 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
i3dLoc: Image-to-range Cross-domain Localization Robust to Inconsistent Environmental Conditions
May 27, 2021
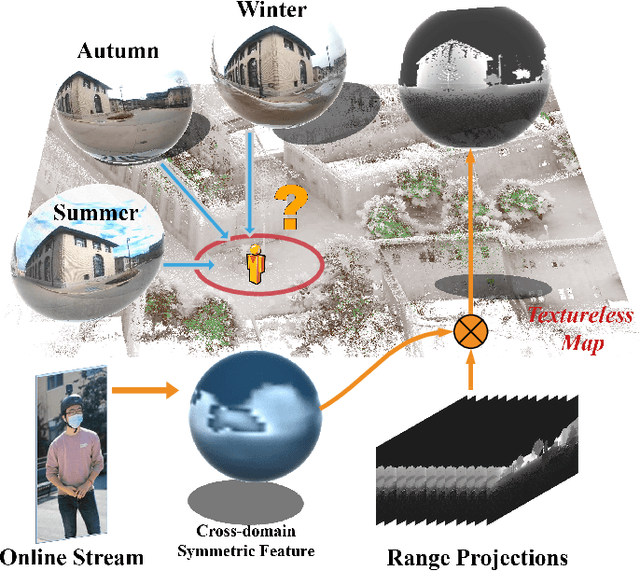
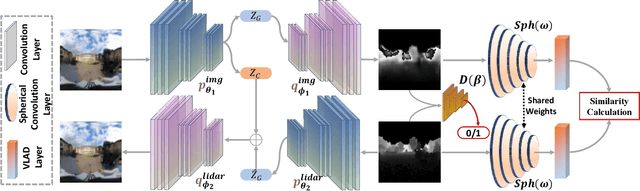
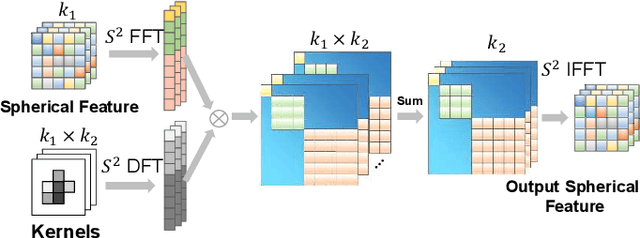
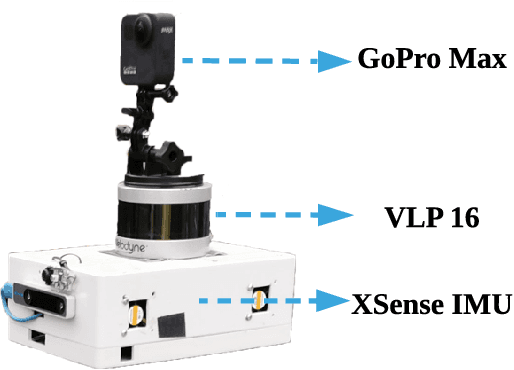
We present a method for localizing a single camera with respect to a point cloud map in indoor and outdoor scenes. The problem is challenging because correspondences of local invariant features are inconsistent across the domains between image and 3D. The problem is even more challenging as the method must handle various environmental conditions such as illumination, weather, and seasonal changes. Our method can match equirectangular images to the 3D range projections by extracting cross-domain symmetric place descriptors. Our key insight is to retain condition-invariant 3D geometry features from limited data samples while eliminating the condition-related features by a designed Generative Adversarial Network. Based on such features, we further design a spherical convolution network to learn viewpoint-invariant symmetric place descriptors. We evaluate our method on extensive self-collected datasets, which involve \textit{Long-term} (variant appearance conditions), \textit{Large-scale} (up to $2km$ structure/unstructured environment), and \textit{Multistory} (four-floor confined space). Our method surpasses other current state-of-the-arts by achieving around $3$ times higher place retrievals to inconsistent environments, and above $3$ times accuracy on online localization. To highlight our method's generalization capabilities, we also evaluate the recognition across different datasets. With a single trained model, i3dLoc can demonstrate reliable visual localization in random conditions.
