 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Text to Image Generation using Mode-seeking Function
Aug 19, 2020

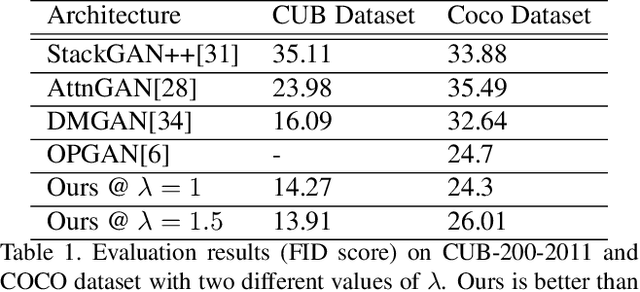


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.
Learning MRI Artifact Removal With Unpaired Data
Oct 09, 2021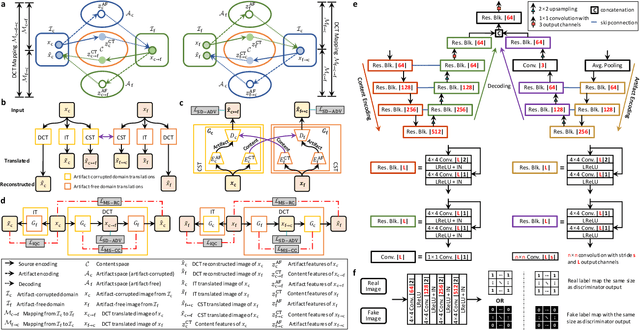
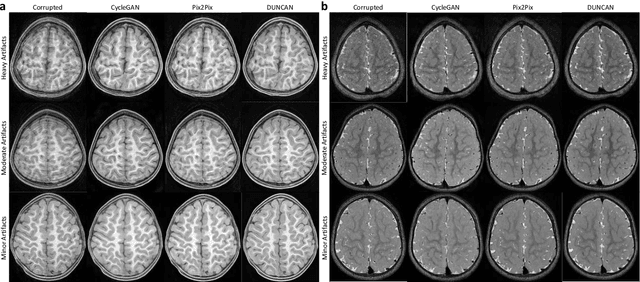
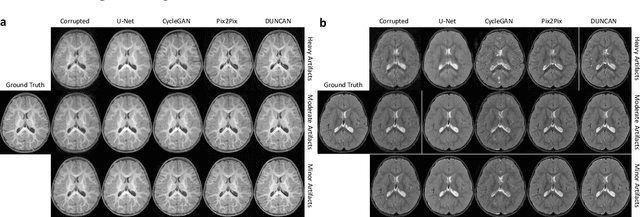
Retrospective artifact correction (RAC) improves image quality post acquisition and enhances image usability. Recent machine learning driven techniques for RAC are predominantly based on supervised learning and therefore practical utility can be limited as data with paired artifact-free and artifact-corrupted images are typically insufficient or even non-existent. Here we show that unwanted image artifacts can be disentangled and removed from an image via an RAC neural network learned with unpaired data. This implies that our method does not require matching artifact-corrupted data to be either collected via acquisition or generated via simulation. Experimental results demonstrate that our method is remarkably effective in removing artifacts and retaining anatomical details in images with different contrasts.
