 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DALE : Dark Region-Aware Low-light Image Enhancement
Aug 28, 2020


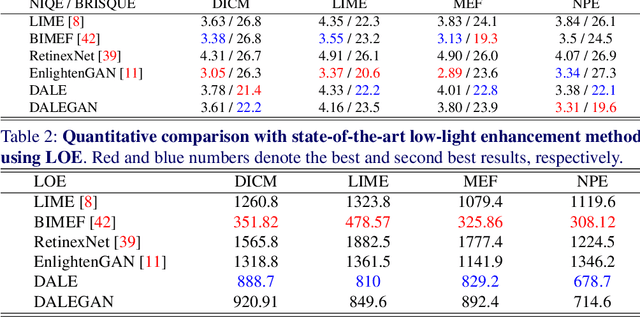

In this paper, we present a novel low-light image enhancement method called dark region-aware low-light image enhancement (DALE), where dark regions are accurately recognized by the proposed visual attention module and their brightness are intensively enhanced. Our method can estimate the visual attention in an efficient manner using super-pixels without any complicated process. Thus, the method can preserve the color, tone, and brightness of original images and prevents normally illuminated areas of the images from being saturated and distorted. Experimental results show that our method accurately identifies dark regions via the proposed visual attention, and qualitatively and quantitatively outperforms state-of-the-art methods.
Machine learning based lens-free imaging technique for field-portable cytometry
Mar 03, 2022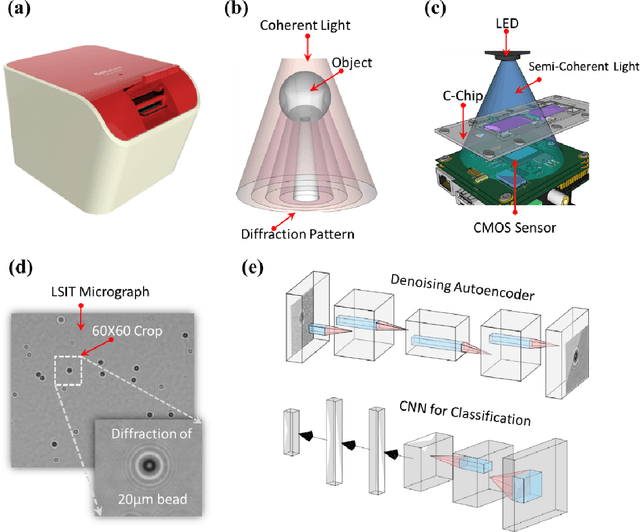
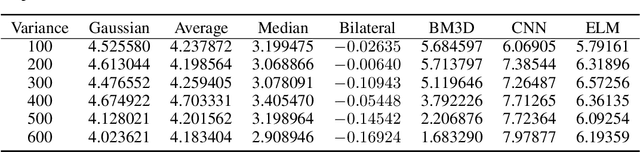


Lens-free Shadow Imaging Technique (LSIT) is a well-established technique for the characterization of microparticles and biological cells. Due to its simplicity and cost-effectiveness, various low-cost solutions have been evolved, such as automatic analysis of complete blood count (CBC), cell viability, 2D cell morphology, 3D cell tomography, etc. The developed auto characterization algorithm so far for this custom-developed LSIT cytometer was based on the hand-crafted features of the cell diffraction patterns from the LSIT cytometer, that were determined from our empirical findings on thousands of samples of individual cell types, which limit the system in terms of induction of a new cell type for auto classification or characterization. Further, its performance is suffering from poor image (cell diffraction pattern) signatures due to its small signal or background noise. In this work, we address these issues by leveraging the artificial intelligence-powered auto signal enhancing scheme such as denoising autoencoder and adaptive cell characterization technique based on the transfer of learning in deep neural networks. The performance of our proposed method shows an increase in accuracy >98% along with the signal enhancement of >5 dB for most of the cell types, such as Red Blood Cell (RBC) and White Blood Cell (WBC). Furthermore, the model is adaptive to learn new type of samples within a few learning iterations and able to successfully classify the newly introduced sample along with the existing other sample types.
