 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Preliminary Comparison Between Compressive Sampling and Anisotropic Mesh-based Image Representation
Nov 19, 2020
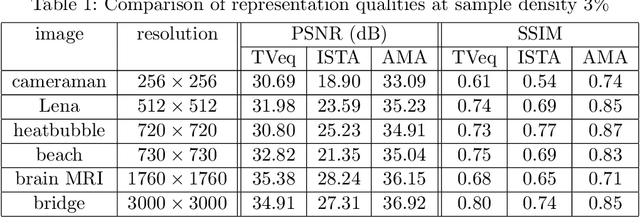
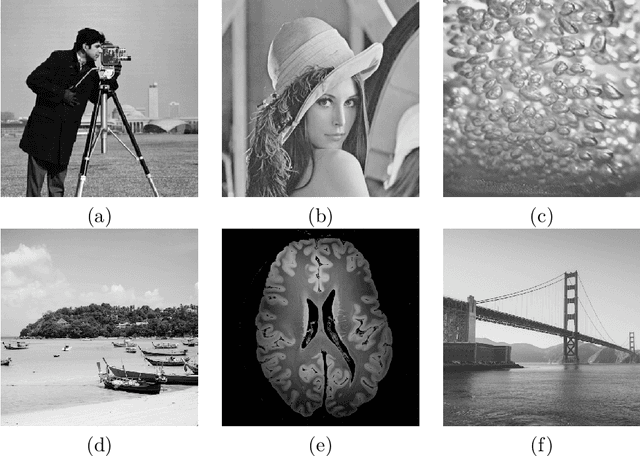
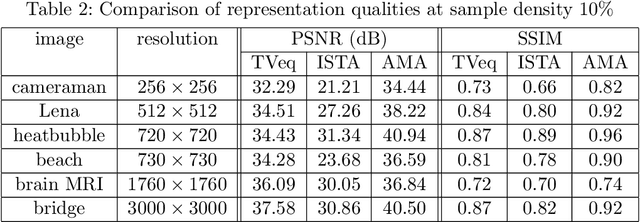

Compressed sensing (CS) has become a popular field in the last two decades to represent and reconstruct a sparse signal with much fewer samples than the signal itself. Although regular images are not sparse in their own, many can be sparsely represented in wavelet transform domain. Therefore, CS has also been widely applied to represent digital images. An alternative approach, adaptive sampling such as mesh-based image representation (MbIR), however, has not attracted as much attention. MbIR works directly on image pixels and represent the image with fewer points using a triangular mesh. In this paper, we perform a preliminary comparison between the CS and a recently developed MbIR method, AMA representation. The results demonstrate that, at the same sample density, AMA representation can provide better reconstruction quality than CS based on the tested algorithms. Further investigation with recent algorithms are needed to perform a thorough comparison.
A Graphical Approach For Brain Haemorrhage Segmentation
Feb 14, 2022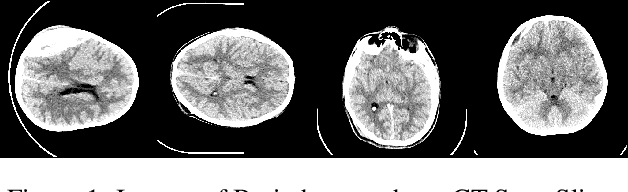



Haemorrhaging of the brain is the leading cause of death in people between the ages of 15 and 24 and the third leading cause of death in people older than that. Computed tomography (CT) is an imaging modality used to diagnose neurological emergencies, including stroke and traumatic brain injury. Recent advances in Deep Learning and Image Processing have utilised different modalities like CT scans to help automate the detection and segmentation of brain haemorrhage occurrences. In this paper, we propose a novel implementation of an architecture consisting of traditional Convolutional Neural Networks(CNN) along with Graph Neural Networks(GNN) to produce a holistic model for the task of brain haemorrhage segmentation.GNNs work on the principle of neighbourhood aggregation thus providing a reliable estimate of global structures present in images. GNNs work with few layers thus in turn requiring fewer parameters to work with. We were able to achieve a dice coefficient score of around 0.81 with limited data with our implementation.
