 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FrePGAN: Robust Deepfake Detection Using Frequency-level Perturbations
Feb 07, 2022
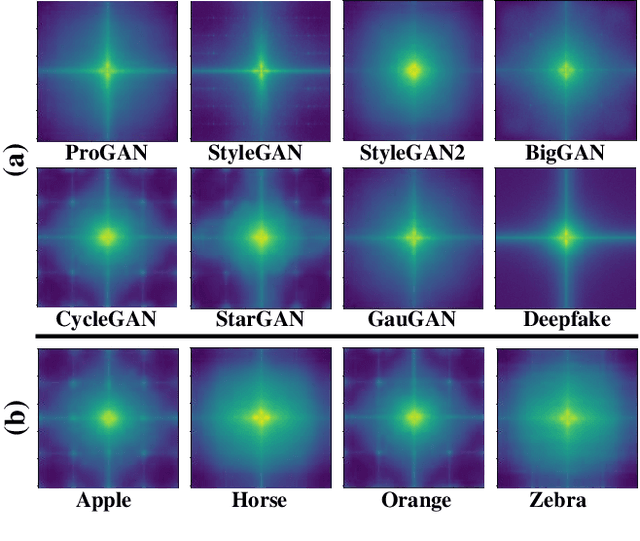

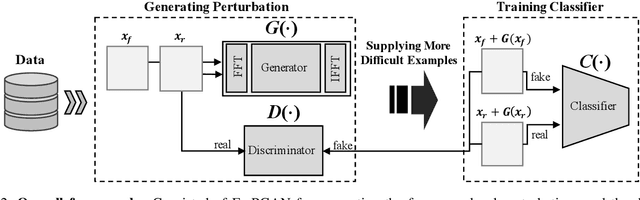
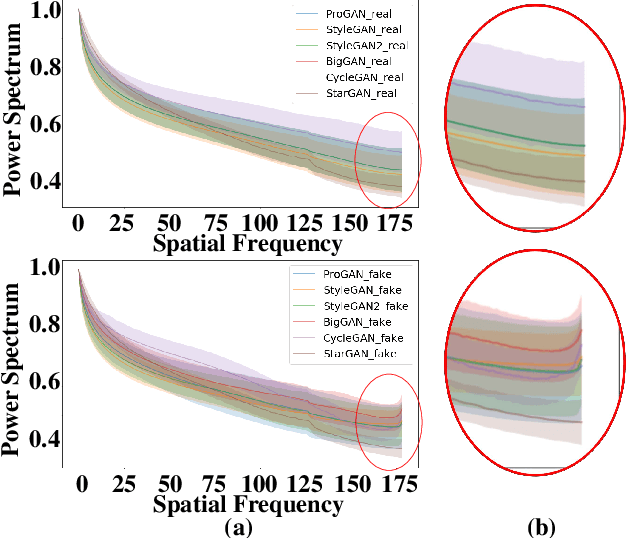
Various deepfake detectors have been proposed, but challenges still exist to detect images of unknown categories or GAN models outside of the training settings. Such issues arise from the overfitting issue, which we discover from our own analysis and the previous studies to originate from the frequency-level artifacts in generated images. We find that ignoring the frequency-level artifacts can improve the detector's generalization across various GAN models, but it can reduce the model's performance for the trained GAN models. Thus, we design a framework to generalize the deepfake detector for both the known and unseen GAN models. Our framework generates the frequency-level perturbation maps to make the generated images indistinguishable from the real images. By updating the deepfake detector along with the training of the perturbation generator, our model is trained to detect the frequency-level artifacts at the initial iterations and consider the image-level irregularities at the last iterations. For experiments, we design new test scenarios varying from the training settings in GAN models, color manipulations, and object categories. Numerous experiments validate the state-of-the-art performance of our deepfake detector.
