 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RestoreDet: Degradation Equivariant Representation for Object Detection in Low Resolution Images
Jan 07, 2022
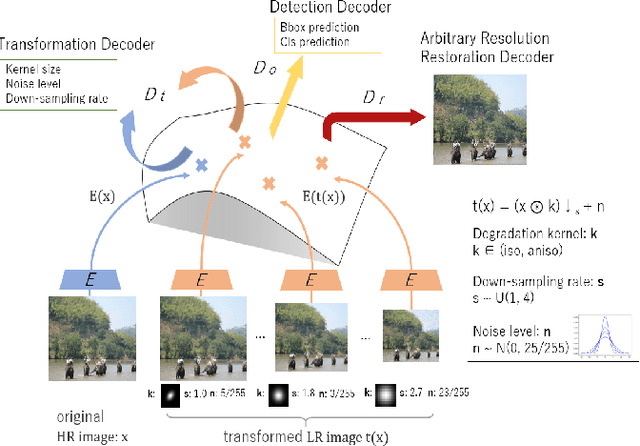
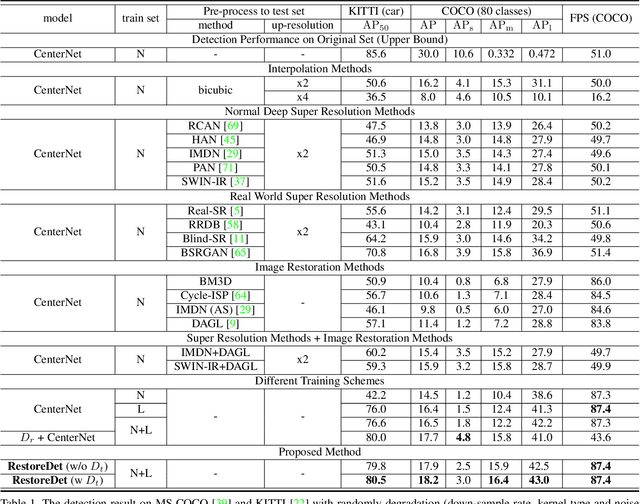
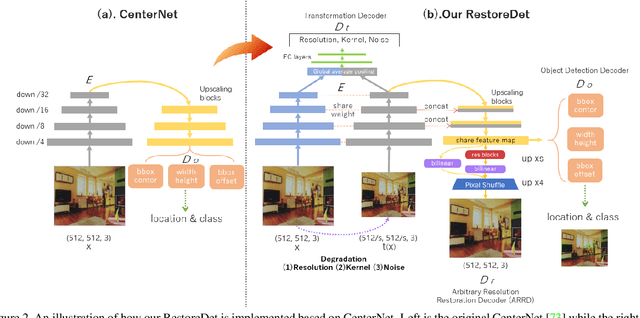
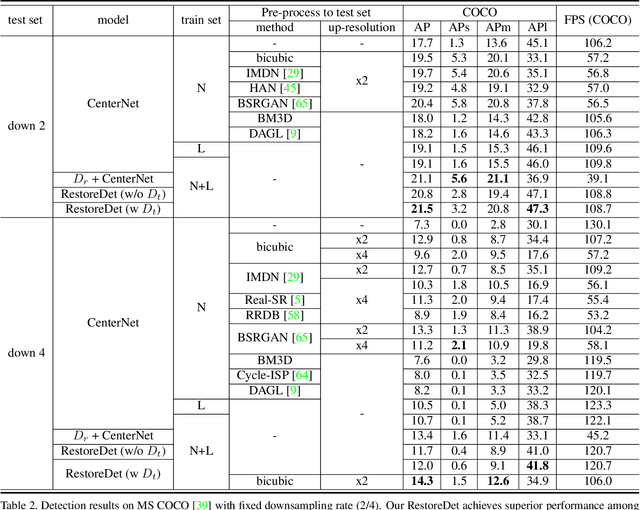
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in degraded images. However, most of these algorithms assume the degradation is fixed and known a priori. When the real degradation is unknown or differs from assumption, both the pre-processing module and the consequent high-level task such as object detection would fail. Here, we propose a novel framework, RestoreDet, to detect objects in degraded low resolution images. RestoreDet utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. Specifically, we learn this intrinsic visual structure by encoding and decoding the degradation transformation from a pair of original and randomly degraded images. The framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. RestoreDet is a generic framework that could be implemented on any mainstream object detection architectures. The extensive experiment shows that our framework based on CenterNet has achieved superior performance compared with existing methods when facing variant degradation situations. Our code would be released soon.
