 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Change Detection from Synthetic Aperture Radar Images via Dual Path Denoising Network
Mar 13, 2022
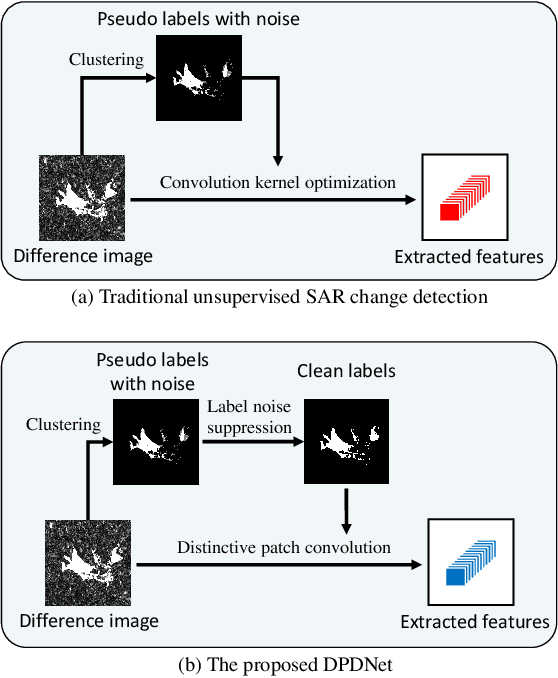

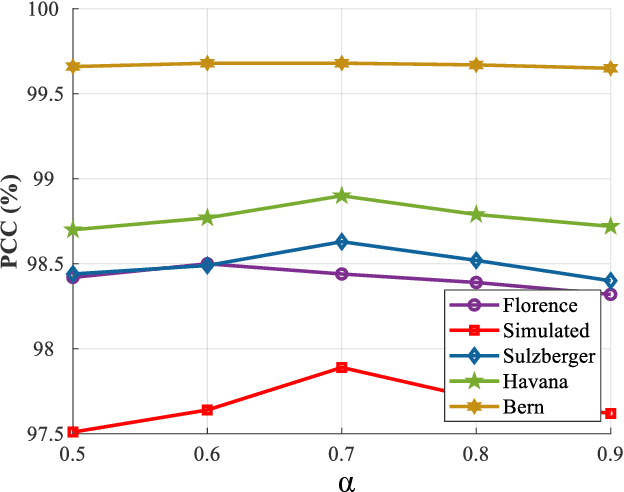
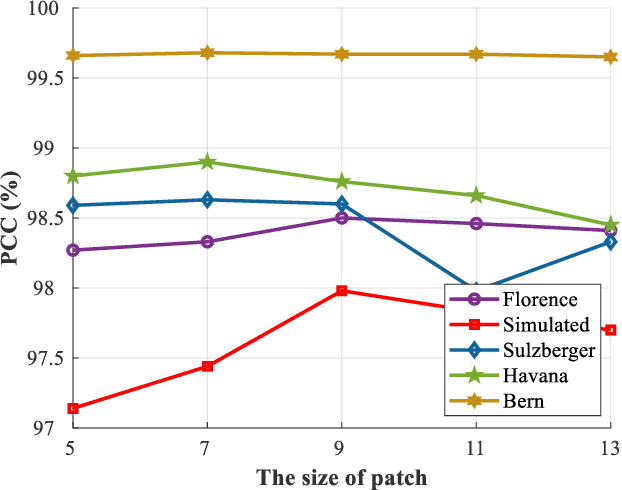
Benefited from the rapid and sustainable development of synthetic aperture radar (SAR) sensors, change detection from SAR images has received increasing attentions over the past few years. Existing unsupervised deep learning-based methods have made great efforts to exploit robust feature representations, but they consume much time to optimize parameters. Besides, these methods use clustering to obtain pseudo-labels for training, and the pseudo-labeled samples often involve errors, which can be considered as "label noise". To address these issues, we propose a Dual Path Denoising Network (DPDNet) for SAR image change detection. In particular, we introduce the random label propagation to clean the label noise involved in preclassification. We also propose the distinctive patch convolution for feature representation learning to reduce the time consumption. Specifically, the attention mechanism is used to select distinctive pixels in the feature maps, and patches around these pixels are selected as convolution kernels. Consequently, the DPDNet does not require a great number of training samples for parameter optimization, and its computational efficiency is greatly enhanced. Extensive experiments have been conducted on five SAR datasets to verify the proposed DPDNet. The experimental results demonstrate that our method outperforms several state-of-the-art methods in change detection results.
