 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Material Blind Beam Hardening Correction Based on Non-Linearity Adjustment of Projections
Mar 09, 2022
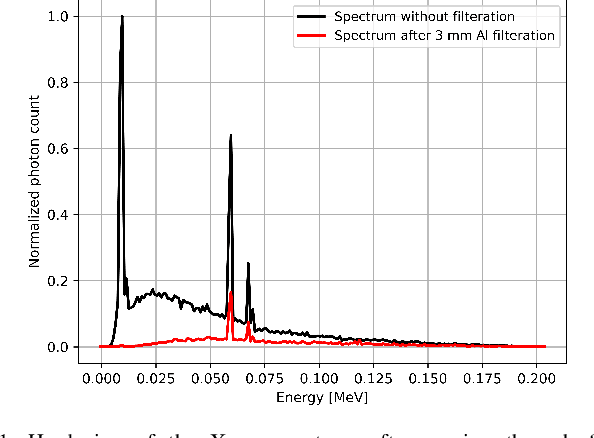
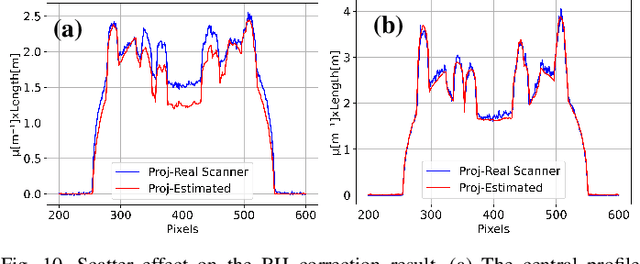
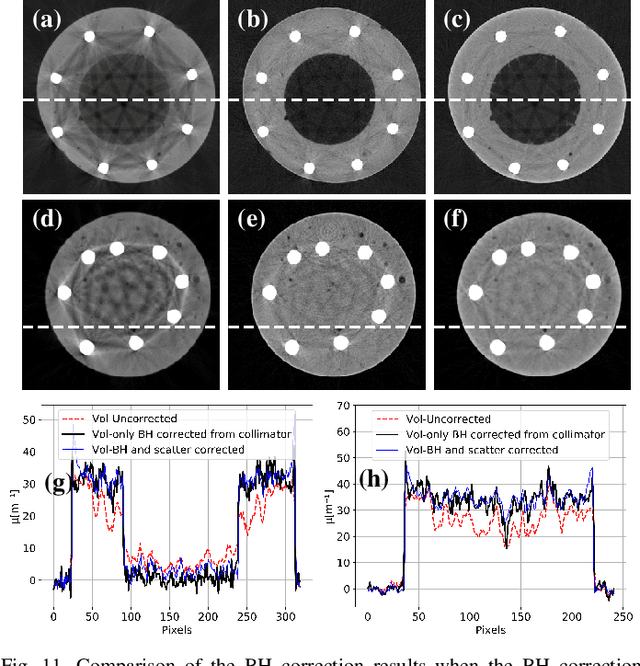
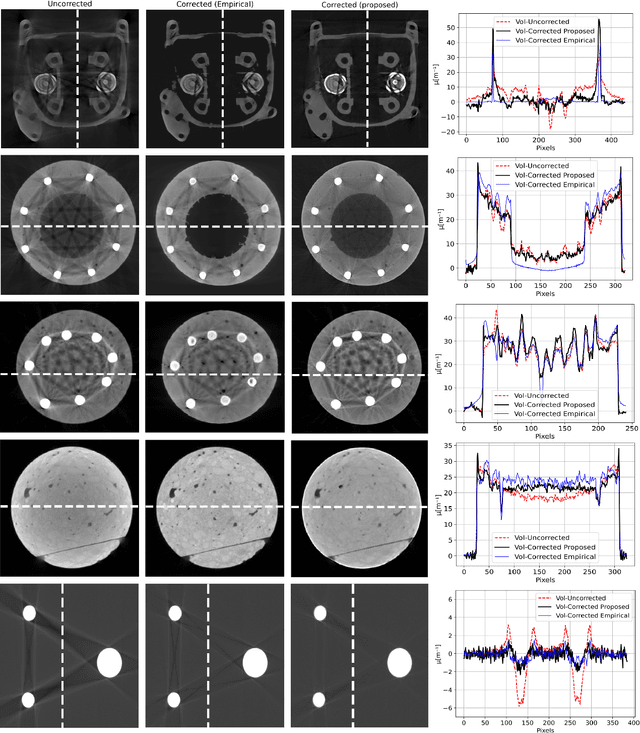
Beam hardening (BH) is one of the major artifacts that severely reduces the quality of Computed Tomography (CT) imaging. In a polychromatic X-ray beam, since low-energy photons are more preferentially absorbed, the attenuation of the beam is no longer a linear function of the absorber thickness. The existing BH correction methods either require a given material, which might be unfeasible in reality, or they require a long computation time. This work aims to propose a fast and accurate BH correction method that requires no prior knowledge of the materials and corrects first and higher-order BH artifacts. In the first step, a wide sweep of the material is performed based on an experimentally measured look-up table to obtain the closest estimate of the material. Then the non-linearity effect of the BH is corrected by adding the difference between the estimated monochromatic and the polychromatic simulated projections of the segmented image. The estimated monochromatic projection is simulated by selecting the energy from the polychromatic spectrum which produces the lowest mean square error (MSE) with the acquired projection from the scanner. The polychromatic projection is estimated by minimizing the difference between the acquired projection and the weighted sum of the simulated polychromatic projections using different spectra of different filtration. To evaluate the proposed BH correction method, we have conducted extensive experiments on the real-world CT data. Compared to the state-of-the-art empirical BH correction method, the experiments show that the proposed method can highly reduce the BH artifacts without prior knowledge of the materials.
