 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LF-VIO: A Visual-Inertial-Odometry Framework for Large Field-of-View Cameras with Negative Plane
Feb 25, 2022
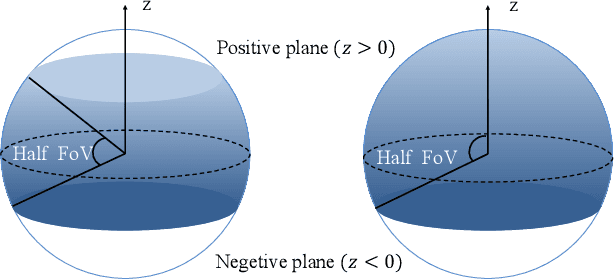
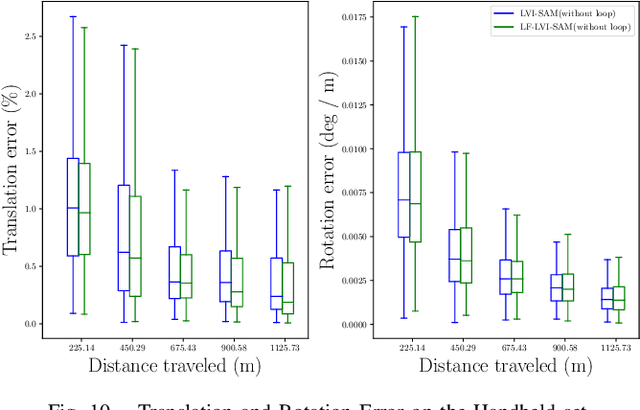
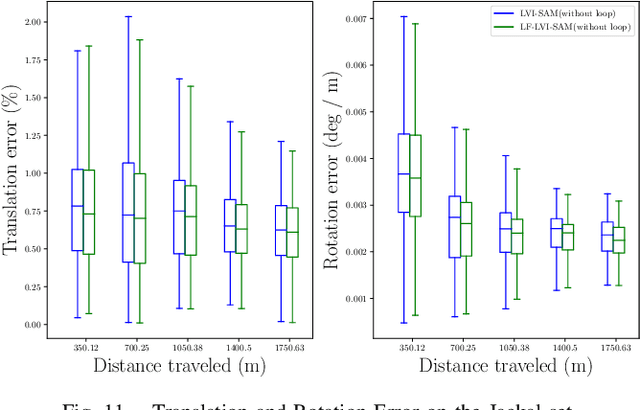

Visual-inertial-odometry has attracted extensive attention in the field of autonomous driving and robotics. The size of Field of View (FoV) plays an important role in Visual-Odometry (VO) and Visual-Inertial-Odometry (VIO), as a large FoV enables to perceive a wide range of surrounding scene elements and features. However, when the field of the camera reaches the negative half plane, one cannot simply use [u,v,1]^T to represent the image feature points anymore. To tackle this issue, we propose LF-VIO, a real-time VIO framework for cameras with extremely large FoV. We leverage a three-dimensional vector with unit length to represent feature points, and design a series of algorithms to overcome this challenge. To address the scarcity of panoramic visual odometry datasets with ground-truth location and pose, we present the PALVIO dataset, collected with a Panoramic Annular Lens (PAL) system with an entire FoV of 360x(40-120) degrees and an IMU sensor. With a comprehensive variety of experiments, the proposed LF-VIO is verified on both the established PALVIO benchmark and a public fisheye camera dataset with a FoV of 360x(0-93.5) degrees. LF-VIO outperforms state-of-the-art visual-inertial-odometry methods. Our dataset and code are made publicly available at https://github.com/flysoaryun/LF-VIO
DiffSDFSim: Differentiable Rigid-Body Dynamics With Implicit Shapes
Nov 30, 2021
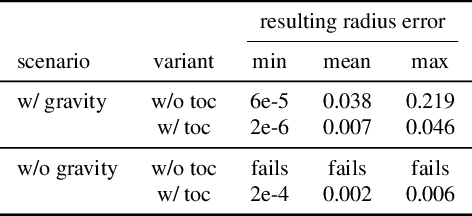
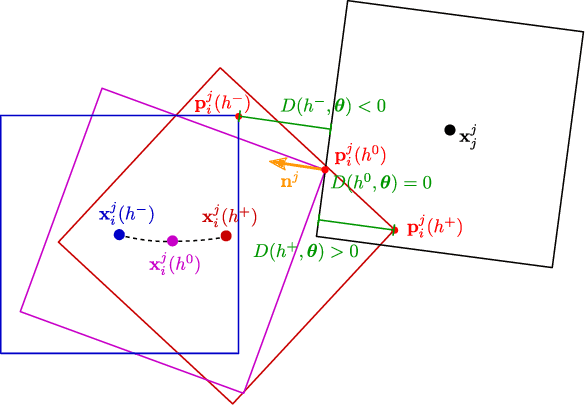
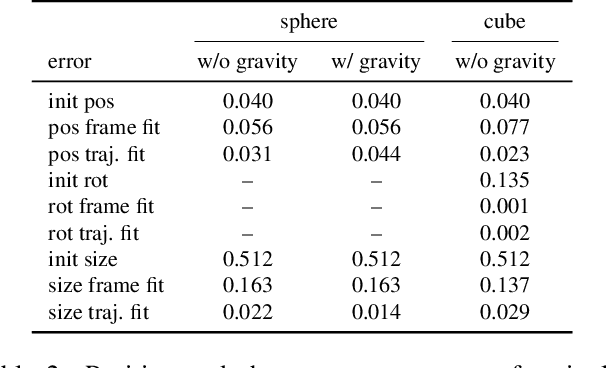