Distortion-Aware Loop Filtering of Intra 360^o Video Coding with Equirectangular Projection
Feb 20, 2022
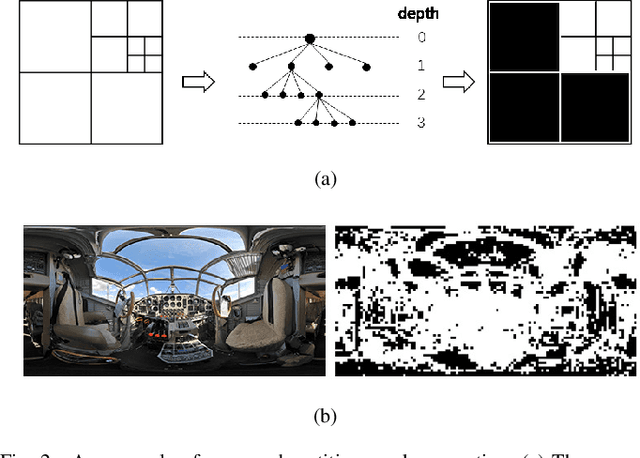
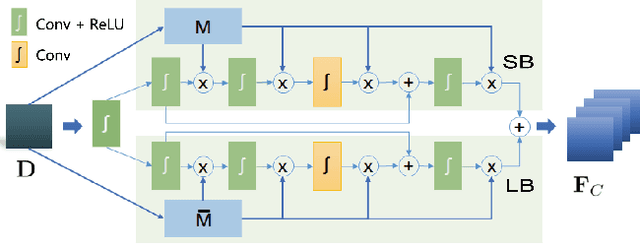
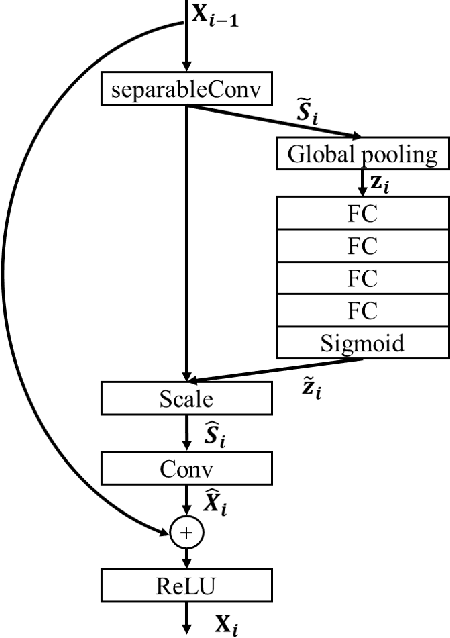
In this paper, we propose a distortion-aware loop filtering model to improve the performance of intra coding for 360$^o$ videos projected via equirectangular projection (ERP) format. To enable the awareness of distortion, our proposed module analyzes content characteristics based on a coding unit (CU) partition mask and processes them through partial convolution to activate the specified area. The feature recalibration module, which leverages cascaded residual channel-wise attention blocks (RCABs) to adjust the inter-channel and intra-channel features automatically, is capable of adapting with different quality levels. The perceptual geometry optimization combining with weighted mean squared error (WMSE) and the perceptual loss guarantees both the local field of view (FoV) and global image reconstruction with high quality. Extensive experimental results show that our proposed scheme achieves significant bitrate savings compared with the anchor (HM + 360Lib), leading to 8.9%, 9.0%, 7.1% and 7.4% on average bit rate reductions in terms of PSNR, WPSNR, and PSNR of two viewports for luminance component of 360^o videos, respectively.
