 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Edge-Enhanced Dual Discriminator Generative Adversarial Network for Fast MRI with Parallel Imaging Using Multi-view Information
Dec 10, 2021
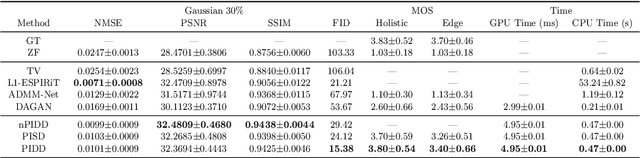
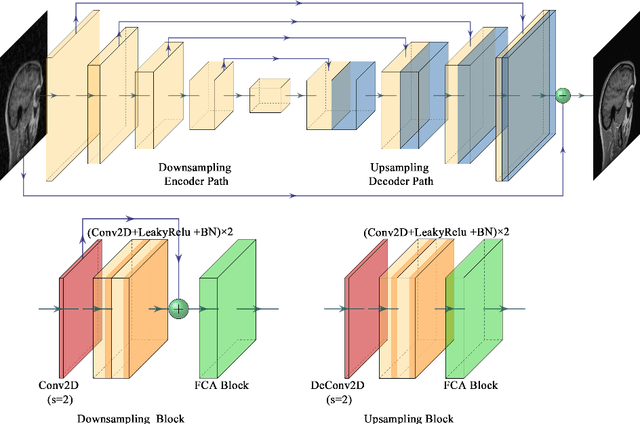
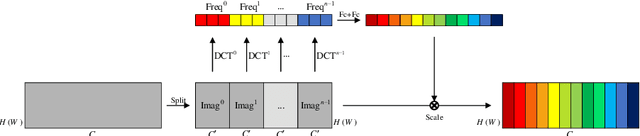
In clinical medicine, magnetic resonance imaging (MRI) is one of the most important tools for diagnosis, triage, prognosis, and treatment planning. However, MRI suffers from an inherent slow data acquisition process because data is collected sequentially in k-space. In recent years, most MRI reconstruction methods proposed in the literature focus on holistic image reconstruction rather than enhancing the edge information. This work steps aside this general trend by elaborating on the enhancement of edge information. Specifically, we introduce a novel parallel imaging coupled dual discriminator generative adversarial network (PIDD-GAN) for fast multi-channel MRI reconstruction by incorporating multi-view information. The dual discriminator design aims to improve the edge information in MRI reconstruction. One discriminator is used for holistic image reconstruction, whereas the other one is responsible for enhancing edge information. An improved U-Net with local and global residual learning is proposed for the generator. Frequency channel attention blocks (FCA Blocks) are embedded in the generator for incorporating attention mechanisms. Content loss is introduced to train the generator for better reconstruction quality. We performed comprehensive experiments on Calgary-Campinas public brain MR dataset and compared our method with state-of-the-art MRI reconstruction methods. Ablation studies of residual learning were conducted on the MICCAI13 dataset to validate the proposed modules. Results show that our PIDD-GAN provides high-quality reconstructed MR images, with well-preserved edge information. The time of single-image reconstruction is below 5ms, which meets the demand of faster processing.