Differentiable physics is a powerful tool in computer vision and robotics for scene understanding and reasoning about interactions. Existing approaches have frequently been limited to objects with simple shape or shapes that are known in advance. In this paper, we propose a novel approach to differentiable physics with frictional contacts which represents object shapes implicitly using signed distance fields (SDFs). Our simulation supports contact point calculation even when the involved shapes are nonconvex. Moreover, we propose ways for differentiating the dynamics for the object shape to facilitate shape optimization using gradient-based methods. In our experiments, we demonstrate that our approach allows for model-based inference of physical parameters such as friction coefficients, mass, forces or shape parameters from trajectory and depth image observations in several challenging synthetic scenarios and a real image sequence.
Zero Experience Required: Plug & Play Modular Transfer Learning for Semantic Visual Navigation
Feb 05, 2022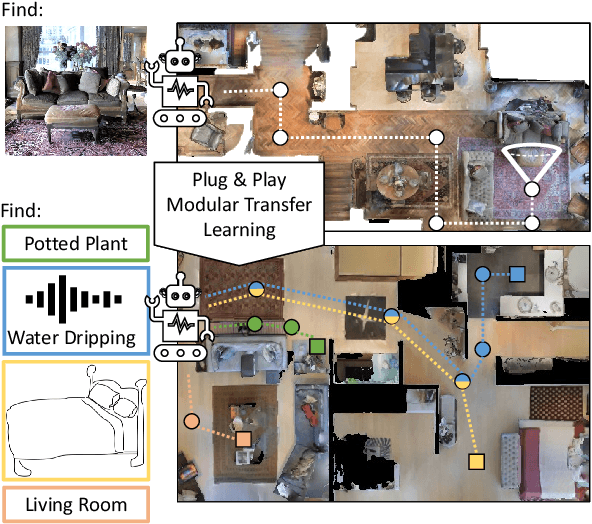
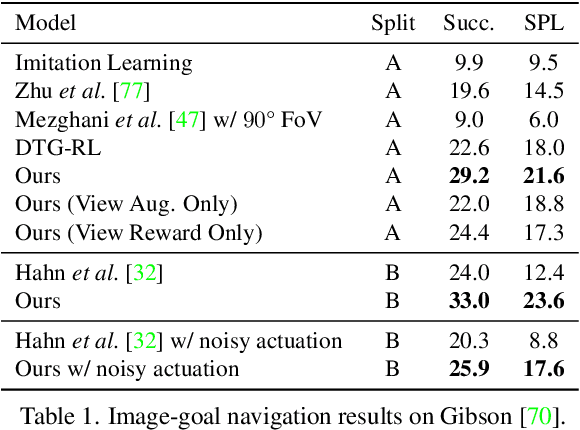
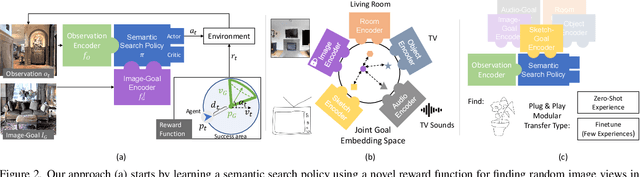
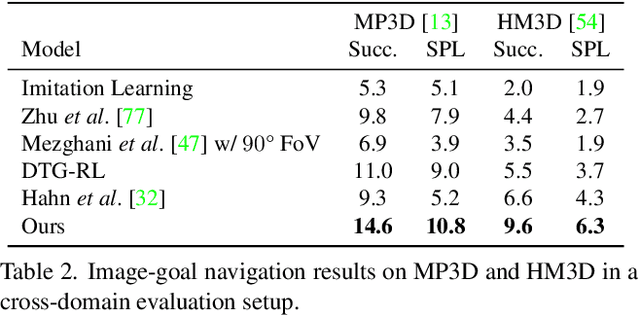
In reinforcement learning for visual navigation, it is common to develop a model for each new task, and train that model from scratch with task-specific interactions in 3D environments. However, this process is expensive; massive amounts of interactions are needed for the model to generalize well. Moreover, this process is repeated whenever there is a change in the task type or the goal modality. We present a unified approach to visual navigation using a novel modular transfer learning model. Our model can effectively leverage its experience from one source task and apply it to multiple target tasks (e.g., ObjectNav, RoomNav, ViewNav) with various goal modalities (e.g., image, sketch, audio, label). Furthermore, our model enables zero-shot experience learning, whereby it can solve the target tasks without receiving any task-specific interactive training. Our experiments on multiple photorealistic datasets and challenging tasks show that our approach learns faster, generalizes better, and outperforms SoTA models by a significant margin.
