 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving the Otsu Thresholding Method of Global Binarization Using Ring Theory for Ultrasonographies of Congestive Heart Failure
Nov 13, 2021
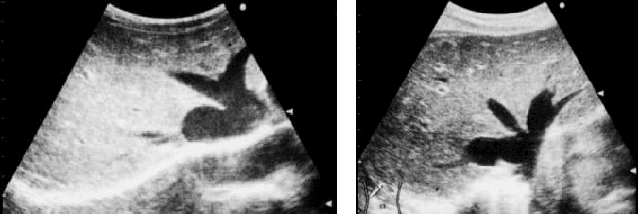


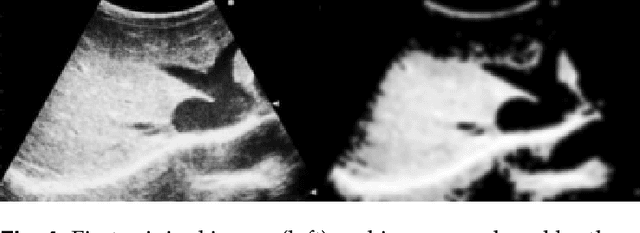
Ring Theory states that a ring is an algebraic structure where two binary operations can be performed among the elements addition and multiplication. Binarization is a method of image processing where values within pixels are reduced to a scale from zero to one, with zero representing the most absence of light and one representing the most presence of light. Currently, sonograms are implemented in scanning for congestive heart failure. However, the renowned Playboy Bunny symbol representing the ailment becomes increasingly difficult to isolate due to surrounding organs and lower quality image productions. This paper examines the Otsu thresholding method and incorporates new elements to account for different image features meant to better isolate congestive heart failure indicators in ultrasound images.
Image Compositing for Segmentation of Surgical Tools without Manual Annotations
Feb 18, 2021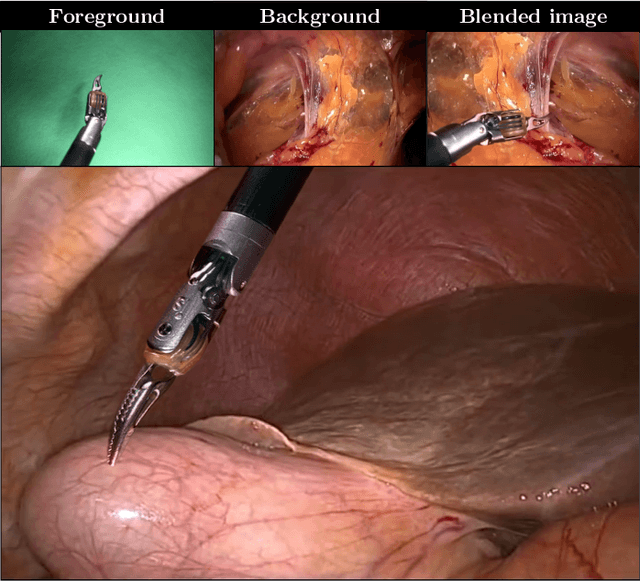
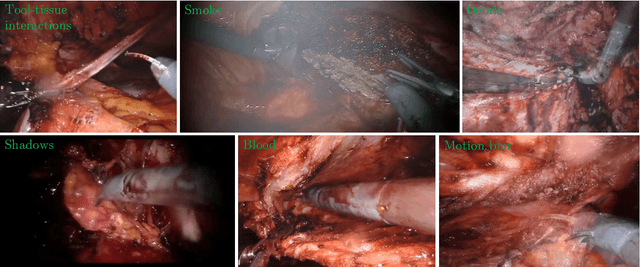
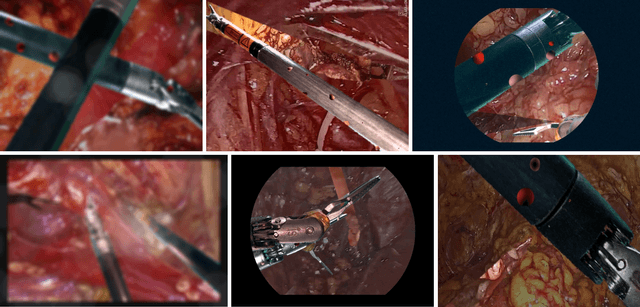
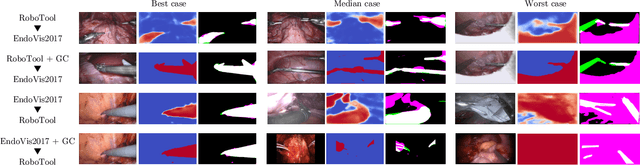
Producing manual, pixel-accurate, image segmentation labels is tedious and time-consuming. This is often a rate-limiting factor when large amounts of labeled images are required, such as for training deep convolutional networks for instrument-background segmentation in surgical scenes. No large datasets comparable to industry standards in the computer vision community are available for this task. To circumvent this problem, we propose to automate the creation of a realistic training dataset by exploiting techniques stemming from special effects and