 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Deep Semi-supervised Learning: An Empirical Distribution Alignment Framework and Its Generalization Bound
Mar 13, 2022
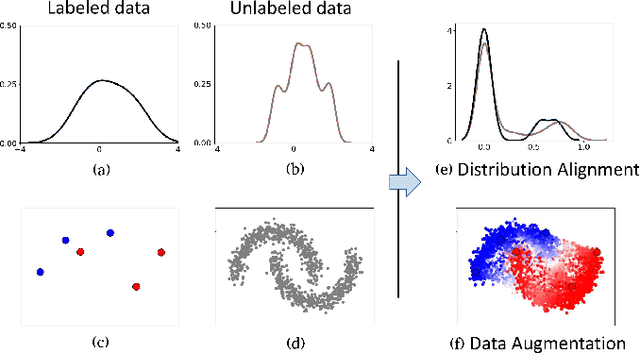
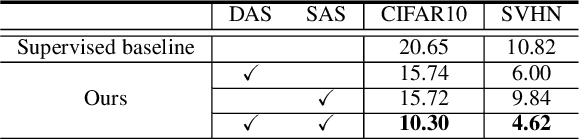
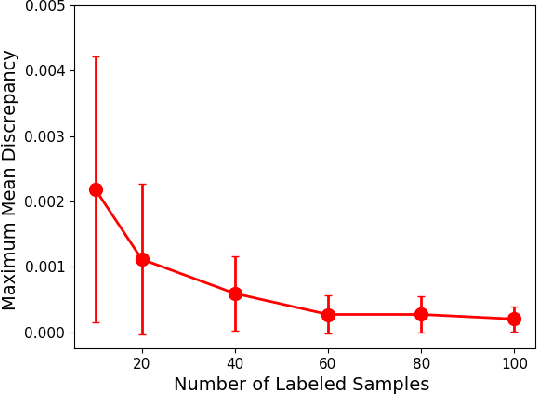
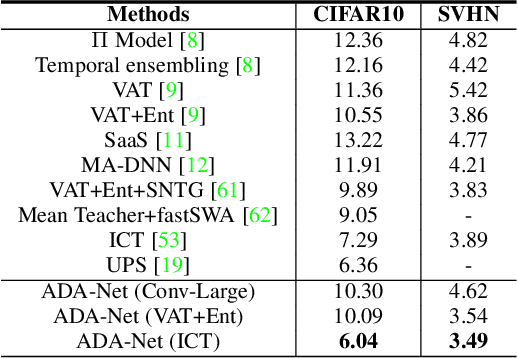
In this work, we revisit the semi-supervised learning (SSL) problem from a new perspective of explicitly reducing empirical distribution mismatch between labeled and unlabeled samples. Benefited from this new perspective, we first propose a new deep semi-supervised learning framework called Semi-supervised Learning by Empirical Distribution Alignment (SLEDA), in which existing technologies from the domain adaptation community can be readily used to address the semi-supervised learning problem through reducing the empirical distribution distance between labeled and unlabeled data. Based on this framework, we also develop a new theoretical generalization bound for the research community to better understand the semi-supervised learning problem, in which we show the generalization error of semi-supervised learning can be effectively bounded by minimizing the training error on labeled data and the empirical distribution distance between labeled and unlabeled data. Building upon our new framework and the theoretical bound, we develop a simple and effective deep semi-supervised learning method called Augmented Distribution Alignment Network (ADA-Net) by simultaneously adopting the well-established adversarial training strategy from the domain adaptation community and a simple sample interpolation strategy for data augmentation. Additionally, we incorporate both strategies in our ADA-Net into two exiting SSL methods to further improve their generalization capability, which indicates that our new framework provides a complementary solution for solving the SSL problem. Our comprehensive experimental results on two benchmark datasets SVHN and CIFAR-10 for the semi-supervised image recognition task and another two benchmark datasets ModelNet40 and ShapeNet55 for the semi-supervised point cloud recognition task demonstrate the effectiveness of our proposed framework for SSL.
