 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Closer Look at Reference Learning for Fourier Phase Retrieval
Oct 26, 2021
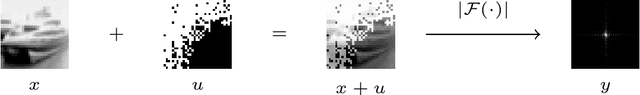
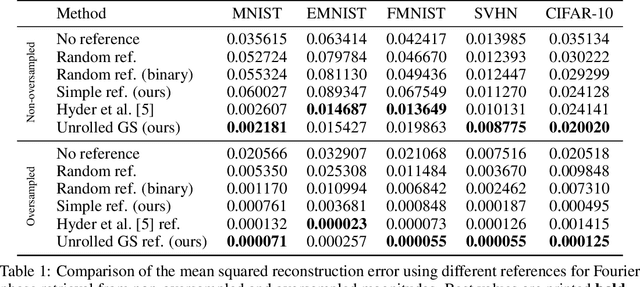

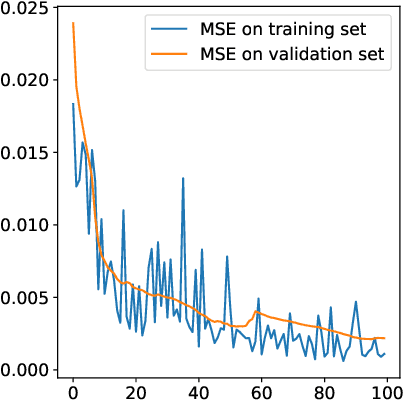
Reconstructing images from their Fourier magnitude measurements is a problem that often arises in different research areas. This process is also referred to as phase retrieval. In this work, we consider a modified version of the phase retrieval problem, which allows for a reference image to be added onto the image before the Fourier magnitudes are measured. We analyze an unrolled Gerchberg-Saxton (GS) algorithm that can be used to learn a good reference image from a dataset. Furthermore, we take a closer look at the learned reference images and propose a simple and efficient heuristic to construct reference images that, in some cases, yields reconstructions of comparable quality as approaches that learn references. Our code is available at https://github.com/tuelwer/reference-learning.
Box Supervised Video Segmentation Proposal Network
Feb 16, 2022
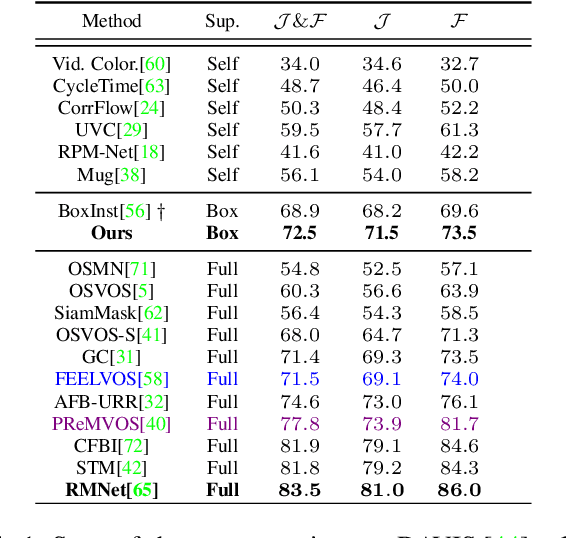
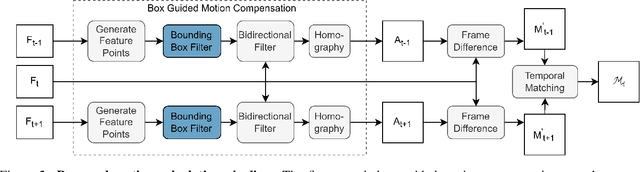
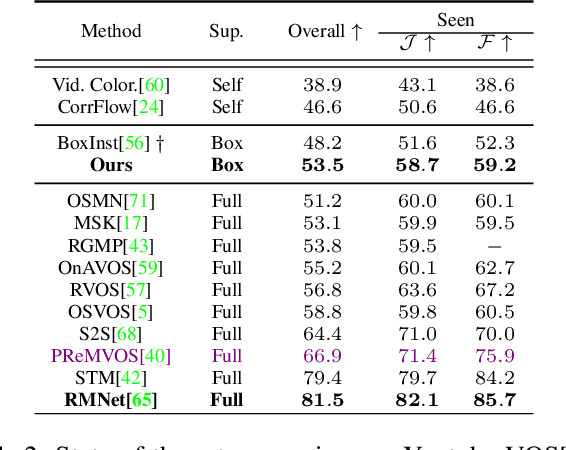
Video Object Segmentation (VOS) has been targeted by various fully-supervised and self-supervised approaches. While fully-supervised methods demonstrate excellent results, self-supervised ones, which do not use pixel-level ground truth, attract much attention. However, self-supervised approaches pose a significant performance gap. Box-level annotations provide a balanced compromise between labeling effort and result quality for image segmentation but have not been exploited for the video domain. In this work, we propose a box-supervised video object segmentation proposal network, which takes advantage