 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hamilton-Jacobi equations on graphs with applications to semi-supervised learning and data depth
Feb 25, 2022
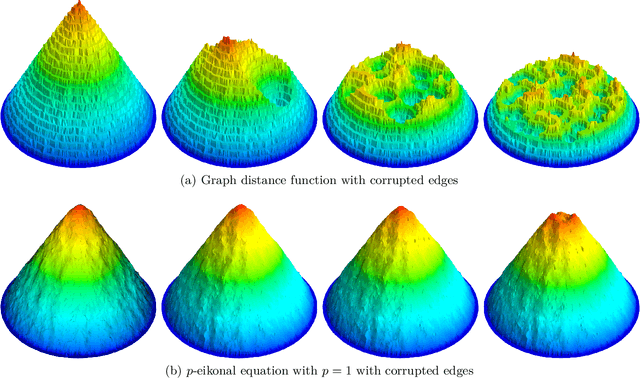
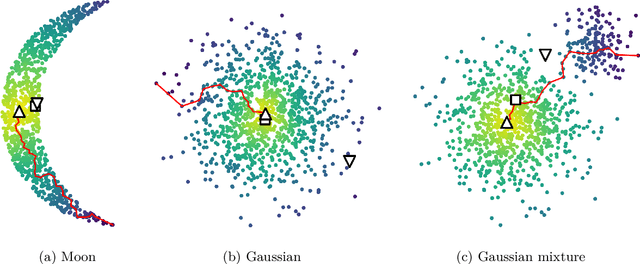
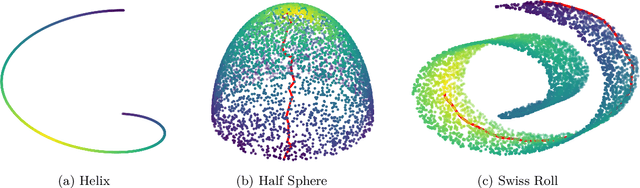
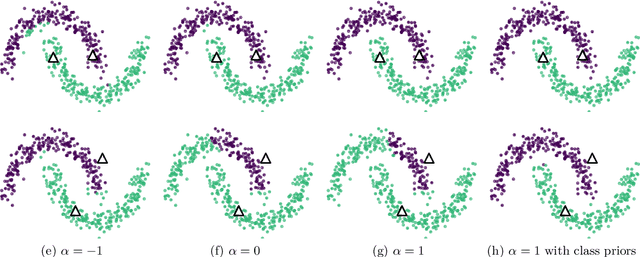
Shortest path graph distances are widely used in data science and machine learning, since they can approximate the underlying geodesic distance on the data manifold. However, the shortest path distance is highly sensitive to the addition of corrupted edges in the graph, either through noise or an adversarial perturbation. In this paper we study a family of Hamilton-Jacobi equations on graphs that we call the $p$-eikonal equation. We show that the $p$-eikonal equation with $p=1$ is a provably robust distance-type function on a graph, and the $p\to \infty$ limit recovers shortest path distances. While the $p$-eikonal equation does not correspond to a shortest-path graph distance, we nonetheless show that the continuum limit of the $p$-eikonal equation on a random geometric graph recovers a geodesic density weighted distance in the continuum. We consider applications of the $p$-eikonal equation to data depth and semi-supervised learning, and use the continuum limit to prove asymptotic consistency results for both applications. Finally, we show the results of experiments with data depth and semi-supervised learning on real image datasets, including MNIST, FashionMNIST and CIFAR-10, which show that the $p$-eikonal equation offers significantly better results compared to shortest path distances.