Atlas-ISTN: Joint Segmentation, Registration and Atlas Construction with Image-and-Spatial Transformer Networks
Dec 18, 2020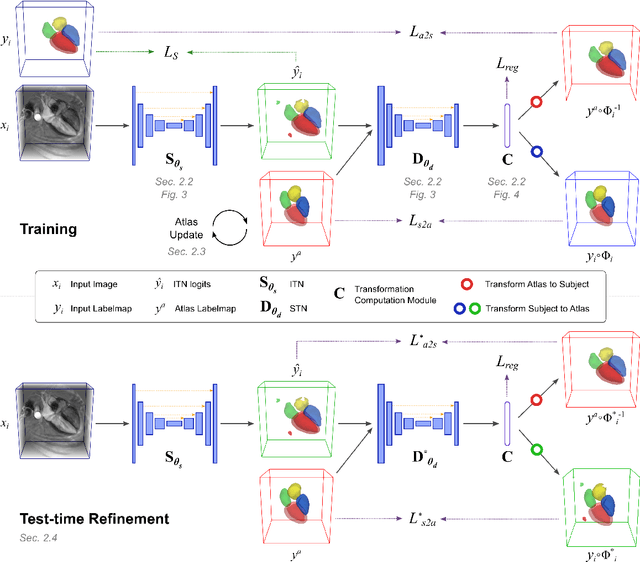
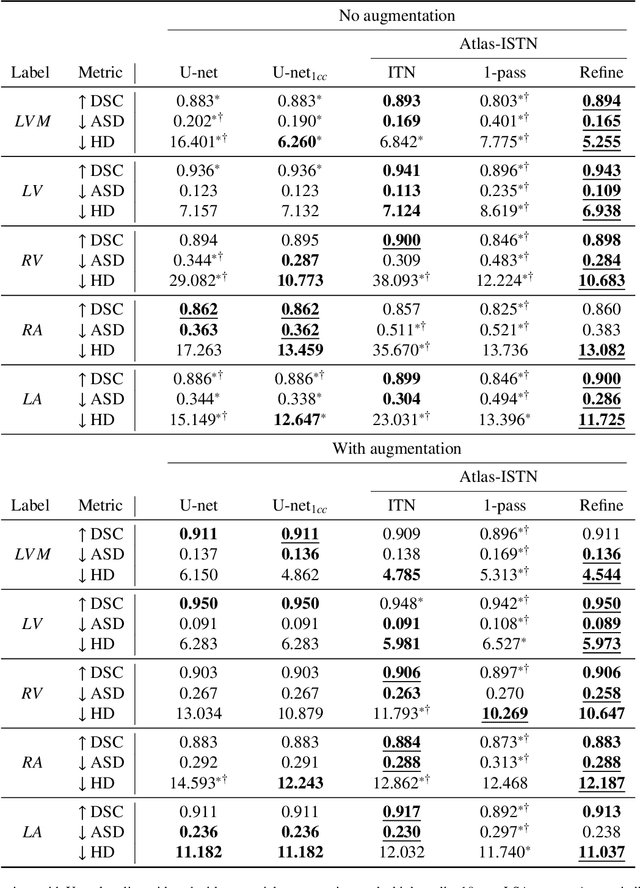
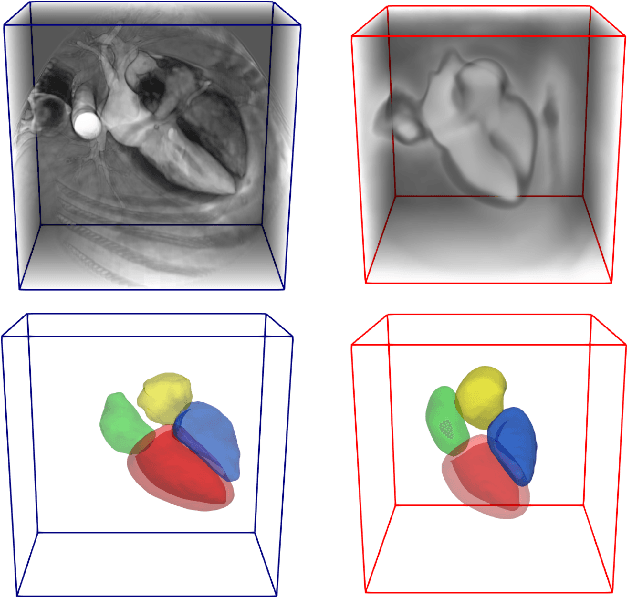
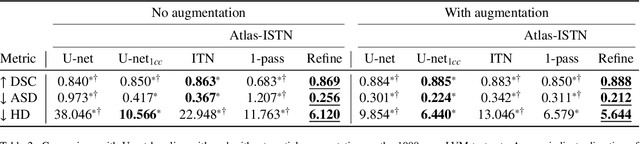
Deep learning models for semantic segmentation are able to learn powerful representations for pixel-wise predictions, but are sensitive to noise at test time and do not guarantee a plausible topology. Image registration models on the other hand are able to warp known topologies to target images as a means of segmentation, but typically require large amounts of training data, and have not widely been benchmarked against pixel-wise segmentation models. We propose Atlas-ISTN, a framework that jointly learns segmentation and registration on 2D and 3D image data, and constructs a population-derived atlas in the process. Atlas-ISTN learns to segment multiple structures of interest and to register the constructed, topologically consistent atlas labelmap to an intermediate pixel-wise segmentation. Additionally, Atlas-ISTN allows for test time refinement of the model's parameters to optimize the alignment of the atlas labelmap to an intermediate pixel-wise segmentation. This process both mitigates for noise in the target image that can result in spurious pixel-wise predictions, as well as improves upon the one-pass prediction of the model. Benefits of the Atlas-ISTN framework are demonstrated qualitatively and quantitatively on 2D synthetic data and 3D cardiac computed tomography and brain magnetic resonance image data, out-performing both segmentation and registration baseline models. Atlas-ISTN also provides inter-subject correspondence of the structures of interest, enabling population-level shape and motion analysis.
