 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mixed Reality Depth Contour Occlusion Using Binocular Similarity Matching and Three-dimensional Contour Optimisation
Mar 04, 2022
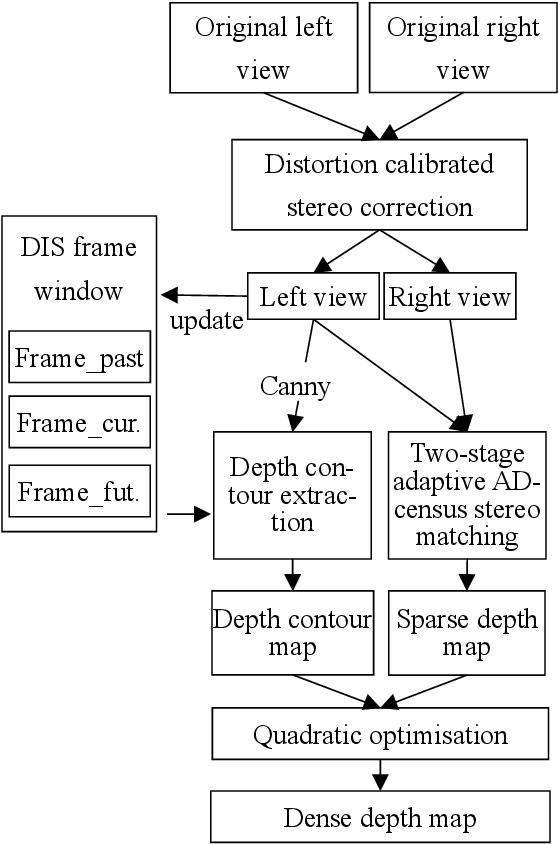
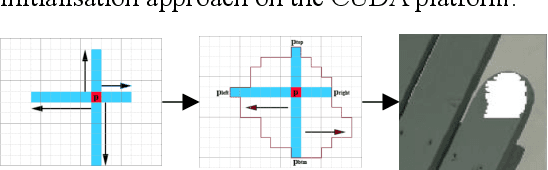
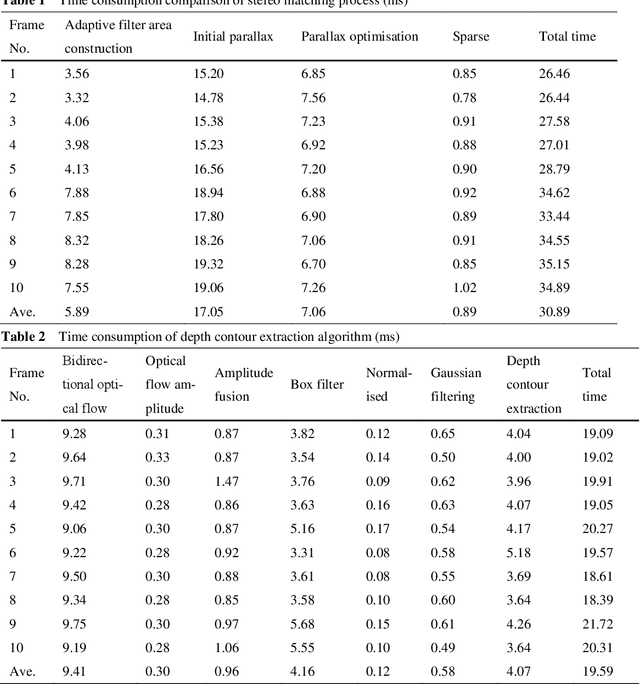

Mixed reality applications often require virtual objects that are partly occluded by real objects. However, previous research and commercial products have limitations in terms of performance and efficiency. To address these challenges, we propose a novel depth contour occlusion (DCO) algorithm. The proposed method is based on the sensitivity of contour occlusion and a binocular stereoscopic vision device. In this method, a depth contour map is combined with a sparse depth map obtained from a two-stage adaptive filter area stereo matching algorithm and the depth contour information of the objects extracted by a digital image stabilisation optical flow method. We also propose a quadratic optimisation model with three constraints to generate an accurate dense map of the depth contour for high-quality real-virtual occlusion. The whole process is accelerated by GPU. To evaluate the effectiveness of the algorithm, we demonstrate a time con-sumption statistical analysis for each stage of the DCO algorithm execution. To verify the relia-bility of the real-virtual occlusion effect, we conduct an experimental analysis on single-sided, enclosed, and complex occlusions; subsequently, we compare it with the occlusion method without quadratic optimisation. With our GPU implementation for real-time DCO, the evaluation indicates that applying the presented DCO algorithm can enhance the real-time performance and the visual quality of real-virtual occlusion.
