 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Brain Cancer Survival Prediction on Treatment-na ive MRI using Deep Anchor Attention Learning with Vision Transformer
Feb 03, 2022
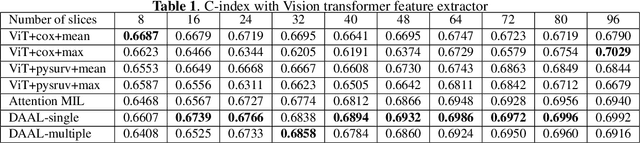
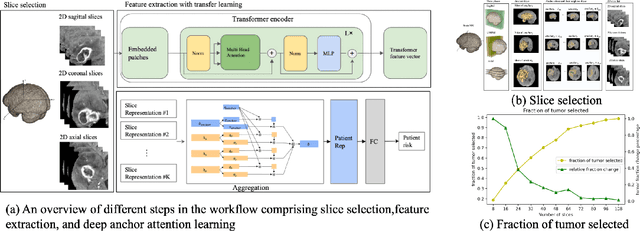
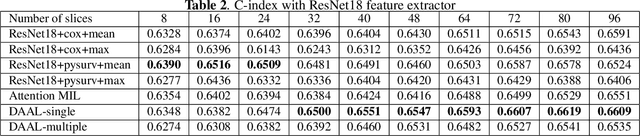
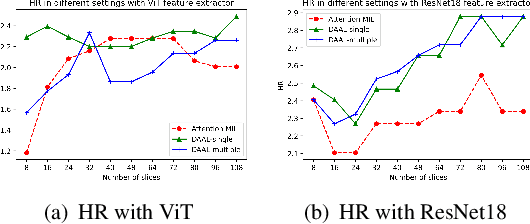
Image-based brain cancer prediction models, based on radiomics, quantify the radiologic phenotype from magnetic resonance imaging (MRI). However, these features are difficult to reproduce because of variability in acquisition and preprocessing pipelines. Despite evidence of intra-tumor phenotypic heterogeneity, the spatial diversity between different slices within an MRI scan has been relatively unexplored using such methods. In this work, we propose a deep anchor attention aggregation strategy with a Vision Transformer to predict survival risk for brain cancer patients. A Deep Anchor Attention Learning (DAAL) algorithm is proposed to assign different weights to slice-level representations with trainable distance measurements. We evaluated our method on N = 326 MRIs. Our results outperformed attention multiple instance learning-based techniques. DAAL highlights the importance of critical slices and corroborates the clinical intuition that inter-slice spatial diversity can reflect disease severity and is implicated in outcome.
Informative Sample Mining Network for Multi-Domain Image-to-Image Translation
Jan 05, 2020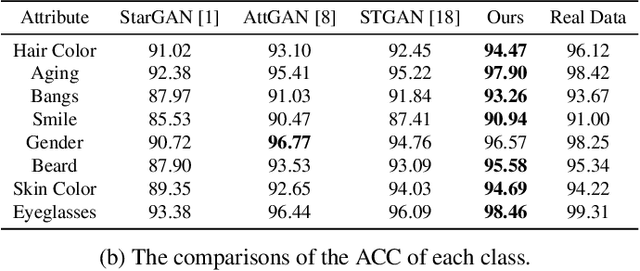

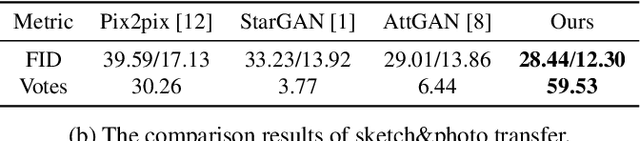
The performance of multi-domain image-to-image translation has been significantly improved by recent progress in deep generative models. Existing approaches can use a unified model to achieve translations between all the visual domains. However, their outcomes are far from satisfying when there are large domain variations. In this paper, we reveal that improving the strategy of sample selection is an effective solution. To select informative samples, we dynamically estimate sample importance during the training of Generative Adversarial Networks, presenting Informative Sample Mining Network. We theoretically analyze the relationship between the sample importance and the prediction of the global optimal discriminator. Then a practical importance estimation function based on general discriminators is derived. In addition, we propose a novel multi-stage sample training scheme to reduce sample hardness while preserving sample informativeness. Extensive experiments on a wide range of specific image-to-image translation tasks are conducted, and the results demonstrate our superiority over current state-of-the-art methods.