Thinking the Fusion Strategy of Multi-reference Face Reenactment
Feb 22, 2022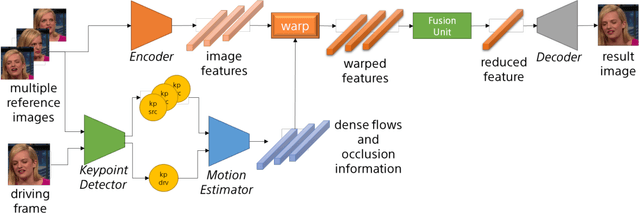

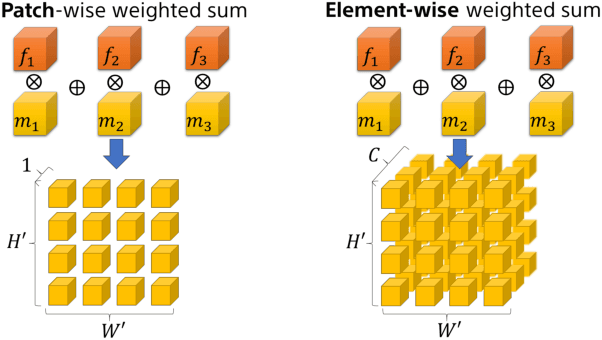
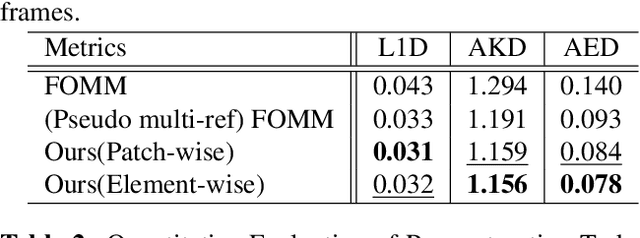
In recent advances of deep generative models, face reenactment -manipulating and controlling human face, including their head movement-has drawn much attention for its wide range of applicability. Despite its strong expressiveness, it is inevitable that the models fail to reconstruct or accurately generate unseen side of the face of a given single reference image. Most of existing methods alleviate this problem by learning appearances of human faces from large amount of data and generate realistic texture at inference time. Rather than completely relying on what generative models learn, we show that simple extension by using multiple reference images significantly improves generation quality. We show this by 1) conducting the reconstruction task on publicly available dataset, 2) conducting facial motion transfer on our original dataset which consists of multi-person's head movement video sequences, and 3) using a newly proposed evaluation metric to validate that our method achieves better quantitative results.
