 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Edge Information and Mask Shrinking Based Image Inpainting Approach
Jun 11, 2020
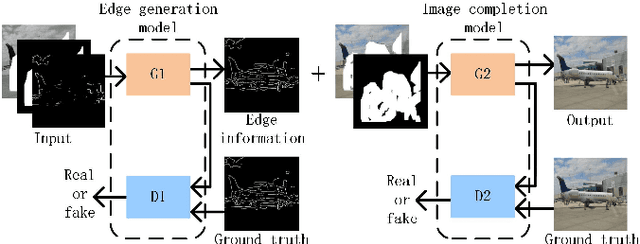
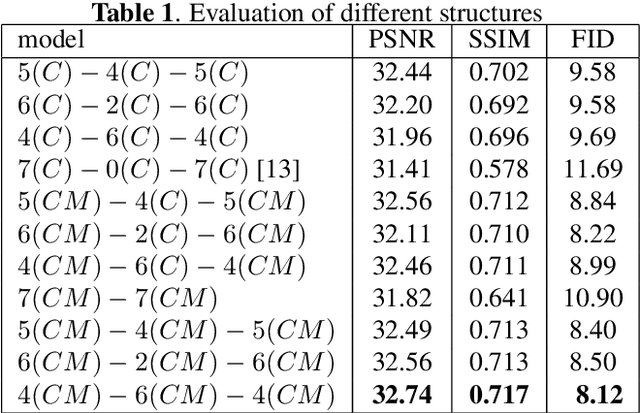
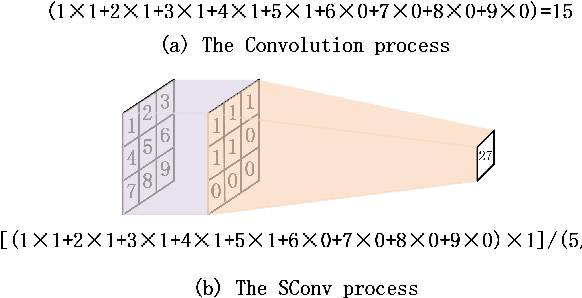
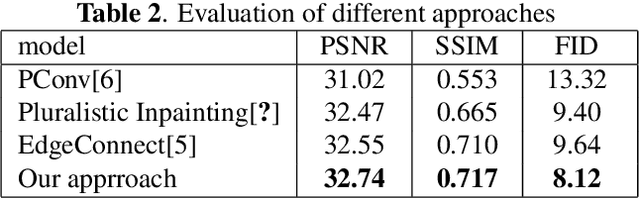
In the image inpainting task, the ability to repair both high-frequency and low-frequency information in the missing regions has a substantial influence on the quality of the restored image. However, existing inpainting methods usually fail to consider both high-frequency and low-frequency information simultaneously. To solve this problem, this paper proposes edge information and mask shrinking based image inpainting approach, which consists of two models. The first model is an edge generation model used to generate complete edge information from the damaged image, and the second model is an image completion model used to fix the missing regions with the generated edge information and the valid contents of the damaged image. The mask shrinking strategy is employed in the image completion model to track the areas to be repaired. The proposed approach is evaluated qualitatively and quantitatively on the dataset Places2. The result shows our approach outperforms state-of-the-art methods.
