 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Phrase-Based Affordance Detection via Cyclic Bilateral Interaction
Feb 25, 2022

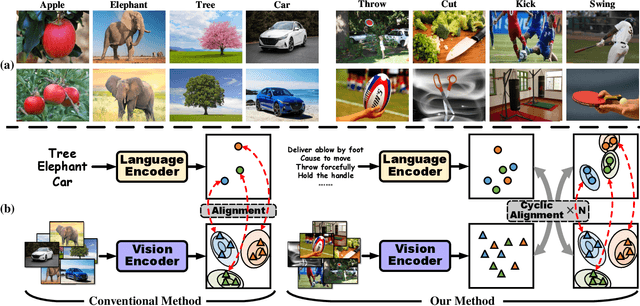
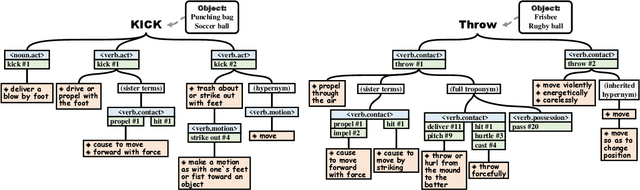
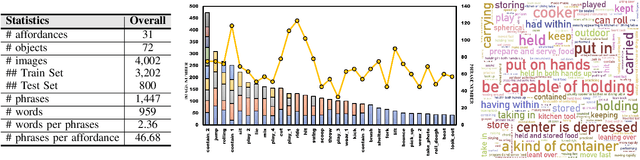
Affordance detection, which refers to perceiving objects with potential action possibilities in images, is a challenging task since the possible affordance depends on the person's purpose in real-world application scenarios. The existing works mainly extract the inherent human-object dependencies from image/video to accommodate affordance properties that change dynamically. In this paper, we explore to perceive affordance from a vision-language perspective and consider the challenging phrase-based affordance detection problem,i.e., given a set of phrases describing the action purposes, all the object regions in a scene with the same affordance should be detected. To this end, we propose a cyclic bilateral consistency enhancement network (CBCE-Net) to align language and vision features progressively. Specifically, the presented CBCE-Net consists of a mutual guided vision-language module that updates the common features of vision and language in a progressive manner, and a cyclic interaction module (CIM) that facilitates the perception of possible interaction with objects in a cyclic manner. In addition, we extend the public Purpose-driven Affordance Dataset (PAD) by annotating affordance categories with short phrases. The contrastive experimental results demonstrate the superiority of our method over nine typical methods from four relevant fields in terms of both objective metrics and visual quality. The related code and dataset will be released at \url{https://github.com/lulsheng/CBCE-Net}.
MantissaCam: Learning Snapshot High-dynamic-range Imaging with Perceptually-based In-pixel Irradiance Encoding
Dec 09, 2021
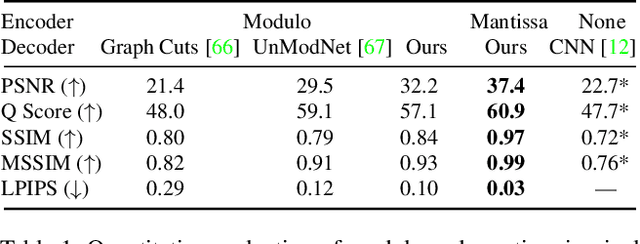
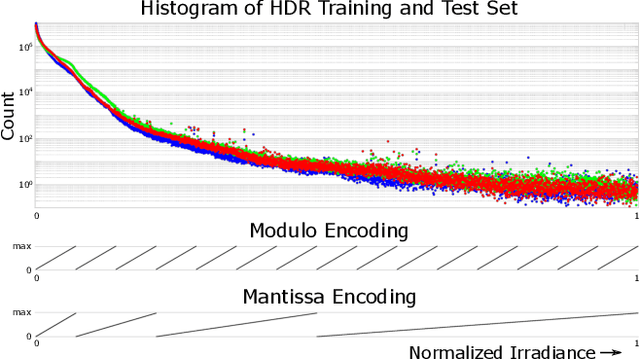

The ability to image high-dynamic-range (HDR) scenes is crucial in many computer vision applications. The dynamic range of conventional sensors, however, is fundamentally limited by their well capacity, resulting in saturation of bright scene parts. To overcome this limitation, emerging sensors offer in-pixel processing capabilities to encode the incident irradiance. Among the most promising encoding schemes is modulo wrapping, which results in a computational photography problem where the HDR scene is computed by an irradiance unwrapping algorithm from the wrapped low-dynamic-range (LDR) sensor image. Here, we design a neural network--based algorithm that outperforms previous irradiance unwrapping methods and, more importantly, we design a perceptually inspired "mantissa" encoding scheme that more efficiently wraps an HDR scene into an LDR sensor. Combined with our reconstruction framework, MantissaCam achieves state-of-the-art results among modulo-type snapshot HDR imaging approaches. We demonstrate the efficacy of our method in simulation and show preliminary results of a prototype MantissaCam implemented with a programmable sensor.