Conditional Sequential Modulation for Efficient Global Image Retouching
Sep 22, 2020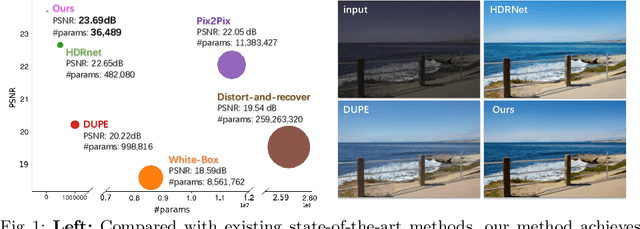
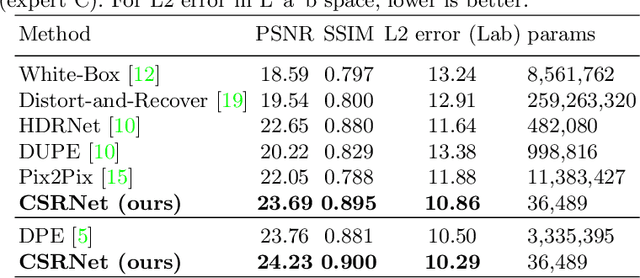
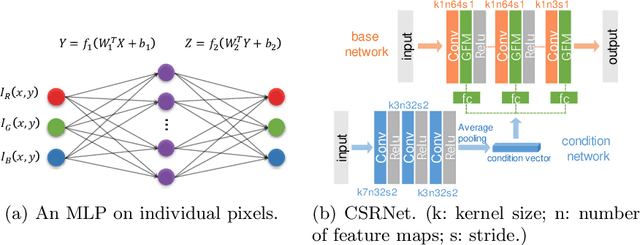
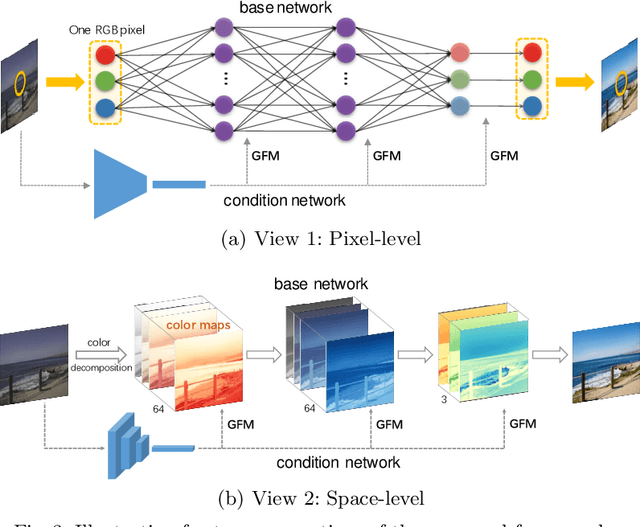
Photo retouching aims at enhancing the aesthetic visual quality of images that suffer from photographic defects such as over/under exposure, poor contrast, inharmonious saturation. Practically, photo retouching can be accomplished by a series of image processing operations. In this paper, we investigate some commonly-used retouching operations and mathematically find that these pixel-independent operations can be approximated or formulated by multi-layer perceptrons (MLPs). Based on this analysis, we propose an extremely light-weight framework - Conditional Sequential Retouching Network (CSRNet) - for efficient global image retouching. CSRNet consists of a base network and a condition network. The base network acts like an MLP that processes each pixel independently and the condition network extracts the global features of the input image to generate a condition vector. To realize retouching operations, we modulate the intermediate features using Global Feature Modulation (GFM), of which the parameters are transformed by condition vector. Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37k trainable parameters, which is orders of magnitude smaller than existing learning-based methods. Extensive experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. Code is available at https://github.com/hejingwenhejingwen/CSRNet.
Revisiting Deep Semi-supervised Learning: An Empirical Distribution Alignment Framework and Its Generalization Bound
Mar 13, 2022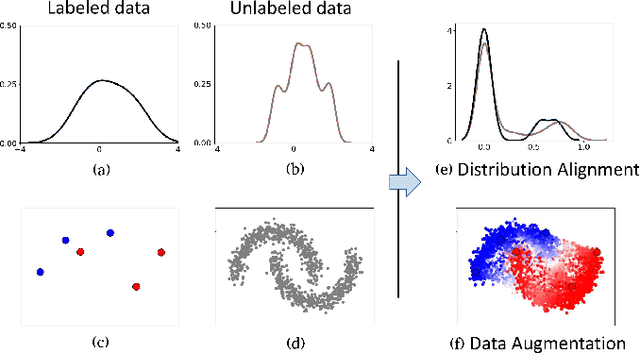
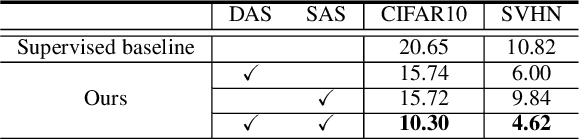