Enhancing Organ at Risk Segmentation with Improved Deep Neural Networks
Feb 03, 2022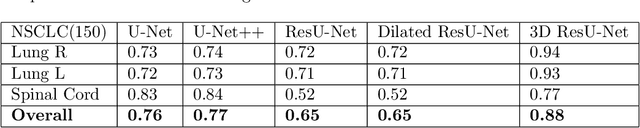
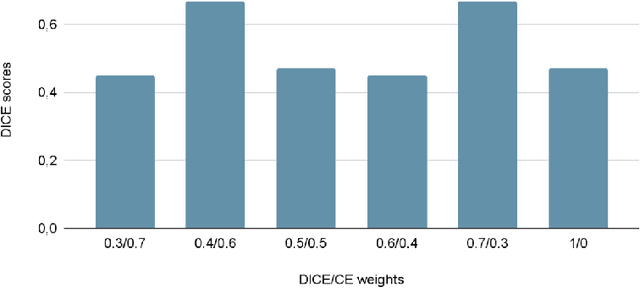
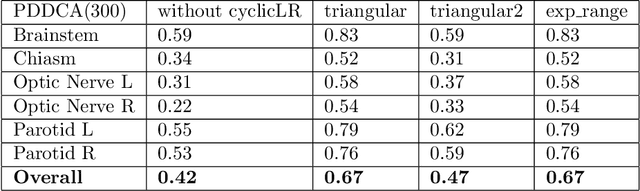
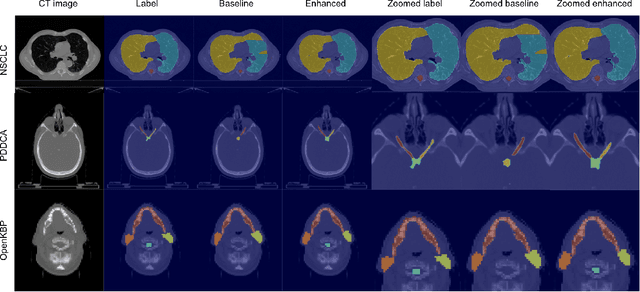
Organ at risk (OAR) segmentation is a crucial step for treatment planning and outcome determination in radiotherapy treatments of cancer patients. Several deep learning based segmentation algorithms have been developed in recent years, however, U-Net remains the de facto algorithm designed specifically for biomedical image segmentation and has spawned many variants with known weaknesses. In this study, our goal is to present simple architectural changes in U-Net to improve its accuracy and generalization properties. Unlike many other available studies evaluating their algorithms on single center data, we thoroughly evaluate several variations of U-Net as well as our proposed enhanced architecture on multiple data sets for an extensive and reliable study of the OAR segmentation problem. Our enhanced segmentation model includes (a)architectural changes in the loss function, (b)optimization framework, and (c)convolution type. Testing on three publicly available multi-object segmentation data sets, we achieved an average of 80% dice score compared to the baseline U-Net performance of 63%.
An Efficient Polyp Segmentation Network
Mar 08, 2022Cancer is a disease that occurs as a result of uncontrolled division and proliferation of cells. The number of cancer cases has been on the rise over the recent years.. Colon cancer is one of the most common types of cancer in the world. Polyps that can be seen in the large intestine can cause cancer if not removed with early intervention. Deep learning and image segmentation techniques are used to minimize the number of polyps that goes unnoticed by the experts during the diagnosis. Although these techniques give good results, they require too many parameters. We propose a new model to solve this problem. Our proposed model includes less parameters as well as outperforming the success of the state of the art models. In the proposed model, a partial decoder is used to reduce the number of parameters while maintaning success. EfficientNetB0, which gives successfull results as well as requiring few parameters, is used in the encoder part. Since polyps have variable aspect and aspect ratios, an asymetric convolution block was used instead of using classic convolution block. Kvasir and CVC-ClinicDB datasets were seperated as training, validation and testing, and CVC-ColonDB, ETIS and Endoscene datasets were used for testing. According to the dice metric, our model had the best results with %71.8 in the ColonDB test dataset, %89.3 in the EndoScene test dataset and %74.8 in the ETIS test dataset. Our model requires a total of 2.626.337 parameters. When we compare it in the literature, according to similar studies, the model that requires the least parameters is U-Net++ with 9.042.177 parameters.
