 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scene Graph Generation: A Comprehensive Survey
Jan 03, 2022
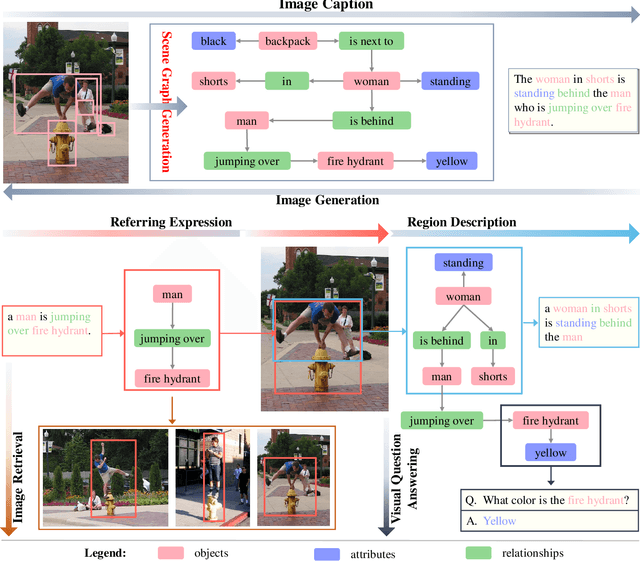
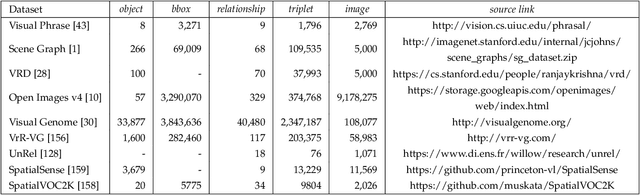
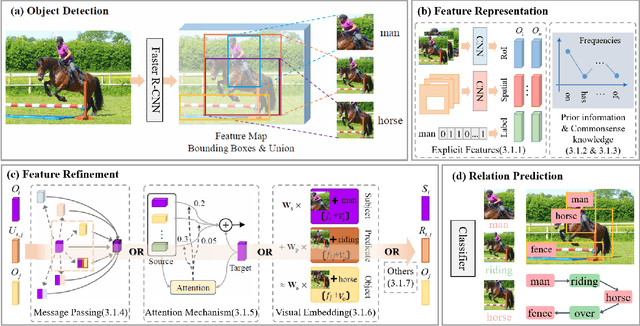
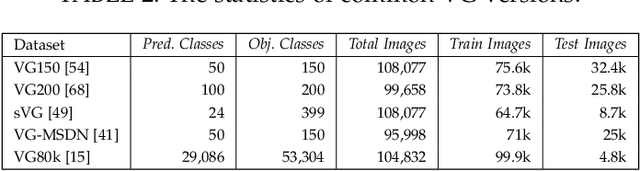
Deep learning techniques have led to remarkable breakthroughs in the field of generic object detection and have spawned a lot of scene-understanding tasks in recent years. Scene graph has been the focus of research because of its powerful semantic representation and applications to scene understanding. Scene Graph Generation (SGG) refers to the task of automatically mapping an image into a semantic structural scene graph, which requires the correct labeling of detected objects and their relationships. Although this is a challenging task, the community has proposed a lot of SGG approaches and achieved good results. In this paper, we provide a comprehensive survey of recent achievements in this field brought about by deep learning techniques. We review 138 representative works that cover different input modalities, and systematically summarize existing methods of image-based SGG from the perspective of feature extraction and fusion. We attempt to connect and systematize the existing visual relationship detection methods, to summarize, and interpret the mechanisms and the strategies of SGG in a comprehensive way. Finally, we finish this survey with deep discussions about current existing problems and future research directions. This survey will help readers to develop a better understanding of the current research status and ideas.