FWB-Net:Front White Balance Network for Color Shift Correction in Single Image Dehazing via Atmospheric Light Estimation
Jan 21, 2021
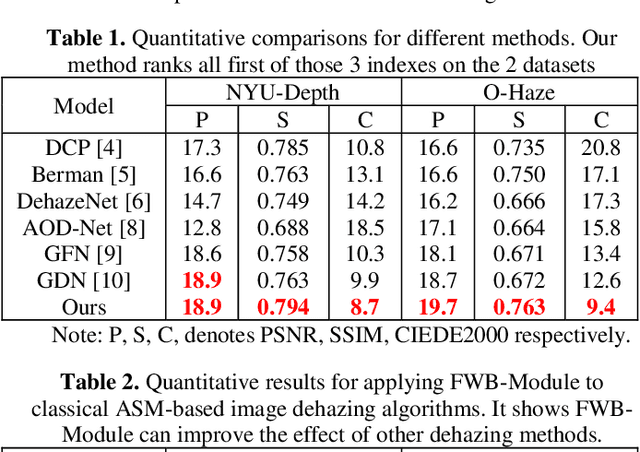
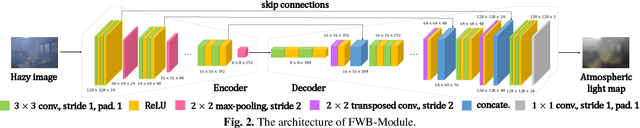
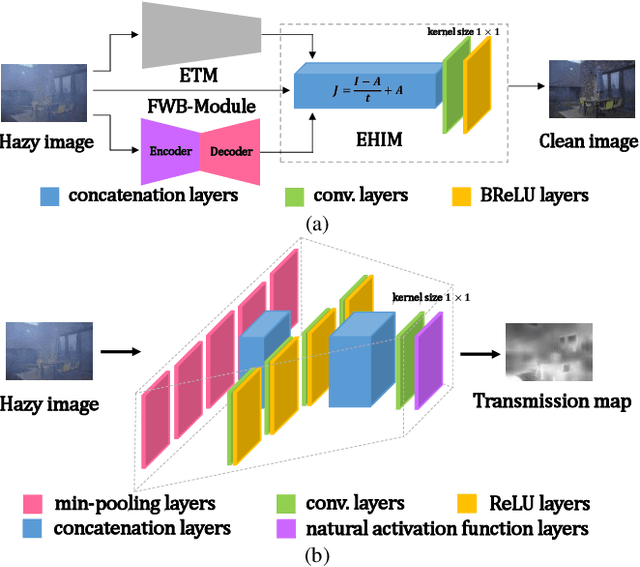
In recent years, single image dehazing deep models based on Atmospheric Scattering Model (ASM) have achieved remarkable results. But the dehazing outputs of those models suffer from color shift. Analyzing the ASM model shows that the atmospheric light factor (ALF) is set as a scalar which indicates ALF is constant for whole image. However, for images taken in real-world, the illumination is not uniformly distributed over whole image which brings model mismatch and possibly results in color shift of the deep models using ASM. Bearing this in mind, in this study, first, a new non-homogeneous atmospheric scattering model (NH-ASM) is proposed for improving image modeling of hazy images taken under complex illumination conditions. Second, a new U-Net based front white balance module (FWB-Module) is dedicatedly designed to correct color shift before generating dehazing result via atmospheric light estimation. Third, a new FWB loss is innovatively developed for training FWB-Module, which imposes penalty on color shift. In the end, based on NH-ASM and front white balance technology, an end-to-end CNN-based color-shift-restraining dehazing network is developed, termed as FWB-Net. Experimental results demonstrate the effectiveness and superiority of our proposed FWB-Net for dehazing on both synthetic and real-world images.
