 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DoFE: Domain-oriented Feature Embedding for Generalizable Fundus Image Segmentation on Unseen Datasets
Oct 13, 2020
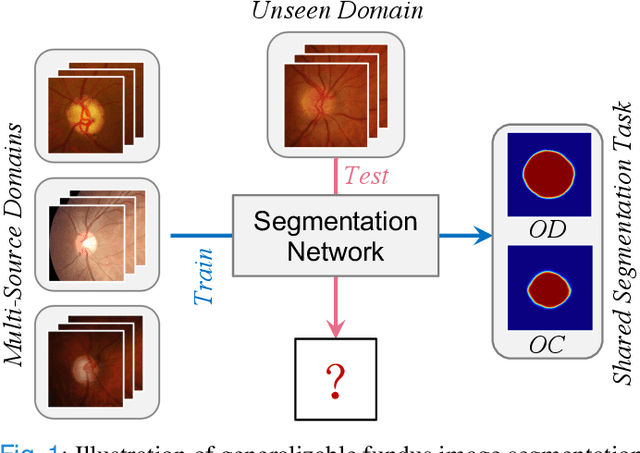
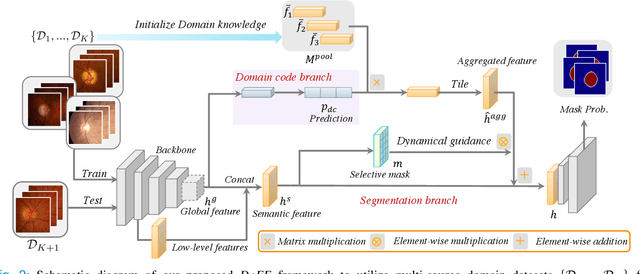
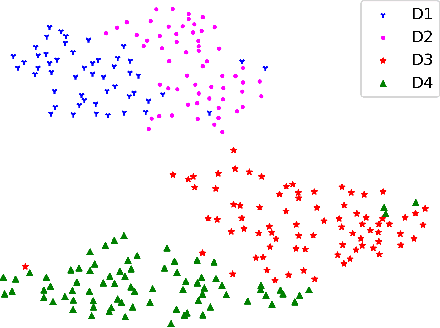
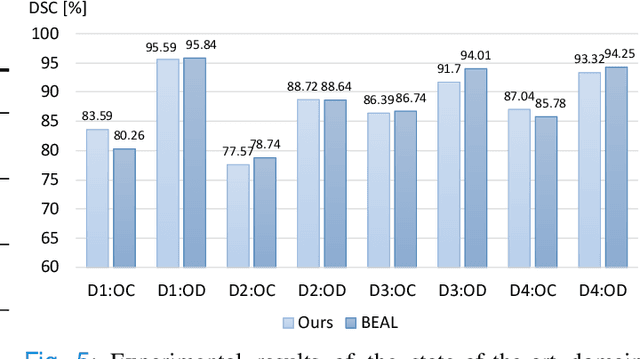
Deep convolutional neural networks have significantly boosted the performance of fundus image segmentation when test datasets have the same distribution as the training datasets. However, in clinical practice, medical images often exhibit variations in appearance for various reasons, e.g., different scanner vendors and image quality. These distribution discrepancies could lead the deep networks to over-fit on the training datasets and lack generalization ability on the unseen test datasets. To alleviate this issue, we present a novel Domain-oriented Feature Embedding (DoFE) framework to improve the generalization ability of CNNs on unseen target domains by exploring the knowledge from multiple source domains. Our DoFE framework dynamically enriches the image features with additional domain prior knowledge learned from multi-source domains to make the semantic features more discriminative. Specifically, we introduce a Domain Knowledge Pool to learn and memorize the prior information extracted from multi-source domains. Then the original image features are augmented with domain-oriented aggregated features, which are induced from the knowledge pool based on the similarity between the input image and multi-source domain images. We further design a novel domain code prediction branch to infer this similarity and employ an attention-guided mechanism to dynamically combine the aggregated features with the semantic features. We comprehensively evaluate our DoFE framework on two fundus image segmentation tasks, including the optic cup and disc segmentation and vessel segmentation. Our DoFE framework generates satisfying segmentation results on unseen datasets and surpasses other domain generalization and network regularization methods.