Mixed Reality Depth Contour Occlusion Using Binocular Similarity Matching and Three-dimensional Contour Optimisation
Mar 04, 2022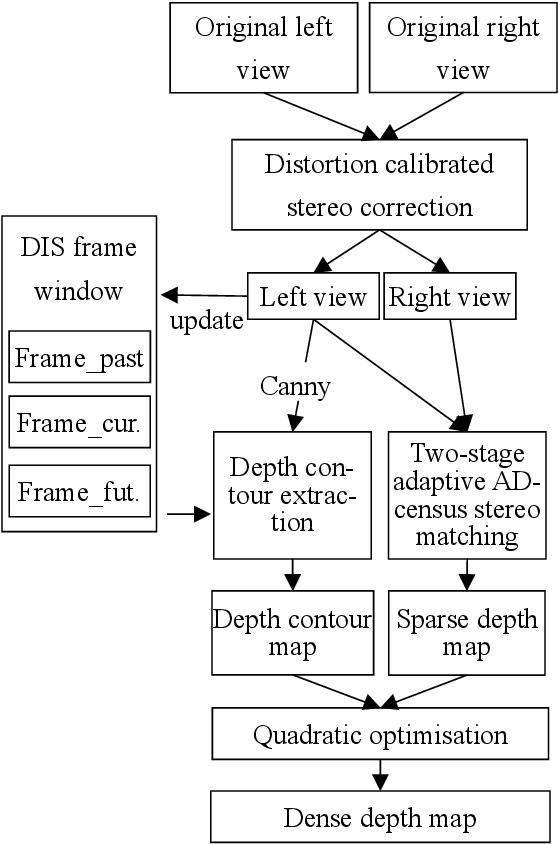
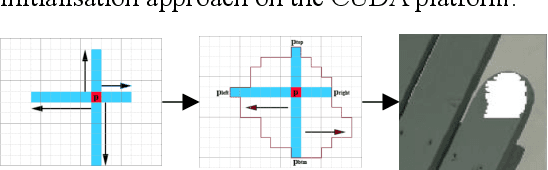
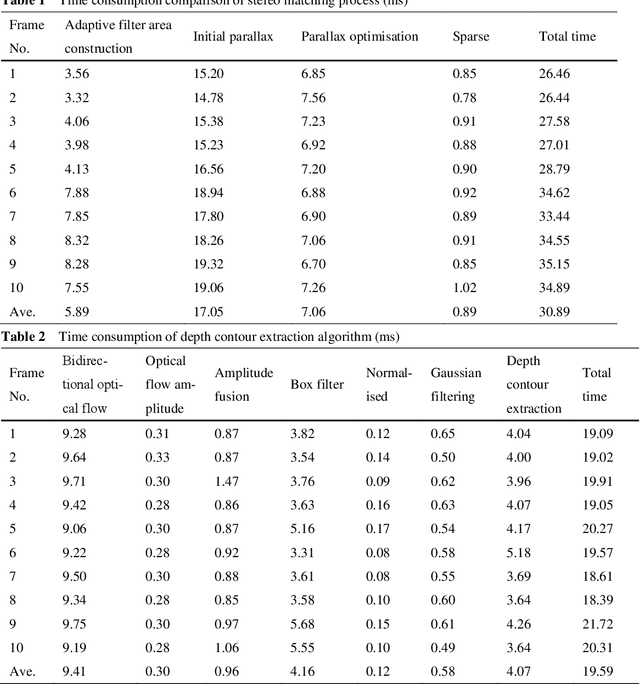

Mixed reality applications often require virtual objects that are partly occluded by real objects. However, previous research and commercial products have limitations in terms of performance and efficiency. To address these challenges, we propose a novel depth contour occlusion (DCO) algorithm. The proposed method is based on the sensitivity of contour occlusion and a binocular stereoscopic vision device. In this method, a depth contour map is combined with a sparse depth map obtained from a two-stage adaptive filter area stereo matching algorithm and the depth contour information of the objects extracted by a digital image stabilisation optical flow method. We also propose a quadratic optimisation model with three constraints to generate an accurate dense map of the depth contour for high-quality real-virtual occlusion. The whole process is accelerated by GPU. To evaluate the effectiveness of the algorithm, we demonstrate a time con-sumption statistical analysis for each stage of the DCO algorithm execution. To verify the relia-bility of the real-virtual occlusion effect, we conduct an experimental analysis on single-sided, enclosed, and complex occlusions; subsequently, we compare it with the occlusion method without quadratic optimisation. With our GPU implementation for real-time DCO, the evaluation indicates that applying the presented DCO algorithm can enhance the real-time performance and the visual quality of real-virtual occlusion.