of intrinsic video properties. Our method incorporates object motion in the following way: first, motion is computed using a bidirectional temporal difference and a novel bounding box-guided motion compensation. Second, we introduce a novel motion-aware affinity loss that encourages the network to predict positive pixel pairs if they share similar motion and color. The proposed method outperforms the state-of-the-art self-supervised benchmark by 16.4% and 6.9% $\mathcal{J}$ &$\mathcal{F}$ score and the majority of fully supervised methods on the DAVIS and Youtube-VOS dataset without imposing network architectural specifications. We provide extensive tests and ablations on the datasets, demonstrating the robustness of our method.
Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis
Jan 12, 2021

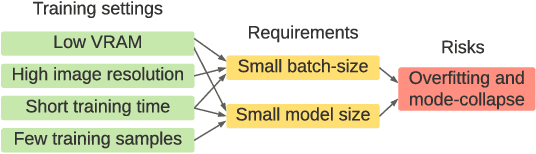
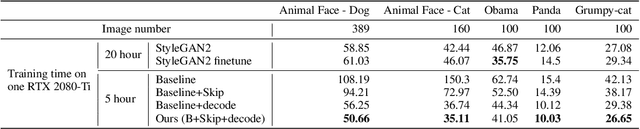
Training Generative Adversarial Networks (GAN) on high-fidelity images usually requires large-scale GPU-clusters and a vast number of training images. In this paper, we study the few-shot image synthesis task for GAN with minimum computing cost. We propose a light-weight GAN structure that gains superior quality on 1024*1024 resolution. Notably, the model converges from scratch with just a few hours of training on a single RTX-2080 GPU, and has a consistent performance, even with less than 100 training samples. Two technique designs constitute our work, a skip-layer channel-wise excitation module and a self-supervised discriminator trained as a feature-encoder. With thirteen datasets covering a wide variety of image domains (The datasets and code are available at: https://github.com/odegeasslbc/FastGAN-pytorch), we show our model's superior performance compared to the state-of-the-art StyleGAN2, when data and computing budget are limited.
