 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning based Prediction of MSI in Colorectal Cancer via Prediction of the Status of MMR Markers
Feb 24, 2022


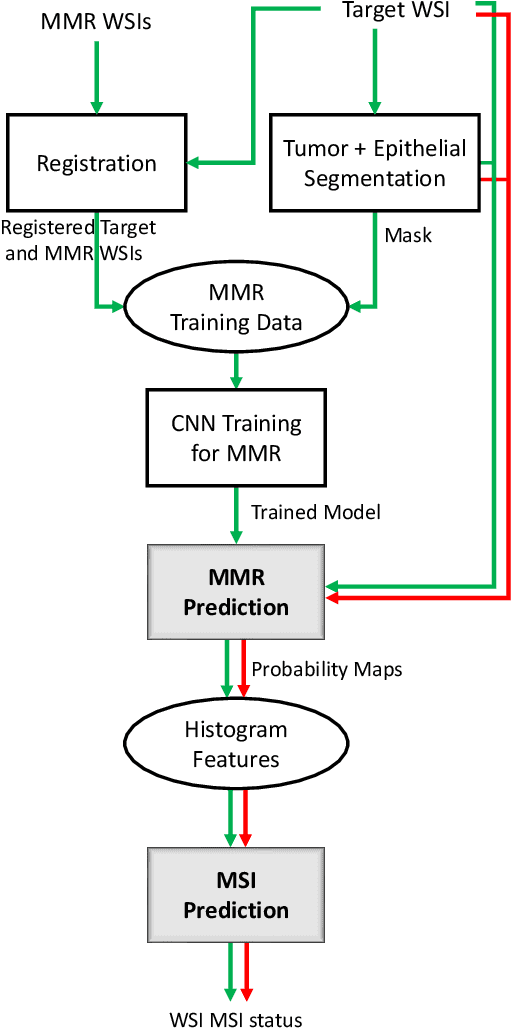
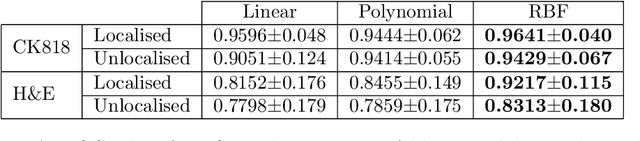
An accurate diagnosis and profiling of tumour are critical to the best treatment choices for cancer patients. In addition to the cancer type and its aggressiveness, molecular heterogeneity also plays a vital role in treatment selection. MSI or MMR deficiency is one of the well-studied aberrations in terms of molecular changes. Colorectal cancer patients with MMR deficiency respond well to immunotherapy, hence assessment of the relevant molecular markers can assist clinicians in making optimal treatment selections for patients. Immunohistochemistry is one of the ways for identifying these molecular changes which requires additional sections of tumour tissue. Introduction of automated methods that can predict MSI or MMR status from a target image without the need for additional sections can substantially reduce the cost associated with it. In this work, we present our work on predicting MSI status in a two-stage process using a single target slide either stained with CK818 or H\&E. First, we train a multi-headed convolutional neural network model where each head is responsible for predicting one of the MMR protein expressions. To this end, we perform registration of MMR slides to the target slide as a pre-processing step. In the second stage, statistical features computed from the MMR prediction maps are used for the final MSI prediction. Our results demonstrate that MSI classification can be improved on incorporating fine-grained MMR labels in comparison to the previous approaches in which coarse labels (MSI/MSS) are utilised.