Going to Extremes: Weakly Supervised Medical Image Segmentation
Sep 25, 2020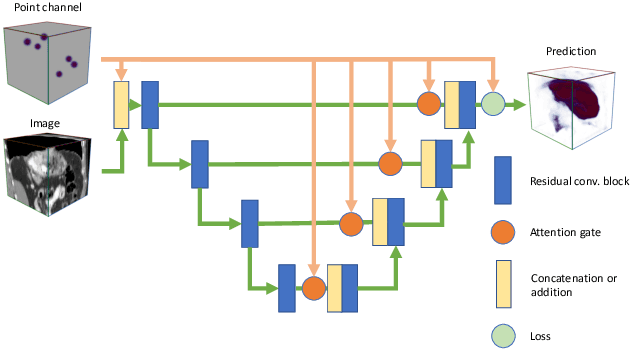
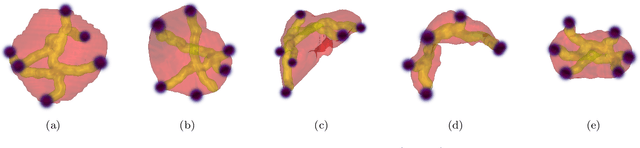

Medical image annotation is a major hurdle for developing precise and robust machine learning models. Annotation is expensive, time-consuming, and often requires expert knowledge, particularly in the medical field. Here, we suggest using minimal user interaction in the form of extreme point clicks to train a segmentation model which, in effect, can be used to speed up medical image annotation. An initial segmentation is generated based on the extreme points utilizing the random walker algorithm. This initial segmentation is then used as a noisy supervision signal to train a fully convolutional network that can segment the organ of interest, based on the provided user clicks. Through experimentation on several medical imaging datasets, we show that the predictions of the network can be refined using several rounds of training with the prediction from the same weakly annotated data. Further improvements are shown utilizing the clicked points within a custom-designed loss and attention mechanism. Our approach has the potential to speed up the process of generating new training datasets for the development of new machine learning and deep learning-based models for, but not exclusively, medical image analysis.
Cross-Modal Transferable Adversarial Attacks from Images to Videos
Dec 10, 2021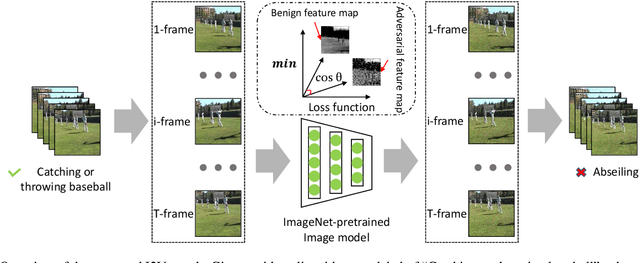
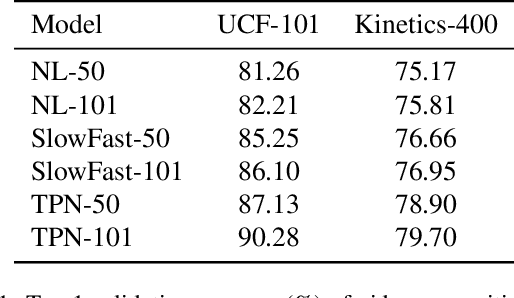
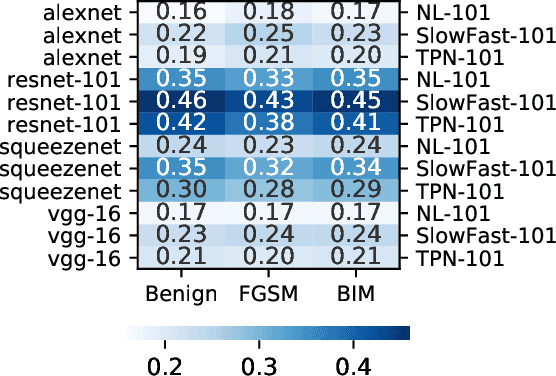
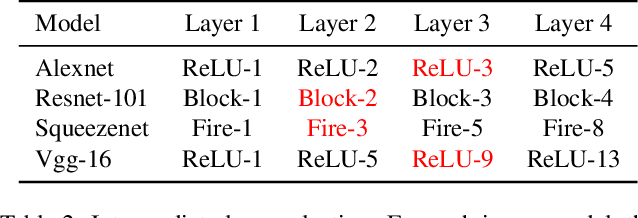