Local Feature Matching with Transformers for low-end devices
Feb 01, 2022LoFTR arXiv:2104.00680 is an efficient deep learning method for finding appropriate local feature matches on image pairs. This paper reports on the optimization of this method to work on devices with low computational performance and limited memory. The original LoFTR approach is based on a ResNet arXiv:1512.03385 head and two modules based on Linear Transformer arXiv:2006.04768 architecture. In the presented work, only the coarse-matching block was left, the number of parameters was significantly reduced, and the network was trained using a knowledge distillation technique. The comparison showed that this approach allows to obtain an appropriate feature detection accuracy for the student model compared to the teacher model in the coarse matching block, despite the significant reduction of model size. Also, the paper shows additional steps required to make model compatible with NVIDIA TensorRT runtime, and shows an approach to optimize training method for low-end GPUs.
Semi-Supervised Image-to-Image Translation
Jan 24, 2019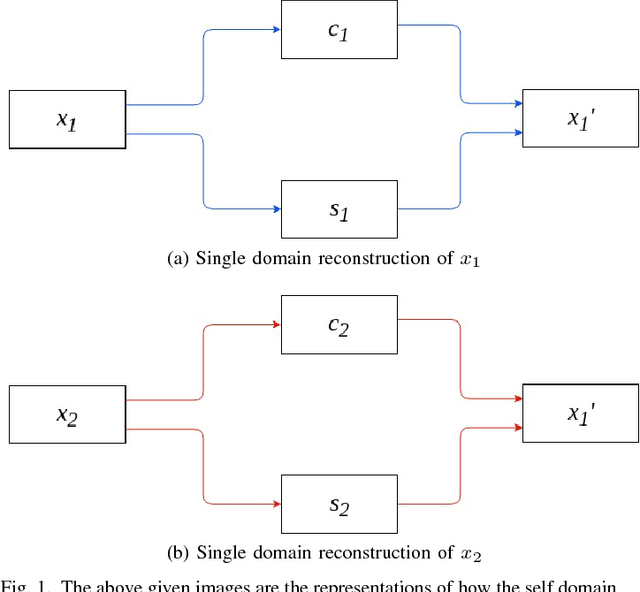
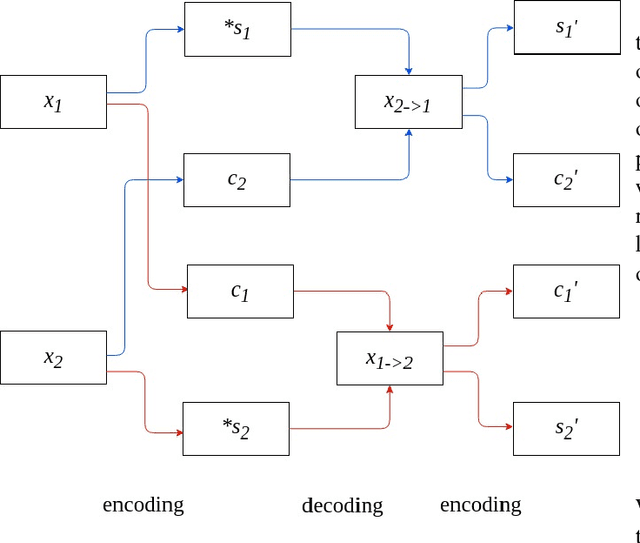
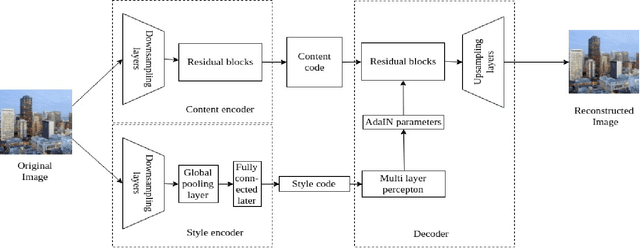

Image-to-image translation is a long-established and a difficult problem in computer vision. In this paper we propose an adversarial based model for image-to-image translation. The regular deep neural-network based methods perform the task of image-to-image translation by comparing gram matrices and using image segmentation which requires human intervention. Our generative adversarial network based model works on a conditional probability approach. This approach makes the image translation independent of any local, global and content or style features. In our approach we use a bidirectional reconstruction model appended with the affine transform factor that helps in conserving the content and photorealism as compared to other models. The advantage of using such an approach is that the image-to-image translation is semi-supervised, independant of image segmentation and inherits the properties of generative adversarial networks tending to produce realistic. This method has proven to produce better results than Multimodal Unsupervised Image-to-image translation.