Hamilton-Jacobi equations on graphs with applications to semi-supervised learning and data depth
Feb 25, 2022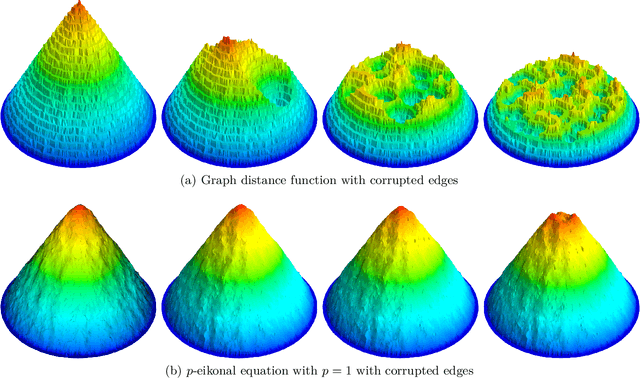
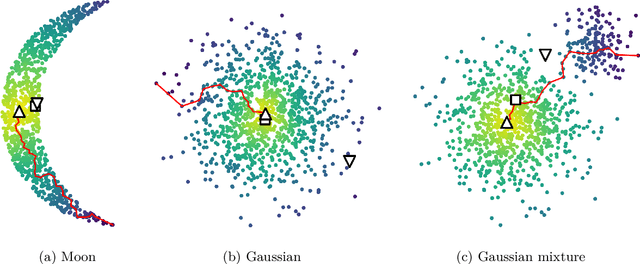
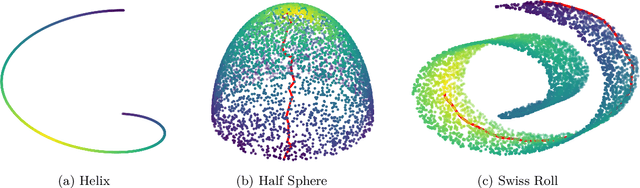
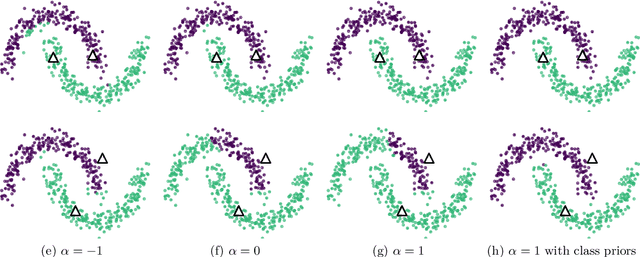
Shortest path graph distances are widely used in data science and machine learning, since they can approximate the underlying geodesic distance on the data manifold. However, the shortest path distance is highly sensitive to the addition of corrupted edges in the graph, either through noise or an adversarial perturbation. In this paper we study a family of Hamilton-Jacobi equations on graphs that we call the $p$-eikonal equation. We show that the $p$-eikonal equation with $p=1$ is a provably robust distance-type function on a graph, and the $p\to \infty$ limit recovers shortest path distances. While the $p$-eikonal equation does not correspond to a shortest-path graph distance, we nonetheless show that the continuum limit of the $p$-eikonal equation on a random geometric graph recovers a geodesic density weighted distance in the continuum. We consider applications of the $p$-eikonal equation to data depth and semi-supervised learning, and use the continuum limit to prove asymptotic consistency results for both applications. Finally, we show the results of experiments with data depth and semi-supervised learning on real image datasets, including MNIST, FashionMNIST and CIFAR-10, which show that the $p$-eikonal equation offers significantly better results compared to shortest path distances.
