 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Right for the Right Reason: Making Image Classification Robust
Jul 23, 2020

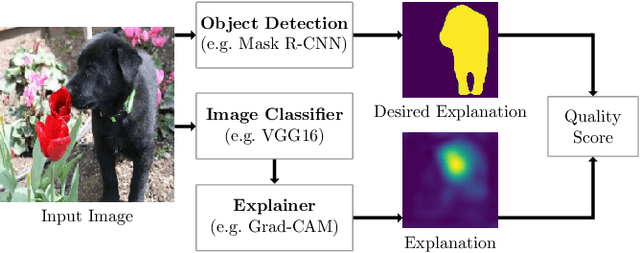
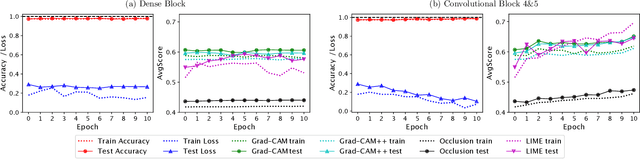

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks. Although such models classify most images correctly, they do not provide any explanation for their decisions. Recently, there have been attempts to provide such an explanation by determining which parts of the input image the classifier focuses on most. It turns out that many models output the correct classification, but for the wrong reason (e.g., based on irrelevant parts of the image). In this paper, we propose a new score for automatically quantifying to which degree the model focuses on the right image parts. The score is calculated by considering the degree to which the most decisive image regions - given by applying an explainer to the CNN model - overlap with the silhouette of the object to be classified. In extensive experiments using VGG16, ResNet, and MobileNet as CNNs, Occlusion, LIME, and Grad-Cam/Grad-Cam++ as explanation methods, and Dogs vs. Cats and Caltech 101 as data sets, we can show that our metric can indeed be used for making CNN models for image classification more robust while keeping their accuracy.
Convolutional-LSTM for Multi-Image to Single Output Medical Prediction
Oct 20, 2020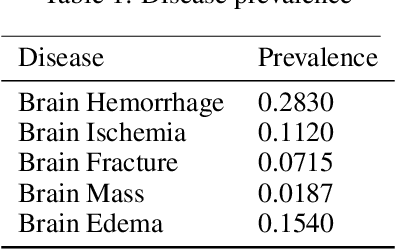
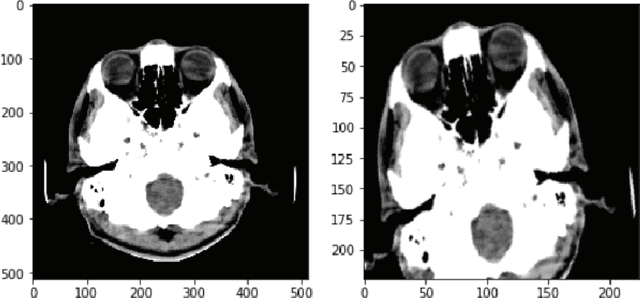
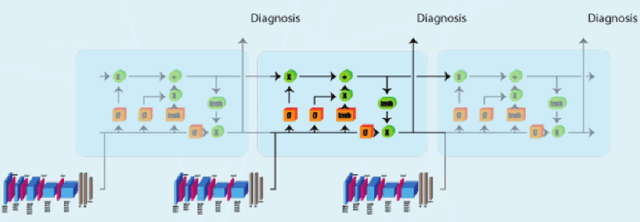
Medical head CT-scan imaging has been successfully combined with deep learning for medical diagnostics of head diseases and lesions[1]. State of the art classification models and algorithms for this task usually are based on 3d convolution layers for volumetric data on a supervised learning setting (1 input volume, 1 prediction per patient) or 2d convolution layers in a supervised setting (1 input image, 1 prediction per image). However a very common scenario in developing countries is to have the volume metadata lost due multiple reasons for example formatting conversion in images (for example .dicom to jpg), in this scenario the doctor analyses the collection of images and then emits a single diagnostic for the patient (with possibly an unfixed and variable number of images per patient) , this prevents it from being possible to use state of the art 3d models, but also is not possible to convert it to a supervised problem in a (1 image,1 diagnostic) setting because different angles or positions of the images for a single patient may not contain the disease or lesion. In this study we propose a solution for this scenario by combining 2d convolutional[2] models with sequence models which generate a prediction only after all images have been processed by the model for a given patient \(i\), this creates a multi-image to single-diagnostic setting \(y^i=f(x_1,x_2,..,x_n)\) where \(n\) may be different between patients. The experimental results demonstrate that it is possible to get a multi-image to single diagnostic model which mimics human doctor diagnostic process: evaluate the collection of patient images and then use important information in memory to decide a single diagnostic for the patient.
