 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
L-SpEx: Localized Target Speaker Extraction
Feb 21, 2022
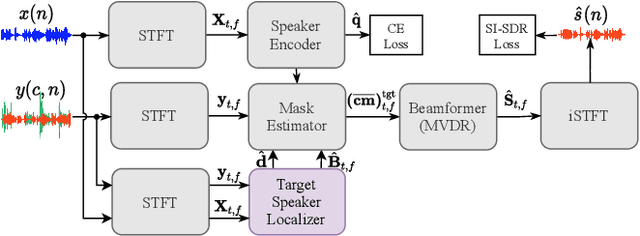
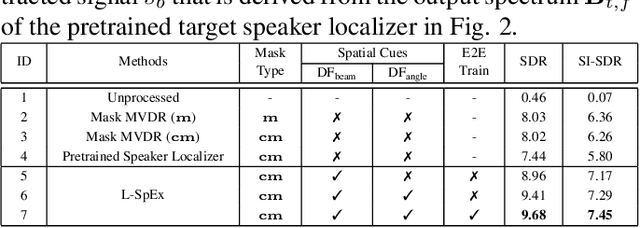
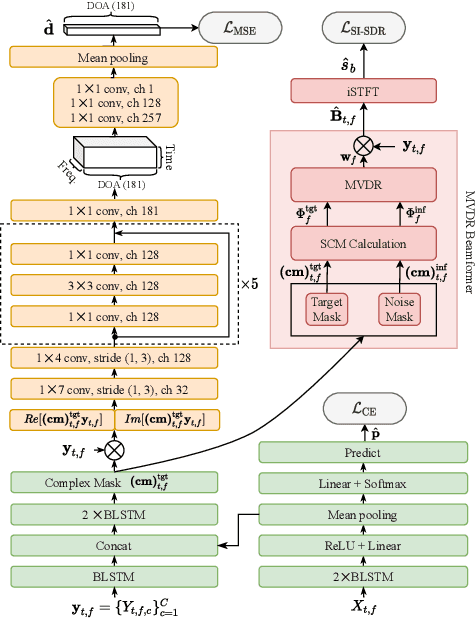
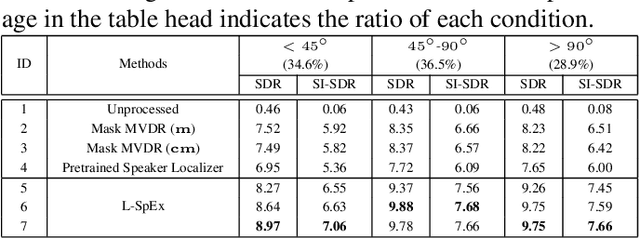
Speaker extraction aims to extract the target speaker's voice from a multi-talker speech mixture given an auxiliary reference utterance. Recent studies show that speaker extraction benefits from the location or direction of the target speaker. However, these studies assume that the target speaker's location is known in advance or detected by an extra visual cue, e.g., face image or video. In this paper, we propose an end-to-end localized target speaker extraction on pure speech cues, that is called L-SpEx. Specifically, we design a speaker localizer driven by the target speaker's embedding to extract the spatial features, including direction-of-arrival (DOA) of the target speaker and beamforming output. Then, the spatial cues and target speaker's embedding are both used to form a top-down auditory attention to the target speaker. Experiments on the multi-channel reverberant dataset called MC-Libri2Mix show that our L-SpEx approach significantly outperforms the baseline system.
NRC-GAMMA: Introducing a Novel Large Gas Meter Image Dataset
Nov 12, 2021



Automatic meter reading technology is not yet widespread. Gas, electricity, or water accumulation meters reading is mostly done manually on-site either by an operator or by the homeowner. In some countries, the operator takes a picture as reading proof to confirm the reading by checking offline with another operator and/or using it as evidence in case of conflicts or complaints. The whole process is time-consuming, expensive, and prone to errors. Automation can optimize and facilitate such labor-intensive and human error-prone processes. With the recent advances in the fields of artificial intelligence and computer vision, automatic meter reading systems are becoming more viable than ever. Motivated by the recent advances in the field of artificial intelligence and inspired by open-source open-access initiatives in the research community, we introduce a novel large benchmark dataset of real-life gas meter images, named the NRC-GAMMA dataset. The data were collected from an Itron 400A diaphragm gas meter on January 20, 2020, between 00:05 am and 11:59 pm. We employed a systematic approach to label the images, validate the labellings, and assure the quality of the annotations. The dataset contains 28,883 images of the entire gas meter along with 57,766 cropped images of the left and the right dial displays. We hope the NRC-GAMMA dataset helps the research community to design and implement accurate, innovative, intelligent, and reproducible automatic gas meter reading solutions.