Self-Supervised Representation Learning via Latent Graph Prediction
Feb 16, 2022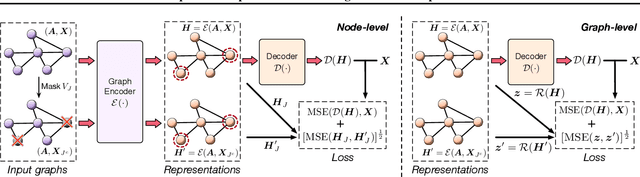
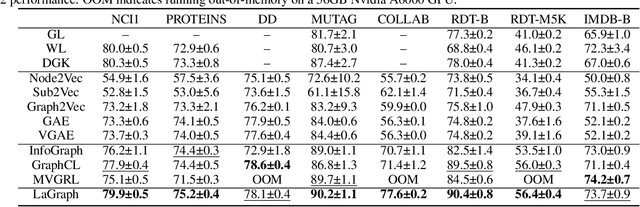
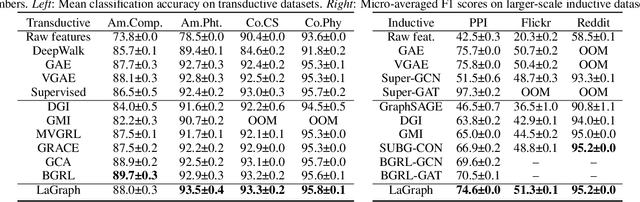
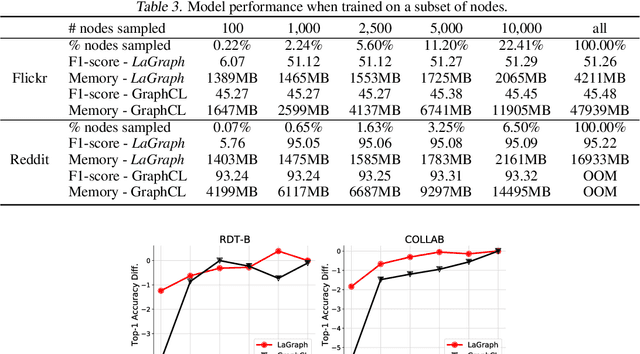
Self-supervised learning (SSL) of graph neural networks is emerging as a promising way of leveraging unlabeled data. Currently, most methods are based on contrastive learning adapted from the image domain, which requires view generation and a sufficient number of negative samples. In contrast, existing predictive models do not require negative sampling, but lack theoretical guidance on the design of pretext training tasks. In this work, we propose the LaGraph, a theoretically grounded predictive SSL framework based on latent graph prediction. Learning objectives of LaGraph are derived as self-supervised upper bounds to objectives for predicting unobserved latent graphs. In addition to its improved performance, LaGraph provides explanations for recent successes of predictive models that include invariance-based objectives. We provide theoretical analysis comparing LaGraph to related methods in different domains. Our experimental results demonstrate the superiority of LaGraph in performance and the robustness to decreasing of training sample size on both graph-level and node-level tasks.