Towards a Unified Foundation Model: Jointly Pre-Training Transformers on Unpaired Images and Text
Dec 14, 2021



In this paper, we explore the possibility of building a unified foundation model that can be adapted to both vision-only and text-only tasks. Starting from BERT and ViT, we design a unified transformer consisting of modality-specific tokenizers, a shared transformer encoder, and task-specific output heads. To efficiently pre-train the proposed model jointly on unpaired images and text, we propose two novel techniques: (i) We employ the separately-trained BERT and ViT models as teachers and apply knowledge distillation to provide additional, accurate supervision signals for the joint training; (ii) We propose a novel gradient masking strategy to balance the parameter updates from the image and text pre-training losses. We evaluate the jointly pre-trained transformer by fine-tuning it on image classification tasks and natural language understanding tasks, respectively. The experiments show that the resultant unified foundation transformer works surprisingly well on both the vision-only and text-only tasks, and the proposed knowledge distillation and gradient masking strategy can effectively lift the performance to approach the level of separately-trained models.
To what extent can Plug-and-Play methods outperform neural networks alone in low-dose CT reconstruction
Feb 15, 2022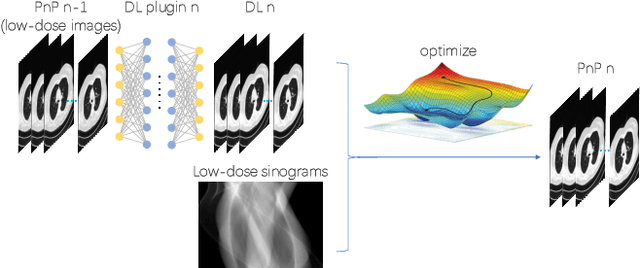
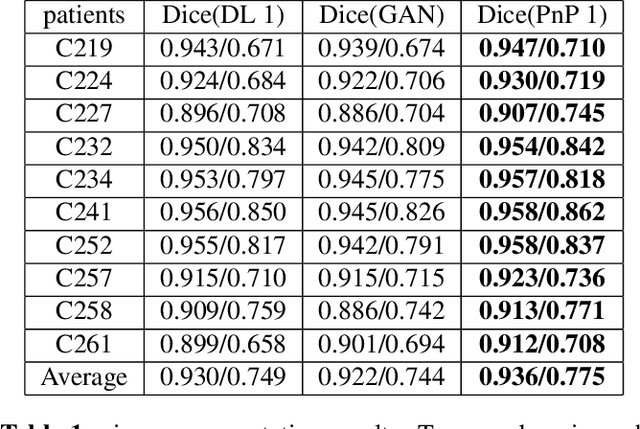
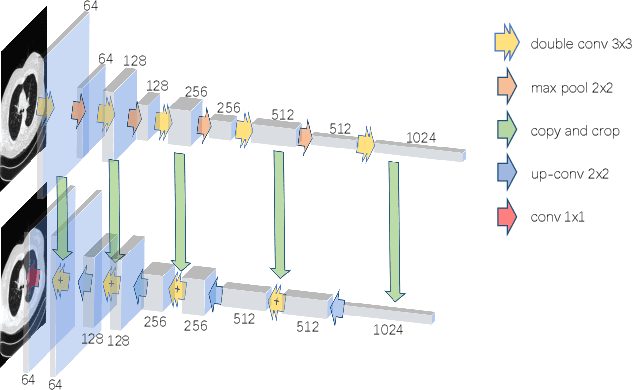
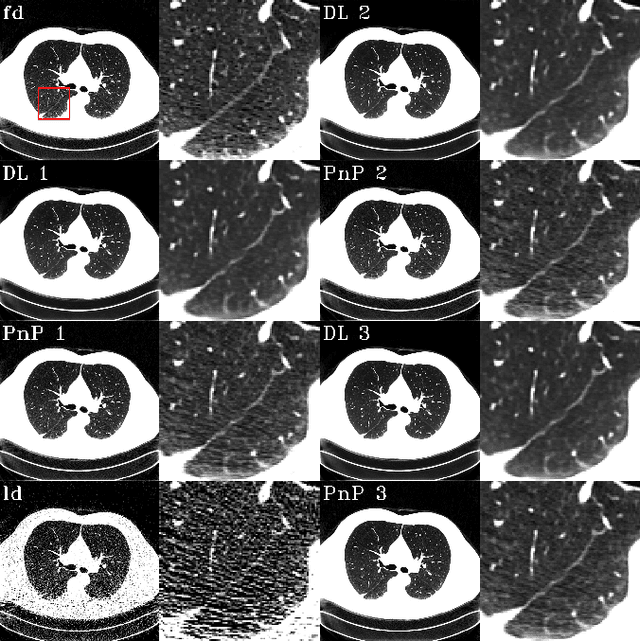
The Plug-and-Play (PnP) framework was recently introduced for low-dose CT reconstruction to leverage the interpretability and the flexibility of model-based methods to incorporate various plugins, such as trained deep learning (DL) neural networks. However, the benefits of PnP vs. state-of-the-art DL methods have not been clearly demonstrated. In this