Movies2Scenes: Learning Scene Representations Using Movie Similarities
Feb 22, 2022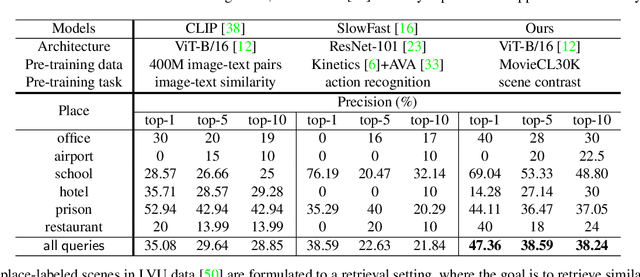
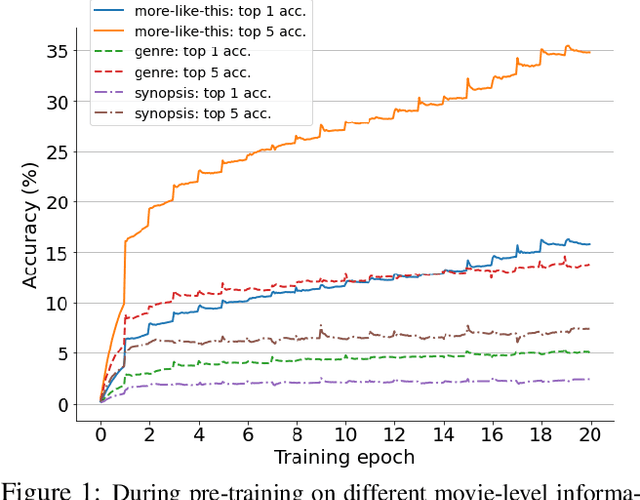
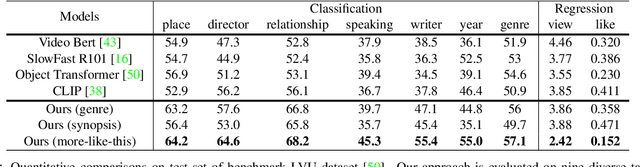
Automatic understanding of movie-scenes is an important problem with multiple downstream applications including video-moderation, search and recommendation. The long-form nature of movies makes labeling of movie scenes a laborious task, which makes applying end-to-end supervised approaches for understanding movie-scenes a challenging problem. Directly applying state-of-the-art visual representations learned from large-scale image datasets for movie-scene understanding does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available sources of movie-information (e.g., genre, synopsis, more-like-this information) to learn a general-purpose scene-representation. Using a new dataset (MovieCL30K) with 30,340 movies, we demonstrate that our learned scene-representation surpasses existing state-of-the-art results on eleven downstream tasks from multiple datasets. To further show the effectiveness of our scene-representation, we introduce another new dataset (MCD) focused on large-scale video-moderation with 44,581 clips containing sex, violence, and drug-use activities covering 18,330 movies and TV episodes, and show strong gains over existing state-of-the-art approaches.
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
Mar 11, 2022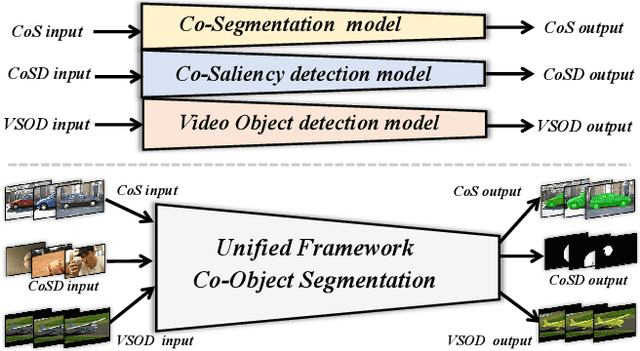
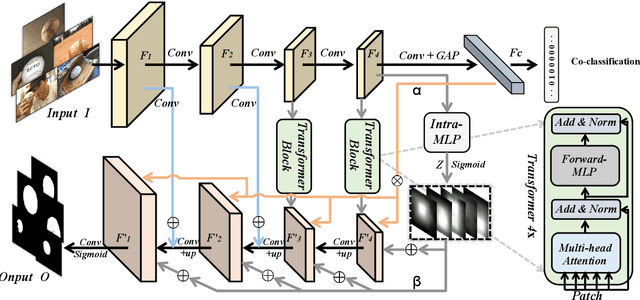
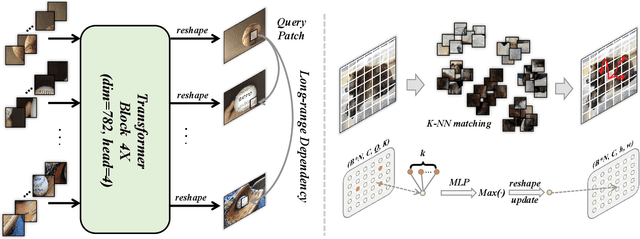
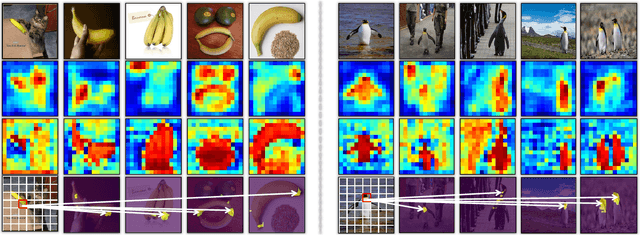
Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transferability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in real-time.
