 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Structure Feature Algorithm for Multi-modal Forearm Registration
Nov 10, 2021
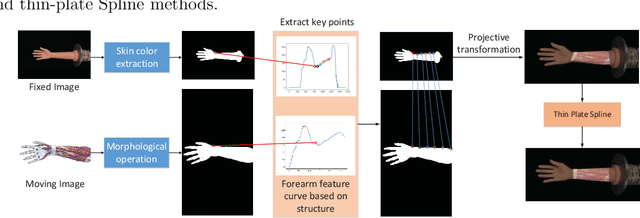
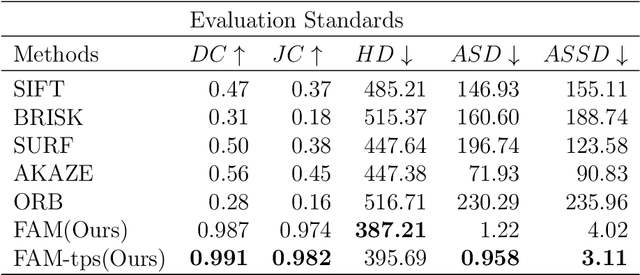
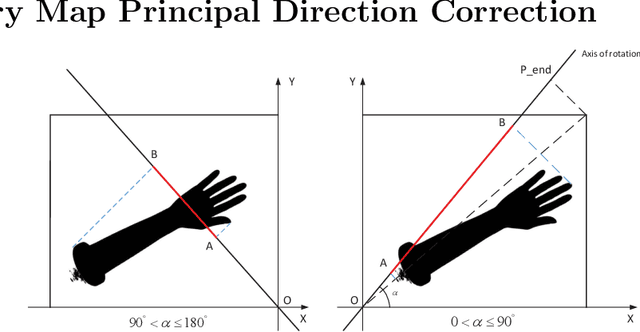
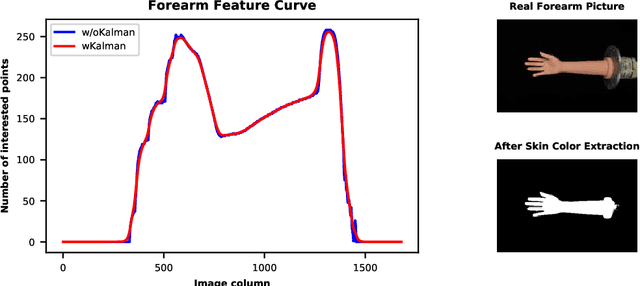
Augmented reality technology based on image registration is becoming increasingly popular for the convenience of pre-surgery preparation and medical education. This paper focuses on the registration of forearm images and digital anatomical models. Due to the difference in texture features of forearm multi-modal images, this paper proposes a forearm feature representation curve (FFRC) based on structure compliant multi-modal image registration framework (FAM) for the forearm.
Learning Affinity-Aware Upsampling for Deep Image Matting
Nov 29, 2020
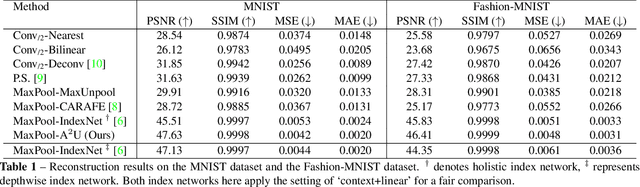
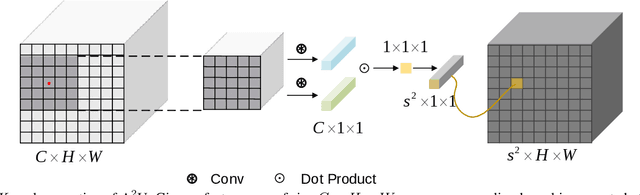
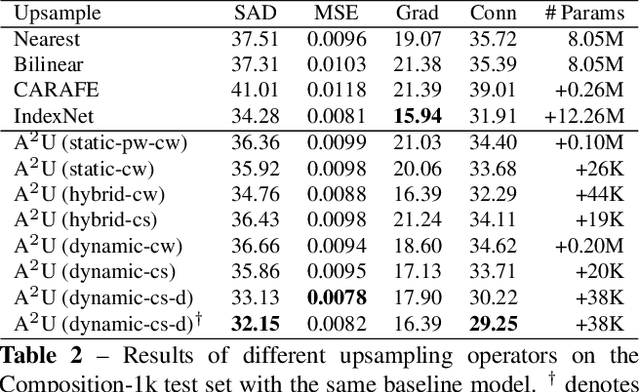
We show that learning affinity in upsampling provides an effective and efficient approach to exploit pairwise interactions in deep networks. Second-order features are commonly used in dense prediction to build adjacent relations with a learnable module after upsampling such as non-local blocks. Since upsampling is essential, learning affinity in upsampling can avoid additional propagation layers, offering the potential for building compact models. By looking at existing upsampling operators from a unified mathematical perspective, we generalize them into a second-order form and introduce Affinity-Aware Upsampling (A2U) where upsampling kernels are generated using a light-weight lowrank bilinear model and are conditioned on second-order features. Our upsampling operator can also be extended to downsampling. We discuss alternative implementations of A2U and verify their effectiveness on