work, we proposed an improved PnP framework to address the previous limitations and develop clinical-relevant segmentation metrics for quantitative result assessment. Compared with the DL alone methods, our proposed PnP framework was slightly inferior in MSE and PSNR. However, the power spectrum of the resulting images better matched that of full-dose images than that of DL denoised images. The resulting images supported higher accuracy in airway segmentation than DL denoised images for all the ten patients in the test set, more substantially on the airways with a cross-section smaller than 0.61cm$^2$, and outperformed the DL denoised images for 45 out of 50 lung lobes in lobar segmentation. Our PnP method proved to be significantly better at preserving the image texture, which translated to task-specific benefits in automated structure segmentation and detection.
Shallow-UWnet : Compressed Model for Underwater Image Enhancement
Jan 06, 2021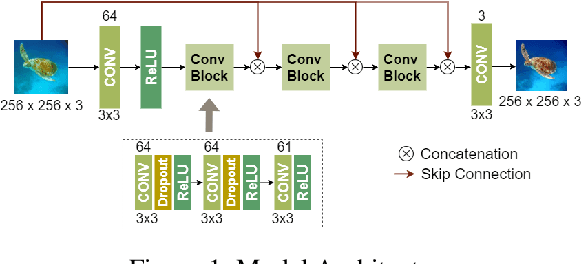
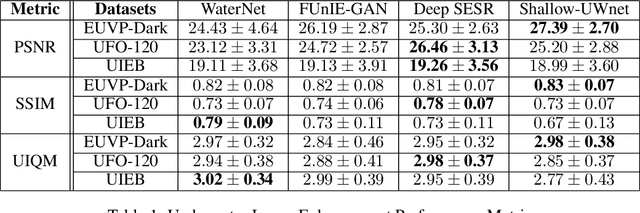


Over the past few decades, underwater image enhancement has attracted increasing amount of research effort due to its significance in underwater robotics and ocean engineering. Research has evolved from implementing physics-based solutions to using very deep CNNs and GANs. However, these state-of-art algorithms are computationally expensive and memory intensive. This hinders their deployment on portable devices for underwater exploration tasks. These models are trained on either synthetic or limited real world datasets making them less practical in real-world scenarios. In this paper we propose a shallow neural network architecture, \textbf{Shallow-UWnet} which maintains performance and has fewer parameters than the state-of-art models. We also demonstrated the generalization of our model by benchmarking its performance on combination of synthetic and real-world datasets.
