 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
Jul 03, 2020
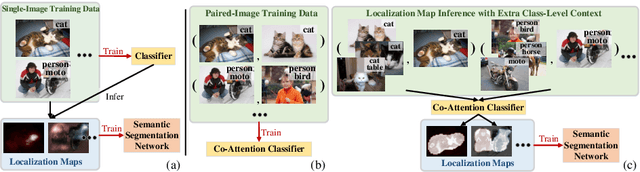
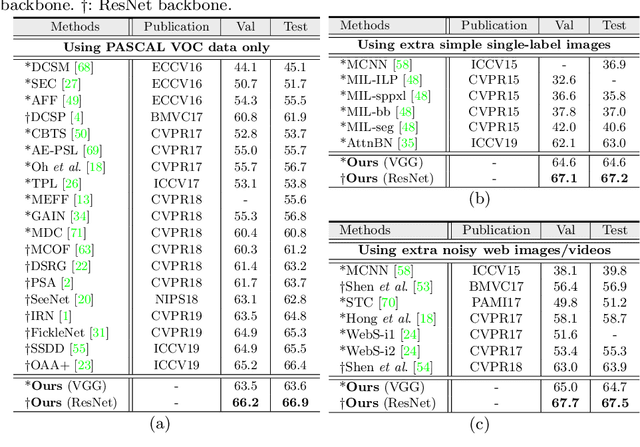
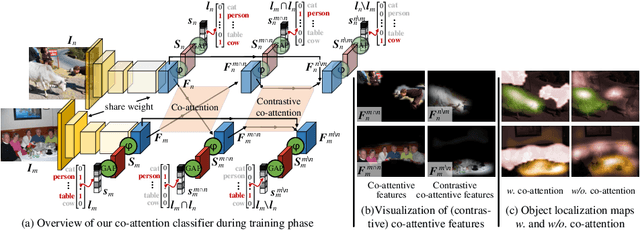
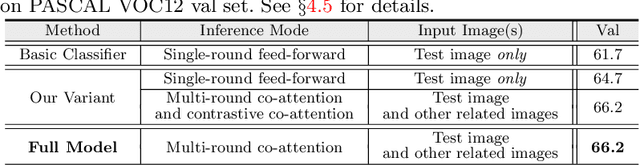
This paper studies the problem of learning semantic segmentation from image-level supervision only. Current popular solutions leverage object localization maps from classifiers as supervision signals, and struggle to make the localization maps capture more complete object content. Rather than previous efforts that primarily focus on intra-image information, we address the value of cross-image semantic relations for comprehensive object pattern mining. To achieve this, two neural co-attentions are incorporated into the classifier to complimentarily capture cross-image semantic similarities and differences. In particular, given a pair of training images, one co-attention enforces the classifier to recognize the common semantics from co-attentive objects, while the other one, called contrastive co-attention, drives the classifier to identify the unshared semantics from the rest, uncommon objects. This helps the classifier discover more object patterns and better ground semantics in image regions. In addition to boosting object pattern learning, the co-attention can leverage context from other related images to improve localization map inference, hence eventually benefiting semantic segmentation learning. More essentially, our algorithm provides a unified framework that handles well different WSSS settings, i.e., learning WSSS with (1) precise image-level supervision only, (2) extra simple single-label data, and (3) extra noisy web data. It sets new state-of-the-arts on all these settings, demonstrating well its efficacy and generalizability. Moreover, our approach ranked 1st place in the Weakly-Supervised Semantic Segmentation Track of CVPR2020 Learning from Imperfect Data Challenge.