harnessing them to target training performance rather than visual appeal. Foreground data is captured by placing sample surgical instruments over a chroma key (a.k.a. green screen) in a controlled environment, thereby making extraction of the relevant image segment straightforward. Multiple lighting conditions and viewpoints can be captured and introduced in the simulation by moving the instruments and camera and modulating the light source. Background data is captured by collecting videos that do not contain instruments. In the absence of pre-existing instrument-free background videos, minimal labeling effort is required, just to select frames that do not contain surgical instruments from videos of surgical interventions freely available online. We compare different methods to blend instruments over tissue and propose a novel data augmentation approach that takes advantage of the plurality of options. We show that by training a vanilla U-Net on semi-synthetic data only and applying a simple post-processing, we are able to match the results of the same network trained on a publicly available manually labeled real dataset.
Accelerating Neural Architecture Exploration Across Modalities Using Genetic Algorithms
Feb 25, 2022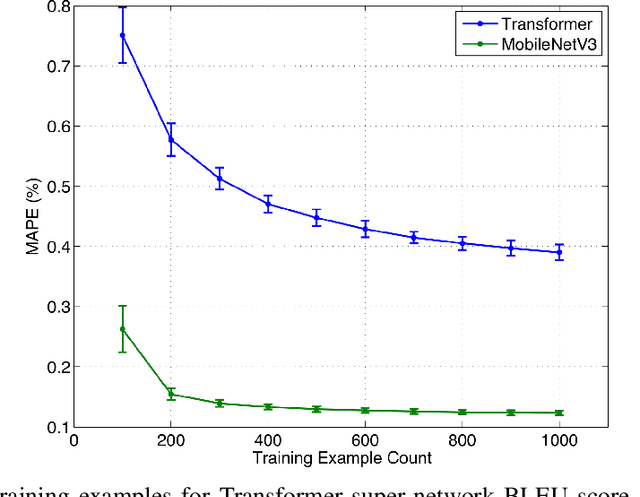
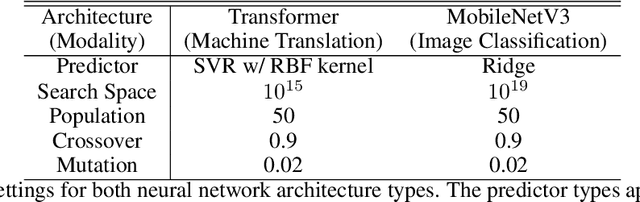
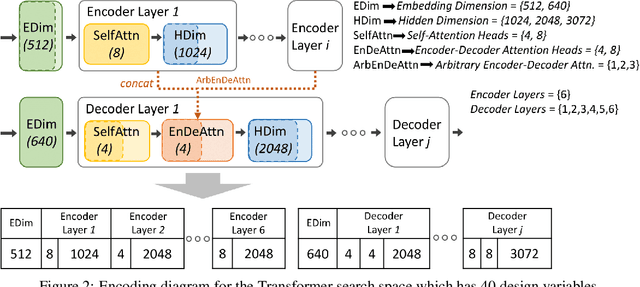
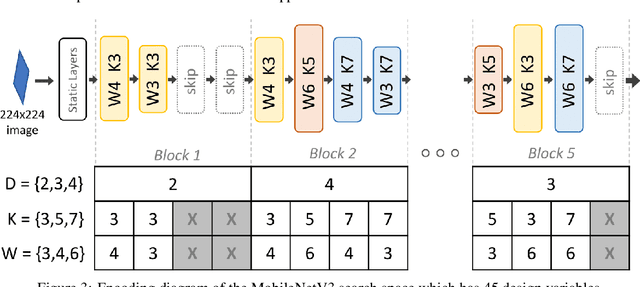
Neural architecture search (NAS), the study of automating the discovery of optimal deep neural network architectures for tasks in domains such as computer vision and natural language processing, has seen rapid growth in the machine learning research community. While there have been many recent advancements in NAS, there is still a significant focus on reducing the computational cost incurred when validating discovered architectures by making search more efficient. Evolutionary algorithms, specifically