* Published in Biosensors Journal
Street-view Panoramic Video Synthesis from a Single Satellite Image
Dec 17, 2020
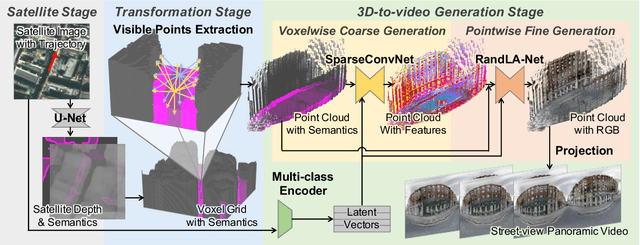


We present a novel method for synthesizing both temporally and geometrically consistent street-view panoramic video from a given single satellite image and camera trajectory. Existing cross-view synthesis approaches focus more on images, while video synthesis in such a case has not yet received enough attention. Single image synthesis approaches are not well suited for video synthesis since they lack temporal consistency which is a crucial property of videos. To this end, our approach explicitly creates a 3D point cloud representation of the scene and maintains dense 3D-2D correspondences across frames that reflect the geometric scene configuration inferred from the satellite view. We implement a cascaded network architecture with two hourglass modules for successive coarse and fine generation for colorizing the point cloud from the semantics and per-class latent vectors. By leveraging computed correspondences, the produced street-view video frames adhere to the 3D geometric scene structure and maintain temporal consistency. Qualitative and quantitative experiments demonstrate superior results compared to other state-of-the-art cross-view synthesis approaches that either lack temporal or geometric consistency. To the best of our knowledge, our work is the first work to synthesize cross-view images to video.
One-Shot Image Classification by Learning to Restore Prototypes
May 04, 2020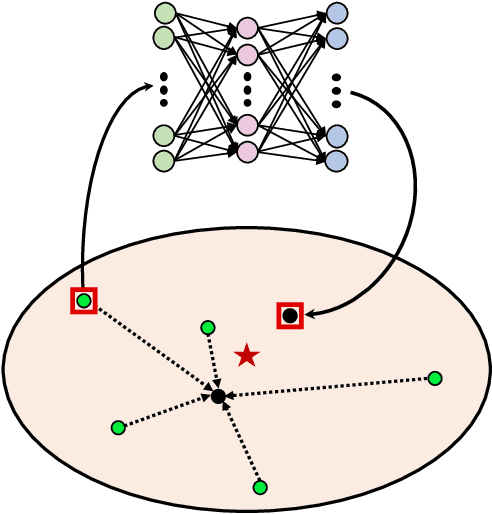


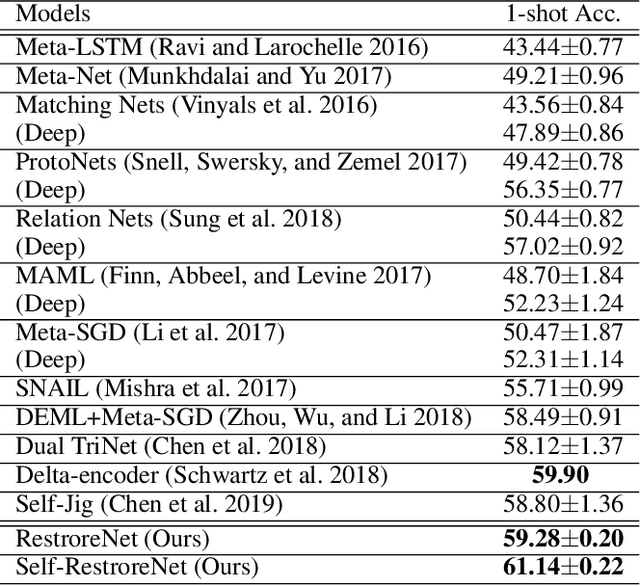
One-shot image classification aims to train image classifiers over the dataset with only one image per category. It is challenging for modern deep neural networks that typically require hundreds or thousands of images per class. In this paper, we adopt metric learning for this problem, which has been applied for few- and many-shot image classification by comparing the distance between the test image and the center of each class in the feature space. However, for one-shot learning, the existing metric learning approaches would suffer poor performance because the single training image may not be representative of the class. For example, if the image is far away from the class center in the feature space, the metric-learning based algorithms are unlikely to make correct predictions for the test images because the decision boundary is shifted by this noisy image. To address this issue, we propose a simple yet effective regression model, denoted by RestoreNet, which learns a class agnostic transformation on the image feature to move the image closer to the class center in the feature space. Experiments demonstrate that RestoreNet obtains superior performance over the state-of-the-art methods on a broad range of datasets. Moreover, RestoreNet can be easily combined with other methods to achieve further improvement.