How to augment your ViTs? Consistency loss and StyleAug, a random style transfer augmentation
Dec 16, 2021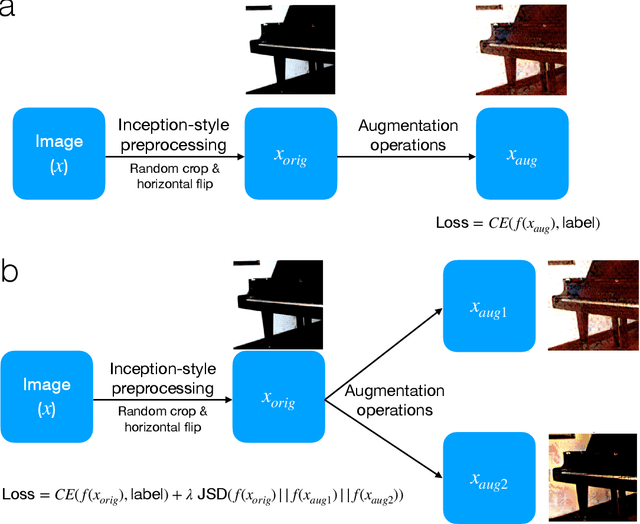

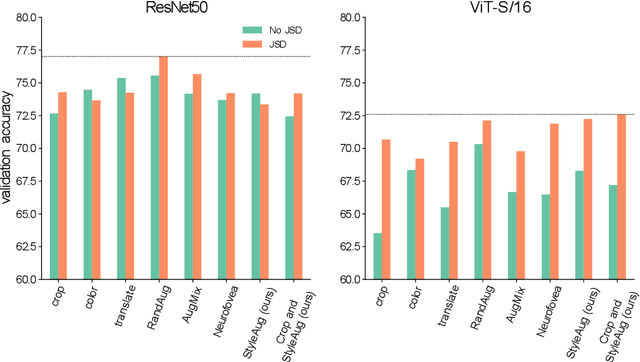
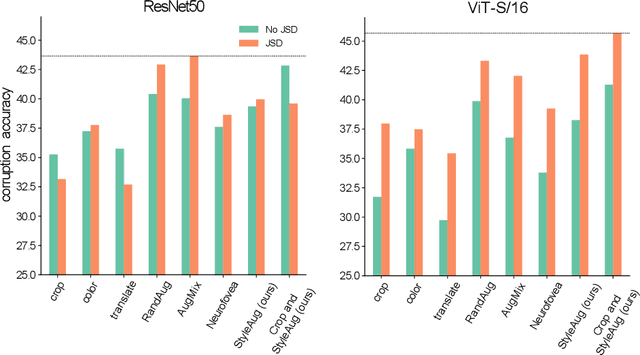
The Vision Transformer (ViT) architecture has recently achieved competitive performance across a variety of computer vision tasks. One of the motivations behind ViTs is weaker inductive biases, when compared to convolutional neural networks (CNNs). However this also makes ViTs more difficult to train. They require very large training datasets, heavy regularization, and strong data augmentations. The data augmentation strategies used to train ViTs have largely been inherited from CNN training, despite the significant differences between the two architectures. In this work, we empirical evaluated how different data augmentation strategies performed on CNN (e.g., ResNet) versus ViT architectures for image classification. We introduced a style transfer data augmentation, termed StyleAug, which worked best for training ViTs, while RandAugment and Augmix typically worked best for training CNNs. We also found that, in addition to a classification loss, using a consistency loss between multiple augmentations of the same image was especially helpful when training ViTs.
