 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AvatarMe++: Facial Shape and BRDF Inference with Photorealistic Rendering-Aware GANs
Dec 11, 2021

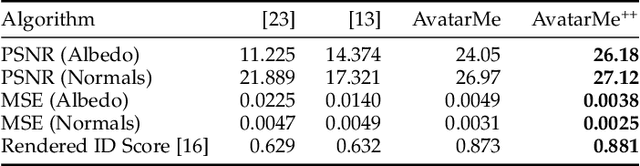


Over the last years, many face analysis tasks have accomplished astounding performance, with applications including face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce render-ready high-resolution 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this work, we introduce the first method that is able to reconstruct photorealistic render-ready 3D facial geometry and BRDF from a single "in-the-wild" image. We capture a large dataset of facial shape and reflectance, which we have made public. We define a fast facial photorealistic differentiable rendering methodology with accurate facial skin diffuse and specular reflection, self-occlusion and subsurface scattering approximation. With this, we train a network that disentangles the facial diffuse and specular BRDF components from a shape and texture with baked illumination, reconstructed with a state-of-the-art 3DMM fitting method. Our method outperforms the existing arts by a significant margin and reconstructs high-resolution 3D faces from a single low-resolution image, that can be rendered in various applications, and bridge the uncanny valley.
Object-Based Visual Camera Pose Estimation From Ellipsoidal Model and 3D-Aware Ellipse Prediction
Mar 09, 2022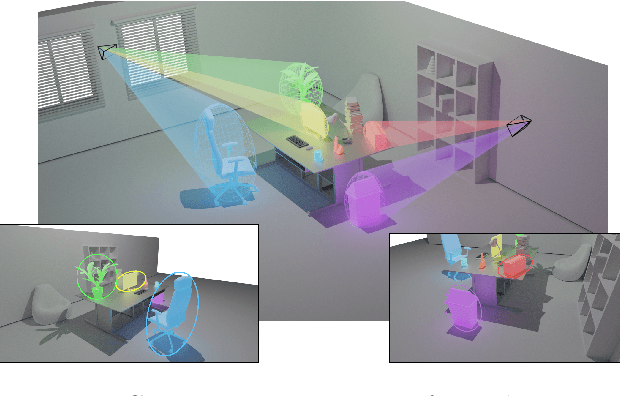

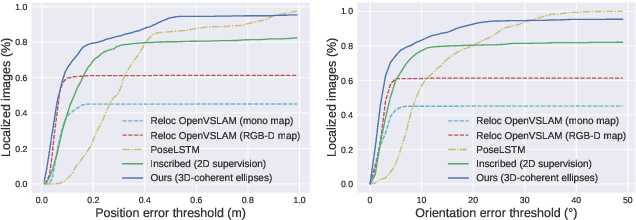
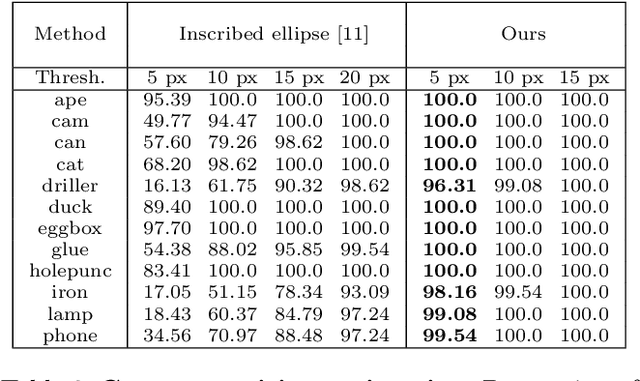
In this paper, we propose a method for initial camera pose estimation from just a single image which is robust to viewing conditions and does not require a detailed model of the scene. This method meets the growing need of easy deployment of robotics or augmented reality applications in any environments, especially those for which no accurate 3D model nor huge amount of ground truth data are available. It exploits the ability of deep learning techniques to reliably detect objects regardless of viewing conditions. Previous works have also shown that abstracting the geometry of a scene of objects by an ellipsoid cloud allows to compute the camera pose accurately