Black-Box Testing of Deep Neural Networks through Test Case Diversity
Jan 18, 2022

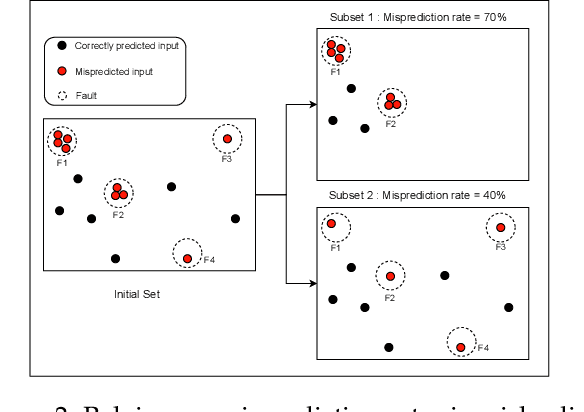

Deep Neural Networks (DNNs) have been extensively used in many areas including image processing, medical diagnostics, and autonomous driving. However, DNNs can exhibit erroneous behaviours that may lead to critical errors, especially when used in safety-critical systems. Inspired by testing techniques for traditional software systems, researchers have proposed neuron coverage criteria, as an analogy to source code coverage, to guide the testing of DNN models. Despite very active research on DNN coverage, several recent studies have questioned the usefulness of such criteria in guiding DNN testing. Further, from a practical standpoint, these criteria are white-box as they require access to the internals or training data of DNN models, which is in many contexts not feasible or convenient. In this paper, we investigate black-box input diversity metrics as an alternative to white-box coverage criteria. To this end, we first select and adapt three diversity metrics and study, in a controlled manner, their capacity to measure actual diversity in input sets. We then analyse their statistical association with fault detection using two datasets and three DNN models. We further compare diversity with state-of-the-art white-box coverage criteria. Our experiments show that relying on the diversity of image features embedded in test input sets is a more reliable indicator than coverage criteria to effectively guide the testing of DNNs. Indeed, we found that one of our selected black-box diversity metrics far outperforms existing coverage criteria in terms of fault-revealing capability and computational time. Results also confirm the suspicions that state-of-the-art coverage metrics are not adequate to guide the construction of test input sets to detect as many faults as possible with natural inputs.
GANSlider: How Users Control Generative Models for Images using Multiple Sliders with and without Feedforward Information
Feb 02, 2022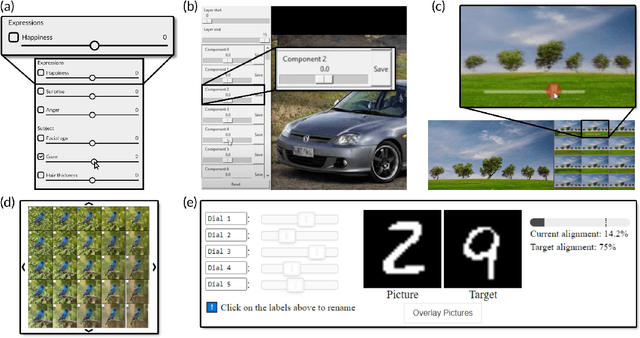
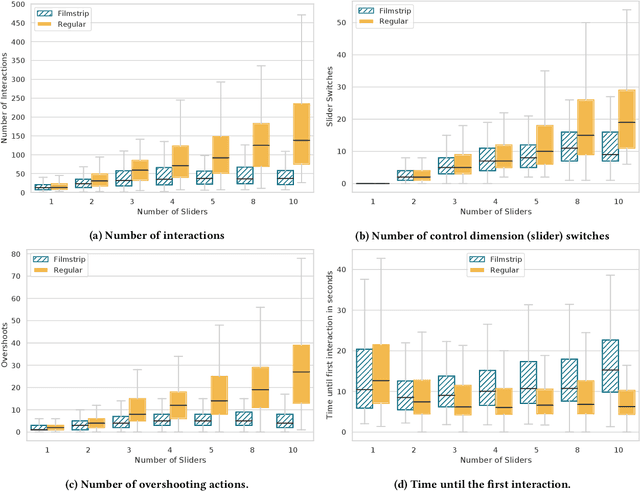
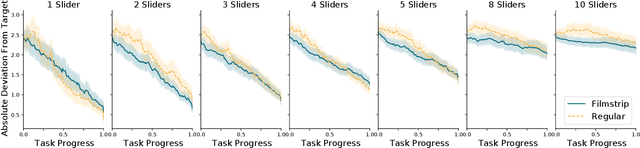