A Gating Model for Bias Calibration in Generalized Zero-shot Learning
Mar 08, 2022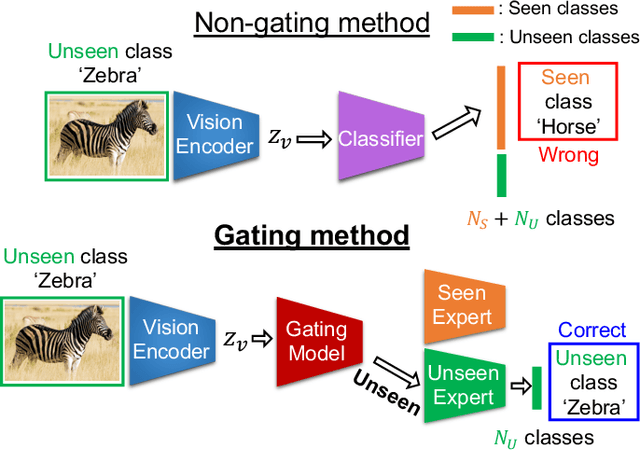
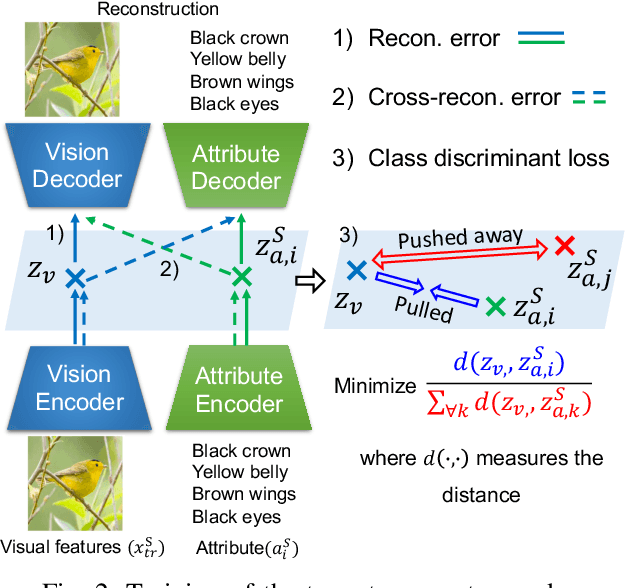
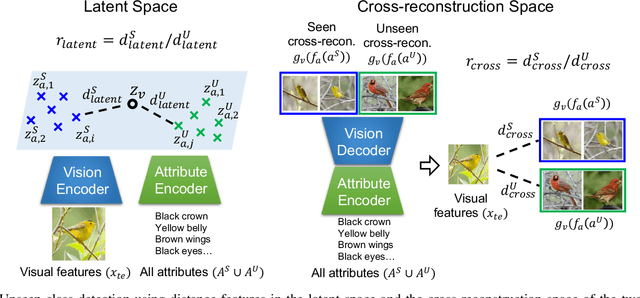

Generalized zero-shot learning (GZSL) aims at training a model that can generalize to unseen class data by only using auxiliary information. One of the main challenges in GZSL is a biased model prediction toward seen classes caused by overfitting on only available seen class data during training. To overcome this issue, we propose a two-stream autoencoder-based gating model for GZSL. Our gating model predicts whether the query data is from seen classes or unseen classes, and utilizes separate seen and unseen experts to predict the class independently from each other. This framework avoids comparing the biased prediction scores for seen classes with the prediction scores for unseen classes. In particular, we measure the distance between visual and attribute representations in the latent space and the cross-reconstruction space of the autoencoder. These distances are utilized as complementary features to characterize unseen classes at different levels of data abstraction. Also, the two-stream autoencoder works as a unified framework for the gating model and the unseen expert, which makes the proposed method computationally efficient. We validate our proposed method in four benchmark image recognition datasets. In comparison with other state-of-the-art methods, we achieve the best harmonic mean accuracy in SUN and AWA2, and the second best in CUB and AWA1. Furthermore, our base model requires at least 20% less number of model parameters than state-of-the-art methods relying on generative models.
Encoding Program as Image: Evaluating Visual Representation of Source Code
Nov 01, 2021
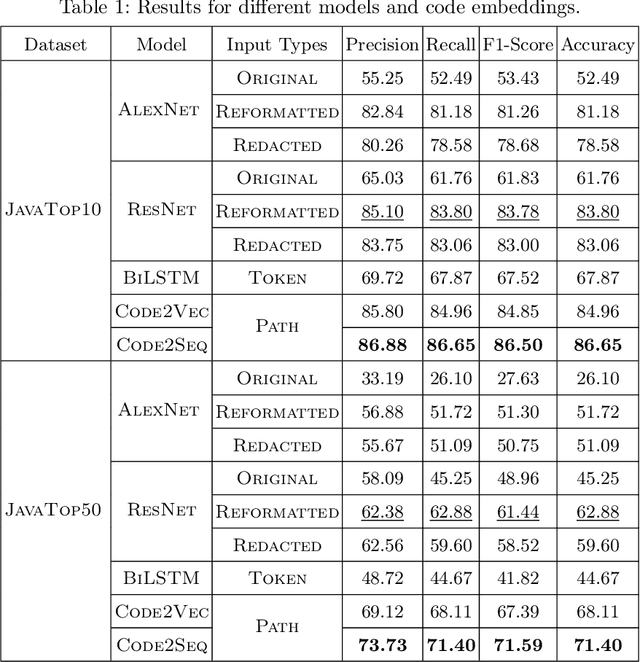

There are several approaches to encode source code in the input vectors of neural models. These approaches attempt to include various syntactic and semantic features of input programs in their encoding. In this paper, we investigate Code2Snapshot, a novel representation of the source code that is based on the snapshots of input programs. We evaluate several variations of this representation and compare its performance with state-of-the-art representations that utilize the rich syntactic and semantic features of input programs. Our preliminary study on the utility of Code2Snapshot in the code summarization task suggests that simple snapshots of input programs have comparable performance to the state-of-the-art representations. Interestingly, obscuring the input programs have insignificant impacts on the Code2Snapshot performance, suggesting that, for some tasks, neural models may provide high performance by relying merely on the structure of input programs.