memeBot: Towards Automatic Image Meme Generation
Apr 30, 2020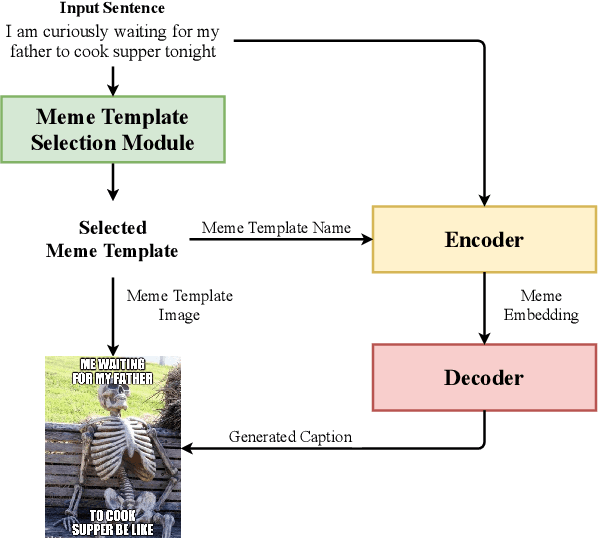



Image memes have become a widespread tool used by people for interacting and exchanging ideas over social media, blogs, and open messengers. This work proposes to treat automatic image meme generation as a translation process, and further present an end to end neural and probabilistic approach to generate an image-based meme for any given sentence using an encoder-decoder architecture. For a given input sentence, an image meme is generated by combining a meme template image and a text caption where the meme template image is selected from a set of popular candidates using a selection module, and the meme caption is generated by an encoder-decoder model. An encoder is used to map the selected meme template and the input sentence into a meme embedding and a decoder is used to decode the meme caption from the meme embedding. The generated natural language meme caption is conditioned on the input sentence and the selected meme template. The model learns the dependencies between the meme captions and the meme template images and generates new memes using the learned dependencies. The quality of the generated captions and the generated memes is evaluated through both automated and human evaluation. An experiment is designed to score how well the generated memes can represent the tweets from Twitter conversations. Experiments on Twitter data show the efficacy of the model in generating memes for sentences in online social interaction.
