 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Latent Outlier Exposure for Anomaly Detection with Contaminated Data
Feb 16, 2022
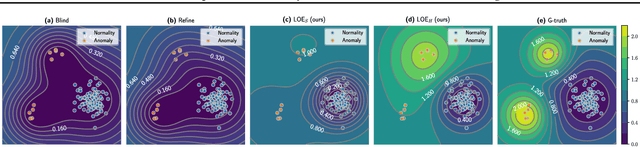
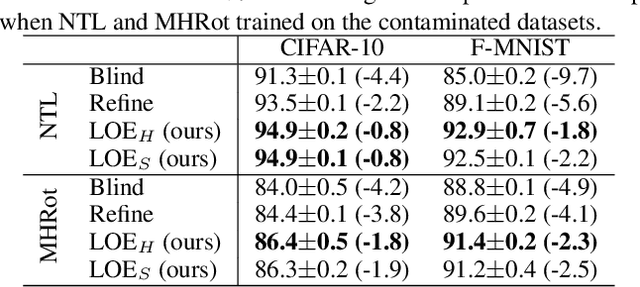
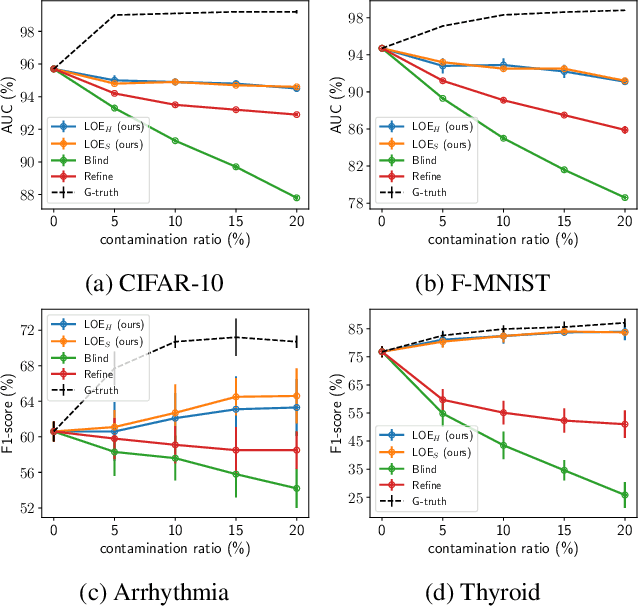
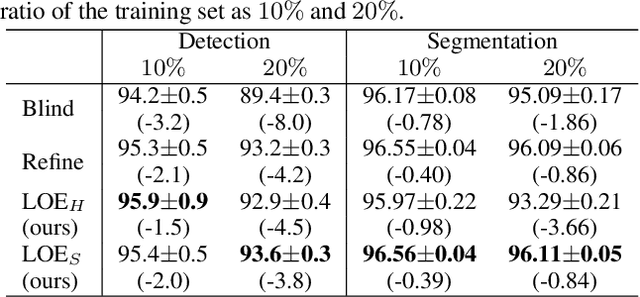
Anomaly detection aims at identifying data points that show systematic deviations from the majority of data in an unlabeled dataset. A common assumption is that clean training data (free of anomalies) is available, which is often violated in practice. We propose a strategy for training an anomaly detector in the presence of unlabeled anomalies that is compatible with a broad class of models. The idea is to jointly infer binary labels to each datum (normal vs. anomalous) while updating the model parameters. Inspired by outlier exposure (Hendrycks et al., 2018) that considers synthetically created, labeled anomalies, we thereby use a combination of two losses that share parameters: one for the normal and one for the anomalous data. We then iteratively proceed with block coordinate updates on the parameters and the most likely (latent) labels. Our experiments with several backbone models on three image datasets, 30 tabular data sets, and a video anomaly detection benchmark showed consistent and significant improvements over the baselines.
