 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020




This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
Direct Reconstruction of Linear Parametric Images from Dynamic PET Using Nonlocal Deep Image Prior
Jun 18, 2021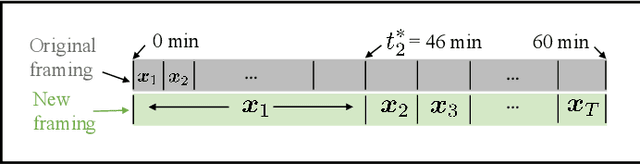
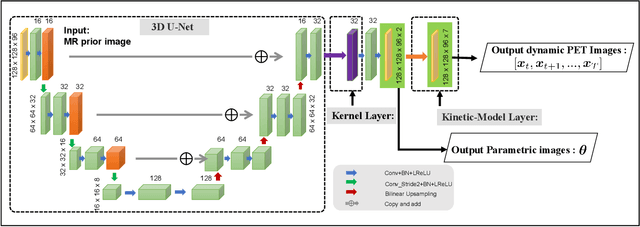
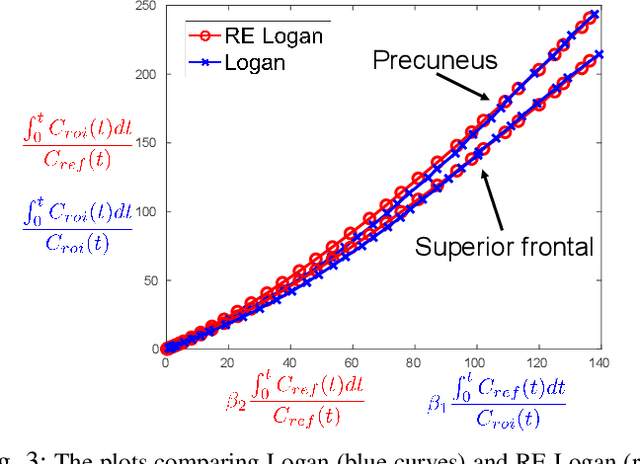
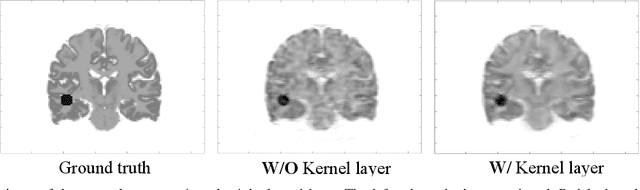
Direct reconstruction methods have been developed to estimate parametric images directly from the measured PET sinograms by combining the PET imaging model and tracer kinetics in an integrated framework. Due to limited counts received, signal-to-noise-ratio (SNR) and resolution of parametric images produced by direct reconstruction frameworks are still limited. Recently supervised deep learning methods have been successfully applied to medical imaging denoising/reconstruction when large number of high-quality training labels are available. For static PET imaging, high-quality training labels can be acquired by extending the scanning time. However, this is not feasible for dynamic PET imaging, where the scanning time is already long enough. In this work, we proposed an unsupervised deep learning framework for direct parametric reconstruction from dynamic PET, which was tested on the Patlak model and the relative equilibrium Logan model. The patient's anatomical prior image, which is readily available from PET/CT or PET/MR scans, was supplied as the network input to provide a manifold constraint, and also utilized to construct a kernel layer to perform non-local feature denoising. The linear kinetic model was embedded in the network structure as a 1x1 convolution layer. The training objective function was based on the PET statistical model. Evaluations based on dynamic datasets of 18F-FDG and 11C-PiB tracers show that the proposed framework can outperform the traditional and the kernel method-based direct reconstruction methods.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Feb 04, 2022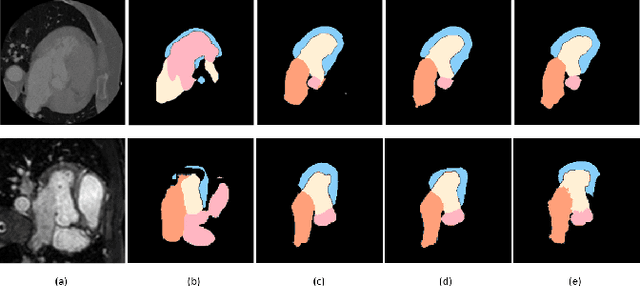
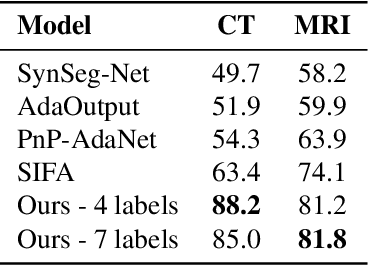


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.