genetic algorithms, have a history of usage in NAS and continue to gain popularity versus other optimization approaches as a highly efficient way to explore the architecture objective space. Most NAS research efforts have centered around computer vision tasks and only recently have other modalities, such as the rapidly growing field of natural language processing, been investigated in depth. In this work, we show how genetic algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate multi-objective architectural exploration in a way that works in the modalities of both machine translation and image classification.
Generalizable Information Theoretic Causal Representation
Feb 17, 2022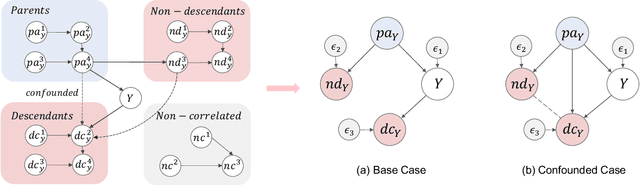
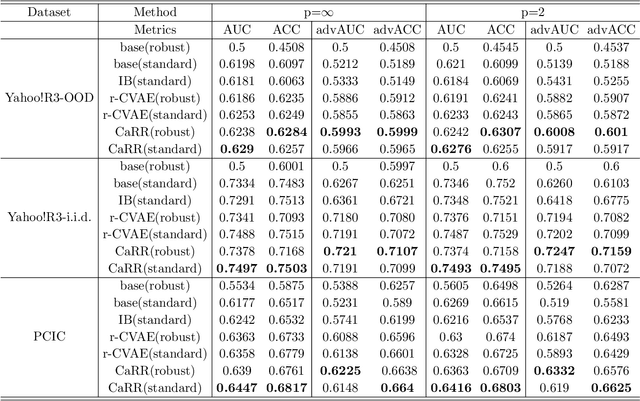
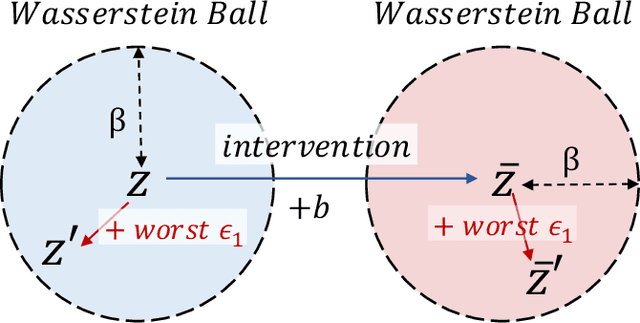
It is evidence that representation learning can improve model's performance over multiple downstream tasks in many real-world scenarios, such as image classification and recommender systems. Existing learning approaches rely on establishing the correlation (or its proxy) between features and the downstream task (labels), which typically results in a representation containing cause, effect and spurious correlated variables of the label. Its generalizability may deteriorate because of the unstability of the non-causal parts. In this paper, we propose to learn causal representation from observational data by regularizing the learning procedure with mutual information measures according to our hypothetical causal graph. The optimization involves a counterfactual loss, based on which we deduce a theoretical guarantee that the causality-inspired learning is with reduced sample complexity and better generalization ability. Extensive experiments show that the models trained on causal representations learned by our approach is robust under adversarial attacks and distribution shift.
