 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recent Trends in 2D Object Detection and Applications in Video Event Recognition
Feb 07, 2022
Object detection serves as a significant step in improving performance of complex downstream computer vision tasks. It has been extensively studied for many years now and current state-of-the-art 2D object detection techniques proffer superlative results even in complex images. In this chapter, we discuss the geometry-based pioneering works in object detection, followed by the recent breakthroughs that employ deep learning. Some of these use a monolithic architecture that takes a RGB image as input and passes it to a feed-forward ConvNet or vision Transformer. These methods, thereby predict class-probability and bounding-box coordinates, all in a single unified pipeline. Two-stage architectures on the other hand, first generate region proposals and then feed it to a CNN to extract features and predict object category and bounding-box. We also elaborate upon the applications of object detection in video event recognition, to achieve better fine-grained video classification performance. Further, we highlight recent datasets for 2D object detection both in images and videos, and present a comparative performance summary of various state-of-the-art object detection techniques.
Summarize and Search: Learning Consensus-aware Dynamic Convolution for Co-Saliency Detection
Oct 01, 2021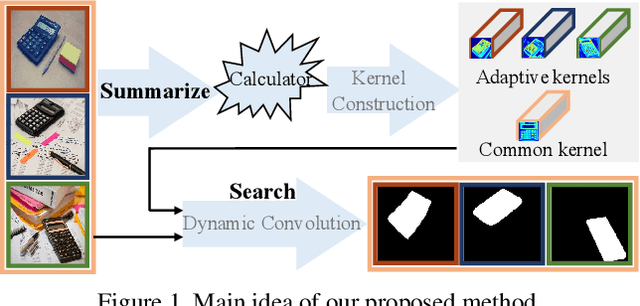
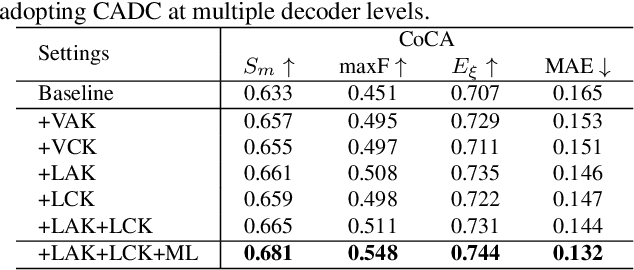
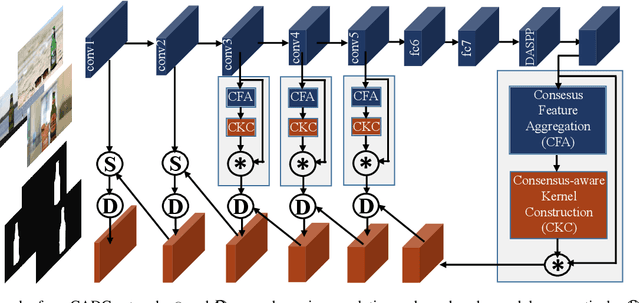
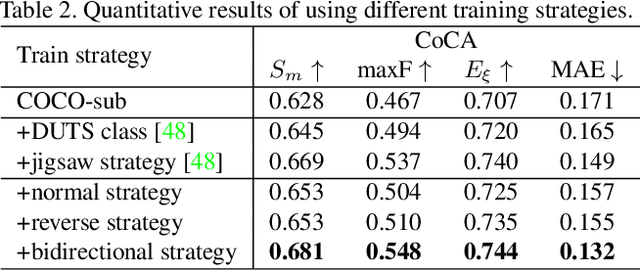
Humans perform co-saliency detection by first summarizing the consensus knowledge in the whole group and then searching corresponding objects in each image. Previous methods usually lack robustness, scalability, or stability for the first process and simply fuse consensus features with image features for the second process. In this paper, we propose a novel consensus-aware dynamic convolution model to explicitly and effectively perform the "summarize and search" process. To summarize consensus image features, we first summarize robust features for every single image using an effective pooling method and then aggregate cross-image consensus cues via the self-attention mechanism. By doing this, our model meets the scalability and stability requirements. Next, we generate dynamic kernels from consensus features to encode the summarized consensus knowledge. Two kinds of kernels are generated in a supplementary way to summarize fine-grained image-specific consensus object cues and the coarse group-wise common knowledge, respectively. Then, we can effectively perform object searching by employing dynamic convolution at multiple scales. Besides, a novel and effective data synthesis method is also proposed to train our network. Experimental results on four benchmark datasets verify the effectiveness of our proposed method. Our code and saliency maps are available at \url{https://github.com/nnizhang/CADC}.