Recent studies have shown that adversarial examples hand-crafted on one white-box model can be used to attack other black-box models. Such cross-model transferability makes it feasible to perform black-box attacks, which has raised security concerns for real-world DNNs applications. Nevertheless, existing works mostly focus on investigating the adversarial transferability across different deep models that share the same modality of input data. The cross-modal transferability of adversarial perturbation has never been explored. This paper investigates the transferability of adversarial perturbation across different modalities, i.e., leveraging adversarial perturbation generated on white-box image models to attack black-box video models. Specifically, motivated by the observation that the low-level feature space between images and video frames are similar, we propose a simple yet effective cross-modal attack method, named as Image To Video (I2V) attack. I2V generates adversarial frames by minimizing the cosine similarity between features of pre-trained image models from adversarial and benign examples, then combines the generated adversarial frames to perform black-box attacks on video recognition models. Extensive experiments demonstrate that I2V can achieve high attack success rates on different black-box video recognition models. On Kinetics-400 and UCF-101, I2V achieves an average attack success rate of 77.88% and 65.68%, respectively, which sheds light on the feasibility of cross-modal adversarial attacks.
PRIME: A Few Primitives Can Boost Robustness to Common Corruptions
Dec 27, 2021
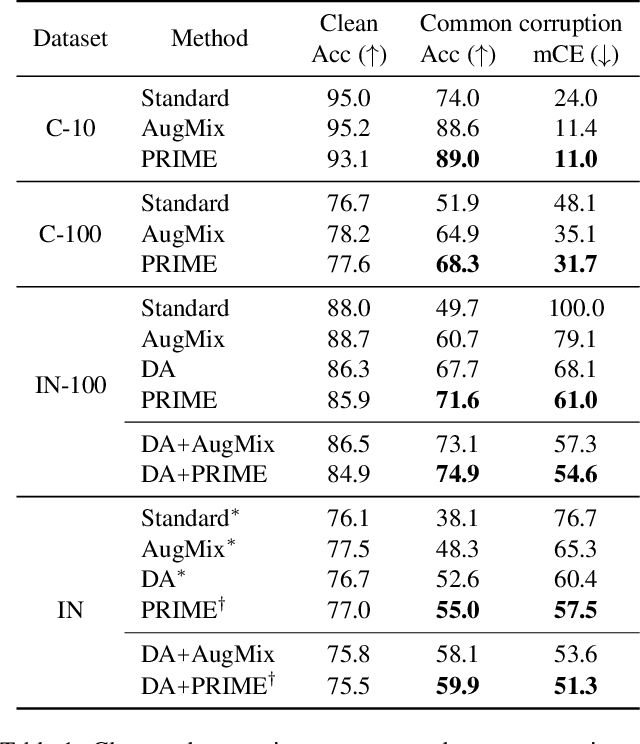

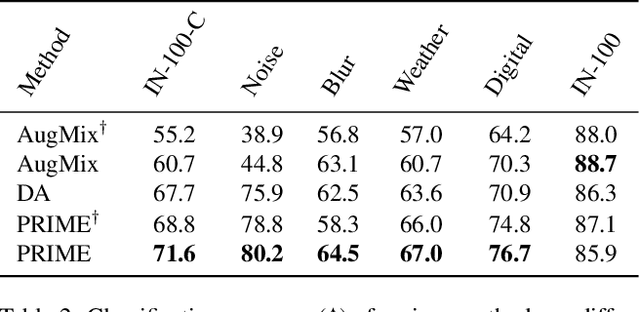