Cross-Scale Internal Graph Neural Network for Image Super-Resolution
Jun 30, 2020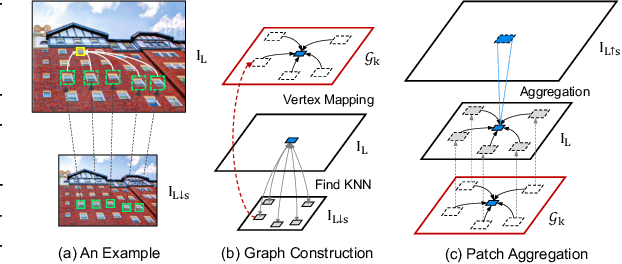
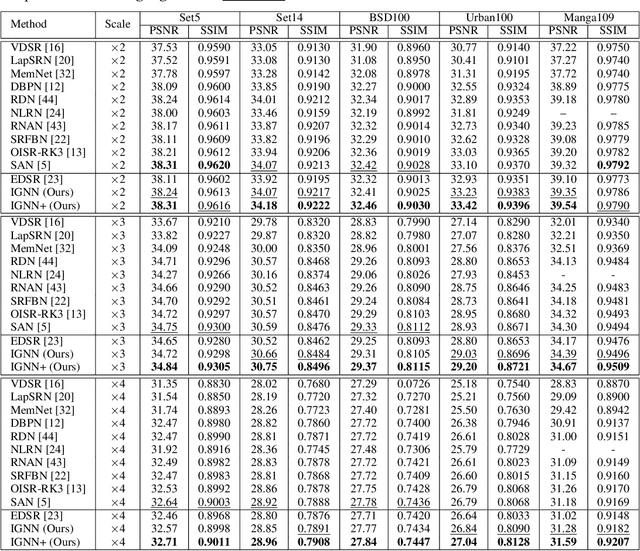
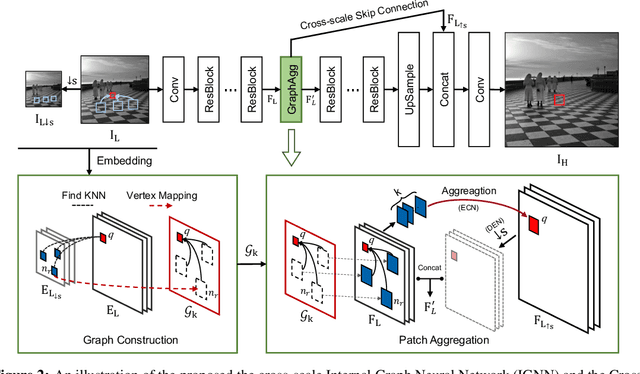

Non-local self-similarity in natural images has been well studied as an effective prior in image restoration. However, for single image super-resolution (SISR), most existing deep non-local methods (e.g., non-local neural networks) only exploit similar patches within the same scale of the low-resolution (LR) input image. Consequently, the restoration is limited to using the same-scale information while neglecting potential high-resolution (HR) cues from other scales. In this paper, we explore the cross-scale patch recurrence property of a natural image, i.e., similar patches tend to recur many times across different scales. This is achieved using a novel cross-scale internal graph neural network (IGNN). Specifically, we dynamically construct a cross-scale graph by searching k-nearest neighboring patches in the downsampled LR image for each query patch in the LR image. We then obtain the corresponding k HR neighboring patches in the LR image and aggregate them adaptively in accordance to the edge label of the constructed graph. In this way, the HR information can be passed from k HR neighboring patches to the LR query patch to help it recover more detailed textures. Besides, these internal image-specific LR/HR exemplars are also significant complements to the external information learned from the training dataset. Extensive experiments demonstrate the effectiveness of IGNN against the state-of-the-art SISR methods including existing non-local networks on standard benchmarks.
An Edge Information and Mask Shrinking Based Image Inpainting Approach
Jun 11, 2020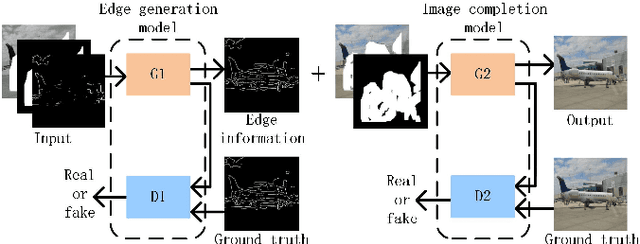
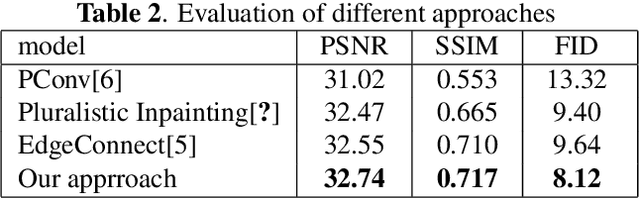
In the image inpainting task, the ability to repair both high-frequency and low-frequency information in the missing regions has a substantial influence on the quality of the restored image. However, existing inpainting methods usually fail to consider both high-frequency and low-frequency information simultaneously. To solve this problem, this paper proposes edge information and mask shrinking based image inpainting approach, which consists of two models. The first model is an edge generation model used to generate complete edge information from the damaged image, and the second model is an image completion model used to fix the missing regions with the generated edge information and the valid contents of the damaged image. The mask shrinking strategy is employed in the image completion model to track the areas to be repaired. The proposed approach is evaluated qualitatively and quantitatively on the dataset Places2. The result shows our approach outperforms state-of-the-art methods.