Domain Adaptation based Technique for Image Emotion Recognition using Pre-trained Facial Expression Recognition Models
Nov 17, 2020

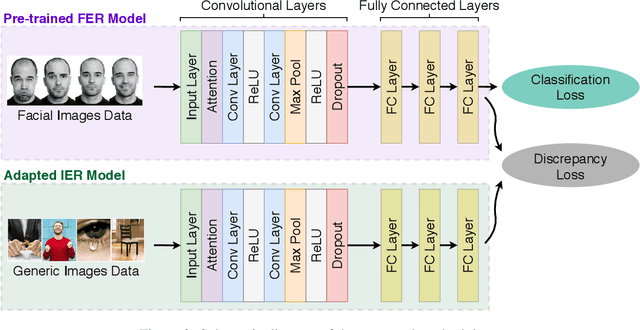
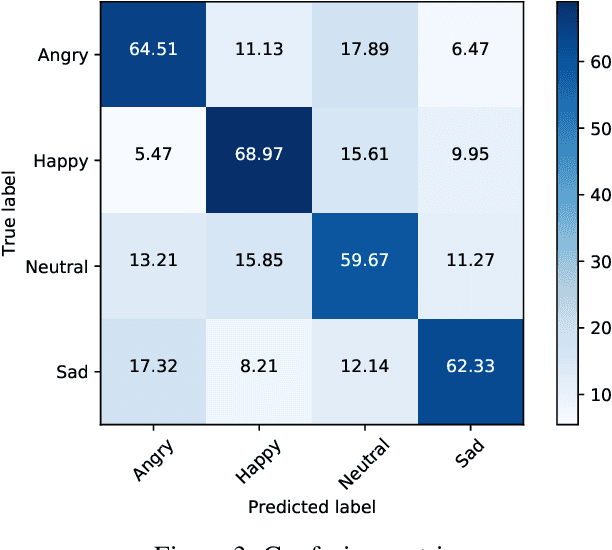
In this paper, a domain adaptation based technique for recognizing the emotions in images containing facial, non-facial, and non-human components has been proposed. We have also proposed a novel technique to explain the proposed system's predictions in terms of Intersection Score. Image emotion recognition is useful for graphics, gaming, animation, entertainment, and cinematography. However, well-labeled large scale datasets and pre-trained models are not available for image emotion recognition. To overcome this challenge, we have proposed a deep learning approach based on an attentional convolutional network that adapts pre-trained facial expression recognition models. It detects the visual features of an image and performs emotion classification based on them. The experiments have been performed on the Flickr image dataset, and the images have been classified in 'angry,' 'happy,' 'sad,' and 'neutral' emotion classes. The proposed system has demonstrated better performance than the benchmark results with an accuracy of 63.87% for image emotion recognition. We have also analyzed the embedding plots for various emotion classes to explain the proposed system's predictions.