FacialGAN: Style Transfer and Attribute Manipulation on Synthetic Faces
Oct 18, 2021



Facial image manipulation is a generation task where the output face is shifted towards an intended target direction in terms of facial attribute and styles. Recent works have achieved great success in various editing techniques such as style transfer and attribute translation. However, current approaches are either focusing on pure style transfer, or on the translation of predefined sets of attributes with restricted interactivity. To address this issue, we propose FacialGAN, a novel framework enabling simultaneous rich style transfers and interactive facial attributes manipulation. While preserving the identity of a source image, we transfer the diverse styles of a target image to the source image. We then incorporate the geometry information of a segmentation mask to provide a fine-grained manipulation of facial attributes. Finally, a multi-objective learning strategy is introduced to optimize the loss of each specific tasks. Experiments on the CelebA-HQ dataset, with CelebAMask-HQ as semantic mask labels, show our model's capacity in producing visually compelling results in style transfer, attribute manipulation, diversity and face verification. For reproducibility, we provide an interactive open-source tool to perform facial manipulations, and the Pytorch implementation of the model.
Dimensions of Motion: Learning to Predict a Subspace of Optical Flow from a Single Image
Dec 02, 2021
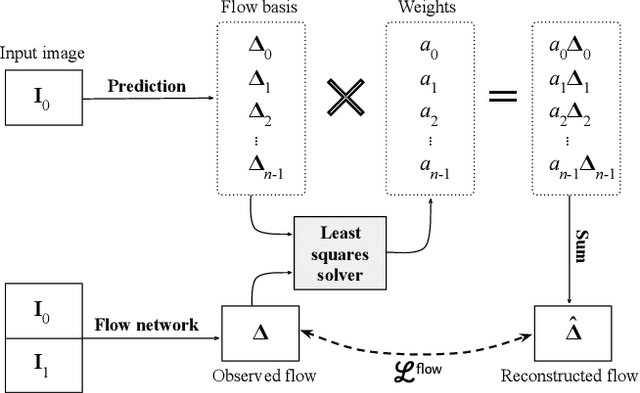
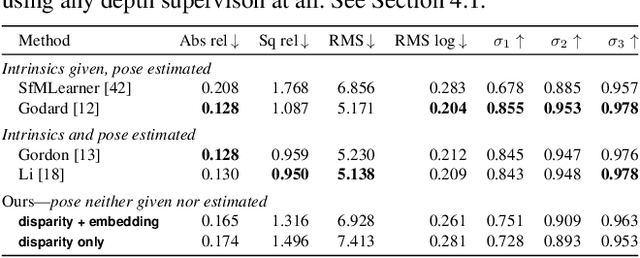
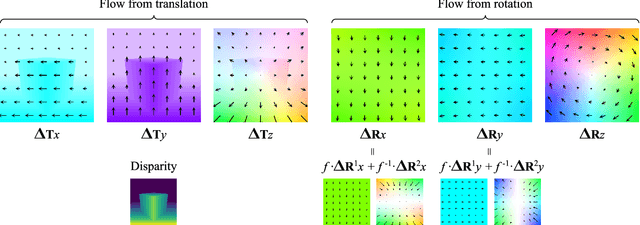
We introduce the problem of predicting, from a single video frame, a low-dimensional subspace of optical flow which includes the actual instantaneous optical flow. We show how several natural scene assumptions allow us to identify an appropriate flow subspace via a set of basis flow fields parameterized by disparity and a representation of object instances. The flow subspace, together with a novel loss function, can be used for the tasks of predicting monocular depth or predicting depth plus an object instance embedding. This provides a new approach to learning these tasks in an unsupervised fashion using monocular input video without requiring camera intrinsics or poses.
