 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Deformation Diffeomorphic Image Registration with Laplacian Pyramid Networks
Jun 30, 2020
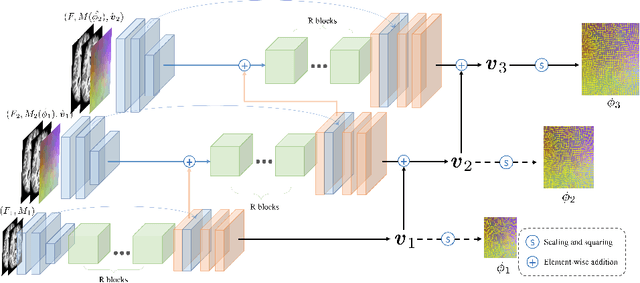
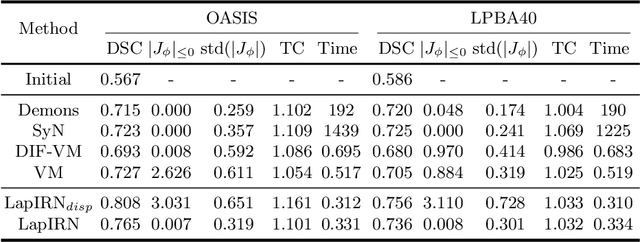
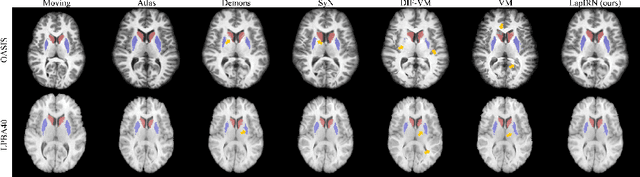
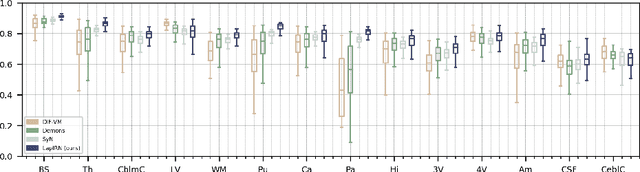
Deep learning-based methods have recently demonstrated promising results in deformable image registration for a wide range of medical image analysis tasks. However, existing deep learning-based methods are usually limited to small deformation settings, and desirable properties of the transformation including bijective mapping and topology preservation are often being ignored by these approaches. In this paper, we propose a deep Laplacian Pyramid Image Registration Network, which can solve the image registration optimization problem in a coarse-to-fine fashion within the space of diffeomorphic maps. Extensive quantitative and qualitative evaluations on two MR brain scan datasets show that our method outperforms the existing methods by a significant margin while maintaining desirable diffeomorphic properties and promising registration speed.
High-Performance Large-Scale Image Recognition Without Normalization
Feb 11, 2021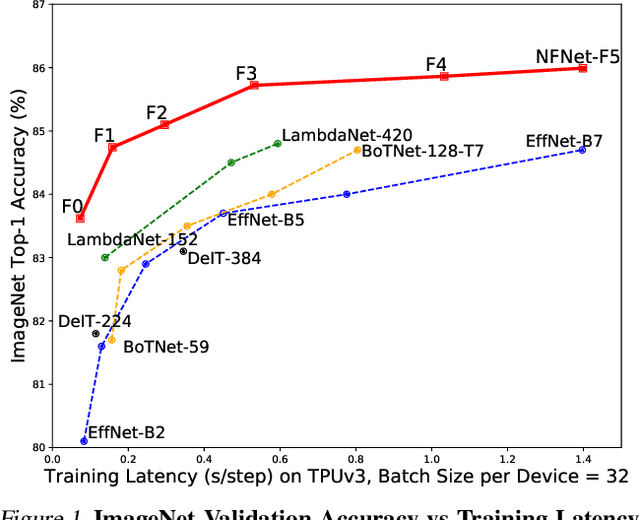
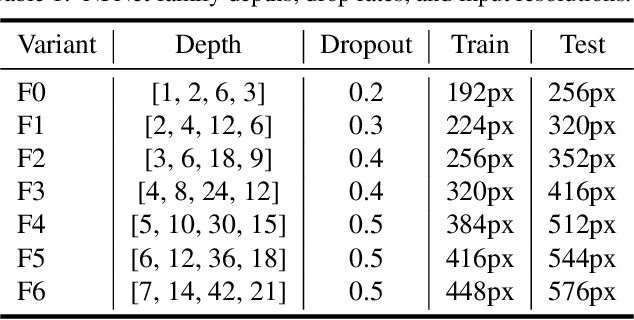
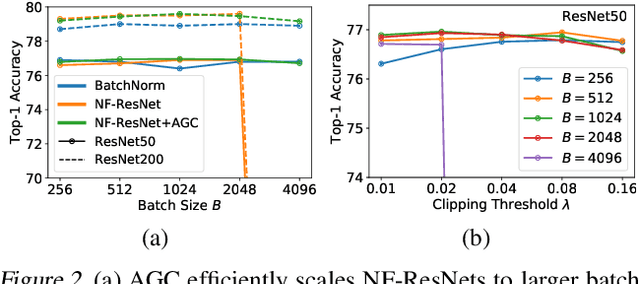
