 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Style Transfer with Target Feature Palette and Attention Coloring
Nov 07, 2021
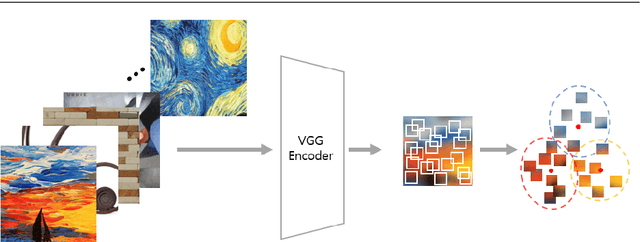
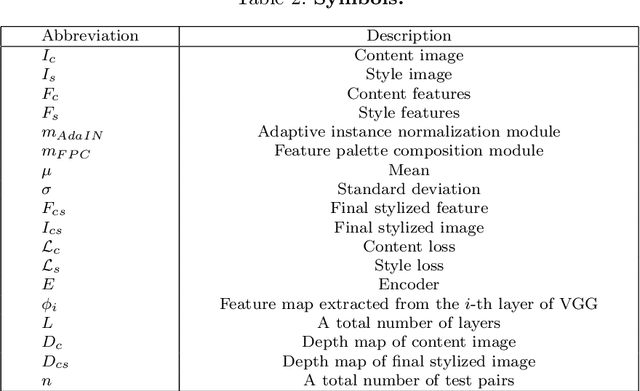
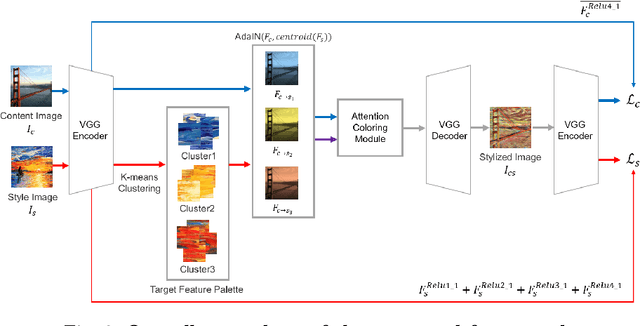
Style transfer has attracted a lot of attentions, as it can change a given image into one with splendid artistic styles while preserving the image structure. However, conventional approaches easily lose image details and tend to produce unpleasant artifacts during style transfer. In this paper, to solve these problems, a novel artistic stylization method with target feature palettes is proposed, which can transfer key features accurately. Specifically, our method contains two modules, namely feature palette composition (FPC) and attention coloring (AC) modules. The FPC module captures representative features based on K-means clustering and produces a feature target palette. The following AC module calculates attention maps between content and style images, and transfers colors and patterns based on the attention map and the target palette. These modules enable the proposed stylization to focus on key features and generate plausibly transferred images. Thus, the contributions of the proposed method are to propose a novel deep learning-based style transfer method and present target feature palette and attention coloring modules, and provide in-depth analysis and insight on the proposed method via exhaustive ablation study. Qualitative and quantitative results show that our stylized images exhibit state-of-the-art performance, with strength in preserving core structures and details of the content image.