Weakly Supervised Nuclei Segmentation via Instance Learning
Feb 11, 2022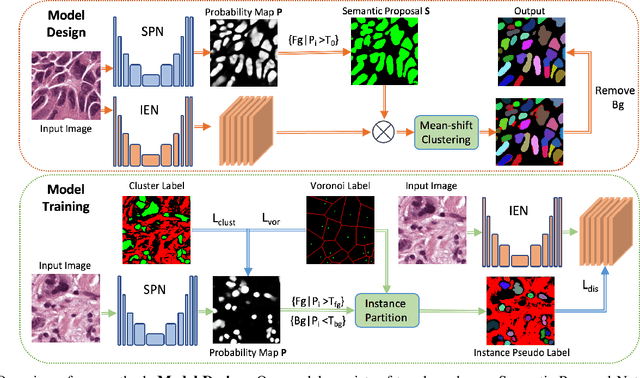
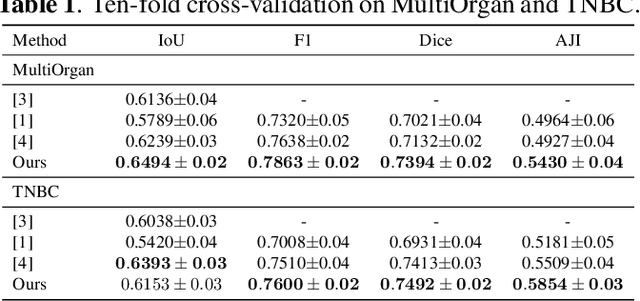
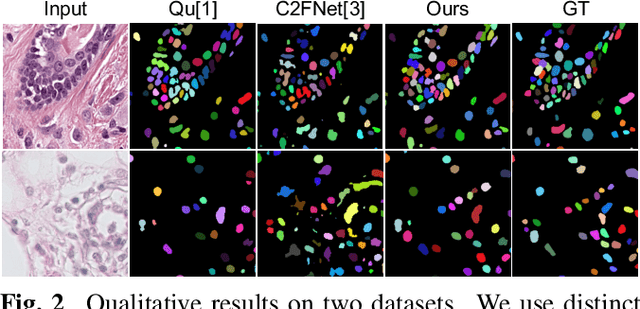
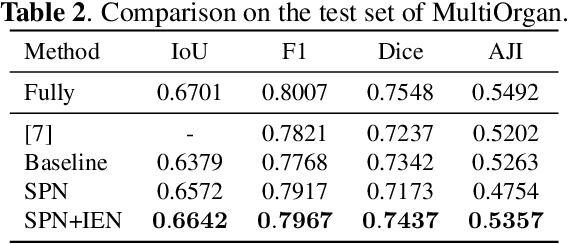
Weakly supervised nuclei segmentation is a critical problem for pathological image analysis and greatly benefits the community due to the significant reduction of labeling cost. Adopting point annotations, previous methods mostly rely on less expressive representations for nuclei instances and thus have difficulty in handling crowded nuclei. In this paper, we propose to decouple weakly supervised semantic and instance segmentation in order to enable more effective subtask learning and to promote instance-aware representation learning. To achieve this, we design a modular deep network with two branches: a semantic proposal network and an instance encoding network, which are trained in a two-stage manner with an instance-sensitive loss. Empirical results show that our approach achieves the state-of-the-art performance on two public benchmarks of pathological images from different types of organs.