Physics-based Shading Reconstruction for Intrinsic Image Decomposition
Sep 03, 2020We investigate the use of photometric invariance and deep learning to compute intrinsic images (albedo and shading). We propose albedo and shading gradient descriptors which are derived from physics-based models. Using the descriptors, albedo transitions are masked out and an initial sparse shading map is calculated directly from the corresponding RGB image gradients in a learning-free unsupervised manner. Then, an optimization method is proposed to reconstruct the full dense shading map. Finally, we integrate the generated shading map into a novel deep learning framework to refine it and also to predict corresponding albedo image to achieve intrinsic image decomposition. By doing so, we are the first to directly address the texture and intensity ambiguity problems of the shading estimations. Large scale experiments show that our approach steered by physics-based invariant descriptors achieve superior results on MIT Intrinsics, NIR-RGB Intrinsics, Multi-Illuminant Intrinsic Images, Spectral Intrinsic Images, As Realistic As Possible, and competitive results on Intrinsic Images in the Wild datasets while achieving state-of-the-art shading estimations.
DelTact: A Vision-based Tactile Sensor Using Dense Color Pattern
Feb 15, 2022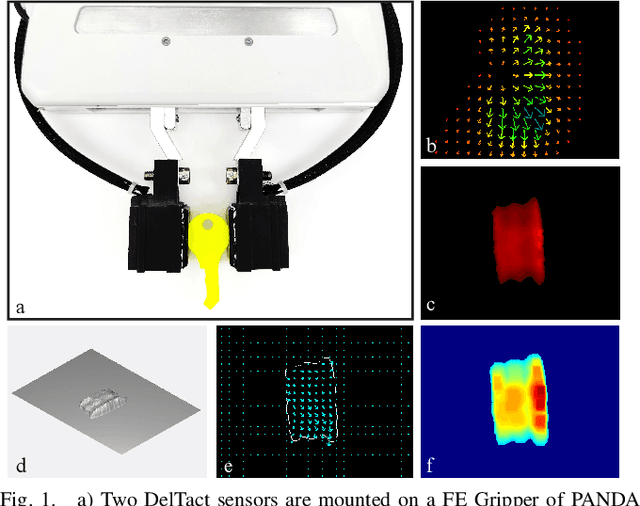
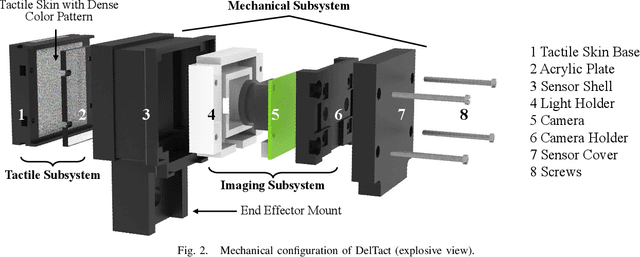

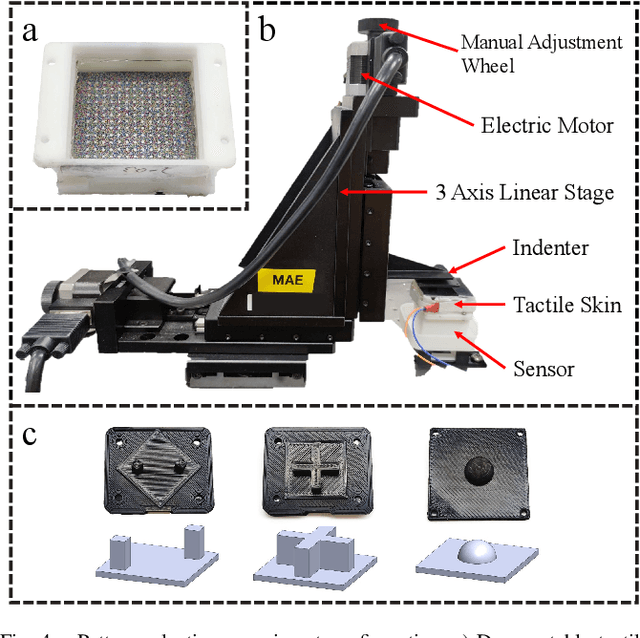
Tactile sensing is an essential perception for robots to complete dexterous tasks. As a promising tactile sensing technique, vision-based tactile sensors have been developed to improve robot performance in manipulation and grasping. Here we propose a new design of vision-based tactile sensor, DelTact, with its high-resolution sensing abilities of surface contact measurement. The sensor uses a modular hardware architecture for compactness whilst maintaining a robust overall design. Moreover, it adopts an improved dense random color pattern based on the previous version to achieve high accuracy of contact deformation tracking. In particular, we optimize the color pattern generation process and select the appropriate pattern for coordinating with a dense optical flow algorithm in a real-world experimental sensory setting using various objects for contact. The optical flow obtained from the raw image is processed to determine shape and force distribution on the contact surface. This sensor can be easily integrated with a parallel gripper where experimental results using qualitative and quantitative analysis demonstrate that the sensor is capable of providing tactile measurements with high temporal and spatial resolution.