Systematic biases when using deep neural networks for annotating large catalogs of astronomical images
Jan 10, 2022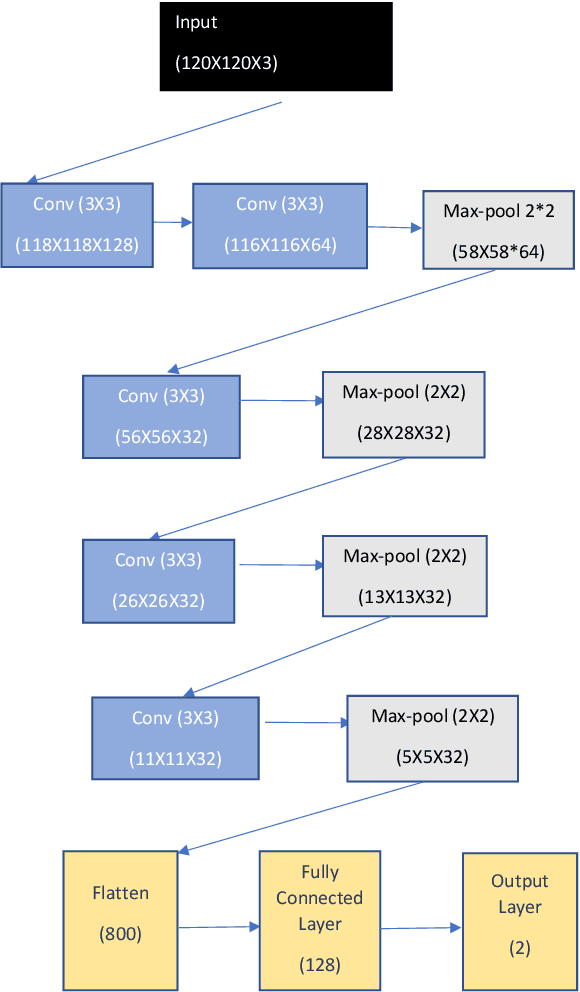
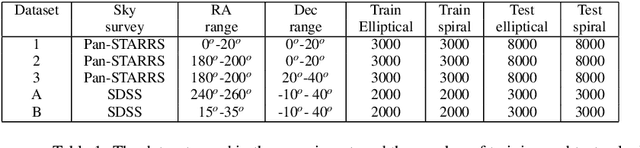
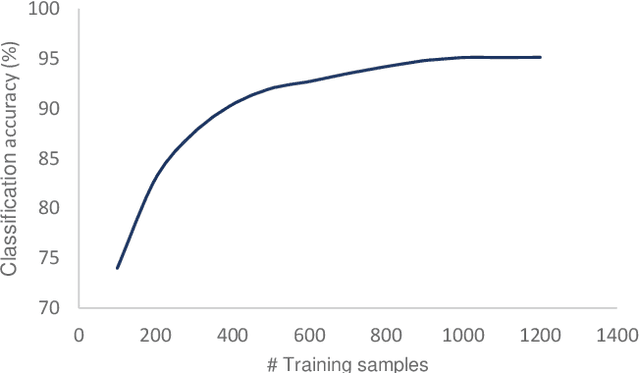
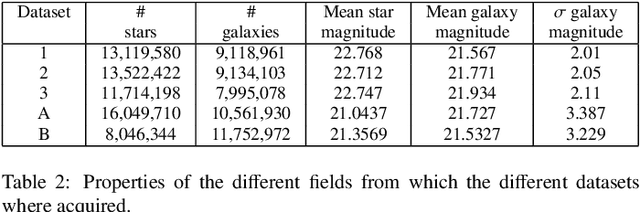
Deep convolutional neural networks (DCNNs) have become the most common solution for automatic image annotation due to their non-parametric nature, good performance, and their accessibility through libraries such as TensorFlow. Among other fields, DCNNs are also a common approach to the annotation of large astronomical image databases acquired by digital sky surveys. One of the main downsides of DCNNs is the complex non-intuitive rules that make DCNNs act as a ``black box", providing annotations in a manner that is unclear to the user. Therefore, the user is often not able to know what information is used by the DCNNs for the classification. Here we demonstrate that the training of a DCNN is sensitive to the context of the training data such as the location of the objects in the sky. We show that for basic classification of elliptical and spiral galaxies, the sky location of the galaxies used for training affects the behavior of the algorithm, and leads to a small but consistent and statistically significant bias. That bias exhibits itself in the form of cosmological-scale anisotropy in the distribution of basic galaxy morphology. Therefore, while DCNNs are powerful tools for annotating images of extended sources, the construction of training sets for galaxy morphology should take into consideration more aspects than the visual appearance of the object. In any case, catalogs created with deep neural networks that exhibit signs of cosmological anisotropy should be interpreted with the possibility of consistent bias.