Uncertainty-Aware Learning for Improvements in Image Quality of the Canada-France-Hawaii Telescope
Jun 30, 2021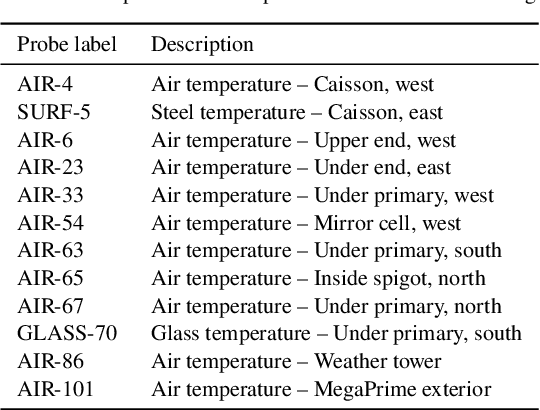
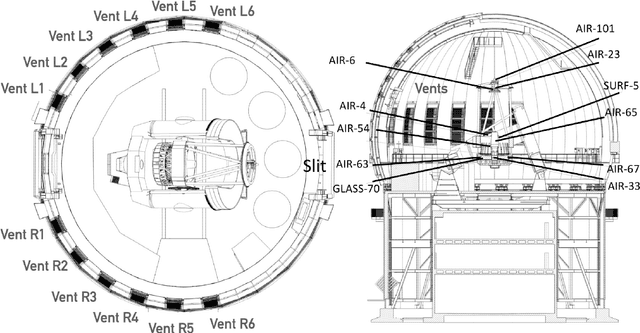
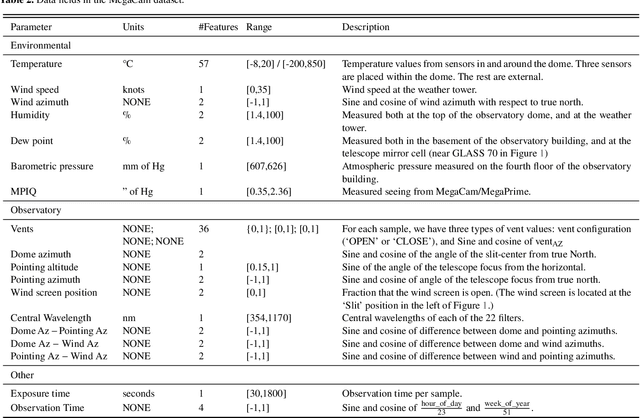
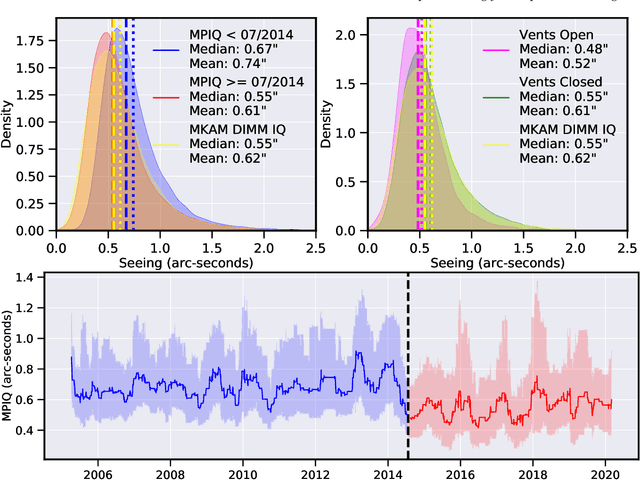
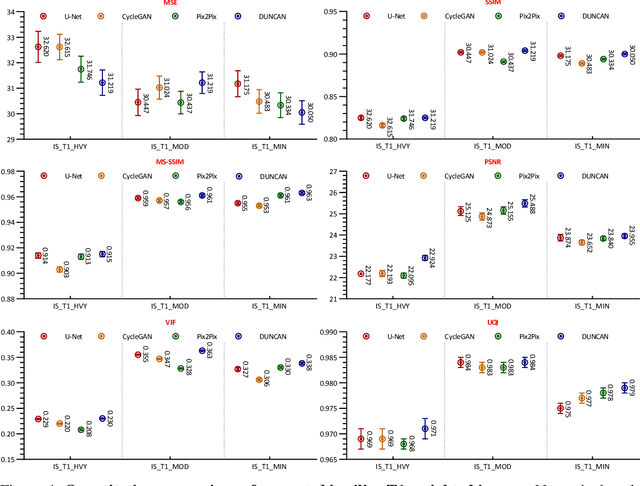
We leverage state-of-the-art machine learning methods and a decade's worth of archival data from the Canada-France-Hawaii Telescope (CFHT) to predict observatory image quality (IQ) from environmental conditions and observatory operating parameters. Specifically, we develop accurate and interpretable models of the complex dependence between data features and observed IQ for CFHT's wide field camera, MegaCam. Our contributions are several-fold. First, we collect, collate and reprocess several disparate data sets gathered by CFHT scientists. Second, we predict probability distribution functions (PDFs) of IQ, and achieve a mean absolute error of $\sim0.07''$ for the predicted medians. Third, we explore data-driven actuation of the 12 dome ``vents'', installed in 2013-14 to accelerate the flushing of hot air from the dome. We leverage epistemic and aleatoric uncertainties in conjunction with probabilistic generative modeling to identify candidate vent adjustments that are in-distribution (ID) and, for the optimal configuration for each ID sample, we predict the reduction in required observing time to achieve a fixed SNR. On average, the reduction is $\sim15\%$. Finally, we rank sensor data features by Shapley values to identify the most predictive variables for each observation. Our long-term goal is to construct reliable and real-time models that can forecast optimal observatory operating parameters for optimization of IQ. Such forecasts can then be fed into scheduling protocols and predictive maintenance routines. We anticipate that such approaches will become standard in automating observatory operations and maintenance by the time CFHT's successor, the Maunakea Spectroscopic Explorer (MSE), is installed in the next decade.