Distilled Dual-Encoder Model for Vision-Language Understanding
Dec 16, 2021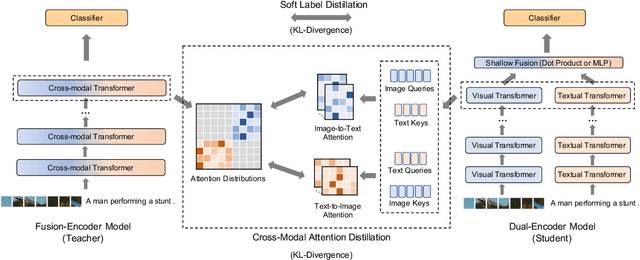
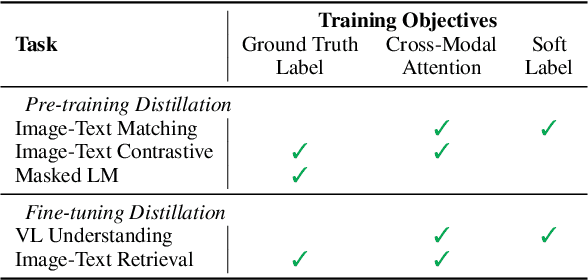

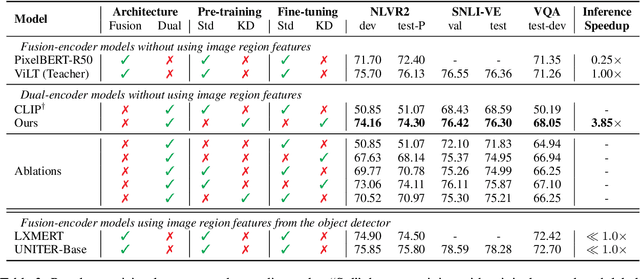
We propose a cross-modal attention distillation framework to train a dual-encoder model for vision-language understanding tasks, such as visual reasoning and visual question answering. Dual-encoder models have a faster inference speed than fusion-encoder models and enable the pre-computation of images and text during inference. However, the shallow interaction module used in dual-encoder models is insufficient to handle complex vision-language understanding tasks. In order to learn deep interactions of images and text, we introduce cross-modal attention distillation, which uses the image-to-text and text-to-image attention distributions of a fusion-encoder model to guide the training of our dual-encoder model. In addition, we show that applying the cross-modal attention distillation for both pre-training and fine-tuning stages achieves further improvements. Experimental results demonstrate that the distilled dual-encoder model achieves competitive performance for visual reasoning, visual entailment and visual question answering tasks while enjoying a much faster inference speed than fusion-encoder models. Our code and models will be publicly available at https://github.com/kugwzk/Distilled-DualEncoder.