Semi-Supervised Adversarial Recognition of Refined Window Structures for Inverse Procedural Façade Modeling
Jan 22, 2022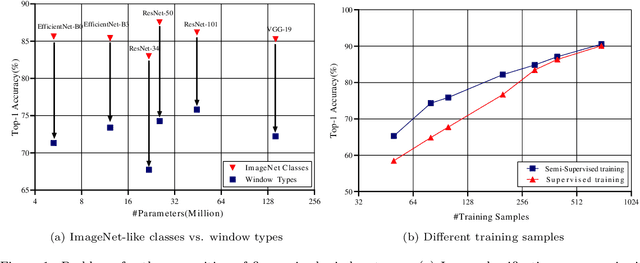

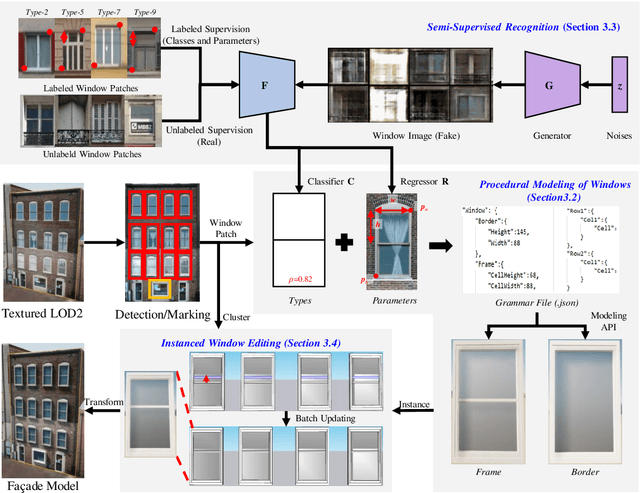
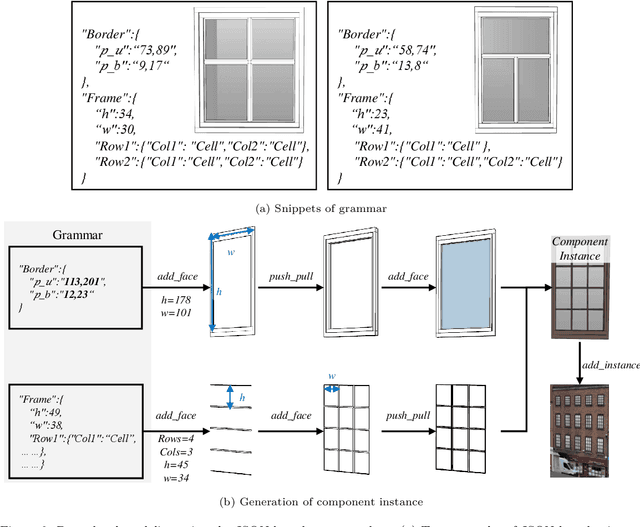
Deep learning methods are notoriously data-hungry, which requires a large number of labeled samples. Unfortunately, the large amount of interactive sample labeling efforts has dramatically hindered the application of deep learning methods, especially for 3D modeling tasks, which require heterogeneous samples. To alleviate the work of data annotation for learned 3D modeling of fa\c{c}ades, this paper proposed a semi-supervised adversarial recognition strategy embedded in inverse procedural modeling. Beginning with textured LOD-2 (Level-of-Details) models, we use the classical convolutional neural networks to recognize the types and estimate the parameters of windows from image patches. The window types and parameters are then assembled into procedural grammar. A simple procedural engine is built inside an existing 3D modeling software, producing fine-grained window geometries. To obtain a useful model from a few labeled samples, we leverage the generative adversarial network to train the feature extractor in a semi-supervised manner. The adversarial training strategy can also exploit unlabeled data to make the training phase more stable. Experiments using publicly available fa\c{c}ade image datasets reveal that the proposed training strategy can obtain about 10% improvement in classification accuracy and 50% improvement in parameter estimation under the same network structure. In addition, performance gains are more pronounced when testing against unseen data featuring different fa\c{c}ade styles.
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
Mar 08, 2022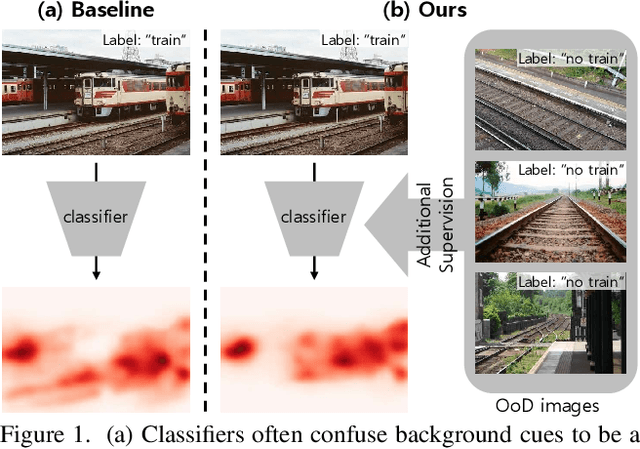
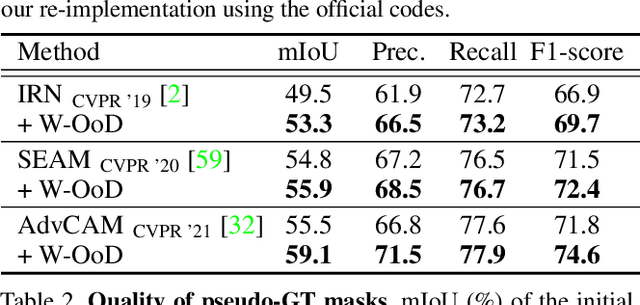

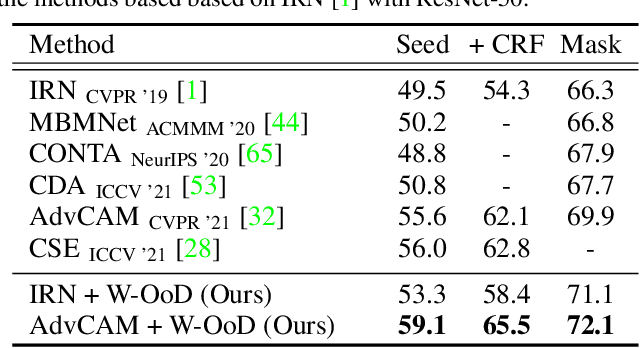