Despite their impressive performance on image classification tasks, deep networks have a hard time generalizing to many common corruptions of their data. To fix this vulnerability, prior works have mostly focused on increasing the complexity of their training pipelines, combining multiple methods, in the name of diversity. However, in this work, we take a step back and follow a principled approach to achieve robustness to common corruptions. We propose PRIME, a general data augmentation scheme that consists of simple families of max-entropy image transformations. We show that PRIME outperforms the prior art for corruption robustness, while its simplicity and plug-and-play nature enables it to be combined with other methods to further boost their robustness. Furthermore, we analyze PRIME to shed light on the importance of the mixing strategy on synthesizing corrupted images, and to reveal the robustness-accuracy trade-offs arising in the context of common corruptions. Finally, we show that the computational efficiency of our method allows it to be easily used in both on-line and off-line data augmentation schemes.
YOLO -- You only look 10647 times
Jan 21, 2022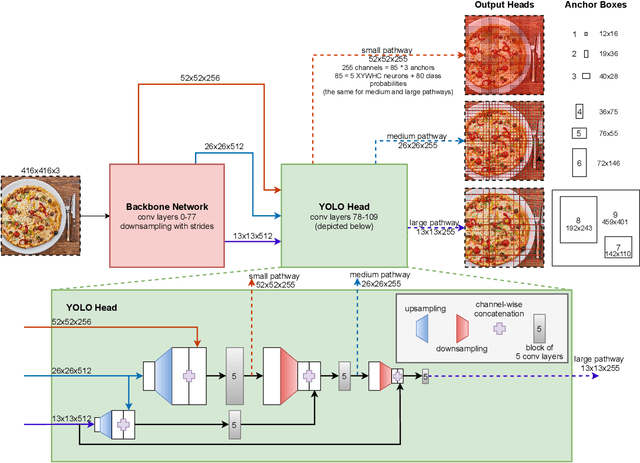



With this work we are explaining the "You Only Look Once" (YOLO) single-stage object detection approach as a parallel classification of 10647 fixed region proposals. We support this view by showing that each of YOLOs output pixel is attentive to a specific sub-region of previous layers, comparable to a local region proposal. This understanding reduces the conceptual gap between YOLO-like single-stage object detection models, RCNN-like two-stage region proposal based models, and ResNet-like image classification models. In addition, we created interactive exploration tools for a better visual understanding of the YOLO information processing streams: https://limchr.github.io/yolo_visualization