A Gating Model for Bias Calibration in Generalized Zero-shot Learning
Mar 08, 2022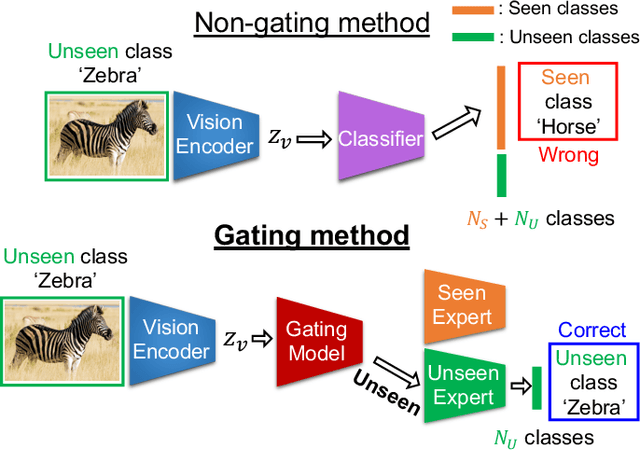
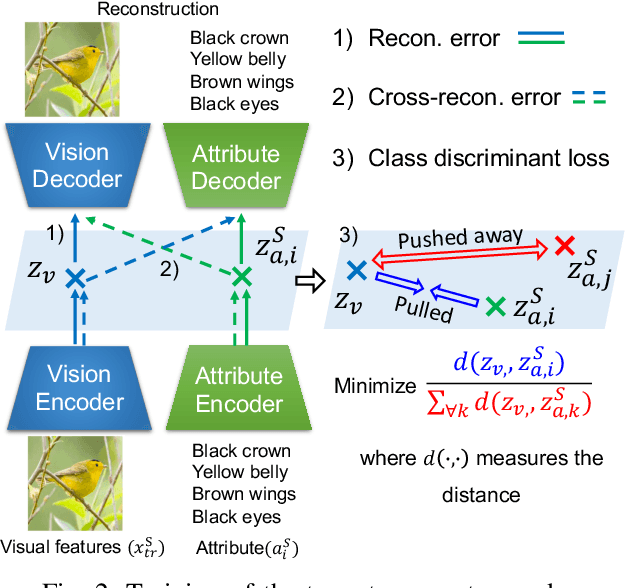
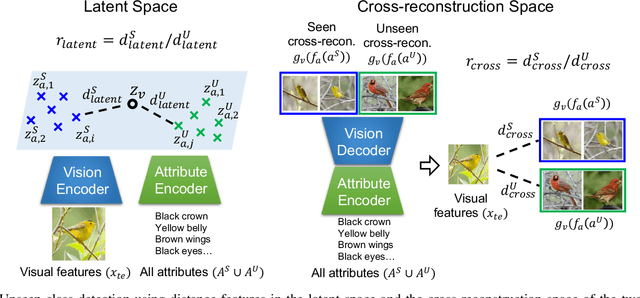

Generalized zero-shot learning (GZSL) aims at training a model that can generalize to unseen class data by only using auxiliary information. One of the main challenges in GZSL is a biased model prediction toward seen classes caused by overfitting on only available seen class data during training. To overcome this issue, we propose a two-stream autoencoder-based gating model for GZSL. Our gating model predicts whether the query data is from seen classes or unseen classes, and utilizes separate seen and unseen experts to predict the class independently from each other. This framework avoids comparing the biased prediction scores for seen classes with the prediction scores for unseen classes. In particular, we measure the distance between visual and attribute representations in the latent space and the cross-reconstruction space of the autoencoder. These distances are utilized as complementary features to characterize unseen classes at different levels of data abstraction. Also, the two-stream autoencoder works as a unified framework for the gating model and the unseen expert, which makes the proposed method computationally efficient. We validate our proposed method in four benchmark image recognition datasets. In comparison with other state-of-the-art methods, we achieve the best harmonic mean accuracy in SUN and AWA2, and the second best in CUB and AWA1. Furthermore, our base model requires at least 20% less number of model parameters than state-of-the-art methods relying on generative models.