Constrained Structure Learning for Scene Graph Generation
Jan 27, 2022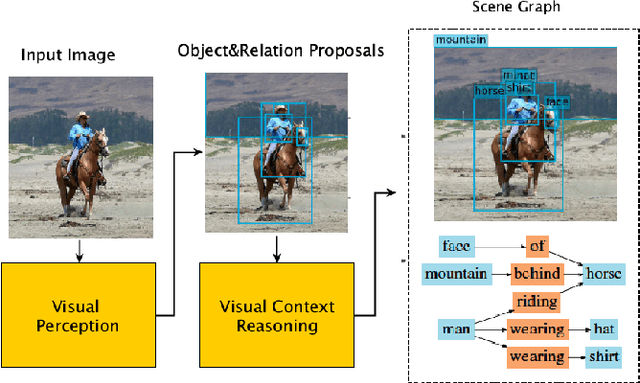
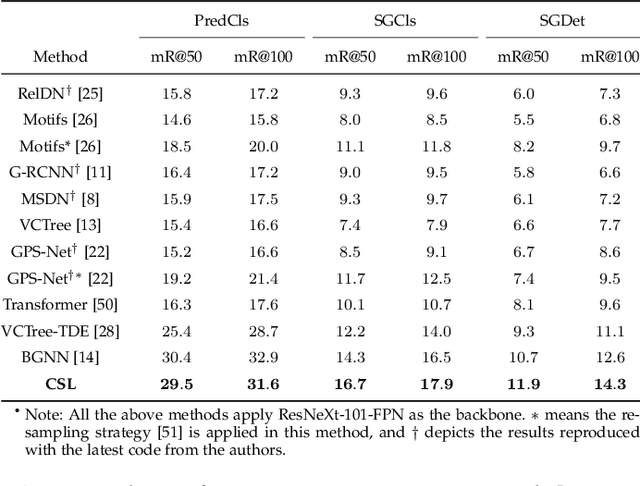
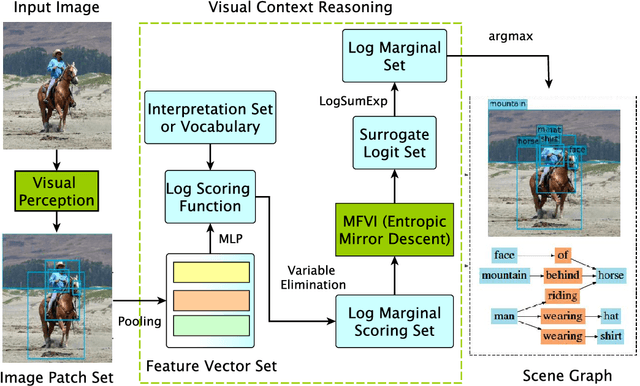
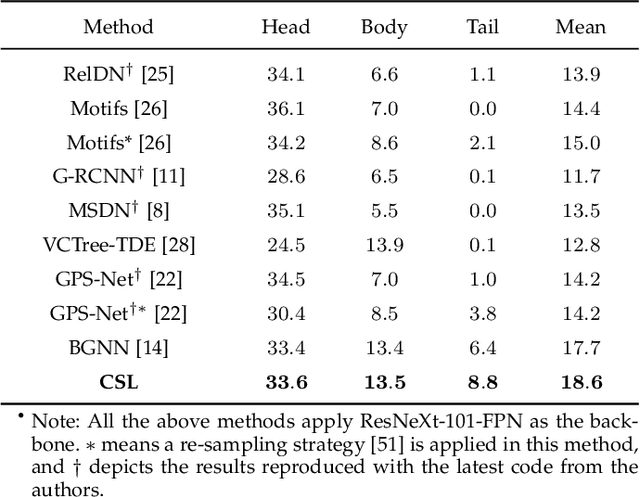
As a structured prediction task, scene graph generation aims to build a visually-grounded scene graph to explicitly model objects and their relationships in an input image. Currently, the mean field variational Bayesian framework is the de facto methodology used by the existing methods, in which the unconstrained inference step is often implemented by a message passing neural network. However, such formulation fails to explore other inference strategies, and largely ignores the more general constrained optimization models. In this paper, we present a constrained structure learning method, for which an explicit constrained variational inference objective is proposed. Instead of applying the ubiquitous message-passing strategy, a generic constrained optimization method - entropic mirror descent - is utilized to solve the constrained variational inference step. We validate the proposed generic model on various popular scene graph generation benchmarks and show that it outperforms the state-of-the-art methods.