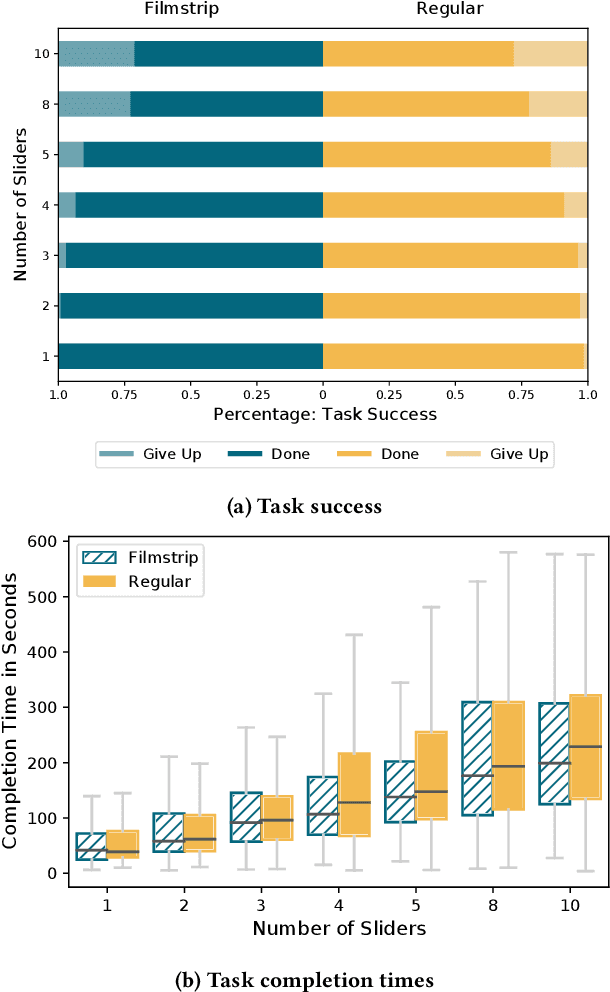
We investigate how multiple sliders with and without feedforward visualizations influence users' control of generative models. In an online study (N=138), we collected a dataset of people interacting with a generative adversarial network (StyleGAN2) in an image reconstruction task. We found that more control dimensions (sliders) significantly increase task difficulty and user actions. Visual feedforward partly mitigates this by enabling more goal-directed interaction. However, we found no evidence of faster or more accurate task performance. This indicates a tradeoff between feedforward detail and implied cognitive costs, such as attention. Moreover, we found that visualizations alone are not always sufficient for users to understand individual control dimensions. Our study quantifies fundamental UI design factors and resulting interaction behavior in this context, revealing opportunities for improvement in the UI design for interactive applications of generative models. We close by discussing design directions and further aspects.
Multi-Label Image Recognition with Multi-Class Attentional Regions
Jul 03, 2020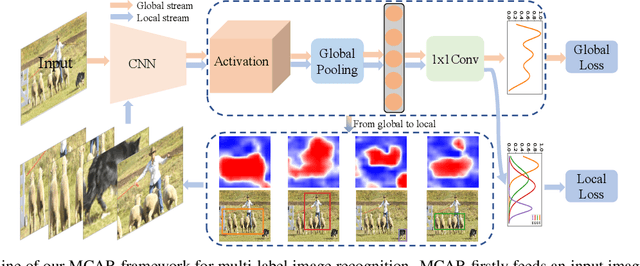
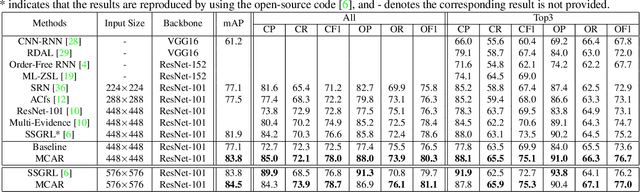
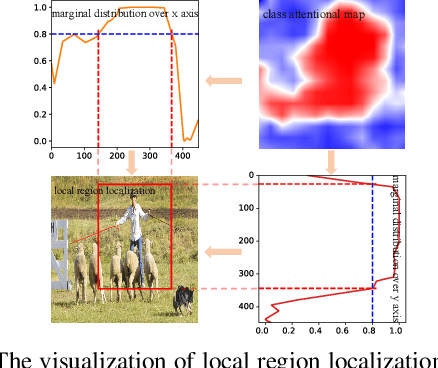
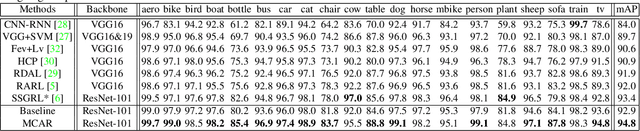
Multi-label image recognition is a practical and challenging task compared to single-label image classification. However, previous works may be suboptimal because of a great number of object proposals or complex attentional region generation modules. In this paper, we propose a simple but efficient two-stream framework to recognize multi-category objects from global image to local regions, similar to how human beings perceive objects. To bridge the gap between global and local streams, we propose a multi-class attentional region module which aims to make the number of attentional regions as small as possible and keep the diversity of these regions as high as possible. Our method can efficiently and effectively recognize multi-class objects with an affordable computation cost and a parameter-free region localization