Spherical Transformer
Feb 10, 2022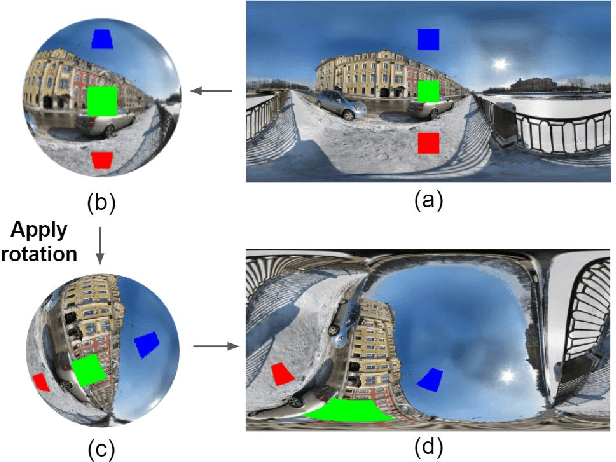
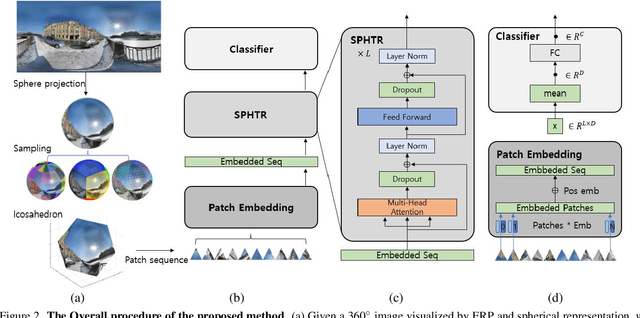
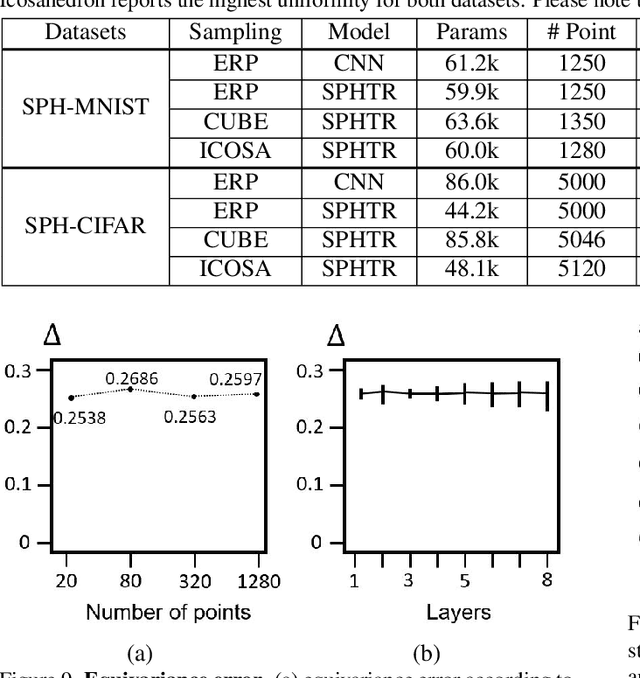
Using convolutional neural networks for 360images can induce sub-optimal performance due to distortions entailed by a planar projection. The distortion gets deteriorated when a rotation is applied to the 360image. Thus, many researches based on convolutions attempt to reduce the distortions to learn accurate representation. In contrast, we leverage the transformer architecture to solve image classification problems for 360images. Using the proposed transformer for 360images has two advantages. First, our method does not require the erroneous planar projection process by sampling pixels from the sphere surface. Second, our sampling method based on regular polyhedrons makes low rotation equivariance errors, because specific rotations can be reduced to permutations of faces. In experiments, we validate our network on two aspects, as follows. First, we show that using a transformer with highly uniform sampling methods can help reduce the distortion. Second, we demonstrate that the transformer architecture can achieve rotation equivariance on specific rotations. We compare our method to other state-of-the-art algorithms using the SPH-MNIST, SPH-CIFAR, and SUN360 datasets and show that our method is competitive with other methods.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021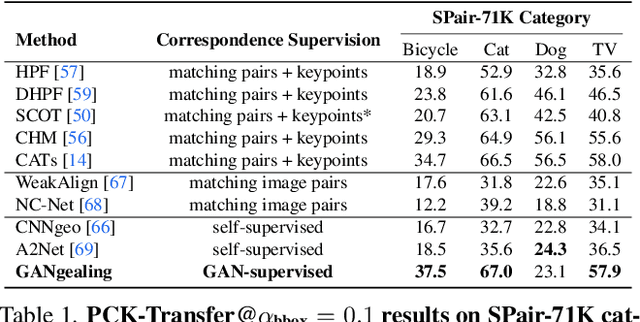
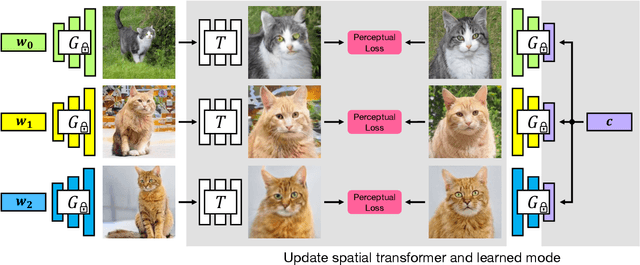