COCO-FUNIT: Few-Shot Unsupervised Image Translation with a Content Conditioned Style Encoder
Jul 15, 2020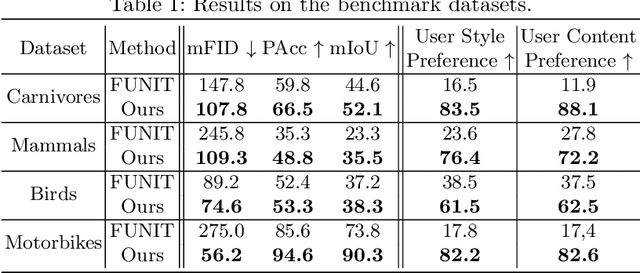
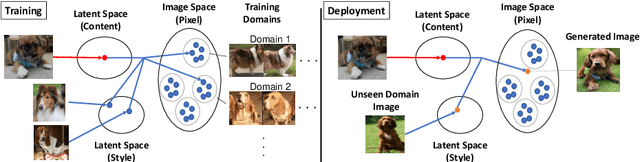

Unsupervised image-to-image translation intends to learn a mapping of an image in a given domain to an analogous image in a different domain, without explicit supervision of the mapping. Few-shot unsupervised image-to-image translation further attempts to generalize the model to an unseen domain by leveraging example images of the unseen domain provided at inference time. While remarkably successful, existing few-shot image-to-image translation models find it difficult to preserve the structure of the input image while emulating the appearance of the unseen domain, which we refer to as the \textit{content loss} problem. This is particularly severe when the poses of the objects in the input and example images are very different. To address the issue, we propose a new few-shot image translation model, \cocofunit, which computes the style embedding of the example images conditioned on the input image and a new module called the constant style bias. Through extensive experimental validations with comparison to the state-of-the-art, our model shows effectiveness in addressing the content loss problem. Code and pretrained models are available at https://nvlabs.github.io/COCO-FUNIT/ .
Bubble identification from images with machine learning methods
Feb 07, 2022
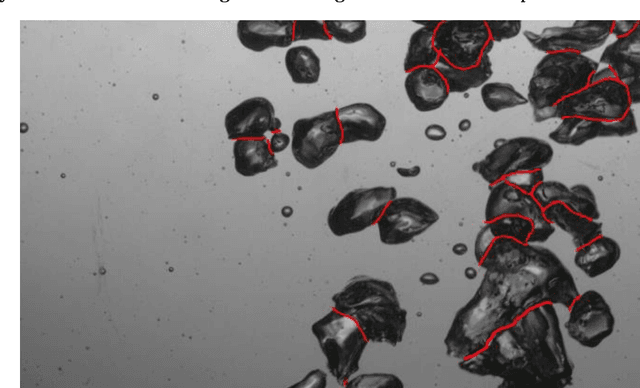
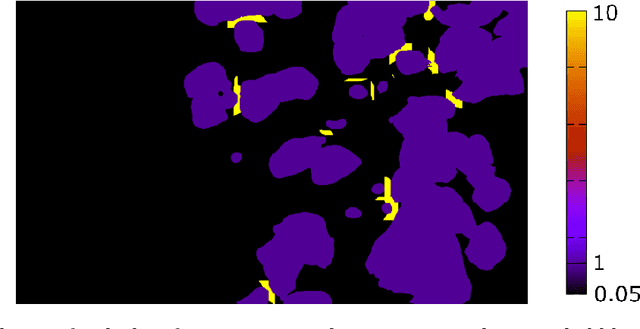
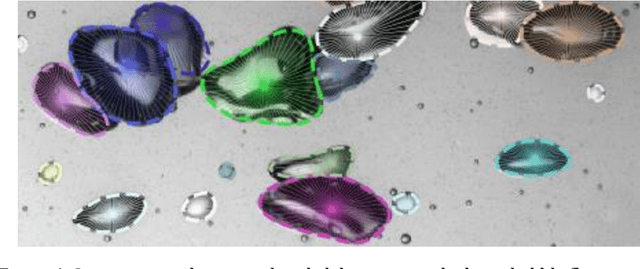
An automated and reliable processing of bubbly flow images is highly needed to analyse large data sets of comprehensive experimental series. A particular difficulty arises due to overlapping bubble projections in recorded images, which highly complicates the identification of individual bubbles. Recent approaches focus on the use of deep learning algorithms for this task and have already proven the high potential of such techniques. The main difficulties are the capability to handle different image conditions, higher gas volume fractions and a proper reconstruction of the hidden segment of a partly occluded bubble. In the present work, we try to tackle these points by testing three different methods based on Convolutional Neural Networks (CNNs) for the two former and two individual approaches that can be used subsequently to address the latter. To validate our methodology, we created test data sets with synthetic images that further demonstrate the capabilities as well as limitations of our combined approach. The generated data, code and trained models are made accessible to facilitate the use as well as further developments in the research field of bubble recognition in experimental images.