Improving Text to Image Generation using Mode-seeking Function
Sep 02, 2020
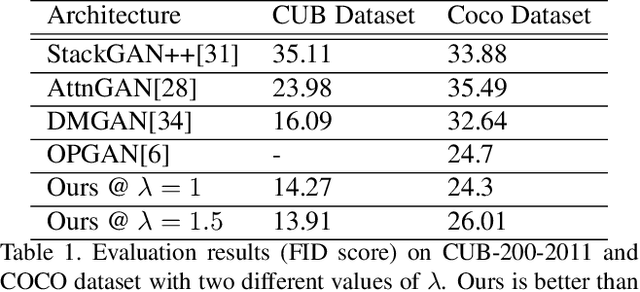


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.
A Polyhedral Study of Lifted Multicuts
Feb 16, 2022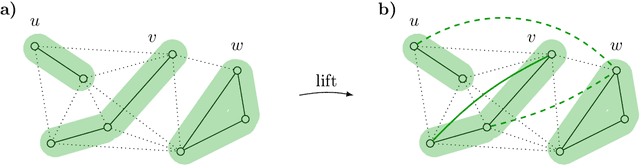
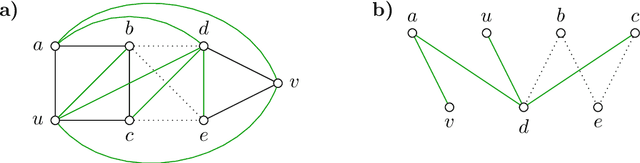
Fundamental to many applications in data analysis are the decompositions of a graph, i.e. partitions of the node set into component-inducing subsets. One way of encoding decompositions is by multicuts, the subsets of those edges that straddle distinct components. Recently, a lifting of multicuts from a graph $G = (V, E)$ to an augmented graph $\hat G = (V, E \cup F)$ has been proposed in the field of image analysis, with the goal of obtaining a more expressive characterization of graph decompositions in which it is made explicit also for pairs $F \subseteq \tbinom{V}{2} \setminus E$ of non-neighboring nodes whether these are in the same or distinct components. In this work, we study in detail the polytope in $\mathbb{R}^{E \cup F}$ whose vertices are precisely the characteristic vectors of multicuts of $\hat G$ lifted from $G$, connecting it, in particular, to the rich body of prior work on the clique partitioning and multilinear polytope.
Deep Image Spatial Transformation for Person Image Generation
Mar 18, 2020
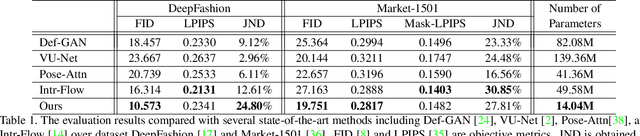
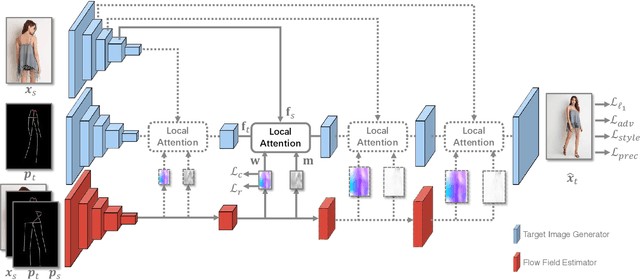

Pose-guided person image generation is to transform a source person image to a target pose. This task requires spatial manipulations of source data. However, Convolutional Neural Networks are limited by the lack of ability to spatially transform the inputs. In this paper, we propose a differentiable global-flow local-attention framework to reassemble the inputs at the feature level. Specifically, our model first calculates the global correlations between sources and targets to predict flow fields. Then, the flowed local patch pairs are extracted from the feature maps to calculate the local attention coefficients. Finally, we warp the source features using a content-aware sampling method with the obtained local attention coefficients. The results of both subjective and objective experiments demonstrate the superiority of our model. Besides, additional results in video animation and view synthesis show that our model is applicable to other tasks requiring spatial transformation. Our source code is available at https://github.com/RenYurui/Global-Flow-Local-Attention.