Look at here : Utilizing supervision to attend subtle key regions
Nov 25, 2021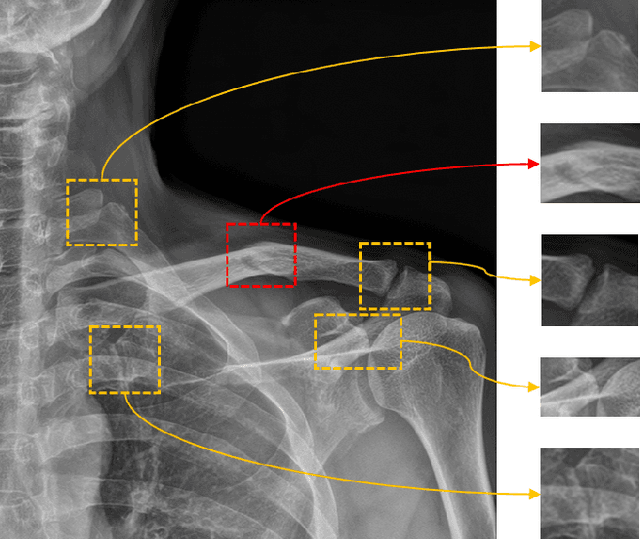

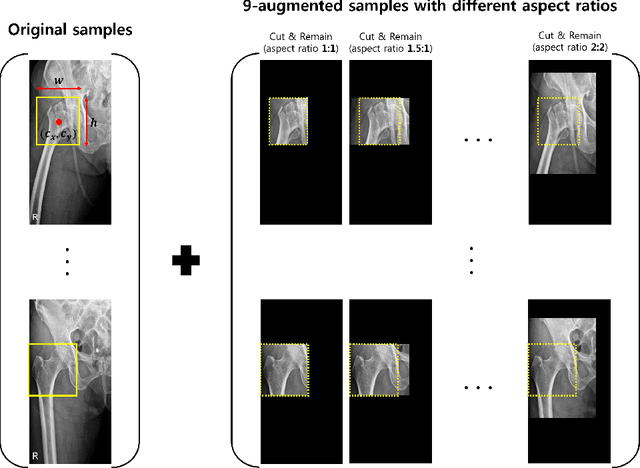
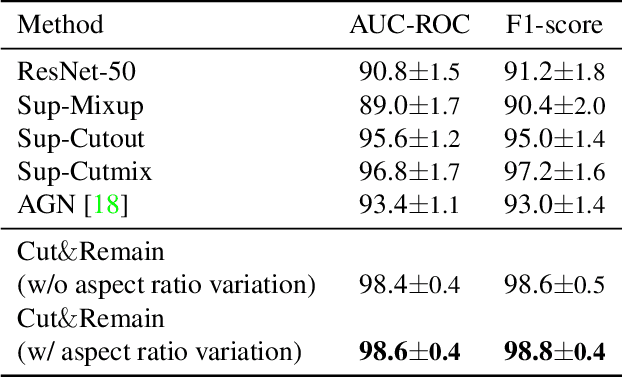
Despite the success of deep learning in computer vision, algorithms to recognize subtle and small objects (or regions) is still challenging. For example, recognizing a baseball or a frisbee on a ground scene or a bone fracture in an X-ray image can easily result in overfitting, unless a huge amount of training data is available. To mitigate this problem, we need a way to force a model should identify subtle regions in limited training data. In this paper, we propose a simple but efficient supervised augmentation method called Cut\&Remain. It achieved better performance on various medical image domain (internally sourced- and public dataset) and a natural image domain (MS-COCO$_s$) than other supervised augmentation and the explicit guidance methods. In addition, using the class activation map, we identified that the Cut\&Remain methods drive a model to focus on relevant subtle and small regions efficiently. We also show that the performance monotonically increased along the Cut\&Remain ratio, indicating that a model can be improved even though only limited amount of Cut\&Remain is applied for, so that it allows low supervising (annotation) cost for improvement.