Controllable Animation of Fluid Elements in Still Images
Dec 06, 2021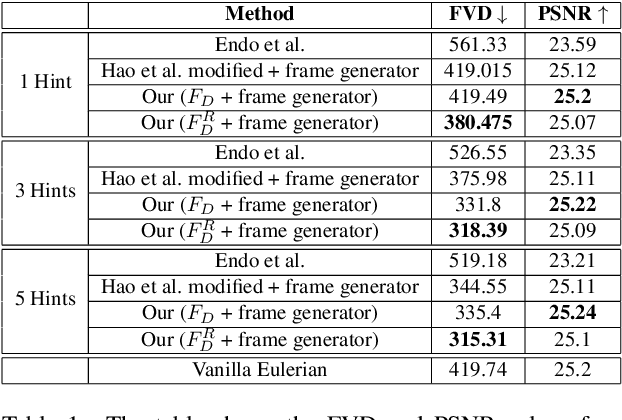
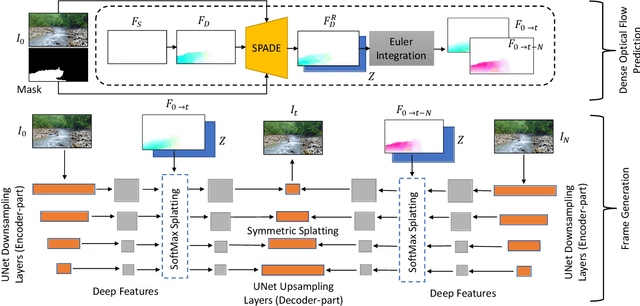
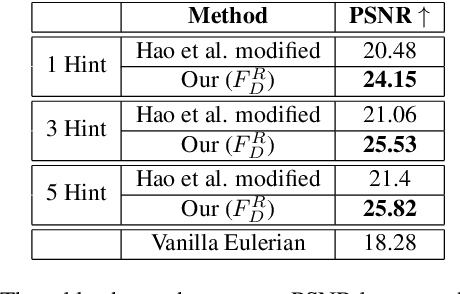

We propose a method to interactively control the animation of fluid elements in still images to generate cinemagraphs. Specifically, we focus on the animation of fluid elements like water, smoke, fire, which have the properties of repeating textures and continuous fluid motion. Taking inspiration from prior works, we represent the motion of such fluid elements in the image in the form of a constant 2D optical flow map. To this end, we allow the user to provide any number of arrow directions and their associated speeds along with a mask of the regions the user wants to animate. The user-provided input arrow directions, their corresponding speed values, and the mask are then converted into a dense flow map representing a constant optical flow map (FD). We observe that FD, obtained using simple exponential operations can closely approximate the plausible motion of elements in the image. We further refine computed dense optical flow map FD using a generative-adversarial network (GAN) to obtain a more realistic flow map. We devise a novel UNet based architecture to autoregressively generate future frames using the refined optical flow map by forward-warping the input image features at different resolutions. We conduct extensive experiments on a publicly available dataset and show that our method is superior to the baselines in terms of qualitative and quantitative metrics. In addition, we show the qualitative animations of the objects in directions that did not exist in the training set and provide a way to synthesize videos that otherwise would not exist in the real world.
An Efficient Polyp Segmentation Network
Mar 08, 2022Cancer is a disease that occurs as a result of uncontrolled division and proliferation of cells. The number of cancer cases has been on the rise over the recent years.. Colon cancer is one of the most common types of cancer in the world. Polyps that can be seen in the large intestine can cause cancer if not removed with early intervention. Deep learning and image segmentation techniques are used to minimize the number of polyps that goes unnoticed by the experts during the diagnosis. Although these techniques give good results, they require too many parameters. We propose a new model to solve this problem. Our proposed model includes less parameters as well as outperforming the success of the state of the art models. In the proposed model, a partial decoder is used to reduce the number of parameters while maintaning success. EfficientNetB0, which gives successfull results as well as requiring few parameters, is used in the encoder part. Since polyps have variable aspect and aspect ratios, an asymetric convolution block was used instead of using classic convolution block. Kvasir and CVC-ClinicDB datasets were seperated as training, validation and testing, and CVC-ColonDB, ETIS and Endoscene datasets were used for testing. According to the dice metric, our model had the best results with %71.8 in the ColonDB test dataset, %89.3 in the EndoScene test dataset and %74.8 in the ETIS test dataset. Our model requires a total of 2.626.337 parameters. When we compare it in the literature, according to similar studies, the model that requires the least parameters is U-Net++ with 9.042.177 parameters.