Weakly supervised semantic segmentation (WSSS) methods are often built on pixel-level localization maps obtained from a classifier. However, training on class labels only, classifiers suffer from the spurious correlation between foreground and background cues (e.g. train and rail), fundamentally bounding the performance of WSSS. There have been previous endeavors to address this issue with additional supervision. We propose a novel source of information to distinguish foreground from the background: Out-of-Distribution (OoD) data, or images devoid of foreground object classes. In particular, we utilize the hard OoDs that the classifier is likely to make false-positive predictions. These samples typically carry key visual features on the background (e.g. rail) that the classifiers often confuse as foreground (e.g. train), so these cues let classifiers correctly suppress spurious background cues. Acquiring such hard OoDs does not require an extensive amount of annotation efforts; it only incurs a few additional image-level labeling costs on top of the original efforts to collect class labels. We propose a method, W-OoD, for utilizing the hard OoDs. W-OoD achieves state-of-the-art performance on Pascal VOC 2012.
Privacy-preserving medical image analysis
Dec 10, 2020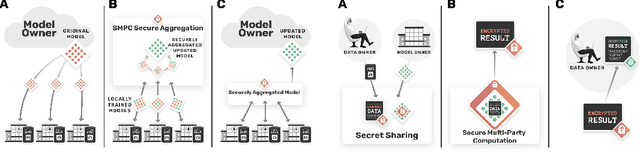
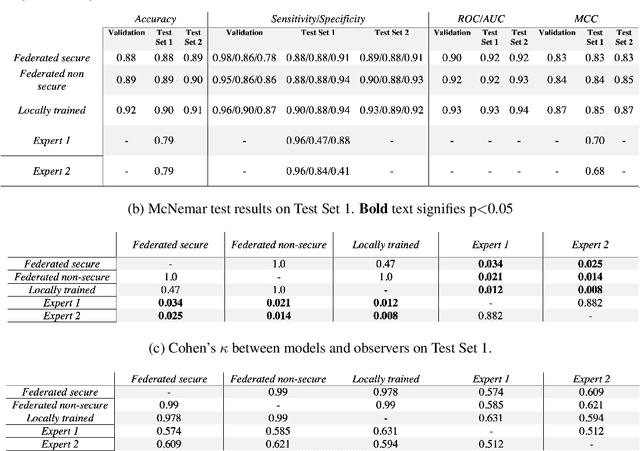
The utilisation of artificial intelligence in medicine and healthcare has led to successful clinical applications in several domains. The conflict between data usage and privacy protection requirements in such systems must be resolved for optimal results as well as ethical and legal compliance. This calls for innovative solutions such as privacy-preserving machine learning (PPML). We present PriMIA (Privacy-preserving Medical Image Analysis), a software framework designed for PPML in medical imaging. In a real-life case study we demonstrate significantly better classification performance of a securely aggregated federated learning model compared to human experts on unseen datasets. Furthermore, we show an inference-as-a-service scenario for end-to-end encrypted diagnosis, where neither the data nor the model are revealed. Lastly, we empirically evaluate the framework's security against a gradient-based model inversion attack and demonstrate that no usable information can be recovered from the model.