module. Over three benchmarks on multi-label image classification, we create new state-of-the-art results with a single model only using image semantics without label dependency. In addition, the effectiveness of the proposed method is extensively demonstrated under different factors such as global pooling strategy, input size and network architecture.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021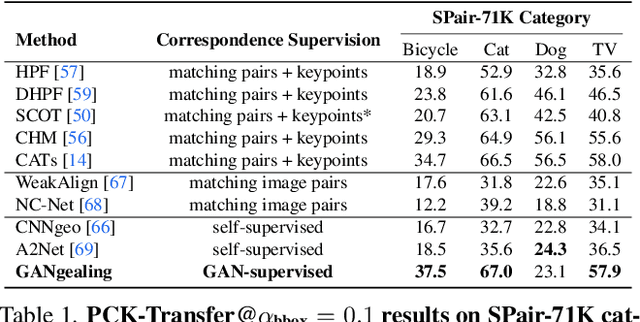
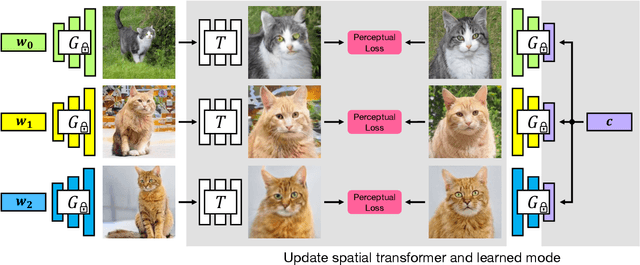


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.
PETA: Photo Albums Event Recognition using Transformers Attention
Sep 26, 2021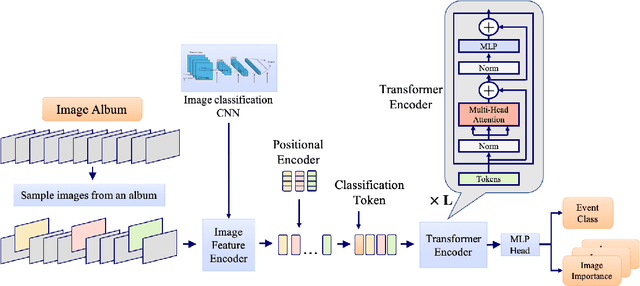
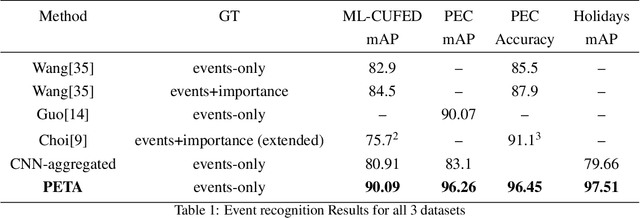

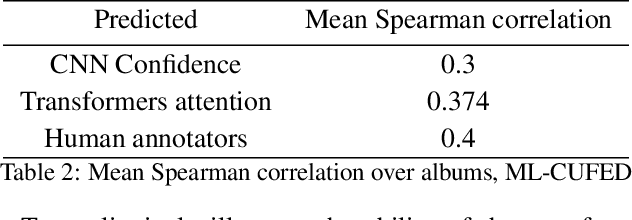
In recent years the amounts of personal photos captured increased significantly, giving rise to new challenges in multi-image understanding and high-level image understanding. Event recognition in personal photo albums presents one challenging scenario where life events are recognized from a disordered collection of images, including both relevant and irrelevant images. Event recognition in images also presents the challenge of high-level image understanding, as opposed to low-level image object classification. In absence of methods to analyze multiple inputs, previous methods adopted temporal mechanisms, including various forms of recurrent neural networks. However, their effective temporal window is local. In addition, they are not a natural choice given the disordered characteristic of photo albums. We address this gap with a tailor-made solution, combining the power of CNNs for image representation and transformers for album representation to perform global reasoning on image collection, offering a practical and efficient solution for photo albums event recognition. Our solution reaches state-of-the-art results on 3 prominent benchmarks, achieving above 90\% mAP on all datasets. We further explore the related image-importance task in event recognition, demonstrating how the learned attentions correlate with the human-annotated importance for this subjective task, thus opening the door for new applications.
