 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Modal Mixup for Robust Fine-tuning
Mar 08, 2022
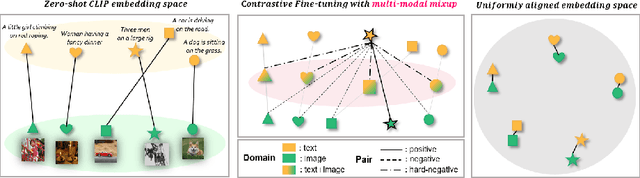
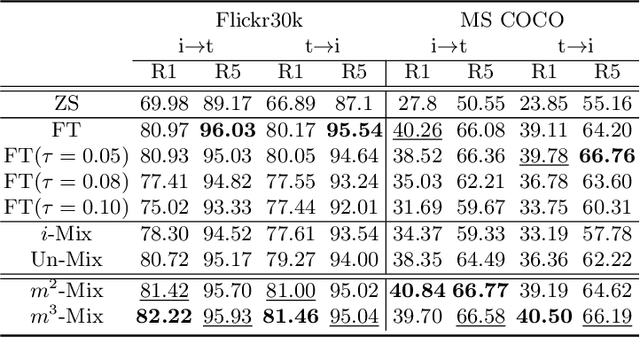
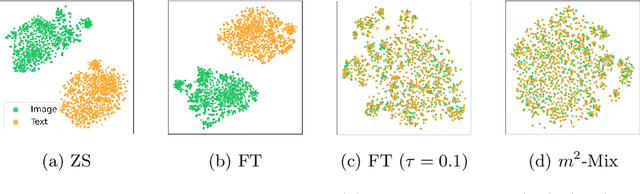
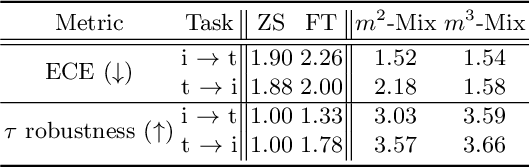
Pre-trained large-scale models provide a transferable embedding, and they show comparable performance on the diverse downstream task. However, the transferability of multi-modal learning is restricted, and the analysis of learned embedding has not been explored well. This paper provides a perspective to understand the multi-modal embedding in terms of uniformity and alignment. We newly find that the representation learned by multi-modal learning models such as CLIP has a two separated representation space for each heterogeneous dataset with less alignment. Besides, there are unexplored large intermediate areas between two modalities with less uniformity. Less robust embedding might restrict the transferability of the representation for the downstream task. This paper provides a new end-to-end fine-tuning method for robust representation that encourages better uniformity and alignment score. First, we propose a multi-modal Mixup, $m^{2}$-Mix that mixes the representation of image and text to generate the hard negative samples. Second, we fine-tune the multi-modal model on a hard negative sample as well as normal negative and positive samples with contrastive learning. Our multi-modal Mixup provides a robust representation, and we validate our methods on classification, retrieval, and structure-awareness task.
Neuro-Inspired Deep Neural Networks with Sparse, Strong Activations
Feb 26, 2022

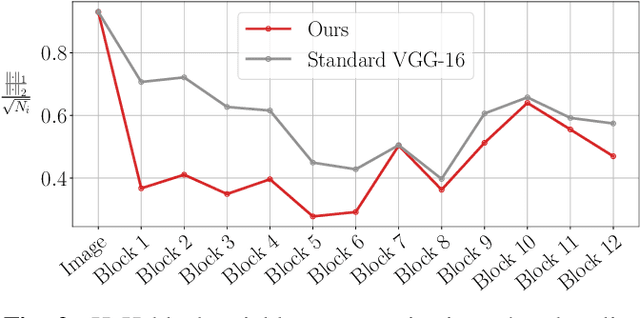
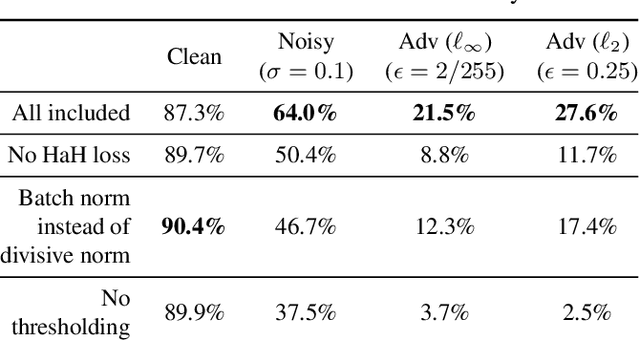
While end-to-end training of Deep Neural Networks (DNNs) yields state of the art performance in an increasing array of applications, it does not provide insight into, or control over, the features being extracted. We report here on a promising neuro-inspired approach to DNNs with sparser and stronger activations. We use standard stochastic gradient training, supplementing the end-to-end discriminative cost function with layer-wise costs promoting Hebbian ("fire together," "wire together") updates for highly active neurons, and anti-Hebbian updates for the remaining neurons. Instead of batch norm, we use divisive normalization of activations (suppressing weak outputs using strong outputs), along with implicit $\ell_2$ normalization of neuronal weights. Experiments with standard image classification tasks on CIFAR-10 demonstrate that, relative to baseline end-to-end trained architectures, our proposed architecture (a) leads to sparser activations (with only a slight compromise on accuracy), (b) exhibits more robustness to noise (without being trained on noisy data), (c) exhibits more robustness to adversarial perturbations (without adversarial training).