Natural Language Descriptions of Deep Visual Features
Jan 26, 2022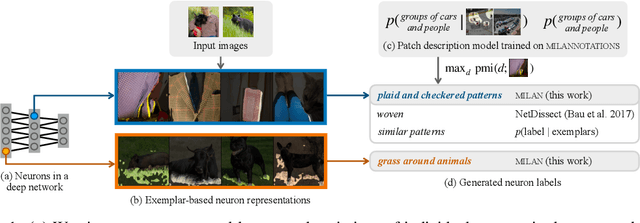
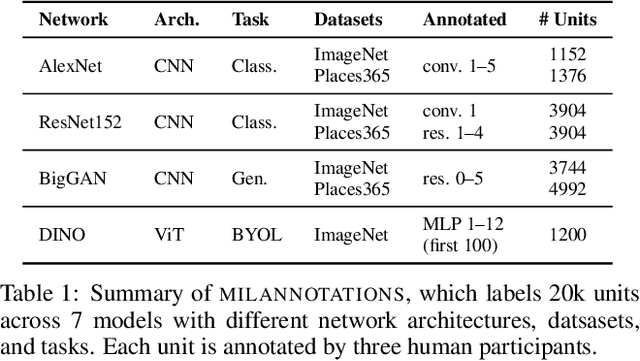
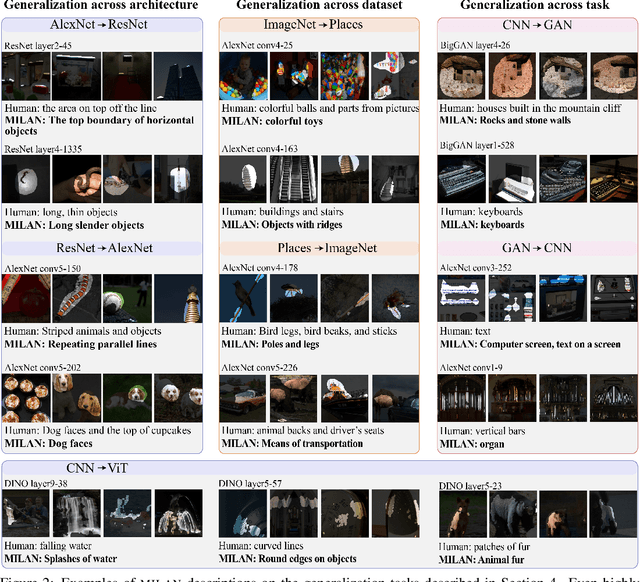
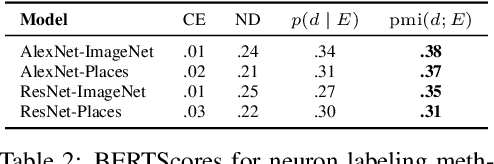
Some neurons in deep networks specialize in recognizing highly specific perceptual, structural, or semantic features of inputs. In computer vision, techniques exist for identifying neurons that respond to individual concept categories like colors, textures, and object classes. But these techniques are limited in scope, labeling only a small subset of neurons and behaviors in any network. Is a richer characterization of neuron-level computation possible? We introduce a procedure (called MILAN, for mutual-information-guided linguistic annotation of neurons) that automatically labels neurons with open-ended, compositional, natural language descriptions. Given a neuron, MILAN generates a description by searching for a natural language string that maximizes pointwise mutual information with the image regions in which the neuron is active. MILAN produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These descriptions obtain high agreement with human-generated feature descriptions across a diverse set of model architectures and tasks, and can aid in understanding and controlling learned models. We highlight three applications of natural language neuron descriptions. First, we use MILAN for analysis, characterizing the distribution and importance of neurons selective for attribute, category, and relational information in vision models. Second, we use MILAN for auditing, surfacing neurons sensitive to protected categories like race and gender in models trained on datasets intended to obscure these features. Finally, we use MILAN for editing, improving robustness in an image classifier by deleting neurons sensitive to text features spuriously correlated with class labels.