Vehicle trajectory prediction in top-view image sequences based on deep learning method
Feb 02, 2021
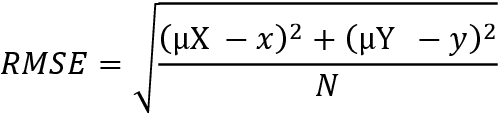
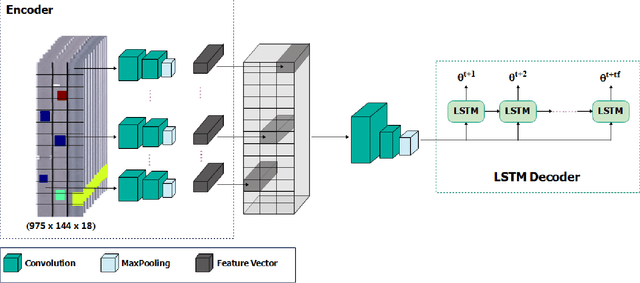
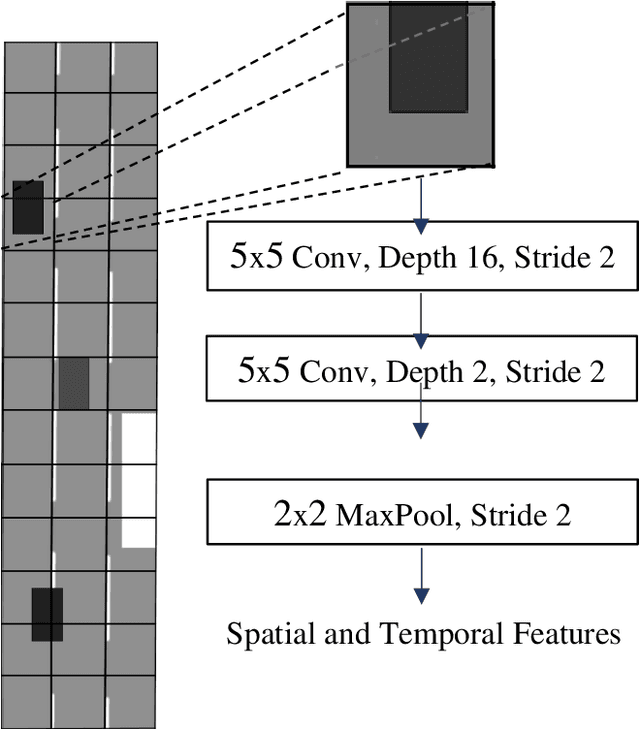
Annually, a large number of injuries and deaths around the world are related to motor vehicle accidents. This value has recently been reduced to some extent, via the use of driver-assistance systems. Developing driver-assistance systems (i.e., automated driving systems) can play a crucial role in reducing this number. Estimating and predicting surrounding vehicles' movement is essential for an automated vehicle and advanced safety systems. Moreover, predicting the trajectory is influenced by numerous factors, such as drivers' behavior during accidents, history of the vehicle's movement and the surrounding vehicles, and their position on the traffic scene. The vehicle must move over a safe path in traffic and react to other drivers' unpredictable behaviors in the shortest time. Herein, to predict automated vehicles' path, a model with low computational complexity is proposed, which is trained by images taken from the road's aerial image. Our method is based on an encoder-decoder model that utilizes a social tensor to model the effect of the surrounding vehicles' movement on the target vehicle. The proposed model can predict the vehicle's future path in any freeway only by viewing the images related to the history of the target vehicle's movement and its neighbors. Deep learning was used as a tool for extracting the features of these images. Using the HighD database, an image dataset of the road's aerial image was created, and the model's performance was evaluated on this new database. We achieved the RMSE of 1.91 for the next 5 seconds and found that the proposed method had less error than the best path-prediction methods in previous studies.
Robust Autoencoder GAN for Cryo-EM Image Denoising
Aug 17, 2020
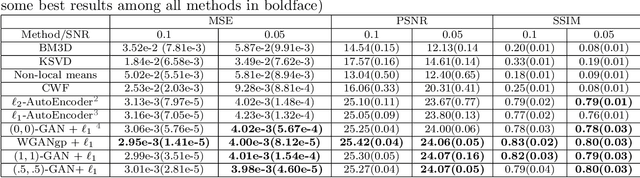
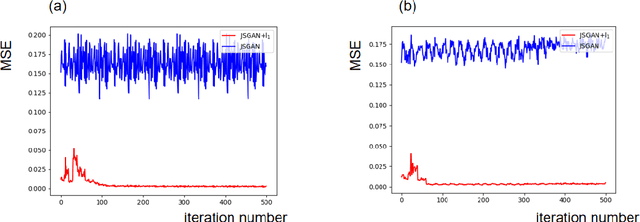
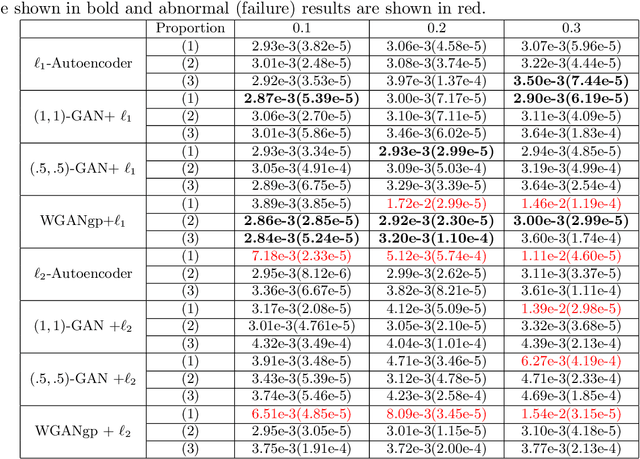
The cryo-electron microscopy (Cryo-EM) becomes popular for macromolecular structure determination. However, the 2D images which Cryo-EM detects are of high noise and often mixed with multiple heterogeneous conformations or contamination, imposing a challenge for denoising. Traditional image denoising methods can not remove Cryo-EM image noise well when the signal-noise-ratio (SNR) of images is meager. Thus it is desired to develop new effective denoising techniques to facilitate further research such as 3D reconstruction, 2D conformation classification, and so on. In this paper, we approach the robust image denoising problem