two detail-sensitive tasks: image reconstruction on a toy dataset; and a largescale image matting task where affinity-based ideas constitute mainstream matting approaches. In particular, results on the Composition-1k matting dataset show that A2U achieves a 14% relative improvement in the SAD metric against a strong baseline with negligible increase of parameters (<0.5%). Compared with the state-of-the-art matting network, we achieve 8% higher performance with only 40% model complexity.
Probabilistic Spatial Distribution Prior Based Attentional Keypoints Matching Network
Nov 23, 2021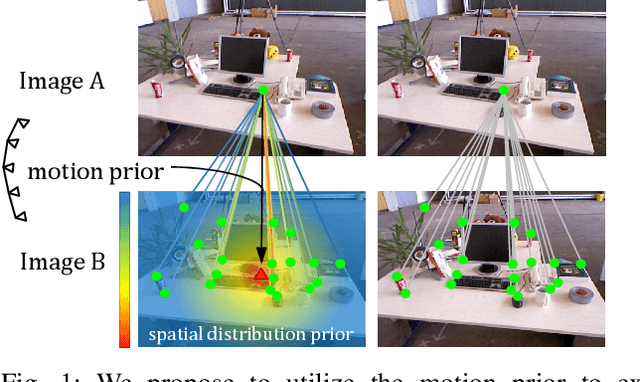

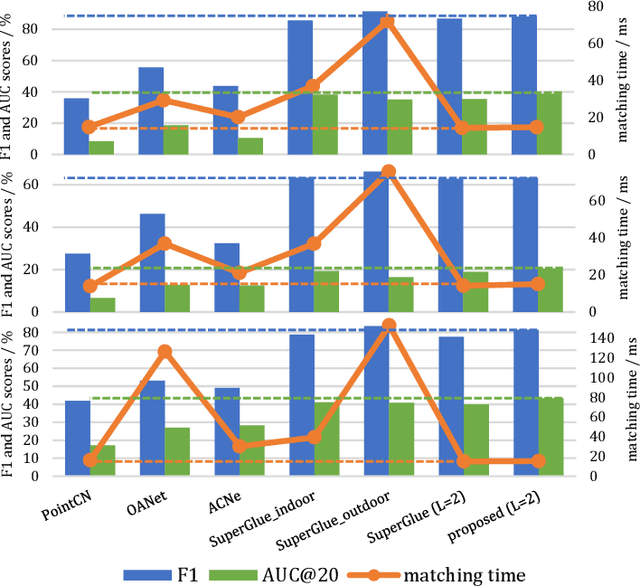
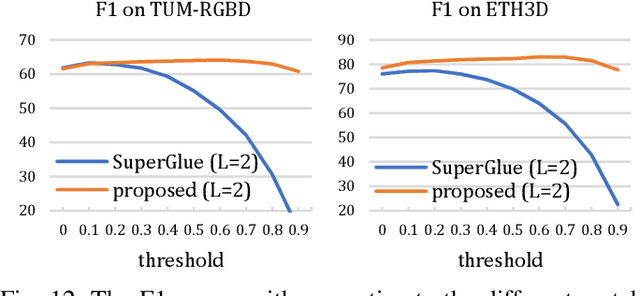
Keypoints matching is a pivotal component for many image-relevant applications such as image stitching, visual simultaneous localization and mapping (SLAM), and so on. Both handcrafted-based and recently emerged deep learning-based keypoints matching methods merely rely on keypoints and local features, while losing sight of other available sensors such as inertial measurement unit (IMU) in the above applications. In this paper, we demonstrate that the motion estimation from IMU integration can be used to exploit the spatial distribution prior of keypoints between images. To this end, a probabilistic perspective of attention formulation is proposed to integrate the spatial distribution prior into the attentional graph neural network naturally. With the assistance of spatial distribution prior, the effort of the network for modeling the hidden features can be reduced. Furthermore, we present a projection loss for the proposed keypoints matching network, which gives a smooth edge between matching and un-matching keypoints. Image matching experiments on visual SLAM datasets indicate the effectiveness and efficiency of the presented method.