Learning to ignore: rethinking attention in CNNs
Nov 10, 2021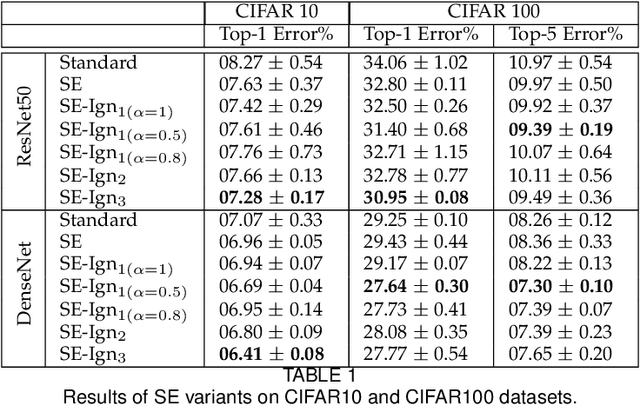
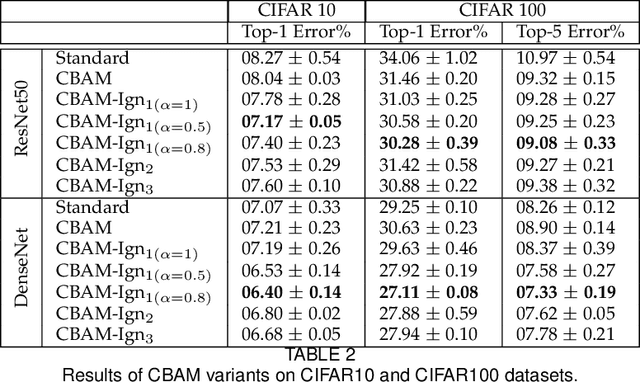
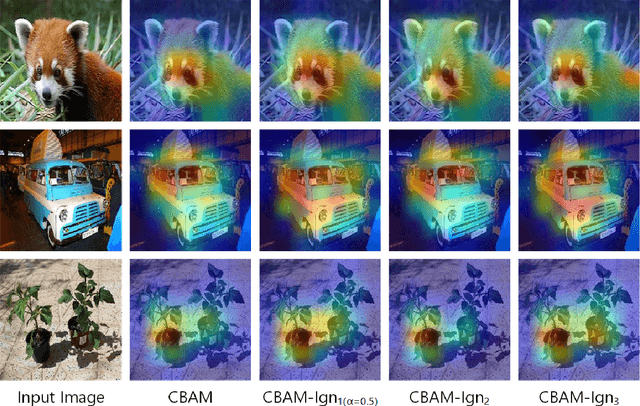
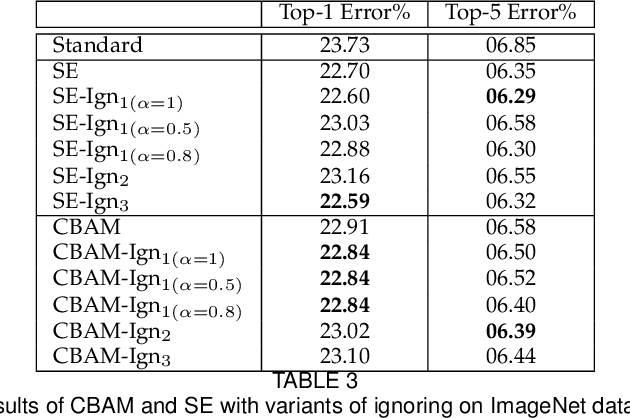
Recently, there has been an increasing interest in applying attention mechanisms in Convolutional Neural Networks (CNNs) to solve computer vision tasks. Most of these methods learn to explicitly identify and highlight relevant parts of the scene and pass the attended image to further layers of the network. In this paper, we argue that such an approach might not be optimal. Arguably, explicitly learning which parts of the image are relevant is typically harder than learning which parts of the image are less relevant and, thus, should be ignored. In fact, in vision domain, there are many easy-to-identify patterns of irrelevant features. For example, image regions close to the borders are less likely to contain useful information for a classification task. Based on this idea, we propose to reformulate the attention mechanism in CNNs to learn to ignore instead of learning to attend. Specifically, we propose to explicitly learn irrelevant information in the scene and suppress it in the produced representation, keeping only important attributes. This implicit attention scheme can be incorporated into any existing attention mechanism. In this work, we validate this idea using two recent attention methods Squeeze and Excitation (SE) block and Convolutional Block Attention Module (CBAM). Experimental results on different datasets and model architectures show that learning to ignore, i.e., implicit attention, yields superior performance compared to the standard approaches.