Comparative Fault Location Estimation by Using Image Processing in Mixed Transmission Lines
Feb 22, 2021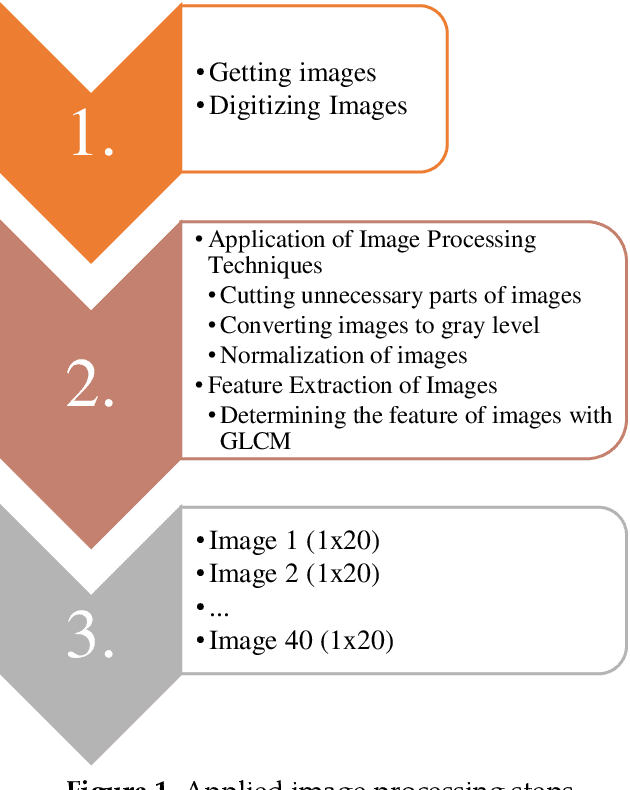
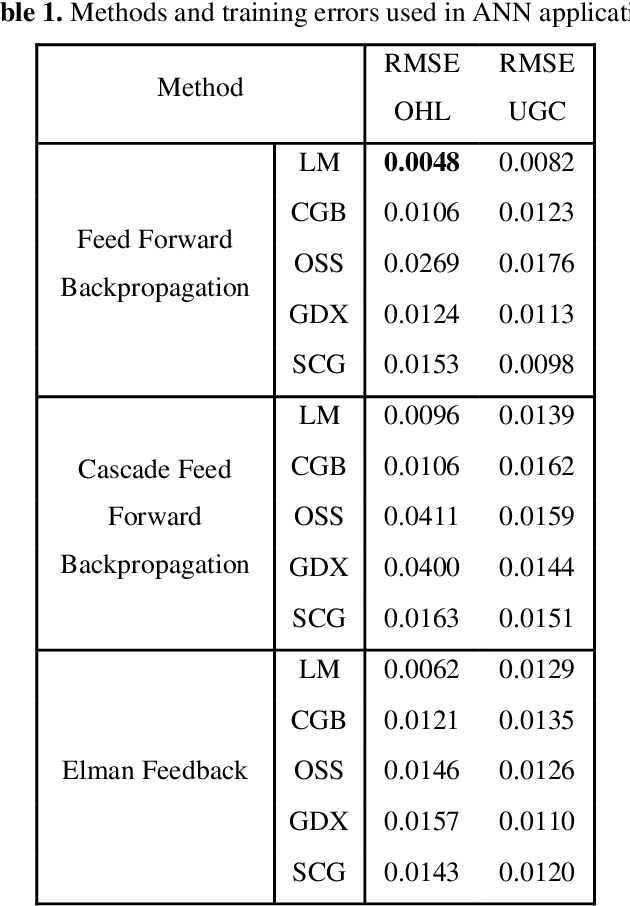
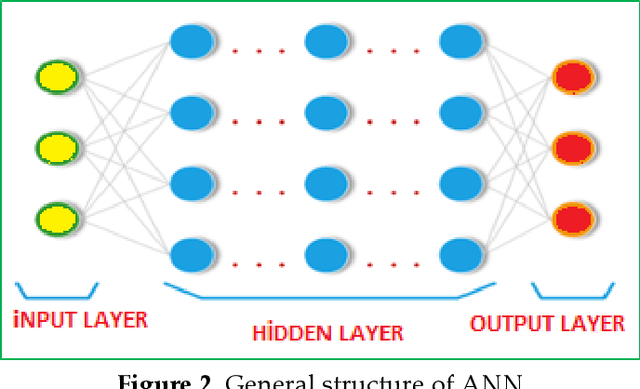
The distance protection relays are used to determine the impedance based fault location according to the current and voltage magnitudes in the transmission lines. However, the fault location cannot be correctly detected in mixed transmission lines due to different characteristic impedance per unit length because the characteristic impedance of high voltage cable line is significantly different from overhead line. Thus, determinations of the fault section and location with the distance protection relays are difficult in the mixed transmission lines. In this study, 154 kV overhead transmission line and underground cable line are examined as the mixed transmission line for the distance protection relays. Phase to ground faults are created in the mixed transmission line. overhead line section and underground cable section are simulated by using PSCAD-EMTDC.The short circuit fault images are generated in the distance protection relay for the overhead transmission line and underground cable transmission line faults. The images include the R-X impedance diagram of the fault, and the R-X impedance diagram have been detected by applying image processing steps. Artificial neural network (ANN) and the regression methods are used for prediction of the fault location, and the results of image processing are used as the input parameters for the training process of ANN and the regression methods. The results of ANN and regression methods are compared to select the most suitable method at the end of this study for forecasting of the fault location in transmission lines.