V-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network
Jan 02, 2022
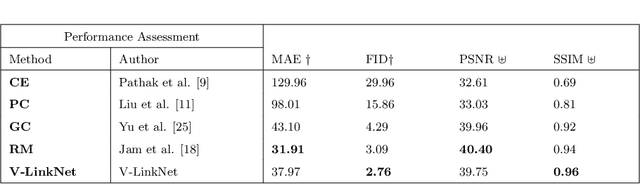

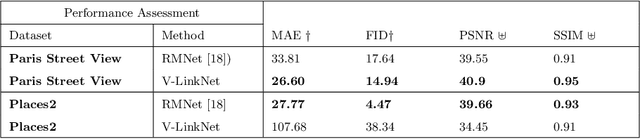
Deep learning methods outperform traditional methods in image inpainting. In order to generate contextual textures, researchers are still working to improve on existing methods and propose models that can extract, propagate, and reconstruct features similar to ground-truth regions. Furthermore, the lack of a high-quality feature transfer mechanism in deeper layers contributes to persistent aberrations on generated inpainted regions. To address these limitations, we propose the V-LinkNet cross-space learning strategy network. To improve learning on contextualised features, we design a loss model that employs both encoders. In addition, we propose a recursive residual transition layer (RSTL). The RSTL extracts high-level semantic information and propagates it down layers. Finally, we compare inpainting performance on the same face with different masks and on different faces with the same masks. To improve image inpainting reproducibility, we propose a standard protocol to overcome biases with various masks and images. We investigate the V-LinkNet components using experimental methods. Our result surpasses the state of the art when evaluated on the CelebA-HQ with the standard protocol. In addition, our model can generalise well when evaluated on Paris Street View, and Places2 datasets with the standard protocol.
Neural Graphics Pipeline for Controllable Image Generation
Jun 18, 2020

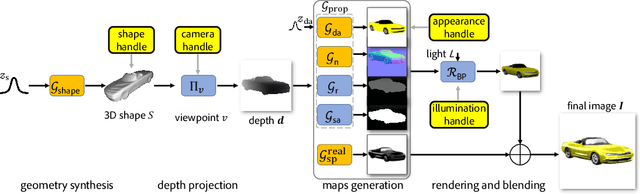
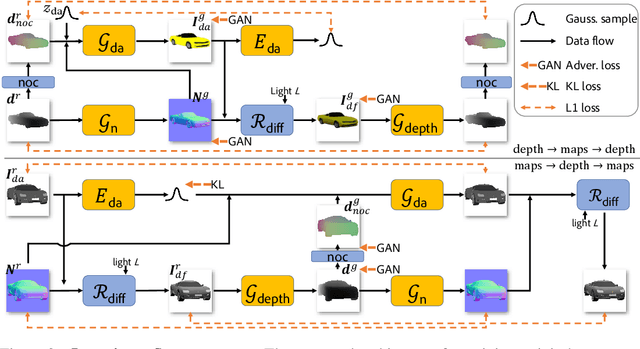
We present Neural Graphics Pipeline (NGP), a hybrid generative model that brings together neural and traditional image formation models. NGP generates coarse 3D models that are fed into neural rendering modules to produce view-specific interpretable 2D maps, which are then composited into the final output image using a traditional image formation model. Our approach offers control over image generation by providing direct handles controlling illumination and camera parameters, in addition to control over shape and appearance variations. The key challenge is to learn these controls through unsupervised training that links generated coarse 3D models with unpaired real images via neural and traditional (e.g., Blinn-Phong) rendering functions without establishing an explicit correspondence between them. We evaluate our hybrid modeling framework, compare with neural-only generation methods (namely, DCGAN, LSGAN, WGAN-GP, VON, and SRNs), report improvement in FID scores against real images, and demonstrate that NGP supports direct controls common in traditional forward rendering. Code, data, and trained models will be released on acceptance.