Revisiting Deep Semi-supervised Learning: An Empirical Distribution Alignment Framework and Its Generalization Bound
Mar 13, 2022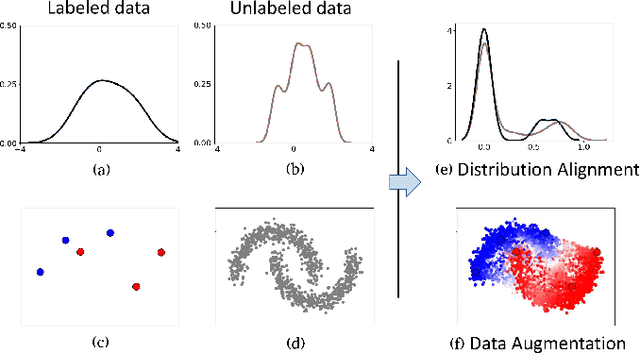
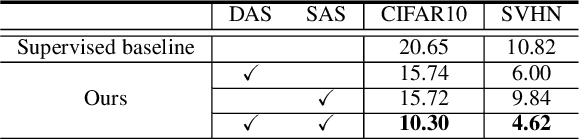
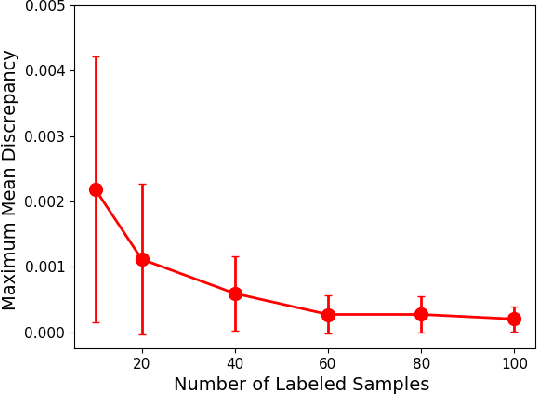
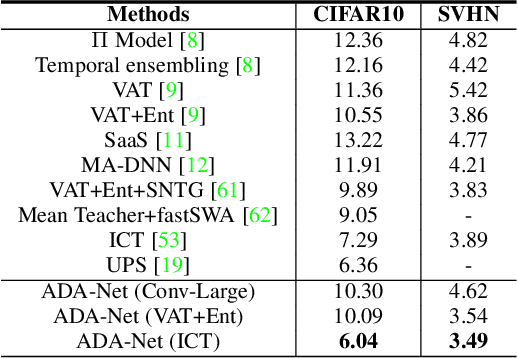
In this work, we revisit the semi-supervised learning (SSL) problem from a new perspective of explicitly reducing empirical distribution mismatch between labeled and unlabeled samples. Benefited from this new perspective, we first propose a new deep semi-supervised learning framework called Semi-supervised Learning by Empirical Distribution Alignment (SLEDA), in which existing technologies from the domain adaptation community can be readily used to address the semi-supervised learning problem through reducing the empirical distribution distance between labeled and unlabeled data. Based on this framework, we also develop a new theoretical generalization bound for the research community to better understand the semi-supervised learning problem, in which we show the generalization error of semi-supervised learning can be effectively bounded by minimizing the training error on labeled data and the empirical distribution distance between labeled and unlabeled data. Building upon our new framework and the theoretical bound, we develop a simple and effective deep semi-supervised learning method called Augmented Distribution Alignment Network (ADA-Net) by simultaneously adopting the well-established adversarial training strategy from the domain adaptation community and a simple sample interpolation strategy for data augmentation. Additionally, we incorporate both strategies in our ADA-Net into two exiting SSL methods to further improve their generalization capability, which indicates that our new framework provides a complementary solution for solving the SSL problem. Our comprehensive experimental results on two benchmark datasets SVHN and CIFAR-10 for the semi-supervised image recognition task and another two benchmark datasets ModelNet40 and ShapeNet55 for the semi-supervised point cloud recognition task demonstrate the effectiveness of our proposed framework for SSL.
