 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024
Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
SCINeRF: Neural Radiance Fields from a Snapshot Compressive Image
Mar 29, 2024
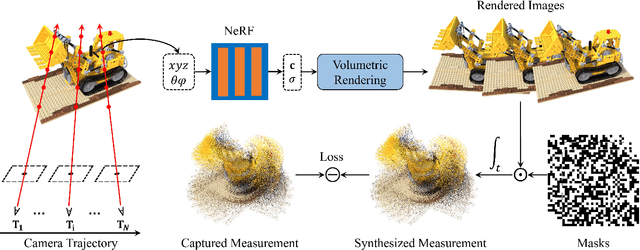


In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene representation from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, which not only reduces storage requirements but also offers potential privacy protection. Inspired by this, to take one step further, our approach builds upon the powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Extensive experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view image synthesis. Moreover, our method also exhibits the ability to restore high frame-rate multi-view consistent images by leveraging SCI and the rendering capabilities of NeRF. The code is available at https://github.com/WU-CVGL/SCINeRF.
RSMamba: Remote Sensing Image Classification with State Space Model
Mar 28, 2024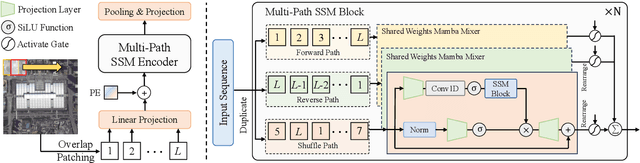
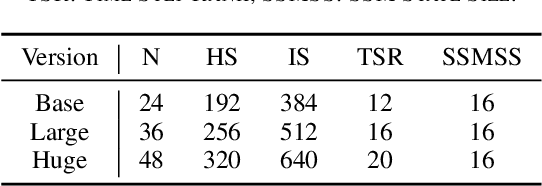
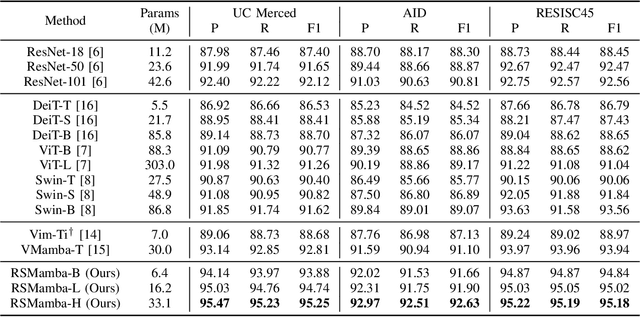
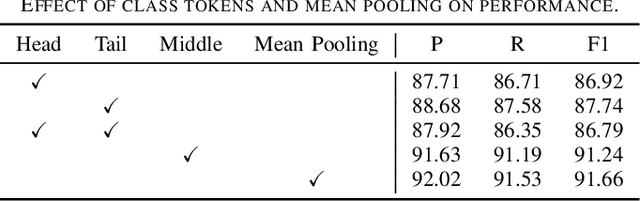
Remote sensing image classification forms the foundation of various understanding tasks, serving a crucial function in remote sensing image interpretation. The recent advancements of Convolutional Neural Networks (CNNs) and Transformers have markedly enhanced classification accuracy. Nonetheless, remote sensing scene classification remains a significant challenge, especially given the complexity and diversity of remote sensing scenarios and the variability of spatiotemporal resolutions. The capacity for whole-image understanding can provide more precise semantic cues for scene discrimination. In this paper, we introduce RSMamba, a novel architecture for remote sensing image classification. RSMamba is based on the State Space Model (SSM) and incorporates an efficient, hardware-aware design known as the Mamba. It integrates the advantages of both a global receptive field and linear modeling complexity. To overcome the limitation of the vanilla Mamba, which can only model causal sequences and is not adaptable to two-dimensional image data, we propose a dynamic multi-path activation mechanism to augment Mamba's capacity to model non-causal data. Notably, RSMamba maintains the inherent modeling mechanism of the vanilla Mamba, yet exhibits superior performance across multiple remote sensing image classification datasets. This indicates that RSMamba holds significant potential to function as the backbone of future visual foundation models. The code will be available at \url{https://github.com/KyanChen/RSMamba}.
TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
Mar 25, 2024Recent advances in text-to-video generation have demonstrated the utility of powerful diffusion models. Nevertheless, the problem is not trivial when shaping diffusion models to animate static image (i.e., image-to-video generation). The difficulty originates from the aspect that the diffusion process of subsequent animated frames should not only preserve the faithful alignment with the given image but also pursue temporal coherence among adjacent frames. To alleviate this, we present TRIP, a new recipe of image-to-video diffusion paradigm that pivots on image noise prior derived from static image to jointly trigger inter-frame relational reasoning and ease the coherent temporal modeling via temporal residual learning. Technically, the image noise prior is first attained through one-step backward diffusion process based on both static image and noised video latent codes. Next, TRIP executes a residual-like dual-path scheme for noise prediction: 1) a shortcut path that directly takes image noise prior as the reference noise of each frame to amplify the alignment between the first frame and subsequent frames; 2) a residual path that employs 3D-UNet over noised video and static image latent codes to enable inter-frame relational reasoning, thereby easing the learning of the residual noise for each frame. Furthermore, both reference and residual noise of each frame are dynamically merged via attention mechanism for final video generation. Extensive experiments on WebVid-10M, DTDB and MSR-VTT datasets demonstrate the effectiveness of our TRIP for image-to-video generation. Please see our project page at https://trip-i2v.github.io/TRIP/.