An Empirical Analysis of Image-Based Learning Techniques for Malware Classification
Mar 24, 2021
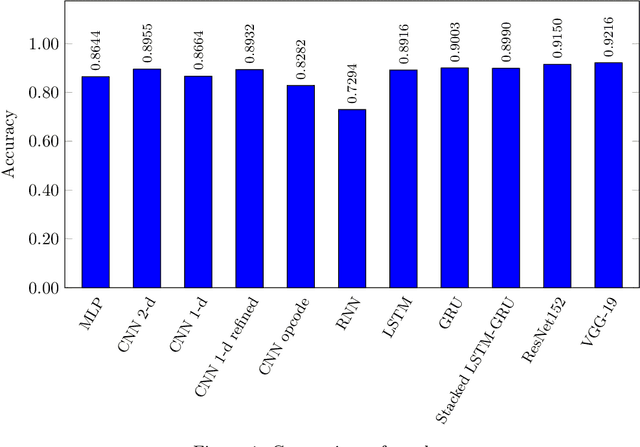
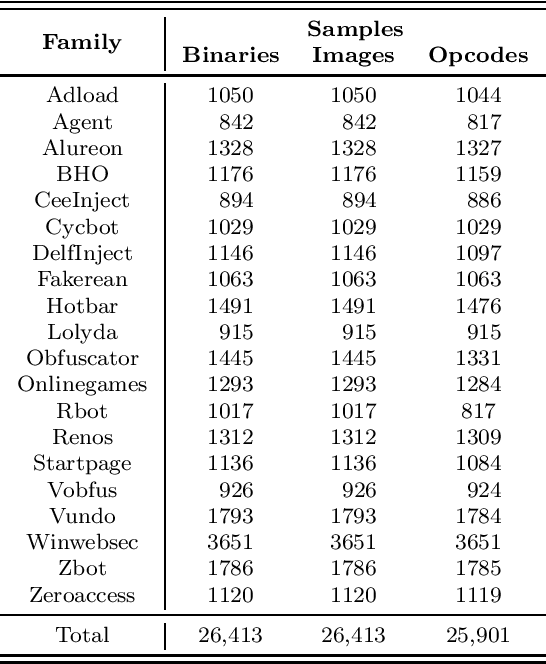
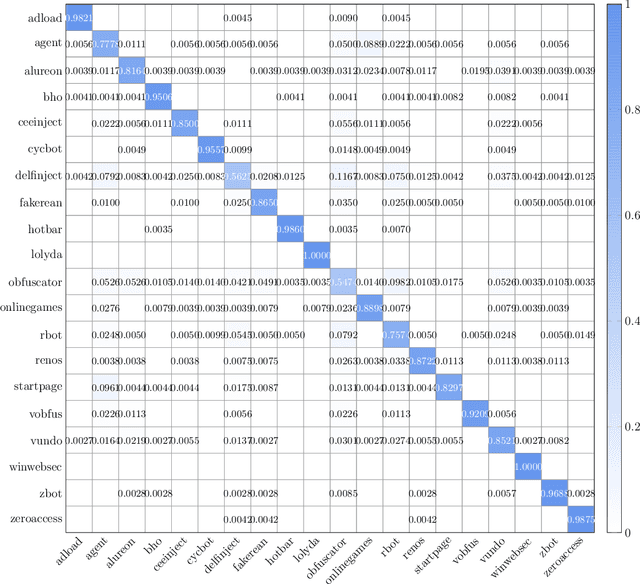
In this paper, we consider malware classification using deep learning techniques and image-based features. We employ a wide variety of deep learning techniques, including multilayer perceptrons (MLP), convolutional neural networks (CNN), long short-term memory (LSTM), and gated recurrent units (GRU). Amongst our CNN experiments, transfer learning plays a prominent role specifically, we test the VGG-19 and ResNet152 models. As compared to previous work, the results presented in this paper are based on a larger and more diverse malware dataset, we consider a wider array of features, and we experiment with a much greater variety of learning techniques. Consequently, our results are the most comprehensive and complete that have yet been published.