DriveGuard: Robustification of Automated Driving Systems with Deep Spatio-Temporal Convolutional Autoencoder
Nov 05, 2021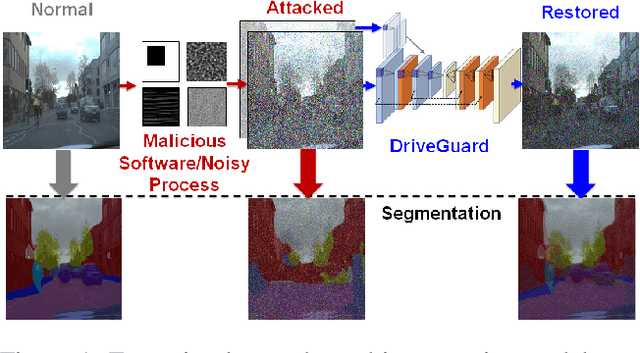
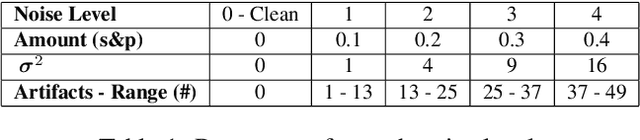
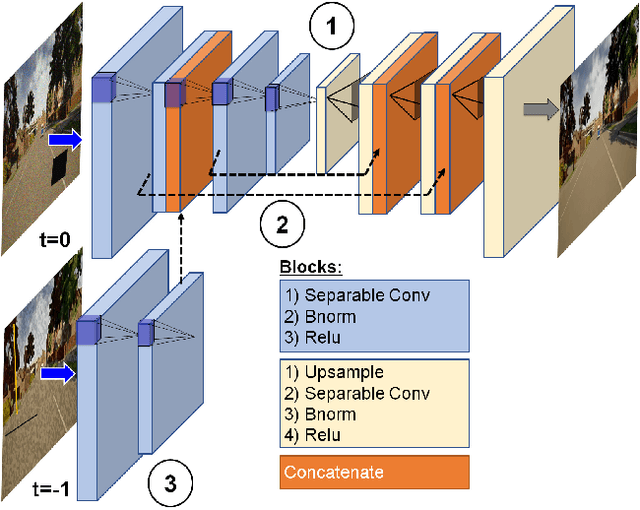

Autonomous vehicles increasingly rely on cameras to provide the input for perception and scene understanding and the ability of these models to classify their environment and objects, under adverse conditions and image noise is crucial. When the input is, either unintentionally or through targeted attacks, deteriorated, the reliability of autonomous vehicle is compromised. In order to mitigate such phenomena, we propose DriveGuard, a lightweight spatio-temporal autoencoder, as a solution to robustify the image segmentation process for autonomous vehicles. By first processing camera images with DriveGuard, we offer a more universal solution than having to re-train each perception model with noisy input. We explore the space of different autoencoder architectures and evaluate them on a diverse dataset created with real and synthetic images demonstrating that by exploiting spatio-temporal information combined with multi-component loss we significantly increase robustness against adverse image effects reaching within 5-6% of that of the original model on clean images.