DF-GAN: Deep Fusion Generative Adversarial Networks for Text-to-Image Synthesis
Aug 13, 2020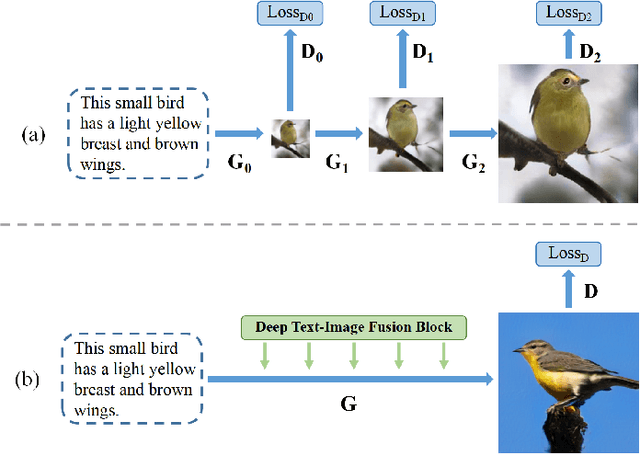

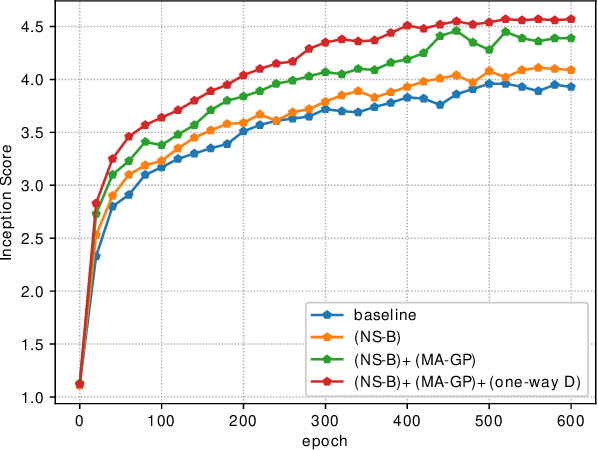
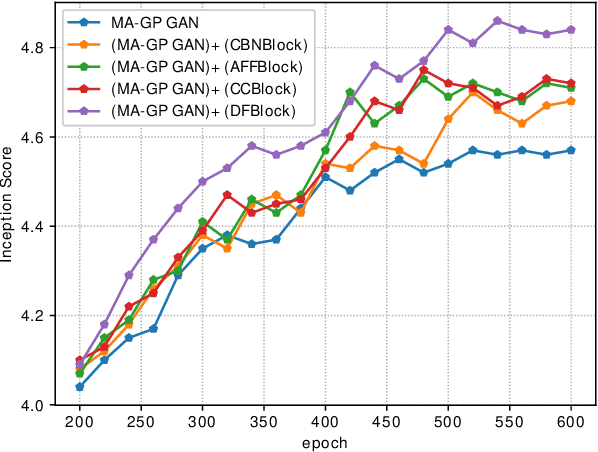
Synthesizing high-resolution realistic images from text descriptions is a challenging task. Almost all existing text-to-image methods employ stacked generative adversarial networks as the backbone, utilize cross-modal attention mechanisms to fuse text and image features, and use extra networks to ensure text-image semantic consistency. The existing text-to-image models have three problems: 1) For the backbone, there are multiple generators and discriminators stacked for generating different scales of images making the training process slow and inefficient. 2) For semantic consistency, the existing models employ extra networks to ensure the semantic consistency increasing the training complexity and bringing an additional computational cost. 3) For the text-image feature fusion method, cross-modal attention is only applied a few times during the generation process due to its computational cost impeding fusing the text and image features deeply. To solve these limitations, we propose 1) a novel simplified text-to-image backbone which is able to synthesize high-quality images directly by one pair of generator and discriminator, 2) a novel regularization method called Matching-Aware zero-centered Gradient Penalty which promotes the generator to synthesize more realistic and text-image semantic consistent images without introducing extra networks, 3) a novel fusion module called Deep Text-Image Fusion Block which can exploit the semantics of text descriptions effectively and fuse text and image features deeply during the generation process. Compared with the previous text-to-image models, our DF-GAN is simpler and more efficient and achieves better performance. Extensive experiments and ablation studies on both Caltech-UCSD Birds 200 and COCO datasets demonstrate the superiority of the proposed model in comparison to state-of-the-art models.