Data-efficient learning of object-centric grasp preferences
Mar 01, 2022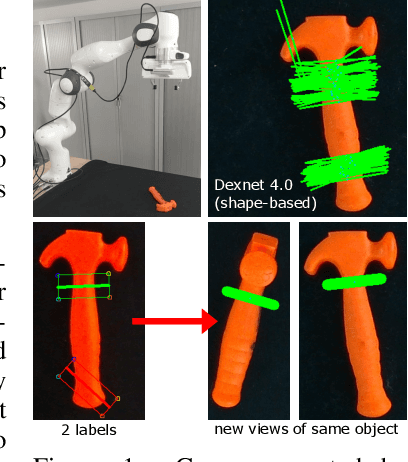
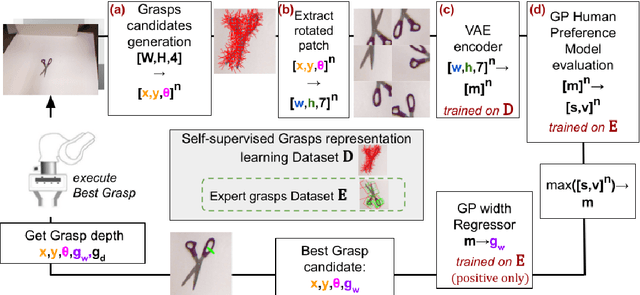
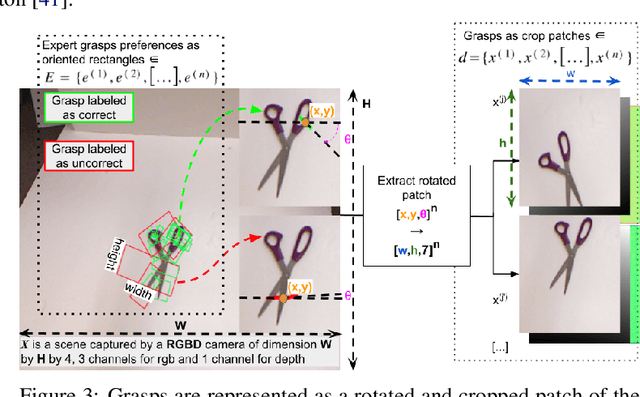

Grasping made impressive progress during the last few years thanks to deep learning. However, there are many objects for which it is not possible to choose a grasp by only looking at an RGB-D image, might it be for physical reasons (e.g., a hammer with uneven mass distribution) or task constraints (e.g., food that should not be spoiled). In such situations, the preferences of experts need to be taken into account. In this paper, we introduce a data-efficient grasping pipeline (Latent Space GP Selector -- LGPS) that learns grasp preferences with only a few labels per object (typically 1 to 4) and generalizes to new views of this object. Our pipeline is based on learning a latent space of grasps with a dataset generated with any state-of-the-art grasp generator (e.g., Dex-Net). This latent space is then used as a low-dimensional input for a Gaussian process classifier that selects the preferred grasp among those proposed by the generator. The results show that our method outperforms both GR-ConvNet and GG-CNN (two state-of-the-art methods that are also based on labeled grasps) on the Cornell dataset, especially when only a few labels are used: only 80 labels are enough to correctly choose 80% of the grasps (885 scenes, 244 objects). Results are similar on our dataset (91 scenes, 28 objects).