Mapping DNN Embedding Manifolds for Network Generalization Prediction
Feb 03, 2022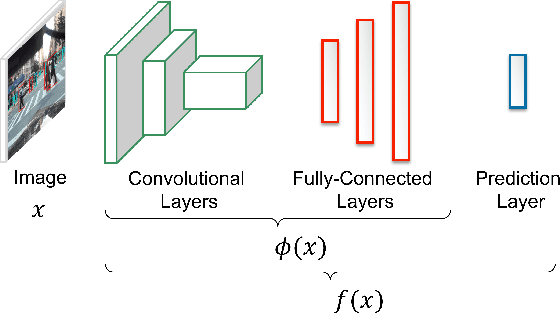
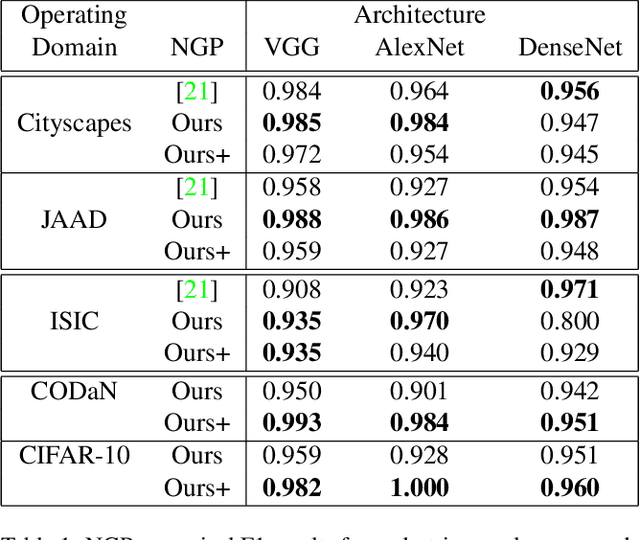

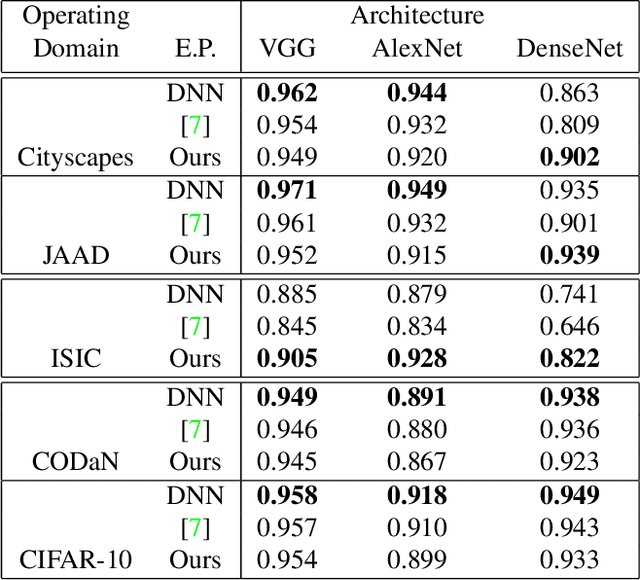
Understanding Deep Neural Network (DNN) performance in changing conditions is essential for deploying DNNs in safety critical applications with unconstrained environments, e.g., perception for self-driving vehicles or medical image analysis. Recently, the task of Network Generalization Prediction (NGP) has been proposed to predict how a DNN will generalize in a new operating domain. Previous NGP approaches have relied on labeled metadata and known distributions for the new operating domains. In this study, we propose the first NGP approach that predicts DNN performance based solely on how unlabeled images from an external operating domain map in the DNN embedding space. We demonstrate this technique for pedestrian, melanoma, and animal classification tasks and show state of the art NGP in 13 of 15 NGP tasks without requiring domain knowledge. Additionally, we show that our NGP embedding maps can be used to identify misclassified images when the DNN performance is poor.