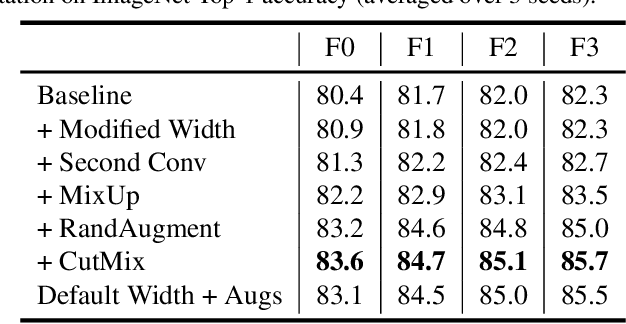
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when finetuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%. Our code is available at https://github.com/deepmind/ deepmind-research/tree/master/nfnets
MIINet: An Image Quality Improvement Framework for Supporting Medical Diagnosis
Nov 28, 2020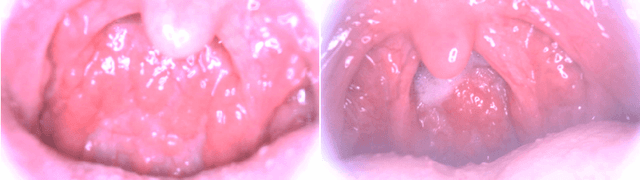
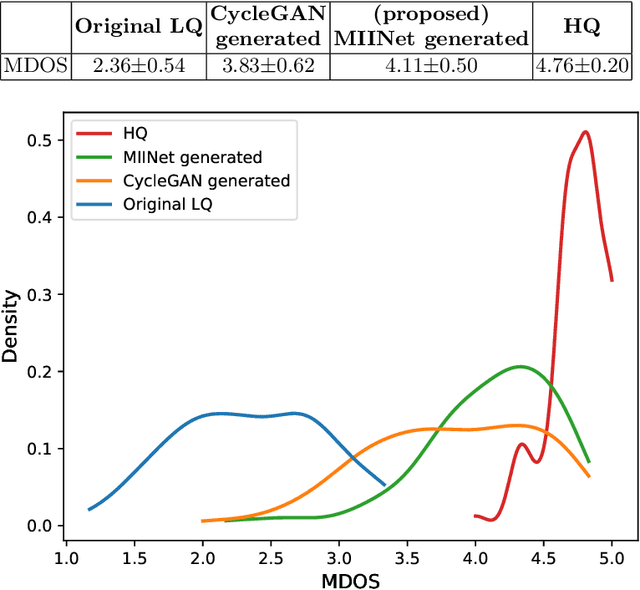

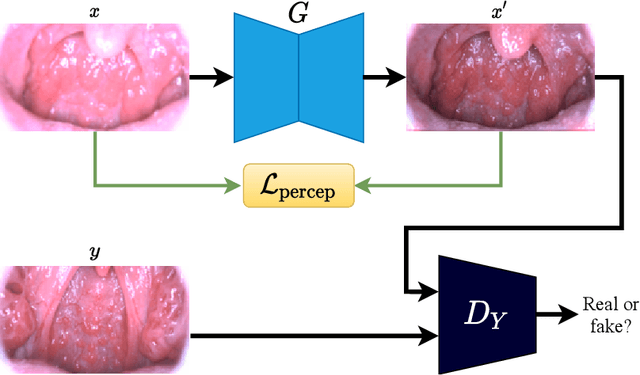
Medical images have been indispensable and useful tools for supporting medical experts in making diagnostic decisions. However, taken medical images especially throat and endoscopy images are normally hazy, lack of focus, or uneven illumination. Thus, these could difficult the diagnosis process for doctors. In this paper, we propose MIINet, a novel image-to-image translation network for improving quality of medical images by unsupervised translating low-quality images to the high-quality clean version. Our MIINet is not only capable of generating high-resolution clean images, but also preserving the attributes of original images, making the diagnostic more favorable for doctors. Experiments on dehazing 100 practical throat images show that our MIINet largely improves the mean doctor opinion score (MDOS), which assesses the quality and the reproducibility of the images from the baseline of 2.36 to 4.11, while dehazed images by CycleGAN got lower score of 3.83. The MIINet is confirmed by three physicians to be satisfying in supporting throat disease diagnostic from original low-quality images.