CNN-Driven Quasiconformal Model for Large Deformation Image Registration
Oct 30, 2020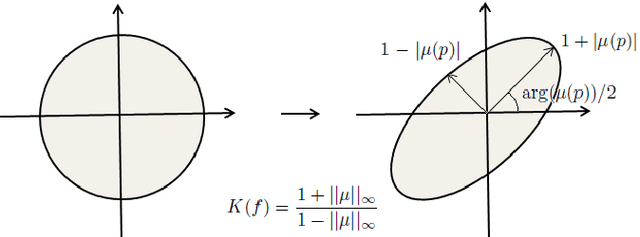
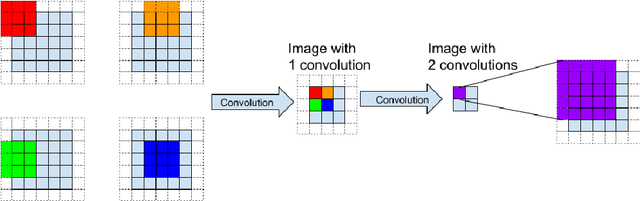
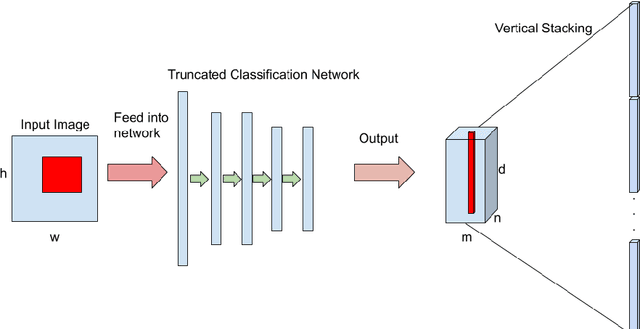
We present a novel way to perform image registration, which is not limited to a specific kind, between image pairs with very large deformation, while preserving Quasiconformal property without tedious manual landmark labeling that conventional mathematical registration methods require. Alongside the practical function of our algorithm, one just-as-important underlying message is that the integration between typical CNN and existing Mathematical model is successful as will be pointed out by our paper, meaning that machine learning and mathematical model could coexist, cover for each other and significantly improve registration result. This paper will demonstrate an unprecedented idea of making use of both robustness of CNNs and rigorousness of mathematical model to obtain meaningful registration maps between 2D images under the aforementioned strict constraints for the sake of well-posedness.