enough for various application needs. Though promising, these approaches use the ellipses fitted to the detection bounding boxes as an approximation of the imaged objects. In this paper, we go one step further and propose a learning-based method which detects improved elliptic approximations of objects which are coherent with the 3D ellipsoids in terms of perspective projection. Experiments prove that the accuracy of the computed pose significantly increases thanks to our method. This is achieved with very little effort in terms of training data acquisition - a few hundred calibrated images of which only three need manual object annotation. Code and models are released at https://gitlab.inria.fr/tangram/3d-aware-ellipses-for-visual-localization
HyperInverter: Improving StyleGAN Inversion via Hypernetwork
Dec 01, 2021
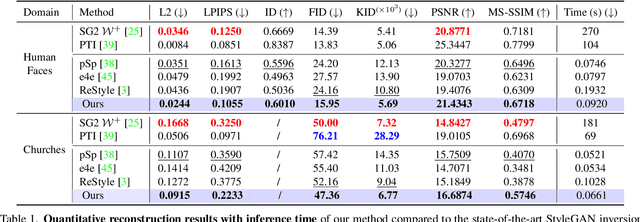
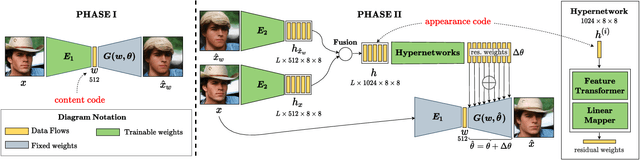
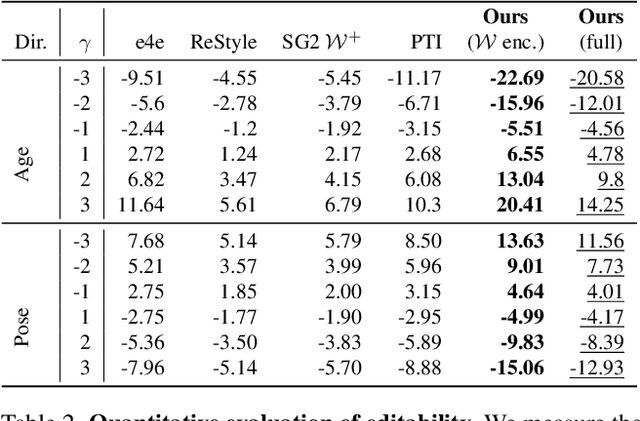
Real-world image manipulation has achieved fantastic progress in recent years as a result of the exploration and utilization of GAN latent spaces. GAN inversion is the first step in this pipeline, which aims to map the real image to the latent code faithfully. Unfortunately, the majority of existing GAN inversion methods fail to meet at least one of the three requirements listed below: high reconstruction quality, editability, and fast inference. We present a novel two-phase strategy in this research that fits all requirements at the same time. In the first phase, we train an encoder to map the input image to StyleGAN2 $\mathcal{W}$-space, which was proven to have excellent editability but lower reconstruction quality. In the second phase, we supplement the reconstruction ability in the initial phase by leveraging a series of hypernetworks to recover the missing information during inversion. These two steps complement each other to yield high reconstruction quality thanks to the hypernetwork branch and excellent editability due to the inversion done in the $\mathcal{W}$-space. Our method is entirely encoder-based, resulting in extremely fast inference. Extensive experiments on two challenging datasets demonstrate the superiority of our method.