EncoderMI: Membership Inference against Pre-trained Encoders in Contrastive Learning
Aug 25, 2021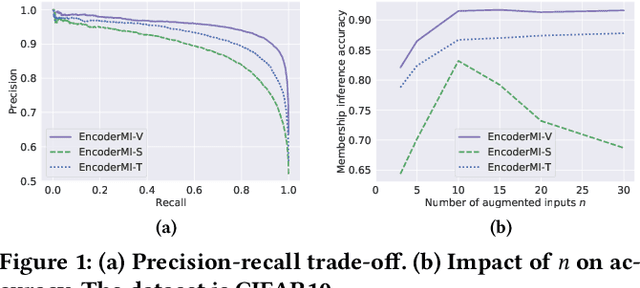
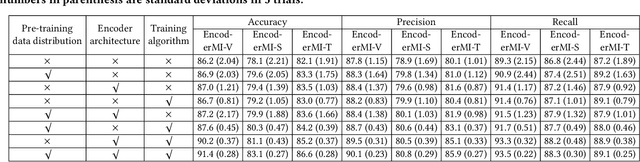
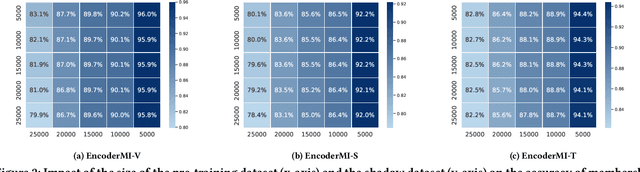
Given a set of unlabeled images or (image, text) pairs, contrastive learning aims to pre-train an image encoder that can be used as a feature extractor for many downstream tasks. In this work, we propose EncoderMI, the first membership inference method against image encoders pre-trained by contrastive learning. In particular, given an input and a black-box access to an image encoder, EncoderMI aims to infer whether the input is in the training dataset of the image encoder. EncoderMI can be used 1) by a data owner to audit whether its (public) data was used to pre-train an image encoder without its authorization or 2) by an attacker to compromise privacy of the training data when it is private/sensitive. Our EncoderMI exploits the overfitting of the image encoder towards its training data. In particular, an overfitted image encoder is more likely to output more (or less) similar feature vectors for two augmented versions of an input in (or not in) its training dataset. We evaluate EncoderMI on image encoders pre-trained on multiple datasets by ourselves as well as the Contrastive Language-Image Pre-training (CLIP) image encoder, which is pre-trained on 400 million (image, text) pairs collected from the Internet and released by OpenAI. Our results show that EncoderMI can achieve high accuracy, precision, and recall. We also explore a countermeasure against EncoderMI via preventing overfitting through early stopping. Our results show that it achieves trade-offs between accuracy of EncoderMI and utility of the image encoder, i.e., it can reduce the accuracy of EncoderMI, but it also incurs classification accuracy loss of the downstream classifiers built based on the image encoder.