End-to-End Segmentation via Patch-wise Polygons Prediction
Dec 05, 2021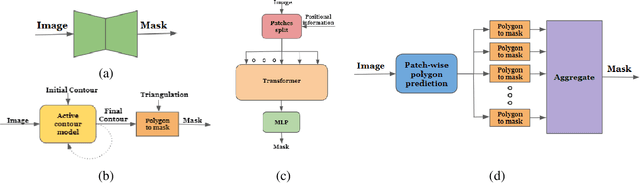
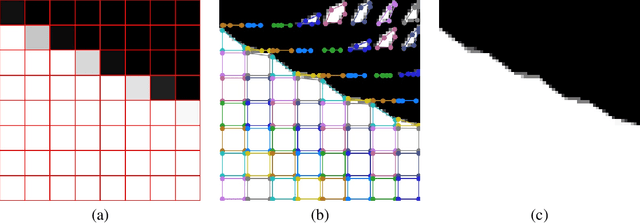
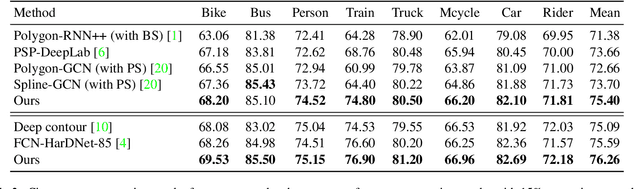
The leading segmentation methods represent the output map as a pixel grid. We study an alternative representation in which the object edges are modeled, per image patch, as a polygon with $k$ vertices that is coupled with per-patch label probabilities. The vertices are optimized by employing a differentiable neural renderer to create a raster image. The delineated region is then compared with the ground truth segmentation. Our method obtains multiple state-of-the-art results: 76.26\% mIoU on the Cityscapes validation, 90.92\% IoU on the Vaihingen building segmentation benchmark, 66.82\% IoU for the MoNU microscopy dataset, and 90.91\% for the bird benchmark CUB. Our code for training and reproducing these results is attached as supplementary.
All You Need is LUV: Unsupervised Collection of Labeled Images using Invisible UV Fluorescent Indicators
Mar 13, 2022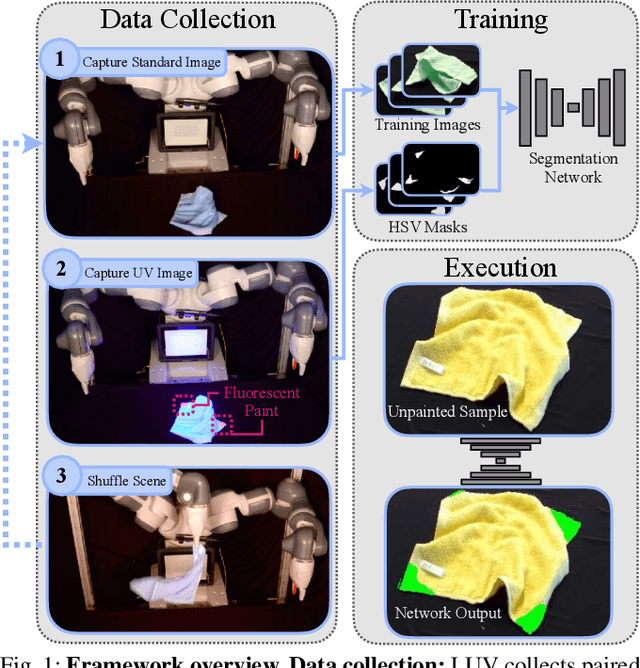



Large-scale semantic image annotation is a significant challenge for learning-based perception systems in robotics. Current approaches often rely on human labelers, which can be expensive, or simulation data, which can visually or physically differ from real data. This paper proposes Labels from UltraViolet (LUV), a novel framework that enables rapid, labeled data collection in real manipulation environments without human labeling. LUV uses transparent, ultraviolet-fluorescent paint with programmable ultraviolet LEDs to collect paired images of a scene in standard lighting and UV lighting to autonomously extract segmentation masks and keypoints via color segmentation. We apply LUV to a suite of diverse robot perception tasks to evaluate its labeling quality, flexibility, and data collection rate. Results suggest that LUV is 180-2500 times faster than a human labeler across the tasks. We show that LUV provides labels consistent with human