Holographic Image Sensing
Feb 09, 2020

Holographic representations of data enable distributed storage with progressive refinement when the stored packets of data are made available in any arbitrary order. In this paper, we propose and test patch-based transform coding holographic sensing of image data. Our proposal is optimized for progressive recovery under random order of retrieval of the stored data. The coding of the image patches relies on the design of distributed projections ensuring best image recovery, in terms of the $\ell_2$ norm, at each retrieval stage. The performance depends only on the number of data packets that has been retrieved thus far. Several possible options to enhance the quality of the recovery while changing the size and number of data packets are discussed and tested. This leads us to examine several interesting bit-allocation and rate-distortion trade offs, highlighted for a set of natural images with ensemble estimated statistical properties.
Video Temporal Relationship Mining for Data-Efficient Person Re-identification
Oct 01, 2021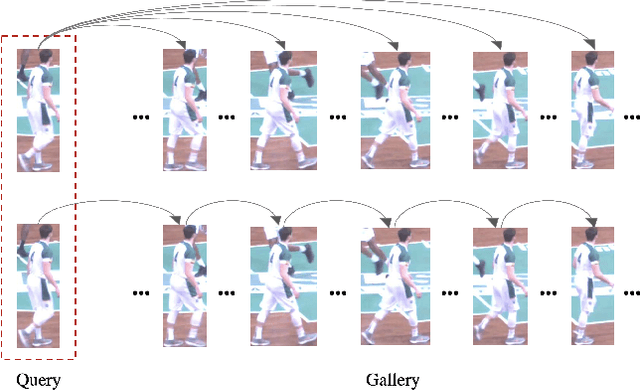
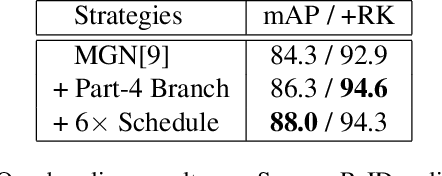
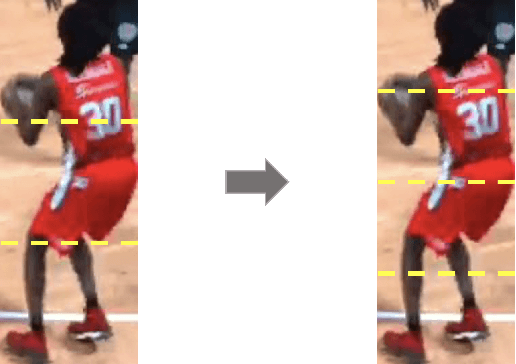
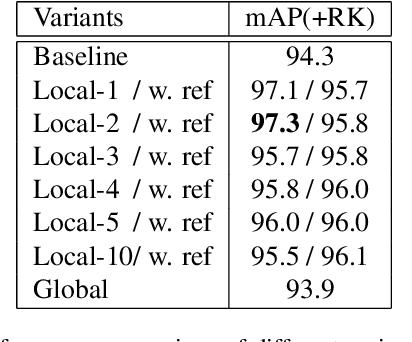
This paper is a technical report to our submission to the ICCV 2021 VIPriors Re-identification Challenge. In order to make full use of the visual inductive priors of the data, we treat the query and gallery images of the same identity as continuous frames in a video sequence. And we propose one novel post-processing strategy for video temporal relationship mining, which not only calculates the distance matrix between query and gallery images, but also the matrix between gallery images. The initial query image is used to retrieve the most similar image from the gallery, then the retrieved image is treated as a new query to retrieve its most similar image from the gallery. By iteratively searching for the closest image, we can achieve accurate image retrieval and finally obtain a robust retrieval sequence.