An efficient feature-preserving PDE algorithm for image denoising based on a spatial-fractional anisotropic diffusion equation
Jan 05, 2021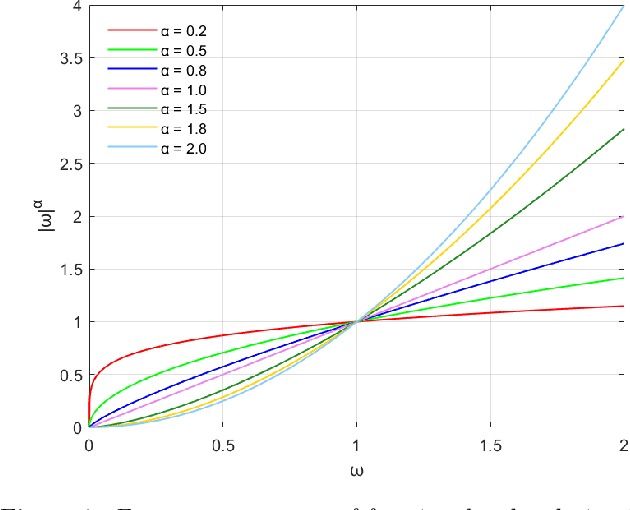
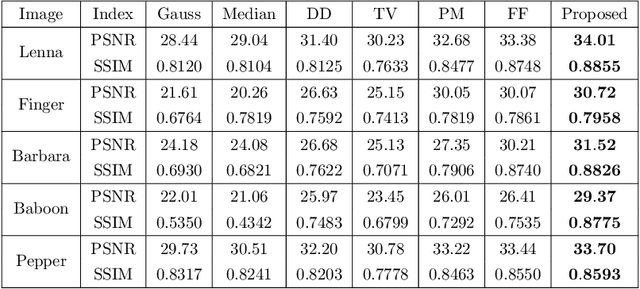

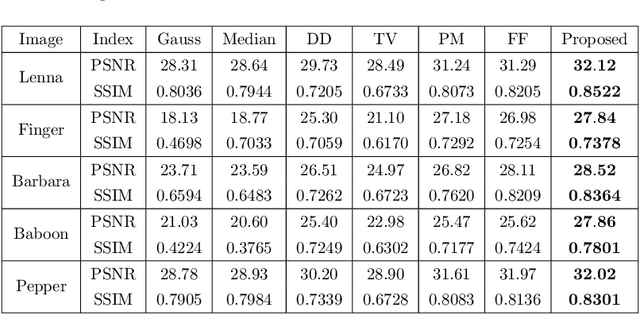
How to effectively remove the noise while preserving the image structure features is a challenging issue in the field of image denoising. In recent years, fractional PDE based methods have attracted more and more research efforts due to the ability to balance the noise removal and the preservation of image edges and textures. Among the existing fractional PDE algorithms, there are only a few using spatial fractional order derivatives, and all the fractional derivatives involved are one-sided derivatives. In this paper, an efficient feature-preserving fractional PDE algorithm is proposed for image denoising based on a nonlinear spatial-fractional anisotropic diffusion equation. Two-sided Grumwald-Letnikov fractional derivatives were used in the PDE model which are suitable to depict the local self-similarity of images. The Short Memory Principle is employed to simplify the approximation scheme. Experimental results show that the proposed method is of a satisfactory performance, i.e. it keeps a remarkable balance between noise removal and feature preserving, and has an extremely high structural retention property.