in Cryo-EM by a joint Autoencoder and Generative Adversarial Networks (GAN) method. Equipped with robust $\ell_1$ Autoencoder and some designs of robust $\beta$-GANs, one can stabilize the training of GANs and achieve the state-of-the-art performance of robust denoising with low SNR data and against possible information contamination. The method is evaluated by both a heterogeneous conformational dataset on the Thermus aquaticus RNA Polymerase (RNAP) and a homogenous dataset on the Plasmodium falciparum 80S ribosome dataset (EMPIRE-10028), in terms of Mean Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), as well as heterogeneous conformation clustering. These results suggest that our proposed methodology provides an effective tool for Cryo-EM 2D image denoising.
Kernel Proposal Network for Arbitrary Shape Text Detection
Mar 12, 2022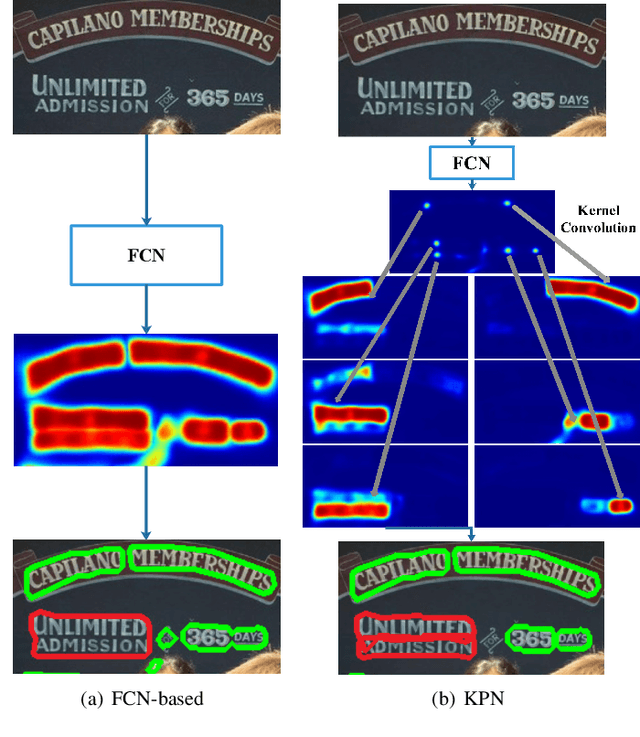


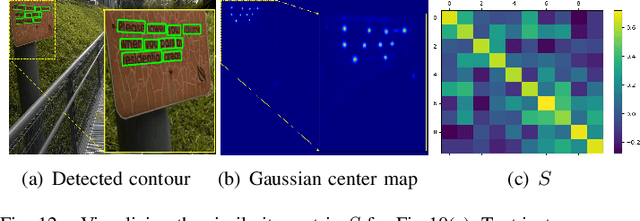
Segmentation-based methods have achieved great success for arbitrary shape text detection. However, separating neighboring text instances is still one of the most challenging problems due to the complexity of texts in scene images. In this paper, we propose an innovative Kernel Proposal Network (dubbed KPN) for arbitrary shape text detection. The proposed KPN can separate neighboring text instances by classifying different texts into instance-independent feature maps, meanwhile avoiding the complex aggregation process existing in segmentation-based arbitrary shape text detection methods. To be concrete, our KPN will predict a Gaussian center map for each text image, which will be used to extract a series of candidate kernel proposals (i.e., dynamic convolution kernel) from the embedding feature maps according to their corresponding keypoint positions. To enforce the independence between kernel proposals, we propose a novel orthogonal learning loss (OLL) via orthogonal constraints. Specifically, our kernel proposals contain important self-information learned by network and location information by position embedding. Finally, kernel proposals will individually convolve all embedding feature maps for generating individual embedded maps of text instances. In this way, our KPN can effectively separate neighboring text instances and improve the robustness against unclear boundaries. To our knowledge, our work is the first to introduce the dynamic convolution kernel strategy to efficiently and effectively tackle the adhesion problem of neighboring text instances in text detection. Experimental results on challenging datasets verify the impressive performance and efficiency of our method. The code and model are available at https://github.com/GXYM/KPN.