Malware Detection Using Frequency Domain-Based Image Visualization and Deep Learning
Jan 26, 2021
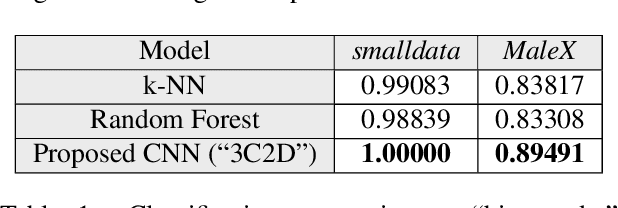

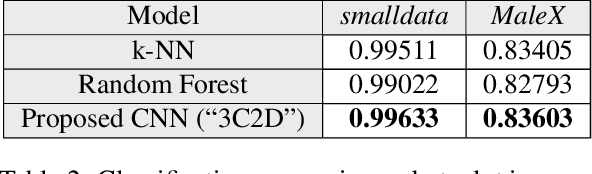
We propose a novel method to detect and visualize malware through image classification. The executable binaries are represented as grayscale images obtained from the count of N-grams (N=2) of bytes in the Discrete Cosine Transform (DCT) domain and a neural network is trained for malware detection. A shallow neural network is trained for classification, and its accuracy is compared with deep-network architectures such as ResNet that are trained using transfer learning. Neither dis-assembly nor behavioral analysis of malware is required for these methods. Motivated by the visual similarity of these images for different malware families, we compare our deep neural network models with standard image features like GIST descriptors to evaluate the performance. A joint feature measure is proposed to combine different features using error analysis to get an accurate ensemble model for improved classification performance. A new dataset called MaleX which contains around 1 million malware and benign Windows executable samples is created for large-scale malware detection and classification experiments. Experimental results are quite promising with 96% binary classification accuracy on MaleX. The proposed model is also able to generalize well on larger unseen malware samples and the results compare favorably with state-of-the-art static analysis-based malware detection algorithms.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021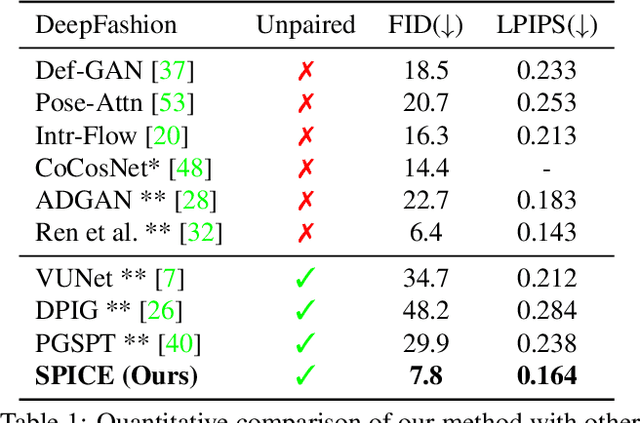
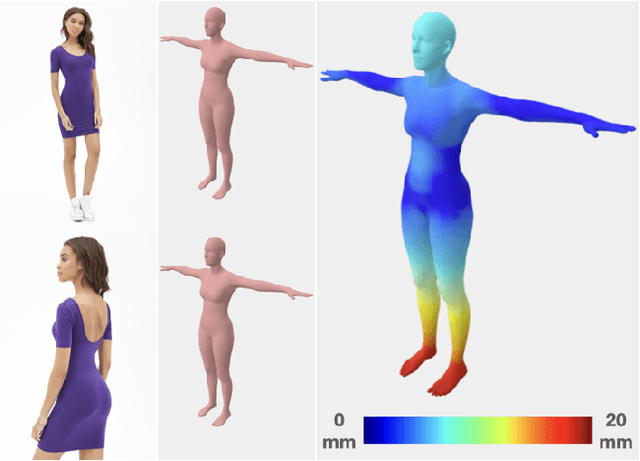

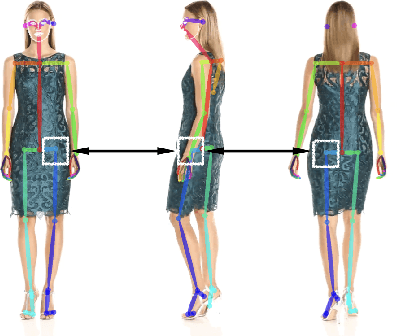
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
2nd Place Solution for IJCAI-PRICAI 2020 3D AI Challenge: 3D Object Reconstruction from A Single Image
May 28, 2021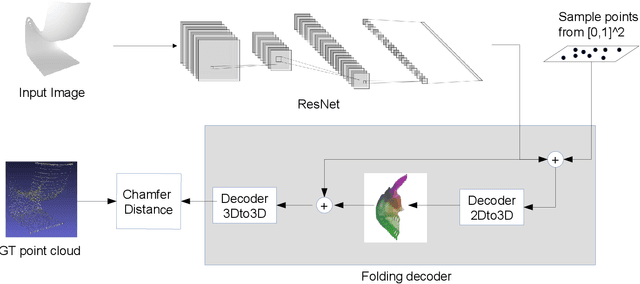



In this paper, we present our solution for the {\it IJCAI--PRICAI--20 3D AI Challenge: 3D Object Reconstruction from A Single Image}. We develop a variant of AtlasNet that consumes single 2D images and generates 3D point clouds through 2D to 3D mapping. To push the performance to the limit and present guidance on crucial implementation choices, we conduct extensive experiments to analyze the influence of decoder design and different settings on the normalization, projection, and sampling methods. Our method achieves 2nd place in the final track with a score of $70.88$, a chamfer distance of $36.87$, and a mean f-score of $59.18$. The source code of our method will be available at https://github.com/em-data/Enhanced_AtlasNet_3DReconstruction.