Masked Face Image Classification with Sparse Representation based on Majority Voting Mechanism
Nov 09, 2020
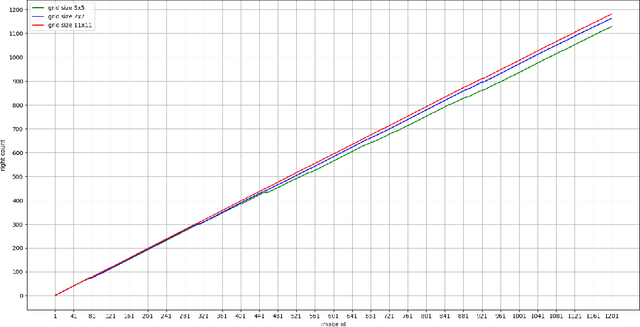
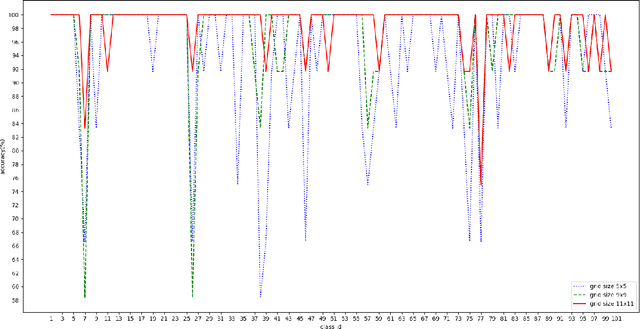
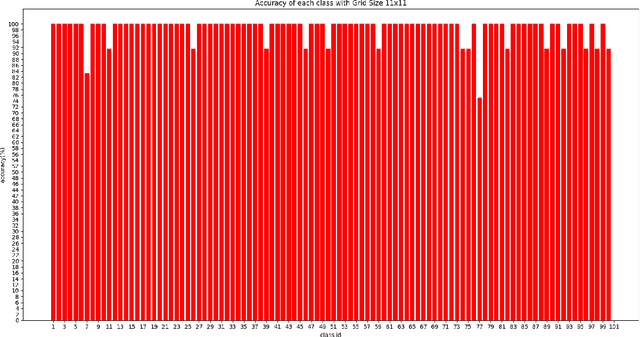
Sparse approximation is the problem to find the sparsest linear combination for a signal from a redundant dictionary, which is widely applied in signal processing and compressed sensing. In this project, I manage to implement the Orthogonal Matching Pursuit (OMP) algorithm and Sparse Representation-based Classification (SRC) algorithm, then use them to finish the task of masked image classification with majority voting. Here the experiment was token on the AR data-set, and the result shows the superiority of OMP algorithm combined with SRC algorithm over masked face image classification with an accuracy of 98.4%.
VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
Oct 07, 2020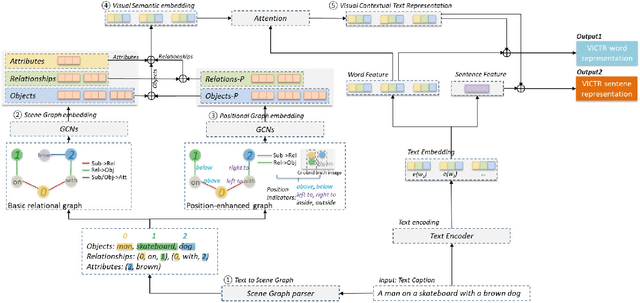
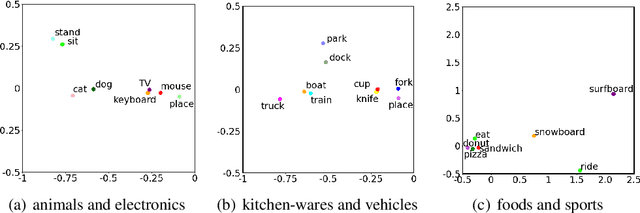
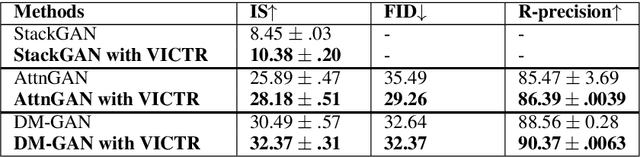
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.