StyleGAN-induced data-driven regularization for inverse problems
Oct 07, 2021
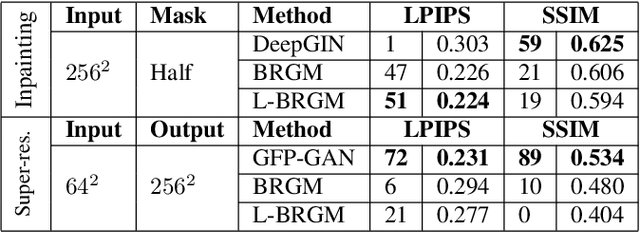

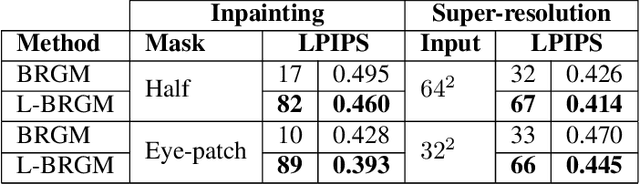
Recent advances in generative adversarial networks (GANs) have opened up the possibility of generating high-resolution photo-realistic images that were impossible to produce previously. The ability of GANs to sample from high-dimensional distributions has naturally motivated researchers to leverage their power for modeling the image prior in inverse problems. We extend this line of research by developing a Bayesian image reconstruction framework that utilizes the full potential of a pre-trained StyleGAN2 generator, which is the currently dominant GAN architecture, for constructing the prior distribution on the underlying image. Our proposed approach, which we refer to as learned Bayesian reconstruction with generative models (L-BRGM), entails joint optimization over the style-code and the input latent code, and enhances the expressive power of a pre-trained StyleGAN2 generator by allowing the style-codes to be different for different generator layers. Considering the inverse problems of image inpainting and super-resolution, we demonstrate that the proposed approach is competitive with, and sometimes superior to, state-of-the-art GAN-based image reconstruction methods.
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 29, 2020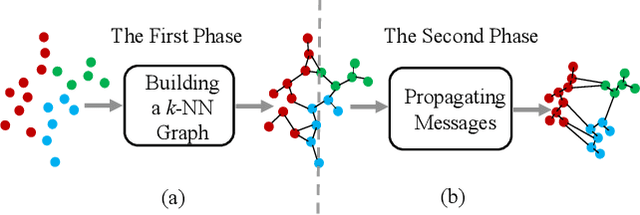

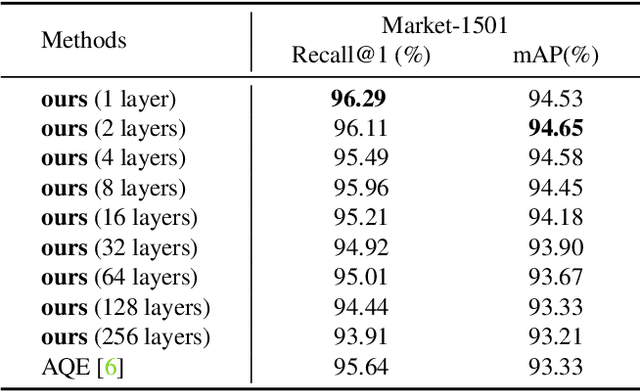
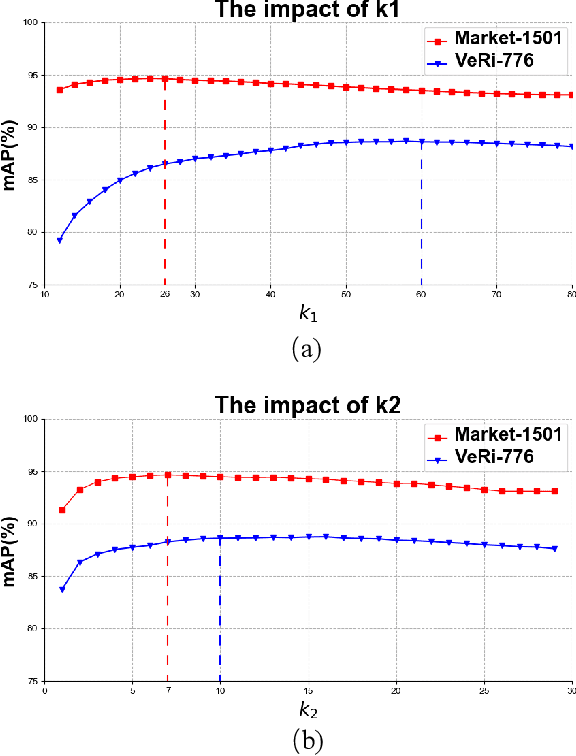
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.