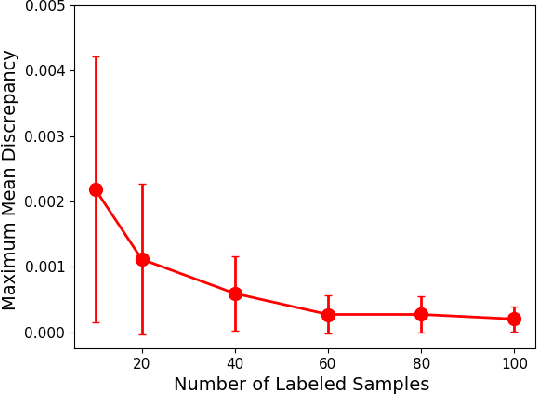
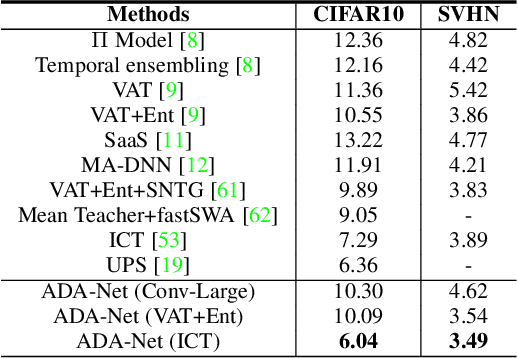
In this work, we revisit the semi-supervised learning (SSL) problem from a new perspective of explicitly reducing empirical distribution mismatch between labeled and unlabeled samples. Benefited from this new perspective, we first propose a new deep semi-supervised learning framework called Semi-supervised Learning by Empirical Distribution Alignment (SLEDA), in which existing technologies from the domain adaptation community can be readily used to address the semi-supervised learning problem through reducing the empirical distribution distance between labeled and unlabeled data. Based on this framework, we also develop a new theoretical generalization bound for the research community to better understand the semi-supervised learning problem, in which we show the generalization error of semi-supervised learning can be effectively bounded by minimizing the training error on labeled data and the empirical distribution distance between labeled and unlabeled data. Building upon our new framework and the theoretical bound, we develop a simple and effective deep semi-supervised learning method called Augmented Distribution Alignment Network (ADA-Net) by simultaneously adopting the well-established adversarial training strategy from the domain adaptation community and a simple sample interpolation strategy for data augmentation. Additionally, we incorporate both strategies in our ADA-Net into two exiting SSL methods to further improve their generalization capability, which indicates that our new framework provides a complementary solution for solving the SSL problem. Our comprehensive experimental results on two benchmark datasets SVHN and CIFAR-10 for the semi-supervised image recognition task and another two benchmark datasets ModelNet40 and ShapeNet55 for the semi-supervised point cloud recognition task demonstrate the effectiveness of our proposed framework for SSL.