Image Generation from Freehand Scene Sketches
Mar 05, 2020
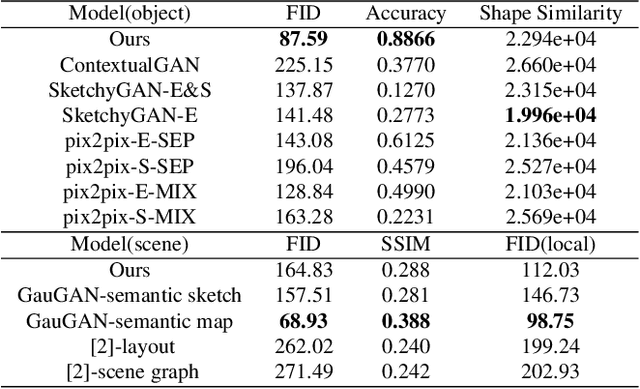
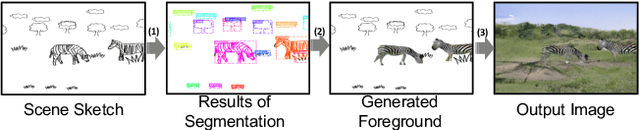
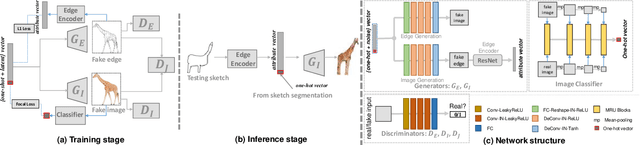
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged generative adversarial network called edgeGAN which supports high visual-quality image content generation without using freehand sketches as training data. We build a large-scale composite dataset called SketchyCOCO to comprehensively evaluate our solution. We validate our approach on the task of both objectlevel and scene-level image generation on SketchyCOCO. We demonstrate the method's capacity to generate realistic complex scene-level images from a variety of freehand sketches by quantitative, qualitative results, and ablation studies.
VIDIT: Virtual Image Dataset for Illumination Transfer
May 13, 2020
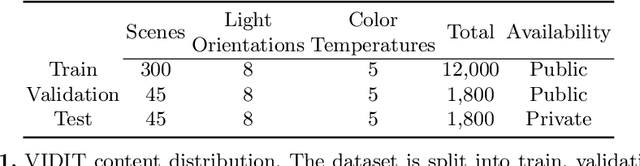

Deep image relighting is gaining more interest lately, as it allows photo enhancement through illumination-specific retouching without human effort. Aside from aesthetic enhancement and photo montage, image relighting is valuable for domain adaptation, whether to augment datasets for training or to normalize input test data. Accurate relighting is, however, very challenging for various reasons, such as the difficulty in removing and recasting shadows and the modeling of different surfaces. We present a novel dataset, the Virtual Image Dataset for Illumination Transfer (VIDIT), in an effort to create a reference evaluation benchmark and to push forward the development of illumination manipulation methods. Virtual datasets are not only an important step towards achieving real-image performance but have also proven capable of improving training even when real datasets are possible to acquire and available. VIDIT contains 300 virtual scenes used for training, where every scene is captured 40 times in total: from 8 equally-spaced azimuthal angles, each lit with 5 different illuminants.