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.
Few-shot Image Classification with Multi-Facet Prototypes
Feb 01, 2021
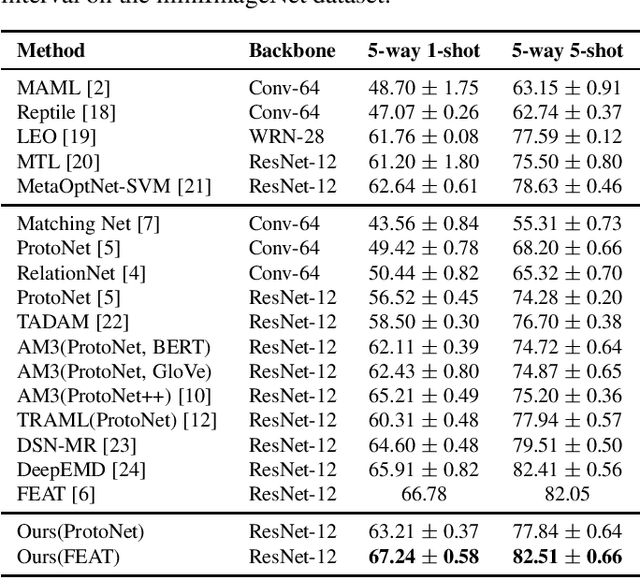
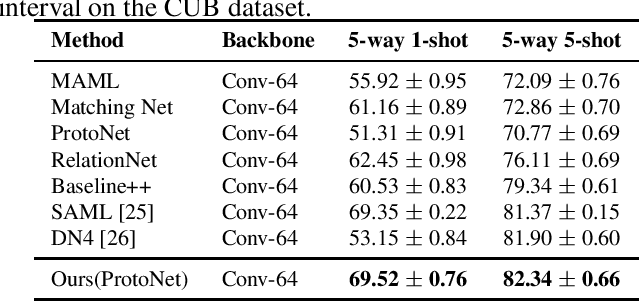
The aim of few-shot learning (FSL) is to learn how to recognize image categories from a small number of training examples. A central challenge is that the available training examples are normally insufficient to determine which visual features are most characteristic of the considered categories. To address this challenge, we organize these visual features into facets, which intuitively group features of the same kind (e.g. features that are relevant to shape, color, or texture). This is motivated from the assumption that (i) the importance of each facet differs from category to category and (ii) it is possible to predict facet importance from a pre-trained embedding of the category names. In particular, we propose an adaptive similarity measure, relying on predicted facet importance weights for a given set of categories. This measure can be used in combination with a wide array of existing metric-based methods. Experiments on miniImageNet and CUB show that our approach improves the state-of-the-art in metric-based FSL.
An Efficient Polyp Segmentation Network
Mar 08, 2022Cancer is a disease that occurs as a result of uncontrolled division and proliferation of cells. The number of cancer cases has been on the rise over the recent years.. Colon cancer is one of the most common types of cancer in the world. Polyps that can be seen in the