Universal adversarial perturbation for remote sensing images
Feb 22, 2022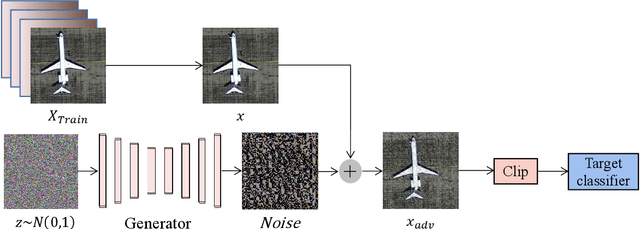
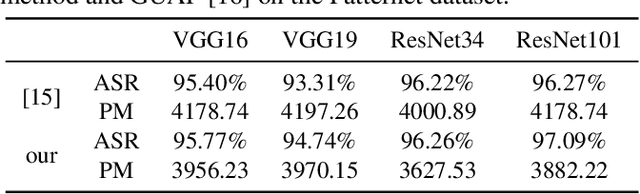
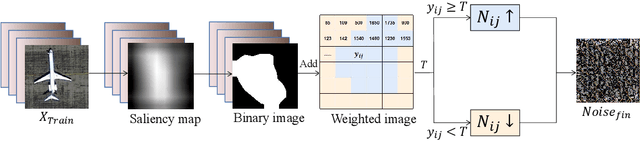
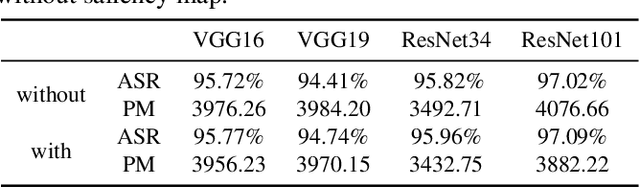
Recently, with the application of deep learning in the remote sensing image (RSI) field, the classification accuracy of the RSI has been greatly improved compared with traditional technology. However, even state-of-the-art object recognition convolutional neural networks are fooled by the universal adversarial perturbation (UAP). To verify that UAP makes the RSI classification model error classification, this paper proposes a novel method combining an encoder-decoder network with an attention mechanism. Firstly, the former can learn the distribution of perturbations better, then the latter is used to find the main regions concerned by the RSI classification model. Finally, the generated regions are used to fine-tune the perturbations making the model misclassified with fewer perturbations. The experimental results show that the UAP can make the RSI misclassify, and the attack success rate (ASR) of our proposed method on the RSI data set is as high as 97.35%.
DATA: Domain-Aware and Task-Aware Self-supervised Learning
Mar 25, 2022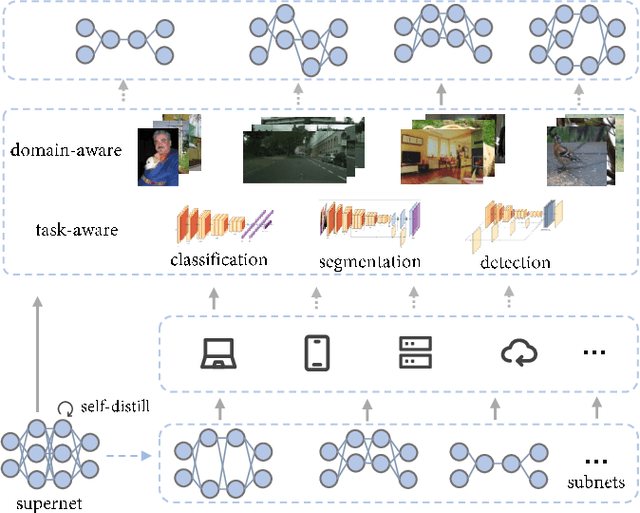
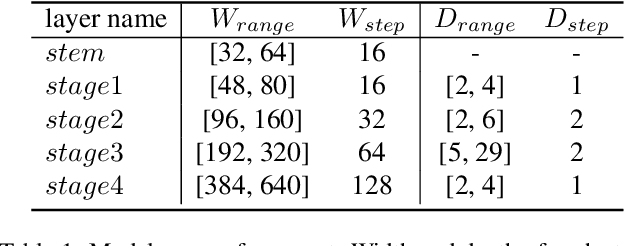
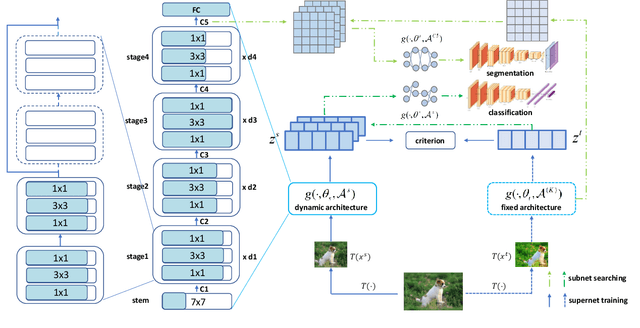
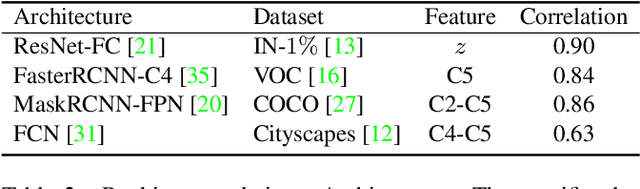