RA V-Net: Deep learning network for automated liver segmentation
Dec 16, 2021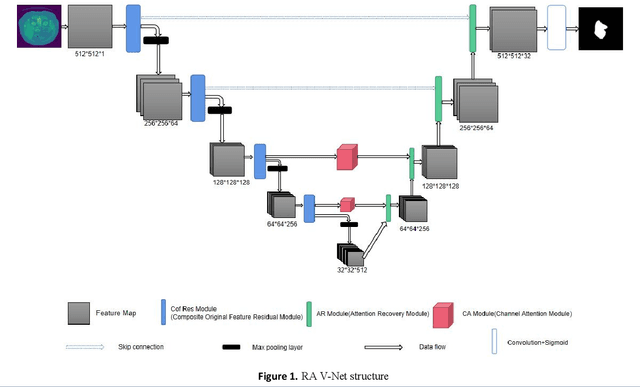

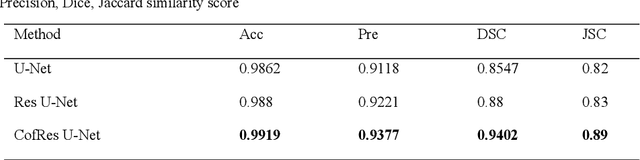
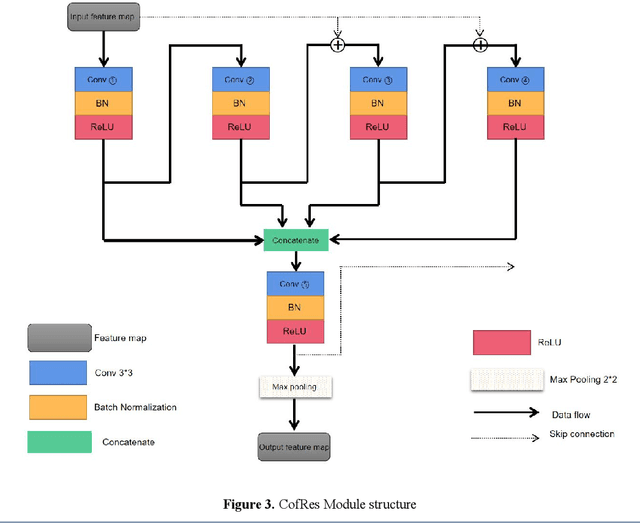
Accurate segmentation of the liver is a prerequisite for the diagnosis of disease. Automated segmentation is an important application of computer-aided detection and diagnosis of liver disease. In recent years, automated processing of medical images has gained breakthroughs. However, the low contrast of abdominal scan CT images and the complexity of liver morphology make accurate automatic segmentation challenging. In this paper, we propose RA V-Net, which is an improved medical image automatic segmentation model based on U-Net. It has the following three main innovations. CofRes Module (Composite Original Feature Residual Module) is proposed. With more complex convolution layers and skip connections to make it obtain a higher level of image feature extraction capability and prevent gradient disappearance or explosion. AR Module (Attention Recovery Module) is proposed to reduce the computational effort of the model. In addition, the spatial features between the data pixels of the encoding and decoding modules are sensed by adjusting the channels and LSTM convolution. Finally, the image features are effectively retained. CA Module (Channel Attention Module) is introduced, which used to extract relevant channels with dependencies and strengthen them by matrix dot product, while weakening irrelevant channels without dependencies. The purpose of channel attention is achieved. The attention mechanism provided by LSTM convolution and CA Module are strong guarantees for the performance of the neural network. The accuracy of U-Net network: 0.9862, precision: 0.9118, DSC: 0.8547, JSC: 0.82. The evaluation metrics of RA V-Net, accuracy: 0.9968, precision: 0.9597, DSC: 0.9654, JSC: 0.9414. The most representative metric for the segmentation effect is DSC, which improves 0.1107 over U-Net, and JSC improves 0.1214.