large intestine can cause cancer if not removed with early intervention. Deep learning and image segmentation techniques are used to minimize the number of polyps that goes unnoticed by the experts during the diagnosis. Although these techniques give good results, they require too many parameters. We propose a new model to solve this problem. Our proposed model includes less parameters as well as outperforming the success of the state of the art models. In the proposed model, a partial decoder is used to reduce the number of parameters while maintaning success. EfficientNetB0, which gives successfull results as well as requiring few parameters, is used in the encoder part. Since polyps have variable aspect and aspect ratios, an asymetric convolution block was used instead of using classic convolution block. Kvasir and CVC-ClinicDB datasets were seperated as training, validation and testing, and CVC-ColonDB, ETIS and Endoscene datasets were used for testing. According to the dice metric, our model had the best results with %71.8 in the ColonDB test dataset, %89.3 in the EndoScene test dataset and %74.8 in the ETIS test dataset. Our model requires a total of 2.626.337 parameters. When we compare it in the literature, according to similar studies, the model that requires the least parameters is U-Net++ with 9.042.177 parameters.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Feb 04, 2022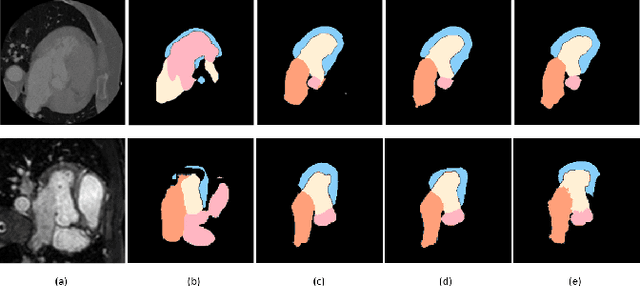
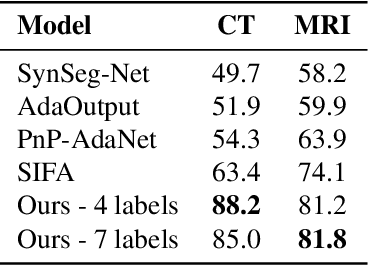


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.