Human Pose Manipulation and Novel View Synthesis using Differentiable Rendering
Nov 24, 2021



We present a new approach for synthesizing novel views of people in new poses. Our novel differentiable renderer enables the synthesis of highly realistic images from any viewpoint. Rather than operating over mesh-based structures, our renderer makes use of diffuse Gaussian primitives that directly represent the underlying skeletal structure of a human. Rendering these primitives gives results in a high-dimensional latent image, which is then transformed into an RGB image by a decoder network. The formulation gives rise to a fully differentiable framework that can be trained end-to-end. We demonstrate the effectiveness of our approach to image reconstruction on both the Human3.6M and Panoptic Studio datasets. We show how our approach can be used for motion transfer between individuals; novel view synthesis of individuals captured from just a single camera; to synthesize individuals from any virtual viewpoint; and to re-render people in novel poses. Code and video results are available at https://github.com/GuillaumeRochette/HumanViewSynthesis.
How to Fill the Optimum Set? Population Gradient Descent with Harmless Diversity
Feb 16, 2022
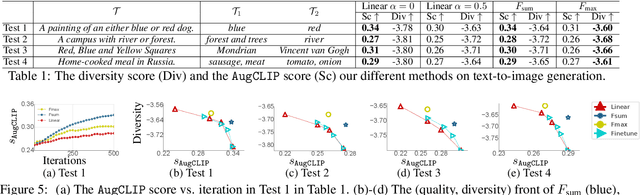
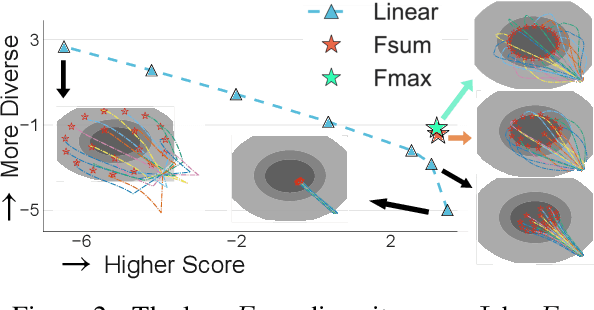

Although traditional optimization methods focus on finding a single optimal solution, most objective functions in modern machine learning problems, especially those in deep learning, often have multiple or infinite numbers of optima. Therefore, it is useful to consider the problem of finding a set of diverse points in the optimum set of an objective function. In this work, we frame this problem as a bi-level optimization problem of maximizing a diversity score inside the optimum set of the main loss function, and solve it with a simple population gradient descent framework that iteratively updates the points to maximize the diversity score in a fashion that does not hurt the optimization of the main loss. We demonstrate that our method can efficiently generate diverse solutions on a variety of applications, including text-to-image generation, text-to-mesh generation, molecular conformation generation and ensemble neural network training.