Adversarial Uni- and Multi-modal Stream Networks for Multimodal Image Registration
Jul 06, 2020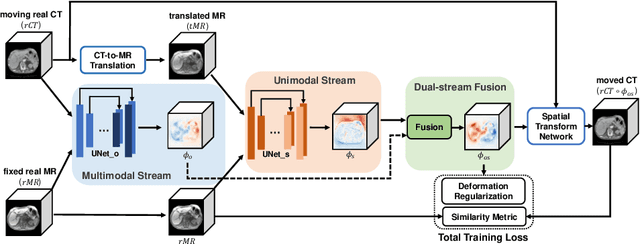

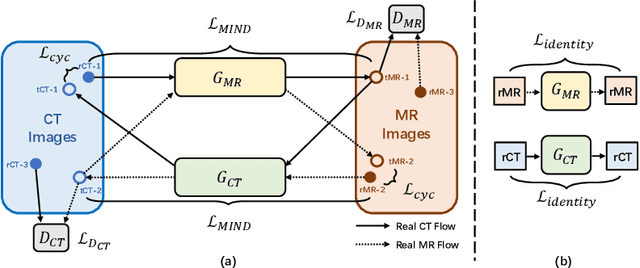
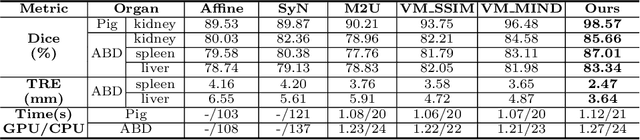
Deformable image registration between Computed Tomography (CT) images and Magnetic Resonance (MR) imaging is essential for many image-guided therapies. In this paper, we propose a novel translation-based unsupervised deformable image registration method. Distinct from other translation-based methods that attempt to convert the multimodal problem (e.g., CT-to-MR) into a unimodal problem (e.g., MR-to-MR) via image-to-image translation, our method leverages the deformation fields estimated from both: (i) the translated MR image and (ii) the original CT image in a dual-stream fashion, and automatically learns how to fuse them to achieve better registration performance. The multimodal registration network can be effectively trained by computationally efficient similarity metrics without any ground-truth deformation. Our method has been evaluated on two clinical datasets and demonstrates promising results compared to state-of-the-art traditional and learning-based methods.