CITRIS: Causal Identifiability from Temporal Intervened Sequences
Feb 07, 2022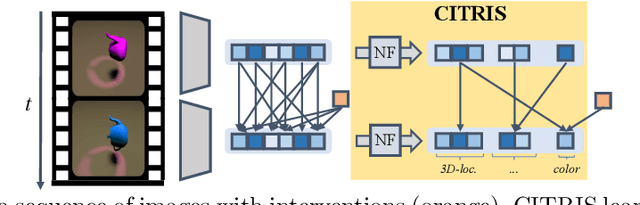
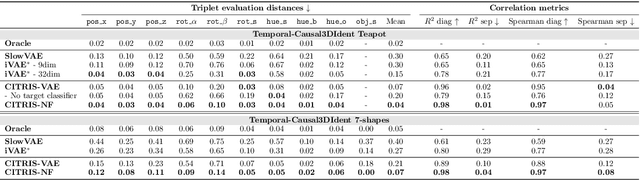

Understanding the latent causal factors of a dynamical system from visual observations is a crucial step towards agents reasoning in complex environments. In this paper, we propose CITRIS, a variational autoencoder framework that learns causal representations from temporal sequences of images in which underlying causal factors have possibly been intervened upon. In contrast to the recent literature, CITRIS exploits temporality and observing intervention targets to identify scalar and multidimensional causal factors, such as 3D rotation angles. Furthermore, by introducing a normalizing flow, CITRIS can be easily extended to leverage and disentangle representations obtained by already pretrained autoencoders. Extending previous results on scalar causal factors, we prove identifiability in a more general setting, in which only some components of a causal factor are affected by interventions. In experiments on 3D rendered image sequences, CITRIS outperforms previous methods on recovering the underlying causal variables. Moreover, using pretrained autoencoders, CITRIS can even generalize to unseen instantiations of causal factors, opening future research areas in sim-to-real generalization for causal representation learning.
Zero-Shot Text-Guided Object Generation with Dream Fields
Dec 02, 2021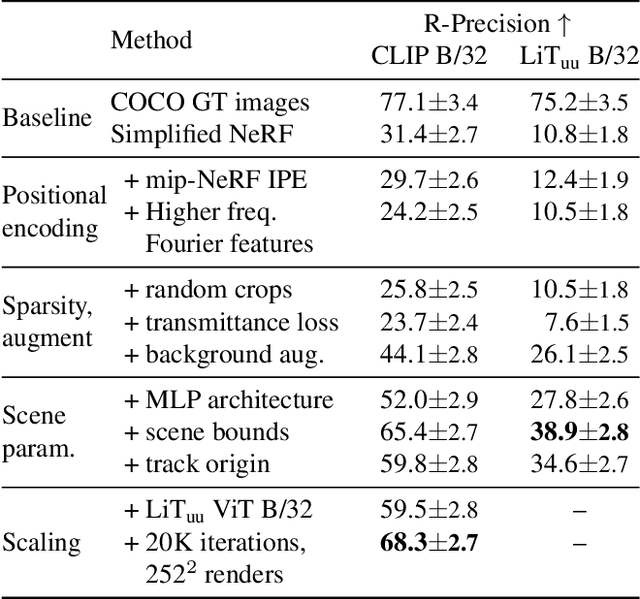

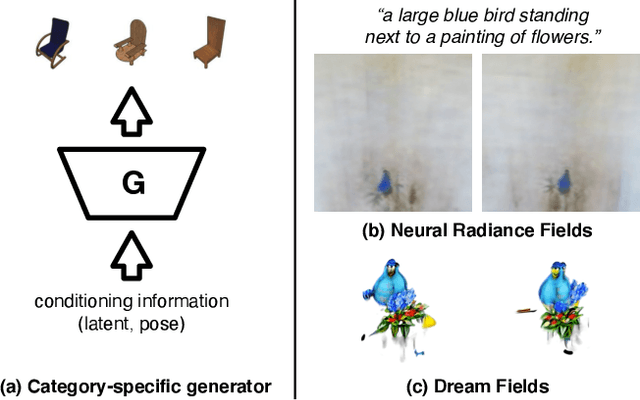
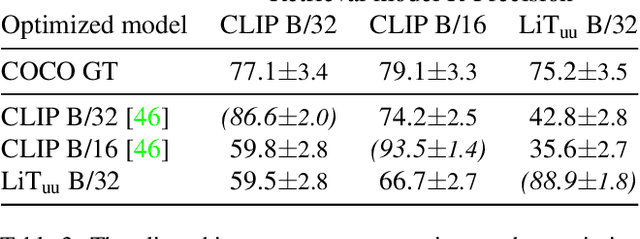