SD-RSIC: Summarization Driven Deep Remote Sensing Image Captioning
Jun 15, 2020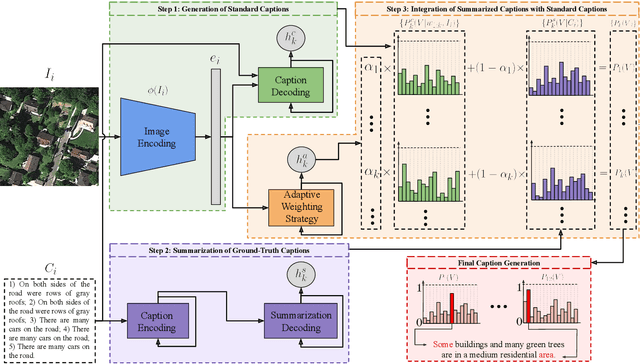


Deep neural networks (DNNs) have been recently found popular for image captioning problems in remote sensing (RS). Existing DNN based approaches rely on the availability of a training set made up of a high number of RS images with their captions. However, captions of training images may contain redundant information (they can be repetitive or semantically similar to each other), resulting in information deficiency while learning a mapping from image domain to language domain. To overcome this limitation, in this paper we present a novel Summarization Driven Remote Sensing Image Captioning (SD-RSIC) approach. The proposed approach consists of three main steps. The first step obtains the standard image captions by jointly exploiting convolutional neural networks (CNNs) with long short-term memory (LSTM) networks. The second step, unlike the existing RS image captioning methods, summarizes the ground-truth captions of each training image into a single caption by exploiting sequence to sequence neural networks and eliminates the redundancy present in the training set. The third step automatically defines the adaptive weights associated to each RS image to combine the standard captions with the summarized captions based on the semantic content of the image. This is achieved by a novel adaptive weighting strategy defined in the context of LSTM networks. Experimental results obtained on the RSCID, UCM-Captions and Sydney-Captions datasets show the effectiveness of the proposed approach compared to the state-of-the-art RS image captioning approaches.
Dual Reinforcement-Based Specification Generation for Image De-Rendering
Mar 02, 2021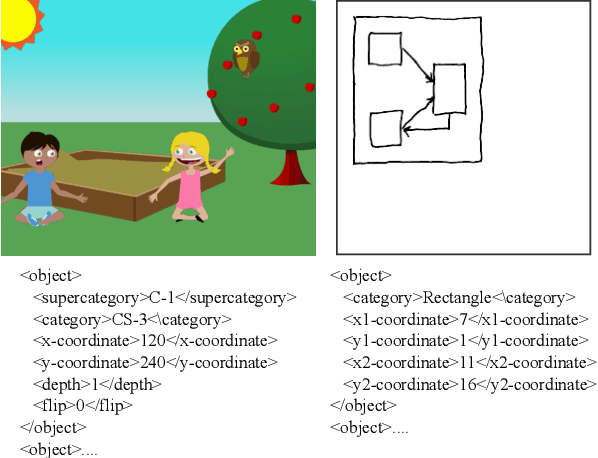
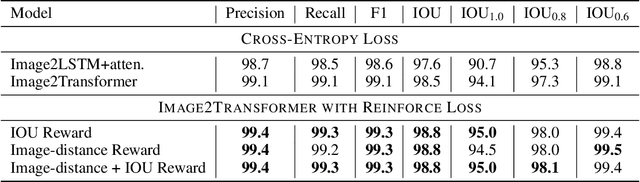

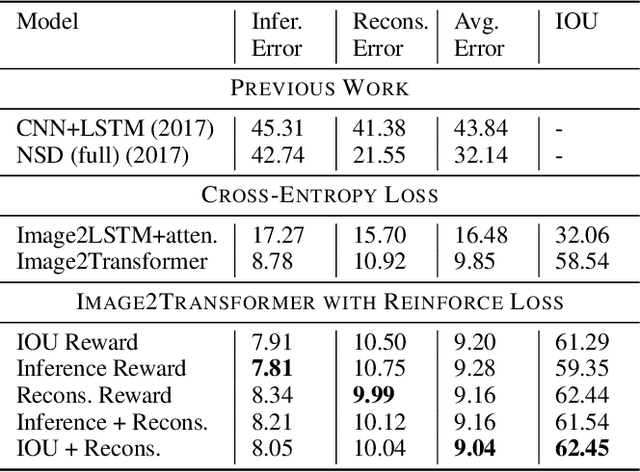
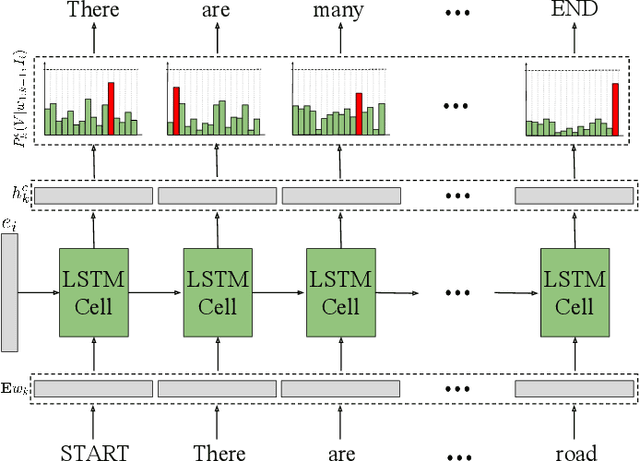