Maximum a posteriori signal recovery for optical coherence tomography angiography image generation and denoising
Oct 29, 2020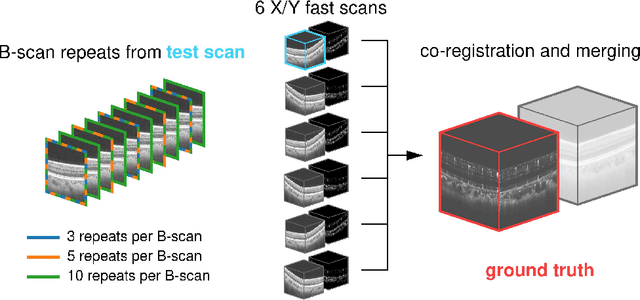
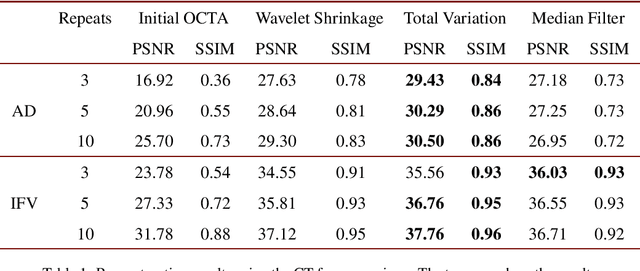
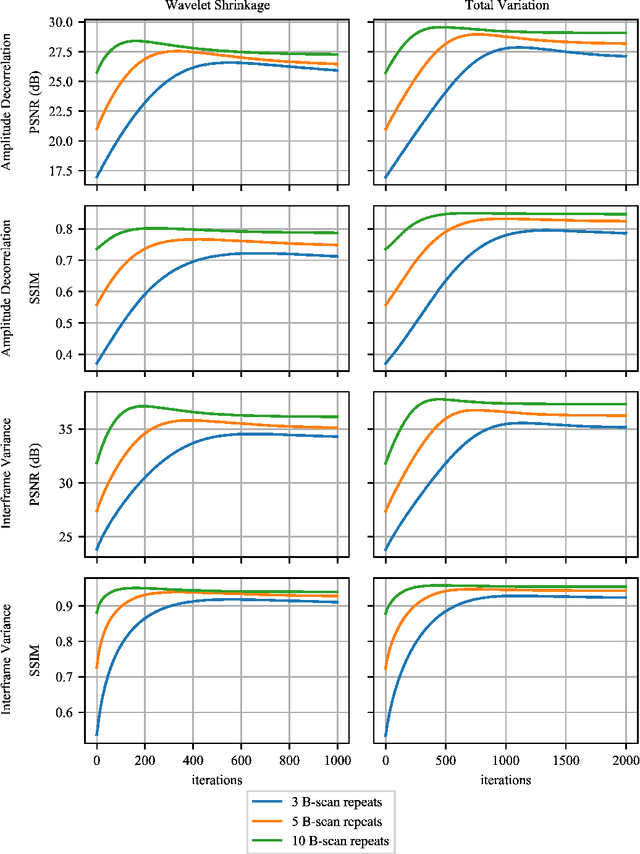

Optical coherence tomography angiography (OCTA) is a novel and clinically promising imaging modality to image retinal and sub-retinal vasculature. Based on repeated optical coherence tomography (OCT) scans, intensity changes are observed over time and used to compute OCTA image data. OCTA data are prone to noise and artifacts caused by variations in flow speed and patient movement. We propose a novel iterative maximum a posteriori signal recovery algorithm in order to generate OCTA volumes with reduced noise and increased image quality. This algorithm is based on previous work on probabilistic OCTA signal models and maximum likelihood estimates. Reconstruction results using total variation minimization and wavelet shrinkage for regularization were compared against an OCTA ground truth volume, merged from six co-registered single OCTA volumes. The results show a significant improvement in peak signal-to-noise ratio and structural similarity. The presented algorithm brings together OCTA image generation and Bayesian statistics and can be developed into new OCTA image generation and denoising algorithms.