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
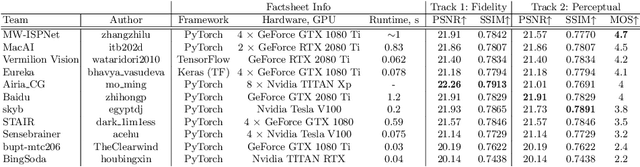
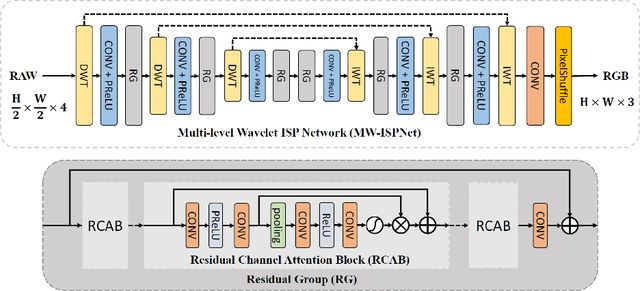
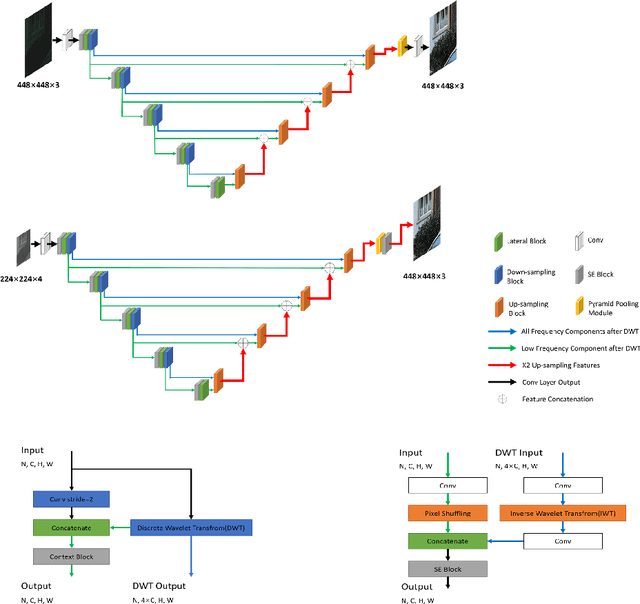
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
Learning CNN filters from user-drawn image markers for coconut-tree image classification
Aug 08, 2020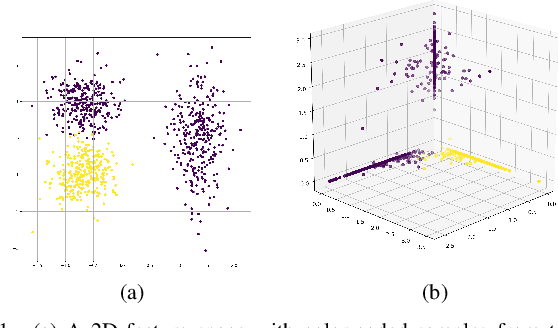
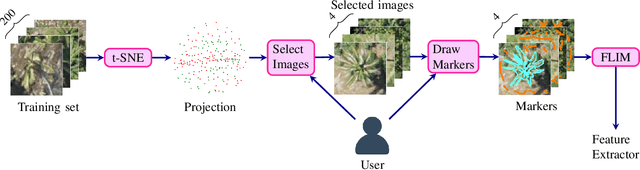


Identifying species of trees in aerial images is essential for land-use classification, plantation monitoring, and impact assessment of natural disasters. The manual identification of trees in aerial images is tedious, costly, and error-prone, so automatic classification methods are necessary. Convolutional Neural Network (CNN) models have well succeeded in image classification applications from different domains. However, CNN models usually require intensive manual annotation to create large training sets. One may conceptually divide a CNN into convolutional layers for feature extraction and fully connected layers for feature space reduction and classification. We present a method that needs a minimal set of user-selected images to train the CNN's feature extractor, reducing the number of required images to train the fully connected layers. The method learns the filters of each convolutional layer from user-drawn markers in image regions that discriminate classes, allowing better user control and understanding of the training process. It does not rely on optimization based on backpropagation, and we demonstrate its advantages on the binary classification of coconut-tree aerial images against one of the most popular CNN models.