Advances in deep learning have led to promising progress in inferring graphics programs by de-rendering computer-generated images. However, current methods do not explore which decoding methods lead to better inductive bias for inferring graphics programs. In our work, we first explore the effectiveness of LSTM-RNN versus Transformer networks as decoders for order-independent graphics programs. Since these are sequence models, we must choose an ordering of the objects in the graphics programs for likelihood training. We found that the LSTM performance was highly sensitive to the sequence ordering (random order vs. pattern-based order), while Transformer performance was roughly independent of the sequence ordering. Further, we present a policy gradient based reinforcement learning approach for better inductive bias in the decoder via multiple diverse rewards based both on the graphics program specification and the rendered image. We also explore the combination of these complementary rewards. We achieve state-of-the-art results on two graphics program generation datasets.
VICTR: Visual Information Captured Text Representation for Text-to-Image Multimodal Tasks
Oct 25, 2020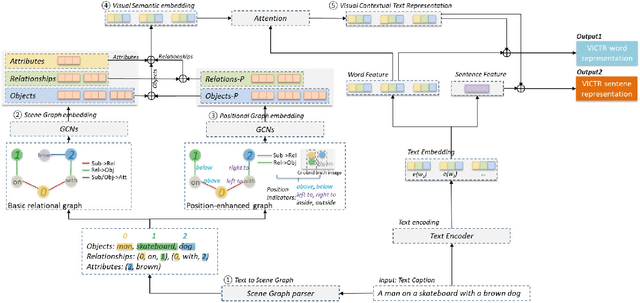
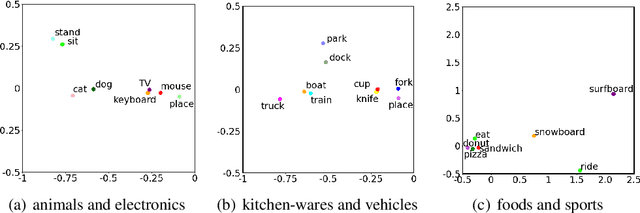
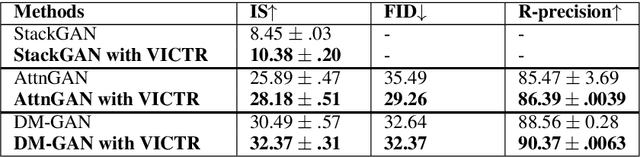
Text-to-image multimodal tasks, generating/retrieving an image from a given text description, are extremely challenging tasks since raw text descriptions cover quite limited information in order to fully describe visually realistic images. We propose a new visual contextual text representation for text-to-image multimodal tasks, VICTR, which captures rich visual semantic information of objects from the text input. First, we use the text description as initial input and conduct dependency parsing to extract the syntactic structure and analyse the semantic aspect, including object quantities, to extract the scene graph. Then, we train the extracted objects, attributes, and relations in the scene graph and the corresponding geometric relation information using Graph Convolutional Networks, and it generates text representation which integrates textual and visual semantic information. The text representation is aggregated with word-level and sentence-level embedding to generate both visual contextual word and sentence representation. For the evaluation, we attached VICTR to the state-of-the-art models in text-to-image generation.VICTR is easily added to existing models and improves across both quantitative and qualitative aspects.