No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models
Feb 14, 2022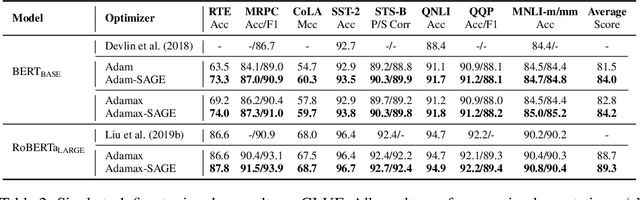
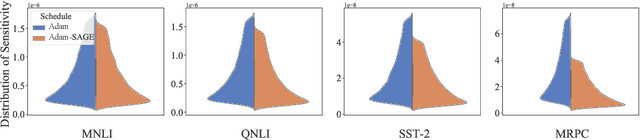

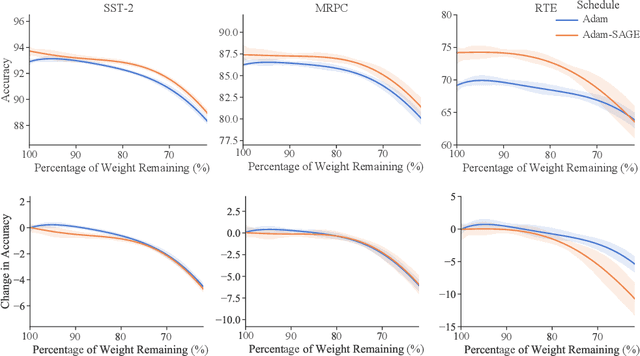
Recent research has shown the existence of significant redundancy in large Transformer models. One can prune the redundant parameters without significantly sacrificing the generalization performance. However, we question whether the redundant parameters could have contributed more if they were properly trained. To answer this question, we propose a novel training strategy that encourages all parameters to be trained sufficiently. Specifically, we adaptively adjust the learning rate for each parameter according to its sensitivity, a robust gradient-based measure reflecting this parameter's contribution to the model performance. A parameter with low sensitivity is redundant, and we improve its fitting by increasing its learning rate. In contrast, a parameter with high sensitivity is well-trained, and we regularize it by decreasing its learning rate to prevent further overfitting. We conduct extensive experiments on natural language understanding, neural machine translation, and image classification to demonstrate the effectiveness of the proposed schedule. Analysis shows that the proposed schedule indeed reduces the redundancy and improves generalization performance.
Nonnegative OPLS for Supervised Design of Filter Banks: Application to Image and Audio Feature Extraction
Dec 22, 2021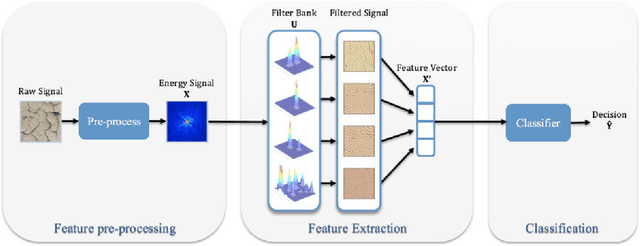
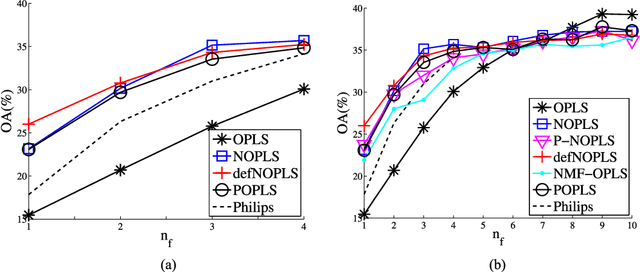
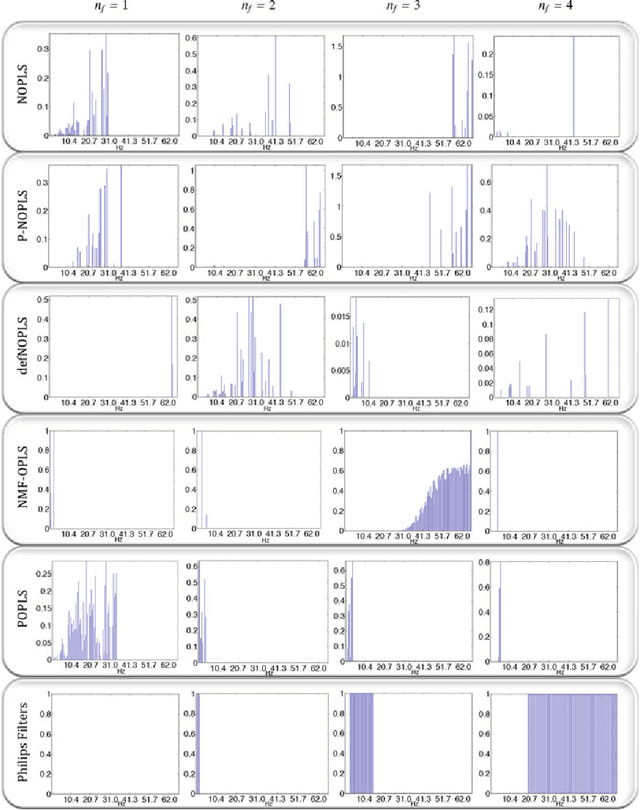