Coordinate-Aligned Multi-Camera Collaboration for Active Multi-Object Tracking
Feb 22, 2022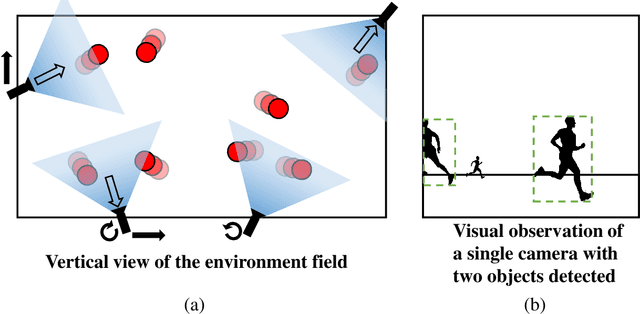
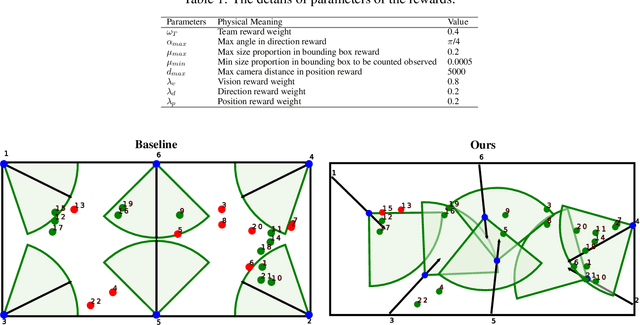
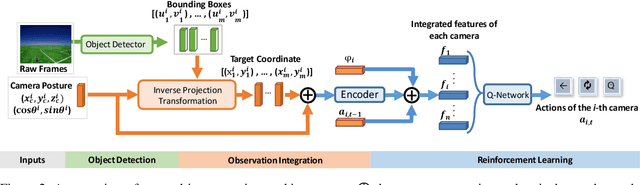

Active Multi-Object Tracking (AMOT) is a task where cameras are controlled by a centralized system to adjust their poses automatically and collaboratively so as to maximize the coverage of targets in their shared visual field. In AMOT, each camera only receives partial information from its observation, which may mislead cameras to take locally optimal action. Besides, the global goal, i.e., maximum coverage of objects, is hard to be directly optimized. To address the above issues, we propose a coordinate-aligned multi-camera collaboration system for AMOT. In our approach, we regard each camera as an agent and address AMOT with a multi-agent reinforcement learning solution. To represent the observation of each agent, we first identify the targets in the camera view with an image detector, and then align the coordinates of the targets in 3D environment. We define the reward of each agent based on both global coverage as well as four individual reward terms. The action policy of the agents is derived with a value-based Q-network. To the best of our knowledge, we are the first to study the AMOT task. To train and evaluate the efficacy of our system, we build a virtual yet credible 3D environment, named "Soccer Court", to mimic the real-world AMOT scenario. The experimental results show that our system achieves a coverage of 71.88%, outperforming the baseline method by 8.9%.