Development and Comparison of Scoring Functions in Curriculum Learning
Feb 10, 2022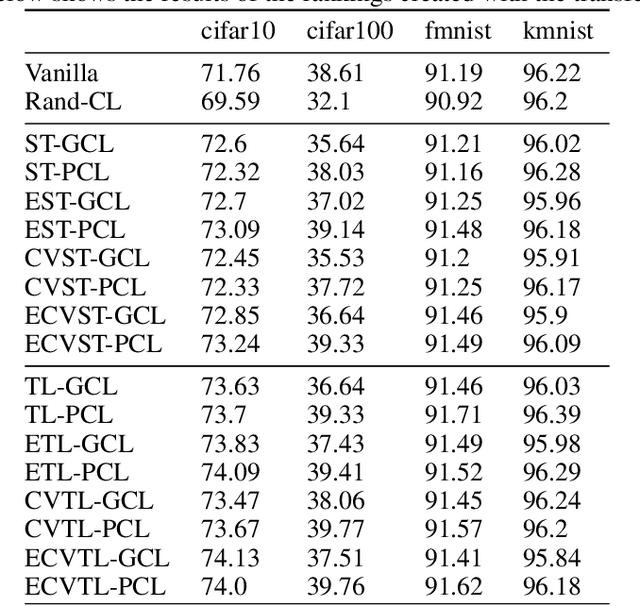
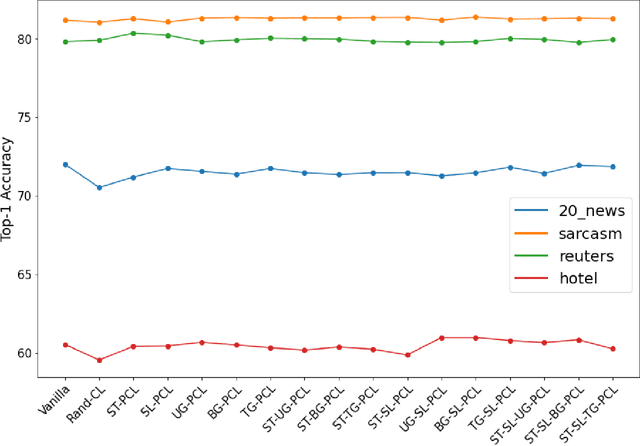
Curriculum Learning is the presentation of samples to the machine learning model in a meaningful order instead of a random order. The main challenge of Curriculum Learning is determining how to rank these samples. The ranking of the samples is expressed by the scoring function. In this study, scoring functions were compared using data set features, using the model to be trained, and using another model and their ensemble versions. Experiments were performed for 4 images and 4 text datasets. No significant differences were found between scoring functions for text datasets, but significant improvements were obtained in scoring functions created using transfer learning compared to classical model training and other scoring functions for image datasets. It shows that different new scoring functions are waiting to be found for text classification tasks.
TIME: Text and Image Mutual-Translation Adversarial Networks
May 27, 2020

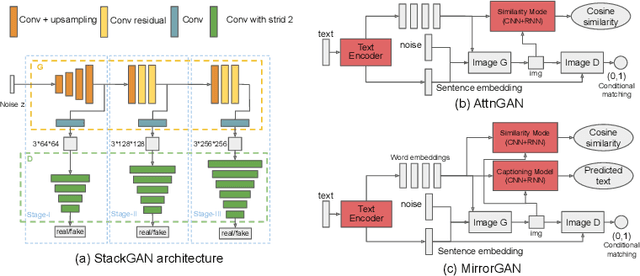

Focusing on text-to-image (T2I) generation, we propose Text and Image Mutual-Translation Adversarial Networks (TIME), a lightweight but effective model that jointly learns a T2I generator $G$ and an image captioning discriminator $D$ under the Generative Adversarial Network framework. While previous methods tackle the T2I problem as a uni-directional task and use pre-trained language models to enforce the image-text consistency, TIME requires neither extra modules nor pre-training. We show that the performance of $G$ can be boosted substantially by training it jointly with $D$ as a language model. Specifically, we adopt Transformers to model the cross-modal connections between the image features and word embeddings, and design a hinged and annealing conditional loss that dynamically balances the adversarial learning. In our experiments, TIME establishes the new state-of-the-art Inception Score of 4.88 on the CUB dataset, and shows competitive performance on MS-COCO on both text-to-image and image captioning tasks.