Blind Image Deconvolution using Student's-t Prior with Overlapping Group Sparsity
Jun 26, 2020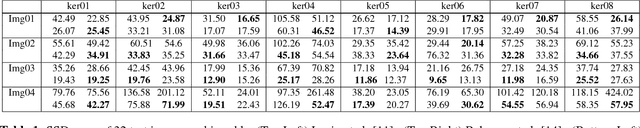
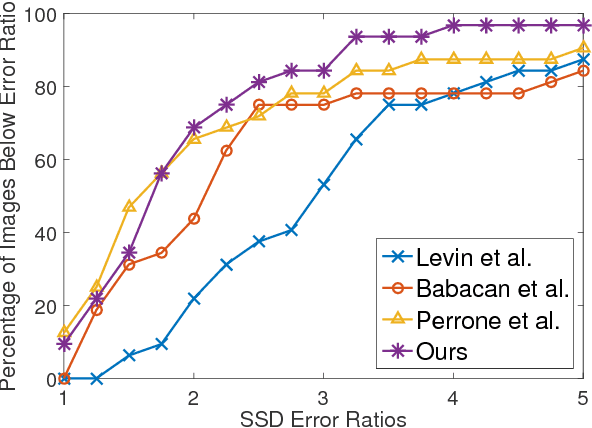
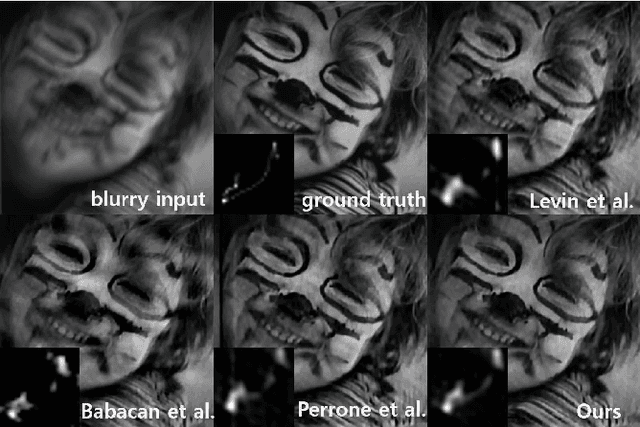
In this paper, we solve blind image deconvolution problem that is to remove blurs form a signal degraded image without any knowledge of the blur kernel. Since the problem is ill-posed, an image prior plays a significant role in accurate blind deconvolution. Traditional image prior assumes coefficients in filtered domains are sparse. However, it is assumed here that there exist additional structures over the sparse coefficients. Accordingly, we propose new problem formulation for the blind image deconvolution, which utilizes the structural information by coupling Student's-t image prior with overlapping group sparsity. The proposed method resulted in an effective blind deconvolution algorithm that outperforms other state-of-the-art algorithms.
Cross-Scale Internal Graph Neural Network for Image Super-Resolution
Jun 30, 2020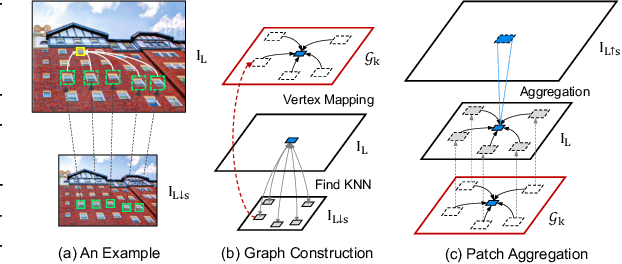
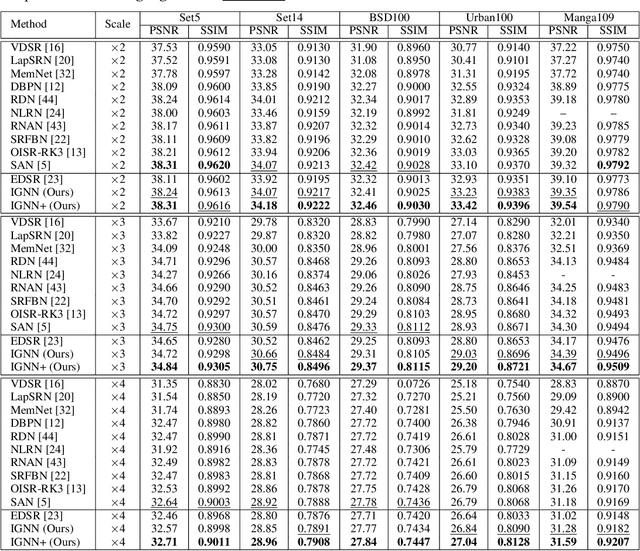
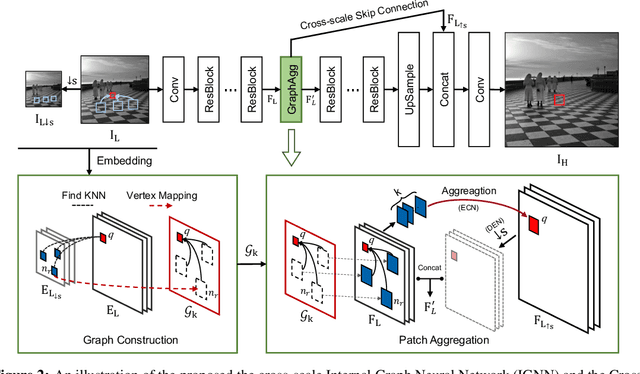

Non-local self-similarity in natural images has been well studied as an effective prior in image restoration. However, for single image super-resolution (SISR), most existing deep non-local methods (e.g., non-local neural networks) only exploit similar patches within the same scale of the low-resolution (LR) input image. Consequently, the restoration is limited to using the same-scale information while neglecting potential high-resolution (HR) cues from other scales. In this paper, we explore the cross-scale patch recurrence property of a natural image, i.e., similar patches tend to recur many times across different scales. This is achieved using a novel cross-scale internal graph neural network (IGNN). Specifically, we dynamically construct a cross-scale graph by searching k-nearest neighboring patches in the downsampled LR image for each