We combine neural rendering with multi-modal image and text representations to synthesize diverse 3D objects solely from natural language descriptions. Our method, Dream Fields, can generate the geometry and color of a wide range of objects without 3D supervision. Due to the scarcity of diverse, captioned 3D data, prior methods only generate objects from a handful of categories, such as ShapeNet. Instead, we guide generation with image-text models pre-trained on large datasets of captioned images from the web. Our method optimizes a Neural Radiance Field from many camera views so that rendered images score highly with a target caption according to a pre-trained CLIP model. To improve fidelity and visual quality, we introduce simple geometric priors, including sparsity-inducing transmittance regularization, scene bounds, and new MLP architectures. In experiments, Dream Fields produce realistic, multi-view consistent object geometry and color from a variety of natural language captions.
Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy
Dec 29, 2020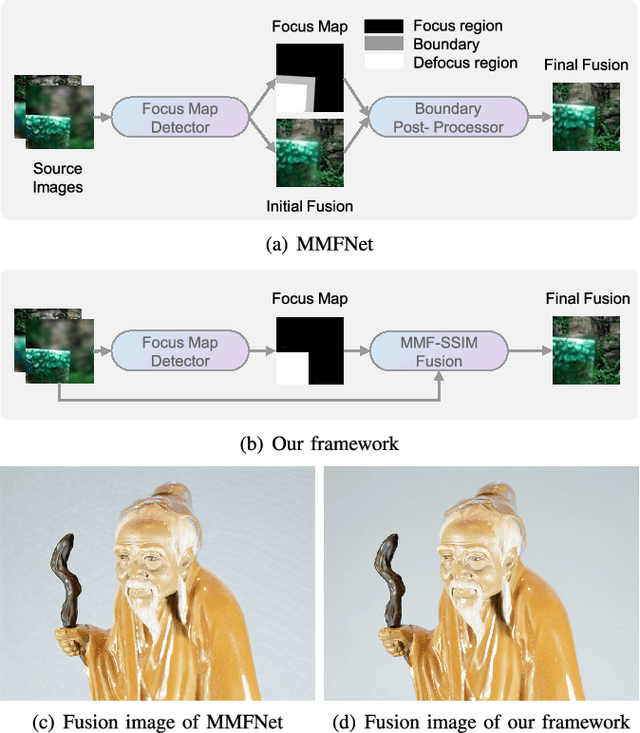
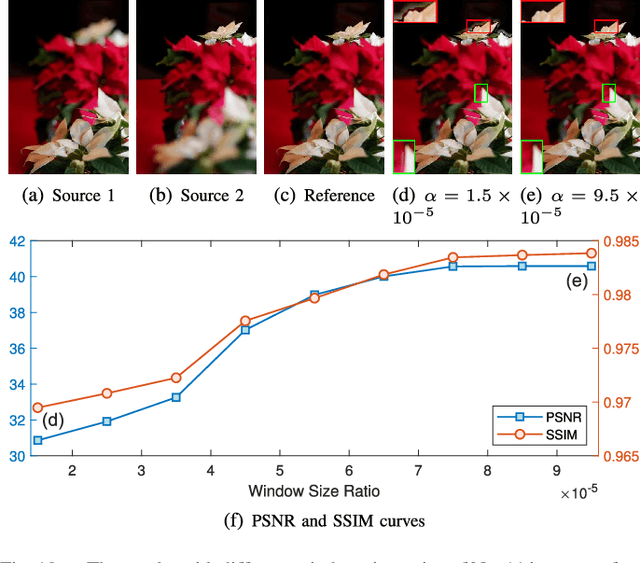


Multi-focus image fusion (MFF) is a popular technique to generate an all-in-focus image, where all objects in the scene are sharp. However, existing methods pay little attention to defocus spread effects of the real-world multi-focus images. Consequently, most of the methods perform badly in the areas near focus map boundaries. According to the idea that each local region in the fused image should be similar to the sharpest one among source images, this paper presents an optimization-based approach to reduce defocus spread effects. Firstly, a new MFF assessmentmetric is presented by combining the principle of structure similarity and detected focus maps. Then, MFF problem is cast into maximizing this metric. The optimization is solved by gradient ascent. Experiments conducted on the real-world dataset verify superiority of the proposed model. The codes are available at https://github.com/xsxjtu/MFF-SSIM.