Perspective Plane Program Induction from a Single Image
Jun 25, 2020
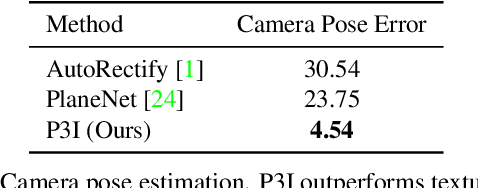

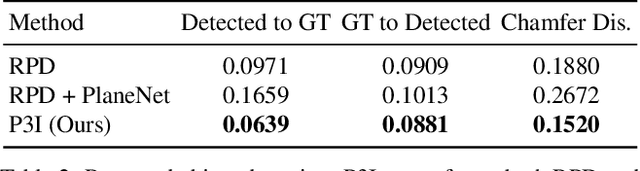
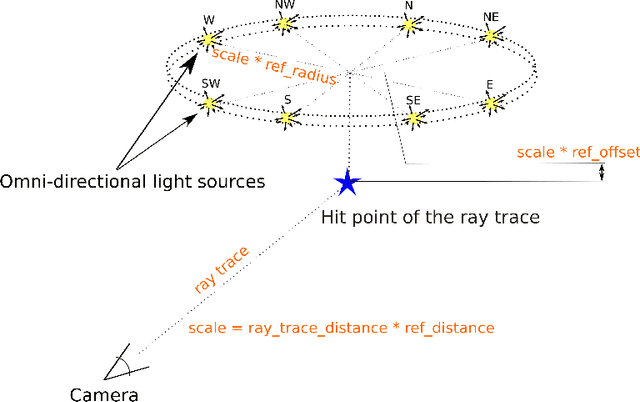
We study the inverse graphics problem of inferring a holistic representation for natural images. Given an input image, our goal is to induce a neuro-symbolic, program-like representation that jointly models camera poses, object locations, and global scene structures. Such high-level, holistic scene representations further facilitate low-level image manipulation tasks such as inpainting. We formulate this problem as jointly finding the camera pose and scene structure that best describe the input image. The benefits of such joint inference are two-fold: scene regularity serves as a new cue for perspective correction, and in turn, correct perspective correction leads to a simplified scene structure, similar to how the correct shape leads to the most regular texture in shape from texture. Our proposed framework, Perspective Plane Program Induction (P3I), combines search-based and gradient-based algorithms to efficiently solve the problem. P3I outperforms a set of baselines on a collection of Internet images, across tasks including camera pose estimation, global structure inference, and down-stream image manipulation tasks.
Fidelity-Controllable Extreme Image Compression with Generative Adversarial Networks
Aug 24, 2020
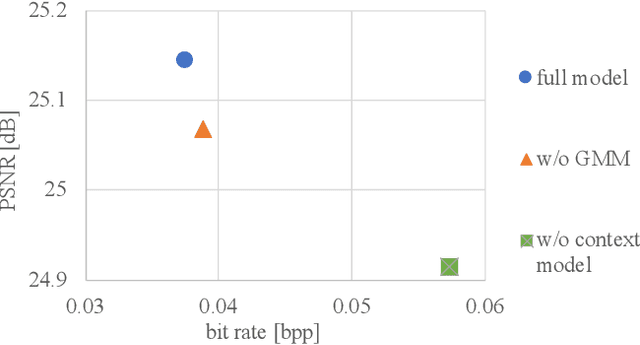

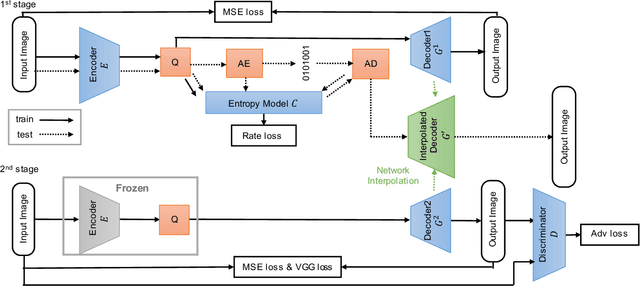
We propose a GAN-based image compression method working at extremely low bitrates below 0.1bpp. Most existing learned image compression methods suffer from blur at extremely low bitrates. Although GAN can help to reconstruct sharp images, there are two drawbacks. First, GAN makes training unstable. Second, the reconstructions often contain unpleasing noise or artifacts. To address both of the drawbacks, our method adopts two-stage training and network interpolation. The two-stage training is effective to stabilize the training. Moreover, the network interpolation utilizes the models in both stages and reduces undesirable noise and artifacts, while maintaining important edges. Hence, we can control the trade-off between perceptual quality and fidelity without re-training models. The experimental results show that our model can reconstruct high quality images. Furthermore, our user study confirms that our reconstructions are preferable to state-of-the-art GAN-based image compression model. The code will be available.