Artificial Intelligence for Suicide Assessment using Audiovisual Cues: A Review
Jan 22, 2022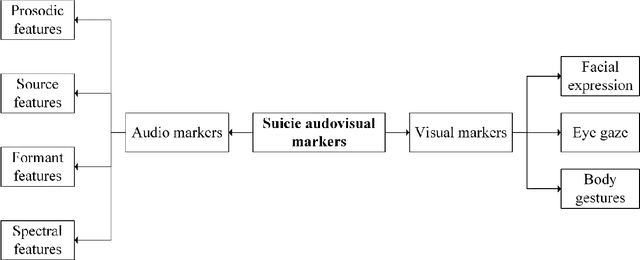
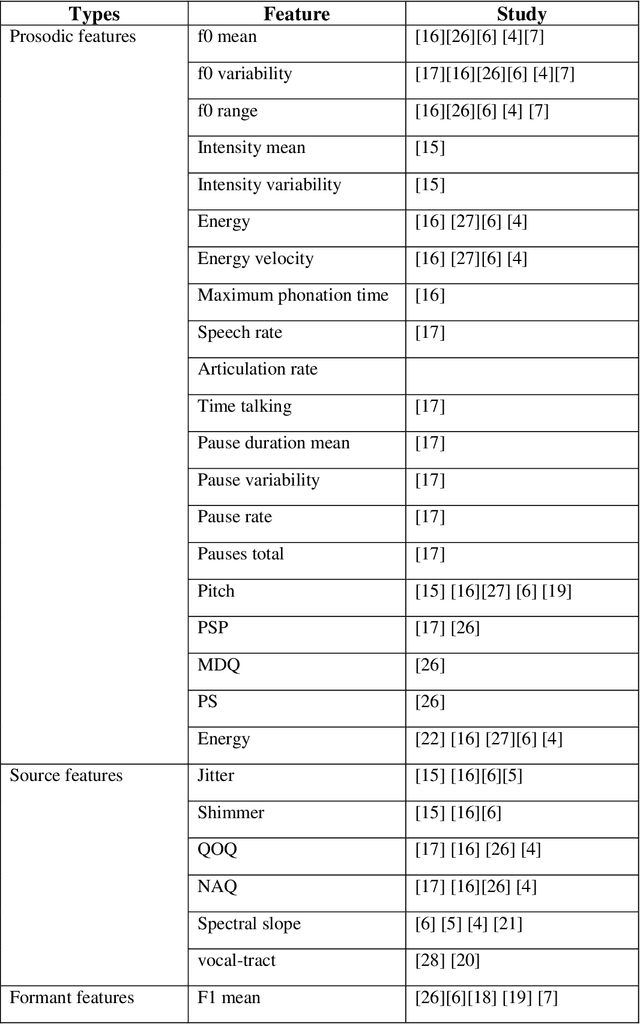
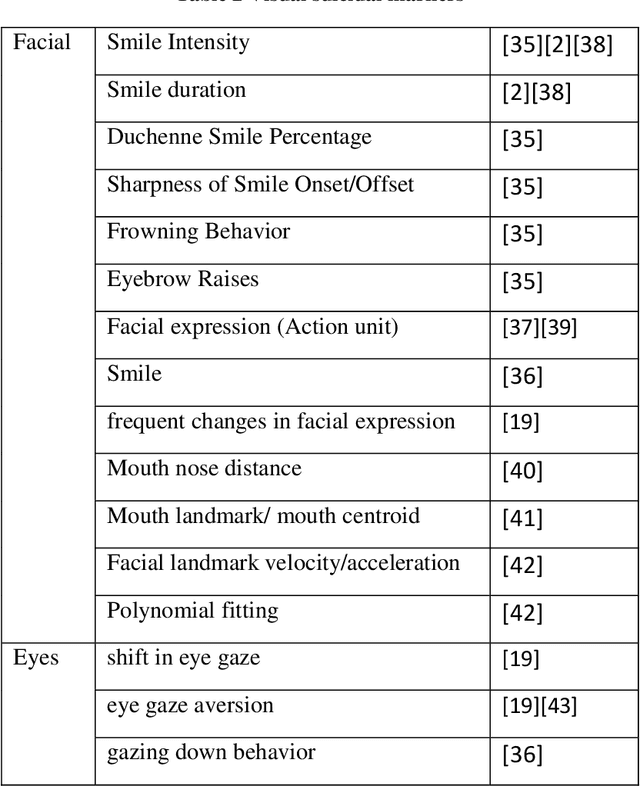
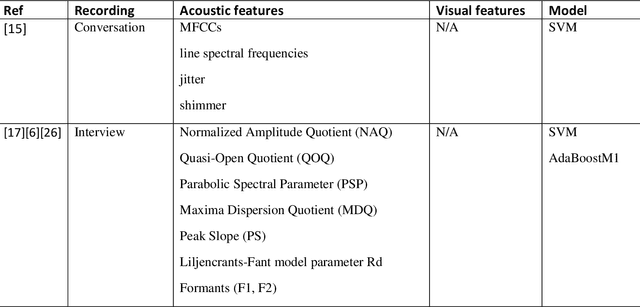
Death by suicide is the seventh of the leading death cause worldwide. The recent advancement in Artificial Intelligence (AI), specifically AI application in image and voice processing, has created a promising opportunity to revolutionize suicide risk assessment. Subsequently, we have witnessed fast-growing literature of researches that applies AI to extract audiovisual non-verbal cues for mental illness assessment. However, the majority of the recent works focus on depression, despite the evident difference between depression signs and suicidal behavior non-verbal cues. In this paper, we review the recent works that study suicide ideation and suicide behavior detection through audiovisual feature analysis, mainly suicidal voice/speech acoustic features analysis and suicidal visual cues.
Simple Dialogue System with AUDITED
Oct 22, 2021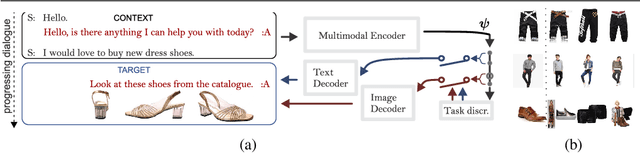