Brain Cancer Survival Prediction on Treatment-na ive MRI using Deep Anchor Attention Learning with Vision Transformer
Feb 03, 2022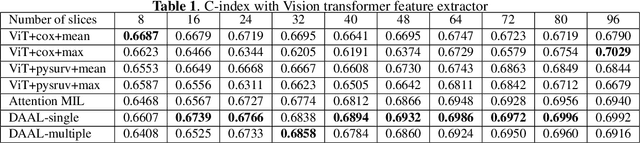
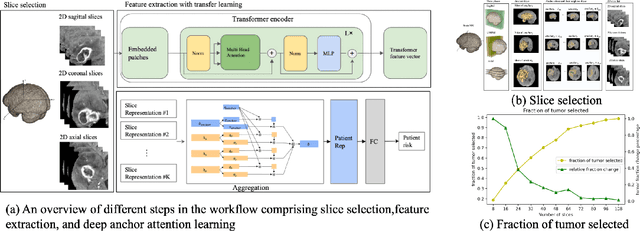
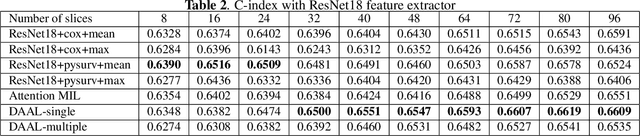
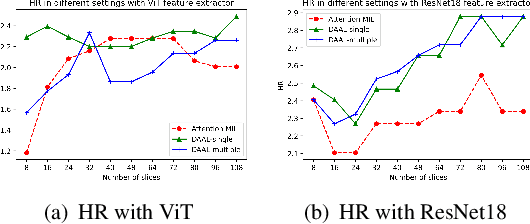
Image-based brain cancer prediction models, based on radiomics, quantify the radiologic phenotype from magnetic resonance imaging (MRI). However, these features are difficult to reproduce because of variability in acquisition and preprocessing pipelines. Despite evidence of intra-tumor phenotypic heterogeneity, the spatial diversity between different slices within an MRI scan has been relatively unexplored using such methods. In this work, we propose a deep anchor attention aggregation strategy with a Vision Transformer to predict survival risk for brain cancer patients. A Deep Anchor Attention Learning (DAAL) algorithm is proposed to assign different weights to slice-level representations with trainable distance measurements. We evaluated our method on N = 326 MRIs. Our results outperformed attention multiple instance learning-based techniques. DAAL highlights the importance of critical slices and corroborates the clinical intuition that inter-slice spatial diversity can reflect disease severity and is implicated in outcome.
Mapping DNN Embedding Manifolds for Network Generalization Prediction
Feb 03, 2022
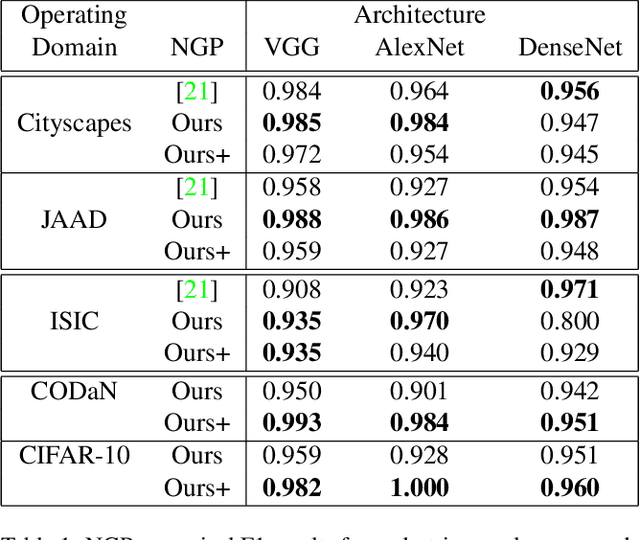

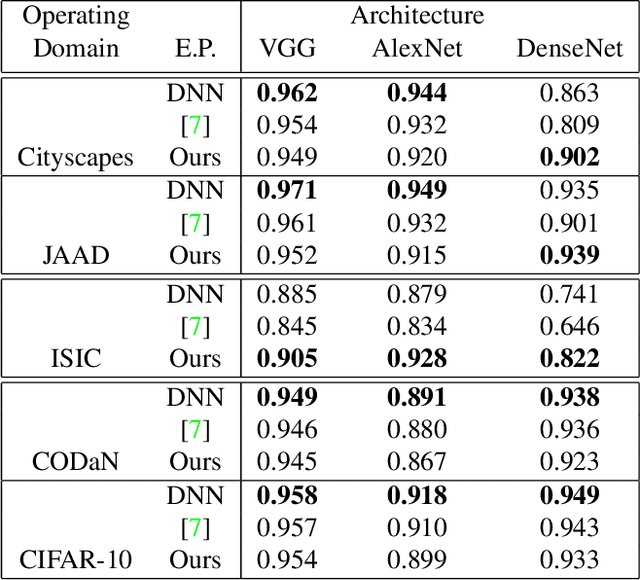
Understanding Deep Neural Network (DNN) performance in changing conditions is essential for deploying DNNs in safety critical applications with unconstrained environments, e.g., perception for self-driving vehicles or medical image analysis. Recently, the task of Network Generalization Prediction (NGP) has been proposed to predict how a DNN will generalize in a new operating domain. Previous NGP approaches have relied on labeled metadata and known distributions for the new operating