Visualizing Color-wise Saliency of Black-Box Image Classification Models
Oct 06, 2020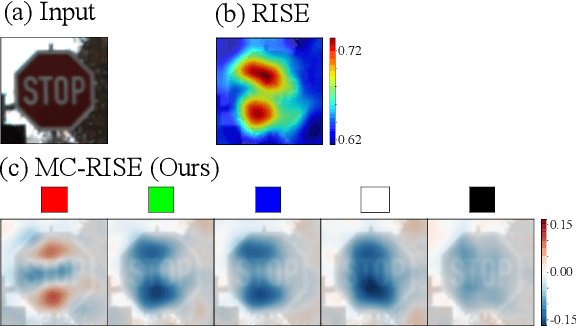
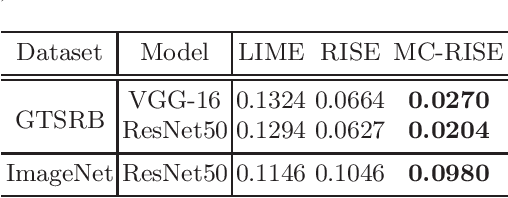
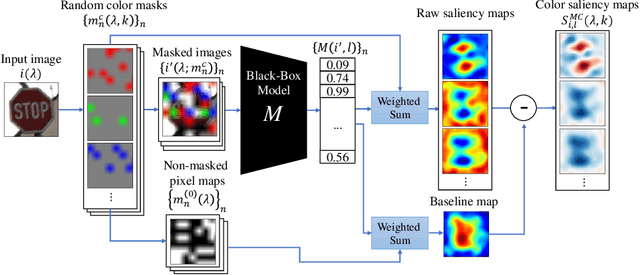
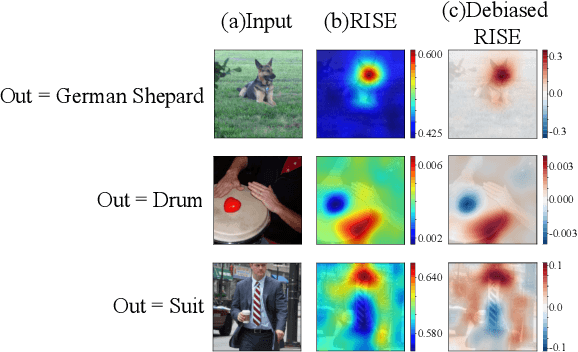
Image classification based on machine learning is being commonly used. However, a classification result given by an advanced method, including deep learning, is often hard to interpret. This problem of interpretability is one of the major obstacles in deploying a trained model in safety-critical systems. Several techniques have been proposed to address this problem; one of which is RISE, which explains a classification result by a heatmap, called a saliency map, which explains the significance of each pixel. We propose MC-RISE (Multi-Color RISE), which is an enhancement of RISE to take color information into account in an explanation. Our method not only shows the saliency of each pixel in a given image as the original RISE does, but the significance of color components of each pixel; a saliency map with color information is useful especially in the domain where the color information matters (e.g., traffic-sign recognition). We implemented MC-RISE and evaluate them using two datasets (GTSRB and ImageNet) to demonstrate the effectiveness of our methods in comparison with existing techniques for interpreting image classification results.