Close the Visual Domain Gap by Physics-Grounded Active Stereovision Depth Sensor Simulation
Feb 07, 2022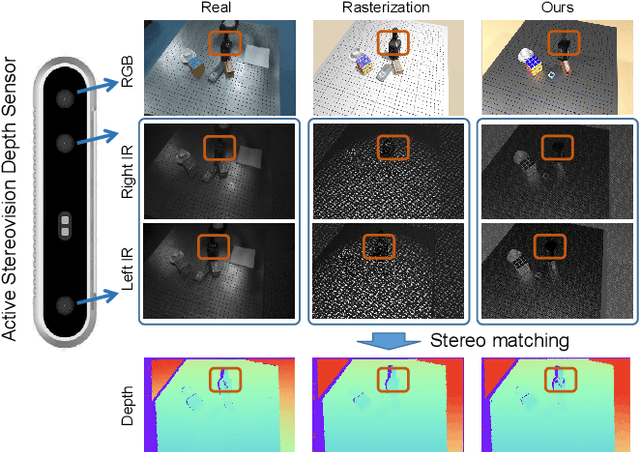
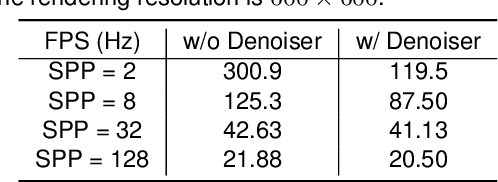
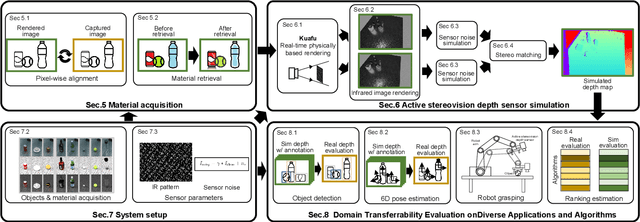
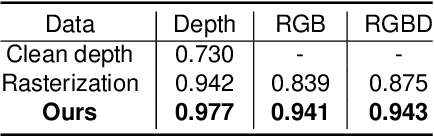
In this paper, we focus on the simulation of active stereovision depth sensors, which are popular in both academic and industry communities. Inspired by the underlying mechanism of the sensors, we designed a fully physics-grounded simulation pipeline, which includes material acquisition, ray tracing based infrared (IR) image rendering, IR noise simulation, and depth estimation. The pipeline is able to generate depth maps with material-dependent error patterns similar to a real depth sensor. We conduct extensive experiments to show that perception algorithms and reinforcement learning policies trained in our simulation platform could transfer well to real world test cases without any fine-tuning. Furthermore, due to the high degree of realism of this simulation, our depth sensor simulator can be used as a convenient testbed to evaluate the algorithm performance in the real world, which will largely reduce the human effort in developing robotic algorithms. The entire pipeline has been integrated into the SAPIEN simulator and is open-sourced to promote the research of vision and robotics communities.