* arXiv admin note: substantial text overlap with arXiv:2011.03238
A Comparison of Multi-View Learning Strategies for Satellite Image-Based Real Estate Appraisal
May 11, 2021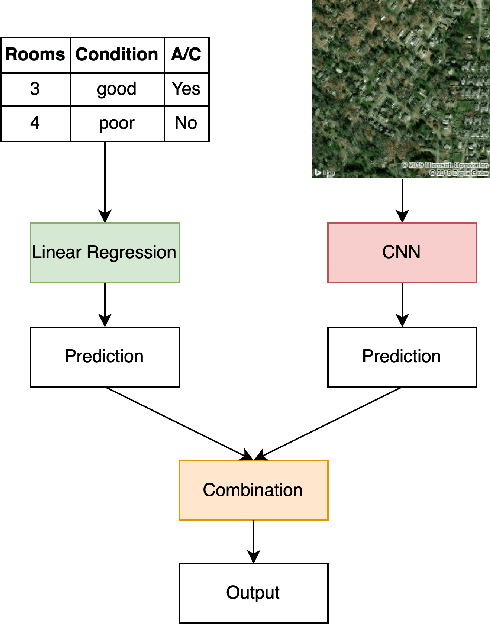
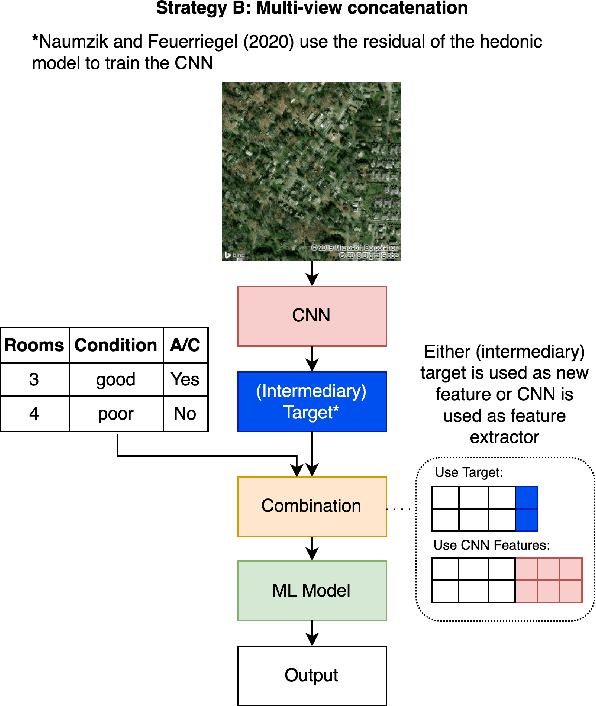

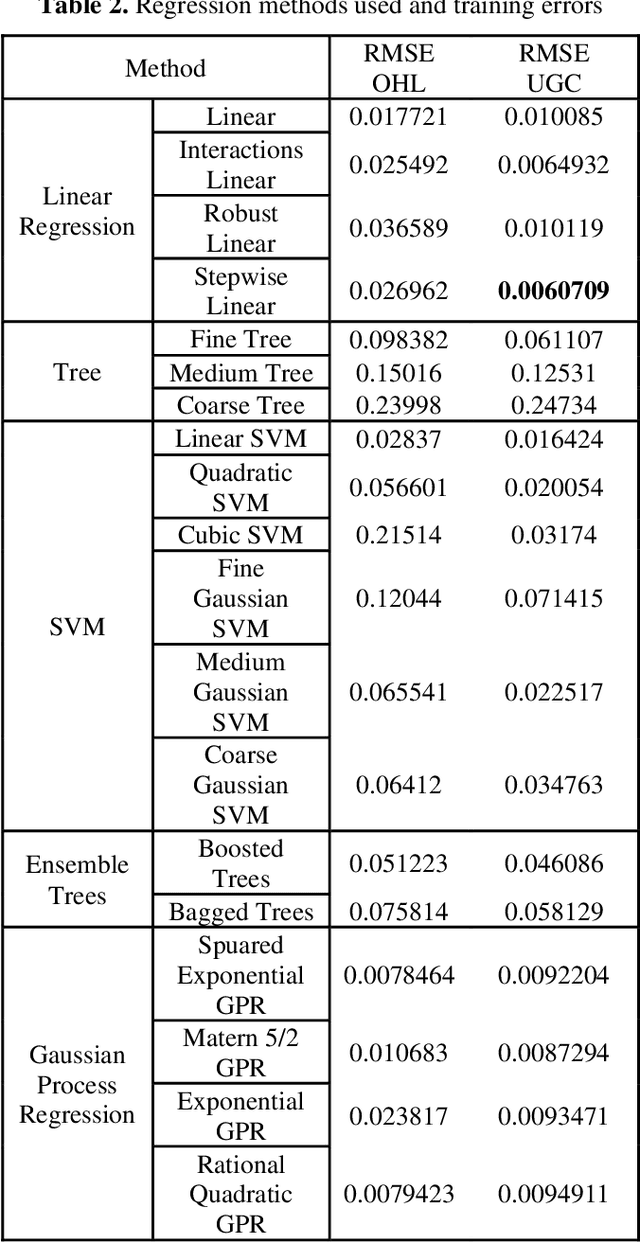
In the house credit process, banks and lenders rely on a fast and accurate estimation of a real estate price to determine the maximum loan value. Real estate appraisal is often based on relational data, capturing the hard facts of the property. Yet, models benefit strongly from including image data, capturing additional soft factors. The combination of the different data types requires a multi-view learning method. Therefore, the question arises which strengths and weaknesses different multi-view learning strategies have. In our study, we test multi-kernel learning, multi-view concatenation and multi-view neural networks on real estate data and satellite images from Asheville, NC. Our results suggest that multi-view learning increases the predictive performance up to 13% in MAE. Multi-view neural networks perform best, however result in intransparent black-box models. For users seeking interpretability, hybrid multi-view neural networks or a boosting strategy are a suitable alternative.
Hierarchical Cross-Modality Semantic Correlation Learning Model for Multimodal Summarization