annotations on unpainted test images. The networks trained on these labels are used to smooth and fold crumpled towels with 83% success rate and achieve 1.7mm position error with respect to human labels on a surgical needle pose estimation task. The low cost of LUV makes it ideal as a lightweight replacement for human labeling systems, with the one-time setup costs at $300 equivalent to the cost of collecting around 200 semantic segmentation labels on Amazon Mechanical Turk. Code, datasets, visualizations, and supplementary material can be found at https://sites.google.com/berkeley.edu/luv
Wasserstein Generative Learning of Conditional Distribution
Dec 19, 2021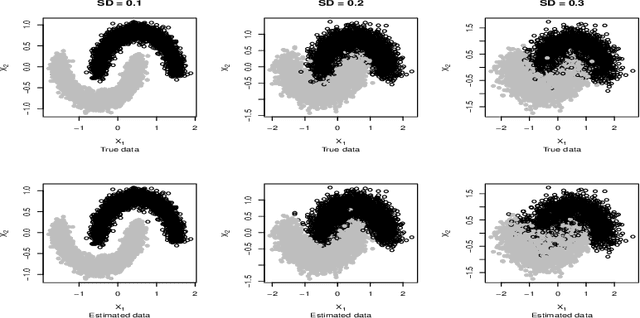
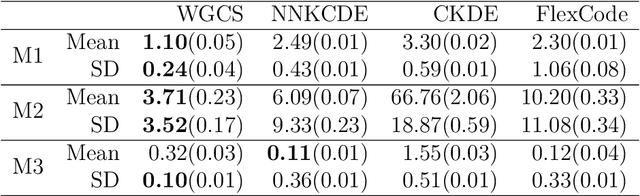
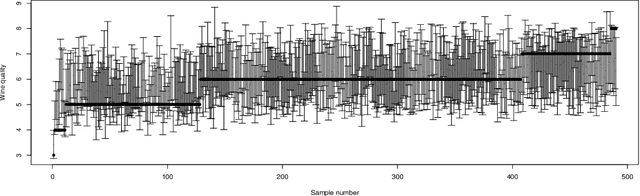
Conditional distribution is a fundamental quantity for describing the relationship between a response and a predictor. We propose a Wasserstein generative approach to learning a conditional distribution. The proposed approach uses a conditional generator to transform a known distribution to the target conditional distribution. The conditional generator is estimated by matching a joint distribution involving the conditional generator and the target joint distribution, using the Wasserstein distance as the discrepancy measure for these joint distributions. We establish non-asymptotic error bound of the conditional sampling distribution generated by the proposed method and show that it is able to mitigate the curse of dimensionality, assuming that the data distribution is supported on a lower-dimensional set. We conduct numerical experiments to validate proposed method and illustrate its applications to conditional sample generation, nonparametric conditional density estimation, prediction uncertainty quantification, bivariate response data, image reconstruction and image generation.
Self-Supervised Monocular Depth and Ego-Motion Estimation in Endoscopy: Appearance Flow to the Rescue
Dec 15, 2021
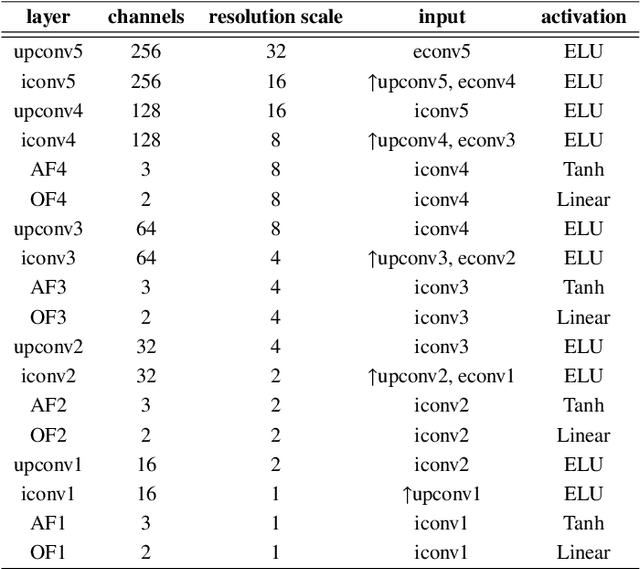
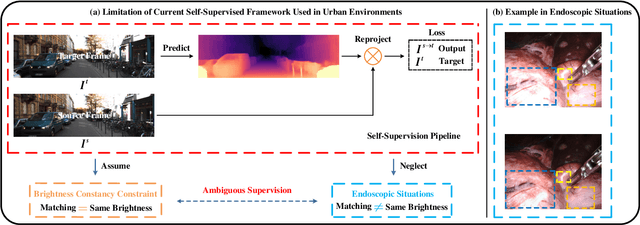