* 5 pages, 2 figures, 5 tables
Multi-Material Blind Beam Hardening Correction Based on Non-Linearity Adjustment of Projections
Mar 09, 2022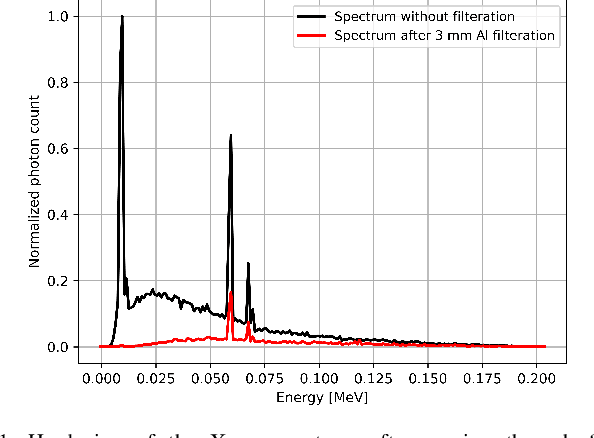
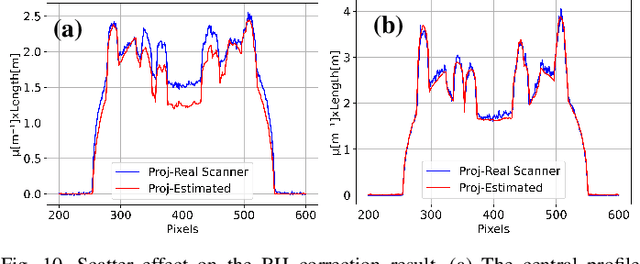
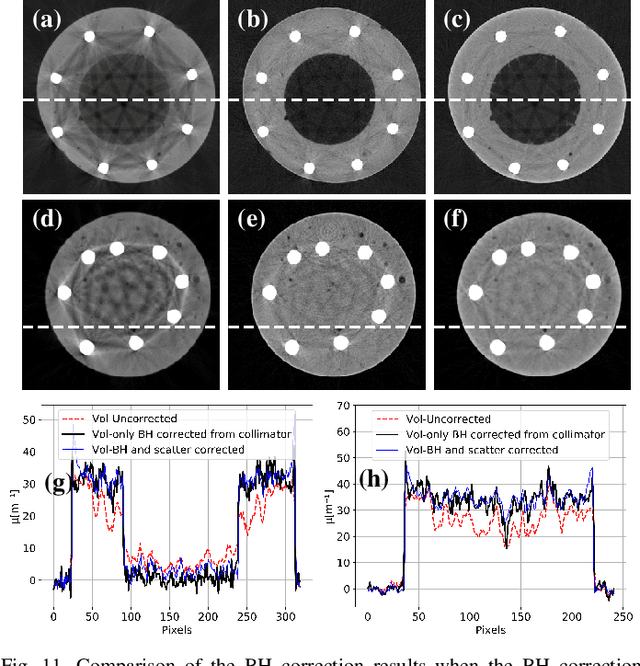
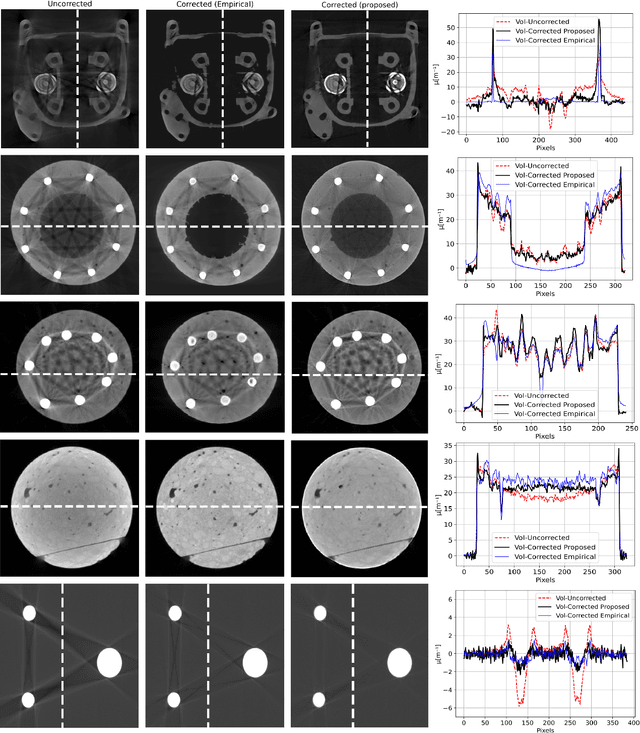
Beam hardening (BH) is one of the major artifacts that severely reduces the quality of Computed Tomography (CT) imaging. In a polychromatic X-ray beam, since low-energy photons are more preferentially absorbed, the attenuation of the beam is no longer a linear function of the absorber thickness. The existing BH correction methods either require a given material, which might be unfeasible in reality, or they require a long computation time. This work aims to propose a fast and accurate BH correction method that requires no prior knowledge of the materials and corrects first and higher-order BH artifacts. In the first step, a wide sweep of the material is performed based on an experimentally measured look-up table to obtain the closest estimate of the material. Then the non-linearity effect of the BH is corrected by adding the difference between the estimated monochromatic and the polychromatic simulated projections of the segmented image. The estimated monochromatic projection is simulated by selecting the energy from the polychromatic spectrum which produces the lowest mean square error (MSE) with the acquired projection from the scanner. The polychromatic projection is estimated by minimizing the difference between the acquired projection and the weighted sum of the