Model-Based Reconstruction for Collimated Beam Ultrasound Systems
Feb 20, 2022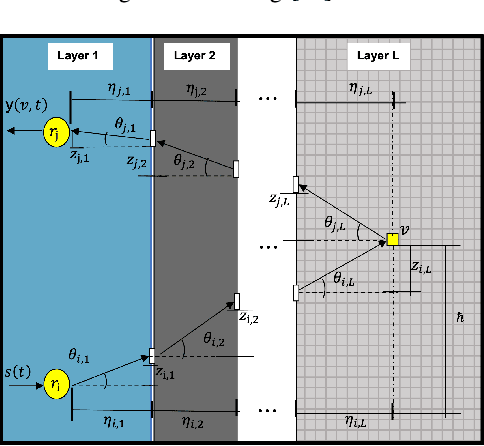
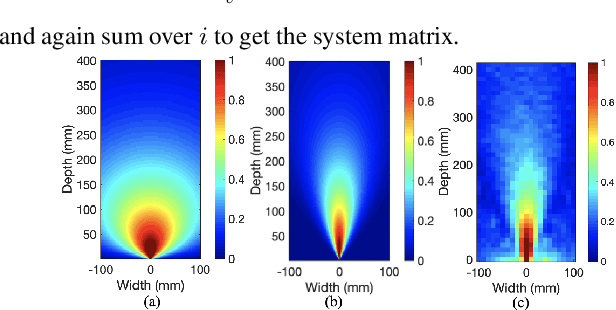
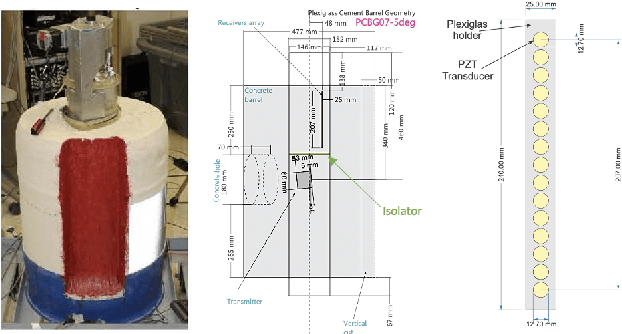
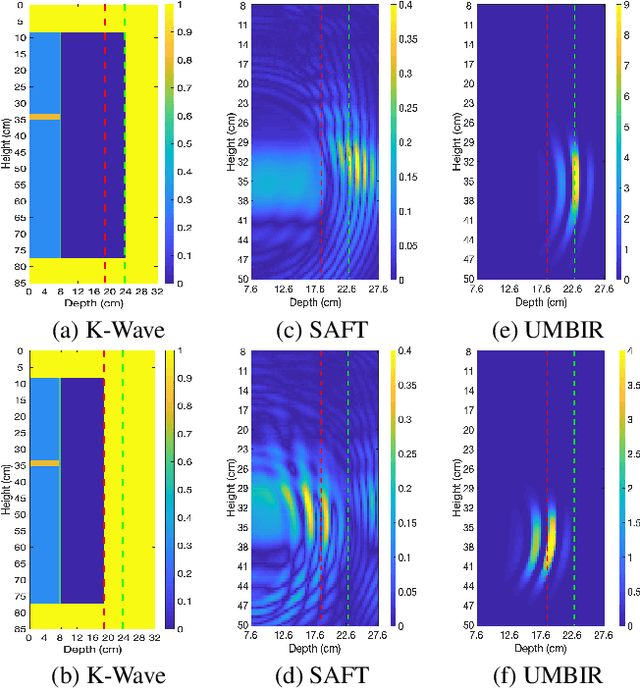
Collimated beam ultrasound systems are a novel technology for imaging inside multi-layered structures such as geothermal wells. Such systems include a transmitter and multiple receivers to capture reflected signals. Common algorithms for ultrasound reconstruction use delay-and-sum (DAS) approaches; these have low computational complexity but produce inaccurate images in the presence of complex structures and specialized geometries such as collimated beams. In this paper, we propose a multi-layer, ultrasonic, model-based iterative reconstruction algorithm designed for collimated beam systems. We introduce a physics-based forward model to accurately account for the propagation of a collimated ultrasonic beam in multi-layer media and describe an efficient implementation using binary search. We model direct arrival signals, detector noise, and a spatially varying image prior, then cast the reconstruction as a maximum a posteriori estimation problem. Using simulated and experimental data we obtain significantly fewer artifacts relative to DAS while running in near real time using commodity compute resources.