Talk, Don't Write: A Study of Direct Speech-Based Image Retrieval
Apr 05, 2021
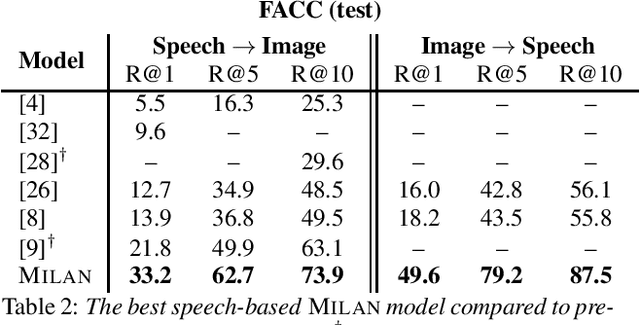
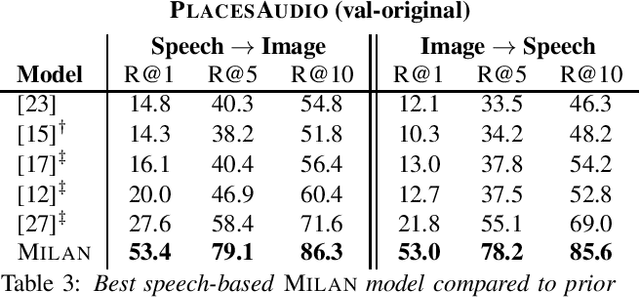
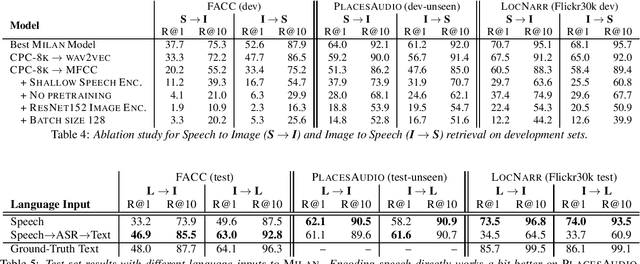
Speech-based image retrieval has been studied as a proxy for joint representation learning, usually without emphasis on retrieval itself. As such, it is unclear how well speech-based retrieval can work in practice -- both in an absolute sense and versus alternative strategies that combine automatic speech recognition (ASR) with strong text encoders. In this work, we extensively study and expand choices of encoder architectures, training methodology (including unimodal and multimodal pretraining), and other factors. Our experiments cover different types of speech in three datasets: Flickr Audio, Places Audio, and Localized Narratives. Our best model configuration achieves large gains over state of the art, e.g., pushing recall-at-one from 21.8% to 33.2% for Flickr Audio and 27.6% to 53.4% for Places Audio. We also show our best speech-based models can match or exceed cascaded ASR-to-text encoding when speech is spontaneous, accented, or otherwise hard to automatically transcribe.