Deep Convolutional Sparse Coding Networks for Image Fusion
May 18, 2020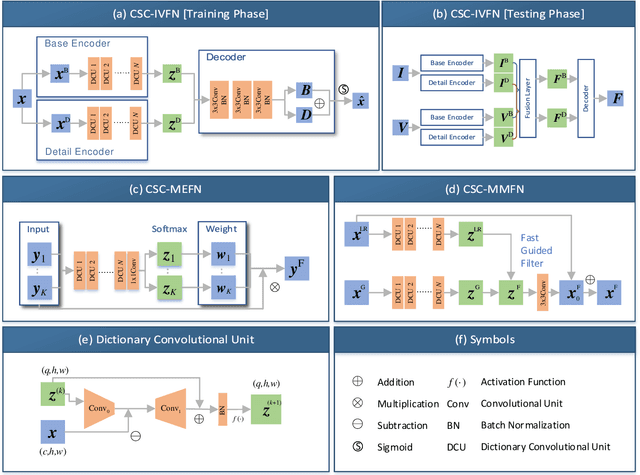


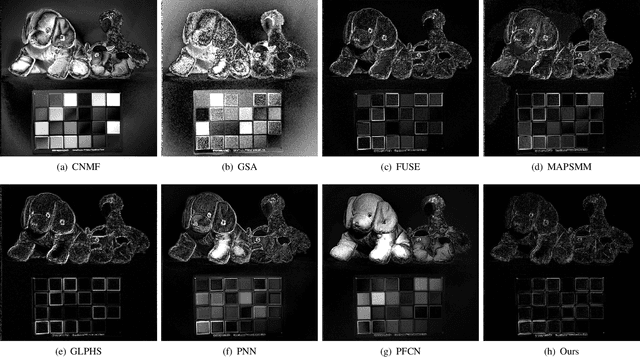
Image fusion is a significant problem in many fields including digital photography, computational imaging and remote sensing, to name but a few. Recently, deep learning has emerged as an important tool for image fusion. This paper presents three deep convolutional sparse coding (CSC) networks for three kinds of image fusion tasks (i.e., infrared and visible image fusion, multi-exposure image fusion, and multi-modal image fusion). The CSC model and the iterative shrinkage and thresholding algorithm are generalized into dictionary convolution units. As a result, all hyper-parameters are learned from data. Our extensive experiments and comprehensive comparisons reveal the superiority of the proposed networks with regard to quantitative evaluation and visual inspection.
Analogical Image Translation for Fog Generation
Jun 28, 2020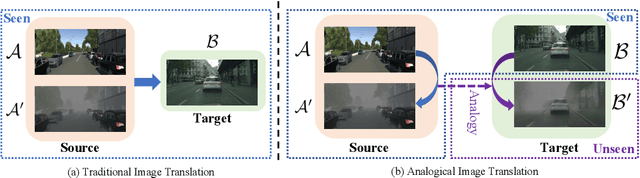
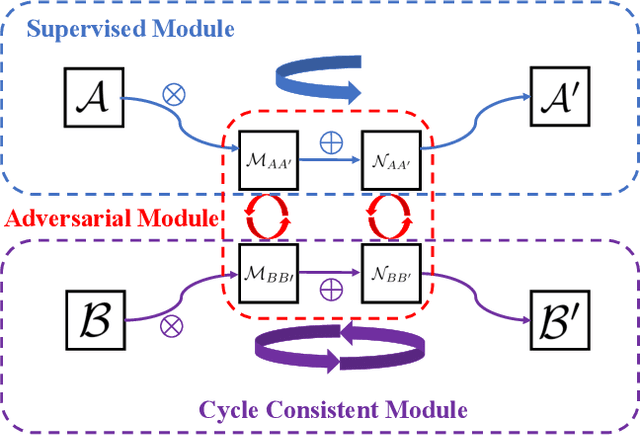

Image-to-image translation is to map images from a given \emph{style} to another given \emph{style}. While exceptionally successful, current methods assume the availability of training images in both source and target domains, which does not always hold in practice. Inspired by humans' reasoning capability of analogy, we propose analogical image translation (AIT). Given images of two styles in the source domain: $\mathcal{A}$ and $\mathcal{A}^\prime$, along with images $\mathcal{B}$ of the first style in the target domain, learn a model to translate $\mathcal{B}$ to $\mathcal{B}^\prime$ in the target domain, such that $\mathcal{A}:\mathcal{A}^\prime ::\mathcal{B}:\mathcal{B}^\prime$. AIT is especially useful for translation scenarios in which training data of one style is hard to obtain but training data of the same two styles in another domain is available. For instance, in the case from normal conditions to extreme, rare conditions, obtaining real