Weakly Supervised Keypoint Discovery
Sep 28, 2021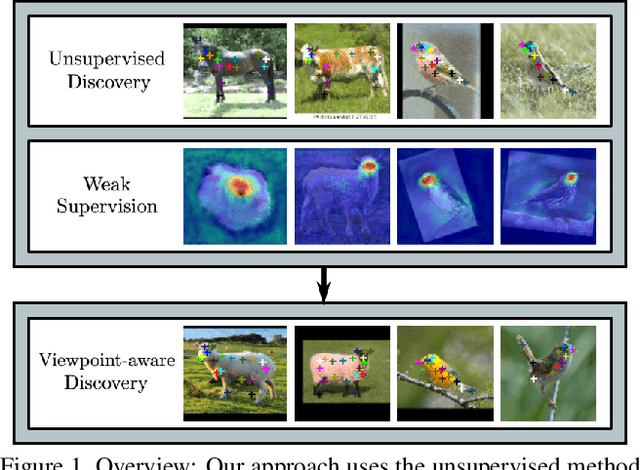

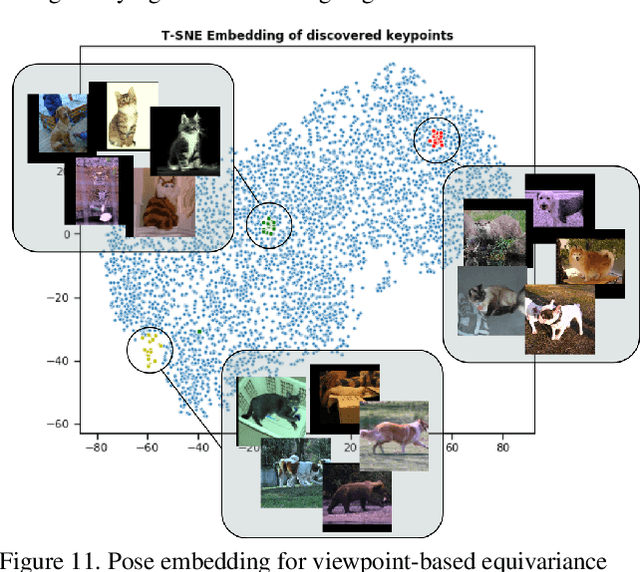

In this paper, we propose a method for keypoint discovery from a 2D image using image-level supervision. Recent works on unsupervised keypoint discovery reliably discover keypoints of aligned instances. However, when the target instances have high viewpoint or appearance variation, the discovered keypoints do not match the semantic correspondences over different images. Our work aims to discover keypoints even when the target instances have high viewpoint and appearance variation by using image-level supervision. Motivated by the weakly-supervised learning approach, our method exploits image-level supervision to identify discriminative parts and infer the viewpoint of the target instance. To discover diverse parts, we adopt a conditional image generation approach using a pair of images with structural deformation. Finally, we enforce a viewpoint-based equivariance constraint using the keypoints from the image-level supervision to resolve the spatial correlation problem that consistently appears in the images taken from various viewpoints. Our approach achieves state-of-the-art performance for the task of keypoint estimation on the limited supervision scenarios. Furthermore, the discovered keypoints are directly applicable to downstream tasks without requiring any keypoint labels.
MoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022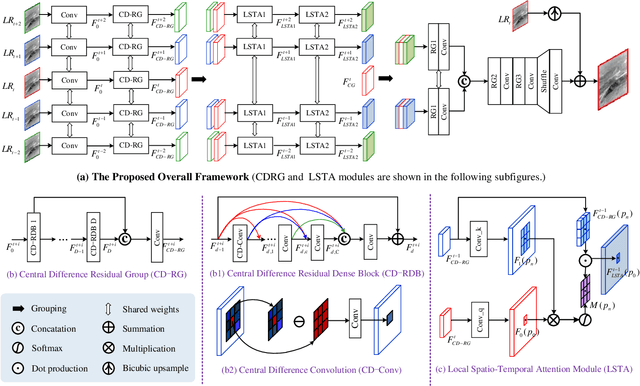
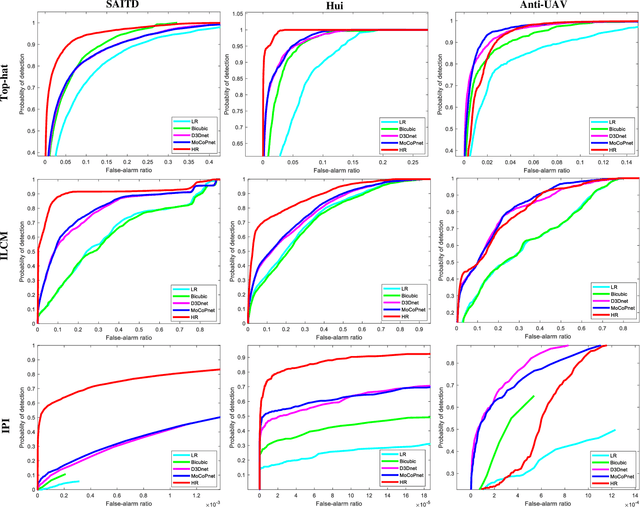

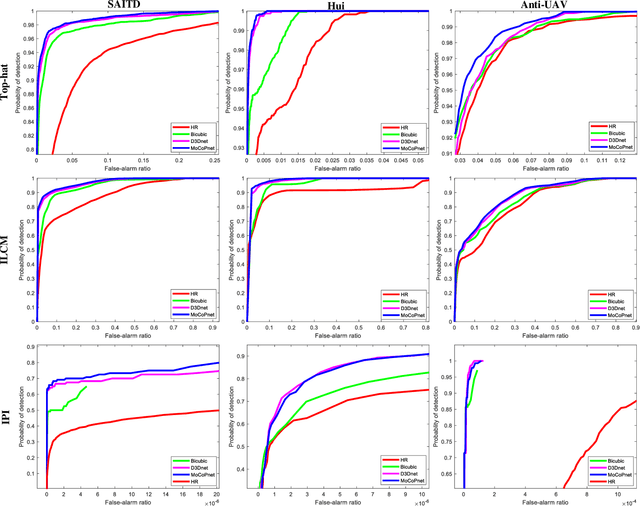