DelTact: A Vision-based Tactile Sensor Using Dense Color Pattern
Feb 15, 2022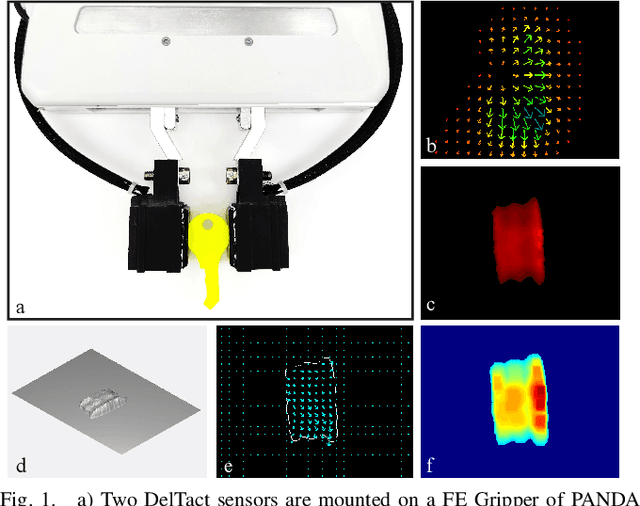
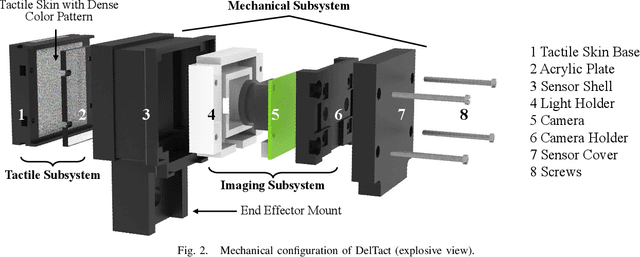

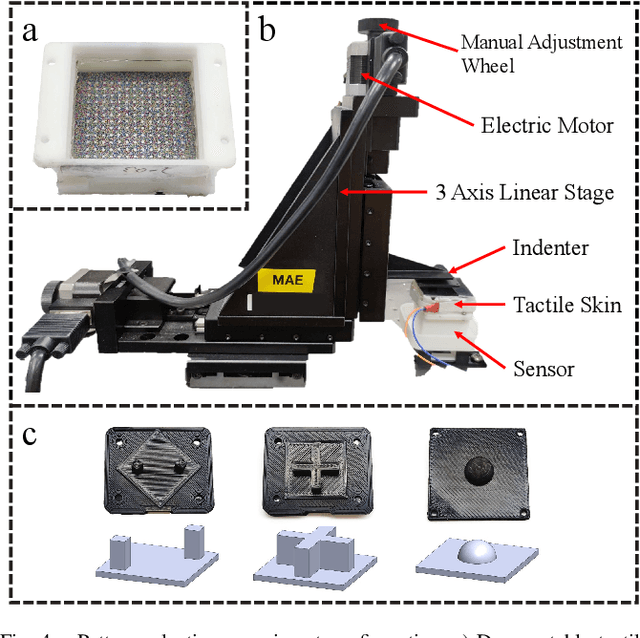
Tactile sensing is an essential perception for robots to complete dexterous tasks. As a promising tactile sensing technique, vision-based tactile sensors have been developed to improve robot performance in manipulation and grasping. Here we propose a new design of vision-based tactile sensor, DelTact, with its high-resolution sensing abilities of surface contact measurement. The sensor uses a modular hardware architecture for compactness whilst maintaining a robust overall design. Moreover, it adopts an improved dense random color pattern based on the previous version to achieve high accuracy of contact deformation tracking. In particular, we optimize the color pattern generation process and select the appropriate pattern for coordinating with a dense optical flow algorithm in a real-world experimental sensory setting using various objects for contact. The optical flow obtained from the raw image is processed to determine shape and force distribution on the contact surface. This sensor can be easily integrated with a parallel gripper where experimental results using qualitative and quantitative analysis demonstrate that the sensor is capable of providing tactile measurements with high temporal and spatial resolution.
StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
Nov 04, 2021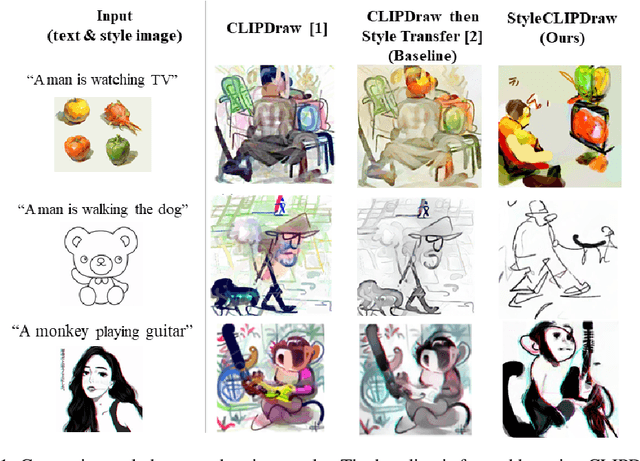
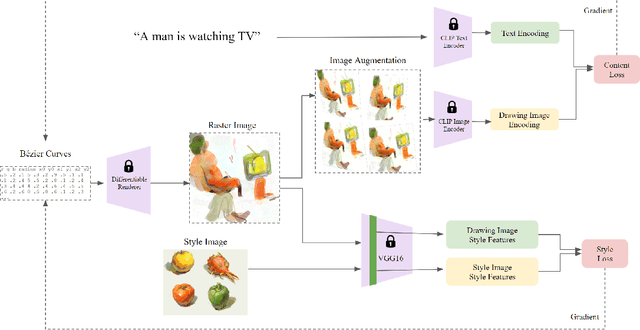