Recently, self-supervised learning technology has been applied to calculate depth and ego-motion from monocular videos, achieving remarkable performance in autonomous driving scenarios. One widely adopted assumption of depth and ego-motion self-supervised learning is that the image brightness remains constant within nearby frames. Unfortunately, the endoscopic scene does not meet this assumption because there are severe brightness fluctuations induced by illumination variations, non-Lambertian reflections and interreflections during data collection, and these brightness fluctuations inevitably deteriorate the depth and ego-motion estimation accuracy. In this work, we introduce a novel concept referred to as appearance flow to address the brightness inconsistency problem. The appearance flow takes into consideration any variations in the brightness pattern and enables us to develop a generalized dynamic image constraint. Furthermore, we build a unified self-supervised framework to estimate monocular depth and ego-motion simultaneously in endoscopic scenes, which comprises a structure module, a motion module, an appearance module and a correspondence module, to accurately reconstruct the appearance and calibrate the image brightness. Extensive experiments are conducted on the SCARED dataset and EndoSLAM dataset, and the proposed unified framework exceeds other self-supervised approaches by a large margin. To validate our framework's generalization ability on different patients and cameras, we train our model on SCARED but test it on the SERV-CT and Hamlyn datasets without any fine-tuning, and the superior results reveal its strong generalization ability. Code will be available at: \url{https://github.com/ShuweiShao/AF-SfMLearner}.
Associative Adversarial Learning Based on Selective Attack
Dec 28, 2021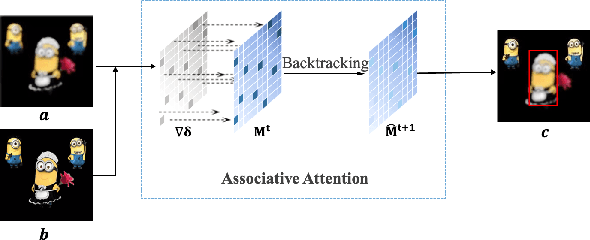
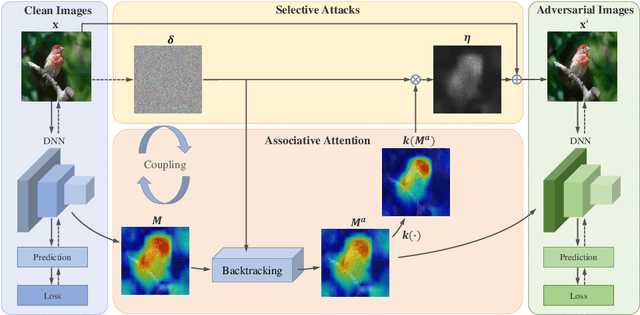
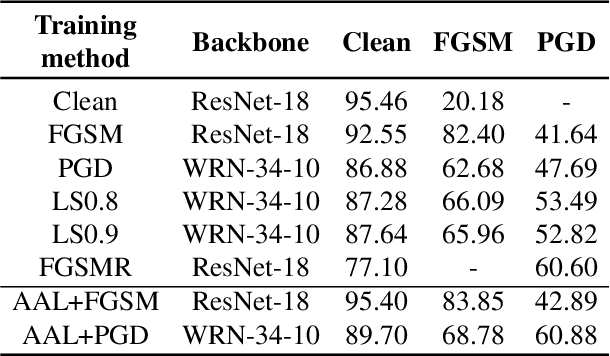
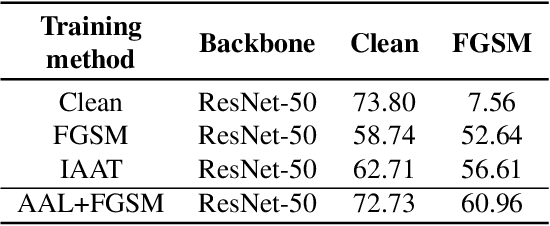
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.