A Data-Augmentation Is Worth A Thousand Samples: Exact Quantification From Analytical Augmented Sample Moments
Feb 16, 2022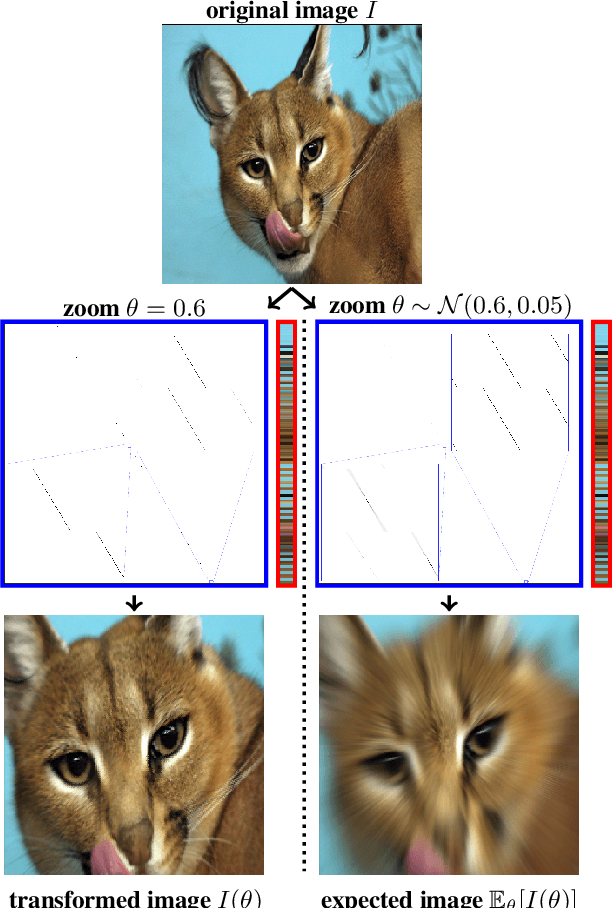
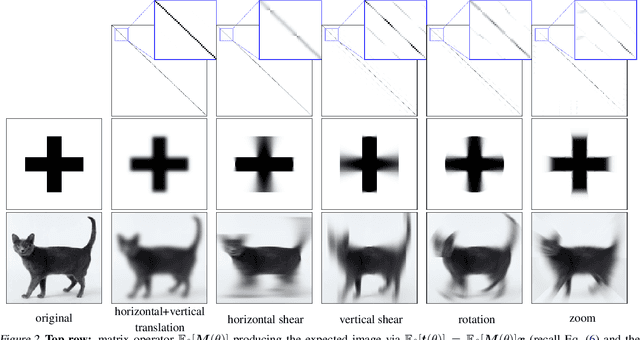
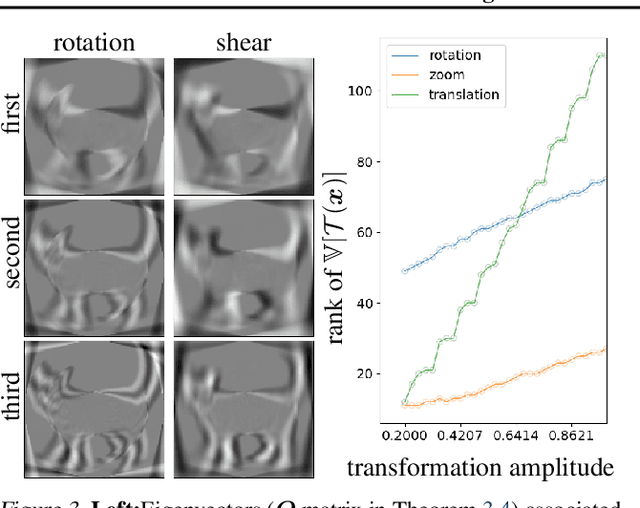
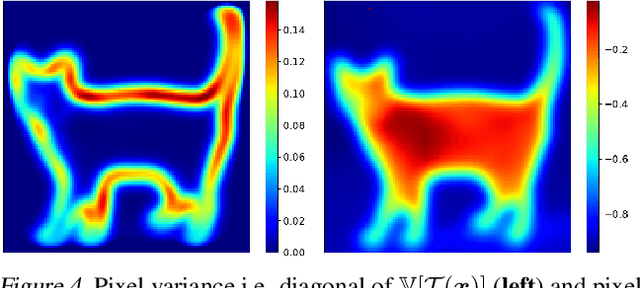
Data-Augmentation (DA) is known to improve performance across tasks and datasets. We propose a method to theoretically analyze the effect of DA and study questions such as: how many augmented samples are needed to correctly estimate the information encoded by that DA? How does the augmentation policy impact the final parameters of a model? We derive several quantities in close-form, such as the expectation and variance of an image, loss, and model's output under a given DA distribution. Those derivations open new avenues to quantify the benefits and limitations of DA. For example, we show that common DAs require tens of thousands of samples for the loss at hand to be correctly estimated and for the model training to converge. We show that for a training loss to be stable under DA sampling, the model's saliency map (gradient of the loss with respect to the model's input) must align with the smallest eigenvector of the sample variance under the considered DA augmentation, hinting at a possible explanation on why models tend to shift their focus from edges to textures.