training images for the latter case is challenging but obtaining synthetic data for both cases is relatively easy. In this work, we are interested in adding adverse weather effects, more specifically fog effects, to images taken in clear weather. To circumvent the challenge of collecting real foggy images, AIT learns with synthetic clear-weather images, synthetic foggy images and real clear-weather images to add fog effects onto real clear-weather images without seeing any real foggy images during training. AIT achieves this zero-shot image translation capability by coupling a supervised training scheme in the synthetic domain, a cycle consistency strategy in the real domain, an adversarial training scheme between the two domains, and a novel network design. Experiments show the effectiveness of our method for zero-short image translation and its benefit for downstream tasks such as semantic foggy scene understanding.
Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding
Apr 27, 2021



Underwater images suffer from color casts and low contrast due to wavelength- and distance-dependent attenuation and scattering. To solve these two degradation issues, we present an underwater image enhancement network via medium transmission-guided multi-color space embedding, called Ucolor. Concretely, we first propose a multi-color space encoder network, which enriches the diversity of feature representations by incorporating the characteristics of different color spaces into a unified structure. Coupled with an attention mechanism, the most discriminative features extracted from multiple color spaces are adaptively integrated and highlighted. Inspired by underwater imaging physical models, we design a medium transmission (indicating the percentage of the scene radiance reaching the camera)-guided decoder network to enhance the response of the network towards quality-degraded regions. As a result, our network can effectively improve the visual quality of underwater images by exploiting multiple color spaces embedding and the advantages of both physical model-based and learning-based methods. Extensive experiments demonstrate that our Ucolor achieves superior performance against state-of-the-art methods in terms of both visual quality and quantitative metrics.