Dec 16, 2021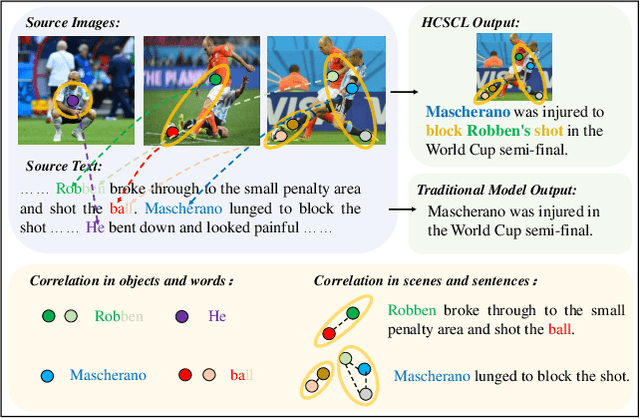

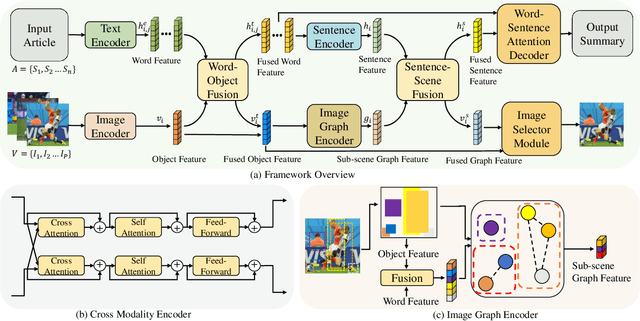
Multimodal summarization with multimodal output (MSMO) generates a summary with both textual and visual content. Multimodal news report contains heterogeneous contents, which makes MSMO nontrivial. Moreover, it is observed that different modalities of data in the news report correlate hierarchically. Traditional MSMO methods indistinguishably handle different modalities of data by learning a representation for the whole data, which is not directly adaptable to the heterogeneous contents and hierarchical correlation. In this paper, we propose a hierarchical cross-modality semantic correlation learning model (HCSCL) to learn the intra- and inter-modal correlation existing in the multimodal data. HCSCL adopts a graph network to encode the intra-modal correlation. Then, a hierarchical fusion framework is proposed to learn the hierarchical correlation between text and images. Furthermore, we construct a new dataset with relevant image annotation and image object label information to provide the supervision information for the learning procedure. Extensive experiments on the dataset show that HCSCL significantly outperforms the baseline methods in automatic summarization metrics and fine-grained diversity tests.