Object-Aware Cropping for Self-Supervised Learning
Dec 01, 2021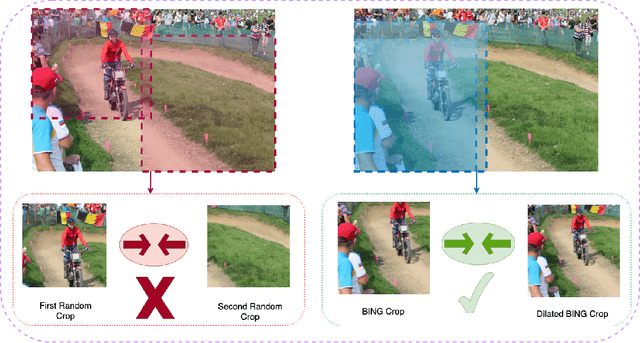
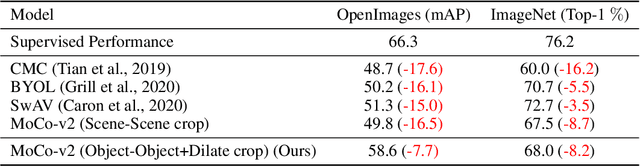
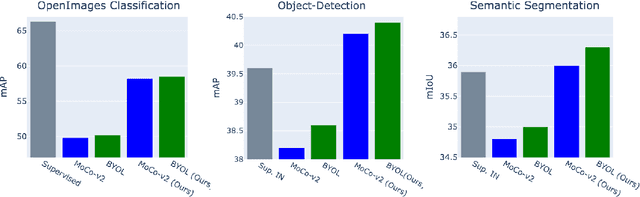

A core component of the recent success of self-supervised learning is cropping data augmentation, which selects sub-regions of an image to be used as positive views in the self-supervised loss. The underlying assumption is that randomly cropped and resized regions of a given image share information about the objects of interest, which the learned representation will capture. This assumption is mostly satisfied in datasets such as ImageNet where there is a large, centered object, which is highly likely to be present in random crops of the full image. However, in other datasets such as OpenImages or COCO, which are more representative of real world uncurated data, there are typically multiple small objects in an image. In this work, we show that self-supervised learning based on the usual random cropping performs poorly on such datasets. We propose replacing one or both of the random crops with crops obtained from an object proposal algorithm. This encourages the model to learn both object and scene level semantic representations. Using this approach, which we call object-aware cropping, results in significant improvements over scene cropping on classification and object detection benchmarks. For example, on OpenImages, our approach achieves an improvement of 8.8% mAP over random scene-level cropping using MoCo-v2 based pre-training. We also show significant improvements on COCO and PASCAL-VOC object detection and segmentation tasks over the state-of-the-art self-supervised learning approaches. Our approach is efficient, simple and general, and can be used in most existing contrastive and non-contrastive self-supervised learning frameworks.
Learnable Adaptive Cosine Estimator (LACE) for Image Classification
Oct 15, 2021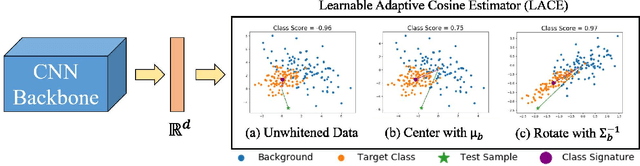
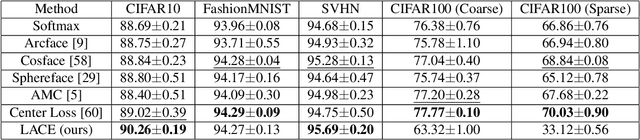
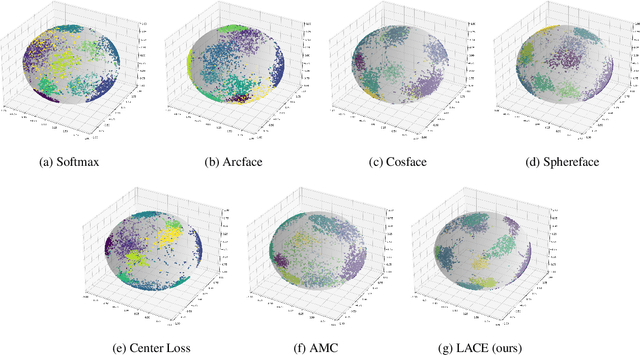
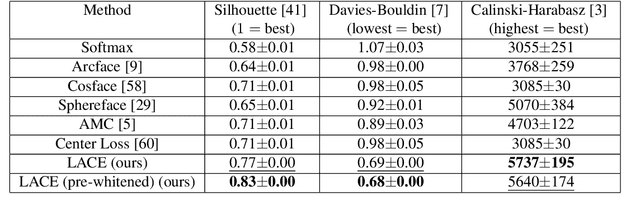
In this work, we propose a new loss to improve feature discriminability and classification performance. Motivated by the adaptive cosine/coherence estimator (ACE), our proposed method incorporates angular information that is inherently learned by artificial neural networks. Our learnable ACE (LACE) transforms the data into a new "whitened" space that improves the inter-class separability and intra-class compactness. We compare our LACE to alternative state-of-the art softmax-based and feature regularization approaches. Our results show that the proposed method can serve as a viable alternative to cross entropy and angular softmax approaches. Our code is publicly available: https://github.com/GatorSense/LACE.