domains. In this study, we propose the first NGP approach that predicts DNN performance based solely on how unlabeled images from an external operating domain map in the DNN embedding space. We demonstrate this technique for pedestrian, melanoma, and animal classification tasks and show state of the art NGP in 13 of 15 NGP tasks without requiring domain knowledge. Additionally, we show that our NGP embedding maps can be used to identify misclassified images when the DNN performance is poor.
A Note on the Implicit Bias Towards Minimal Depth of Deep Neural Networks
Feb 18, 2022
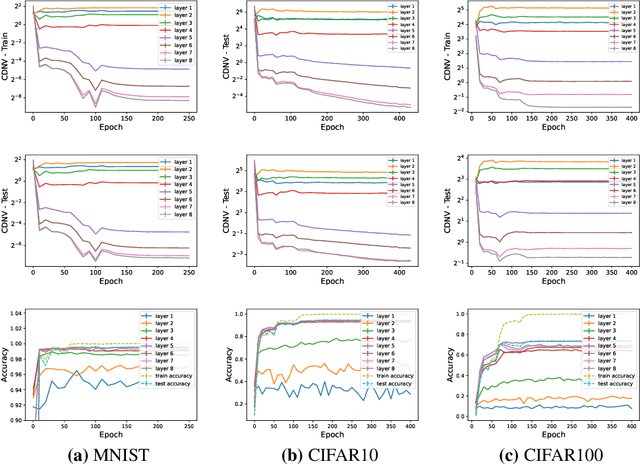
Deep learning systems have steadily advanced the state of the art in a wide variety of benchmarks, demonstrating impressive performance in tasks ranging from image classification \citep{taigman2014deepface,zhai2021scaling}, language processing \citep{devlin-etal-2019-bert,NEURIPS2020_1457c0d6}, open-ended environments \citep{SilverHuangEtAl16nature,arulkumaran2019alphastar}, to coding \citep{chen2021evaluating}. A central aspect that enables the success of these systems is the ability to train deep models instead of wide shallow ones \citep{7780459}. Intuitively, a neural network is decomposed into hierarchical representations from raw data to high-level, more abstract features. While training deep neural networks repetitively achieves superior performance against their shallow counterparts, an understanding of the role of depth in representation learning is still lacking. In this work, we suggest a new perspective on understanding the role of depth in deep learning. We hypothesize that {\bf\em SGD training of overparameterized neural networks exhibits an implicit bias that favors solutions of minimal effective depth}. Namely, SGD trains neural networks for which the top several layers are redundant. To evaluate the redundancy of layers, we revisit the recently discovered phenomenon of neural collapse \citep{Papyan24652,han2021neural}.