Synchronized Audio-Visual Frames with Fractional Positional Encoding for Transformers in Video-to-Text Translation
Dec 28, 2021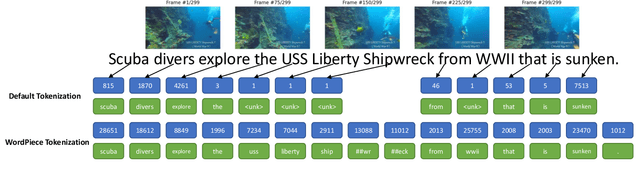
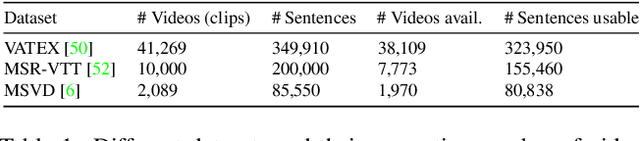
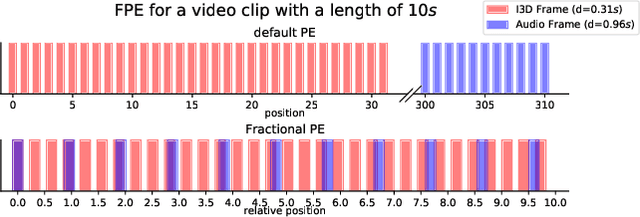
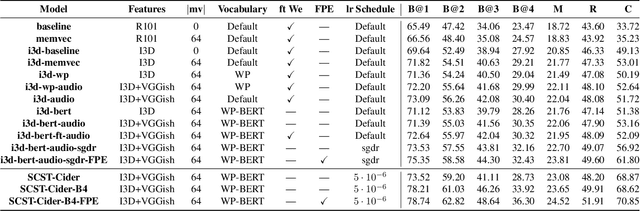
Video-to-Text (VTT) is the task of automatically generating descriptions for short audio-visual video clips, which can support visually impaired people to understand scenes of a YouTube video for instance. Transformer architectures have shown great performance in both machine translation and image captioning, lacking a straightforward and reproducible application for VTT. However, there is no comprehensive study on different strategies and advice for video description generation including exploiting the accompanying audio with fully self-attentive networks. Thus, we explore promising approaches from image captioning and video processing and apply them to VTT by developing a straightforward Transformer architecture. Additionally, we present a novel way of synchronizing audio and video features in Transformers which we call Fractional Positional Encoding (FPE). We run multiple experiments on the VATEX dataset to determine a configuration applicable to unseen datasets that helps describe short video clips in natural language and improved the CIDEr and BLEU-4 scores by 37.13 and 12.83 points compared to a vanilla Transformer network and achieve state-of-the-art results on the MSR-VTT and MSVD datasets. Also, FPE helps increase the CIDEr score by a relative factor of 8.6%.
Kernel Proposal Network for Arbitrary Shape Text Detection
Mar 12, 2022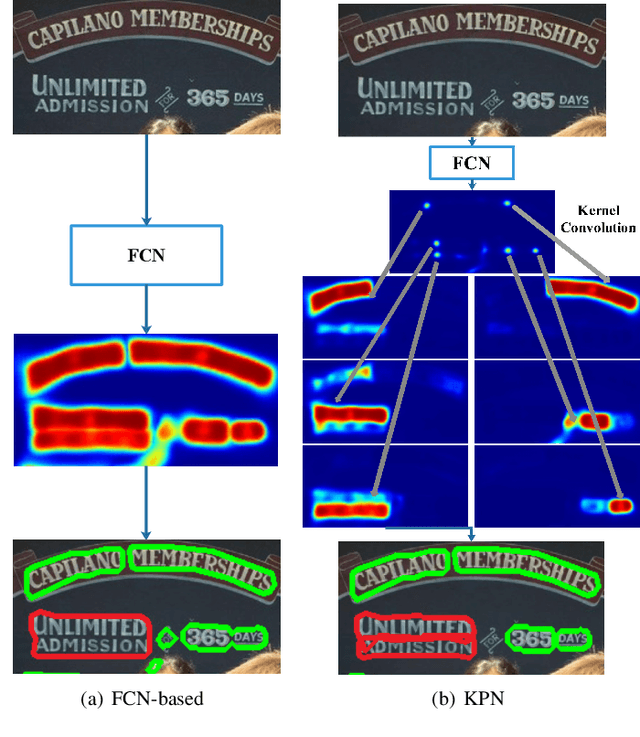


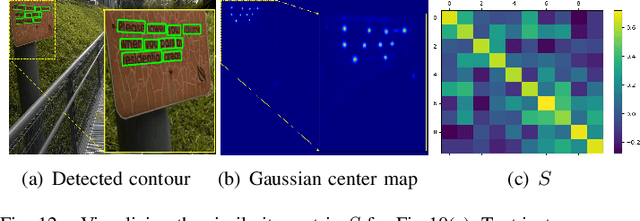
Segmentation-based methods have achieved great success for arbitrary shape text detection. However, separating neighboring text instances is still one of the most challenging problems due to the complexity of texts in scene images. In this paper, we propose an innovative Kernel Proposal Network (dubbed KPN) for arbitrary shape text detection. The proposed KPN can separate neighboring text instances by classifying different texts into instance-independent feature maps, meanwhile avoiding the complex aggregation process existing in segmentation-based arbitrary shape text detection methods. To be concrete, our KPN will predict a Gaussian center map for each text image, which will be used to extract a series of candidate kernel proposals (i.e., dynamic convolution kernel) from the embedding feature maps according to their corresponding keypoint positions. To enforce the independence between kernel proposals, we propose a novel orthogonal learning loss (OLL) via orthogonal constraints. Specifically, our kernel proposals contain important self-information learned by network and location information by position embedding. Finally, kernel proposals will individually convolve all embedding feature maps for generating individual embedded maps of text instances. In this way, our KPN can effectively separate neighboring text instances and improve the robustness against unclear boundaries. To our knowledge, our work is the first to introduce the dynamic convolution kernel strategy to efficiently and effectively tackle the adhesion problem of neighboring text instances in text detection. Experimental results on challenging datasets verify the impressive performance and efficiency of our method. The code and model are available at https://github.com/GXYM/KPN.