Microstructure reconstruction via artificial neural networks: A combination of causal and non-causal approach
Oct 19, 2021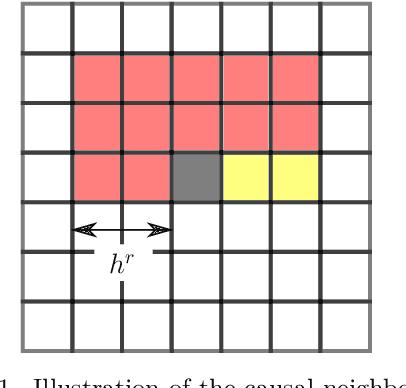
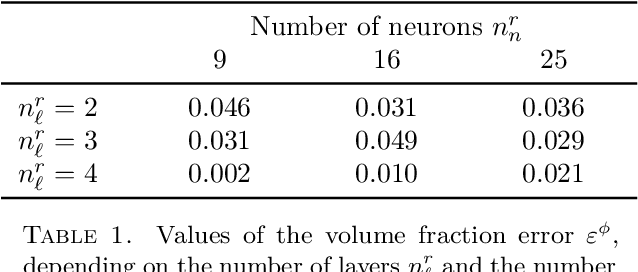


We investigate the applicability of artificial neural networks (ANNs) in reconstructing a sample image of a sponge-like microstructure. We propose to reconstruct the image by predicting the phase of the current pixel based on its causal neighbourhood, and subsequently, use a non-causal ANN model to smooth out the reconstructed image as a form of post-processing. We also consider the impacts of different configurations of the ANN model (e.g. number of densely connected layers, number of neurons in each layer, the size of both the causal and non-causal neighbourhood) on the models' predictive abilities quantified by the discrepancy between the spatial statistics of the reference and the reconstructed sample.
Batch Processing and Data Streaming Fourier-based Convolutional Neural Network Accelerator
Dec 23, 2021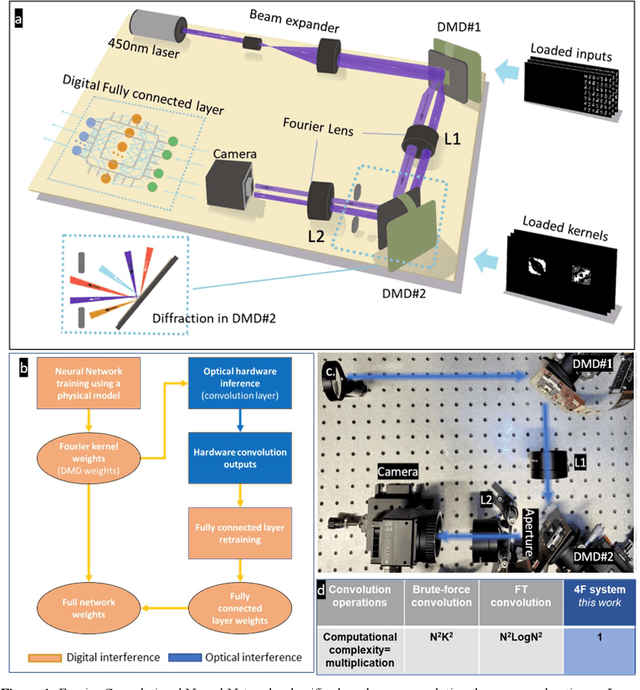

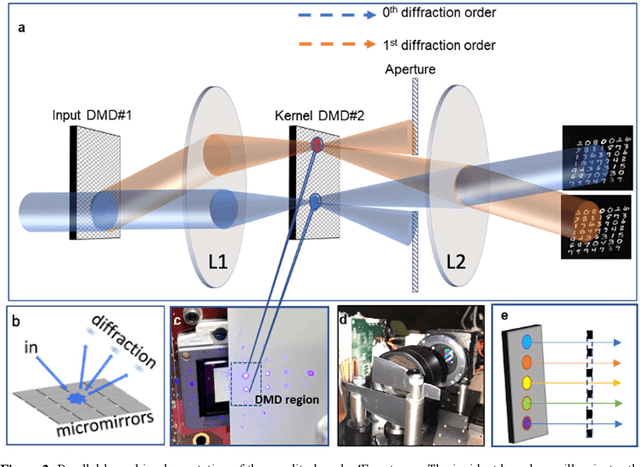
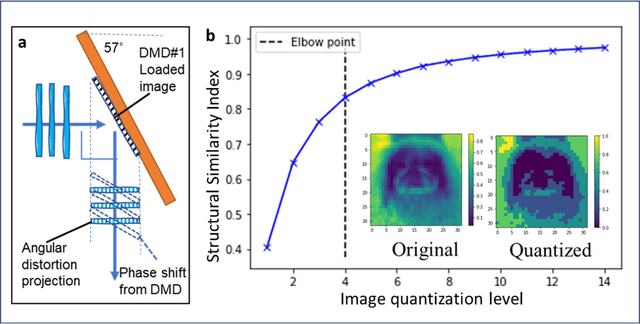
Decision-making by artificial neural networks with minimal latency is paramount for numerous applications such as navigation, tracking, and real-time machine action systems. This requires the machine learning hardware to handle multidimensional data with a high throughput. Processing convolution operations being the major computational tool for data classification tasks, unfortunately, follows a challenging run-time complexity scaling law. However, implementing the convolution theorem homomorphically in a Fourier-optic display-light-processor enables a non-iterative O(1) runtime complexity for data inputs beyond 1,000 x 1,000 large matrices. Following this approach, here we demonstrate data streaming multi-kernel image batch-processing with a Fourier Convolutional Neural Network (FCNN) accelerator. We show image batch processing of large-scale matrices as passive 2-million dot-product multiplications performed by digital light-processing modules in the Fourier domain. In addition, we parallelize this optical FCNN system further by utilizing multiple spatio-parallel diffraction orders, thus achieving a 