Danish Airs and Grounds: A Dataset for Aerial-to-Street-Level Place Recognition and Localization
Feb 03, 2022


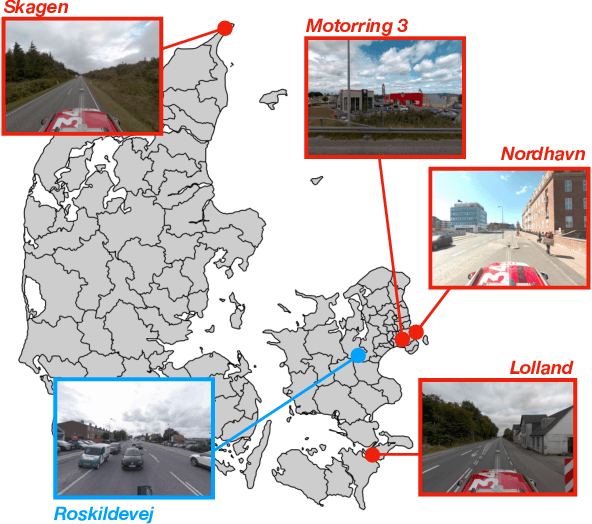
Place recognition and visual localization are particularly challenging in wide baseline configurations. In this paper, we contribute with the \emph{Danish Airs and Grounds} (DAG) dataset, a large collection of street-level and aerial images targeting such cases. Its main challenge lies in the extreme viewing-angle difference between query and reference images with consequent changes in illumination and perspective. The dataset is larger and more diverse than current publicly available data, including more than 50 km of road in urban, suburban and rural areas. All images are associated with accurate 6-DoF metadata that allows the benchmarking of visual localization methods. We also propose a map-to-image re-localization pipeline, that first estimates a dense 3D reconstruction from the aerial images and then matches query street-level images to street-level renderings of the 3D model. The dataset can be downloaded at: https://frederikwarburg.github.io/DAG
SMILE: Semantically-guided Multi-attribute Image and Layout Editing
Oct 05, 2020
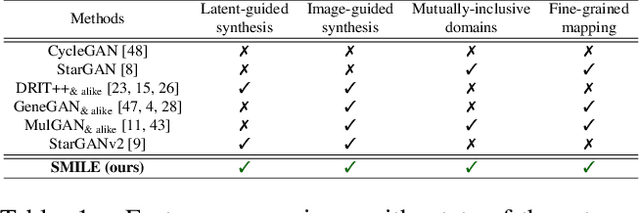
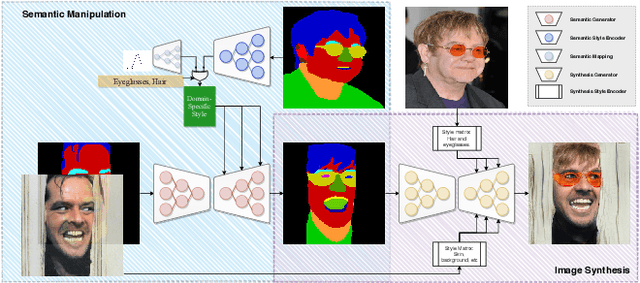

Attribute image manipulation has been a very active topic since the introduction of Generative Adversarial Networks (GANs). Exploring the disentangled attribute space within a transformation is a very challenging task due to the multiple and mutually-inclusive nature of the facial images, where different labels (eyeglasses, hats, hair, identity, etc.) can co-exist at the same time. Several works address this issue either by exploiting the modality of each domain/attribute using a conditional random vector noise, or extracting the modality from an exemplary image. However, existing methods cannot handle both random and reference transformations for multiple attributes, which limits the generality of the solutions. In this paper, we successfully exploit a multimodal representation that handles all attributes, be it guided by random noise or exemplar images, while only using the underlying domain information of the target domain. We present extensive qualitative and quantitative results for facial datasets and several different attributes that show the superiority of our method. Additionally, our method is capable of adding, removing or changing either fine-grained or coarse attributes by using an image as a reference or by exploring the style distribution space, and it can be easily extended to head-swapping and face-reenactment applications without being trained on videos.