simulated polychromatic projections using different spectra of different filtration. To evaluate the proposed BH correction method, we have conducted extensive experiments on the real-world CT data. Compared to the state-of-the-art empirical BH correction method, the experiments show that the proposed method can highly reduce the BH artifacts without prior knowledge of the materials.
Robust Autoencoder GAN for Cryo-EM Image Denoising
Aug 17, 2020
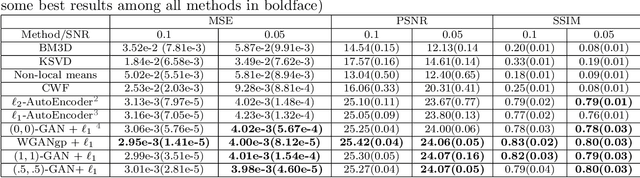
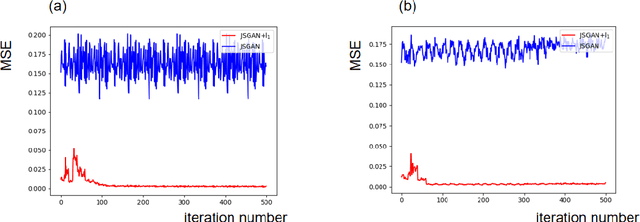
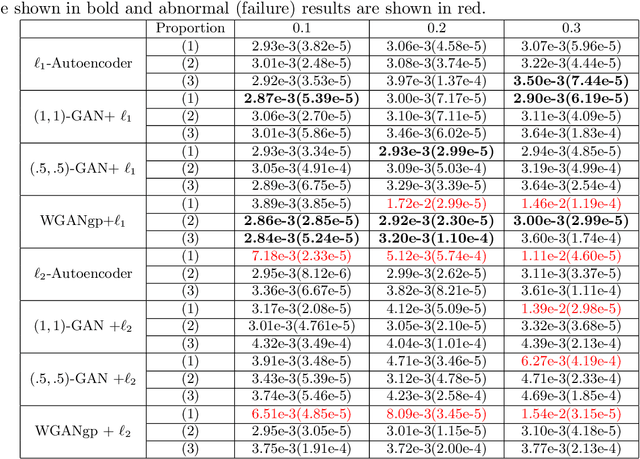
The cryo-electron microscopy (Cryo-EM) becomes popular for macromolecular structure determination. However, the 2D images which Cryo-EM detects are of high noise and often mixed with multiple heterogeneous conformations or contamination, imposing a challenge for denoising. Traditional image denoising methods can not remove Cryo-EM image noise well when the signal-noise-ratio (SNR) of images is meager. Thus it is desired to develop new effective denoising techniques to facilitate further research such as 3D reconstruction, 2D conformation classification, and so on. In this paper, we approach the robust image denoising problem in Cryo-EM by a joint Autoencoder and Generative Adversarial Networks (GAN) method. Equipped with robust $\ell_1$ Autoencoder and some designs of robust $\beta$-GANs, one can stabilize the training of GANs and achieve the state-of-the-art performance of robust denoising with low SNR data and against possible information contamination. The method is evaluated by both a heterogeneous