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
Learning to Improve Image Compression without Changing the Standard Decoder
Oct 23, 2020
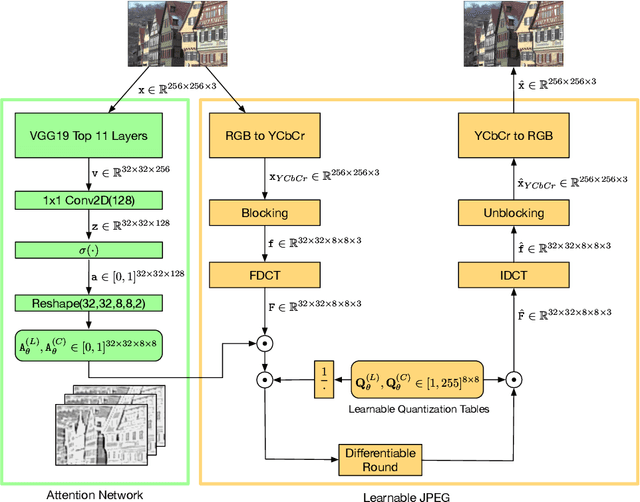
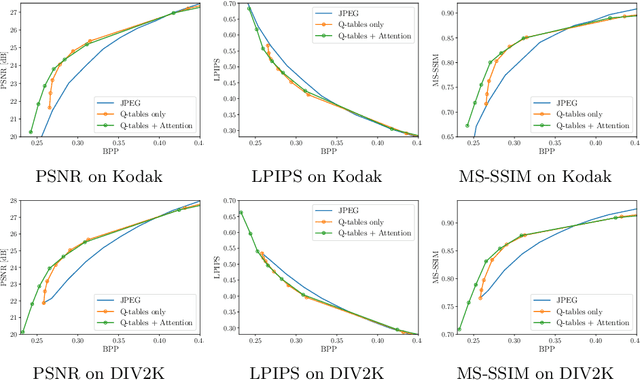

In recent years we have witnessed an increasing interest in applying Deep Neural Networks (DNNs) to improve the rate-distortion performance in image compression. However, the existing approaches either train a post-processing DNN on the decoder side, or propose learning for image compression in an end-to-end manner. This way, the trained DNNs are required in the decoder, leading to the incompatibility to the standard image decoders (e.g., JPEG) in personal computers and mobiles. Therefore, we propose learning to improve the encoding performance with the standard decoder. In this paper, We work on JPEG as an example. Specifically, a frequency-domain pre-editing method is proposed to optimize the distribution of DCT coefficients, aiming at facilitating the JPEG compression. Moreover, we propose learning the JPEG quantization table jointly with the pre-editing network. Most importantly, we do not modify the JPEG decoder and therefore our approach is applicable when viewing images with the widely used standard JPEG decoder. The experiments validate that our approach successfully improves the rate-distortion performance of JPEG in terms of various quality metrics, such as PSNR, MS-SSIM and LPIPS. Visually, this translates to better overall color retention especially when strong compression is applied. The codes are available at https://github.com/YannickStruempler/LearnedJPEG.