Automatic Radish Wilt Detection Using Image Processing Based Techniques and Machine Learning Algorithm
Sep 01, 2020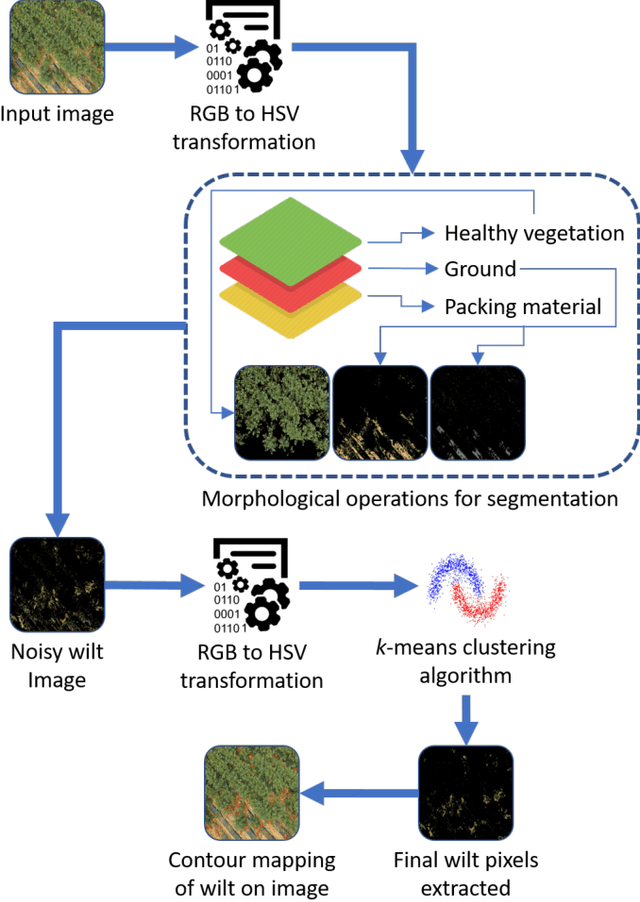
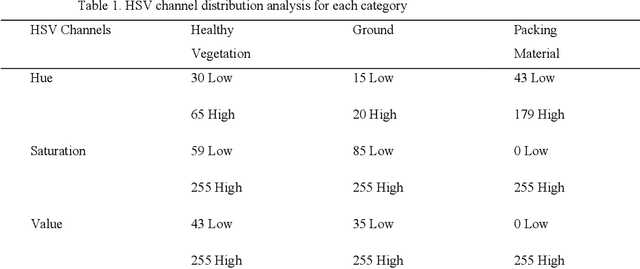

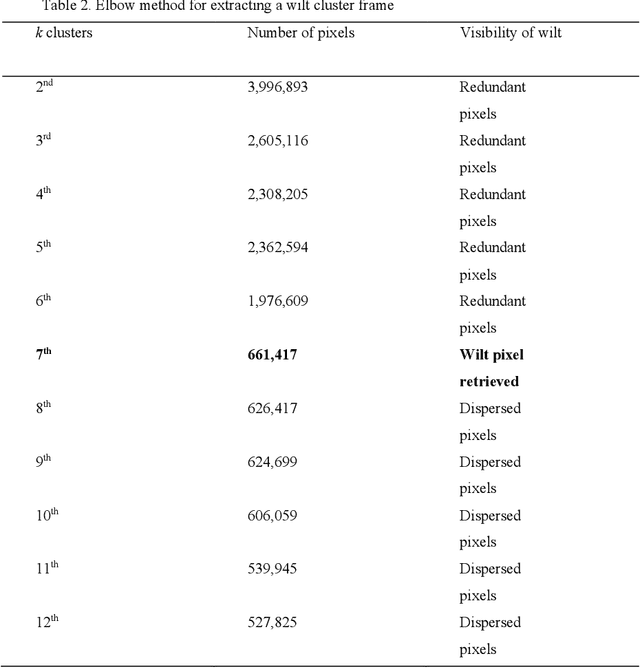
Image processing, computer vision, and pattern recognition have been playing a vital role in diverse agricultural applications, such as species detection, recognition, classification, identification, plant growth stages, plant disease detection, and many more. On the other hand, there is a growing need to capture high resolution images using unmanned aerial vehicles (UAV) and to develop better algorithms in order to find highly accurate and to the point results. In this paper, we propose a segmentation and extraction-based technique to detect fusarium wilt in radish crops. Recent wilt detection algorithms are either based on image processing techniques or conventional machine learning algorithms. However, our methodology is based on a hybrid algorithm, which combines image processing and machine learning. First, the crop image is divided into three segments, which include viz., healthy vegetation, ground and packing material. Based on the HSV decision tree algorithm, all the three segments are segregated from the image. Second, the extracted segments are summed together into an empty canvas of the same resolution as the image and one new image is produced. Third, this new image is compared with the original image, and a final noisy image, which contains traces