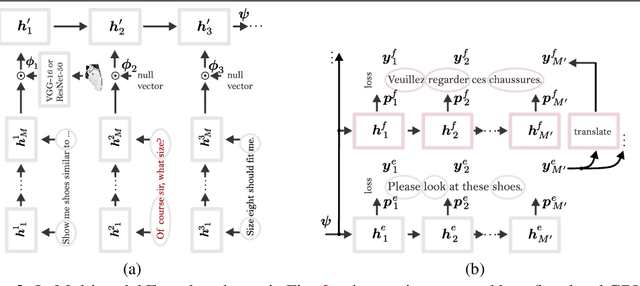
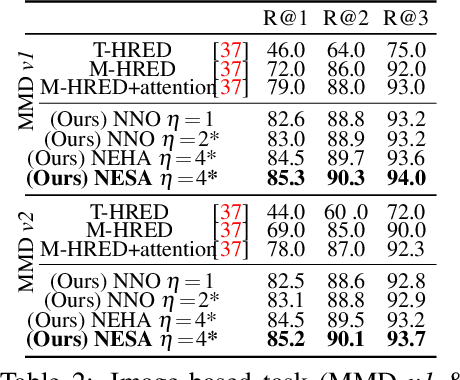
We devise a multimodal conversation system for dialogue utterances composed of text, image or both modalities. We leverage Auxiliary UnsuperviseD vIsual and TExtual Data (AUDITED). To improve the performance of text-based task, we utilize translations of target sentences from English to French to form the assisted supervision. For the image-based task, we employ the DeepFashion dataset in which we seek nearest neighbor images of positive and negative target images of the MMD data. These nearest neighbors form the nearest neighbor embedding providing an external context for target images. We form two methods to create neighbor embedding vectors, namely Neighbor Embedding by Hard Assignment (NEHA) and Neighbor Embedding by Soft Assignment (NESA) which generate context subspaces per target image. Subsequently, these subspaces are learnt by our pipeline as a context for the target data. We also propose a discriminator which switches between the image- and text-based tasks. We show improvements over baselines on the large-scale Multimodal Dialogue Dataset (MMD) and SIMMC.