Generating images that fit a given text description using machine learning has improved greatly with the release of technologies such as the CLIP image-text encoder model; however, current methods lack artistic control of the style of image to be generated. We introduce StyleCLIPDraw which adds a style loss to the CLIPDraw text-to-drawing synthesis model to allow artistic control of the synthesized drawings in addition to control of the content via text. Whereas performing decoupled style transfer on a generated image only affects the texture, our proposed coupled approach is able to capture a style in both texture and shape, suggesting that the style of the drawing is coupled with the drawing process itself. More results and our code are available at https://github.com/pschaldenbrand/StyleCLIPDraw
Real Image Super Resolution Via Heterogeneous Model using GP-NAS
Sep 02, 2020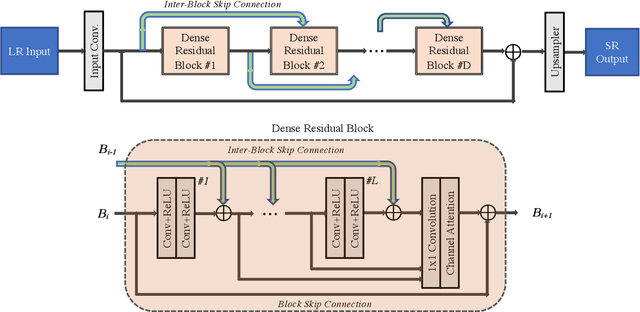
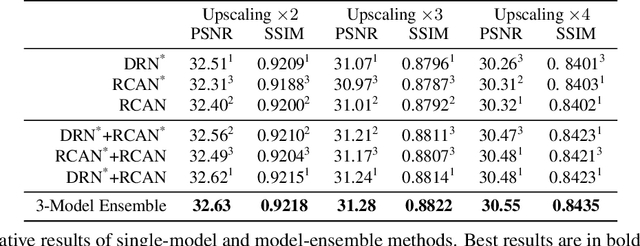
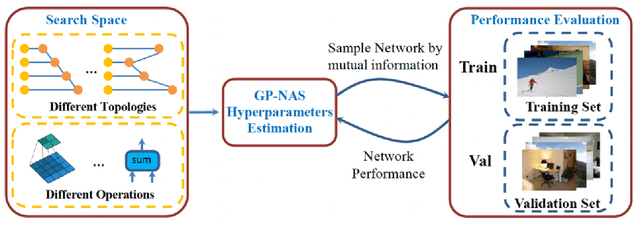
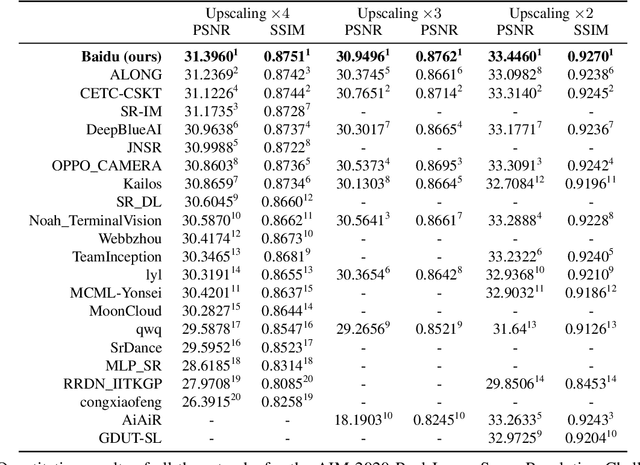
With advancement in deep neural network (DNN), recent state-of-the-art (SOTA) image superresolution (SR) methods have achieved impressive performance using deep residual network with dense skip connections. While these models perform well on benchmark dataset where low-resolution (LR) images are constructed from high-resolution (HR) references with known blur kernel, real image SR is more challenging when both images in the LR-HR pair are collected from real cameras. Based on existing dense residual networks, a Gaussian process based neural architecture search (GP-NAS) scheme is utilized to find candidate network architectures using a large search space by varying the number of dense residual blocks, the block size and the number of features. A suite of heterogeneous models with diverse network structure and hyperparameter are selected for model-ensemble to achieve outstanding performance in real image SR. The proposed method won the first place in all three tracks of the AIM 2020 Real Image Super-Resolution Challenge.