Task-Oriented Multi-User Semantic Communications
Dec 19, 2021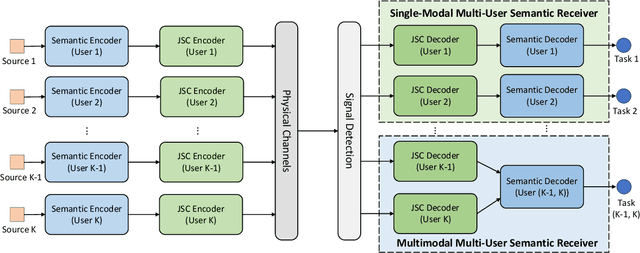


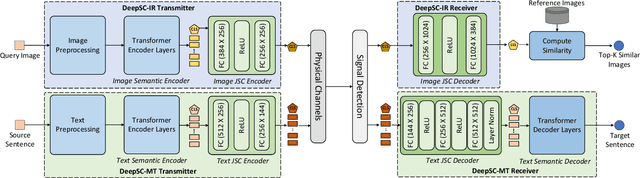
While semantic communications have shown the potential in the case of single-modal single-users, its applications to the multi-user scenario remain limited. In this paper, we investigate deep learning (DL) based multi-user semantic communication systems for transmitting single-modal data and multimodal data, respectively. We will adopt three intelligent tasks, including, image retrieval, machine translation, and visual question answering (VQA) as the transmission goal of semantic communication systems. We will then propose a Transformer based unique framework to unify the structure of transmitters for different tasks. For the single-modal multi-user system, we will propose two Transformer based models, named, DeepSC-IR and DeepSC-MT, to perform image retrieval and machine translation, respectively. In this case, DeepSC-IR is trained to optimize the distance in embedding space between images and DeepSC-MT is trained to minimize the semantic errors by recovering the semantic meaning of sentences. For the multimodal multi-user system, we develop a Transformer enabled model, named, DeepSC-VQA, for the VQA task by extracting text-image information at the transmitters and fusing it at the receiver. In particular, a novel layer-wise Transformer is designed to help fuse multimodal data by adding connection between each of the encoder and decoder layers. Numerical results will show that the proposed models are superior to traditional communications in terms of the robustness to channels, computational complexity, transmission delay, and the task-execution performance at various task-specific metrics.
Adaptive Path Planning for UAVs for Multi-Resolution Semantic Segmentation
Mar 03, 2022
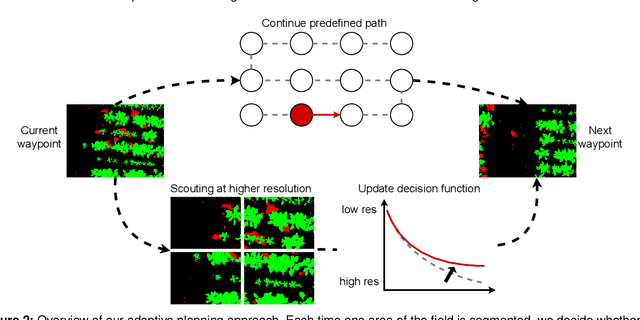
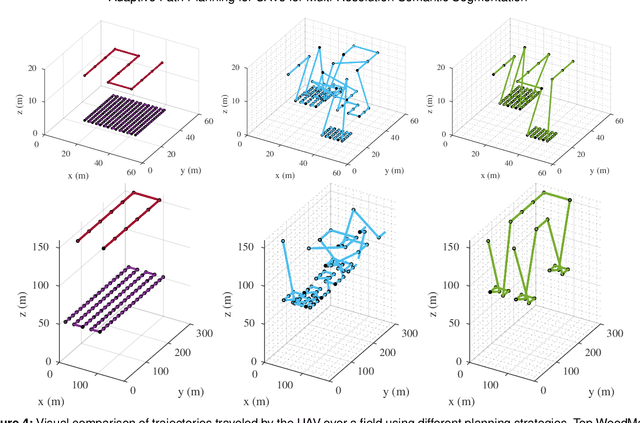
Efficient data collection methods play a major role in helping us better understand the Earth and its ecosystems. In many applications, the usage of unmanned aerial vehicles (UAVs) for monitoring and remote sensing is rapidly gaining momentum due to their high mobility, low cost, and flexible deployment. A key challenge is planning missions to maximize the value of acquired data in large environments given flight time limitations. This is, for example, relevant for monitoring agricultural fields. This paper addresses the problem of adaptive path planning for accurate semantic segmentation of using UAVs. We propose an online planning algorithm which adapts the UAV paths to obtain high-resolution semantic segmentations necessary in areas with fine details as they are detected in incoming images. This enables us to perform close inspections at low altitudes only where required, without wasting energy on exhaustive mapping at maximum image resolution. A key feature of our approach is a new accuracy model for deep learning-based architectures that captures the relationship between UAV altitude and semantic segmentation accuracy. We evaluate our approach on different domains using real-world data, proving the efficacy and generability of our solution.
FMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Nov 30, 2021
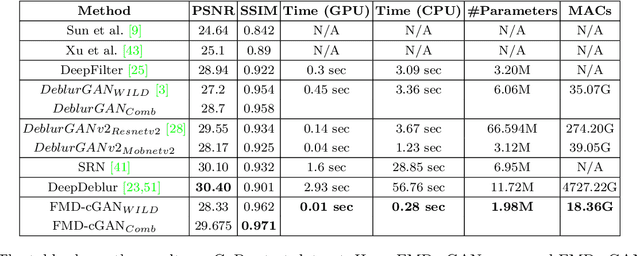


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.
Leveraging Visual Question Answering to Improve Text-to-Image Synthesis
Oct 28, 2020
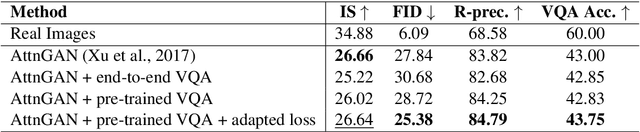
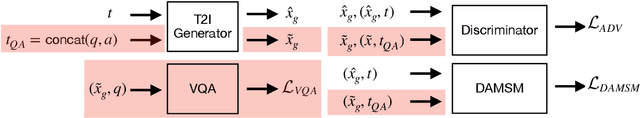
Generating images from textual descriptions has recently attracted a lot of interest. While current models can generate photo-realistic images of individual objects such as birds and human faces, synthesising images with multiple objects is still very difficult. In this paper, we propose an effective way to combine Text-to-Image (T2I) synthesis with Visual Question Answering (VQA) to improve the image quality and image-text alignment of generated images by leveraging the VQA 2.0 dataset. We create additional training samples by concatenating question and answer (QA) pairs and employ a standard VQA model to provide the T2I model with an auxiliary learning signal. We encourage images generated from QA pairs to look realistic and additionally minimize an external VQA loss. Our method lowers the FID from 27.84 to 25.38 and increases the R-prec. from 83.82% to 84.79% when compared to the baseline, which indicates that T2I synthesis can successfully be improved using a standard VQA model.
Exploring Intensity Invariance in Deep Neural Networks for Brain Image Registration
Sep 21, 2020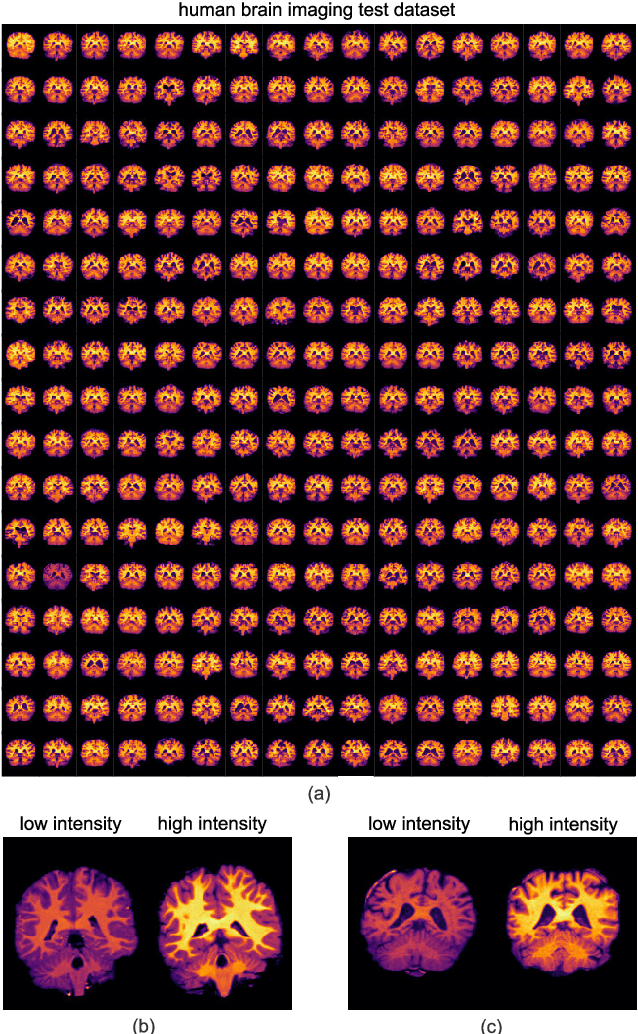
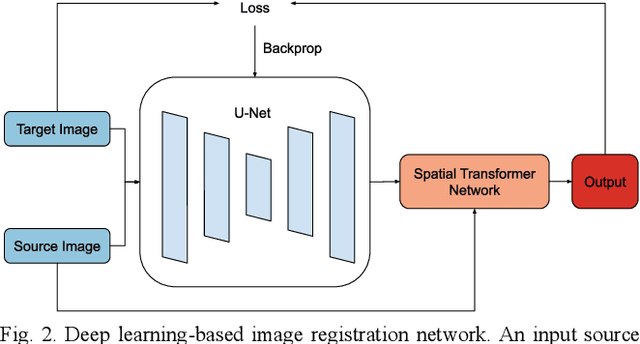

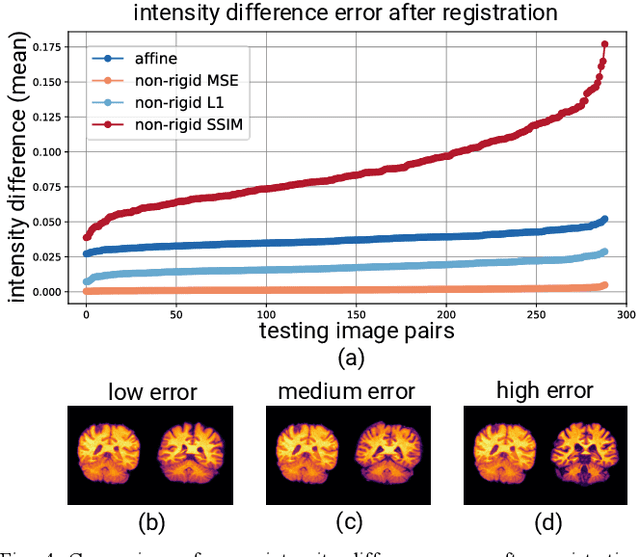
Image registration is a widely-used technique in analysing large scale datasets that are captured through various imaging modalities and techniques in biomedical imaging such as MRI, X-Rays, etc. These datasets are typically collected from various sites and under different imaging protocols using a variety of scanners. Such heterogeneity in the data collection process causes inhomogeneity or variation in intensity (brightness) and noise distribution. These variations play a detrimental role in the performance of image registration, segmentation and detection algorithms. Classical image registration methods are computationally expensive but are able to handle these