Lossless Image Compression through Super-Resolution
Apr 06, 2020

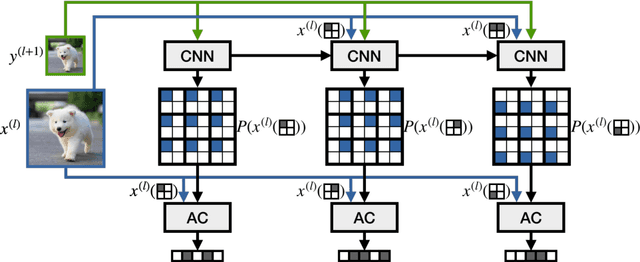
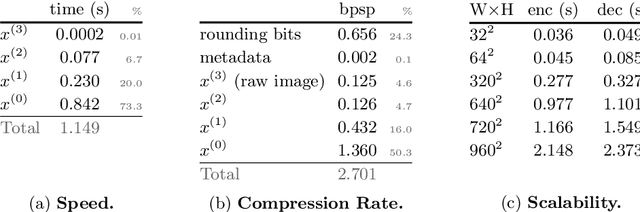
We introduce a simple and efficient lossless image compression algorithm. We store a low resolution version of an image as raw pixels, followed by several iterations of lossless super-resolution. For lossless super-resolution, we predict the probability of a high-resolution image, conditioned on the low-resolution input, and use entropy coding to compress this super-resolution operator. Super-Resolution based Compression (SReC) is able to achieve state-of-the-art compression rates with practical runtimes on large datasets. Code is available online at https://github.com/caoscott/SReC.
Danish Airs and Grounds: A Dataset for Aerial-to-Street-Level Place Recognition and Localization
Feb 03, 2022


Place recognition and visual localization are particularly challenging in wide baseline configurations. In this paper, we contribute with the \emph{Danish Airs and Grounds} (DAG) dataset, a large collection of street-level and aerial images targeting such cases. Its main challenge lies in the extreme viewing-angle difference between query and reference images with consequent changes in illumination and perspective. The dataset is larger and more diverse than current publicly available data, including more than 50 km of road in urban, suburban and rural areas. All images are associated with accurate 6-DoF metadata that allows the benchmarking of visual localization methods. We also propose a map-to-image re-localization pipeline, that first estimates a dense 3D reconstruction from the aerial images and then matches query street-level images to street-level renderings of the 3D model. The dataset can be downloaded at: https://frederikwarburg.github.io/DAG
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 29, 2020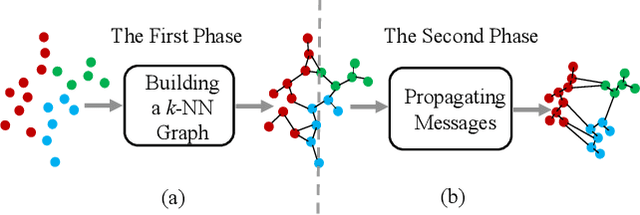

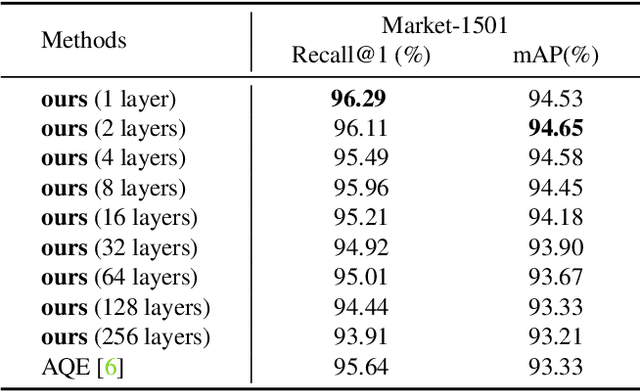
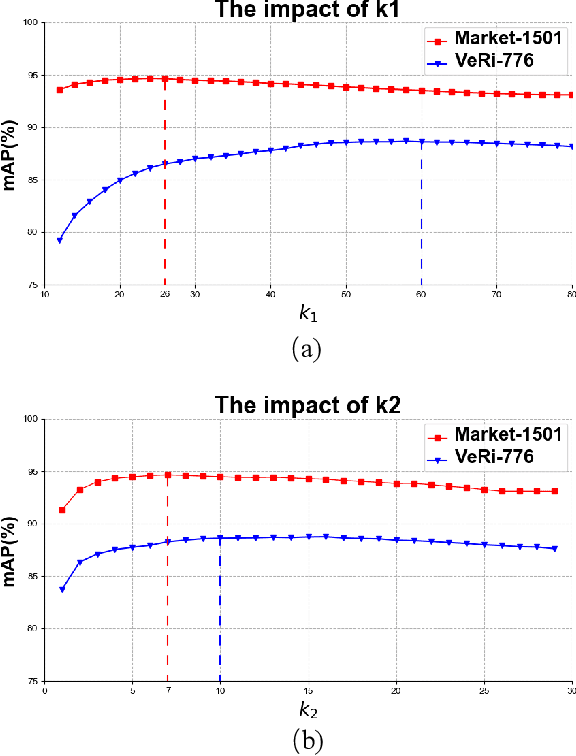
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.