Tackling the Class Imbalance Problem of Deep Learning Based Head and Neck Organ Segmentation
Jan 05, 2022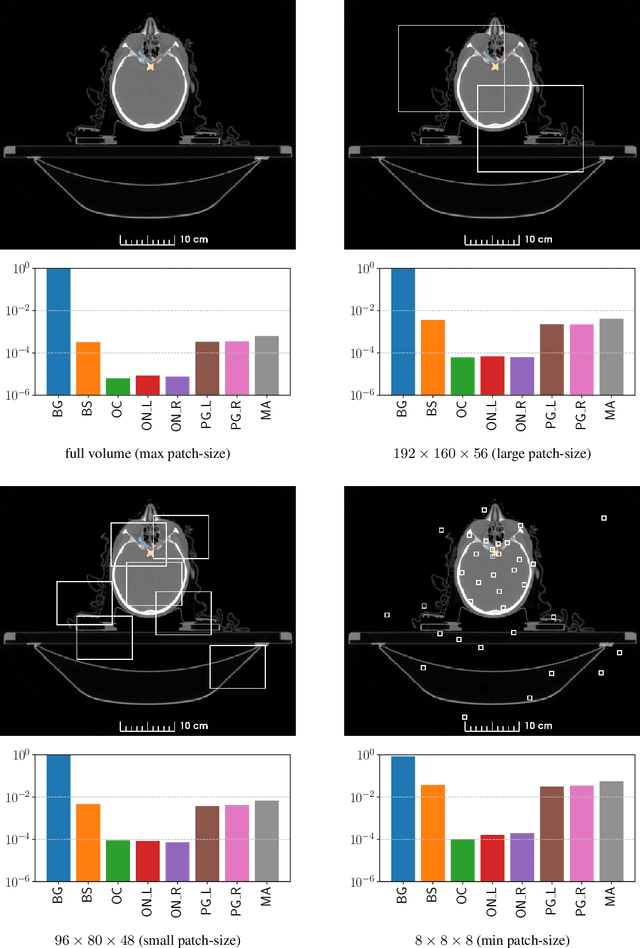
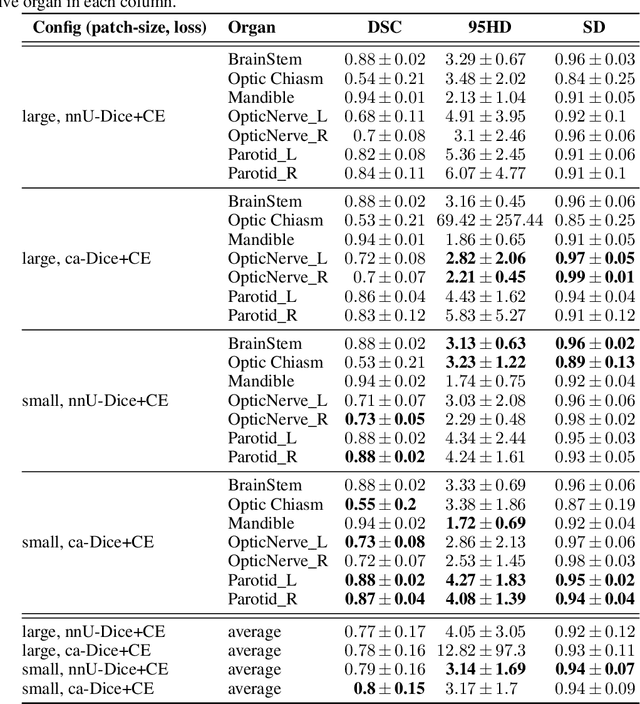
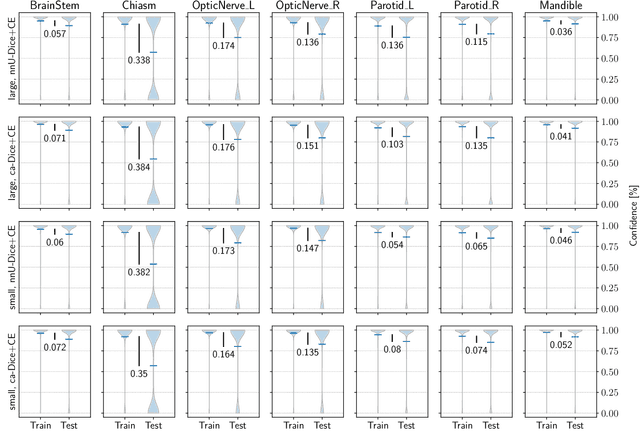
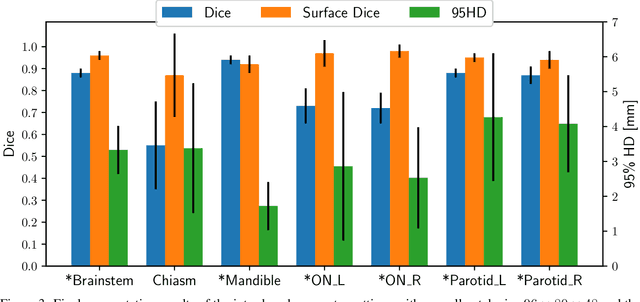
The segmentation of organs at risk (OAR) is a required precondition for the cancer treatment with image guided radiation therapy. The automation of the segmentation task is therefore of high clinical relevance. Deep Learning (DL) based medical image segmentation is currently the most successful approach, but suffers from the over-presence of the background class and the anatomically given organ size difference, which is most severe in the head and neck (HAN) area. To tackle the HAN area specific class imbalance problem we first optimize the patch-size of the currently best performing general purpose segmentation framework, the nnU-Net, based on the introduced class imbalance measurement, and second, introduce the class adaptive Dice loss to further compensate for the highly imbalanced setting. Both the patch-size and the loss function are parameters with direct influence on the class imbalance and their optimization leads to a 3\% increase of the Dice score and 22% reduction of the 95% Hausdorff distance compared to the baseline, finally reaching $0.8\pm0.15$ and $3.17\pm1.7$ mm for the segmentation of seven HAN organs using a single and simple neural network. The patch-size optimization and the class adaptive Dice loss are both simply integrable in current DL based segmentation approaches and allow to increase the performance for class imbalanced segmentation tasks.