How to augment your ViTs? Consistency loss and StyleAug, a random style transfer augmentation
Dec 16, 2021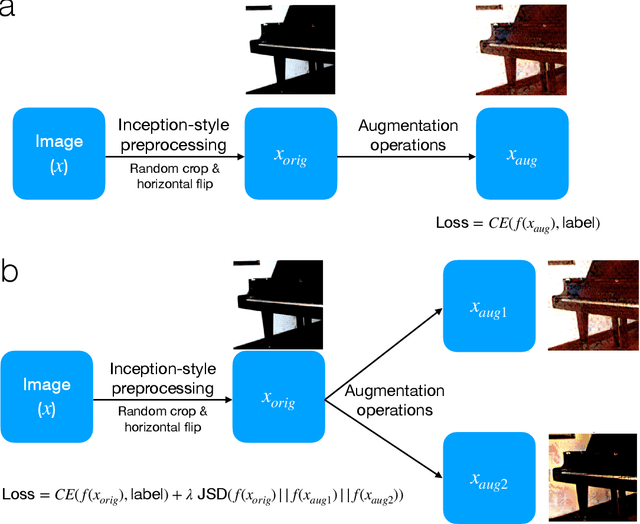

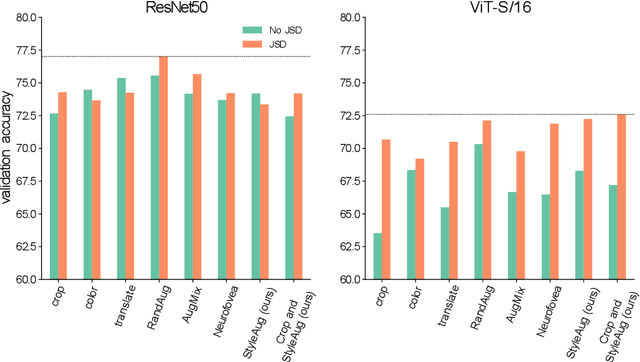
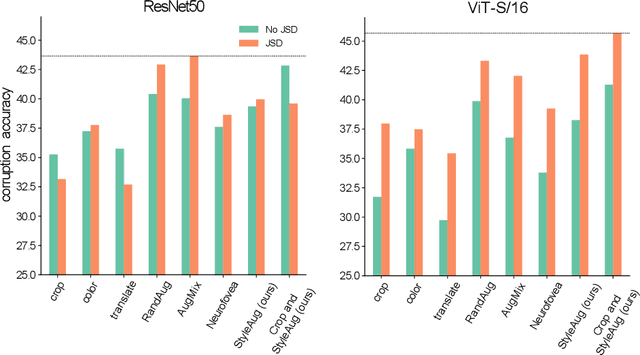
The Vision Transformer (ViT) architecture has recently achieved competitive performance across a variety of computer vision tasks. One of the motivations behind ViTs is weaker inductive biases, when compared to convolutional neural networks (CNNs). However this also makes ViTs more difficult to train. They require very large training datasets, heavy regularization, and strong data augmentations. The data augmentation strategies used to train ViTs have largely been inherited from CNN training, despite the significant differences between the two architectures. In this work, we empirical evaluated how different data augmentation strategies performed on CNN (e.g., ResNet) versus ViT architectures for image classification. We introduced a style transfer data augmentation, termed StyleAug, which worked best for training ViTs, while RandAugment and Augmix typically worked best for training CNNs. We also found that, in addition to a classification loss, using a consistency loss between multiple augmentations of the same image was especially helpful when training ViTs.