LookinGood^π: Real-time Person-independent Neural Re-rendering for High-quality Human Performance Capture
Dec 15, 2021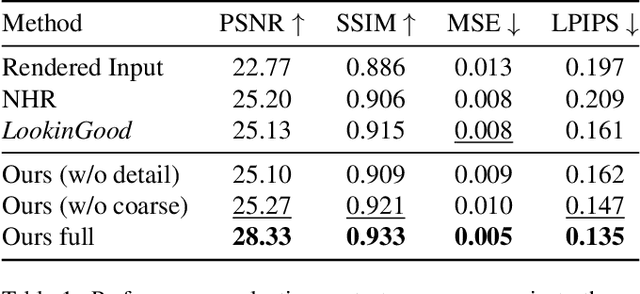
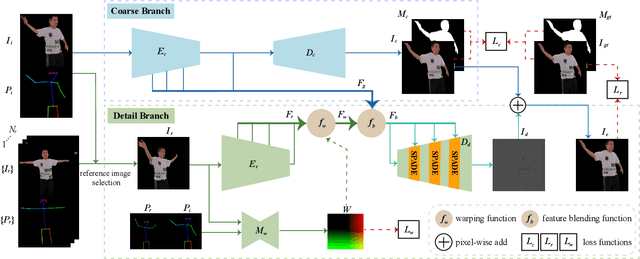
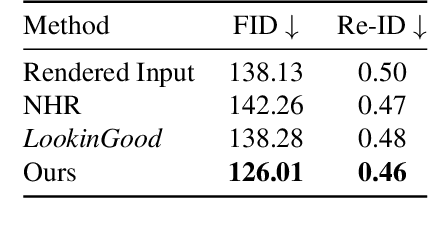

We propose LookinGood^{\pi}, a novel neural re-rendering approach that is aimed to (1) improve the rendering quality of the low-quality reconstructed results from human performance capture system in real-time; (2) improve the generalization ability of the neural rendering network on unseen people. Our key idea is to utilize the rendered image of reconstructed geometry as the guidance to assist the prediction of person-specific details from few reference images, thus enhancing the re-rendered result. In light of this, we design a two-branch network. A coarse branch is designed to fix some artifacts (i.e. holes, noise) and obtain a coarse version of the rendered input, while a detail branch is designed to predict "correct" details from the warped references. The guidance of the rendered image is realized by blending features from two branches effectively in the training of the detail branch, which improves both the warping accuracy and the details' fidelity. We demonstrate that our method outperforms state-of-the-art methods at producing high-fidelity images on unseen people.
Learning Multi-Object Dynamics with Compositional Neural Radiance Fields
Mar 04, 2022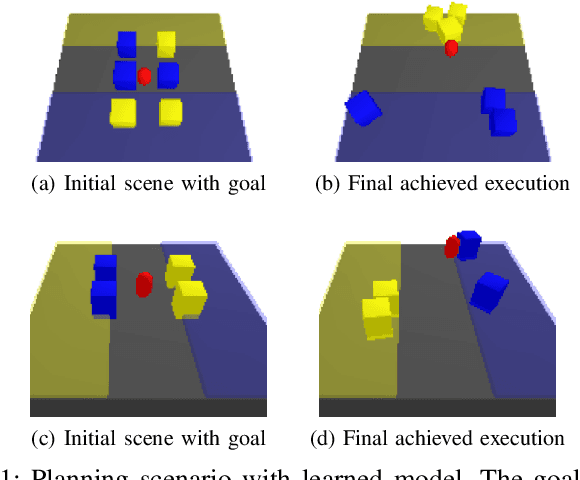
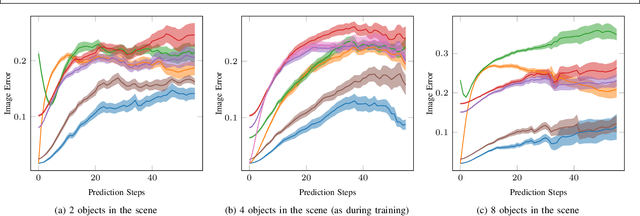
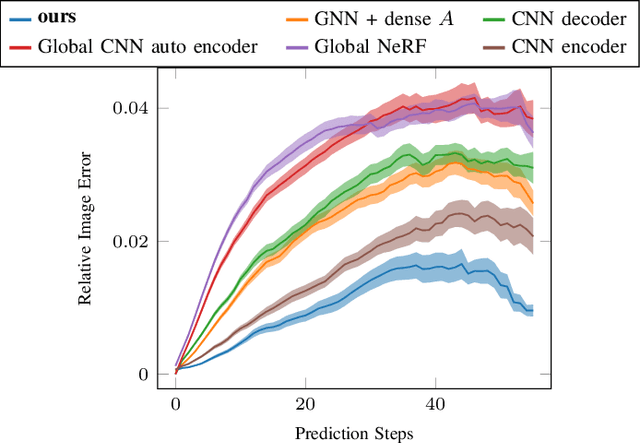