artifacts relatively better. However, deep learning-based techniques are shown to be computationally efficient for automated brain registration but are sensitive to the intensity variations. In this study, we investigate the effect of variation in intensity distribution among input image pairs for deep learning-based image registration methods. We find a performance degradation of these models when brain image pairs with different intensity distribution are presented even with similar structures. To overcome this limitation, we incorporate a structural similarity-based loss function in a deep neural network and test its performance on the validation split separated before training as well as on a completely unseen new dataset. We report that the deep learning models trained with structure similarity-based loss seems to perform better for both datasets. This investigation highlights a possible performance limiting factor in deep learning-based registration models and suggests a potential solution to incorporate the intensity distribution variation in the input image pairs. Our code and models are available at https://github.com/hassaanmahmood/DeepIntense.
Dynamic Object Comprehension: A Framework For Evaluating Artificial Visual Perception
Feb 17, 2022Augmented and Mixed Reality are emerging as likely successors to the mobile internet. However, many technical challenges remain. One of the key requirements of these systems is the ability to create a continuity between physical and virtual worlds, with the user's visual perception as the primary interface medium. Building this continuity requires the system to develop a visual understanding of the physical world. While there has been significant recent progress in computer vision and AI techniques such as image classification and object detection, success in these areas has not yet led to the visual perception required for these critical MR and AR applications. A significant issue is that current evaluation criteria are insufficient for these applications. To motivate and evaluate progress in this emerging area, there is a need for new metrics. In this paper we outline limitations of current evaluation criteria and propose new criteria.