Towards Creativity Characterization of Generative Models via Group-based Subset Scanning
Mar 03, 2022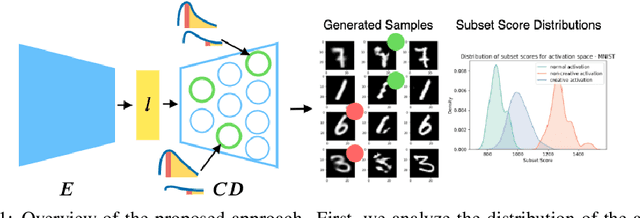
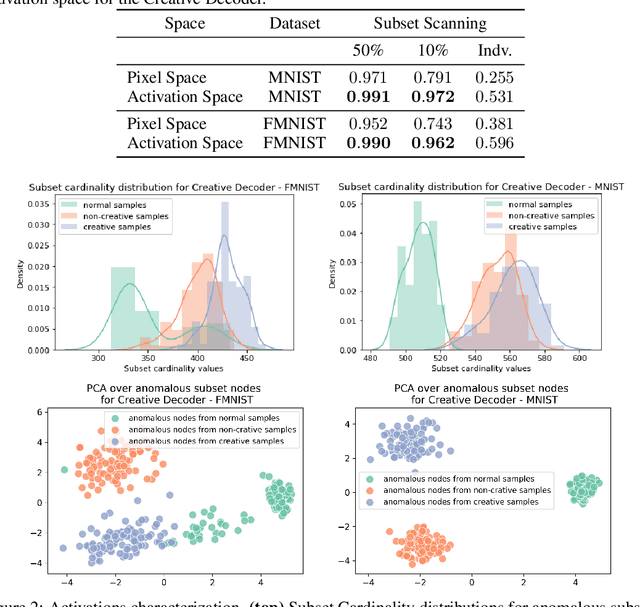
Deep generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, thereby limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed toward creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to identify, quantify, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of the generative models. Our experiments on the standard image benchmarks, and their "creatively generated" variants, reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for the normal sample generation. Lastly, we assess if the images from the subsets selected by our method were also found creative by human evaluators, presenting a link between creativity perception in humans and node activations within deep neural nets.
Synchronized Audio-Visual Frames with Fractional Positional Encoding for Transformers in Video-to-Text Translation
Dec 28, 2021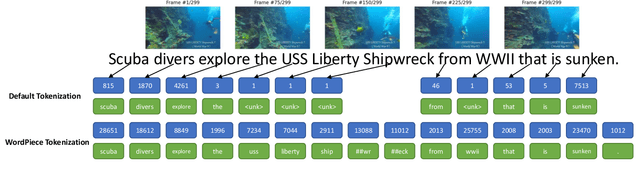
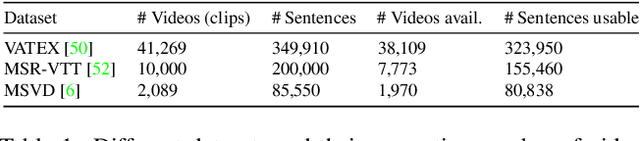
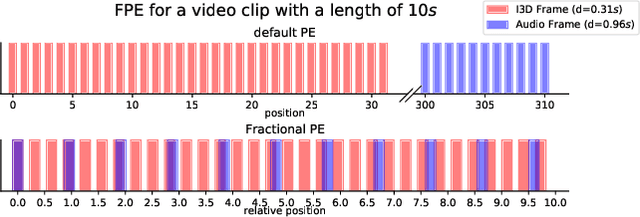
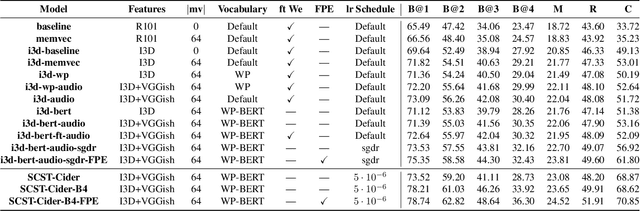
Video-to-Text (VTT) is the task of automatically generating descriptions for short audio-visual video clips, which can support visually impaired people to understand scenes of a YouTube video for instance. Transformer architectures have shown great performance in both machine translation and image captioning, lacking a straightforward and reproducible application for VTT. However, there is no comprehensive study on different strategies and advice for video description generation including exploiting the accompanying audio with fully self-attentive networks. Thus, we explore promising approaches from image captioning and video processing and apply them to VTT by developing a straightforward Transformer architecture. Additionally, we present a novel way of synchronizing audio and video features in Transformers which we call Fractional Positional Encoding (FPE). We run multiple experiments on the VATEX dataset to determine a configuration applicable to unseen datasets that helps describe short video clips in natural language and improved the CIDEr and BLEU-4 scores by 37.13 and 12.83 points compared to a vanilla Transformer network and achieve state-of-the-art results on the MSR-VTT and MSVD datasets. Also, FPE helps increase the CIDEr score by a relative factor of 8.6%.