FWB-Net:Front White Balance Network for Color Shift Correction in Single Image Dehazing via Atmospheric Light Estimation
Jan 21, 2021
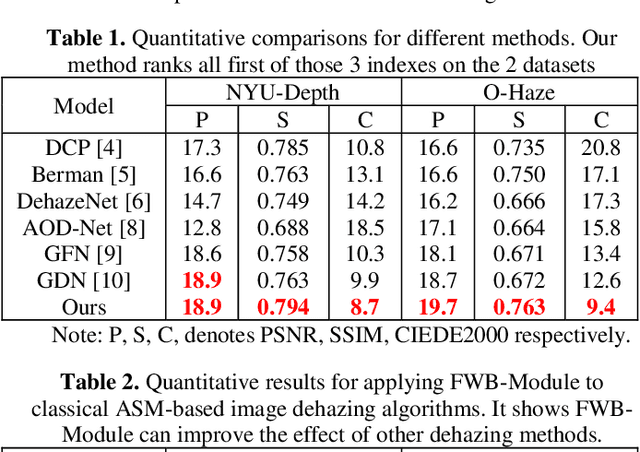
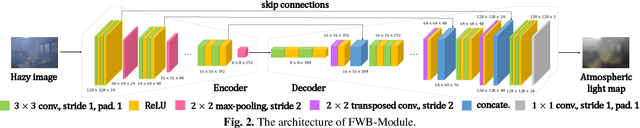
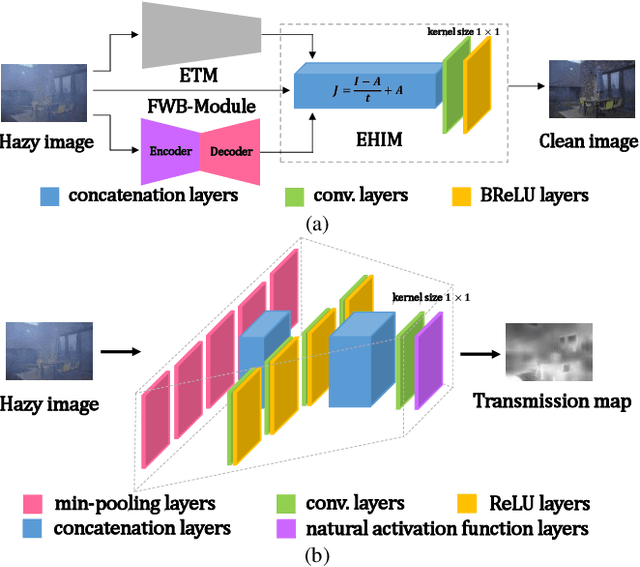
In recent years, single image dehazing deep models based on Atmospheric Scattering Model (ASM) have achieved remarkable results. But the dehazing outputs of those models suffer from color shift. Analyzing the ASM model shows that the atmospheric light factor (ALF) is set as a scalar which indicates ALF is constant for whole image. However, for images taken in real-world, the illumination is not uniformly distributed over whole image which brings model mismatch and possibly results in color shift of the deep models using ASM. Bearing this in mind, in this study, first, a new non-homogeneous atmospheric scattering model (NH-ASM) is proposed for improving image modeling of hazy images taken under complex illumination conditions. Second, a new U-Net based front white balance module (FWB-Module) is dedicatedly designed to correct color shift before generating dehazing result via atmospheric light estimation. Third, a new FWB loss is innovatively developed for training FWB-Module, which imposes penalty on color shift. In the end, based on NH-ASM and front white balance technology, an end-to-end CNN-based color-shift-restraining dehazing network is developed, termed as FWB-Net. Experimental results demonstrate the effectiveness and superiority of our proposed FWB-Net for dehazing on both synthetic and real-world images.