Structural-analogy from a Single Image Pair
Apr 16, 2020
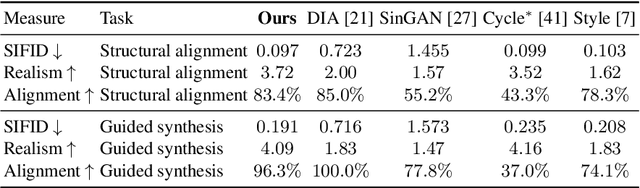
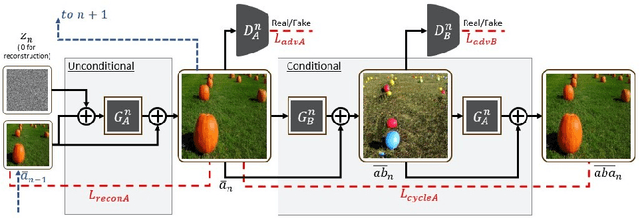
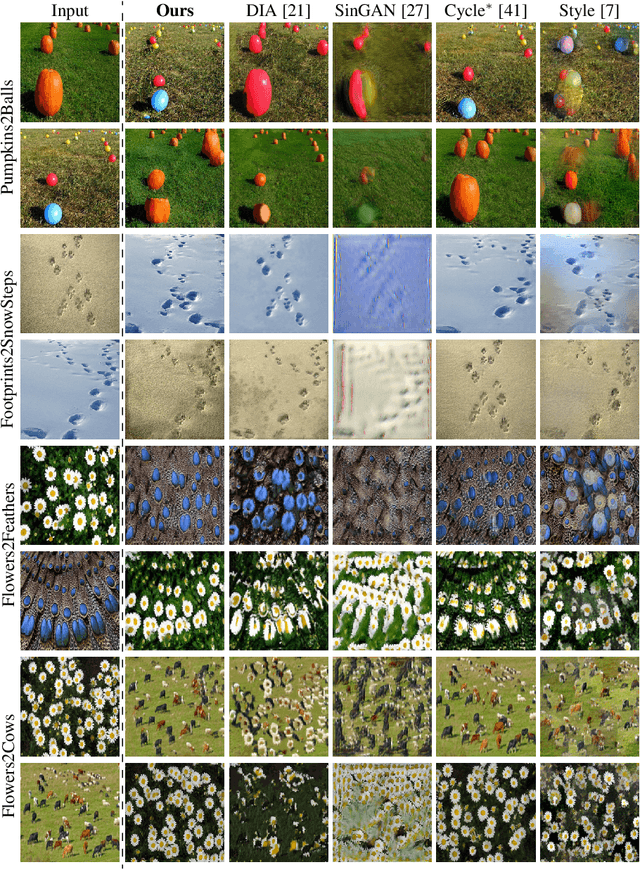
The task of unsupervised image-to-image translation has seen substantial advancements in recent years through the use of deep neural networks. Typically, the proposed solutions learn the characterizing distribution of two large, unpaired collections of images, and are able to alter the appearance of a given image, while keeping its geometry intact. In this paper, we explore the capabilities of neural networks to understand image structure given only a single pair of images, A and B. We seek to generate images that are structurally aligned: that is, to generate an image that keeps the appearance and style of B, but has a structural arrangement that corresponds to A. The key idea is to map between image patches at different scales. This enables controlling the granularity at which analogies are produced, which determines the conceptual distinction between style and content. In addition to structural alignment, our method can be used to generate high quality imagery in other conditional generation tasks utilizing images A and B only: guided image synthesis, style and texture transfer, text translation as well as video translation. Our code and additional results are available in https://github.com/rmokady/structural-analogy/.
The interpretation of endobronchial ultrasound image using 3D convolutional neural network for differentiating malignant and benign mediastinal lesions
Aug 02, 2021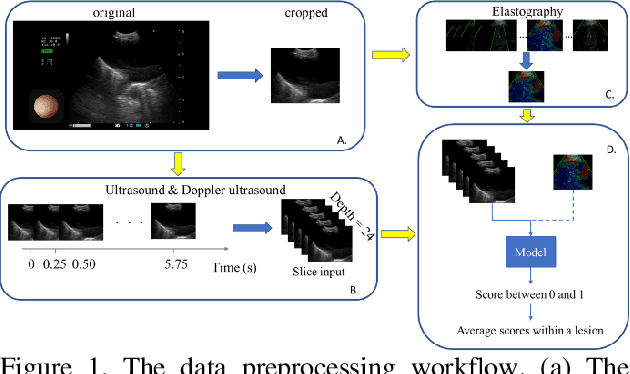
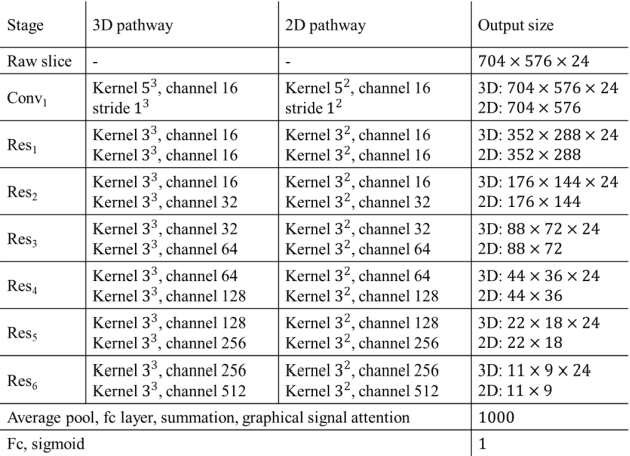
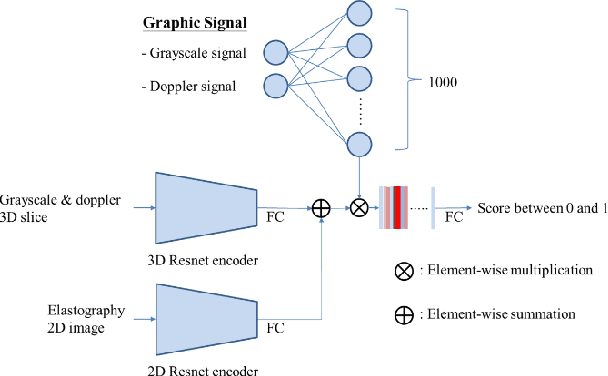
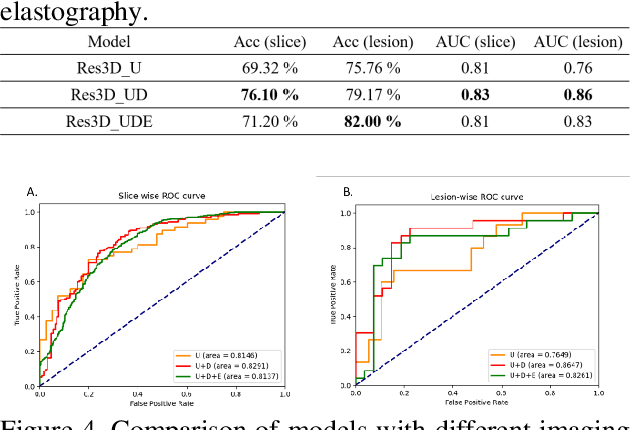