Solving Inverse Problems with Hybrid Deep Image Priors: the challenge of preventing overfitting
Nov 03, 2020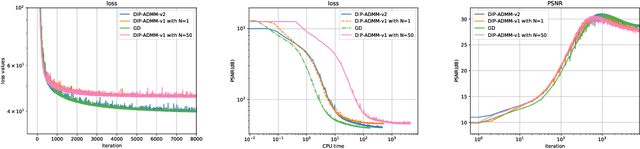
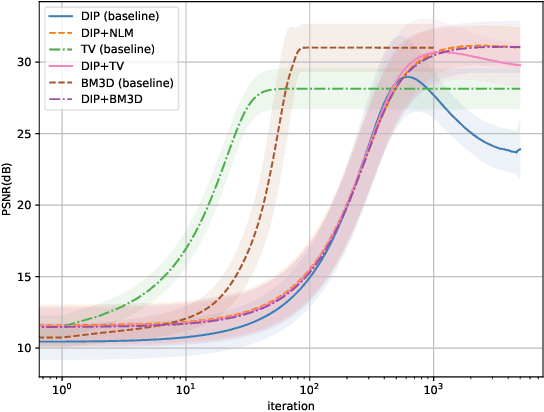
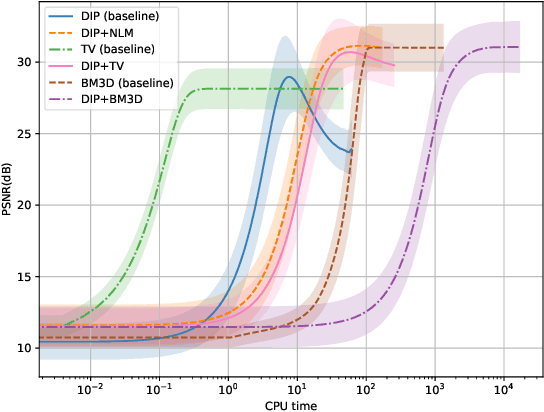

We mainly analyze and solve the overfitting problem of deep image prior (DIP). Deep image prior can solve inverse problems such as super-resolution, inpainting and denoising. The main advantage of DIP over other deep learning approaches is that it does not need access to a large dataset. However, due to the large number of parameters of the neural network and noisy data, DIP overfits to the noise in the image as the number of iterations grows. In the thesis, we use hybrid deep image priors to avoid overfitting. The hybrid priors are to combine DIP with an explicit prior such as total variation or with an implicit prior such as a denoising algorithm. We use the alternating direction method-of-multipliers (ADMM) to incorporate the new prior and try different forms of ADMM to avoid extra computation caused by the inner loop of ADMM steps. We also study the relation between the dynamics of gradient descent, and the overfitting phenomenon. The numerical results show the hybrid priors play an important role in preventing overfitting. Besides, we try to fit the image along some directions and find this method can reduce overfitting when the noise level is large. When the noise level is small, it does not considerably reduce the overfitting problem.