A Closer Look at Prototype Classifier for Few-shot Image Classification
Nov 02, 2021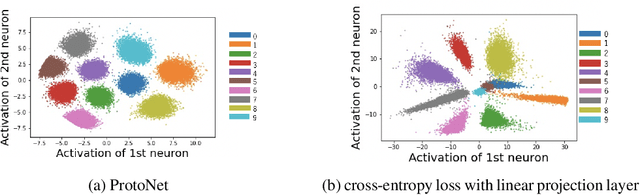
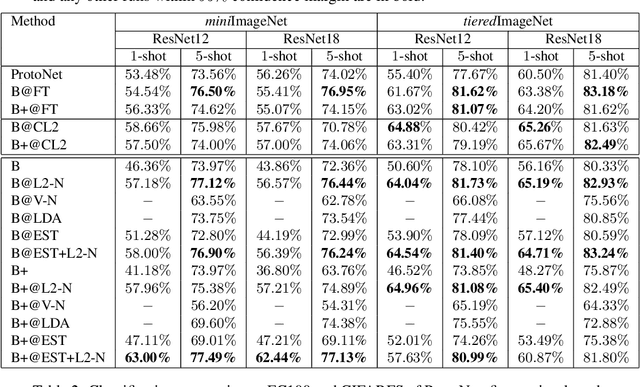
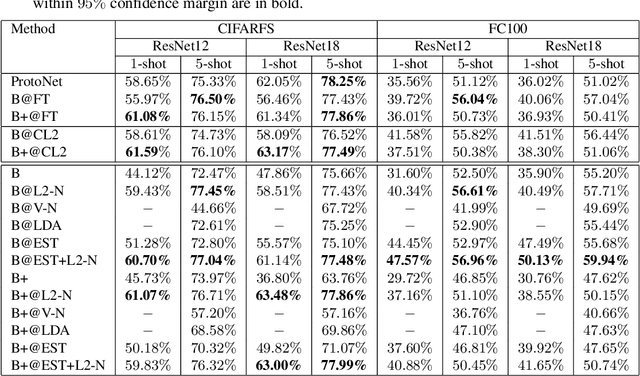
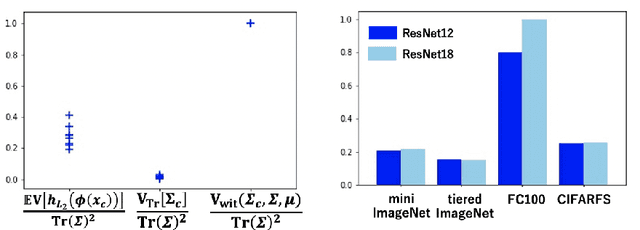
The prototypical network is a prototype classifier based on meta-learning and is widely used for few-shot learning because it classifies unseen examples by constructing class-specific prototypes without adjusting hyper-parameters during meta-testing. Interestingly, recent research has attracted a lot of attention, showing that a linear classifier with fine-tuning, which does not use a meta-learning algorithm, performs comparably with the prototypical network. However, fine-tuning requires additional hyper-parameters when adapting a model to a new environment. In addition, although the purpose of few-shot learning is to enable the model to quickly adapt to a new environment, fine-tuning needs to be applied every time a new class appears, making fast adaptation difficult. In this paper, we analyze how a prototype classifier works equally well without fine-tuning and meta-learning. We experimentally found that directly using the feature vector extracted using standard pre-trained models to construct a prototype classifier in meta-testing does not perform as well as the prototypical network and linear classifiers with fine-tuning and feature vectors of pre-trained models. Thus, we derive a novel generalization bound for the prototypical network and show that focusing on the variance of the norm of a feature vector can improve performance. We experimentally investigated several normalization methods for minimizing the variance of the norm and found that the same performance can be obtained by using the L2 normalization and embedding space transformation without fine-tuning or meta-learning.