On-chip QNN: Towards Efficient On-Chip Training of Quantum Neural Networks
Feb 26, 2022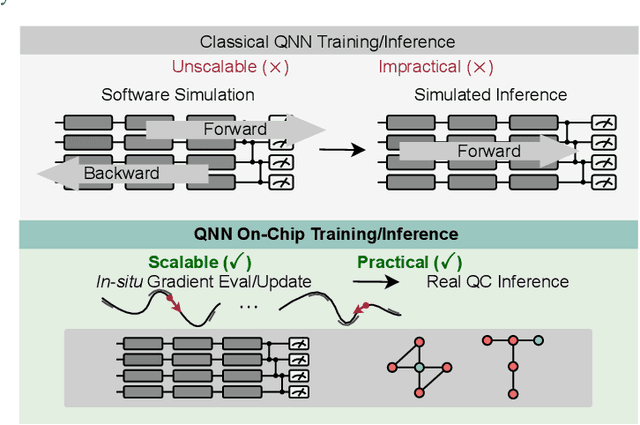
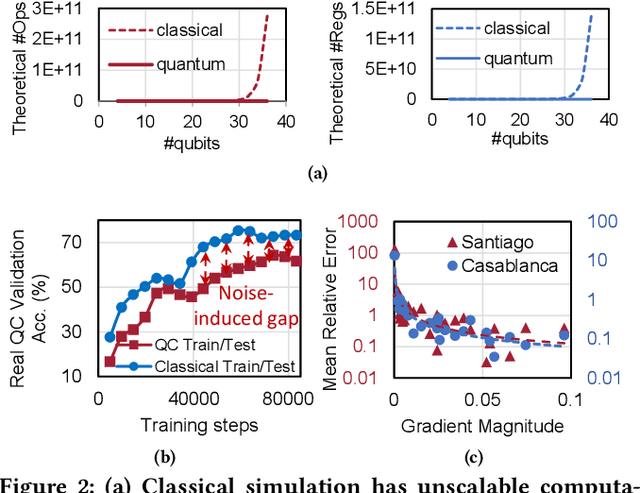

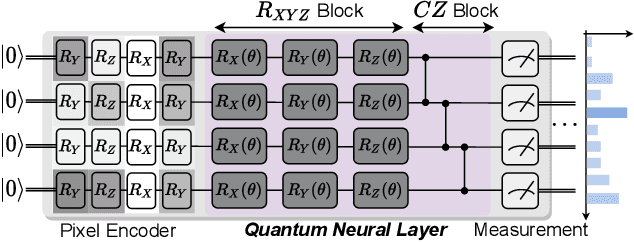
Quantum Neural Network (QNN) is drawing increasing research interest thanks to its potential to achieve quantum advantage on near-term Noisy Intermediate Scale Quantum (NISQ) hardware. In order to achieve scalable QNN learning, the training process needs to be offloaded to real quantum machines instead of using exponential-cost classical simulators. One common approach to obtain QNN gradients is parameter shift whose cost scales linearly with the number of qubits. We present On-chip QNN, the first experimental demonstration of practical on-chip QNN training with parameter shift. Nevertheless, we find that due to the significant quantum errors (noises) on real machines, gradients obtained from naive parameter shift have low fidelity and thus degrade the training accuracy. To this end, we further propose probabilistic gradient pruning to firstly identify gradients with potentially large errors and then remove them. Specifically, small gradients have larger relative errors than large ones, thus having a higher probability to be pruned. We perform extensive experiments on 5 classification tasks with 5 real quantum machines. The results demonstrate that our on-chip training achieves over 90% and 60% accuracy for 2-class and 4-class image classification tasks. The probabilistic gradient pruning brings up to 7% QNN accuracy improvements over no pruning. Overall, we successfully obtain similar on-chip training accuracy compared with noise-free simulation but have much better training scalability. The code for parameter shift on-chip training is available in the TorchQuantum library.