Simultaneous Multivariate Forecast of Space Weather Indices using Deep Neural Network Ensembles
Dec 16, 2021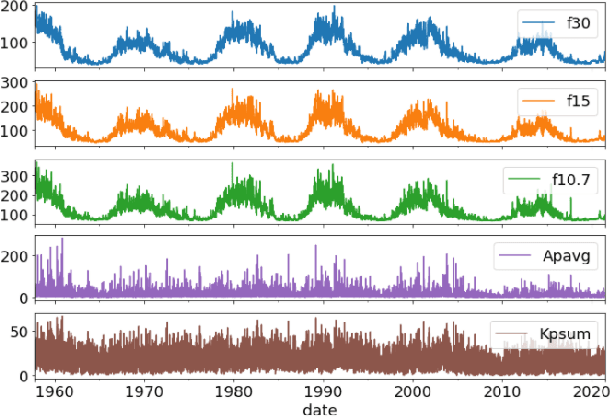
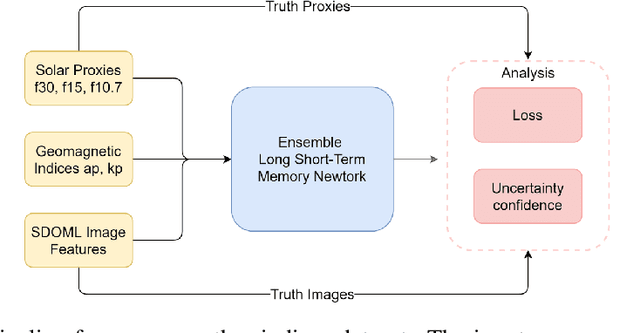
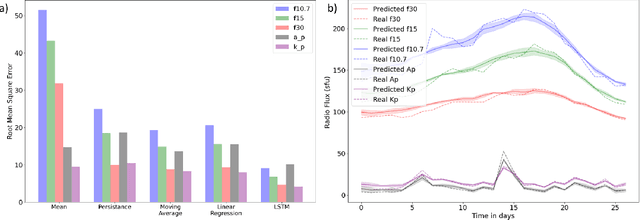
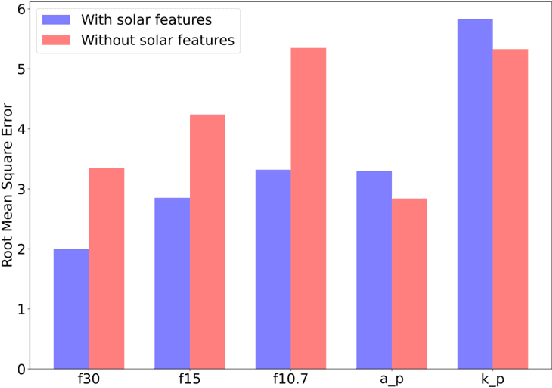
Solar radio flux along with geomagnetic indices are important indicators of solar activity and its effects. Extreme solar events such as flares and geomagnetic storms can negatively affect the space environment including satellites in low-Earth orbit. Therefore, forecasting these space weather indices is of great importance in space operations and science. In this study, we propose a model based on long short-term memory neural networks to learn the distribution of time series data with the capability to provide a simultaneous multivariate 27-day forecast of the space weather indices using time series as well as solar image data. We show a 30-40\% improvement of the root mean-square error while including solar image data with time series data compared to using time series data alone. Simple baselines such as a persistence and running average forecasts are also compared with the trained deep neural network models. We also quantify the uncertainty in our prediction using a model ensemble.