of wilt is extracted. Finally, a k-means algorithm is applied to eliminate the noise and to extract the accurate wilt from it. Moreover, the extracted wilt is mapped on the original image using the contouring method. The proposed combination of algorithms detects the wilt appropriately, which surpasses the traditional practice of separately using the image processing techniques or machine learning.
HDNet: High-resolution Dual-domain Learning for Spectral Compressive Imaging
Mar 04, 2022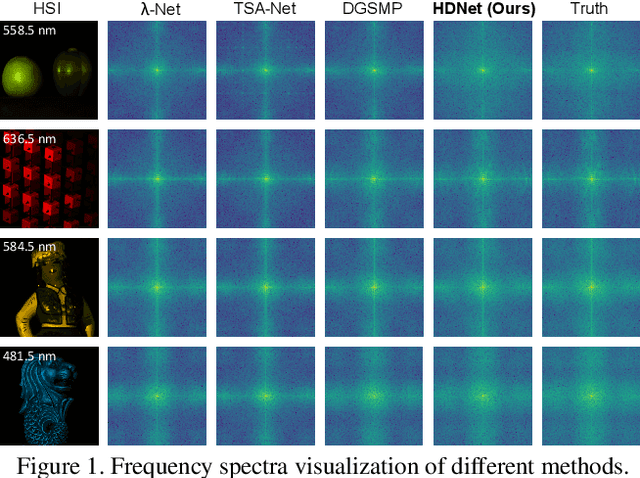
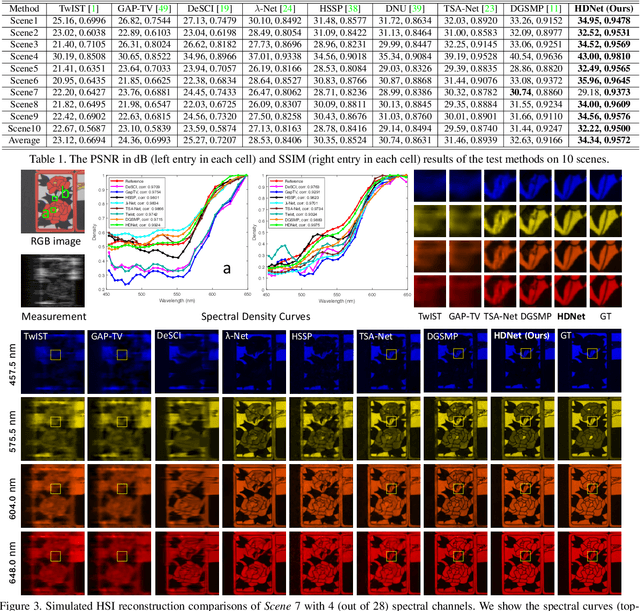
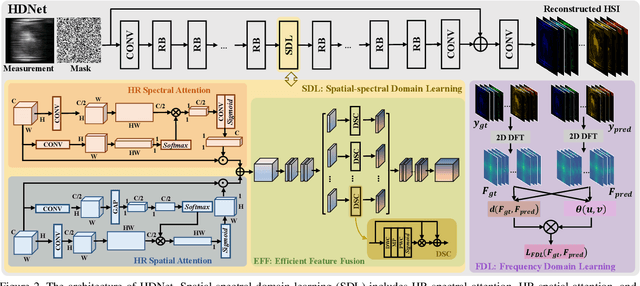

The rapid development of deep learning provides a better solution for the end-to-end reconstruction of hyperspectral image (HSI). However, existing learning-based methods have two major defects. Firstly, networks with self-attention usually sacrifice internal resolution to balance model performance against complexity, losing fine-grained high-resolution (HR) features. Secondly, even if the optimization focusing on spatial-spectral domain learning (SDL) converges to the ideal solution, there is still a significant visual difference between the reconstructed HSI and the truth. Therefore, we propose a high-resolution dual-domain learning network (HDNet) for HSI reconstruction. On the one hand, the proposed HR spatial-spectral attention module with its efficient feature fusion provides continuous and fine pixel-level features. On the other hand, frequency domain learning (FDL) is introduced for HSI