Towards Unbiased Multi-label Zero-Shot Learning with Pyramid and Semantic Attention
Mar 07, 2022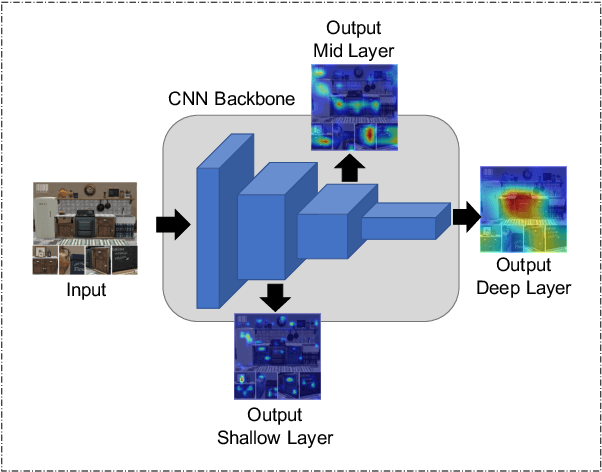
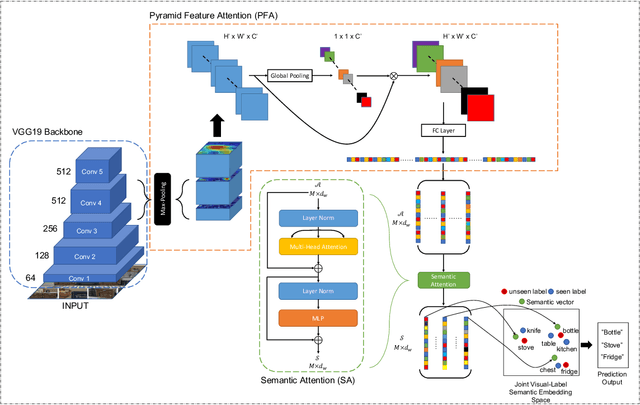
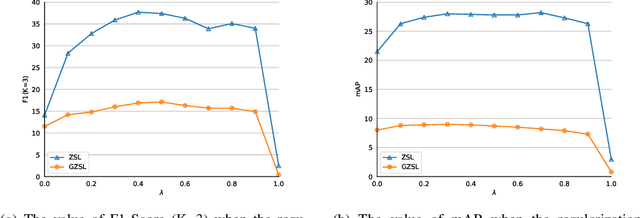

Multi-label zero-shot learning extends conventional single-label zero-shot learning to a more realistic scenario that aims at recognizing multiple unseen labels of classes for each input sample. Existing works usually exploit attention mechanism to generate the correlation among different labels. However, most of them are usually biased on several major classes while neglect most of the minor classes with the same importance in input samples, and may thus result in overly diffused attention maps that cannot sufficiently cover minor classes. We argue that disregarding the connection between major and minor classes, i.e., correspond to the global and local information, respectively, is the cause of the problem. In this paper, we propose a novel framework of unbiased multi-label zero-shot learning, by considering various class-specific regions to calibrate the training process of the classifier. Specifically, Pyramid Feature Attention (PFA) is proposed to build the correlation between global and local information of samples to balance the presence of each class. Meanwhile, for the generated semantic representations of input samples, we propose Semantic Attention (SA) to strengthen the element-wise correlation among these vectors, which can encourage the coordinated representation of them. Extensive experiments on the large-scale multi-label zero-shot benchmarks NUS-WIDE and Open-Image demonstrate that the proposed method surpasses other representative methods by significant margins.