Image Denoising for Strong Gaussian Noises With Specialized CNNs for Different Frequency Components
Nov 26, 2020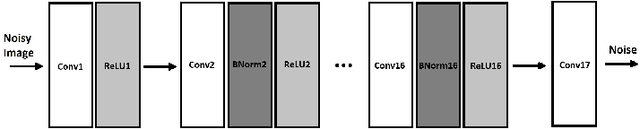
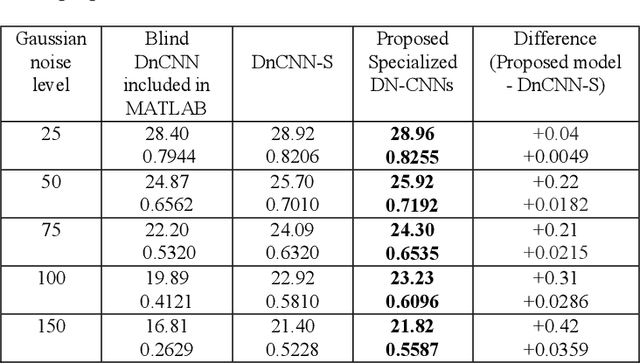
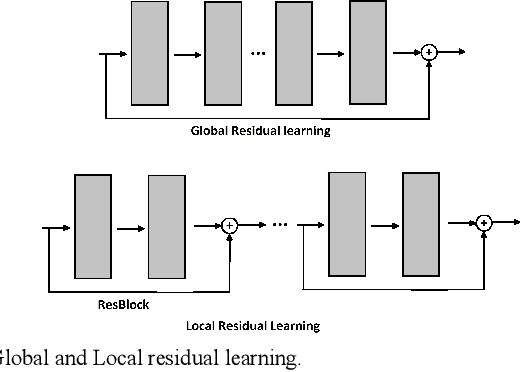
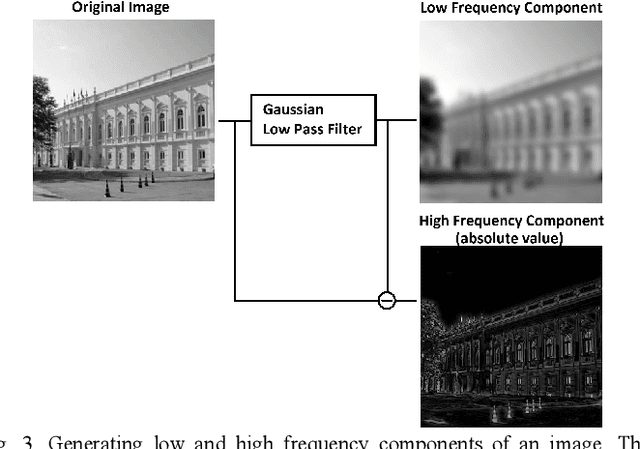
In machine learning approach to image denoising a network is trained to recover a clean image from a noisy one. In this paper a novel structure is proposed based on training multiple specialized networks as opposed to existing structures that are base on a single network. The proposed model is an alternative for training a very deep network to avoid issues like vanishing or exploding gradient. By dividing a very deep network into two smaller networks the same number of learnable parameters will be available, but two smaller networks should be trained which are easier to train. Over smoothing and waxy artifacts are major problems with existing methods; because the network tries to keep the Mean Square Error (MSE) low for general structures and details, which leads to overlooking of details. This problem is more severe in the presence of strong noise. To reduce this problem, in the proposed structure, the image is decomposed into its low and high frequency components and each component is used to train a separate denoising convolutional neural network. One network is specialized to reconstruct the general structure of the image and the other one is specialized to reconstruct the details. Results of the proposed method show higher peak signal to noise ratio (PSNR), and structural similarity index (SSIM) compared to a popular state of the art denoising method in the presence of strong noises.