Deep Symmetric Adaptation Network for Cross-modality Medical Image Segmentation
Jan 18, 2021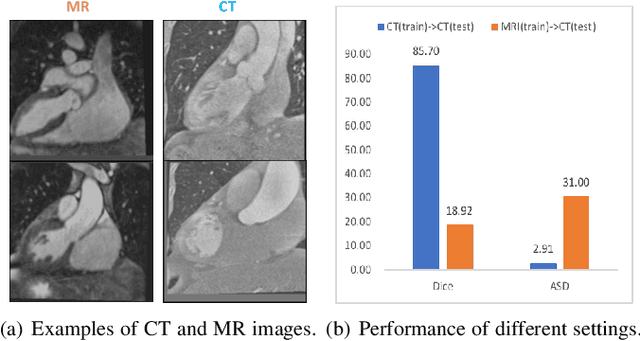
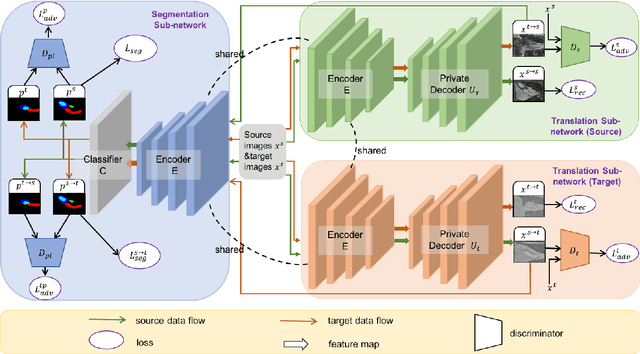
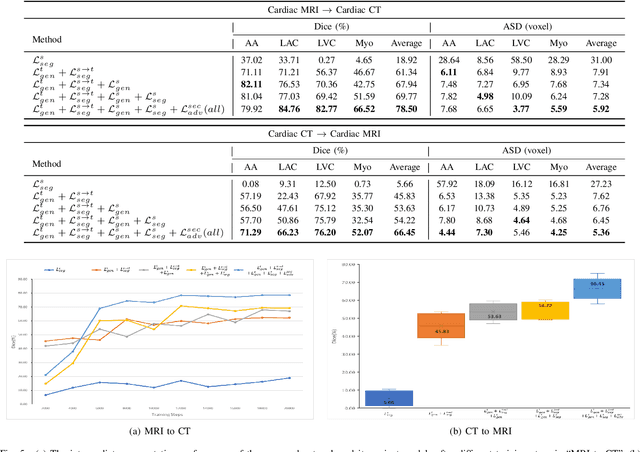
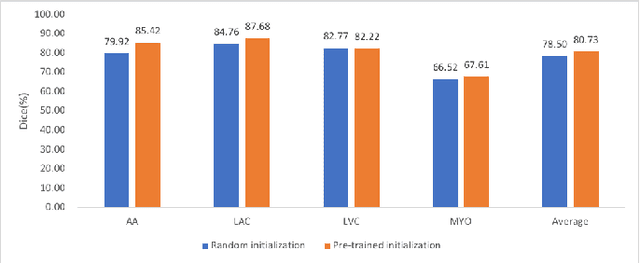
Unsupervised domain adaptation (UDA) methods have shown their promising performance in the cross-modality medical image segmentation tasks. These typical methods usually utilize a translation network to transform images from the source domain to target domain or train the pixel-level classifier merely using translated source images and original target images. However, when there exists a large domain shift between source and target domains, we argue that this asymmetric structure could not fully eliminate the domain gap. In this paper, we present a novel deep symmetric architecture of UDA for medical image segmentation, which consists of a segmentation sub-network, and two symmetric source and target domain translation sub-networks. To be specific, based on two translation sub-networks, we introduce a bidirectional alignment scheme via a shared encoder and private decoders to simultaneously align features 1) from source to target domain and 2) from target to source domain, which helps effectively mitigate the discrepancy between domains. Furthermore, for the segmentation sub-network, we train a pixel-level classifier using not only original target images and translated source images, but also original source images and translated target images, which helps sufficiently leverage the semantic information from the images with different styles. Extensive experiments demonstrate that our method has remarkable advantages compared to the state-of-the-art methods in both cross-modality Cardiac and BraTS segmentation tasks.