SMILE: Semantically-guided Multi-attribute Image and Layout Editing
Oct 05, 2020
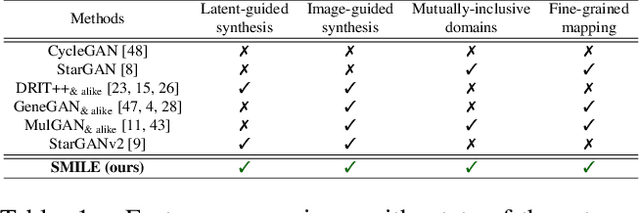
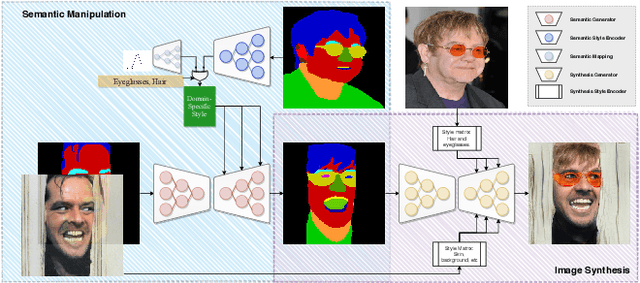

Attribute image manipulation has been a very active topic since the introduction of Generative Adversarial Networks (GANs). Exploring the disentangled attribute space within a transformation is a very challenging task due to the multiple and mutually-inclusive nature of the facial images, where different labels (eyeglasses, hats, hair, identity, etc.) can co-exist at the same time. Several works address this issue either by exploiting the modality of each domain/attribute using a conditional random vector noise, or extracting the modality from an exemplary image. However, existing methods cannot handle both random and reference transformations for multiple attributes, which limits the generality of the solutions. In this paper, we successfully exploit a multimodal representation that handles all attributes, be it guided by random noise or exemplar images, while only using the underlying domain information of the target domain. We present extensive qualitative and quantitative results for facial datasets and several different attributes that show the superiority of our method. Additionally, our method is capable of adding, removing or changing either fine-grained or coarse attributes by using an image as a reference or by exploring the style distribution space, and it can be easily extended to head-swapping and face-reenactment applications without being trained on videos.
Generalized Closed-form Formulae for Feature-based Subpixel Alignment in Patch-based Matching
Dec 02, 2021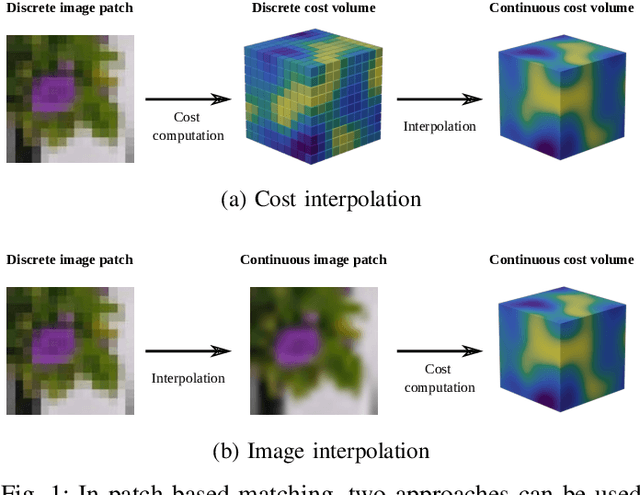

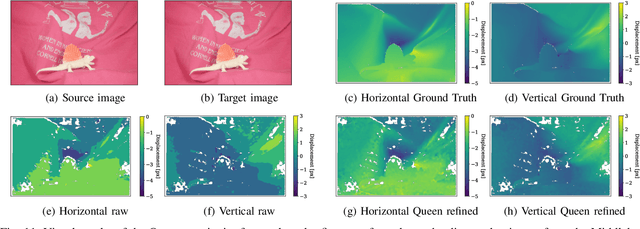
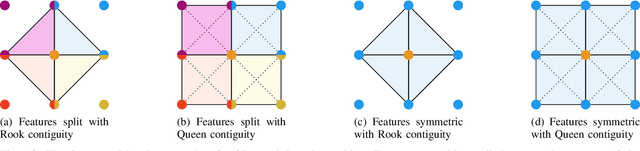
Cost-based image patch matching is at the core of various techniques in computer vision, photogrammetry and remote sensing. When the subpixel disparity between the reference patch in the source and target images is required, either the cost function or the target image have to be interpolated. While cost-based interpolation is the easiest to implement, multiple works have shown that image based interpolation