Look at here : Utilizing supervision to attend subtle key regions
Nov 25, 2021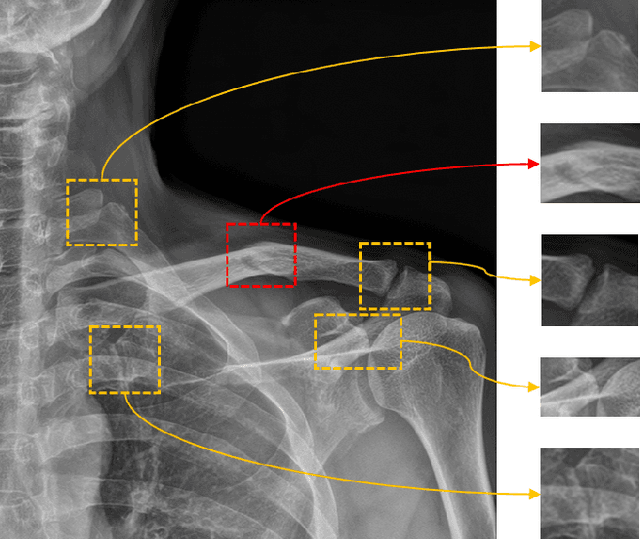

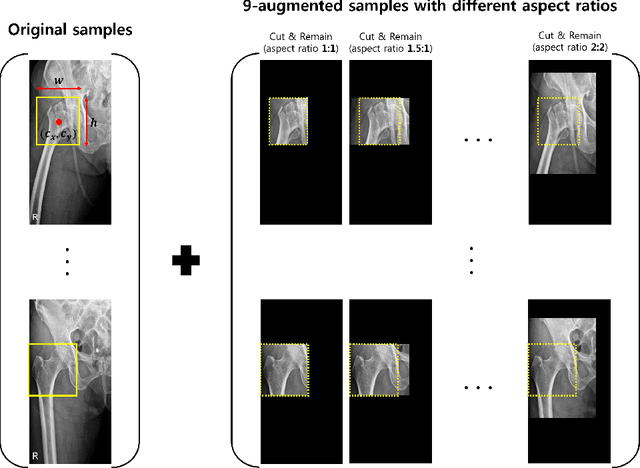
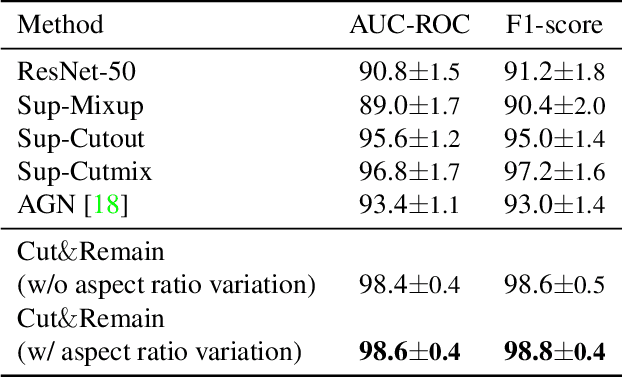
Despite the success of deep learning in computer vision, algorithms to recognize subtle and small objects (or regions) is still challenging. For example, recognizing a baseball or a frisbee on a ground scene or a bone fracture in an X-ray image can easily result in overfitting, unless a huge amount of training data is available. To mitigate this problem, we need a way to force a model should identify subtle regions in limited training data. In this paper, we propose a simple but efficient supervised augmentation method called Cut\&Remain. It achieved better performance on various medical image domain (internally sourced- and public dataset) and a natural image domain (MS-COCO$_s$) than other supervised augmentation and the explicit guidance methods. In addition, using the class activation map, we identified that the Cut\&Remain methods drive a model to focus on relevant subtle and small regions efficiently. We also show that the performance monotonically increased along the Cut\&Remain ratio, indicating that a model can be improved even though only limited amount of Cut\&Remain is applied for, so that it allows low supervising (annotation) cost for improvement.