Improved Conditional Flow Models for Molecule to Image Synthesis
Jun 15, 2020
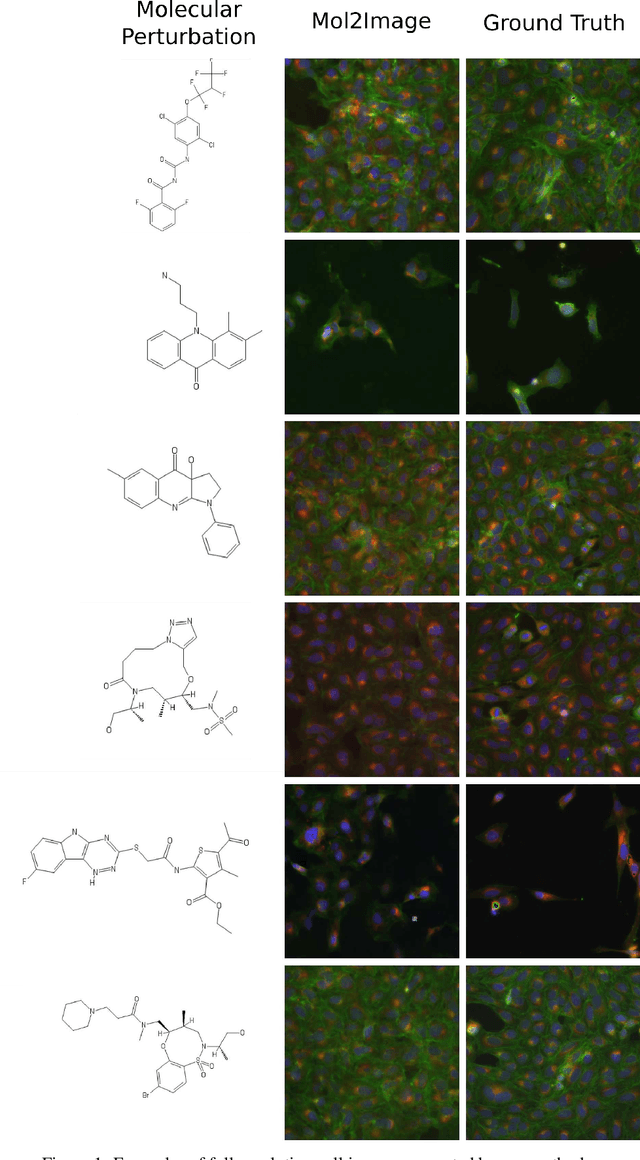

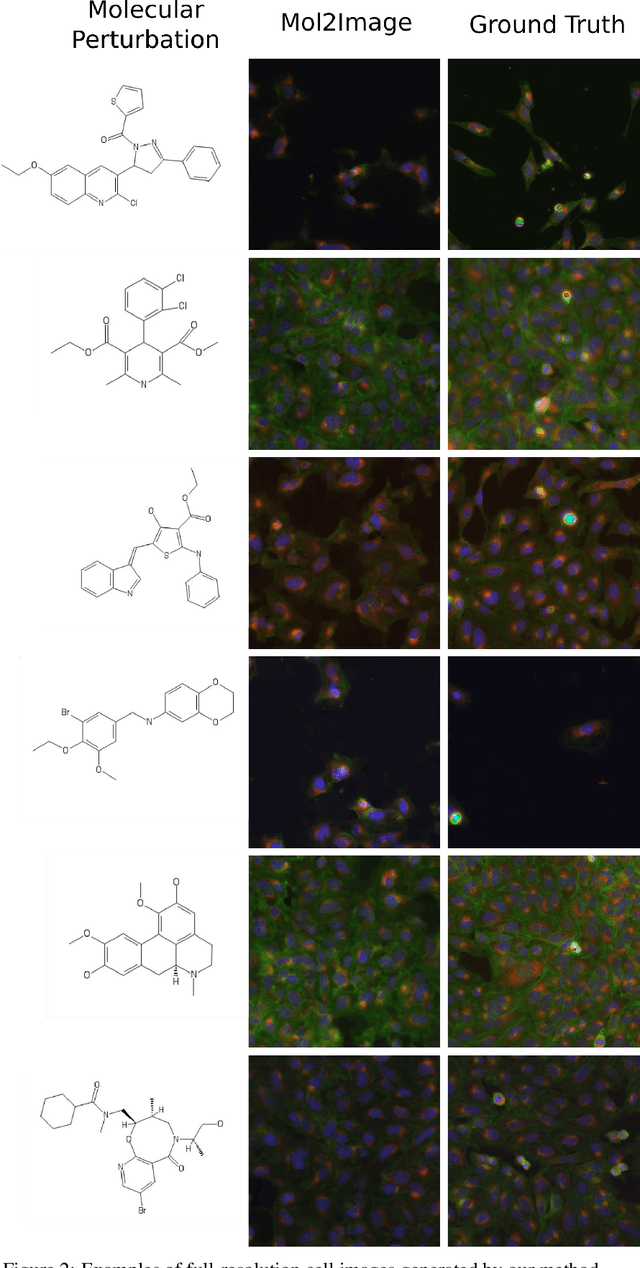
In this paper, we aim to synthesize cell microscopy images under different molecular interventions, motivated by practical applications to drug development. Building on the recent success of graph neural networks for learning molecular embeddings and flow-based models for image generation, we propose Mol2Image: a flow-based generative model for molecule to cell image synthesis. To generate cell features at different resolutions and scale to high-resolution images, we develop a novel multi-scale flow architecture based on a Haar wavelet image pyramid. To maximize the mutual information between the generated images and the molecular interventions, we devise a training strategy based on contrastive learning. To evaluate our model, we propose a new set of metrics for biological image generation that are robust, interpretable, and relevant to practitioners. We show quantitatively that our method learns a meaningful embedding of the molecular intervention, which is translated into an image representation reflecting the biological effects of the intervention.
Unsupervised Image Classification for Deep Representation Learning