Style Agnostic 3D Reconstruction via Adversarial Style Transfer
Oct 20, 2021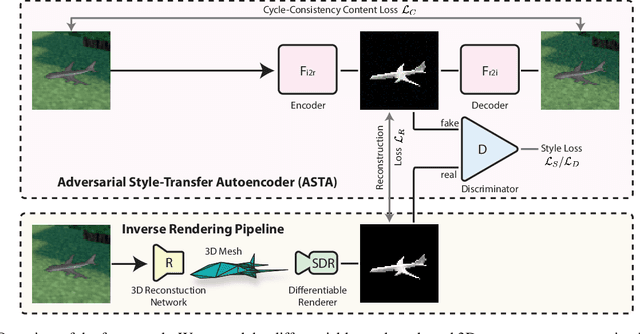
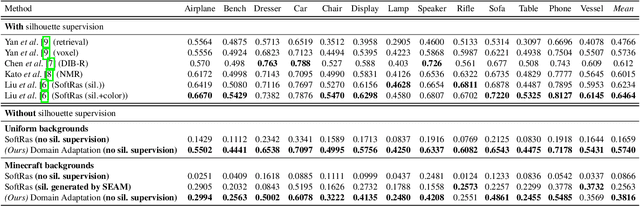
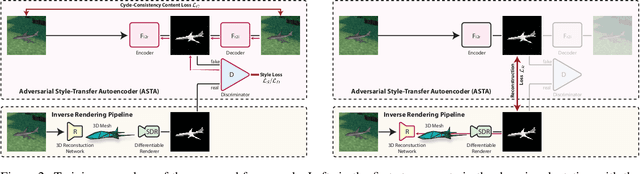

Reconstructing the 3D geometry of an object from an image is a major challenge in computer vision. Recently introduced differentiable renderers can be leveraged to learn the 3D geometry of objects from 2D images, but those approaches require additional supervision to enable the renderer to produce an output that can be compared to the input image. This can be scene information or constraints such as object silhouettes, uniform backgrounds, material, texture, and lighting. In this paper, we propose an approach that enables a differentiable rendering-based learning of 3D objects from images with backgrounds without the need for silhouette supervision. Instead of trying to render an image close to the input, we propose an adversarial style-transfer and domain adaptation pipeline that allows to translate the input image domain to the rendered image domain. This allows us to directly compare between a translated image and the differentiable rendering of a 3D object reconstruction in order to train the 3D object reconstruction network. We show that the approach learns 3D geometry from images with backgrounds and provides a better performance than constrained methods for single-view 3D object reconstruction on this task.
LocATe: End-to-end Localization of Actions in 3D with Transformers
Mar 21, 2022

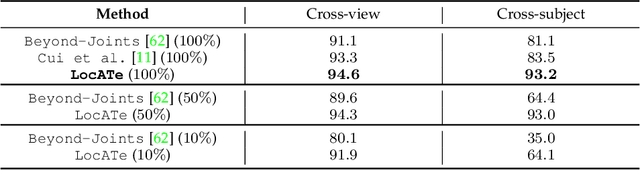
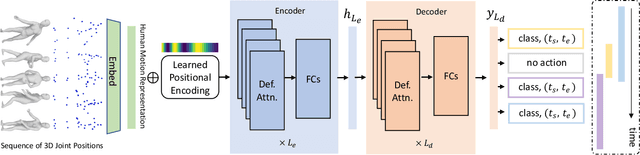
Understanding a person's behavior from their 3D motion is a fundamental problem in computer vision with many applications. An important component of this problem is 3D Temporal Action Localization (3D-TAL), which involves recognizing what actions a person is performing, and when. State-of-the-art 3D-TAL methods employ a two-stage approach in which the action span detection task and the action recognition task are implemented as a cascade. This approach, however, limits the possibility of error-correction. In contrast, we propose LocATe, an end-to-end approach that jointly localizes and recognizes actions in a 3D sequence. Further, unlike existing autoregressive models that focus on modeling the local context in a sequence, LocATe's transformer model is capable of capturing long-term correlations between actions in a sequence. Unlike transformer-based object-detection and classification models which consider image or patch features as input, the input in 3D-TAL is a long sequence of highly correlated frames. To handle the high-dimensional input, we implement an effective input representation, and overcome the diffuse attention across long time horizons by introducing sparse attention in the model. LocATe outperforms previous approaches on the existing PKU-MMD 3D-TAL benchmark (mAP=93.2%). Finally, we argue that benchmark datasets are most useful where there is clear room for performance improvement. To that end, we introduce a new, challenging, and more realistic benchmark dataset, BABEL-TAL-20 (BT20), where the performance of state-of-the-art methods is significantly worse. The dataset and code for the method will be available for research purposes.