A Note on the Implicit Bias Towards Minimal Depth of Deep Neural Networks
Feb 18, 2022
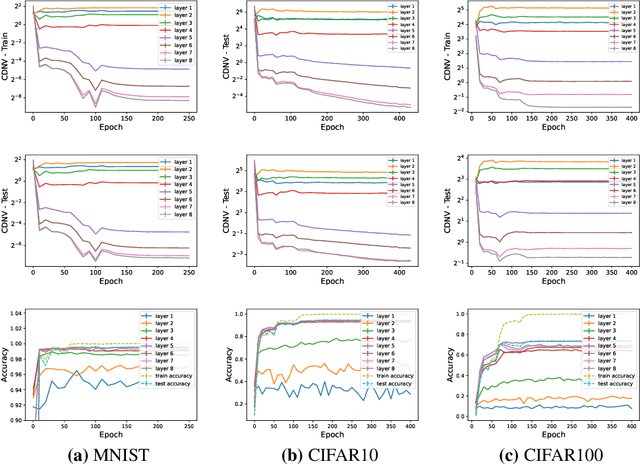
Deep learning systems have steadily advanced the state of the art in a wide variety of benchmarks, demonstrating impressive performance in tasks ranging from image classification \citep{taigman2014deepface,zhai2021scaling}, language processing \citep{devlin-etal-2019-bert,NEURIPS2020_1457c0d6}, open-ended environments \citep{SilverHuangEtAl16nature,arulkumaran2019alphastar}, to coding \citep{chen2021evaluating}. A central aspect that enables the success of these systems is the ability to train deep models instead of wide shallow ones \citep{7780459}. Intuitively, a neural network is decomposed into hierarchical representations from raw data to high-level, more abstract features. While training deep neural networks repetitively achieves superior performance against their shallow counterparts, an understanding of the role of depth in representation learning is still lacking. In this work, we suggest a new perspective on understanding the role of depth in deep learning. We hypothesize that {\bf\em SGD training of overparameterized neural networks exhibits an implicit bias that favors solutions of minimal effective depth}. Namely, SGD trains neural networks for which the top several layers are redundant. To evaluate the redundancy of layers, we revisit the recently discovered phenomenon of neural collapse \citep{Papyan24652,han2021neural}.
Morph Detection Enhanced by Structured Group Sparsity
Nov 29, 2021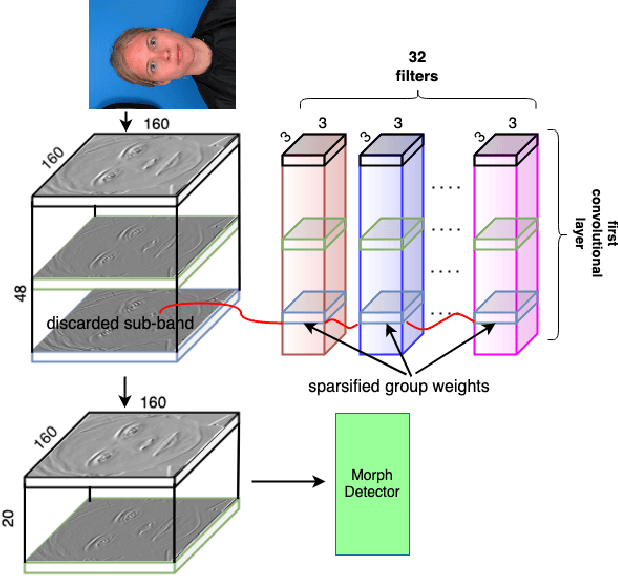