Optimizing Random Mixup with Gaussian Differential Privacy
Feb 14, 2022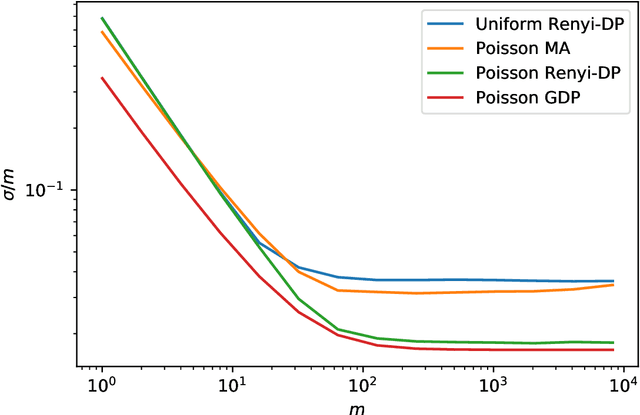
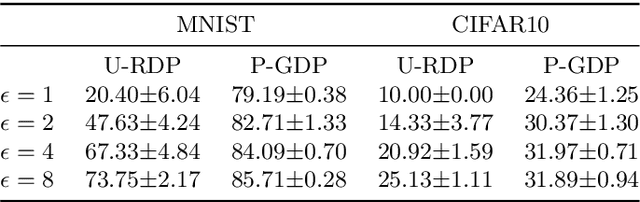
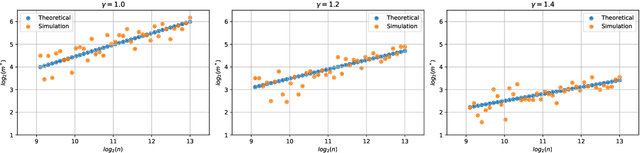
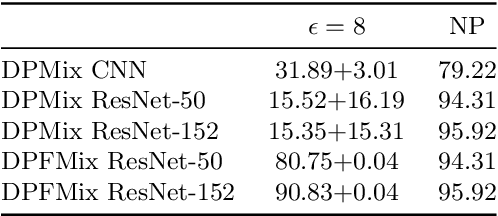
Differentially private data release receives rising attention in machine learning community. Recently, an algorithm called DPMix is proposed to release high-dimensional data after a random mixup of degree $m$ with differential privacy. However, limited theoretical justifications are given about the "sweet spot $m$" phenomenon, and directly applying DPMix to image data suffers from severe loss of utility. In this paper, we revisit random mixup with recent progress on differential privacy. In theory, equipped with Gaussian Differential Privacy with Poisson subsampling, a tight closed form analysis is presented that enables a quantitative characterization of optimal mixup $m^*$ based on linear regression models. In practice, mixup of features, extracted by handcraft or pre-trained neural networks such as self-supervised learning without labels, is adopted to significantly boost the performance with privacy protection. We name it as Differentially Private Feature Mixup (DPFMix). Experiments on MNIST, CIFAR10/100 are conducted to demonstrate its remarkable utility improvement and protection against attacks.
Satellite Image Classification with Deep Learning
Oct 13, 2020
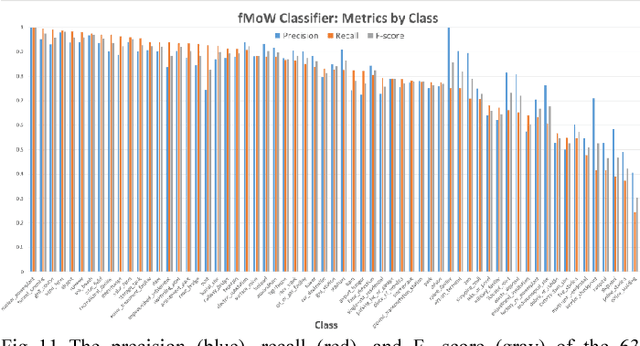
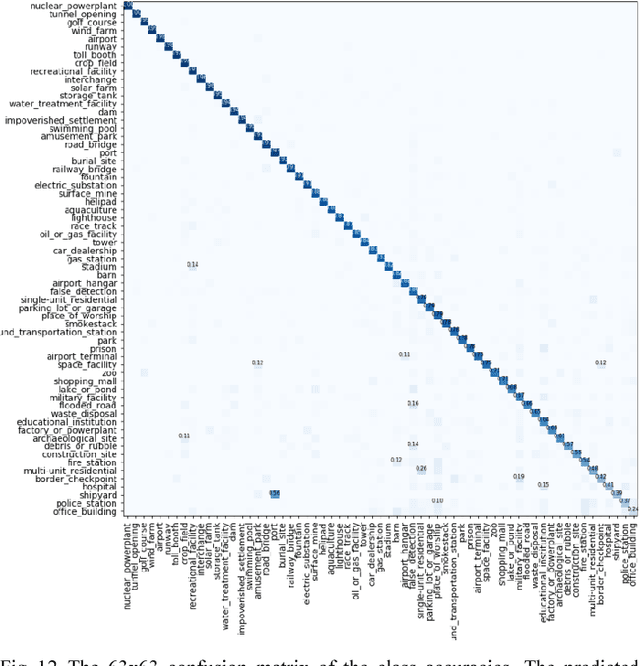

Satellite imagery is important for many applications including disaster response, law enforcement, and environmental monitoring. These applications require the manual identification of objects and facilities in the imagery. Because the geographic expanses to be covered are great and the analysts available to conduct the searches are few, automation is required. Yet traditional object detection and classification algorithms are too inaccurate and unreliable to solve the problem. Deep learning is a family of machine learning algorithms that have shown promise for the automation of such tasks. It has achieved success in image understanding by means of convolutional neural networks. In this paper we apply them to the problem of object and facility recognition in high-resolution, multi-spectral satellite imagery. We describe a deep learning system for classifying objects and facilities from the IARPA Functional Map of the World (fMoW) dataset into 63 different classes. The system consists of an ensemble of convolutional neural networks and additional neural networks that integrate satellite metadata with image features. It is implemented in Python using the Keras and TensorFlow deep learning libraries and runs on a Linux server with an NVIDIA Titan X graphics card. At the time of writing the system is in 2nd place in the fMoW TopCoder competition. Its total accuracy is 83%, the F1 score is 0.797, and it classifies 15 of the classes with accuracies of 95% or better.