Probe-Based Interventions for Modifying Agent Behavior
Jan 26, 2022Neural nets are powerful function approximators, but the behavior of a given neural net, once trained, cannot be easily modified. We wish, however, for people to be able to influence neural agents' actions despite the agents never training with humans, which we formalize as a human-assisted decision-making problem. Inspired by prior art initially developed for model explainability, we develop a method for updating representations in pre-trained neural nets according to externally-specified properties. In experiments, we show how our method may be used to improve human-agent team performance for a variety of neural networks from image classifiers to agents in multi-agent reinforcement learning settings.
Towards Bi-directional Skip Connections in Encoder-Decoder Architectures and Beyond
Mar 17, 2022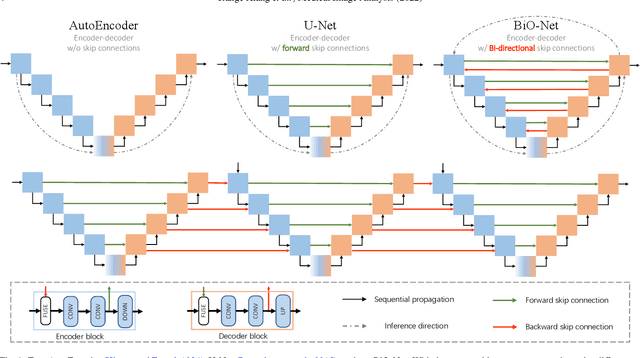
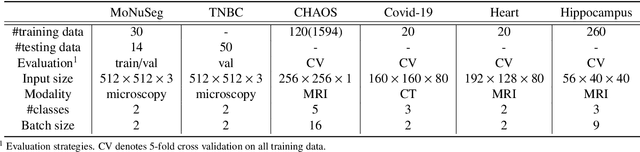
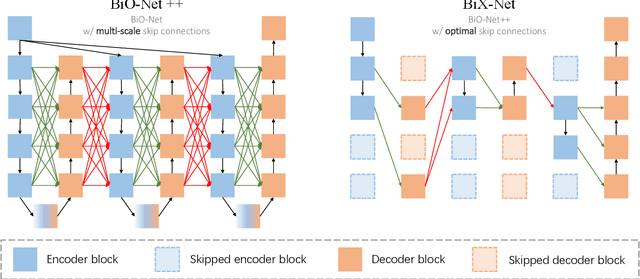
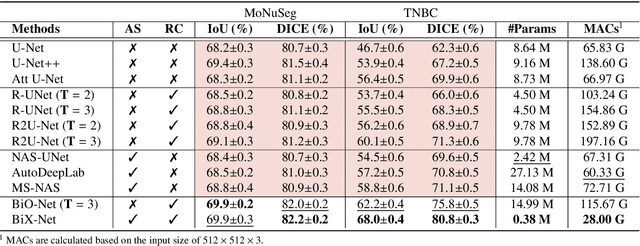
U-Net, as an encoder-decoder architecture with forward skip connections, has achieved promising results in various medical image analysis tasks. Many recent approaches have also extended U-Net with more complex building blocks, which typically increase the number of network parameters considerably. Such complexity makes the inference stage highly inefficient for clinical applications. Towards an effective yet economic segmentation network design, in this work, we propose backward skip connections that bring decoded features back to the encoder. Our design can be jointly adopted with forward skip connections in any encoder-decoder architecture forming a recurrence structure without introducing extra parameters. With the backward skip connections, we propose a U-Net based network family, namely Bi-directional O-shape networks, which set new benchmarks on multiple public medical imaging segmentation datasets. On the other hand, with the most plain architecture (BiO-Net), network computations inevitably increase along with the pre-set recurrence time. We have thus studied the deficiency bottleneck of such recurrent design and propose a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS, to search for the best multi-scale bi-directional skip connections. The ineffective skip connections are then discarded to reduce computational costs and speed up network inference. The finally searched BiX-Net yields the least network complexity and outperforms other state-of-the-art counterparts by large margins. We evaluate our methods on both 2D and 3D segmentation tasks in a total of six datasets. Extensive ablation studies have also been conducted to provide a comprehensive analysis for our proposed methods.