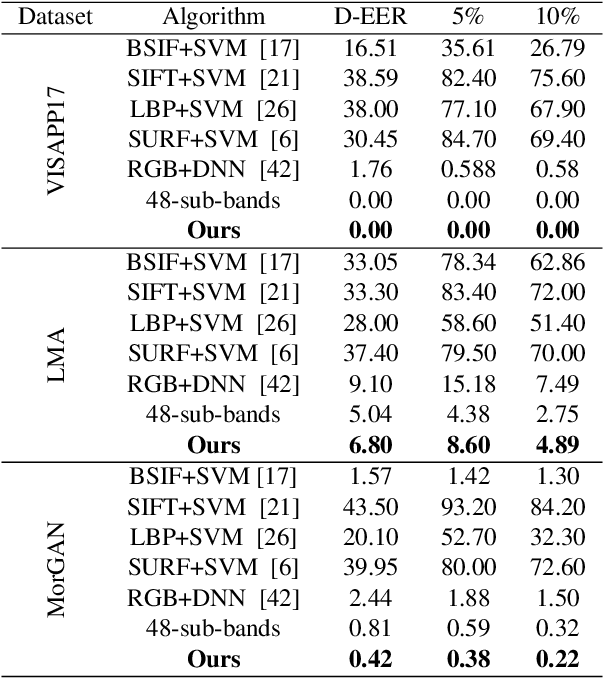
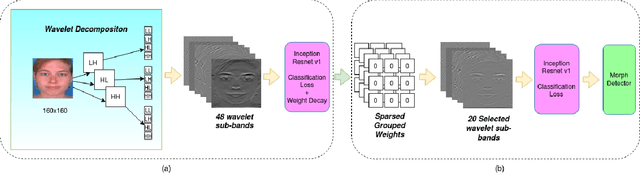
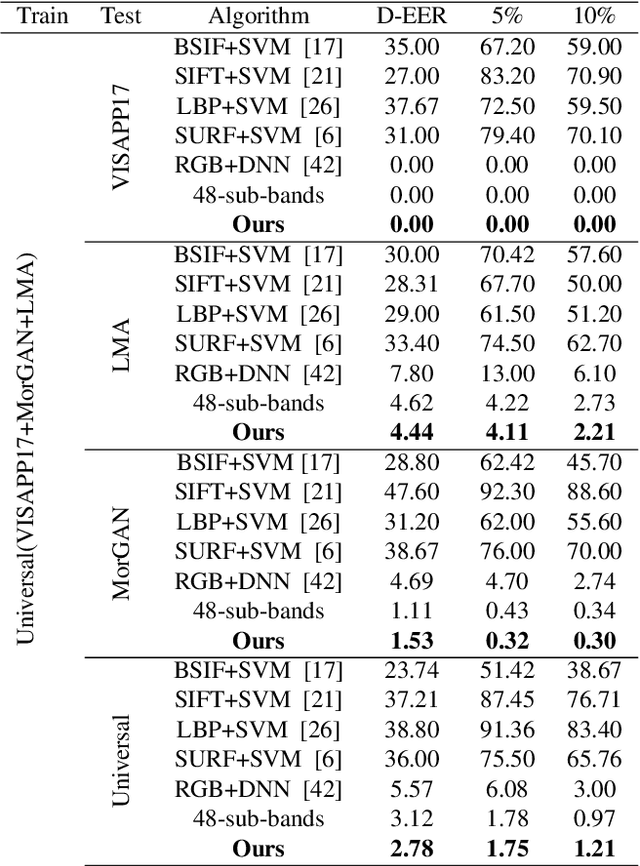
In this paper, we consider the challenge of face morphing attacks, which substantially undermine the integrity of face recognition systems such as those adopted for use in border protection agencies. Morph detection can be formulated as extracting fine-grained representations, where local discriminative features are harnessed for learning a hypothesis. To acquire discriminative features at different granularity as well as a decoupled spectral information, we leverage wavelet domain analysis to gain insight into the spatial-frequency content of a morphed face. As such, instead of using images in the RGB domain, we decompose every image into its wavelet sub-bands using 2D wavelet decomposition and a deep supervised feature selection scheme is employed to find the most discriminative wavelet sub-bands of input images. To this end, we train a Deep Neural Network (DNN) morph detector using the decomposed wavelet sub-bands of the morphed and bona fide images. In the training phase, our structured group sparsity-constrained DNN picks the most discriminative wavelet sub-bands out of all the sub-bands, with which we retrain our DNN, resulting in a precise detection of morphed images when inference is achieved on a probe image. The efficacy of our deep morph detector which is enhanced by structured group lasso is validated through experiments on three facial morph image databases, i.e., VISAPP17, LMA, and MorGAN.