DeepJSCC-Q: Channel Input Constrained Deep Joint Source-Channel Coding
Nov 25, 2021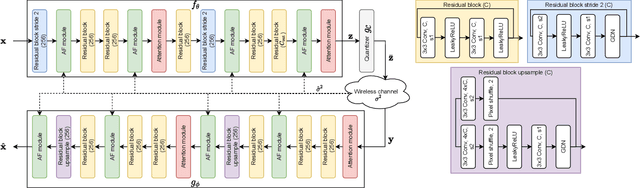
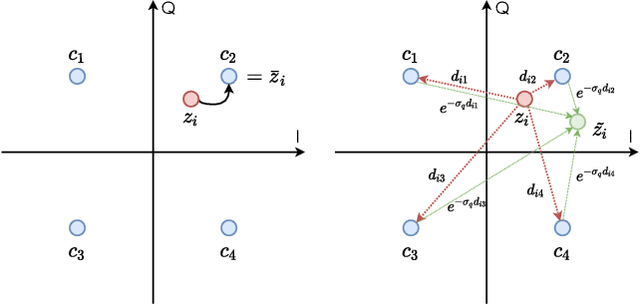
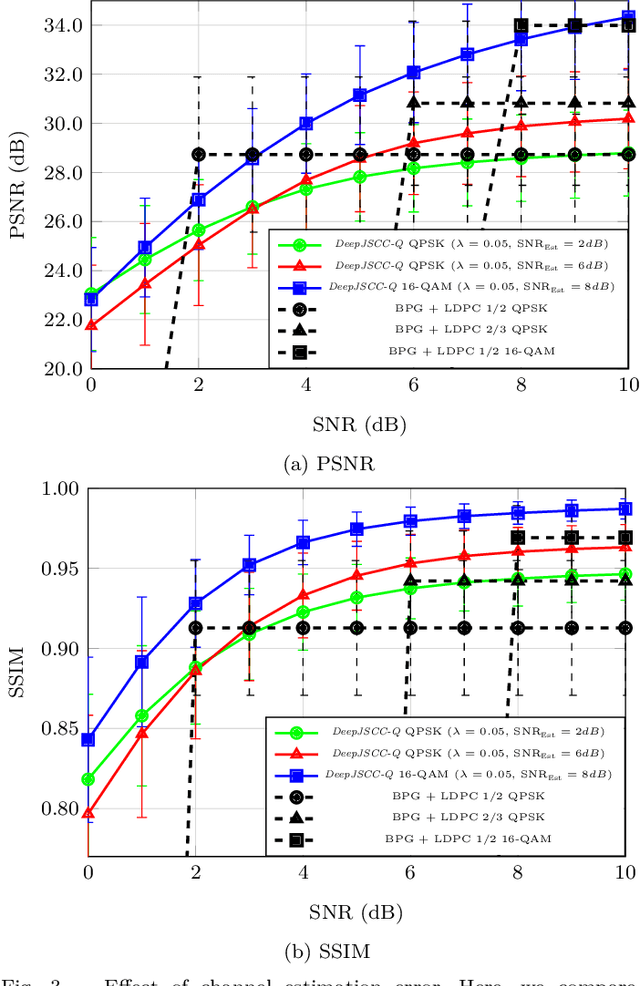
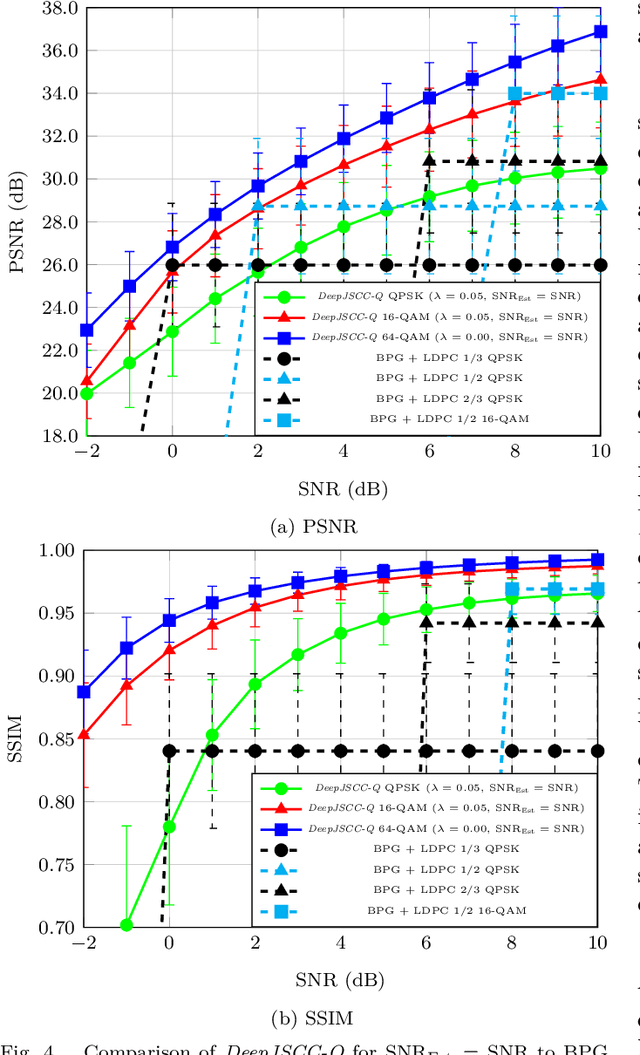
Recent works have shown that the task of wireless transmission of images can be learned with the use of machine learning techniques. Very promising results in end-to-end image quality, superior to popular digital schemes that utilize source and channel coding separation, have been demonstrated through the training of an autoencoder, with a non-trainable channel layer in the middle. However, these methods assume that any complex value can be transmitted over the channel, which can prevent the application of the algorithm in scenarios where the hardware or protocol can only admit certain sets of channel inputs, such as the use of a digital