Vehicle trajectory prediction in top-view image sequences based on deep learning method
Feb 02, 2021
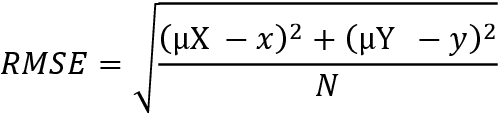
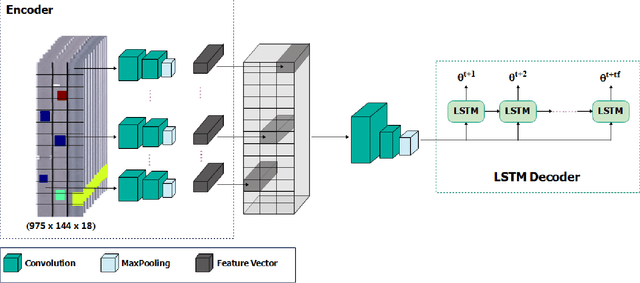
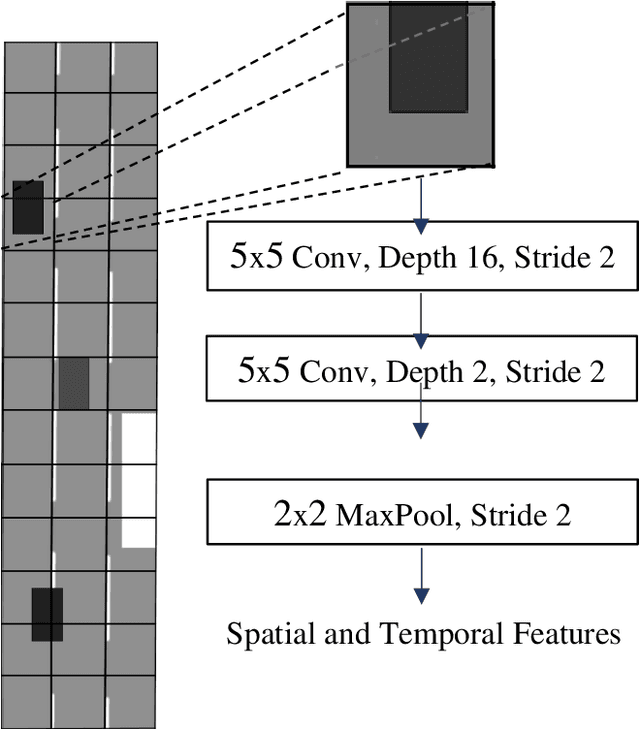
Annually, a large number of injuries and deaths around the world are related to motor vehicle accidents. This value has recently been reduced to some extent, via the use of driver-assistance systems. Developing driver-assistance systems (i.e., automated driving systems) can play a crucial role in reducing this number. Estimating and predicting surrounding vehicles' movement is essential for an automated vehicle and advanced safety systems. Moreover, predicting the trajectory is influenced by numerous factors, such as drivers' behavior during accidents, history of the vehicle's movement and the surrounding vehicles, and their position on the traffic scene. The vehicle must move over a safe path in traffic and react to other drivers' unpredictable behaviors in the shortest time. Herein, to predict automated vehicles' path, a model with low computational complexity is proposed, which is trained by images taken from the road's aerial image. Our method is based on an encoder-decoder model that utilizes a social tensor to model the effect of the surrounding vehicles' movement on the target vehicle. The proposed model can predict the vehicle's future path in any freeway only by viewing the images related to the history of the target vehicle's movement and its neighbors. Deep learning was used as a tool for extracting the features of these images. Using the HighD database, an image dataset of the road's aerial image was created, and the model's performance was evaluated on this new database. We achieved the RMSE of 1.91 for the next 5 seconds and found that the proposed method had less error than the best path-prediction methods in previous studies.