Audio or visual data analysis tasks usually have to deal with high-dimensional and nonnegative signals. However, most data analysis methods suffer from overfitting and numerical problems when data have more than a few dimensions needing a dimensionality reduction preprocessing. Moreover, interpretability about how and why filters work for audio or visual applications is a desired property, especially when energy or spectral signals are involved. In these cases, due to the nature of these signals, the nonnegativity of the filter weights is a desired property to better understand its working. Because of these two necessities, we propose different methods to reduce the dimensionality of data while the nonnegativity and interpretability of the solution are assured. In particular, we propose a generalized methodology to design filter banks in a supervised way for applications dealing with nonnegative data, and we explore different ways of solving the proposed objective function consisting of a nonnegative version of the orthonormalized partial least-squares method. We analyze the discriminative power of the features obtained with the proposed methods for two different and widely studied applications: texture and music genre classification. Furthermore, we compare the filter banks achieved by our methods with other state-of-the-art methods specifically designed for feature extraction.
Graphonomy: Universal Image Parsing via Graph Reasoning and Transfer
Jan 26, 2021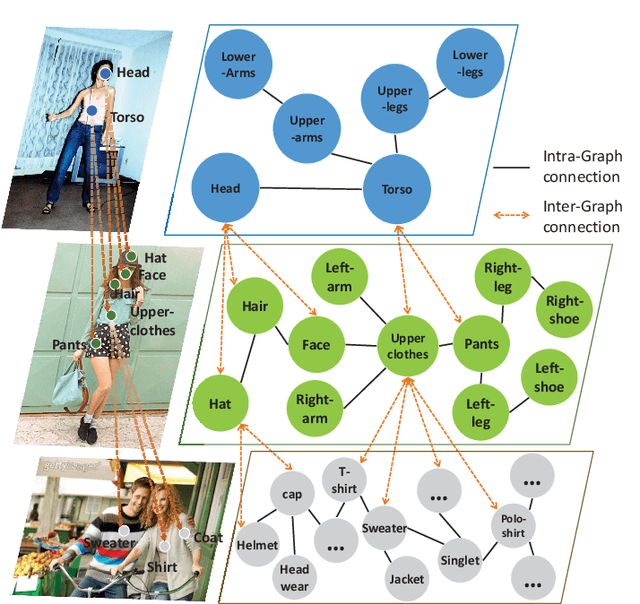

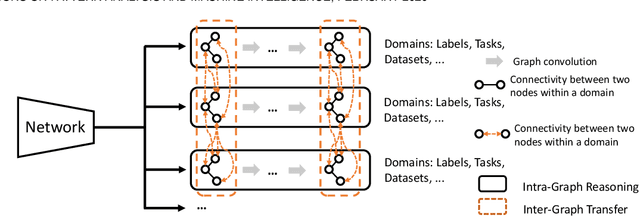
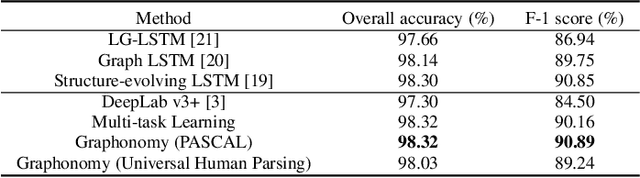
Prior highly-tuned image parsing models are usually studied in a certain domain with a specific set of semantic labels and can hardly be adapted into other scenarios (e.g., sharing discrepant label granularity) without extensive re-training. Learning a single universal parsing model by unifying label annotations from different domains or at various levels of granularity