The purpose of this study is to differentiate malignant and benign mediastinal lesions by using the three-dimensional convolutional neural network through the endobronchial ultrasound (EBUS) image. Compared with previous study, our proposed model is robust to noise and able to fuse various imaging features and spatiotemporal features of EBUS videos. Endobronchial ultrasound-guided transbronchial needle aspiration (EBUS-TBNA) is a diagnostic tool for intrathoracic lymph nodes. Physician can observe the characteristics of the lesion using grayscale mode, doppler mode, and elastography during the procedure. To process the EBUS data in the form of a video and appropriately integrate the features of multiple imaging modes, we used a time-series three-dimensional convolutional neural network (3D CNN) to learn the spatiotemporal features and design a variety of architectures to fuse each imaging mode. Our model (Res3D_UDE) took grayscale mode, Doppler mode, and elastography as training data and achieved an accuracy of 82.00% and area under the curve (AUC) of 0.83 on the validation set. Compared with previous study, we directly used videos recorded during procedure as training and validation data, without additional manual selection, which might be easier for clinical application. In addition, model designed with 3D CNN can also effectively learn spatiotemporal features and improve accuracy. In the future, our model may be used to guide physicians to quickly and correctly find the target lesions for slice sampling during the inspection process, reduce the number of slices of benign lesions, and shorten the inspection time.
Artificial Intelligence for Suicide Assessment using Audiovisual Cues: A Review
Jan 22, 2022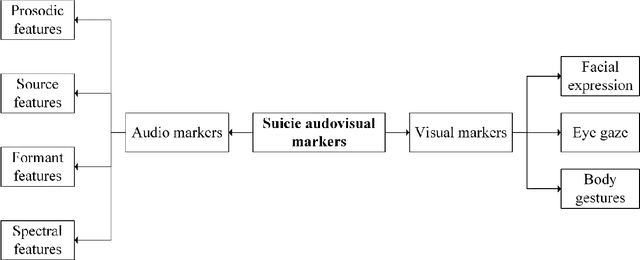
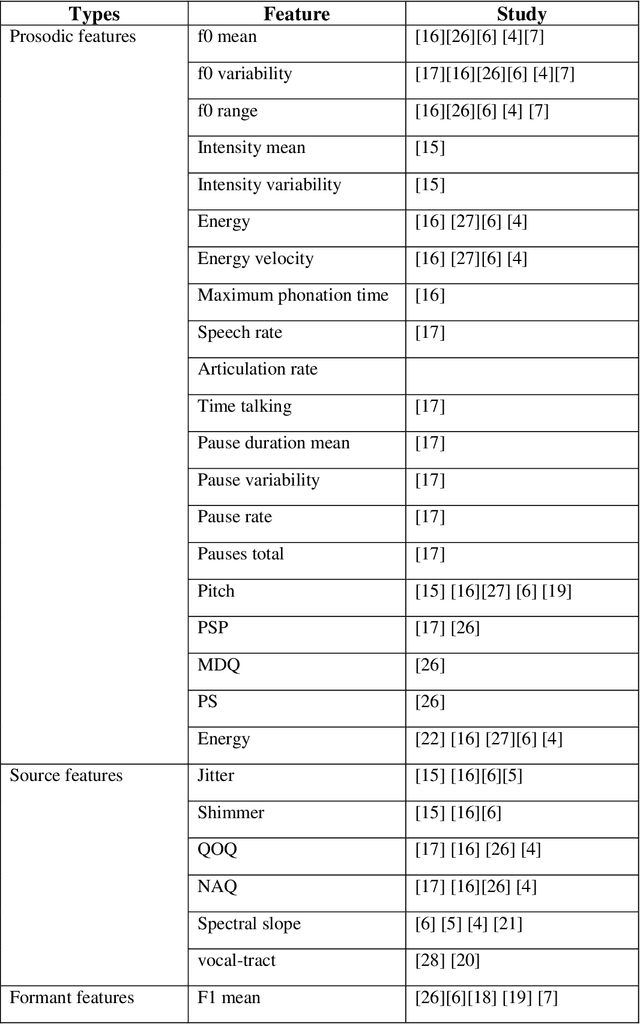
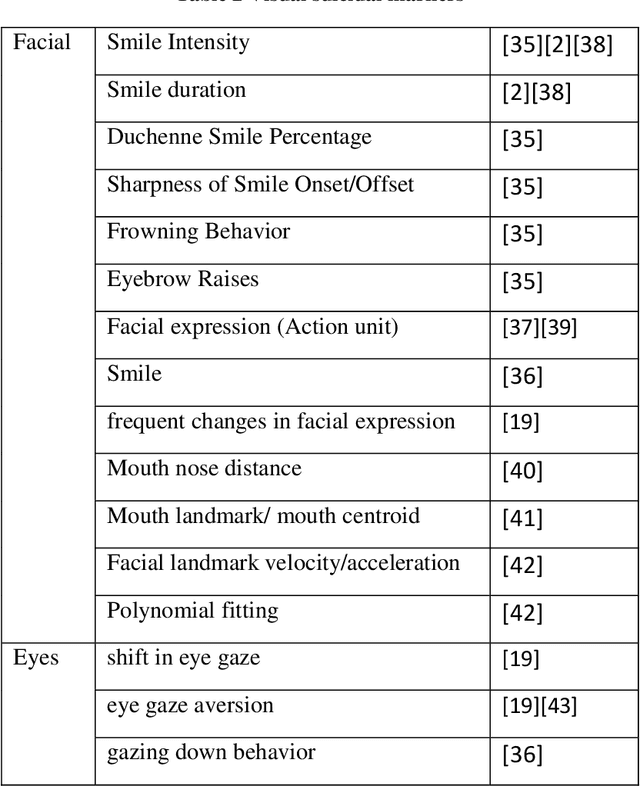
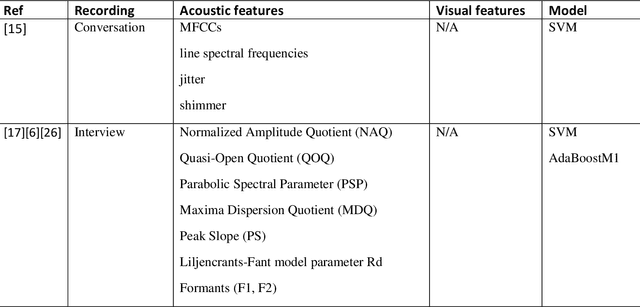