Shape constrained CNN for segmentation guided prediction of myocardial shape and pose parameters in cardiac MRI
Mar 02, 2022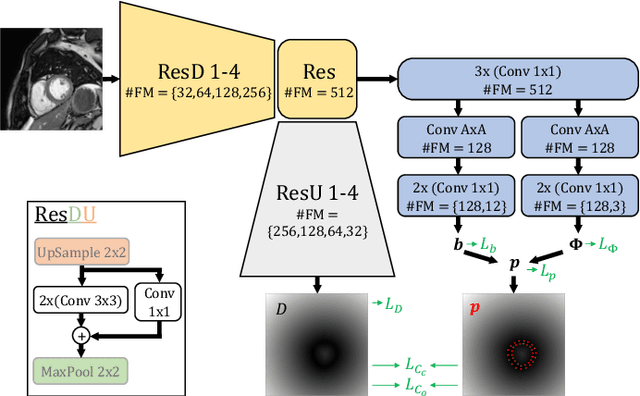
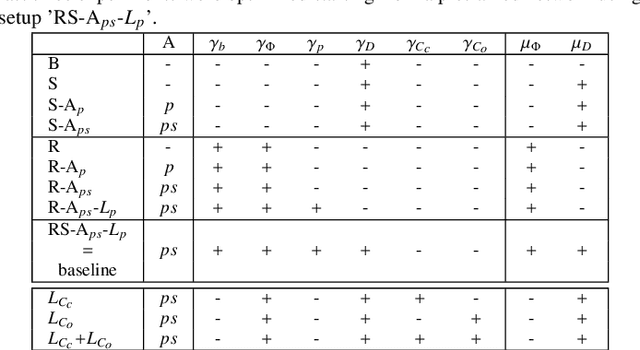
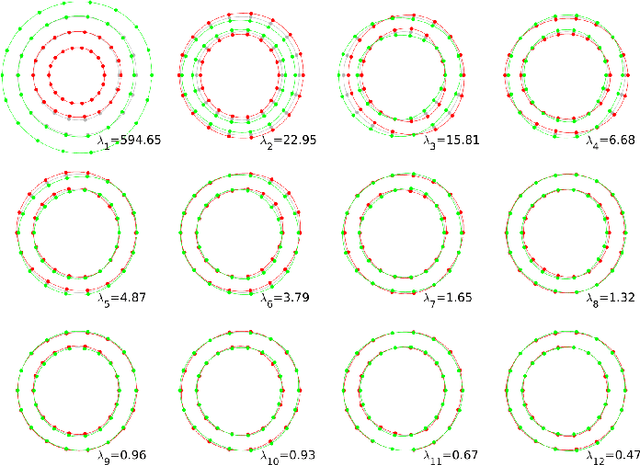
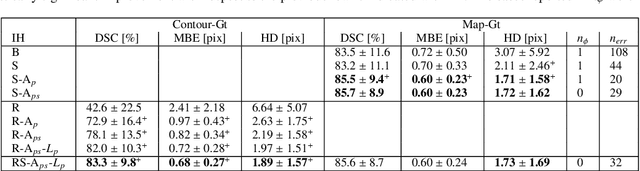
Semantic segmentation using convolutional neural networks (CNNs) is the state-of-the-art for many medical image segmentation tasks including myocardial segmentation in cardiac MR images. However, the predicted segmentation maps obtained from such standard CNN do not allow direct quantification of regional shape properties such as regional wall thickness. Furthermore, the CNNs lack explicit shape constraints, occasionally resulting in unrealistic segmentations. In this paper, we use a CNN to predict shape parameters of an underlying statistical shape model of the myocardium learned from a training set of images. Additionally, the cardiac pose is predicted, which allows to reconstruct the myocardial contours. The integrated shape model regularizes the predicted contours and guarantees realistic shapes. We enforce robustness of shape and pose prediction by simultaneously performing pixel-wise semantic segmentation during training and define two loss functions to impose consistency between the two predicted representations: one distance-based loss and one overlap-based loss. We evaluated the proposed method in a 5-fold cross validation on an in-house clinical dataset with 75 subjects and on the ACDC and LVQuan19 public datasets. We show the benefits of simultaneous semantic segmentation and the two newly defined loss functions for the prediction of shape parameters. Our method achieved a correlation of 99% for left ventricular (LV) area on the three datasets, between 91% and 97% for myocardial area, 98-99% for LV dimensions and between 80% and 92% for regional wall thickness.