reconstruction to narrow the frequency domain discrepancy. Dynamic FDL supervision forces the model to reconstruct fine-grained frequencies and compensate for excessive smoothing and distortion caused by pixel-level losses. The HR pixel-level attention and frequency-level refinement in our HDNet mutually promote HSI perceptual quality. Extensive quantitative and qualitative evaluation experiments show that our method achieves SOTA performance on simulated and real HSI datasets. Code and models will be released.
Retaining Image Feature Matching Performance Under Low Light Conditions
Sep 02, 2020
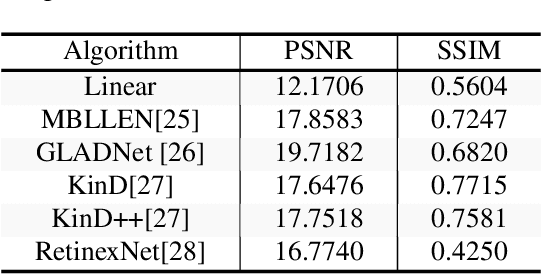

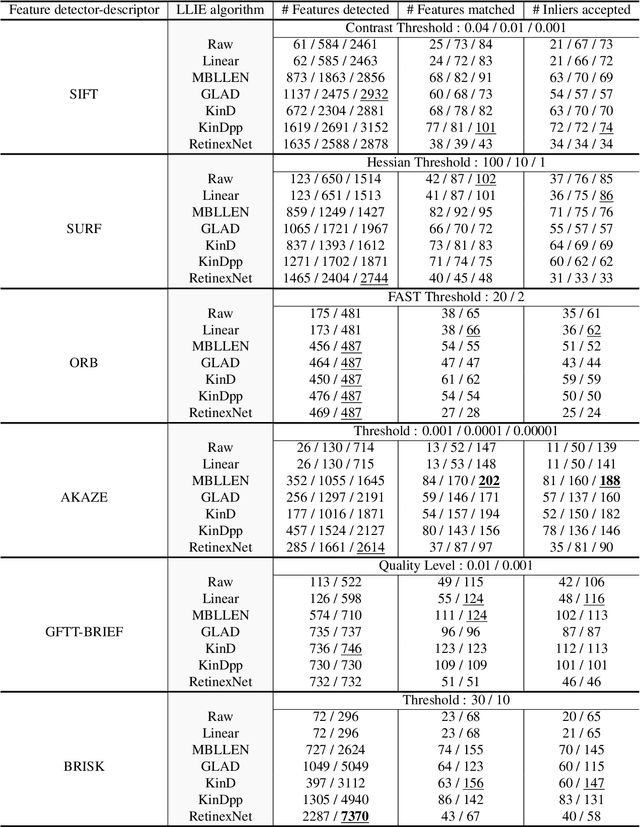
Poor image quality in low light images may result in a reduced number of feature matching between images. In this paper, we investigate the performance of feature extraction algorithms in low light environments. To find an optimal setting to retain feature matching performance in low light images, we look into the effect of changing feature acceptance threshold for feature detector and adding pre-processing in the form of Low Light Image Enhancement (LLIE) prior to feature detection. We observe that even in low light images, feature matching using traditional hand-crafted feature detectors still performs reasonably well by lowering the threshold parameter. We also show that applying Low Light Image Enhancement (LLIE) algorithms can improve feature matching even more when paired with the right feature extraction algorithm.