Domain Adaptation based Technique for Image Emotion Recognition using Pre-trained Facial Expression Recognition Models
Nov 17, 2020

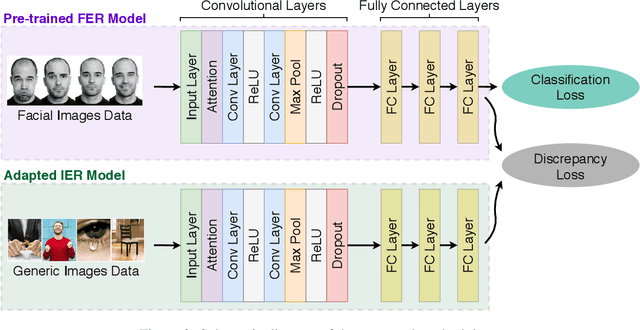
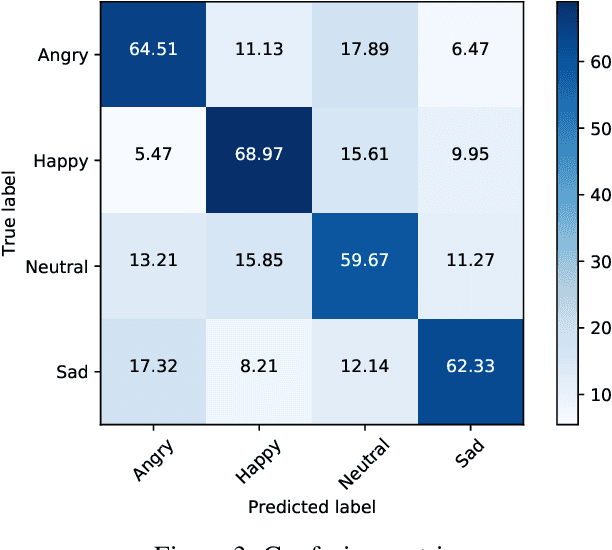
In this paper, a domain adaptation based technique for recognizing the emotions in images containing facial, non-facial, and non-human components has been proposed. We have also proposed a novel technique to explain the proposed system's predictions in terms of Intersection Score. Image emotion recognition is useful for graphics, gaming, animation, entertainment, and cinematography. However, well-labeled large scale datasets and pre-trained models are not available for image emotion recognition. To overcome this challenge, we have proposed a deep learning approach based on an attentional convolutional network that adapts pre-trained facial expression recognition models. It detects the visual features of an image and performs emotion classification based on them. The experiments have been performed on the Flickr image dataset, and the images have been classified in 'angry,' 'happy,' 'sad,' and 'neutral' emotion classes. The proposed system has demonstrated better performance than the benchmark results with an accuracy of 63.87% for image emotion recognition. We have also analyzed the embedding plots for various emotion classes to explain the proposed system's predictions.
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
Mar 09, 2022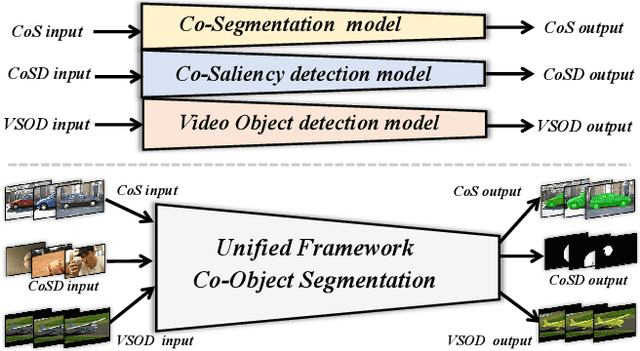
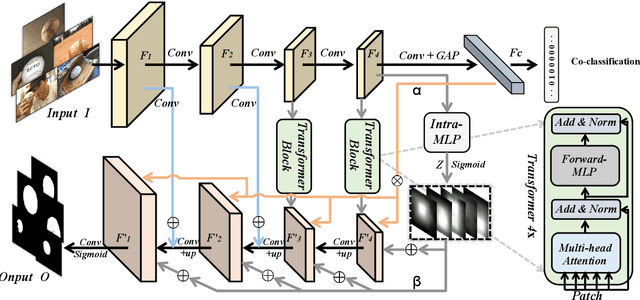
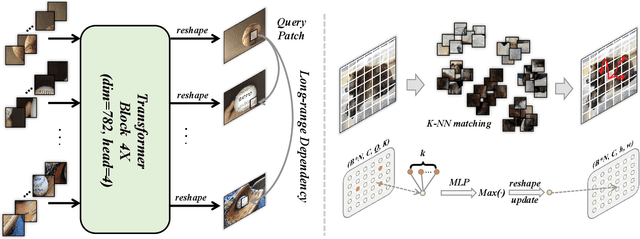
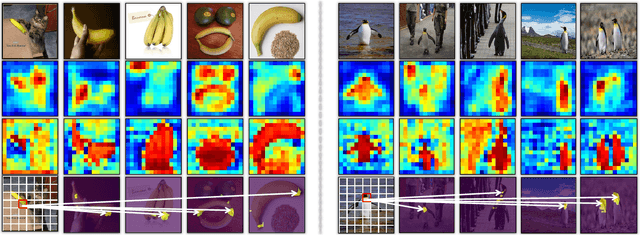
Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transferability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in real-time.