Model2Detector: Widening the Information Bottleneck for Out-of-Distribution Detection using a Handful of Gradient Steps
Feb 22, 2022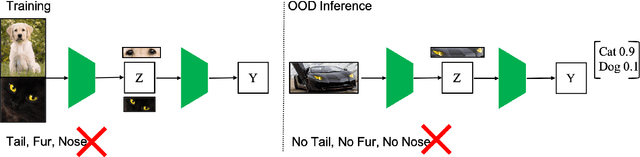
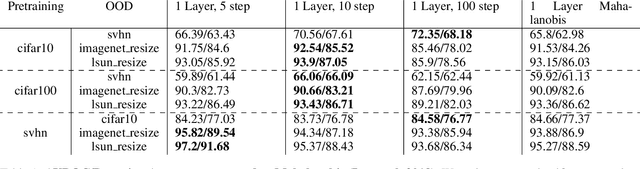
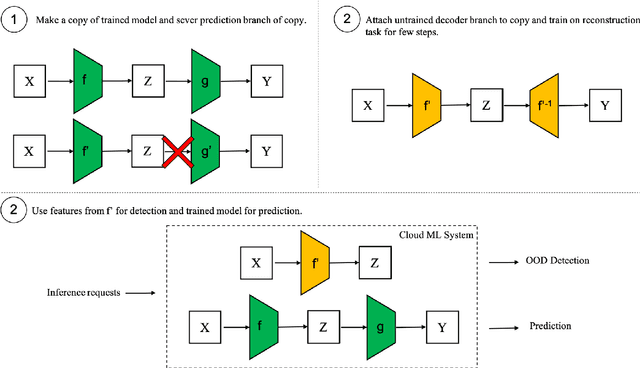
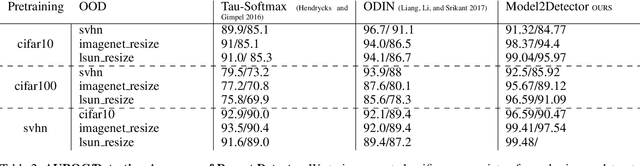
Out-of-distribution detection is an important capability that has long eluded vanilla neural networks. Deep Neural networks (DNNs) tend to generate over-confident predictions when presented with inputs that are significantly out-of-distribution (OOD). This can be dangerous when employing machine learning systems in the wild as detecting attacks can thus be difficult. Recent advances inference-time out-of-distribution detection help mitigate some of these problems. However, existing methods can be restrictive as they are often computationally expensive. Additionally, these methods require training of a downstream detector model which learns to detect OOD inputs from in-distribution ones. This, therefore, adds latency during inference. Here, we offer an information theoretic perspective on why neural networks are inherently incapable of OOD detection. We attempt to mitigate these flaws by converting a trained model into a an OOD detector using a handful of steps of gradient descent. Our work can be employed as a post-processing method whereby an inference-time ML system can convert a trained model into an OOD detector. Experimentally, we show how our method consistently outperforms the state-of-the-art in detection accuracy on popular image datasets while also reducing computational complexity.