constellation. Herein, we propose DeepJSCC-Q, an end-to-end optimized joint source-channel coding scheme for wireless image transmission, which is able to operate with a fixed channel input alphabet. We show that DeepJSCC-Q can achieve similar performance to models that use continuous-valued channel input. Importantly, it preserves the graceful degradation of image quality observed in prior work when channel conditions worsen, making DeepJSCC-Q much more attractive for deployment in practical systems.
VLP: A Survey on Vision-Language Pre-training
Feb 21, 2022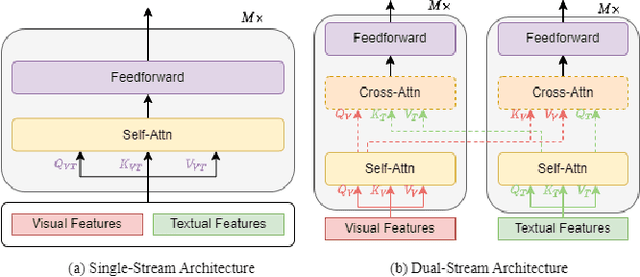
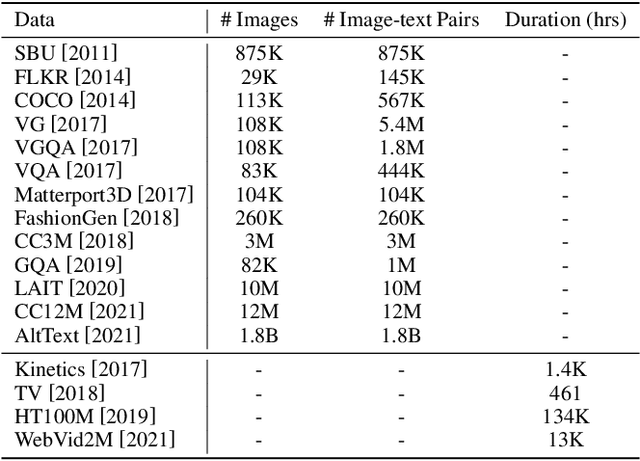
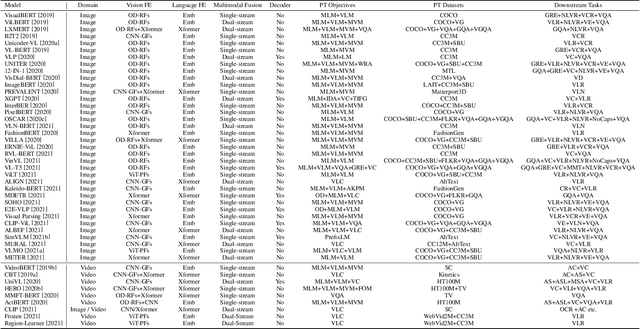
In the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances from five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey on VLP. We hope that this survey can shed light on future research in the VLP field.