Multi-Scale Hourglass Hierarchical Fusion Network for Single Image Deraining
Apr 25, 2021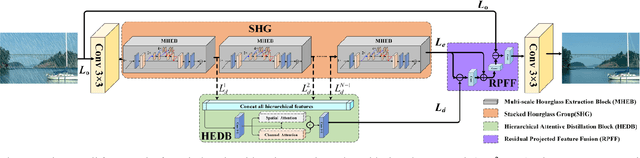

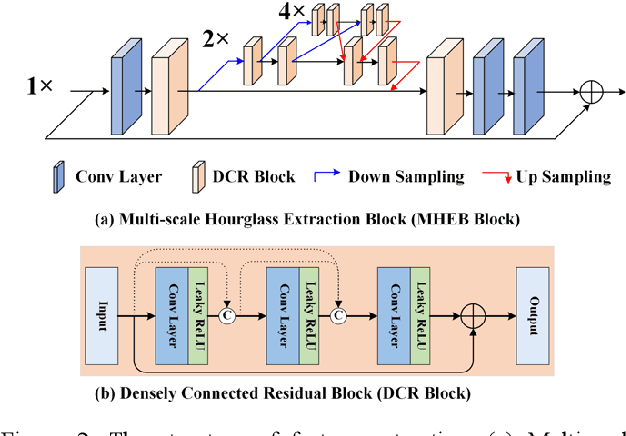
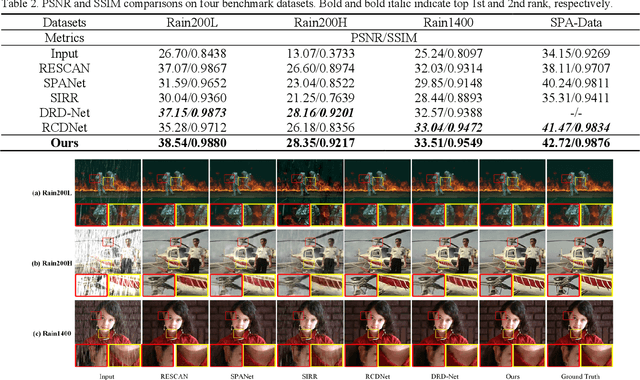
Rain streaks bring serious blurring and visual quality degradation, which often vary in size, direction and density. Current CNN-based methods achieve encouraging performance, while are limited to depict rain characteristics and recover image details in the poor visibility environment. To address these issues, we present a Multi-scale Hourglass Hierarchical Fusion Network (MH2F-Net) in end-to-end manner, to exactly captures rain streak features with multi-scale extraction, hierarchical distillation and information aggregation. For better extracting the features, a novel Multi-scale Hourglass Extraction Block (MHEB) is proposed to get local and global features across different scales through down- and up-sample process. Besides, a Hierarchical Attentive Distillation Block (HADB) then employs the dual attention feature responses to adaptively recalibrate the hierarchical features and eliminate the redundant ones. Further, we introduce a Residual Projected Feature Fusion (RPFF) strategy to progressively discriminate feature learning and aggregate different features instead of directly concatenating or adding. Extensive experiments on both synthetic and real rainy datasets demonstrate the effectiveness of the designed MH2F-Net by comparing with recent state-of-the-art deraining algorithms. Our source code will be available on the GitHub: https://github.com/cxtalk/MH2F-Net.
Diversify and Disambiguate: Learning From Underspecified Data
Feb 07, 2022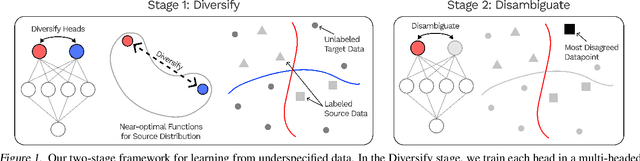
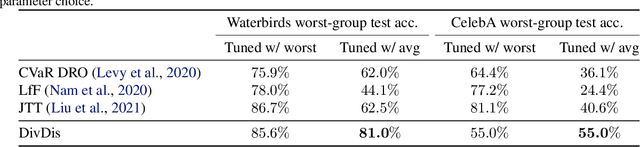
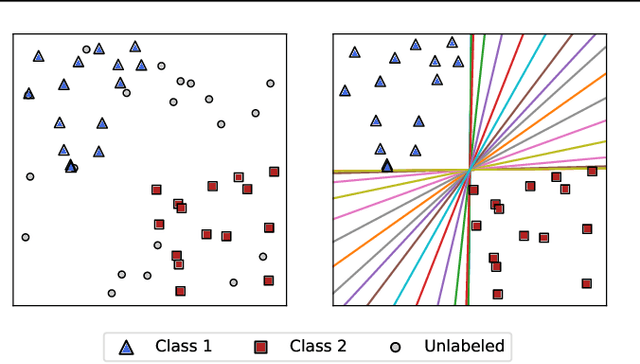
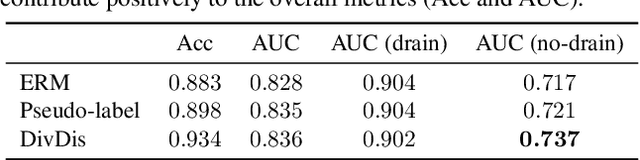
Many datasets are underspecified, which means there are several equally viable solutions for the data. Underspecified datasets can be problematic for methods that learn a single hypothesis because different functions that achieve low training loss can focus on different predictive features and thus have widely varying predictions on out-of-distribution data. We propose DivDis, a simple two-stage framework that first learns a diverse collection of hypotheses for a task by leveraging unlabeled data from the test distribution. We then disambiguate by selecting one of the discovered hypotheses using minimal additional supervision, in the form of additional labels or inspection of function visualization. We demonstrate the ability of DivDis to find hypotheses that use robust features in image classification and natural language processing problems with underspecification.