DeepCapture: Image Spam Detection Using Deep Learning and Data Augmentation
Jun 16, 2020
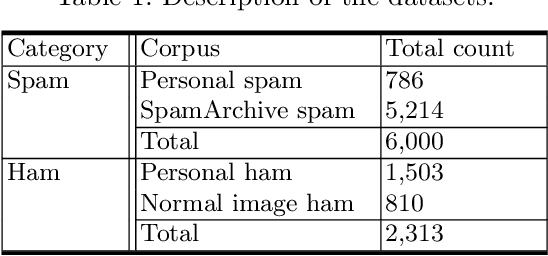

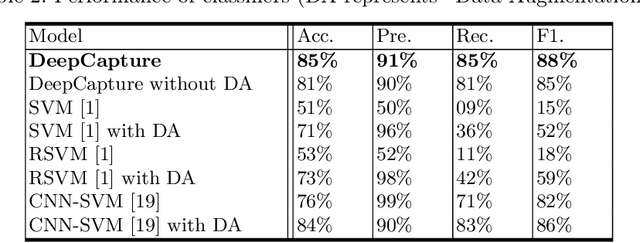
Image spam emails are often used to evade text-based spam filters that detect spam emails with their frequently used keywords. In this paper, we propose a new image spam email detection tool called DeepCapture using a convolutional neural network (CNN) model. There have been many efforts to detect image spam emails, but there is a significant performance degrade against entirely new and unseen image spam emails due to overfitting during the training phase. To address this challenging issue, we mainly focus on developing a more robust model to address the overfitting problem. Our key idea is to build a CNN-XGBoost framework consisting of eight layers only with a large number of training samples using data augmentation techniques tailored towards the image spam detection task. To show the feasibility of DeepCapture, we evaluate its performance with publicly available datasets consisting of 6,000 spam and 2,313 non-spam image samples. The experimental results show that DeepCapture is capable of achieving an F1-score of 88%, which has a 6% improvement over the best existing spam detection model CNN-SVM with an F1-score of 82%. Moreover, DeepCapture outperformed existing image spam detection solutions against new and unseen image datasets.
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
Nov 14, 2020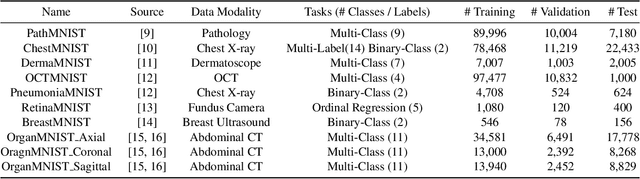
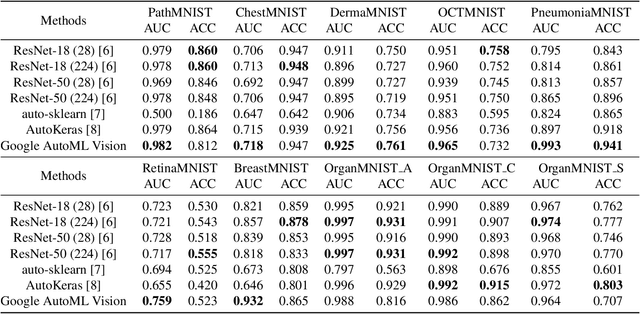

We present MedMNIST, a collection of 10 pre-processed medical open datasets. MedMNIST is standardized to perform classification tasks on lightweight 28x28 images, which requires no background knowledge. Covering the primary data modalities in medical image analysis, it is diverse on data scale (from 100 to 100,000) and tasks (binary/multi-class, ordinal regression and multi-label). MedMNIST could be used for educational purpose, rapid prototyping, multi-modal machine learning or AutoML in medical image analysis. Moreover, MedMNIST Classification Decathlon is designed to benchmark AutoML algorithms on all 10 datasets; We have compared several baseline methods, including open-source or commercial AutoML tools. The datasets, evaluation code and baseline methods for MedMNIST are publicly available at https://medmnist.github.io/.