is a crucial but rarely addressed topic. This poses many fundamental learning challenges, e.g., discovering underlying semantic structures among different label granularity or mining label correlation across relevant tasks. To address these challenges, we propose a graph reasoning and transfer learning framework, named "Graphonomy", which incorporates human knowledge and label taxonomy into the intermediate graph representation learning beyond local convolutions. In particular, Graphonomy learns the global and structured semantic coherency in multiple domains via semantic-aware graph reasoning and transfer, enforcing the mutual benefits of the parsing across domains (e.g., different datasets or co-related tasks). The Graphonomy includes two iterated modules: Intra-Graph Reasoning and Inter-Graph Transfer modules. The former extracts the semantic graph in each domain to improve the feature representation learning by propagating information with the graph; the latter exploits the dependencies among the graphs from different domains for bidirectional knowledge transfer. We apply Graphonomy to two relevant but different image understanding research topics: human parsing and panoptic segmentation, and show Graphonomy can handle both of them well via a standard pipeline against current state-of-the-art approaches. Moreover, some extra benefit of our framework is demonstrated, e.g., generating the human parsing at various levels of granularity by unifying annotations across different datasets.
Trained Model in Supervised Deep Learning is a Conditional Risk Minimizer
Feb 08, 2022
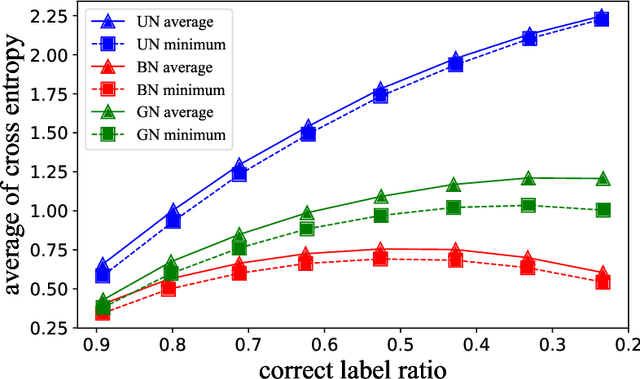
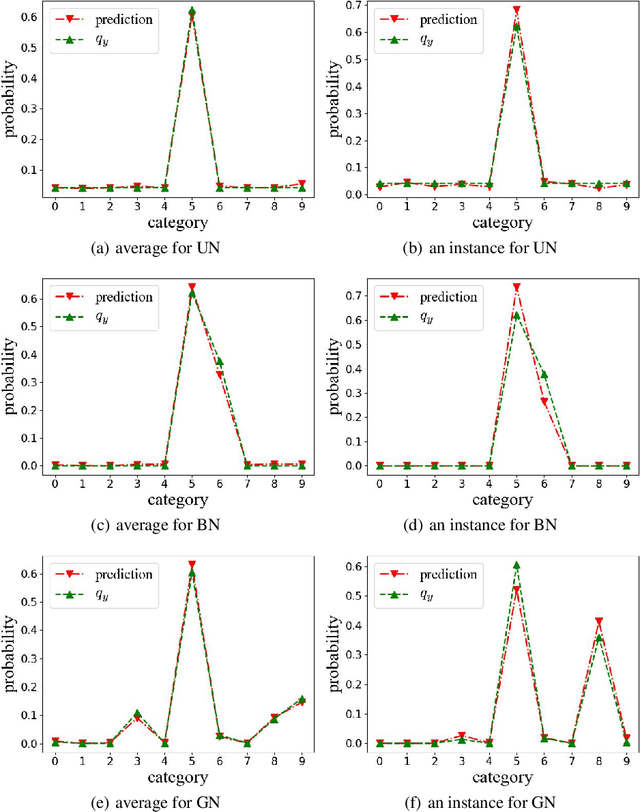
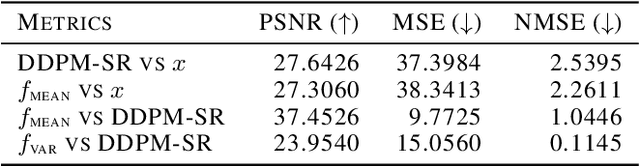