conformational dataset on the Thermus aquaticus RNA Polymerase (RNAP) and a homogenous dataset on the Plasmodium falciparum 80S ribosome dataset (EMPIRE-10028), in terms of Mean Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), as well as heterogeneous conformation clustering. These results suggest that our proposed methodology provides an effective tool for Cryo-EM 2D image denoising.
SISE-PC: Semi-supervised Image Subsampling for Explainable Pathology
Feb 23, 2021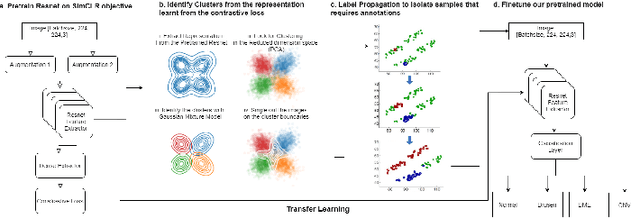
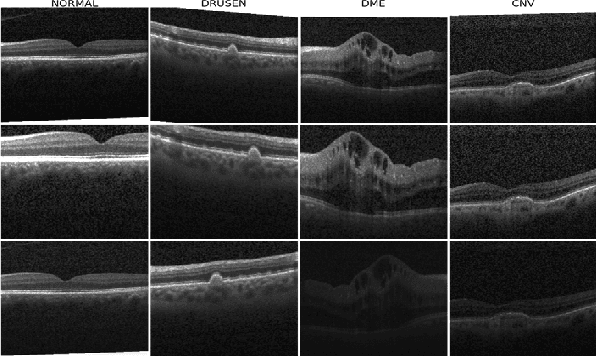
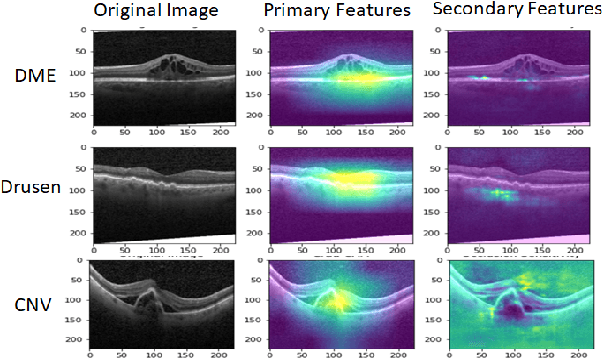
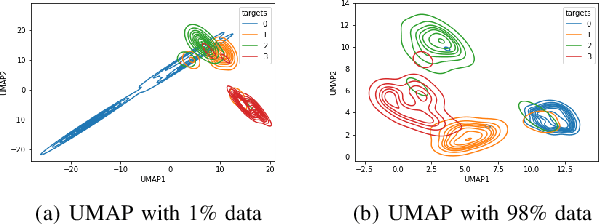
Although automated pathology classification using deep learning (DL) has proved to be predictively efficient, DL methods are found to be data and compute cost intensive. In this work, we aim to reduce DL training costs by pre-training a Resnet feature extractor using SimCLR contrastive loss for latent encoding of OCT images. We propose a novel active learning framework that identifies a minimal sub-sampled dataset containing the most uncertain OCT image samples using label propagation on the SimCLR latent encodings. The pre-trained Resnet model is then fine-tuned with the labelled minimal sub-sampled data and the underlying pathological sites are visually explained. Our framework identifies upto 2% of OCT images to be most uncertain that need prioritized specialist attention and that can fine-tune a Resnet model to achieve upto 97% classification accuracy. The proposed method can be extended to other medical images to minimize prediction costs.