Towards Unbiased Multi-label Zero-Shot Learning with Pyramid and Semantic Attention
Mar 07, 2022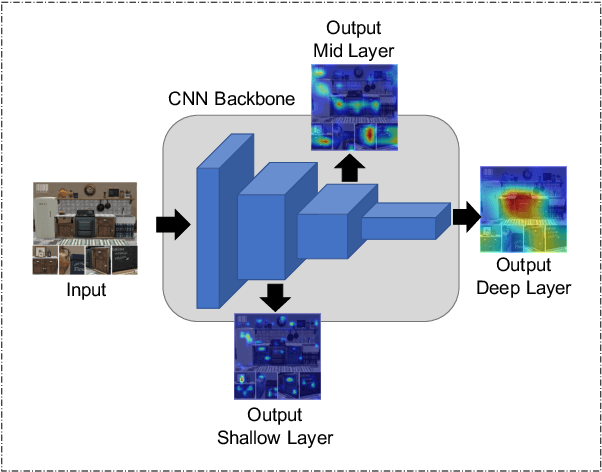
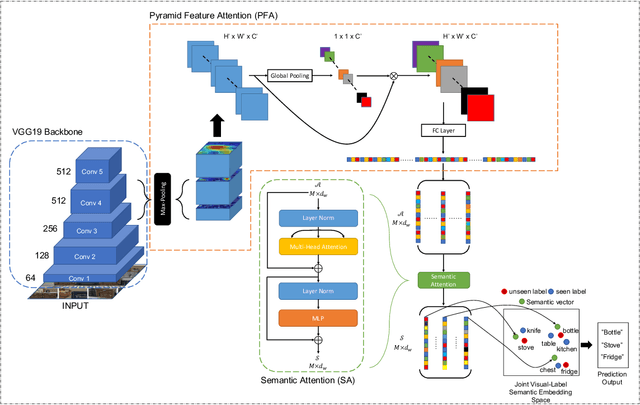
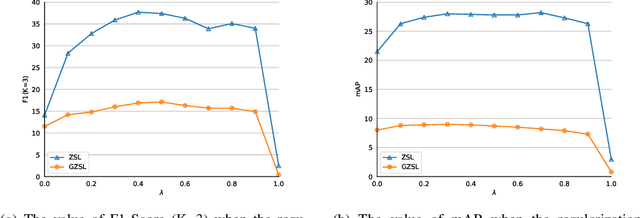

Multi-label zero-shot learning extends conventional single-label zero-shot learning to a more realistic scenario that aims at recognizing multiple unseen labels of classes for each input sample. Existing works usually exploit attention mechanism to generate the correlation among different labels. However, most of them are usually biased on several major classes while neglect most of the minor classes with the same importance in input samples, and may thus result in overly diffused attention maps that cannot sufficiently cover minor classes. We argue that disregarding the connection between major and minor classes, i.e., correspond to the global and local information, respectively, is the cause of the problem. In this paper, we propose a novel framework of unbiased multi-label zero-shot learning, by considering various class-specific regions to calibrate the training process of the classifier. Specifically, Pyramid Feature Attention (PFA) is proposed to build the correlation between global and local information of samples to balance the presence of each class. Meanwhile, for the generated semantic representations of input samples, we propose Semantic Attention (SA) to strengthen the element-wise correlation among these vectors, which can encourage the coordinated representation of them. Extensive experiments on the large-scale multi-label zero-shot benchmarks NUS-WIDE and Open-Image demonstrate that the proposed method surpasses other representative methods by significant margins.
RestoreDet: Degradation Equivariant Representation for Object Detection in Low Resolution Images