Semantic-Aware Generation for Self-Supervised Visual Representation Learning
Nov 25, 2021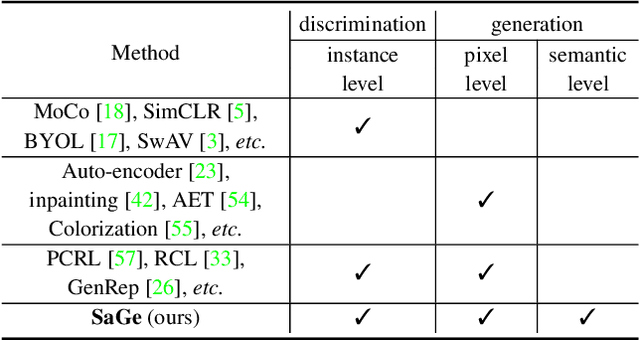
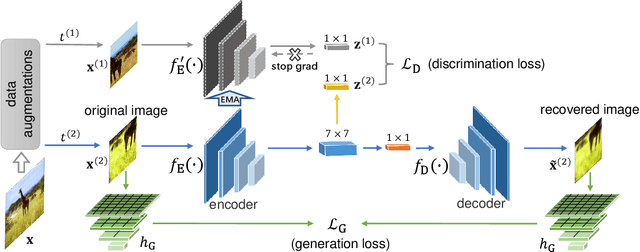

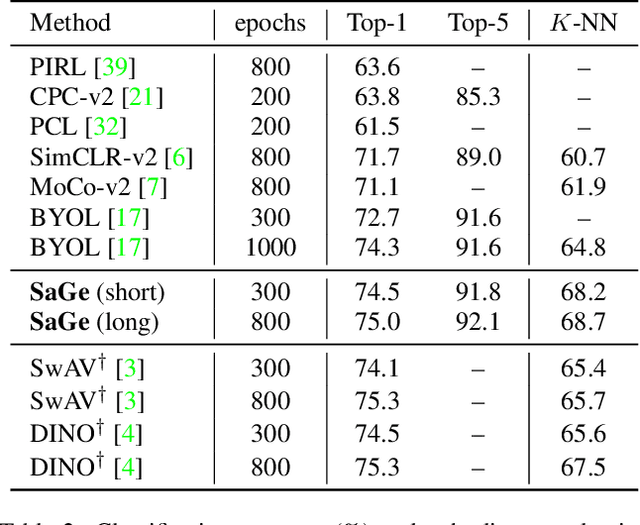
In this paper, we propose a self-supervised visual representation learning approach which involves both generative and discriminative proxies, where we focus on the former part by requiring the target network to recover the original image based on the mid-level features. Different from prior work that mostly focuses on pixel-level similarity between the original and generated images, we advocate for Semantic-aware Generation (SaGe) to facilitate richer semantics rather than details to be preserved in the generated image. The core idea of implementing SaGe is to use an evaluator, a deep network that is pre-trained without labels, for extracting semantic-aware features. SaGe complements the target network with view-specific features and thus alleviates the semantic degradation brought by intensive data augmentations. We execute SaGe on ImageNet-1K and evaluate the pre-trained models on five downstream tasks including nearest neighbor test, linear classification, and fine-scaled image recognition, demonstrating its ability to learn stronger visual representations.