* 7 pages, 18 figures, 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
Knowledge AI: New Medical AI Solution for Medical image Diagnosis
Jan 08, 2021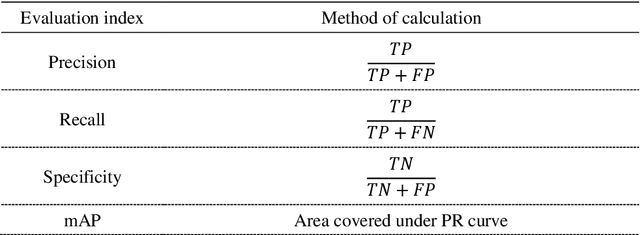

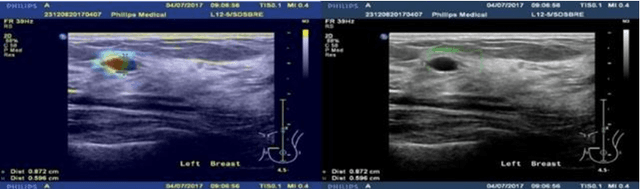
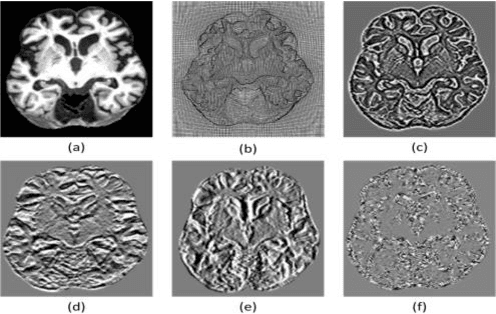
The implementation of medical AI has always been a problem. The effect of traditional perceptual AI algorithm in medical image processing needs to be improved. Here we propose a method of knowledge AI, which is a combination of perceptual AI and clinical knowledge and experience. Based on this method, the geometric information mining of medical images can represent the experience and information and evaluate the quality of medical images.