98-times throughput improvement over state-of-art FCNN accelerators. The comprehensive discussion of the practical challenges related to working on the edge of the system's capabilities highlights issues of crosstalk in the Fourier domain and resolution scaling laws. Accelerating convolutions by utilizing the massive parallelism in display technology brings forth a non-van Neuman-based machine learning acceleration.
DGSS : Domain Generalized Semantic Segmentation using Iterative Style Mining and Latent Representation Alignment
Feb 26, 2022

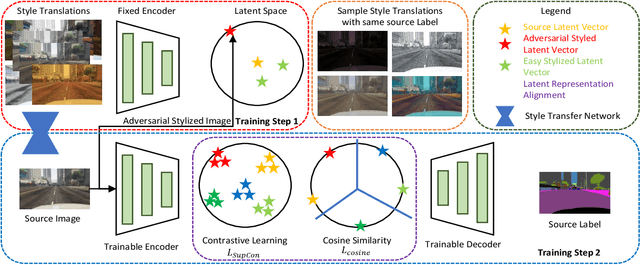

Semantic segmentation algorithms require access to well-annotated datasets captured under diverse illumination conditions to ensure consistent performance. However, poor visibility conditions at varying illumination conditions result in laborious and error-prone labeling. Alternatively, using synthetic samples to train segmentation algorithms has gained interest with the drawback of domain gap that results in sub-optimal performance. While current state-of-the-art (SoTA) have proposed different mechanisms to bridge the domain gap, they still perform poorly in low illumination conditions with an average performance drop of - 10.7 mIOU. In this paper, we focus upon single source domain generalization to overcome the domain gap and propose a two-step framework wherein we first identify an adversarial style that maximizes the domain gap between stylized and source images. Subsequently, these stylized images are used to categorically align features such that features belonging to the same class are clustered together in latent space, irrespective of domain gap. Furthermore, to increase intra-class variance while training, we propose a style mixing mechanism wherein the same objects from different styles are mixed to construct a new training image. This framework allows us to achieve a domain generalized semantic segmentation algorithm with consistent performance without prior information of the target domain while relying on a single source. Based on extensive experiments, we match SoTA performance on SYNTHIA $\to$ Cityscapes, GTAV $\to$ Cityscapes while setting new SoTA on GTAV $\to$ Dark Zurich and GTAV $\to$ Night Driving benchmarks without retraining.