query patch in the LR image. We then obtain the corresponding k HR neighboring patches in the LR image and aggregate them adaptively in accordance to the edge label of the constructed graph. In this way, the HR information can be passed from k HR neighboring patches to the LR query patch to help it recover more detailed textures. Besides, these internal image-specific LR/HR exemplars are also significant complements to the external information learned from the training dataset. Extensive experiments demonstrate the effectiveness of IGNN against the state-of-the-art SISR methods including existing non-local networks on standard benchmarks.
High Perceptual Quality Image Denoising with a Posterior Sampling CGAN
Mar 17, 2021
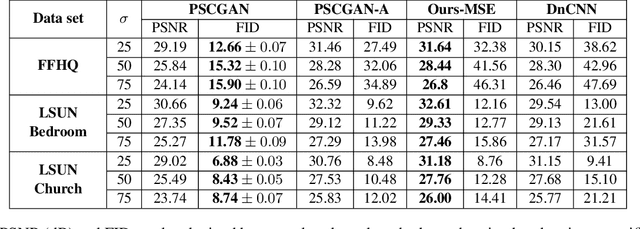

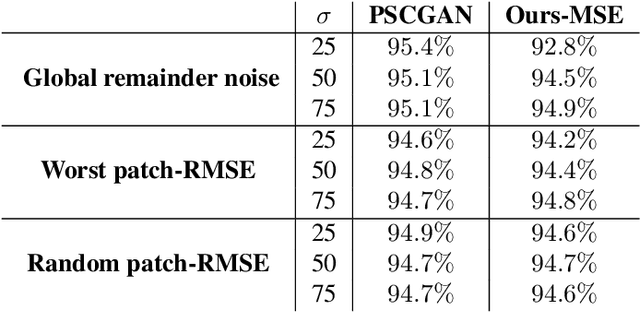
The vast work in Deep Learning (DL) has led to a leap in image denoising research. Most DL solutions for this task have chosen to put their efforts on the denoiser's architecture while maximizing distortion performance. However, distortion driven solutions lead to blurry results with sub-optimal perceptual quality, especially in immoderate noise levels. In this paper we propose a different perspective, aiming to produce sharp and visually pleasing denoised images that are still faithful to their clean sources. Formally, our goal is to achieve high perceptual quality with acceptable distortion. This is attained by a stochastic denoiser that samples from the posterior distribution, trained as a generator in the framework of conditional generative adversarial networks (CGAN). Contrary to distortion-based regularization terms that conflict with perceptual quality, we introduce to the CGAN objective a theoretically founded penalty term that does not force a distortion requirement on individual samples, but rather on their mean. We showcase our proposed method with a novel denoiser architecture that achieves the reformed denoising goal and produces vivid and diverse outcomes in immoderate noise levels.