Multiclass Burn Wound Image Classification Using Deep Convolutional Neural Networks
Mar 01, 2021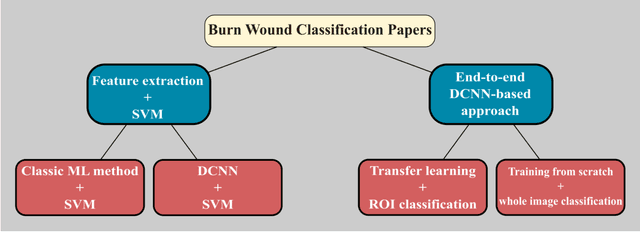
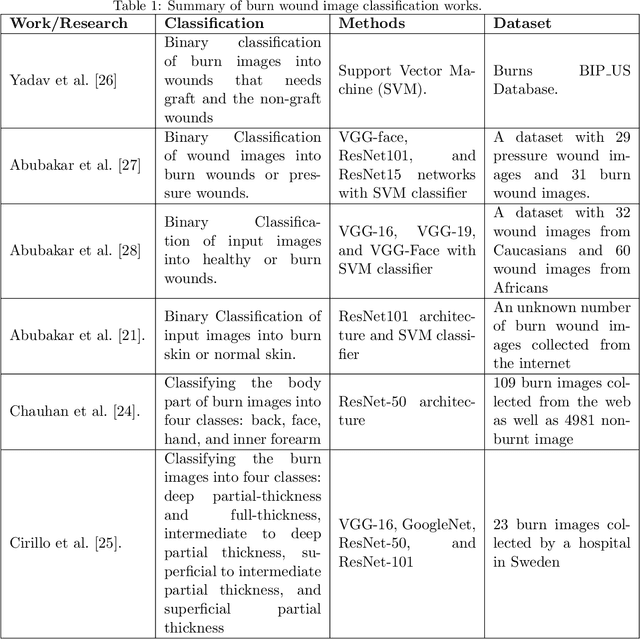
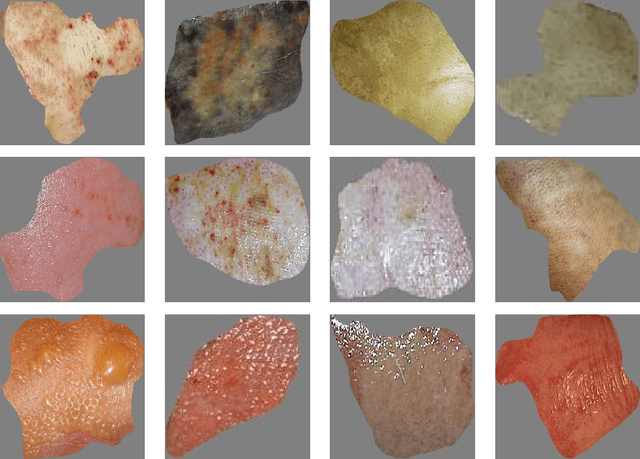
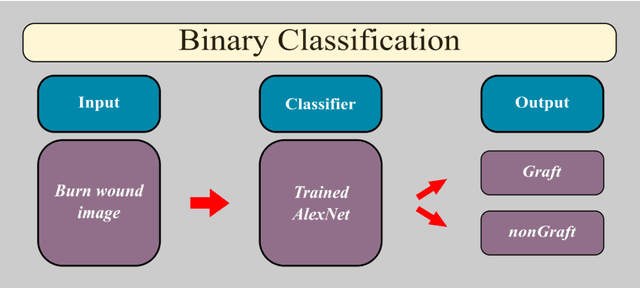
Millions of people are affected by acute and chronic wounds yearly across the world. Continuous wound monitoring is important for wound specialists to allow more accurate diagnosis and optimization of management protocols. Machine Learning-based classification approaches provide optimal care strategies resulting in more reliable outcomes, cost savings, healing time reduction, and improved patient satisfaction. In this study, we use a deep learning-based method to classify burn wound images into two or three different categories based on the wound conditions. A pre-trained deep convolutional neural network, AlexNet, is fine-tuned using a burn wound image dataset and utilized as the classifier. The classifier's performance is evaluated using classification metrics such as accuracy, precision, and recall as well as confusion matrix. A comparison with previous works that used the same dataset showed that our designed classifier improved the classification accuracy by more than 8%.