CSformer: Bridging Convolution and Transformer for Compressive Sensing
Dec 31, 2021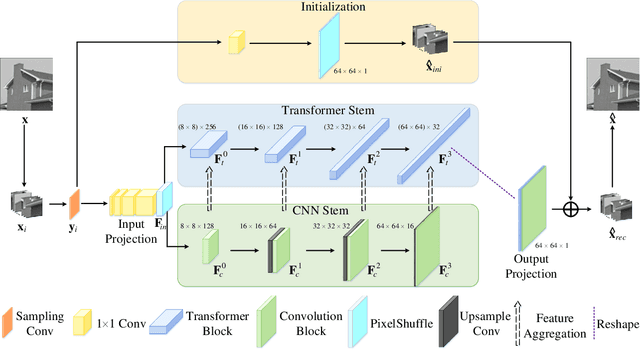
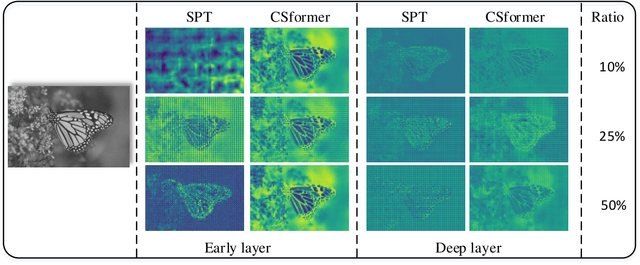
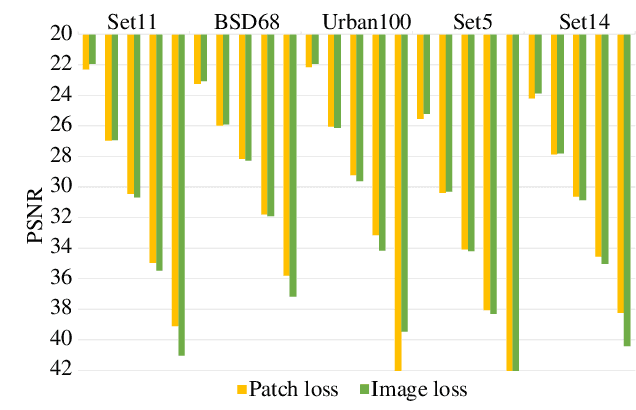
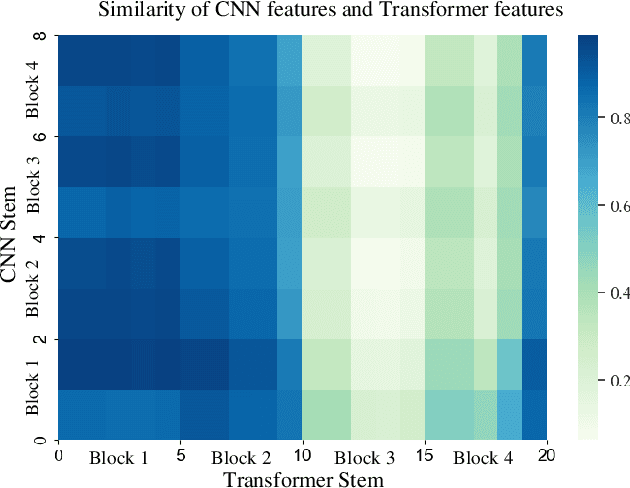
Convolution neural networks (CNNs) have succeeded in compressive image sensing. However, due to the inductive bias of locality and weight sharing, the convolution operations demonstrate the intrinsic limitations in modeling the long-range dependency. Transformer, designed initially as a sequence-to-sequence model, excels at capturing global contexts due to the self-attention-based architectures even though it may be equipped with limited localization abilities. This paper proposes CSformer, a hybrid framework that integrates the advantages of leveraging both detailed spatial information from CNN and the global context provided by transformer for enhanced representation learning. The proposed approach is an end-to-end compressive image sensing method, composed of adaptive sampling and recovery. In the sampling module, images are measured block-by-block by the learned sampling matrix. In the reconstruction stage, the measurement is projected into dual stems. One is the CNN stem for modeling the neighborhood relationships by convolution, and the other is the transformer stem for adopting global self-attention mechanism. The dual branches structure is concurrent, and the local