Attention Mechanisms in Computer Vision: A Survey
Nov 15, 2021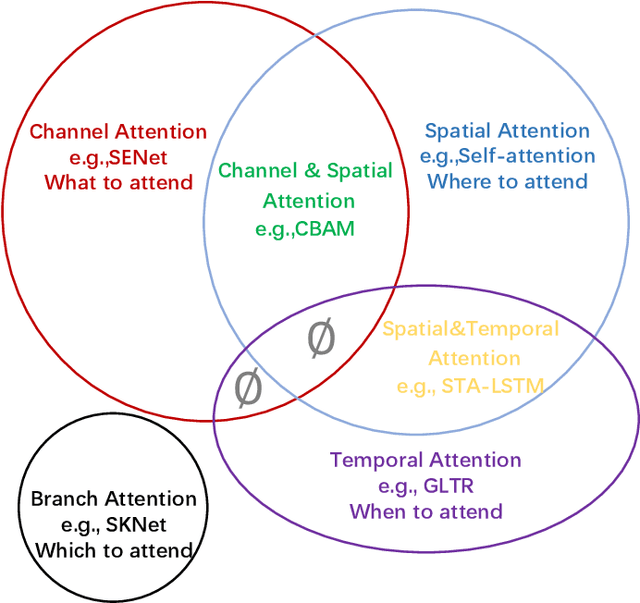

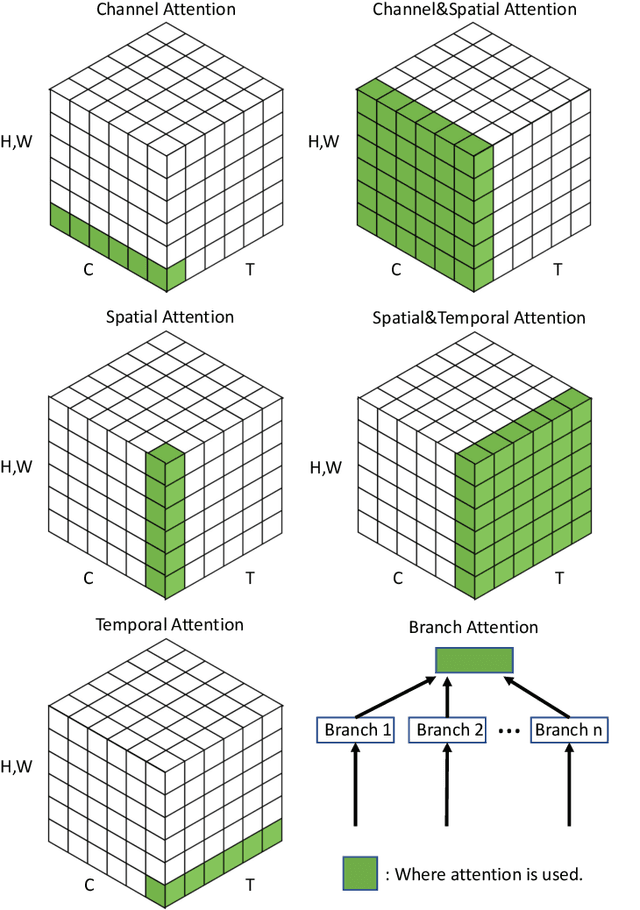
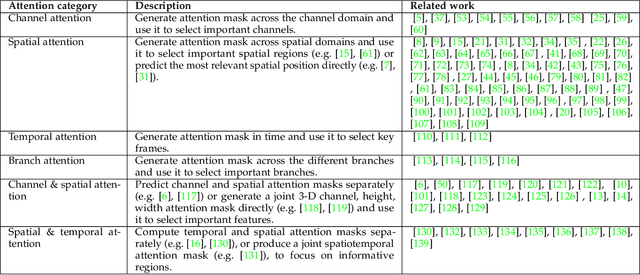
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is dedicated to collecting related work. We also suggest future directions for attention mechanism research.