Jan 07, 2022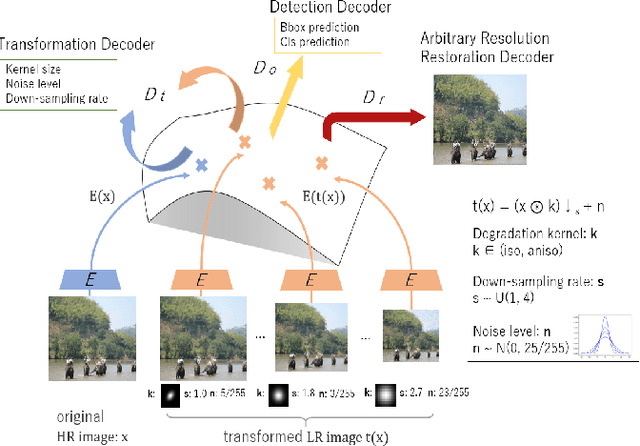
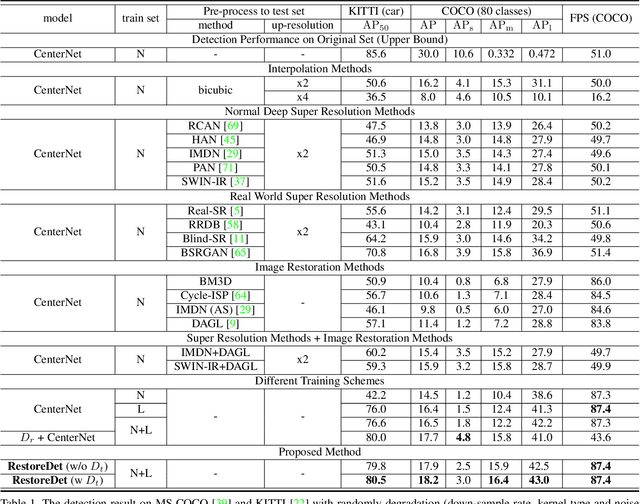
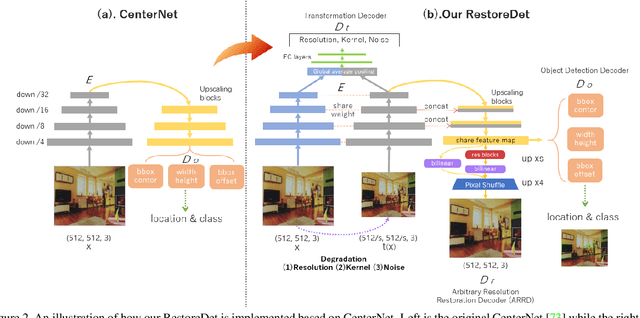
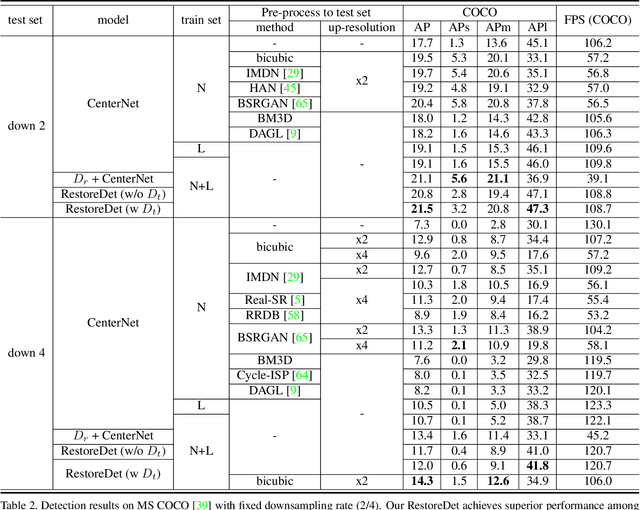
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in degraded images. However, most of these algorithms assume the degradation is fixed and known a priori. When the real degradation is unknown or differs from assumption, both the pre-processing module and the consequent high-level task such as object detection would fail. Here, we propose a novel framework, RestoreDet, to detect objects in degraded low resolution images. RestoreDet utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. Specifically, we learn this intrinsic visual structure by encoding and decoding the degradation transformation from a pair of original and randomly degraded images. The framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. RestoreDet is a generic framework that could be implemented on any mainstream object detection architectures. The extensive experiment shows that our framework based on CenterNet has achieved superior performance compared with existing methods when facing variant degradation situations. Our code would be released soon.
YOLO -- You only look 10647 times
Jan 21, 2022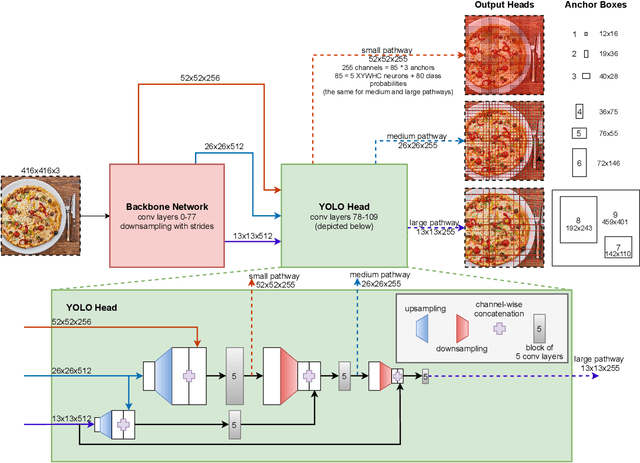



With this work we are explaining the "You Only Look Once" (YOLO) single-stage object detection approach as a parallel classification of 10647 fixed region proposals. We support this view by showing that each of YOLOs output pixel is attentive to a specific sub-region of previous layers, comparable to a local region proposal. This understanding reduces the conceptual gap between YOLO-like single-stage object detection models, RCNN-like two-stage region proposal based models, and ResNet-like image classification models. In addition, we created interactive exploration tools for a better visual understanding of the YOLO information processing streams: https://limchr.github.io/yolo_visualization