features and global representations are fused under different resolutions to maximize the complementary of features. Furthermore, we explore a progressive strategy and window-based transformer block to reduce the parameter and computational complexity. The experimental results demonstrate the effectiveness of the dedicated transformer-based architecture for compressive sensing, which achieves superior performance compared to state-of-the-art methods on different datasets.
Blind Image Deconvolution using Student's-t Prior with Overlapping Group Sparsity
Jun 26, 2020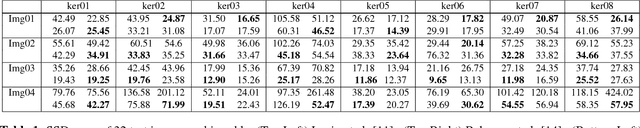
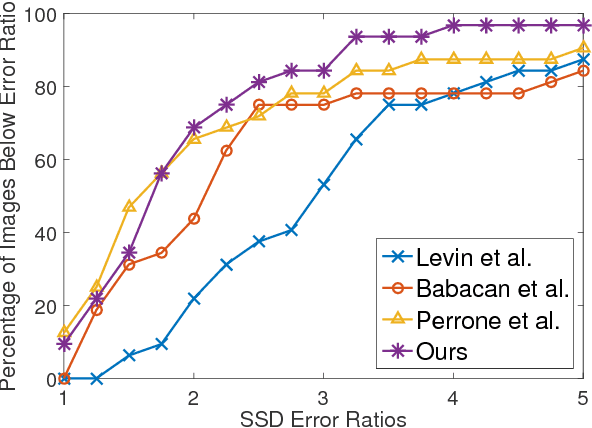
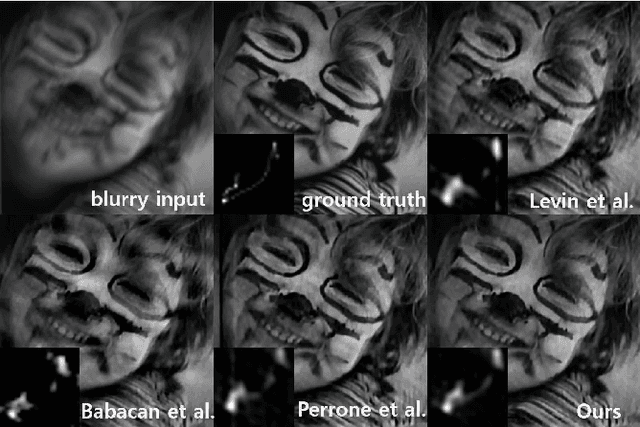
In this paper, we solve blind image deconvolution problem that is to remove blurs form a signal degraded image without any knowledge of the blur kernel. Since the problem is ill-posed, an image prior plays a significant role in accurate blind deconvolution. Traditional image prior assumes coefficients in filtered domains are sparse. However, it is assumed here that there exist additional structures over the sparse coefficients. Accordingly, we propose new problem formulation for the blind image deconvolution, which utilizes the structural information by coupling Student's-t image prior with overlapping group sparsity. The proposed method resulted in an effective blind deconvolution algorithm that outperforms other state-of-the-art algorithms.