No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models
Feb 06, 2022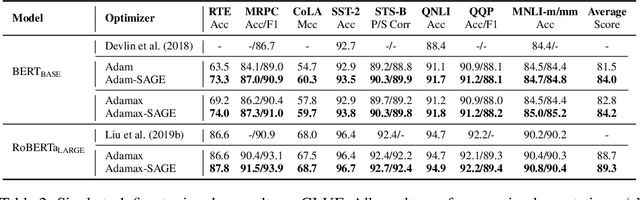
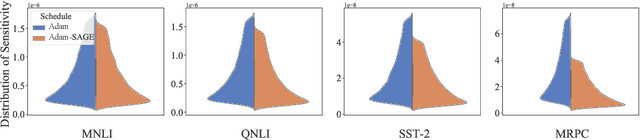

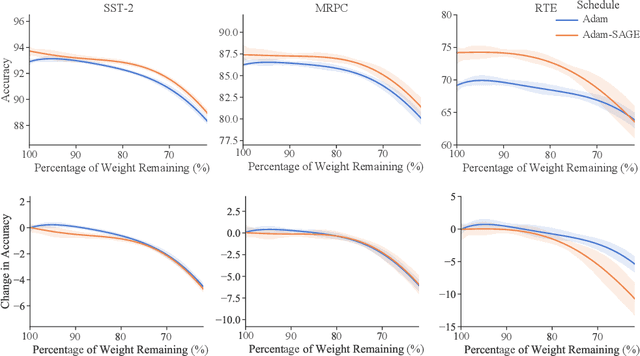
Recent research has shown the existence of significant redundancy in large Transformer models. One can prune the redundant parameters without significantly sacrificing the generalization performance. However, we question whether the redundant parameters could have contributed more if they were properly trained. To answer this question, we propose a novel training strategy that encourages all parameters to be trained sufficiently. Specifically, we adaptively adjust the learning rate for each parameter according to its sensitivity, a robust gradient-based measure reflecting this parameter's contribution to the model performance. A parameter with low sensitivity is redundant, and we improve its fitting by increasing its learning rate. In contrast, a parameter with high sensitivity is well-trained, and we regularize it by decreasing its learning rate to prevent further overfitting. We conduct extensive experiments on natural language understanding, neural machine translation, and image classification to demonstrate the effectiveness of the proposed schedule. Analysis shows that the proposed schedule indeed reduces the redundancy and improves generalization performance.
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks
Jan 15, 2022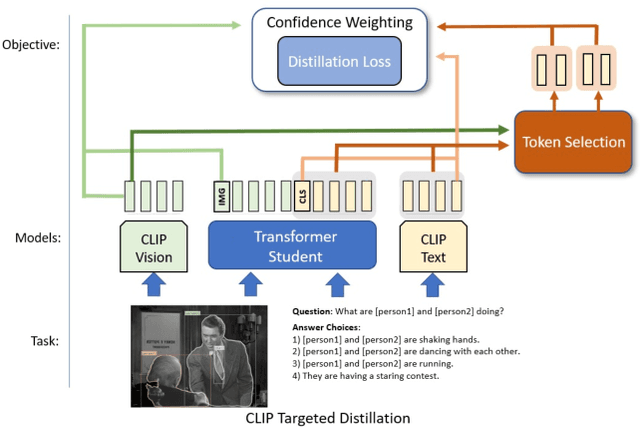
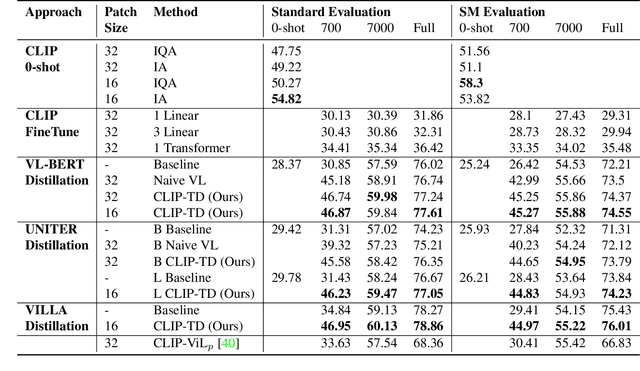
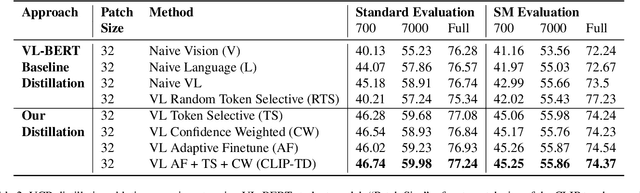

Contrastive language-image pretraining (CLIP) links vision and language modalities into a unified embedding space, yielding the tremendous potential for vision-language (VL) tasks. While early concurrent works have begun to study this potential on a subset of tasks, important questions remain: 1) What is the benefit of CLIP on unstudied VL tasks? 2) Does CLIP provide benefit in low-shot or domain-shifted scenarios? 3) Can CLIP improve existing approaches without impacting inference or pretraining complexity? In this work, we seek to answer these questions through two key contributions. First, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data availability constraints and conditions of domain shift. Second, we propose an approach, named CLIP Targeted Distillation (CLIP-TD), to intelligently distill knowledge from CLIP into existing architectures using a dynamically weighted objective applied to adaptively selected tokens per instance. Experiments demonstrate that our proposed CLIP-TD leads to exceptional gains in the low-shot (up to 51.9%) and domain-shifted (up to 71.3%) conditions of VCR, while simultaneously improving performance under standard fully-supervised conditions (up to 2%), achieving state-of-art performance on VCR compared to other single models that are pretrained with image-text data only. On SNLI-VE, CLIP-TD produces significant gains in low-shot conditions (up to 6.6%) as well as fully supervised (up to 3%). On VQA, CLIP-TD provides improvement in low-shot (up to 9%), and in fully-supervised (up to 1.3%). Finally, CLIP-TD outperforms concurrent works utilizing CLIP for finetuning, as well as baseline naive distillation approaches. Code will be made available.
Multi-Label Image Recognition with Multi-Class Attentional Regions
Jul 03, 2020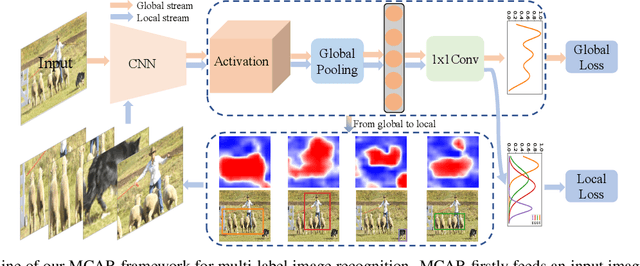
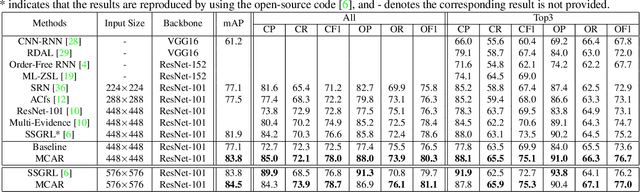
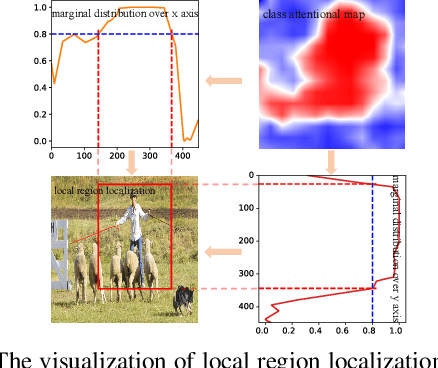
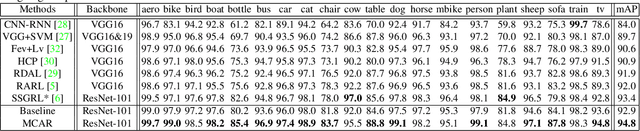
Multi-label image recognition is a practical and challenging task compared to single-label image classification. However, previous works may be suboptimal because of a great number of object proposals or complex attentional region generation modules. In this paper, we propose a simple but efficient two-stream framework to recognize multi-category objects from global image to local regions, similar to how human beings perceive objects. To bridge the gap between global and local streams, we propose a multi-class attentional region module which aims to make the number of attentional regions as small as possible and keep the diversity of these regions as high as possible. Our method can efficiently and effectively recognize multi-class objects with an affordable computation cost and a parameter-free region localization module. Over three benchmarks on multi-label image classification, we create new state-of-the-art results with a single model only using image semantics without label dependency. In addition, the effectiveness of the proposed method is extensively demonstrated under different factors such as global pooling strategy, input size and network architecture.