Transferable End-to-end Room Layout Estimation via Implicit Encoding
Dec 21, 2021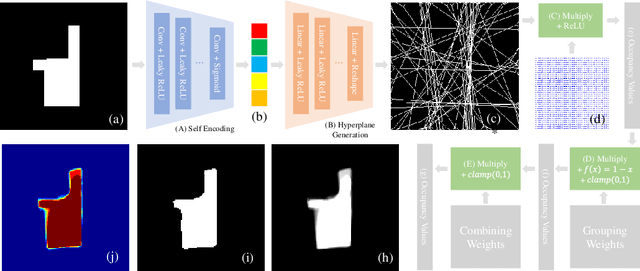

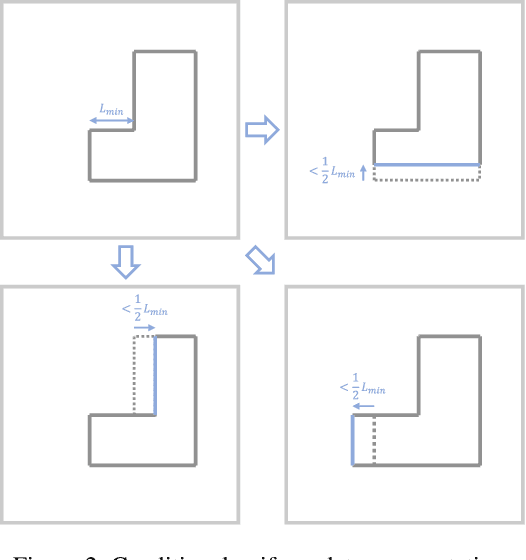
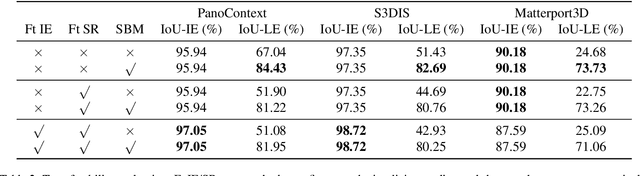
We study the problem of estimating room layouts from a single panorama image. Most former works have two stages: feature extraction and parametric model fitting. Here we propose an end-to-end method that directly predicts parametric layouts from an input panorama image. It exploits an implicit encoding procedure that embeds parametric layouts into a latent space. Then learning a mapping from images to this latent space makes end-to-end room layout estimation possible. However end-to-end methods have several notorious drawbacks despite many intriguing properties. A widely raised criticism is that they are troubled with dataset bias and do not transfer to unfamiliar domains. Our study echos this common belief. To this end, we propose to use semantic boundary prediction maps as an intermediate domain. It brings significant performance boost on four benchmarks (Structured3D, PanoContext, S3DIS, and Matterport3D), notably in the zero-shot transfer setting. Code, data, and models will be released.