Investigating Bias in Image Classification using Model Explanations
Dec 10, 2020
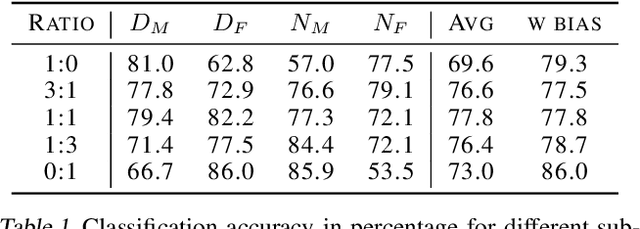
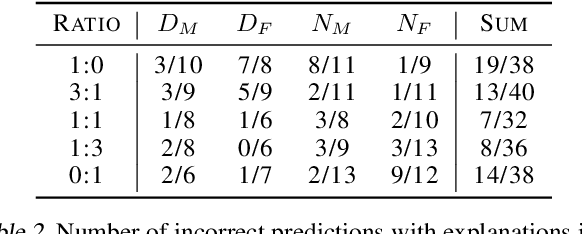
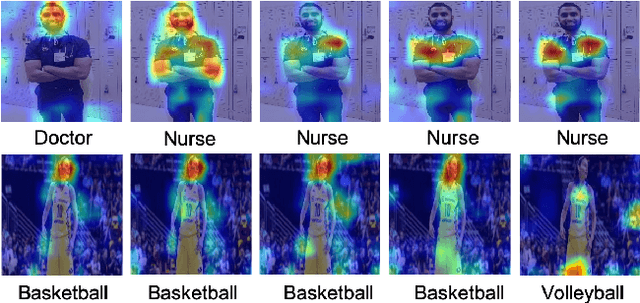
We evaluated whether model explanations could efficiently detect bias in image classification by highlighting discriminating features, thereby removing the reliance on sensitive attributes for fairness calculations. To this end, we formulated important characteristics for bias detection and observed how explanations change as the degree of bias in models change. The paper identifies strengths and best practices for detecting bias using explanations, as well as three main weaknesses: explanations poorly estimate the degree of bias, could potentially introduce additional bias into the analysis, and are sometimes inefficient in terms of human effort involved.
Improving Person Re-Identification with Temporal Constraints
Nov 17, 2021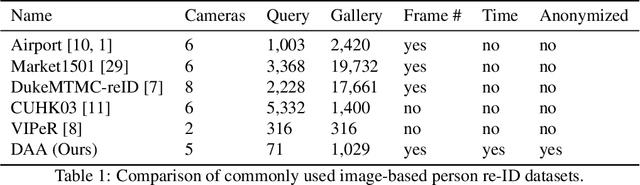

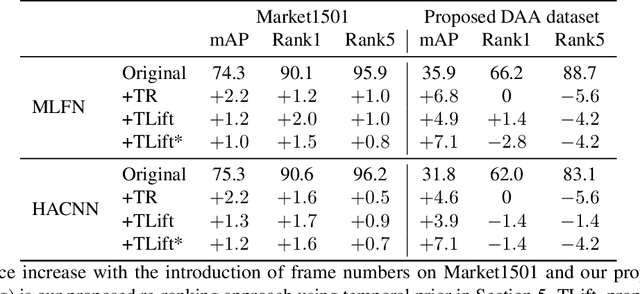
In this paper we introduce an image-based person re-identification dataset collected across five non-overlapping camera views in the large and busy airport in Dublin, Ireland. Unlike all publicly available image-based datasets, our dataset contains timestamp information in addition to frame number, and camera and person IDs. Also our dataset has been fully anonymized to comply with modern data privacy regulations. We apply state-of-the-art person re-identification models to our dataset and show that by leveraging the available timestamp information we are able to achieve a significant gain of 37.43% in mAP and a gain of 30.22% in Rank1 accuracy. We also propose a Bayesian temporal re-ranking post-processing step, which further adds a 10.03% gain in mAP and 9.95% gain in Rank1 accuracy metrics. This work on combining visual and temporal information is not possible on other image-based person re-identification datasets. We believe that the proposed new dataset will enable further development of person re-identification research for challenging real-world applications. DAA dataset can be downloaded from https://bit.ly/3AtXTd6