Deep learning-based reconstruction of highly accelerated 3D MRI
Mar 09, 2022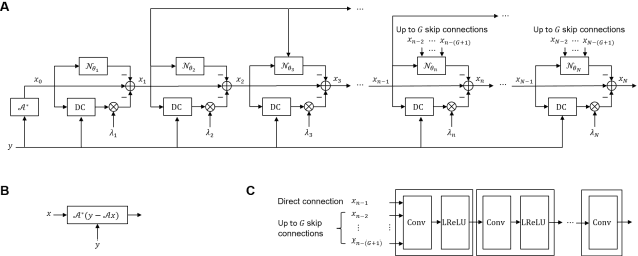
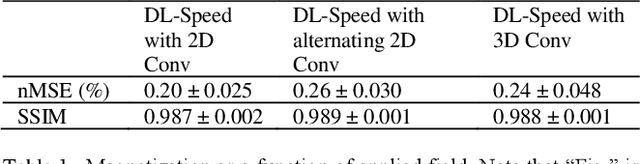
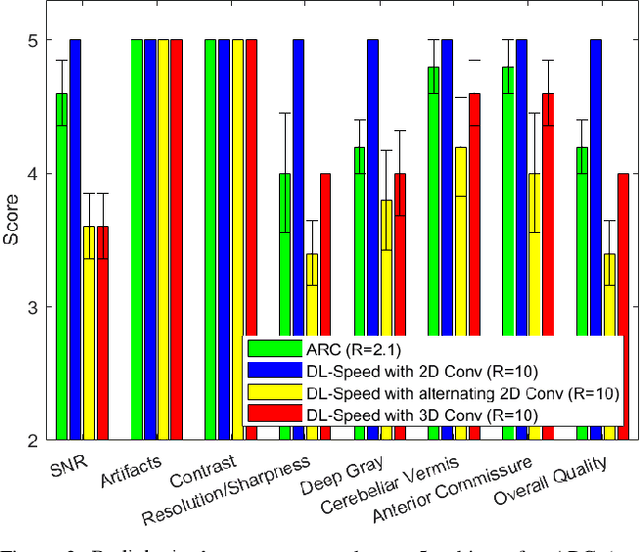
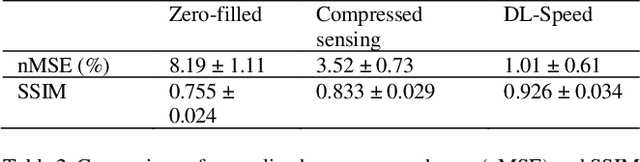
Purpose: To accelerate brain 3D MRI scans by using a deep learning method for reconstructing images from highly-undersampled multi-coil k-space data Methods: DL-Speed, an unrolled optimization architecture with dense skip-layer connections, was trained on 3D T1-weighted brain scan data to reconstruct complex-valued images from highly-undersampled k-space data. The trained model was evaluated on 3D MPRAGE brain scan data retrospectively-undersampled with a 10-fold acceleration, compared to a conventional parallel imaging method with a 2-fold acceleration. Scores of SNR, artifacts, gray/white matter contrast, resolution/sharpness, deep gray-matter, cerebellar vermis, anterior commissure, and overall quality, on a 5-point Likert scale, were assessed by experienced radiologists. In addition, the trained model was tested on retrospectively-undersampled 3D T1-weighted LAVA (Liver Acquisition with Volume Acceleration) abdominal scan data, and prospectively-undersampled 3D MPRAGE and LAVA scans in three healthy volunteers and one, respectively. Results: The qualitative scores for DL-Speed with a 10-fold acceleration were higher than or equal to those for the parallel imaging with 2-fold acceleration. DL-Speed outperformed a compressed sensing method in quantitative metrics on retrospectively-undersampled LAVA data. DL-Speed was demonstrated to perform reasonably well on prospectively-undersampled scan data, realizing a 2-5 times reduction in scan time. Conclusion: DL-Speed was shown to accelerate 3D MPRAGE and LAVA with up to a net 10-fold acceleration, achieving 2-5 times faster scans compared to conventional parallel imaging and acceleration, while maintaining diagnostic image quality and real-time reconstruction. The brain scan data-trained DL-Speed also performed well when reconstructing abdominal LAVA scan data, demonstrating versatility of the network.