Accelerating Laue Depth Reconstruction Algorithm with CUDA
Jan 20, 2022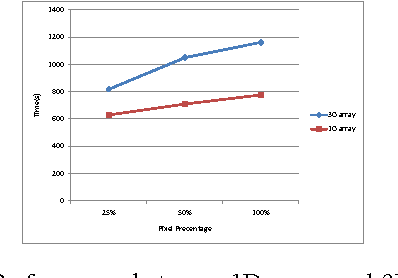
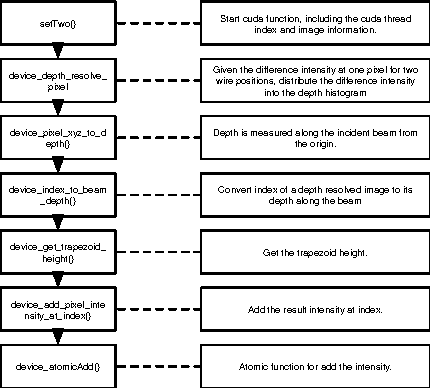
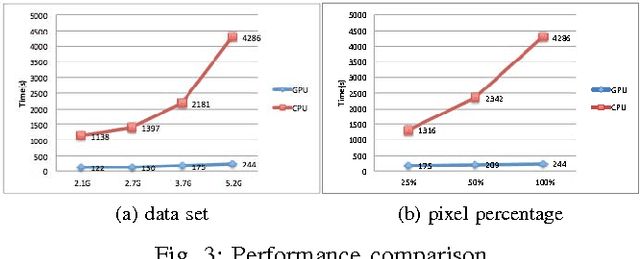
The Laue diffraction microscopy experiment uses the polychromatic Laue micro-diffraction technique to examine the structure of materials with sub-micron spatial resolution in all three dimensions. During this experiment, local crystallographic orientations, orientation gradients and strains are measured as properties which will be recorded in HDF5 image format. The recorded images will be processed with a depth reconstruction algorithm for future data analysis. But the current depth reconstruction algorithm consumes considerable processing time and might take up to 2 weeks for reconstructing data collected from one single experiment. To improve the depth reconstruction computation speed, we propose a scalable GPU program solution on the depth reconstruction problem in this paper. The test result shows that the running time would be 10 to 20 times faster than the prior CPU design for various size of input data.
Localized Super Resolution for Foreground Images using U-Net and MR-CNN
Oct 27, 2021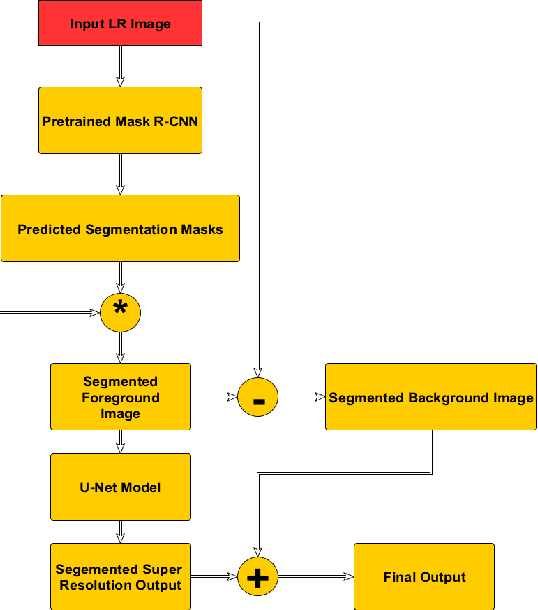
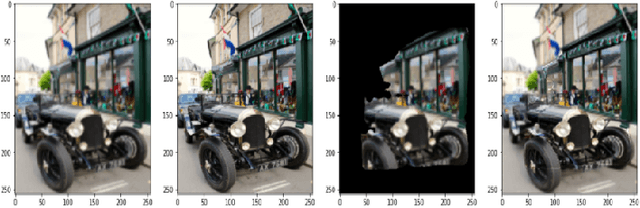
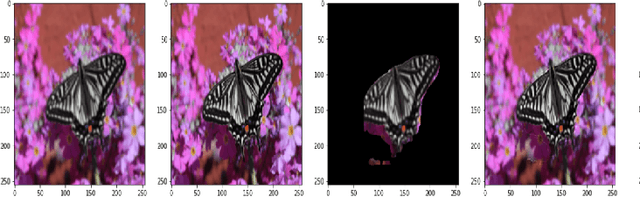
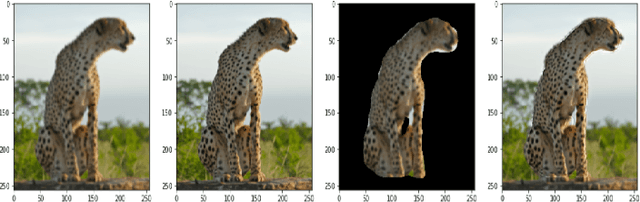