Improving Text to Image Generation using Mode-seeking Function
Sep 04, 2020
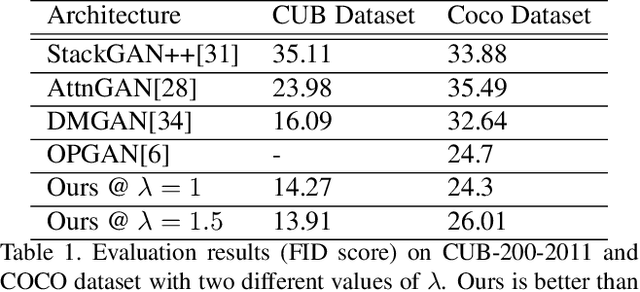


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.
Direct evaluation of progression or regression of disease burden in brain metastatic disease with Deep Neuroevolution
Mar 24, 2022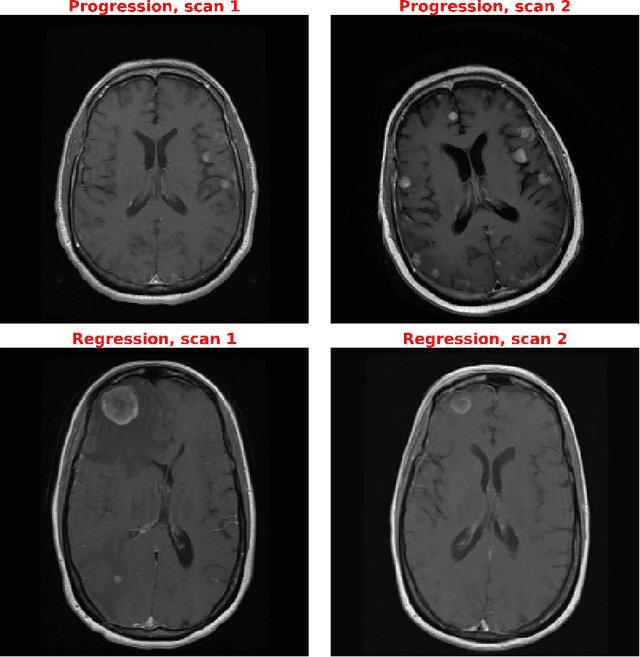
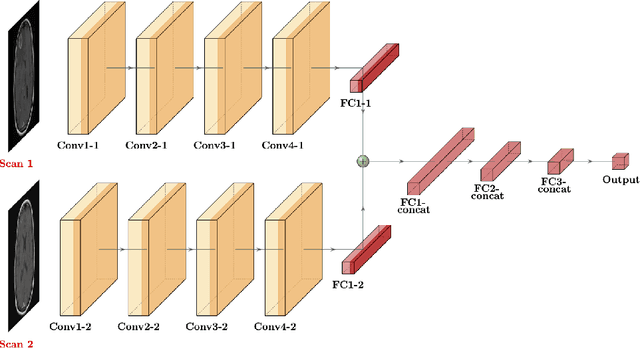
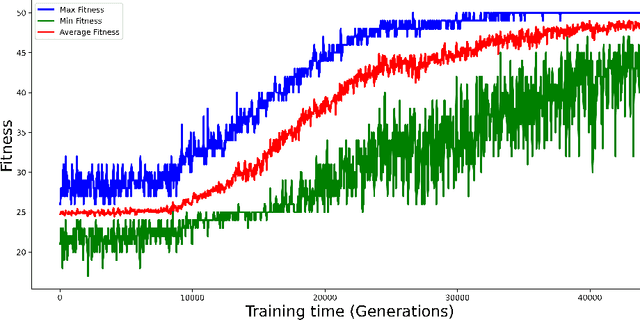
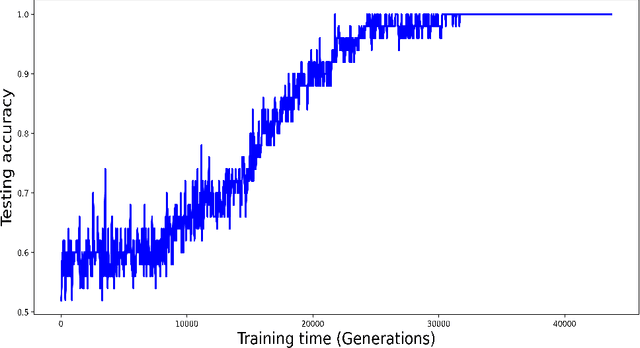
Purpose: A core component of advancing cancer treatment research is assessing response to therapy. Doing so by hand, for example as per RECIST or RANO criteria, is tedious, time-consuming, and can miss important tumor response information; most notably, they exclude non-target lesions. We wish to assess change in a holistic fashion that includes all lesions, obtaining simple, informative, and automated assessments of tumor progression or regression. Due to often low patient enrolments in clinical trials, we wish to make response assessments with small training sets. Deep neuroevolution (DNE) can produce radiology artificial intelligence (AI) that performs well on small training sets. Here we use DNE for function approximation that predicts progression versus regression of metastatic brain disease. Methods: We analyzed 50 pairs of MRI contrast-enhanced images as our training set. Half of these