Jun 20, 2020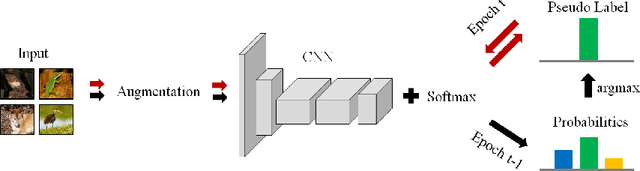
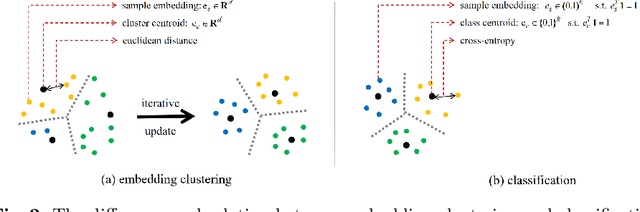
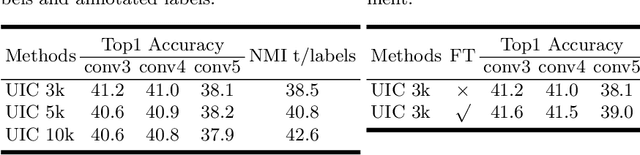

Deep clustering against self-supervised learning is a very important and promising direction for unsupervised visual representation learning since it requires little domain knowledge to design pretext tasks. However, the key component, embedding clustering, limits its extension to the extremely large-scale dataset due to its prerequisite to save the global latent embedding of the entire dataset. In this work, we aim to make this framework more simple and elegant without performance decline. We propose an unsupervised image classification framework without using embedding clustering, which is very similar to standard supervised training manner. For detailed interpretation, we further analyze its relation with deep clustering and contrastive learning. Extensive experiments on ImageNet dataset have been conducted to prove the effectiveness of our method. Furthermore, the experiments on transfer learning benchmarks have verified its generalization to other downstream tasks, including multi-label image classification, object detection, semantic segmentation and few-shot image classification.