Death by suicide is the seventh of the leading death cause worldwide. The recent advancement in Artificial Intelligence (AI), specifically AI application in image and voice processing, has created a promising opportunity to revolutionize suicide risk assessment. Subsequently, we have witnessed fast-growing literature of researches that applies AI to extract audiovisual non-verbal cues for mental illness assessment. However, the majority of the recent works focus on depression, despite the evident difference between depression signs and suicidal behavior non-verbal cues. In this paper, we review the recent works that study suicide ideation and suicide behavior detection through audiovisual feature analysis, mainly suicidal voice/speech acoustic features analysis and suicidal visual cues.
Backretrieval: An Image-Pivoted Evaluation Metric for Cross-Lingual Text Representations Without Parallel Corpora
May 11, 2021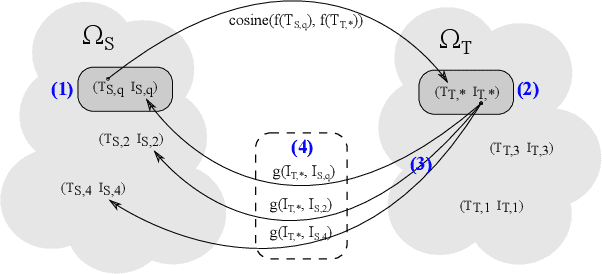
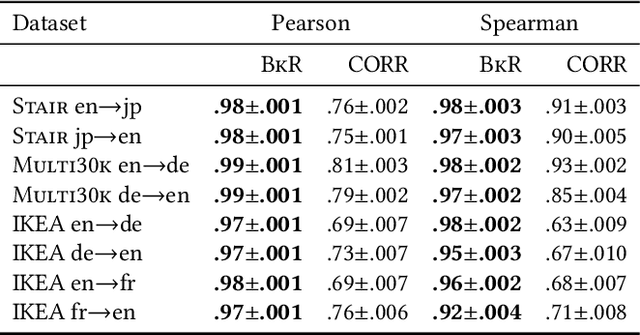
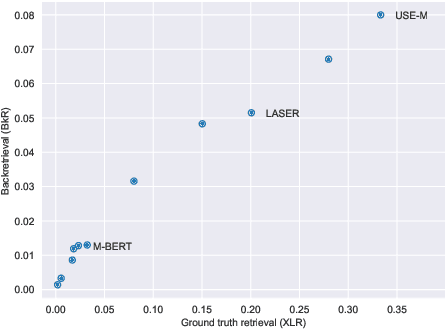
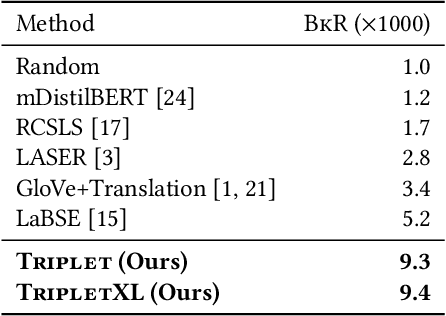
Cross-lingual text representations have gained popularity lately and act as the backbone of many tasks such as unsupervised machine translation and cross-lingual information retrieval, to name a few. However, evaluation of such representations is difficult in the domains beyond standard benchmarks due to the necessity of obtaining domain-specific parallel language data across different pairs of languages. In this paper, we propose an automatic metric for evaluating the quality of cross-lingual textual representations using images as a proxy in a paired image-text evaluation dataset. Experimentally, Backretrieval is shown to highly correlate with ground truth metrics on annotated datasets, and our analysis shows statistically significant improvements over baselines. Our experiments conclude with a case study on a recipe dataset without parallel cross-lingual data. We illustrate how to judge cross-lingual embedding quality with Backretrieval, and validate the outcome with a small human study.