pairs, separated in time, qualified as disease progression, while the other 25 images constituted regression. We trained the parameters of a relatively small CNN via mutations that consisted of random CNN weight adjustments and mutation fitness. We then incorporated the best mutations into the next generations CNN, repeating this process for approximately 50,000 generations. We applied the CNNs to our training set, as well as a separate testing set with the same class balance of 25 progression and 25 regression images. Results: DNE achieved monotonic convergence to 100% training set accuracy. DNE also converged monotonically to 100% testing set accuracy. Conclusion: DNE can accurately classify brain-metastatic disease progression versus regression. Future work will extend the input from 2D image slices to full 3D volumes, and include the category of no change. We believe that an approach such as our could ultimately provide a useful adjunct to RANO/RECIST assessment.
A Hybrid Spatial-temporal Deep Learning Architecture for Lane Detection
Oct 14, 2021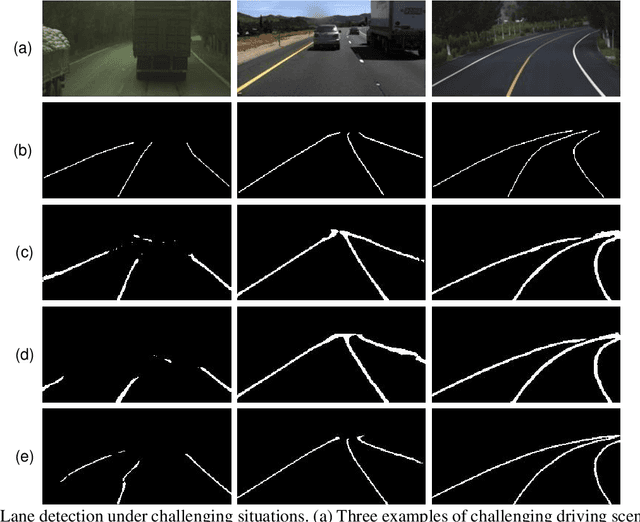
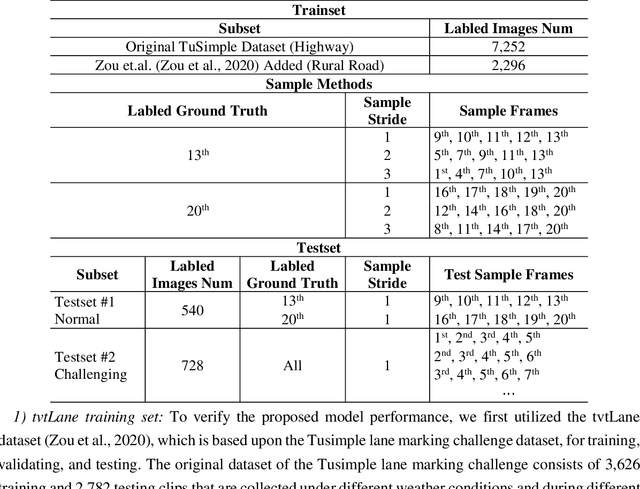
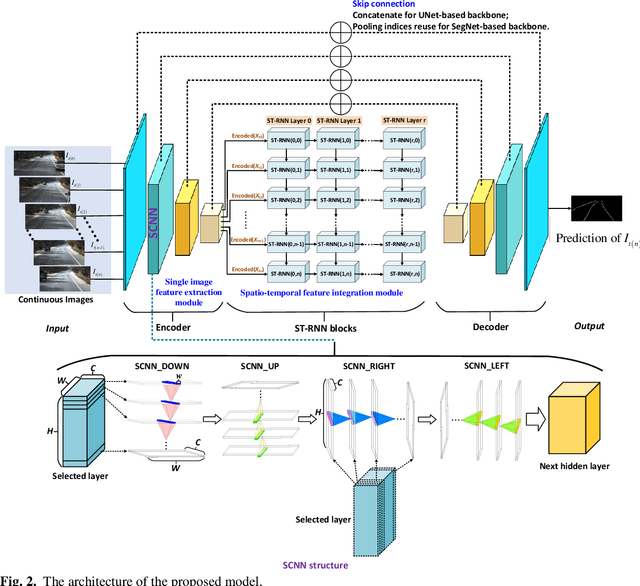
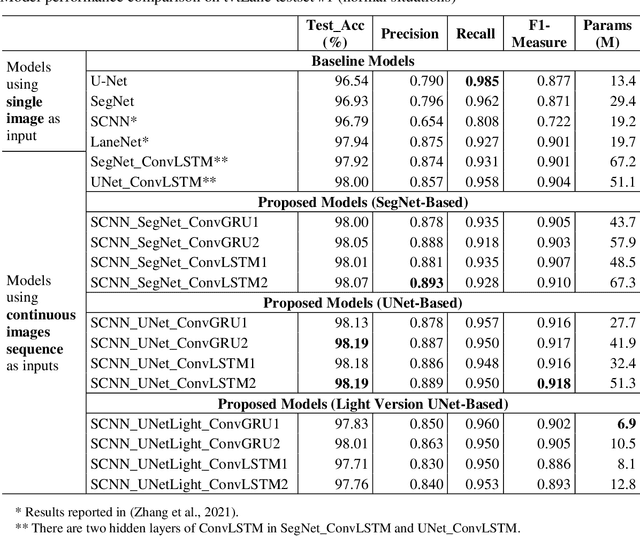
Reliable and accurate lane detection is of vital importance for the safe performance of Lane Keeping Assistance and Lane Departure Warning systems. However, under certain challenging peculiar circumstances, it is difficult to get satisfactory performance in accurately detecting the lanes from one single image which is often the case in current literature. Since lane markings are continuous lines, the lanes that are difficult to be accurately detected in the single current image can potentially be better deduced if information from previous frames is incorporated. This study proposes a novel hybrid spatial-temporal sequence-to-one deep learning architecture making full use of the spatial-temporal information in multiple continuous image frames to detect lane markings in the very last current frame. Specifically, the hybrid model integrates the single image feature extraction module with the spatial convolutional neural network (SCNN) embedded for excavating spatial features and relationships in one single image, the spatial-temporal feature integration module with spatial-temporal recurrent neural network (ST-RNN), which can capture the spatial-temporal correlations and time dependencies among image sequences, and the encoder-decoder structure, which makes this image segmentation problem work in an end-to-end supervised learning format. Extensive experiments reveal that the proposed model can effectively handle challenging driving scenes and outperforms available state-of-the-art methods with a large margin.