We proved that a trained model in supervised deep learning minimizes the conditional risk for each input (Theorem 2.1). This property provided insights into the behavior of trained models and established a connection between supervised and unsupervised learning in some cases. In addition, when the labels are intractable but can be written as a conditional risk minimizer, we proved an equivalent form of the original supervised learning problem with accessible labels (Theorem 2.2). We demonstrated that many existing works, such as Noise2Score, Noise2Noise and score function estimation can be explained by our theorem. Moreover, we derived a property of classification problem with noisy labels using Theorem 2.1 and validated it using MNIST dataset. Furthermore, We proposed a method to estimate uncertainty in image super-resolution based on Theorem 2.2 and validated it using ImageNet dataset. Our code is available on github.
Detecting Adversaries, yet Faltering to Noise? Leveraging Conditional Variational AutoEncoders for Adversary Detection in the Presence of Noisy Images
Nov 28, 2021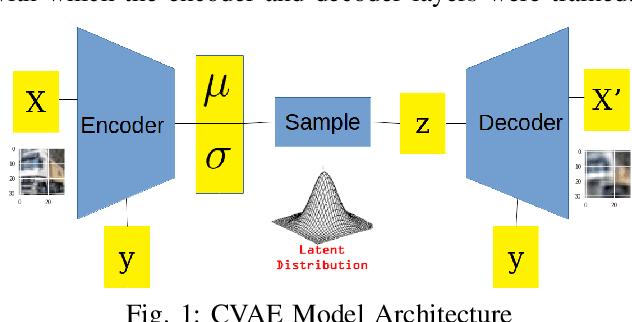
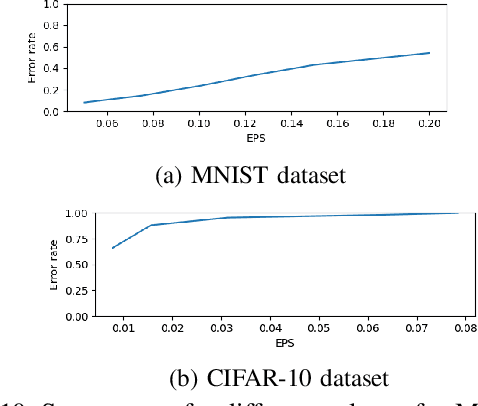
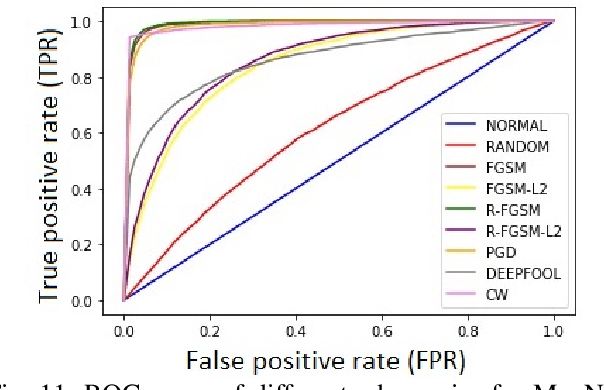
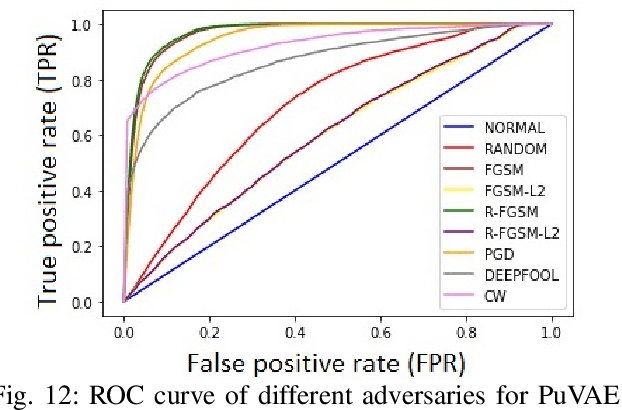
With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. What is so special in the slightest intelligent perturbations or noise additions over normal images that it leads to catastrophic classifications by the deep neural networks? Using statistical hypothesis testing, we find that Conditional Variational AutoEncoders (CVAE) are surprisingly good at detecting imperceptible image perturbations. In this paper, we show how CVAEs can be effectively used to detect adversarial attacks on image classification networks. We demonstrate our results over MNIST, CIFAR-10 dataset and show how our method gives comparable performance to the state-of-the-art methods in detecting adversaries while not getting confused with noisy images, where most of the existing methods falter.
