorimeter and tracker cells are given as an input to a Single Shot Detection network. The algorithm, named PFJet-SSD performs simultaneous localization, classification and regression tasks to cluster jets and reconstruct their features. This all-in-one single feed-forward pass gives advantages in terms of execution time and an improved accuracy w.r.t. traditional rule-based methods. A further gain is obtained from network slimming, homogeneous quantization, and optimized runtime for meeting memory and latency constraints of a typical real-time processing environment. We experiment with 8-bit and ternary quantization, benchmarking their accuracy and inference latency against a single-precision floating-point. We show that the ternary network closely matches the performance of its full-precision equivalent and outperforms the state-of-the-art rule-based algorithm. Finally, we report the inference latency on different hardware platforms and discuss future applications.
Hallucinating Pose-Compatible Scenes
Dec 13, 2021
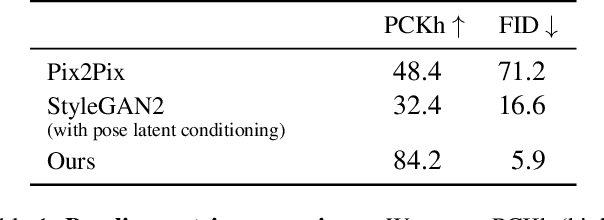

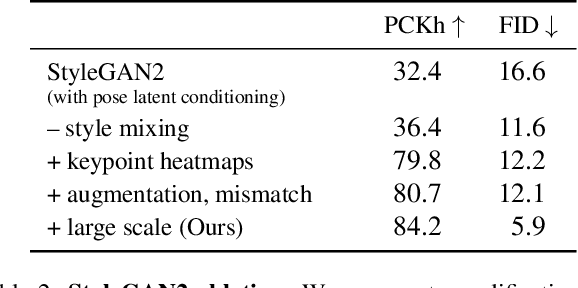
What does human pose tell us about a scene? We propose a task to answer this question: given human pose as input, hallucinate a compatible scene. Subtle cues captured by human pose -- action semantics, environment affordances, object interactions -- provide surprising insight into which scenes are compatible. We present a large-scale generative adversarial network for pose-conditioned scene generation. We significantly scale the size and complexity of training data, curating a massive meta-dataset containing over 19 million frames of humans in everyday environments. We double the capacity of our model with respect to StyleGAN2 to handle such complex data, and design a pose conditioning mechanism that drives our model to learn the nuanced relationship between pose and scene. We leverage our trained model for various applications: hallucinating pose-compatible scene(s) with or without humans, visualizing incompatible scenes and poses, placing a person from one generated image into another scene, and animating pose. Our model produces diverse samples and outperforms pose-conditioned StyleGAN2 and Pix2Pix baselines in terms of accurate human placement (percent of correct keypoints) and image quality (Frechet inception distance).