PAM: Pose Attention Module for Pose-Invariant Face Recognition
Nov 23, 2021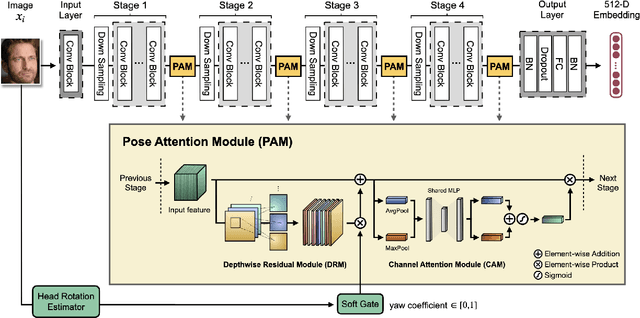
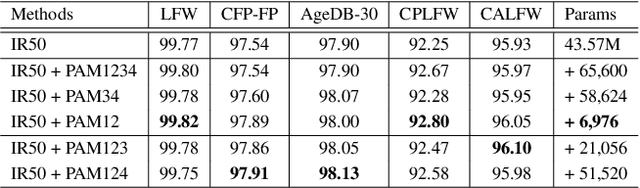
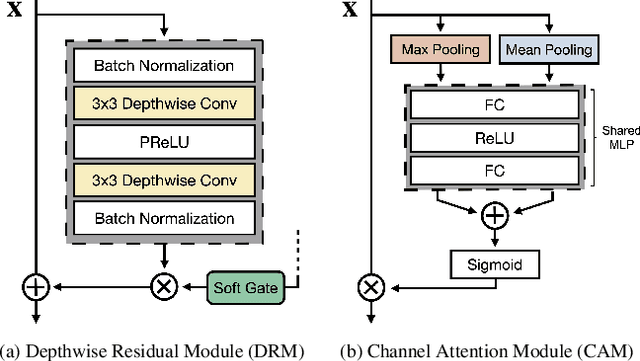
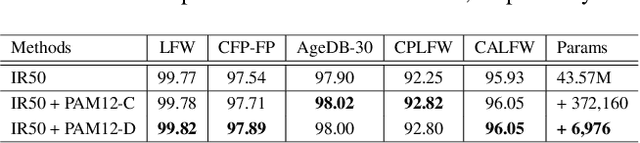
Pose variation is one of the key challenges in face recognition. Conventional techniques mainly focus on face frontalization or face augmentation in image space. However, transforming face images in image space is not guaranteed to preserve the lossless identity features of the original image. Moreover, these methods suffer from more computational costs and memory requirements due to the additional models. We argue that it is more desirable to perform feature transformation in hierarchical feature space rather than image space, which can take advantage of different feature levels and benefit from joint learning with representation learning. To this end, we propose a lightweight and easy-to-implement attention block, named Pose Attention Module (PAM), for pose-invariant face recognition. Specifically, PAM performs frontal-profile feature transformation in hierarchical feature space by learning residuals between pose variations with a soft gate mechanism. We validated the effectiveness of PAM block design through extensive ablation studies and verified the performance on several popular benchmarks, including LFW, CFP-FP, AgeDB-30, CPLFW, and CALFW. Experimental results show that our method not only outperforms state-of-the-art methods but also effectively reduces memory requirements by more than 75 times. It is noteworthy that our method is not limited to face recognition with large pose variations. By adjusting the soft gate mechanism of PAM to a specific coefficient, such semantic attention block can easily extend to address other intra-class imbalance problems in face recognition, including large variations in age, illumination, expression, etc.