Explainability Tools Enabling Deep Learning in Future In-Situ Real-Time Planetary Explorations
Jan 15, 2022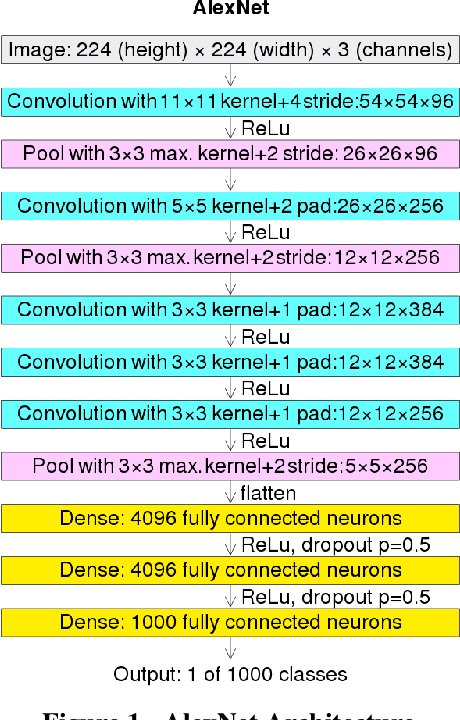
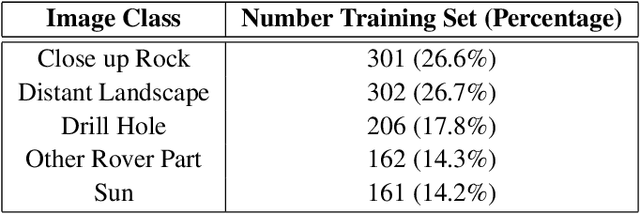


Deep learning (DL) has proven to be an effective machine learning and computer vision technique. DL-based image segmentation, object recognition and classification will aid many in-situ Mars rover tasks such as path planning and artifact recognition/extraction. However, most of the Deep Neural Network (DNN) architectures are so complex that they are considered a 'black box'. In this paper, we used integrated gradients to describe the attributions of each neuron to the output classes. It provides a set of explainability tools (ET) that opens the black box of a DNN so that the individual contribution of neurons to category classification can be ranked and visualized. The neurons in each dense layer are mapped and ranked by measuring expected contribution of a neuron to a class vote given a true image label. The importance of neurons is prioritized according to their correct or incorrect contribution to the output classes and suppression or bolstering of incorrect classes, weighted by the size of each class. ET provides an interface to prune the network to enhance high-rank neurons and remove low-performing neurons. ET technology will make DNNs smaller and more efficient for implementation in small embedded systems. It also leads to more explainable and testable DNNs that can make systems easier for Validation \& Verification. The goal of ET technology is to enable the adoption of DL in future in-situ planetary exploration missions.