Piracy-Resistant DNN Watermarking by Block-Wise Image Transformation with Secret Key
Apr 09, 2021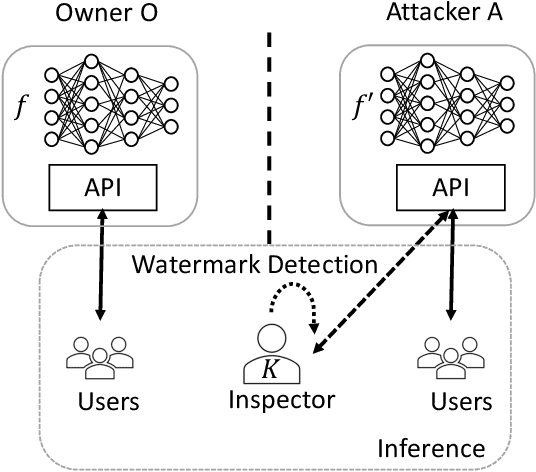
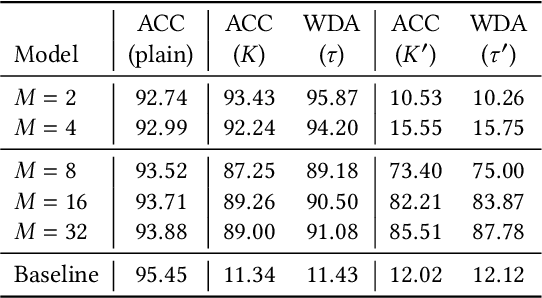
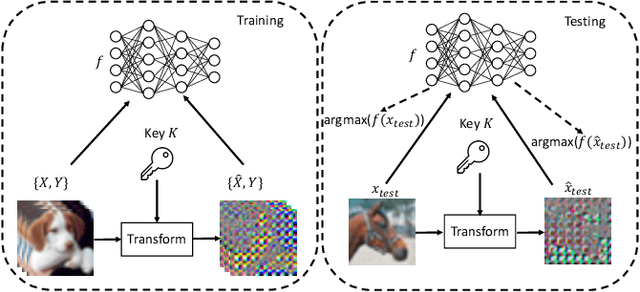

In this paper, we propose a novel DNN watermarking method that utilizes a learnable image transformation method with a secret key. The proposed method embeds a watermark pattern in a model by using learnable transformed images and allows us to remotely verify the ownership of the model. As a result, it is piracy-resistant, so the original watermark cannot be overwritten by a pirated watermark, and adding a new watermark decreases the model accuracy unlike most of the existing DNN watermarking methods. In addition, it does not require a special pre-defined training set or trigger set. We empirically evaluated the proposed method on the CIFAR-10 dataset. The results show that it was resilient against fine-tuning and pruning attacks while maintaining a high watermark-detection accuracy.
SubICap: Towards Subword-informed Image Captioning
Dec 24, 2020
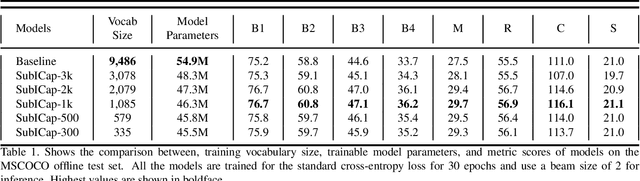
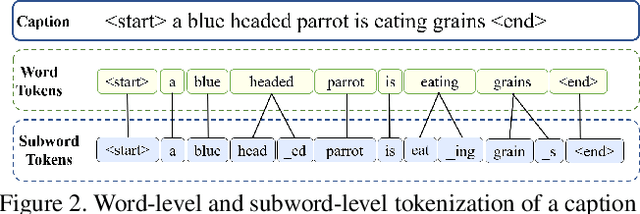
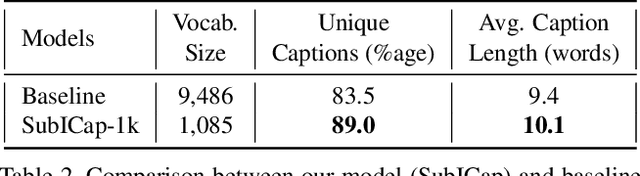
Existing Image Captioning (IC) systems model words as atomic units in captions and are unable to exploit the structural information in the words. This makes representation of rare words very difficult and out-of-vocabulary words impossible. Moreover, to avoid computational complexity, existing IC models operate over a modest sized vocabulary of frequent words, such that the identity of rare words is lost. In this work we address this common limitation of IC systems in dealing with rare words in the corpora. We decompose words into smaller constituent units 'subwords' and represent captions as a sequence of subwords instead of words. This helps represent all words in the corpora using a significantly lower subword vocabulary, leading to better parameter learning. Using subword language modeling, our captioning system improves various metric scores, with a training vocabulary size approximately 90% less than the baseline and various state-of-the-art word-level models. Our quantitative and qualitative results and analysis signify the efficacy of our proposed approach.
* 8 pages