A Shift-insensitive Full Reference Image Quality Assessment Model Based on Quadratic Sum of Gradient Magnitude and LOG signals
Dec 21, 2020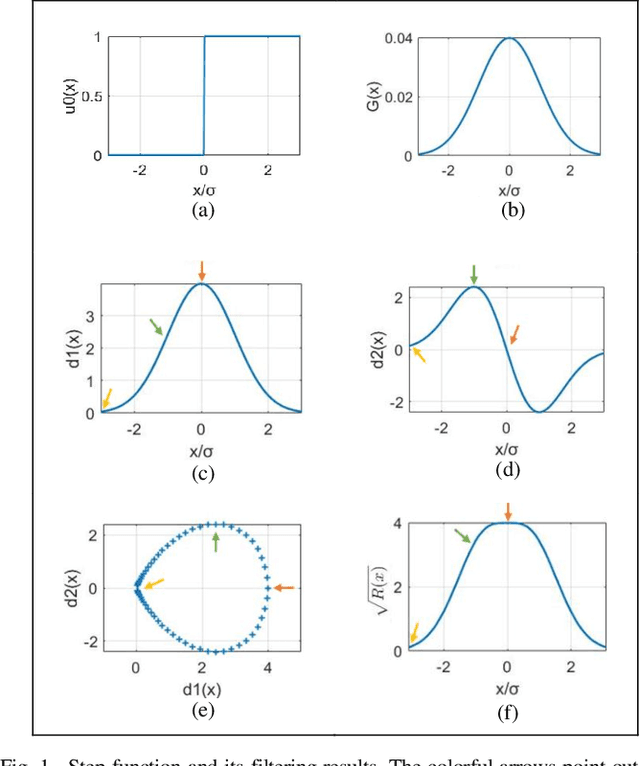
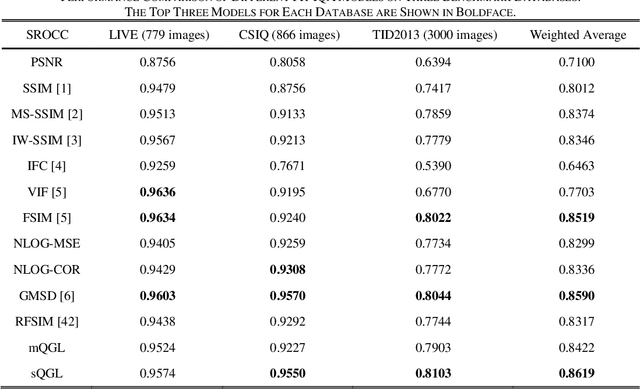

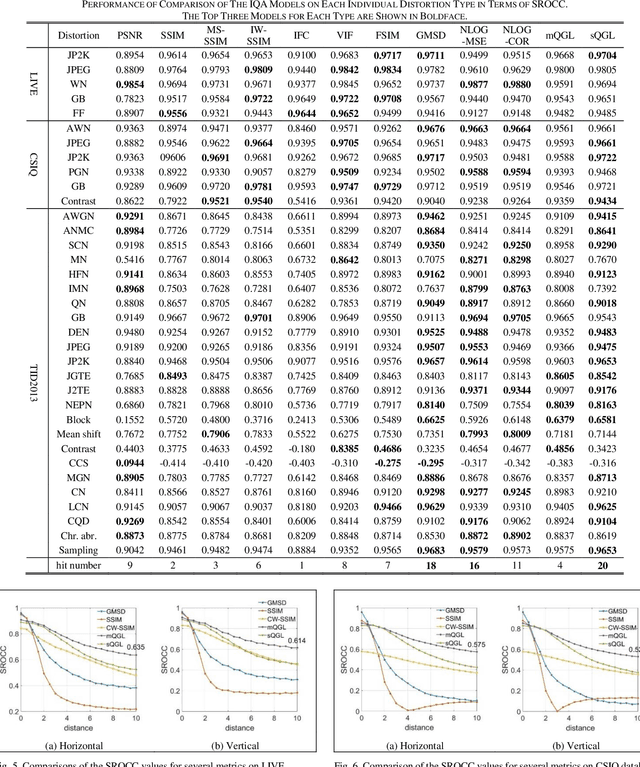
Image quality assessment that aims at estimating the subject quality of images, builds models to evaluate the perceptual quality of the image in different applications. Based on the fact that the human visual system (HVS) is highly sensitive to structural information, the edge information extraction is widely applied in different IQA metrics. According to previous studies, the image gradient magnitude (GM) and the Laplacian of Gaussian (LOG) operator are two efficient structural features in IQA tasks. However, most of the IQA metrics achieve good performance only when the distorted image is totally registered with the reference image, but fail to perform on images with small translations. In this paper, we propose an FR-IQA model with the quadratic sum of the GM and the LOG signals, which obtains good performance in image quality estimation considering shift-insensitive property for not well-registered reference and distortion image pairs. Experimental results show that the proposed model works robustly on three large scale subjective IQA databases which contain a variety of distortion types and levels, and stays in the state-of-the-art FR-IQA models no matter for single distortion type or across whole database. Furthermore, we validated that the proposed metric performs better with shift-insensitive property compared with the CW-SSIM metric that is considered to be shift-insensitive IQA so far. Meanwhile, the proposed model is much simple than the CW-SSIM, which is efficient for applications.