U-Net and its variants for medical image segmentation: theory and applications
Nov 02, 2020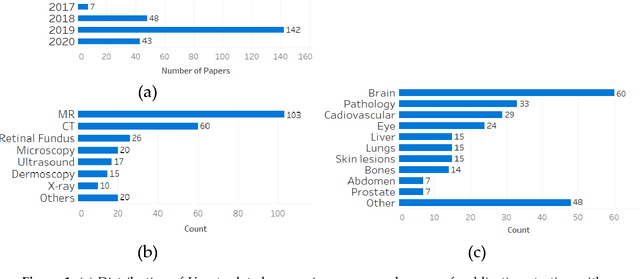

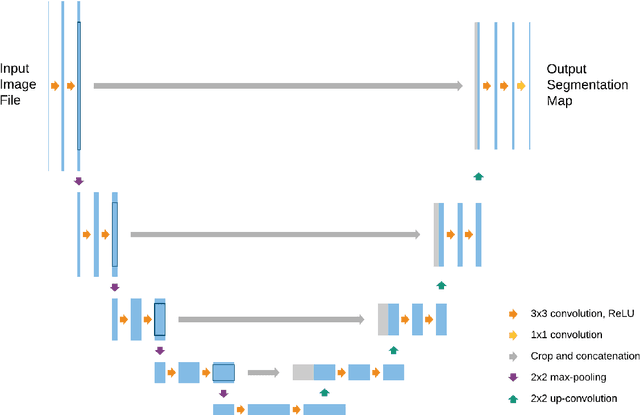
U-net is an image segmentation technique developed primarily for medical image analysis that can precisely segment images using a scarce amount of training data. These traits provide U-net with a very high utility within the medical imaging community and have resulted in extensive adoption of U-net as the primary tool for segmentation tasks in medical imaging. The success of U-net is evident in its widespread use in all major image modalities from CT scans and MRI to X-rays and microscopy. Furthermore, while U-net is largely a segmentation tool, there have been instances of the use of U-net in other applications. As the potential of U-net is still increasing, in this review we look at the various developments that have been made in the U-net architecture and provide observations on recent trends. We examine the various innovations that have been made in deep learning and discuss how these tools facilitate U-net. Furthermore, we look at image modalities and application areas where U-net has been applied.
Semantic Example Guided Image-to-Image Translation
Oct 04, 2019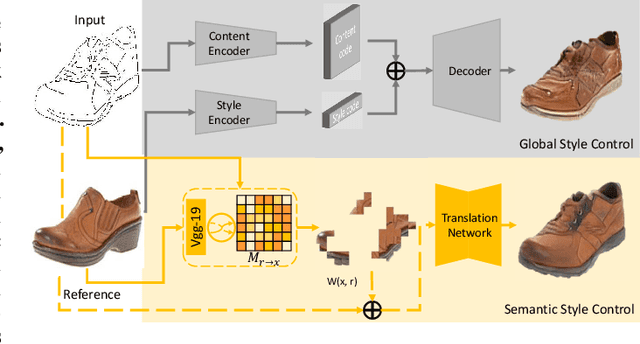


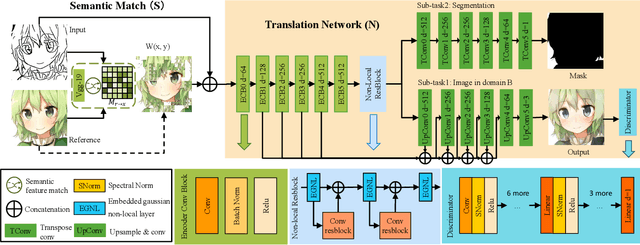
Many image-to-image (I2I) translation problems are in nature of high diversity that a single input may have various counterparts. Prior works proposed the multi-modal network that can build a many-to-many mapping between two visual domains. However, most of them are guided by sampled noises. Some others encode the reference images into a latent vector, by which the semantic information of the reference image will be washed away. In this work, we aim to provide a solution to control the output based on references semantically. Given a reference image and an input in another domain, a semantic matching is first performed between the two visual contents and generates the auxiliary image, which is explicitly encouraged to preserve semantic characteristics of the reference. A deep network then is used for I2I translation and the final outputs are expected to be semantically similar to both the input and the reference; however, no such paired data can satisfy that dual-similarity in a supervised fashion, so we build up a self-supervised framework to serve the training purpose. We improve the quality and diversity of the outputs by employing non-local blocks and a multi-task architecture. We assess the proposed method through extensive qualitative and quantitative evaluations and also presented comparisons with several state-of-art models.