NPC: Neuron Path Coverage via Characterizing Decision Logic of Deep Neural Networks
Mar 26, 2022
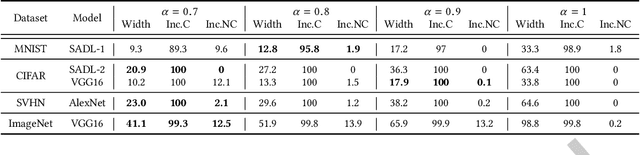
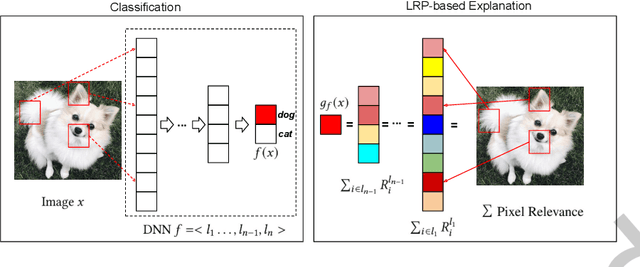
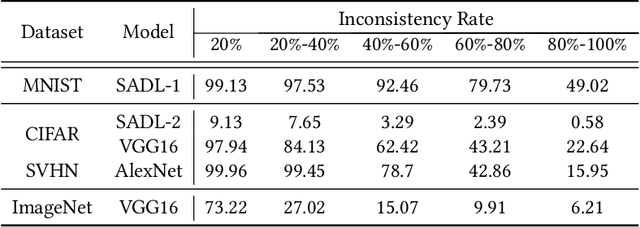
Deep learning has recently been widely applied to many applications across different domains, e.g., image classification and audio recognition. However, the quality of Deep Neural Networks (DNNs) still raises concerns in the practical operational environment, which calls for systematic testing, especially in safety-critical scenarios. Inspired by software testing, a number of structural coverage criteria are designed and proposed to measure the test adequacy of DNNs. However, due to the blackbox nature of DNN, the existing structural coverage criteria are difficult to interpret, making it hard to understand the underlying principles of these criteria. The relationship between the structural coverage and the decision logic of DNNs is unknown. Moreover, recent studies have further revealed the non-existence of correlation between the structural coverage and DNN defect detection, which further posts concerns on what a suitable DNN testing criterion should be. In this paper, we propose the interpretable coverage criteria through constructing the decision structure of a DNN. Mirroring the control flow graph of the traditional program, we first extract a decision graph from a DNN based on its interpretation, where a path of the decision graph represents a decision logic of the DNN. Based on the control flow and data flow of the decision graph, we propose two variants of path coverage to measure the adequacy of the test cases in exercising the decision logic. The higher the path coverage, the more diverse decision logic the DNN is expected to be explored. Our large-scale evaluation results demonstrate that: the path in the decision graph is effective in characterizing the decision of the DNN, and the proposed coverage criteria are also sensitive with errors including natural errors and adversarial examples, and strongly correlated with the output impartiality.