RBSRICNN: Raw Burst Super-Resolution through Iterative Convolutional Neural Network
Oct 25, 2021


Modern digital cameras and smartphones mostly rely on image signal processing (ISP) pipelines to produce realistic colored RGB images. However, compared to DSLR cameras, low-quality images are usually obtained in many portable mobile devices with compact camera sensors due to their physical limitations. The low-quality images have multiple degradations i.e., sub-pixel shift due to camera motion, mosaick patterns due to camera color filter array, low-resolution due to smaller camera sensors, and the rest information are corrupted by the noise. Such degradations limit the performance of current Single Image Super-resolution (SISR) methods in recovering high-resolution (HR) image details from a single low-resolution (LR) image. In this work, we propose a Raw Burst Super-Resolution Iterative Convolutional Neural Network (RBSRICNN) that follows the burst photography pipeline as a whole by a forward (physical) model. The proposed Burst SR scheme solves the problem with classical image regularization, convex optimization, and deep learning techniques, compared to existing black-box data-driven methods. The proposed network produces the final output by an iterative refinement of the intermediate SR estimates. We demonstrate the effectiveness of our proposed approach in quantitative and qualitative experiments that generalize robustly to real LR burst inputs with onl synthetic burst data available for training.
Open-Edit: Open-Domain Image Manipulation with Open-Vocabulary Instructions
Aug 04, 2020
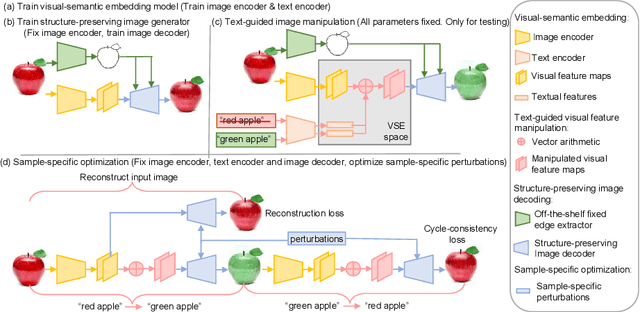


We propose a novel algorithm, named Open-Edit, which is the first attempt on open-domain image manipulation with open-vocabulary instructions. It is a challenging task considering the large variation of image domains and the lack of training supervision. Our approach takes advantage of the unified visual-semantic embedding space pretrained on a general image-caption dataset, and manipulates the embedded visual features by applying text-guided vector arithmetic on the image feature maps. A structure-preserving image decoder then generates the manipulated images from the manipulated feature maps. We further propose an on-the-fly sample-specific optimization approach with cycle-consistency constraints to regularize the manipulated images and force them to preserve details of the source images. Our approach shows promising results in manipulating open-vocabulary color, texture, and high-level attributes for various scenarios of open-domain images.