GIQA: Generated Image Quality Assessment
Mar 19, 2020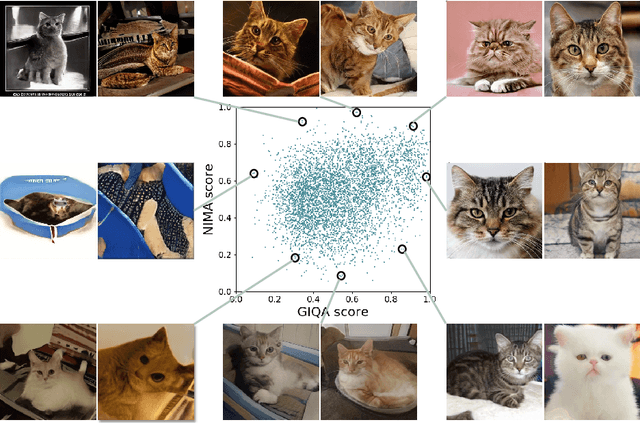
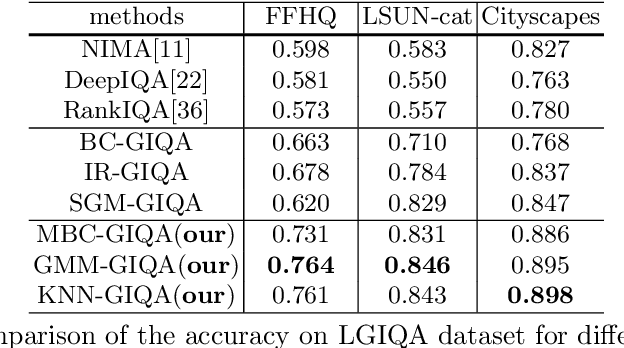
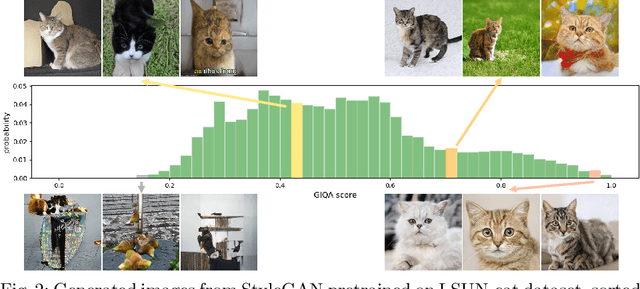

Generative adversarial networks (GANs) have achieved impressive results today, but not all generated images are perfect. A number of quantitative criteria have recently emerged for generative model, but none of them are designed for a single generated image. In this paper, we propose a new research topic, Generated Image Quality Assessment (GIQA), which quantitatively evaluates the quality of each generated image. We introduce three GIQA algorithms from two perspectives: learning-based and data-based. We evaluate a number of images generated by various recent GAN models on different datasets and demonstrate that they are consistent with human assessments. Furthermore, GIQA is available to many applications, like separately evaluating the realism and diversity of generative models, and enabling online hard negative mining (OHEM) in the training of GANs to improve the results.