Image Generation from Freehand Scene Sketches
Mar 11, 2020
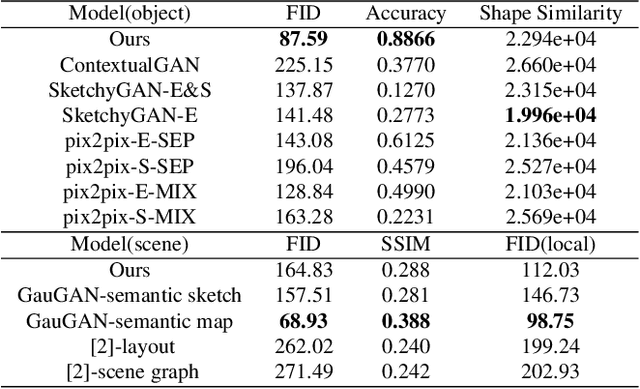
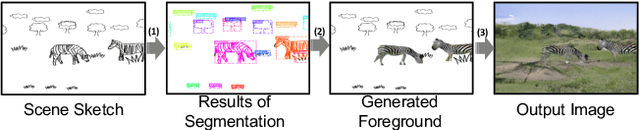
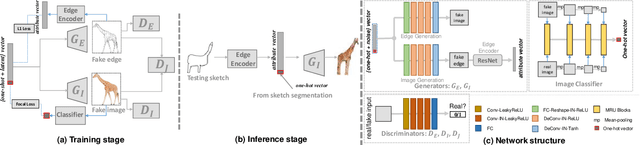
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged generative adversarial network called edgeGAN which supports high visual-quality image content generation without using freehand sketches as training data. We build a large-scale composite dataset called SketchyCOCO to comprehensively evaluate our solution. We validate our approach on the task of both objectlevel and scene-level image generation on SketchyCOCO. We demonstrate the method's capacity to generate realistic complex scene-level images from a variety of freehand sketches by quantitative, qualitative results, and ablation studies.
Pseudo Numerical Methods for Diffusion Models on Manifolds
Feb 20, 2022

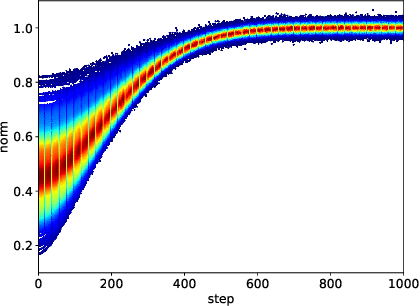
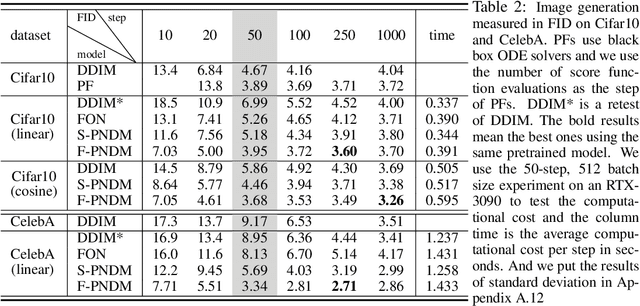
Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules. Our implementation is available at https://github.com/luping-liu/PNDM.
Segmentation of 2D Brain MR Images
Nov 05, 2021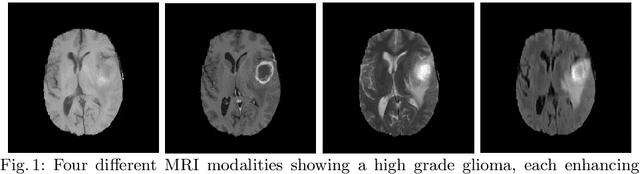

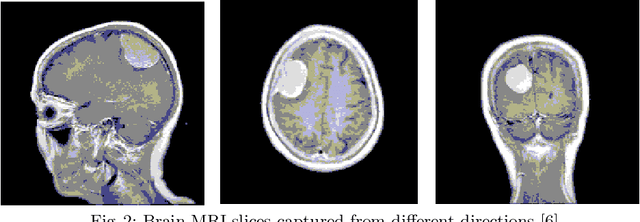
Brain tumour segmentation is an essential task in medical image processing. Early diagnosis of brain tumours plays a crucial role in improving treatment possibilities and increases the survival rate of the patients. Manual segmentation of the brain tumours for cancer diagnosis, from large number of MRI images, is both a difficult and time-consuming task. There is a need for automatic brain tumour image segmentation. The purpose of this project is to provide an automatic brain tumour segmentation method of MRI images to help locate the tumour accurately and quickly.
WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets for hyperspectral image classification
Dec 27, 2020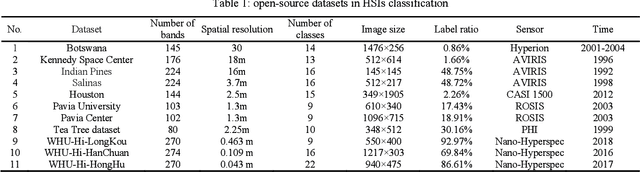
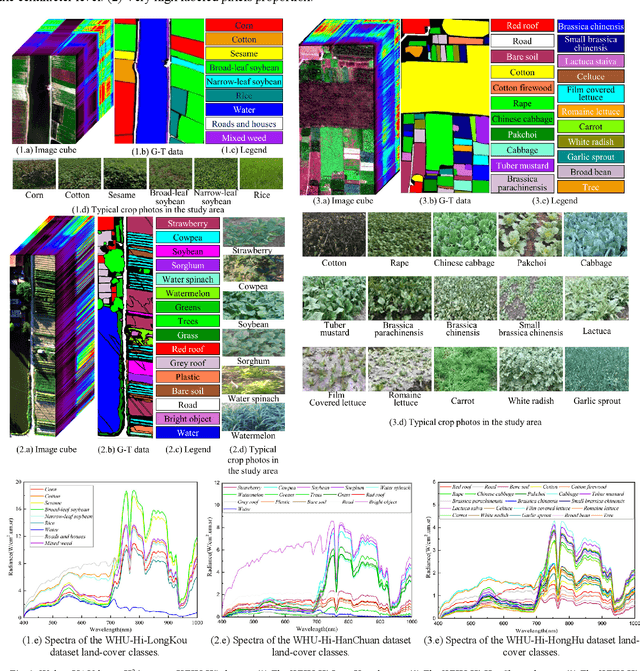
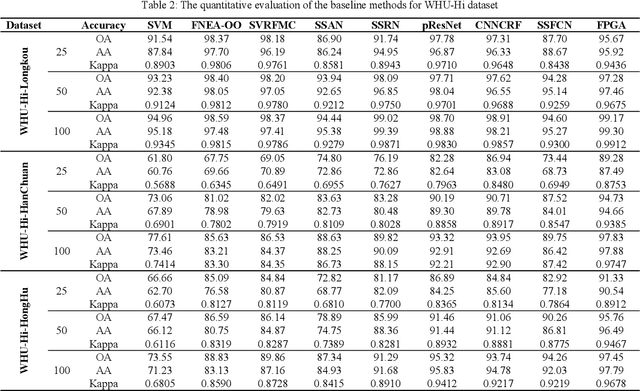
Classification is an important aspect of hyperspectral images processing and application. At present, the researchers mostly use the classic airborne hyperspectral imagery as the benchmark dataset. However, existing datasets suffer from three bottlenecks: (1) low spatial resolution; (2) low labeled pixels proportion; (3) low degree of subclasses distinction. In this paper, a new benchmark dataset named the Wuhan UAV-borne hyperspectral image (WHU-Hi) dataset was built for hyperspectral image classification. The WHU-Hi dataset with a high spectral resolution (nm level) and a very high spatial resolution (cm level), which we refer to here as H2 imager. Besides, the WHU-Hi dataset has a higher pixel labeling ratio and finer subclasses. Some start-of-art hyperspectral image classification methods benchmarked the WHU-Hi dataset, and the experimental results show that WHU-Hi is a challenging dataset. We hope WHU-Hi dataset can become a strong benchmark to accelerate future research.