GPU optimization of the 3D Scale-invariant Feature Transform Algorithm and a Novel BRIEF-inspired 3D Fast Descriptor
Dec 19, 2021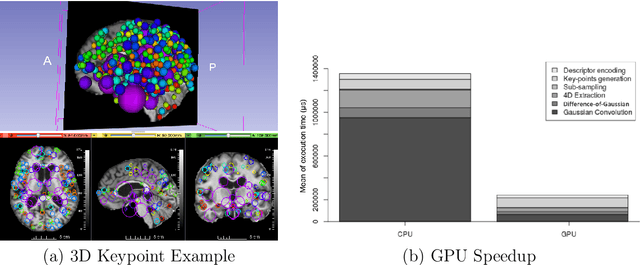
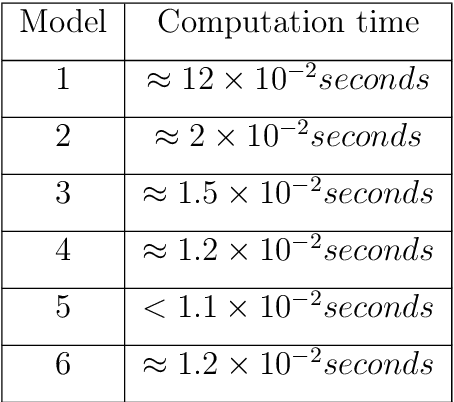
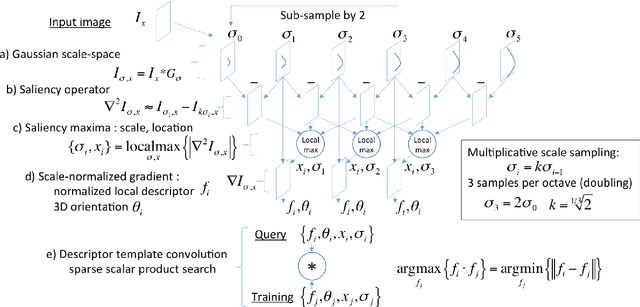
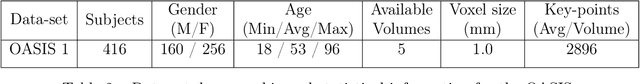
This work details a highly efficient implementation of the 3D scale-invariant feature transform (SIFT) algorithm, for the purpose of machine learning from large sets of volumetric medical image data. The primary operations of the 3D SIFT code are implemented on a graphics processing unit (GPU), including convolution, sub-sampling, and 4D peak detection from scale-space pyramids. The performance improvements are quantified in keypoint detection and image-to-image matching experiments, using 3D MRI human brain volumes of different people. Computationally efficient 3D keypoint descriptors are proposed based on the Binary Robust Independent Elementary Feature (BRIEF) code, including a novel descriptor we call Ranked Robust Independent Elementary Features (RRIEF), and compared to the original 3D SIFT-Rank method\citep{toews2013efficient}. The GPU implementation affords a speedup of approximately 7X beyond an optimised CPU implementation, where computation time is reduced from 1.4 seconds to 0.2 seconds for 3D volumes of size (145, 174, 145) voxels with approximately 3000 keypoints. Notable speedups include the convolution operation (20X), 4D peak detection (3X), sub-sampling (3X), and difference-of-Gaussian pyramid construction (2X). Efficient descriptors offer a speedup of 2X and a memory savings of 6X compared to standard SIFT-Rank descriptors, at a cost of reduced numbers of keypoint correspondences, revealing a trade-off between computational efficiency and algorithmic performance. The speedups gained by our implementation will allow for a more efficient analysis on larger data sets. Our optimized GPU implementation of the 3D SIFT-Rank extractor is available at https://github.com/CarluerJB/3D_SIFT_CUDA.