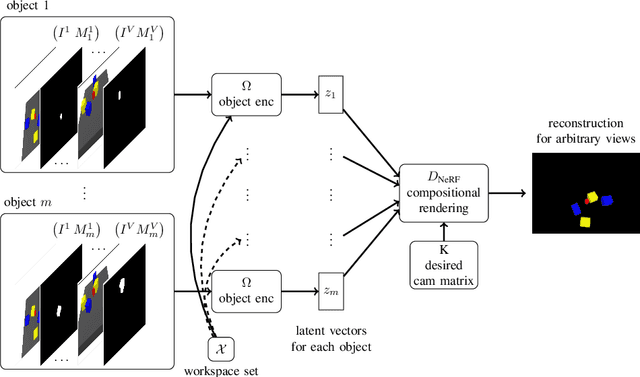
We present a method to learn compositional predictive models from image observations based on implicit object encoders, Neural Radiance Fields (NeRFs), and graph neural networks. A central question in learning dynamic models from sensor observations is on which representations predictions should be performed. NeRFs have become a popular choice for representing scenes due to their strong 3D prior. However, most NeRF approaches are trained on a single scene, representing the whole scene with a global model, making generalization to novel scenes, containing different numbers of objects, challenging. Instead, we present a compositional, object-centric auto-encoder framework that maps multiple views of the scene to a \emph{set} of latent vectors representing each object separately. The latent vectors parameterize individual NeRF models from which the scene can be reconstructed and rendered from novel viewpoints. We train a graph neural network dynamics model in the latent space to achieve compositionality for dynamics prediction. A key feature of our approach is that the learned 3D information of the scene through the NeRF model enables us to incorporate structural priors in learning the dynamics models, making long-term predictions more stable. The model can further be used to synthesize new scenes from individual object observations. For planning, we utilize RRTs in the learned latent space, where we can exploit our model and the implicit object encoder to make sampling the latent space informative and more efficient. In the experiments, we show that the model outperforms several baselines on a pushing task containing many objects. Video: https://dannydriess.github.io/compnerfdyn/
Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
Feb 15, 2022
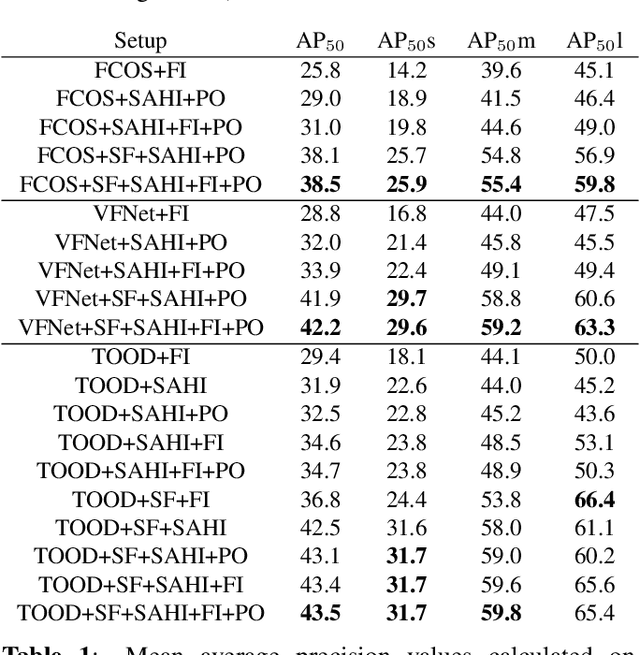
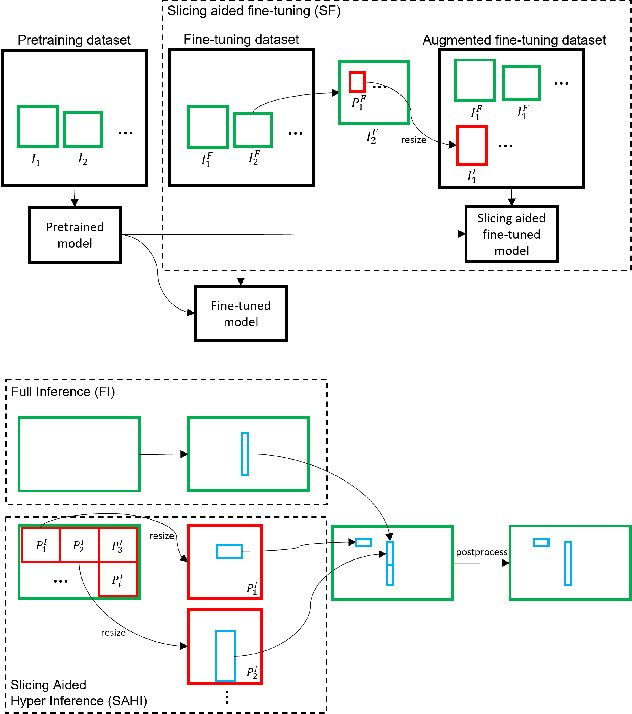
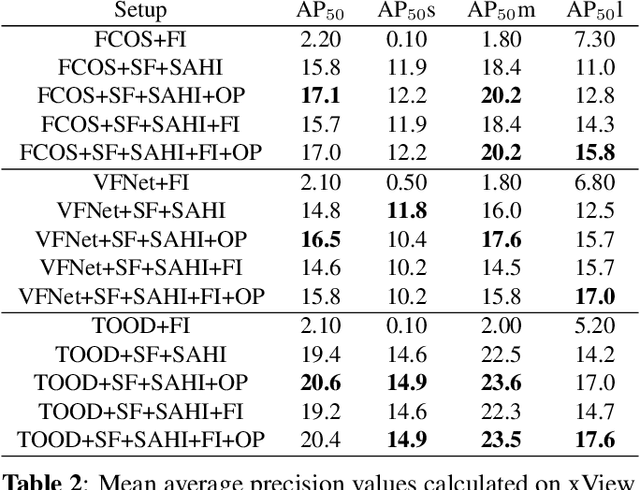
Detection of small objects and objects far away in the scene is a major challenge in surveillance applications. Such objects are represented by small number of pixels in the image and lack sufficient details, making them difficult to detect using conventional detectors. In this work, an open-source framework called Slicing Aided Hyper Inference (SAHI) is proposed that provides a generic slicing aided inference and fine-tuning pipeline for small object detection. The proposed technique is generic in the sense that it can be applied on top of any available object detector without any fine-tuning. Experimental evaluations, using object detection baselines on the Visdrone and xView aerial object detection datasets show that the proposed inference method can increase object detection AP by 6.8%, 5.1% and 5.3% for FCOS, VFNet and TOOD detectors, respectively. Moreover, the detection accuracy can be further increased with a slicing aided fine-tuning, resulting in a cumulative increase of 12.7%, 13.4% and 14.5% AP in the same order. Proposed technique has been integrated with Detectron2, MMDetection and YOLOv5 models and it is publicly available at https://github.com/obss/sahi.git .