Images play a vital role in understanding data through visual representation. It gives a clear representation of the object in context. But if this image is not clear it might not be of much use. Thus, the topic of Image Super Resolution arose and many researchers have been working towards applying Computer Vision and Deep Learning Techniques to increase the quality of images. One of the applications of Super Resolution is to increase the quality of Portrait Images. Portrait Images are images which mainly focus on capturing the essence of the main object in the frame, where the object in context is highlighted whereas the background is occluded. When performing Super Resolution the model tries to increase the overall resolution of the image. But in portrait images the foreground resolution is more important than that of the background. In this paper, the performance of a Convolutional Neural Network (CNN) architecture known as U-Net for Super Resolution combined with Mask Region Based CNN (MR-CNN) for foreground super resolution is analysed. This analysis is carried out based on Localized Super Resolution i.e. We pass the LR Images to a pre-trained Image Segmentation model (MR-CNN) and perform super resolution inference on the foreground or Segmented Images and compute the Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR) metrics for comparisons.
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 14, 2020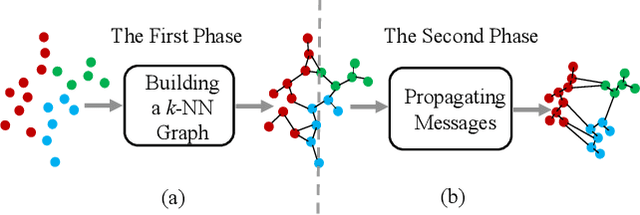

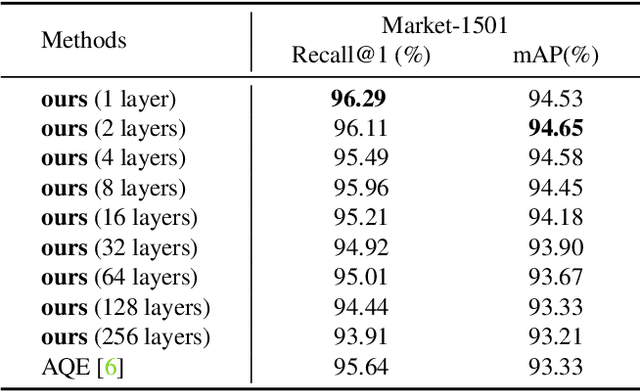
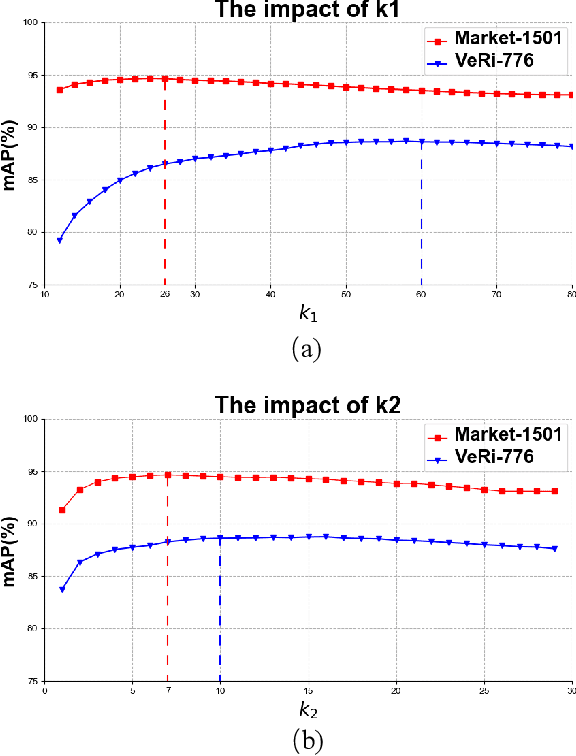
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.