Associative Memories Using Complex-Valued Hopfield Networks Based on Spin-Torque Oscillator Arrays
Dec 06, 2021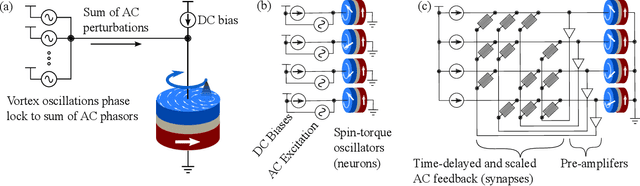
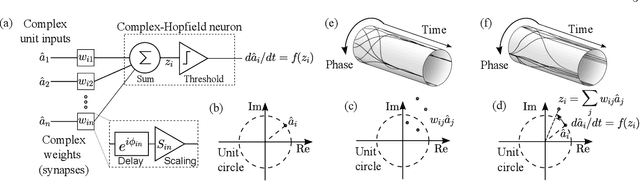
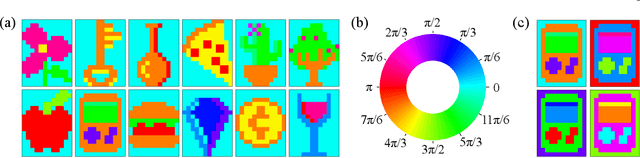
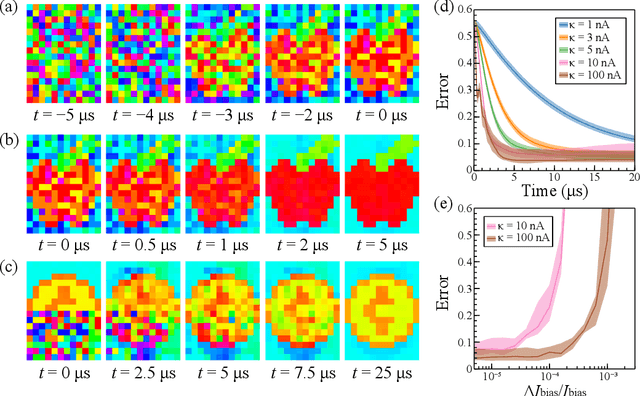
Simulations of complex-valued Hopfield networks based on spin-torque oscillators can recover phase-encoded images. Sequences of memristor-augmented inverters provide tunable delay elements that implement complex weights by phase shifting the oscillatory output of the oscillators. Pseudo-inverse training suffices to store at least 12 images in a set of 192 oscillators, representing 16$\times$12 pixel images. The energy required to recover an image depends on the desired error level. For the oscillators and circuitry considered here, 5 % root mean square deviations from the ideal image require approximately 5 $\mu$s and consume roughly 130 nJ. Simulations show that the network functions well when the resonant frequency of the oscillators can be tuned to have a fractional spread less than $10^{-3}$, depending on the strength of the feedback.
The Dual Form of Neural Networks Revisited: Connecting Test Time Predictions to Training Patterns via Spotlights of Attention
Feb 11, 2022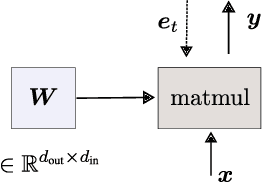
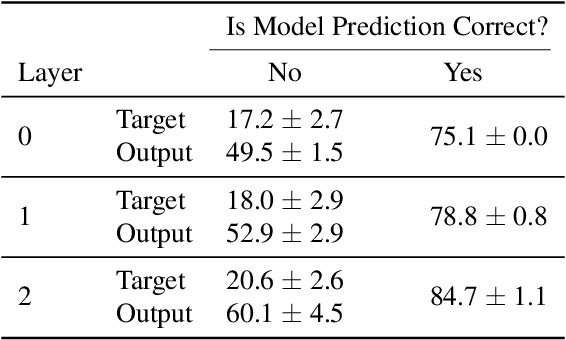
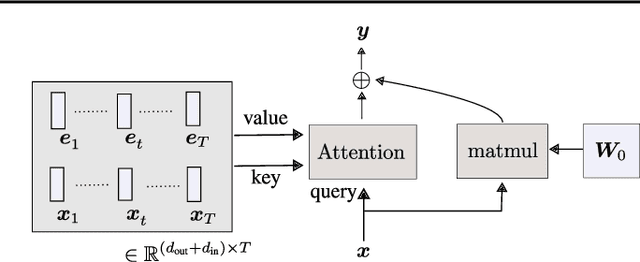

Linear layers in neural networks (NNs) trained by gradient descent can be expressed as a key-value memory system which stores all training datapoints and the initial weights, and produces outputs using unnormalised dot attention over the entire training experience. While this has been technically known since the '60s, no prior work has effectively studied the operations of NNs in such a form, presumably due to prohibitive time and space complexities and impractical model sizes, all of them growing linearly with the number of training patterns which may get very large. However, this dual formulation offers a possibility of directly visualizing how an NN makes use of training patterns at test time, by examining the corresponding attention weights. We conduct experiments on small scale supervised image classification tasks in single-task, multi-task, and continual learning settings, as well as language modelling, and discuss potentials and limits of this view for better understanding and interpreting how NNs exploit training patterns. Our code is public.