Indirect Domain Shift for Single Image Dehazing
Feb 05, 2021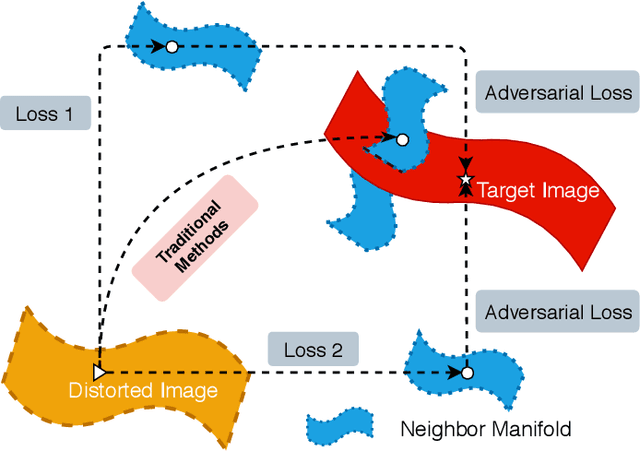

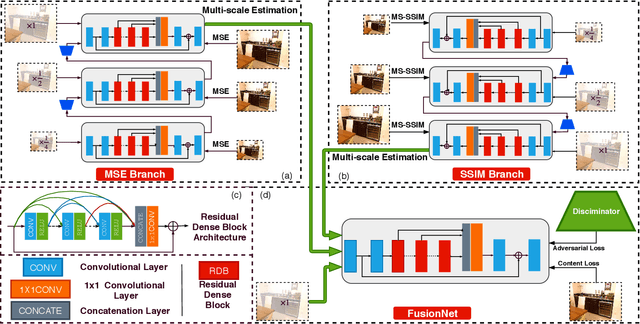
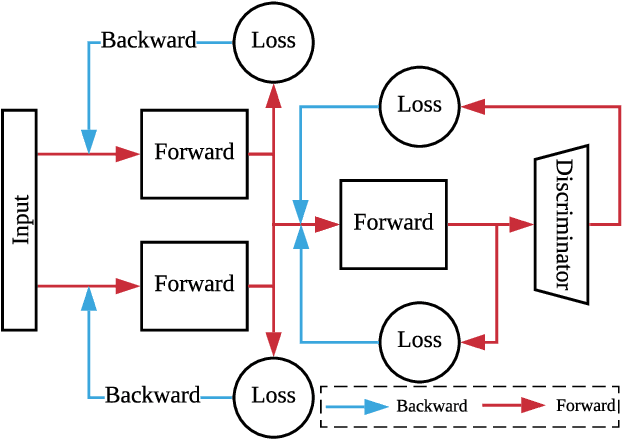
Despite their remarkable expressibility, convolution neural networks (CNNs) still fall short of delivering satisfactory results on single image dehazing, especially in terms of faithful recovery of fine texture details. In this paper, we argue that the inadequacy of conventional CNN-based dehazing methods can be attributed to the fact that the domain of hazy images is too far away from that of clear images, rendering it difficult to train a CNN for learning direct domain shift through an end-to-end manner and recovering texture details simultaneously. To address this issue, we propose to add explicit constraints inside a deep CNN model to guide the restoration process. In contrast to direct learning, the proposed mechanism shifts and narrows the candidate region for the estimation output via multiple confident neighborhoods. Therefore, it is capable of consolidating the expressibility of different architectures, resulting in a more accurate indirect domain shift (IDS) from the hazy images to that of clear images. We also propose two different training schemes, including hard IDS and soft IDS, which further reveal the effectiveness of the proposed method. Our extensive experimental results indicate that the dehazing method based on this mechanism outperforms the state-of-the-arts.