RegNet: Self-Regulated Network for Image Classification
Jan 03, 2021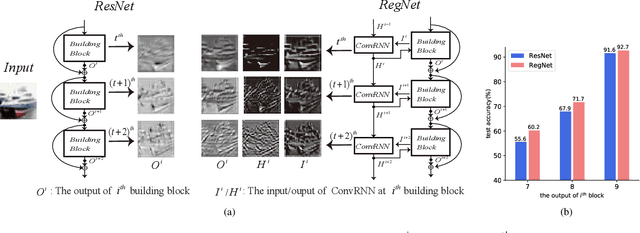
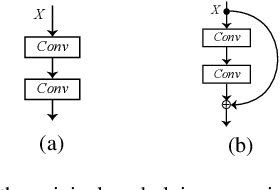
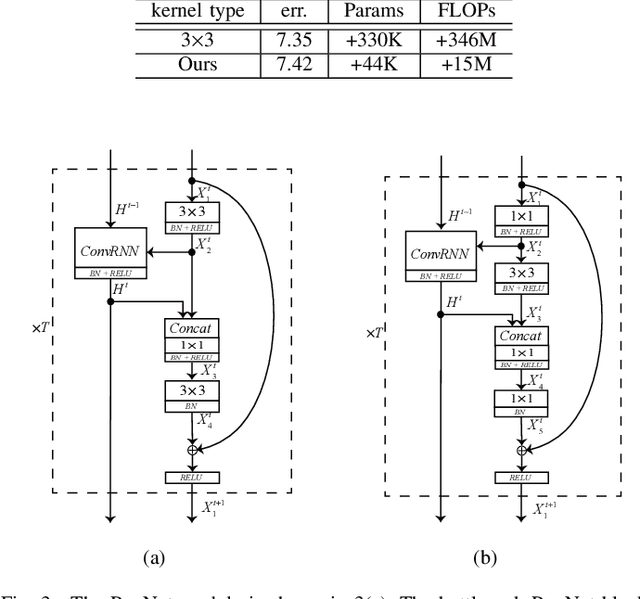
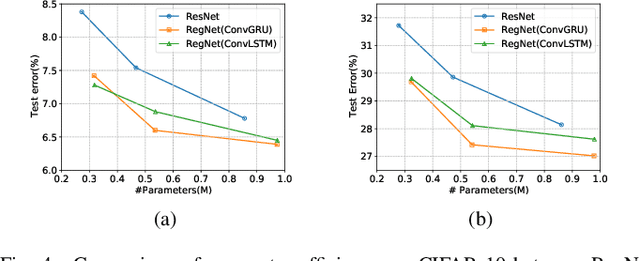
The ResNet and its variants have achieved remarkable successes in various computer vision tasks. Despite its success in making gradient flow through building blocks, the simple shortcut connection mechanism limits the ability of re-exploring new potentially complementary features due to the additive function. To address this issue, in this paper, we propose to introduce a regulator module as a memory mechanism to extract complementary features, which are further fed to the ResNet. In particular, the regulator module is composed of convolutional RNNs (e.g., Convolutional LSTMs or Convolutional GRUs), which are shown to be good at extracting Spatio-temporal information. We named the new regulated networks as RegNet. The regulator module can be easily implemented and appended to any ResNet architecture. We also apply the regulator module for improving the Squeeze-and-Excitation ResNet to show the generalization ability of our method. Experimental results on three image classification datasets have demonstrated the promising performance of the proposed architecture compared with the standard ResNet, SE-ResNet, and other state-of-the-art architectures.