can increase the accuracy of the subpixel matching, but usually at the cost of expensive search procedures. This, however, is problematic, especially for very computation intensive applications such as stereo matching or optical flow computation. In this paper, we show that closed form formulae for subpixel disparity computation for the case of one dimensional matching, e.g., in the case of rectified stereo images where the search space is of one dimension, exists when using the standard NCC, SSD and SAD cost functions. We then demonstrate how to generalize the proposed formulae to the case of high dimensional search spaces, which is required for unrectified stereo matching and optical flow extraction. We also compare our results with traditional cost volume interpolation formulae as well as with state-of-the-art cost-based refinement methods, and show that the proposed formulae bring a small improvement over the state-of-the-art cost-based methods in the case of one dimensional search spaces, and a significant improvement when the search space is two dimensional.
Large Deformation Diffeomorphic Image Registration with Laplacian Pyramid Networks
Jun 30, 2020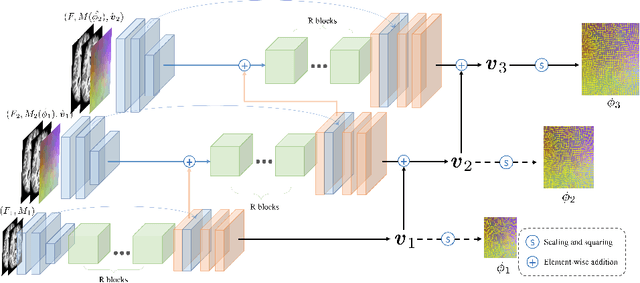
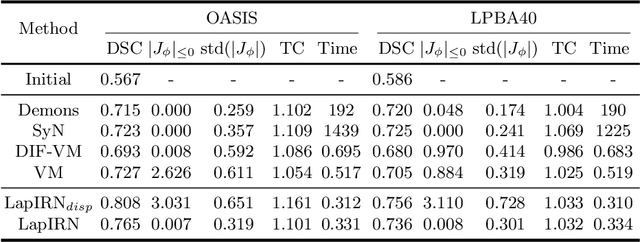
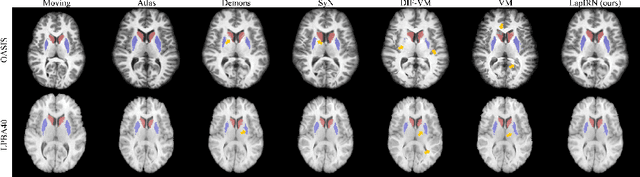
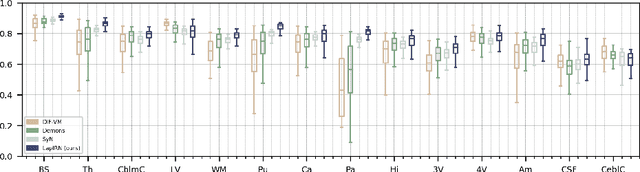
Deep learning-based methods have recently demonstrated promising results in deformable image registration for a wide range of medical image analysis tasks. However, existing deep learning-based methods are usually limited to small deformation settings, and desirable properties of the transformation including bijective mapping and topology preservation are often being ignored by these approaches. In this paper, we propose a deep Laplacian Pyramid Image Registration Network, which can solve the image registration optimization problem in a coarse-to-fine fashion within the space of diffeomorphic maps. Extensive quantitative and qualitative evaluations on two MR brain scan datasets show that our method outperforms the existing methods by a significant margin while maintaining desirable diffeomorphic properties and promising registration speed.