On adversarial training and the 1 Nearest Neighbor classifier
Apr 11, 2024The ability to fool deep learning classifiers with tiny perturbations of the input has lead to the development of adversarial training in which the loss with respect to adversarial examples is minimized in addition to the training examples. While adversarial training improves the robustness of the learned classifiers, the procedure is computationally expensive, sensitive to hyperparameters and may still leave the classifier vulnerable to other types of small perturbations. In this paper we analyze the adversarial robustness of the 1 Nearest Neighbor (1NN) classifier and compare its performance to adversarial training. We prove that under reasonable assumptions, the 1 NN classifier will be robust to {\em any} small image perturbation of the training images and will give high adversarial accuracy on test images as the number of training examples goes to infinity. In experiments with 45 different binary image classification problems taken from CIFAR10, we find that 1NN outperform TRADES (a powerful adversarial training algorithm) in terms of average adversarial accuracy. In additional experiments with 69 pretrained robust models for CIFAR10, we find that 1NN outperforms almost all of them in terms of robustness to perturbations that are only slightly different from those seen during training. Taken together, our results suggest that modern adversarial training methods still fall short of the robustness of the simple 1NN classifier. our code can be found at https://github.com/amirhagai/On-Adversarial-Training-And-The-1-Nearest-Neighbor-Classifier
Training a Vision Language Model as Smartphone Assistant
Apr 12, 2024Addressing the challenge of a digital assistant capable of executing a wide array of user tasks, our research focuses on the realm of instruction-based mobile device control. We leverage recent advancements in large language models (LLMs) and present a visual language model (VLM) that can fulfill diverse tasks on mobile devices. Our model functions by interacting solely with the user interface (UI). It uses the visual input from the device screen and mimics human-like interactions, encompassing gestures such as tapping and swiping. This generality in the input and output space allows our agent to interact with any application on the device. Unlike previous methods, our model operates not only on a single screen image but on vision-language sentences created from sequences of past screenshots along with corresponding actions. Evaluating our method on the challenging Android in the Wild benchmark demonstrates its promising efficacy and potential.
No Bells, Just Whistles: Sports Field Registration by Leveraging Geometric Properties
Apr 12, 2024Broadcast sports field registration is traditionally addressed as a homography estimation task, mapping the visible image area to a planar field model, predominantly focusing on the main camera shot. Addressing the shortcomings of previous approaches, we propose a novel calibration pipeline enabling camera calibration using a 3D soccer field model and extending the process to assess the multiple-view nature of broadcast videos. Our approach begins with a keypoint generation pipeline derived from SoccerNet dataset annotations, leveraging the geometric properties of the court. Subsequently, we execute classical camera calibration through DLT algorithm in a minimalist fashion, without further refinement. Through extensive experimentation on real-world soccer broadcast datasets such as SoccerNet-Calibration, WorldCup 2014 and TS- WorldCup, our method demonstrates superior performance in both multiple- and single-view 3D camera calibration while maintaining competitive results in homography estimation compared to state-of-the-art techniques.
Image Deraining via Self-supervised Reinforcement Learning
Mar 27, 2024The quality of images captured outdoors is often affected by the weather. One factor that interferes with sight is rain, which can obstruct the view of observers and computer vision applications that rely on those images. The work aims to recover rain images by removing rain streaks via Self-supervised Reinforcement Learning (RL) for image deraining (SRL-Derain). We locate rain streak pixels from the input rain image via dictionary learning and use pixel-wise RL agents to take multiple inpainting actions to remove rain progressively. To our knowledge, this work is the first attempt where self-supervised RL is applied to image deraining. Experimental results on several benchmark image-deraining datasets show that the proposed SRL-Derain performs favorably against state-of-the-art few-shot and self-supervised deraining and denoising methods.
Efficient Denoising using Score Embedding in Score-based Diffusion Models
Apr 10, 2024It is well known that training a denoising score-based diffusion models requires tens of thousands of epochs and a substantial number of image data to train the model. In this paper, we propose to increase the efficiency in training score-based diffusion models. Our method allows us to decrease the number of epochs needed to train the diffusion model. We accomplish this by solving the log-density Fokker-Planck (FP) Equation numerically to compute the score \textit{before} training. The pre-computed score is embedded into the image to encourage faster training under slice Wasserstein distance. Consequently, it also allows us to decrease the number of images we need to train the neural network to learn an accurate score. We demonstrate through our numerical experiments the improved performance of our proposed method compared to standard score-based diffusion models. Our proposed method achieves a similar quality to the standard method meaningfully faster.
MedRG: Medical Report Grounding with Multi-modal Large Language Model
Apr 10, 2024Medical Report Grounding is pivotal in identifying the most relevant regions in medical images based on a given phrase query, a critical aspect in medical image analysis and radiological diagnosis. However, prevailing visual grounding approaches necessitate the manual extraction of key phrases from medical reports, imposing substantial burdens on both system efficiency and physicians. In this paper, we introduce a novel framework, Medical Report Grounding (MedRG), an end-to-end solution for utilizing a multi-modal Large Language Model to predict key phrase by incorporating a unique token, BOX, into the vocabulary to serve as an embedding for unlocking detection capabilities. Subsequently, the vision encoder-decoder jointly decodes the hidden embedding and the input medical image, generating the corresponding grounding box. The experimental results validate the effectiveness of MedRG, surpassing the performance of the existing state-of-the-art medical phrase grounding methods. This study represents a pioneering exploration of the medical report grounding task, marking the first-ever endeavor in this domain.