Self-Supervised Modality-Aware Multiple Granularity Pre-Training for RGB-Infrared Person Re-Identification
Dec 12, 2021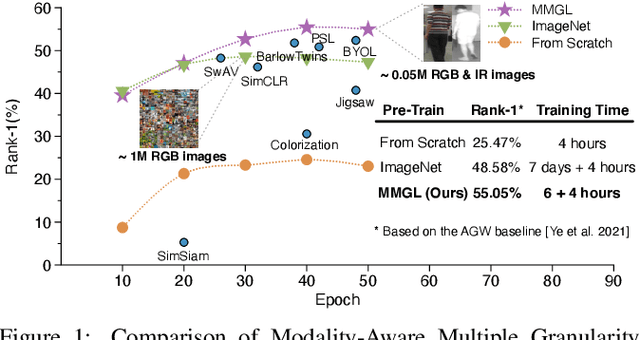
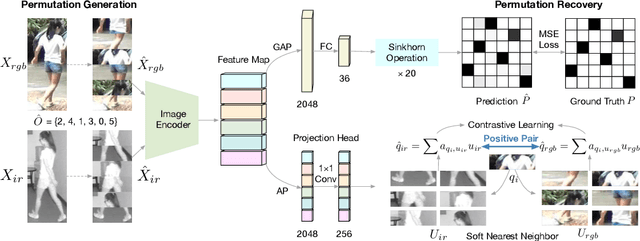
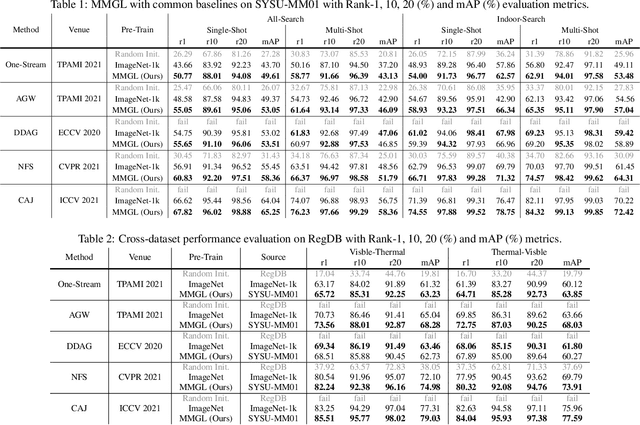
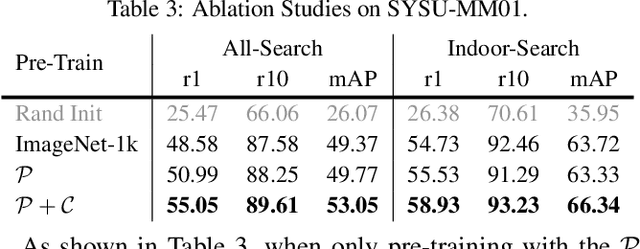
While RGB-Infrared cross-modality person re-identification (RGB-IR ReID) has enabled great progress in 24-hour intelligent surveillance, state-of-the-arts still heavily rely on fine-tuning ImageNet pre-trained networks. Due to the single-modality nature, such large-scale pre-training may yield RGB-biased representations that hinder the performance of cross-modality image retrieval. This paper presents a self-supervised pre-training alternative, named Modality-Aware Multiple Granularity Learning (MMGL), which directly trains models from scratch on multi-modality ReID datasets, but achieving competitive results without external data and sophisticated tuning tricks. Specifically, MMGL globally maps shuffled RGB-IR images into a shared latent permutation space and further improves local discriminability by maximizing agreement between cycle-consistent RGB-IR image patches. Experiments demonstrate that MMGL learns better representations (+6.47% Rank-1) with faster training speed (converge in few hours) and solider data efficiency (<5% data size) than ImageNet pre-training. The results also suggest it generalizes well to various existing models, losses and has promising transferability across datasets. The code will be released.