Image-based Intraluminal Contact Force Monitoring in Robotic Vascular Navigation
Dec 19, 2020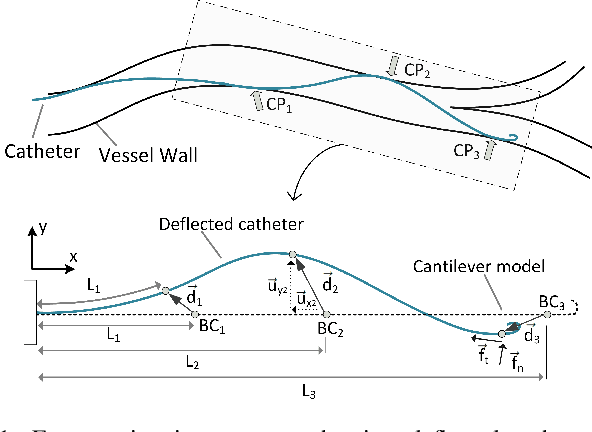
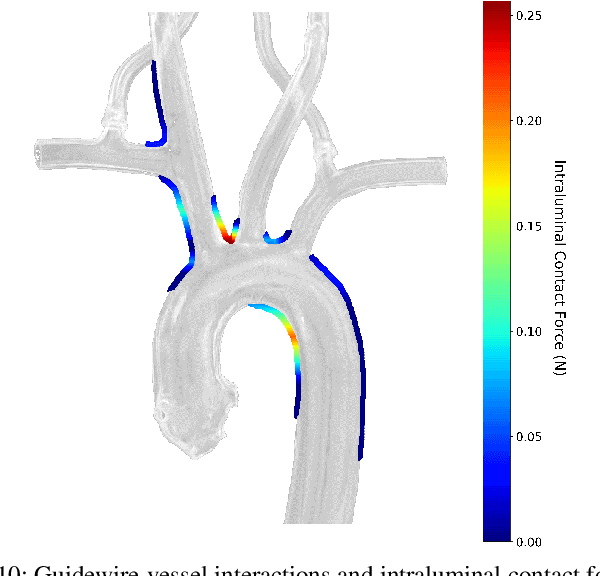
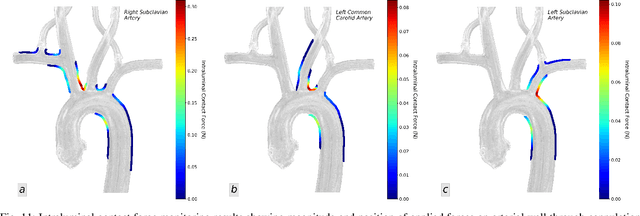
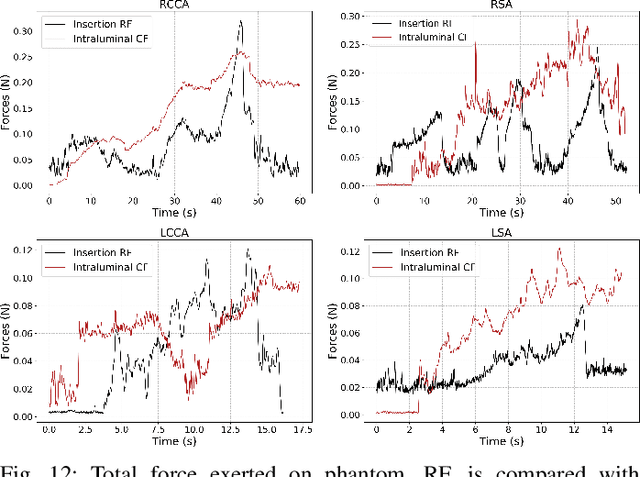
Embolization, stroke, ischaemic lesion, and perforation remain significant concerns in endovascular interventions. Sensing catheter interaction inside the artery is advantageous to minimize such complications and enhances navigation safety. Intraluminal information is currently limited due to the lack of intravascular contact sensing technologies. We present monitoring of the intraluminal catheter interaction with the arterial wall using an image-based estimation approach within vascular robotic navigation. The proposed image-based method employs continuous finite element simulation of the catheter motion using imaging data to estimate multi-point forces along catheter-vessel interaction. We implemented imaging algorithms to detect and track contacts and compute catheter pose measurements. The catheter model is constructed based on the nonlinear beam element and flexural rigidity distribution. During remote cannulation of aortic arteries, intraluminal monitoring achieved tracking local contact forces, building contour map of force on the arterial wall, and estimating structural stress of catheter. Shape estimation error was within 2% range. Results suggest that high-risk intraluminal forces may happen even in low insertion forces. The presented online monitoring tool delivers insight into the intraluminal behavior of catheters and is well-suited for intraoperative visual guidance of clinicians, robotic control vascular system, and optimizing interventional device design.