TransZero: Attribute-guided Transformer for Zero-Shot Learning
Dec 03, 2021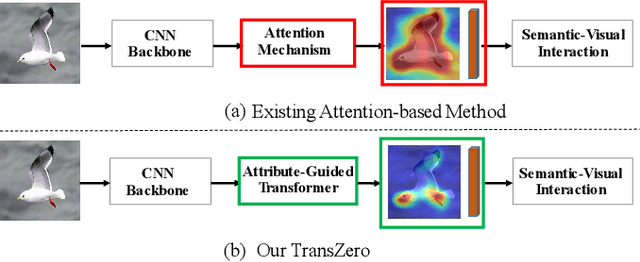
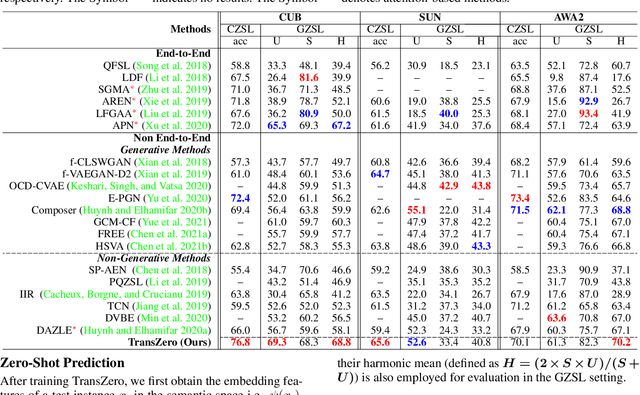
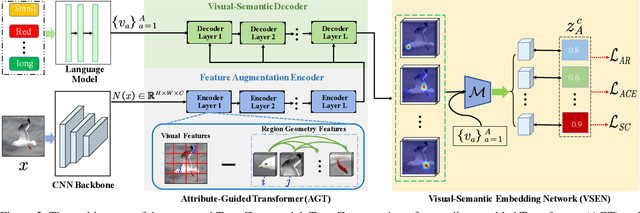
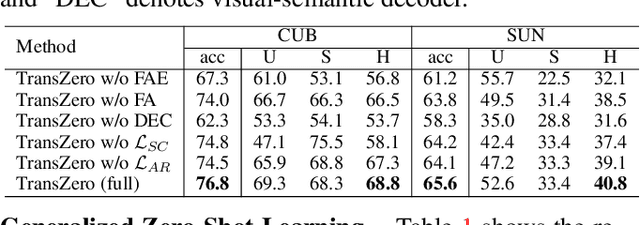
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is learned from attribute descriptions shared between different classes, which act as strong priors for localizing object attributes that represent discriminative region features, enabling significant visual-semantic interaction. Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected. In this paper, we propose an attribute-guided Transformer network, termed TransZero, to refine visual features and learn attribute localization for discriminative visual embedding representations in ZSL. Specifically, TransZero takes a feature augmentation encoder to alleviate the cross-dataset bias between ImageNet and ZSL benchmarks, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. To learn locality-augmented visual features, TransZero employs a visual-semantic decoder to localize the image regions most relevant to each attribute in a given image, under the guidance of semantic attribute information. Then, the locality-augmented visual features and semantic vectors are used to conduct effective visual-semantic interaction in a visual-semantic embedding network. Extensive experiments show that TransZero achieves the new state of the art on three ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero}.
Learning Weakly-Supervised Contrastive Representations
Feb 14, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.