Deep Metric Learning-based Image Retrieval System for Chest Radiograph and its Clinical Applications in COVID-19
Nov 26, 2020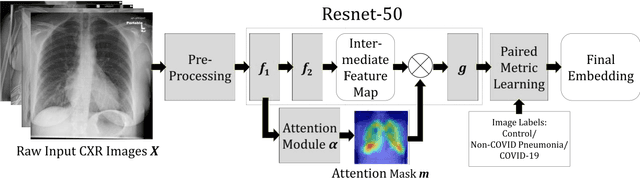


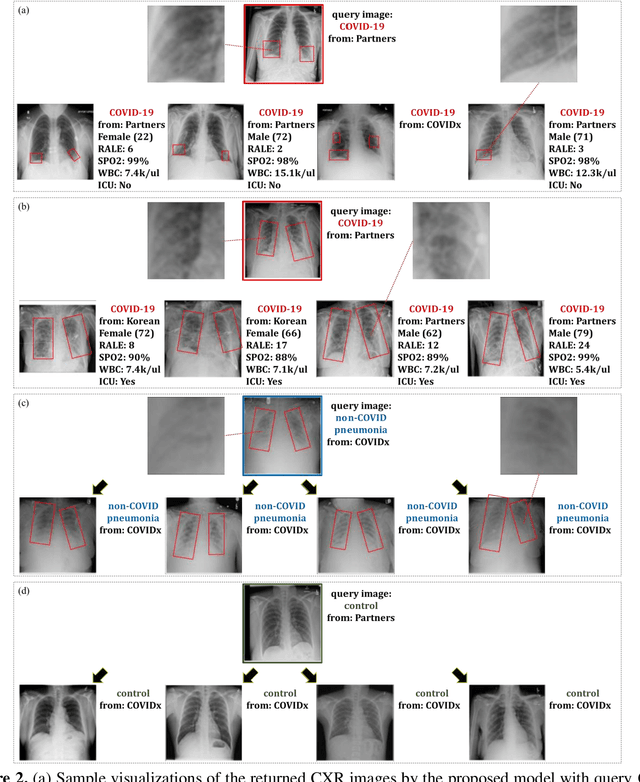
In recent years, deep learning-based image analysis methods have been widely applied in computer-aided detection, diagnosis and prognosis, and has shown its value during the public health crisis of the novel coronavirus disease 2019 (COVID-19) pandemic. Chest radiograph (CXR) has been playing a crucial role in COVID-19 patient triaging, diagnosing and monitoring, particularly in the United States. Considering the mixed and unspecific signals in CXR, an image retrieval model of CXR that provides both similar images and associated clinical information can be more clinically meaningful than a direct image diagnostic model. In this work we develop a novel CXR image retrieval model based on deep metric learning. Unlike traditional diagnostic models which aims at learning the direct mapping from images to labels, the proposed model aims at learning the optimized embedding space of images, where images with the same labels and similar contents are pulled together. It utilizes multi-similarity loss with hard-mining sampling strategy and attention mechanism to learn the optimized embedding space, and provides similar images to the query image. The model is trained and validated on an international multi-site COVID-19 dataset collected from 3 different sources. Experimental results of COVID-19 image retrieval and diagnosis tasks show that the proposed model can serve as a robust solution for CXR analysis and patient management for COVID-19. The model is also tested on its transferability on a different clinical decision support task, where the pre-trained model is applied to extract image features from a new dataset without any further training. These results demonstrate our deep metric learning based image retrieval model is highly efficient in the CXR retrieval, diagnosis and prognosis, and thus has great clinical value for the treatment and management of COVID-19 patients.
Dynamic Low-light Imaging with Quanta Image Sensors
Jul 16, 2020
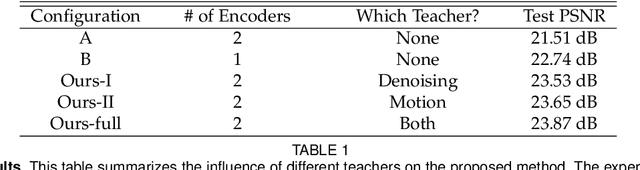


Imaging in low light is difficult because the number of photons arriving at the sensor is low. Imaging dynamic scenes in low-light environments is even more difficult because as the scene moves, pixels in adjacent frames need to be aligned before they can be denoised. Conventional CMOS image sensors (CIS) are at a particular disadvantage in dynamic low-light settings because the exposure cannot be too short lest the read noise overwhelms the signal. We propose a solution using Quanta Image Sensors (QIS) and present a new image reconstruction algorithm. QIS are single-photon image sensors with photon counting capabilities. Studies over the past decade have confirmed the effectiveness of QIS for low-light imaging but reconstruction algorithms for dynamic scenes in low light remain an open problem. We fill the gap by proposing a student-teacher training protocol that transfers knowledge from a motion teacher and a denoising teacher to a student network. We show that dynamic scenes can be reconstructed from a burst of frames at a photon level of 1 photon per pixel per frame. Experimental results confirm the advantages of the proposed method compared to existing methods.