MDReg-Net: Multi-resolution diffeomorphic image registration using fully convolutional networks with deep self-supervision
Oct 04, 2020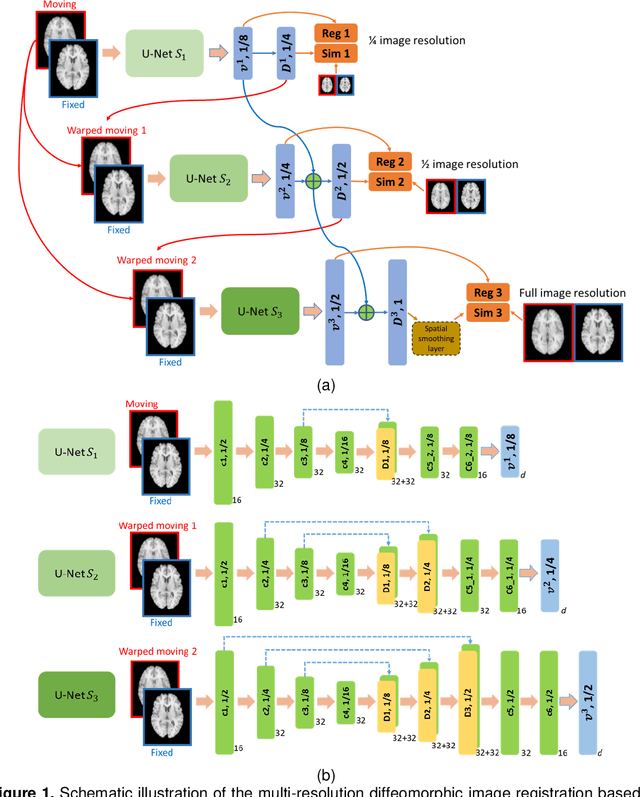
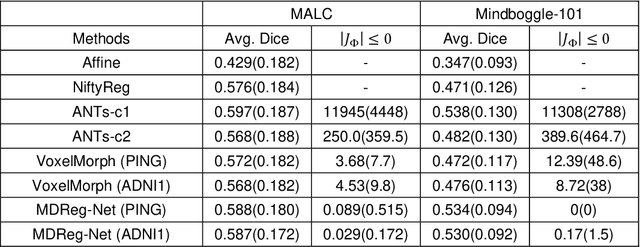
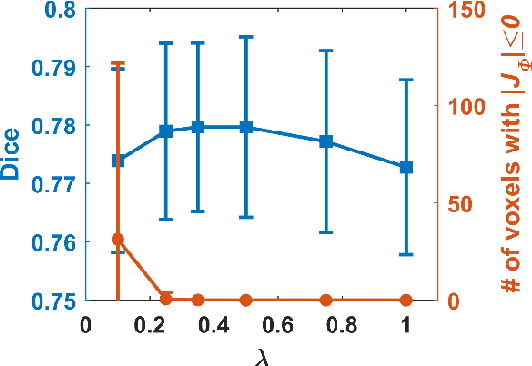
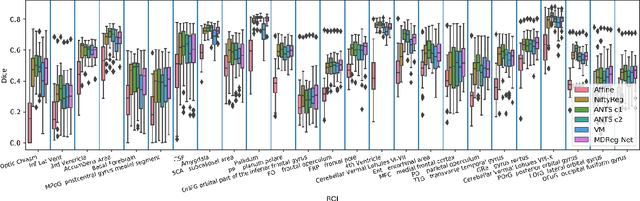
We present a diffeomorphic image registration algorithm to learn spatial transformations between pairs of images to be registered using fully convolutional networks (FCNs) under a self-supervised learning setting. The network is trained to estimate diffeomorphic spatial transformations between pairs of images by maximizing an image-wise similarity metric between fixed and warped moving images, similar to conventional image registration algorithms. It is implemented in a multi-resolution image registration framework to optimize and learn spatial transformations at different image resolutions jointly and incrementally with deep self-supervision in order to better handle large deformation between images. A spatial Gaussian smoothing kernel is integrated with the FCNs to yield sufficiently smooth deformation fields to achieve diffeomorphic image registration. Particularly, spatial transformations learned at coarser resolutions are utilized to warp the moving image, which is subsequently used for learning incremental transformations at finer resolutions. This procedure proceeds recursively to the full image resolution and the accumulated transformations serve as the final transformation to warp the moving image at the finest resolution. Experimental results for registering high resolution 3D structural brain magnetic resonance (MR) images have demonstrated that image registration networks trained by our method obtain robust, diffeomorphic image registration results within seconds with improved accuracy compared with state-of-the-art image registration algorithms.