The paradigm of training models on massive data without label through self-supervised learning (SSL) and finetuning on many downstream tasks has become a trend recently. However, due to the high training costs and the unconsciousness of downstream usages, most self-supervised learning methods lack the capability to correspond to the diversities of downstream scenarios, as there are various data domains, different vision tasks and latency constraints on models. Neural architecture search (NAS) is one universally acknowledged fashion to conquer the issues above, but applying NAS on SSL seems impossible as there is no label or metric provided for judging model selection. In this paper, we present DATA, a simple yet effective NAS approach specialized for SSL that provides Domain-Aware and Task-Aware pre-training. Specifically, we (i) train a supernet which could be deemed as a set of millions of networks covering a wide range of model scales without any label, (ii) propose a flexible searching mechanism compatible with SSL that enables finding networks of different computation costs, for various downstream vision tasks and data domains without explicit metric provided. Instantiated With MoCo v2, our method achieves promising results across a wide range of computation costs on downstream tasks, including image classification, object detection and semantic segmentation. DATA is orthogonal to most existing SSL methods and endows them the ability of customization on downstream needs. Extensive experiments on other SSL methods demonstrate the generalizability of the proposed method. Code is released at https://github.com/GAIA-vision/GAIA-ssl
Towards performant and reliable undersampled MR reconstruction via diffusion model sampling
Mar 08, 2022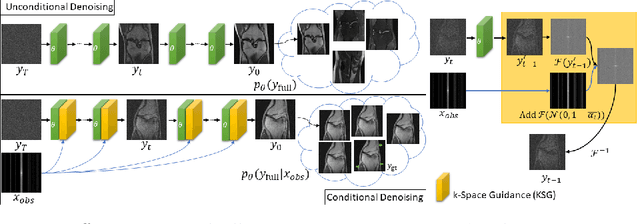
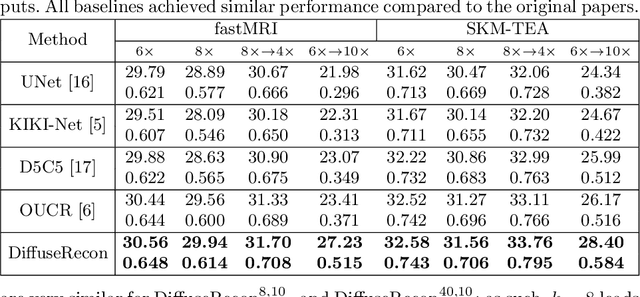
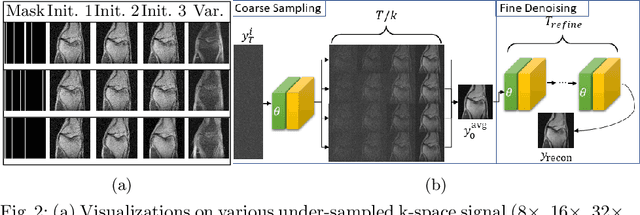
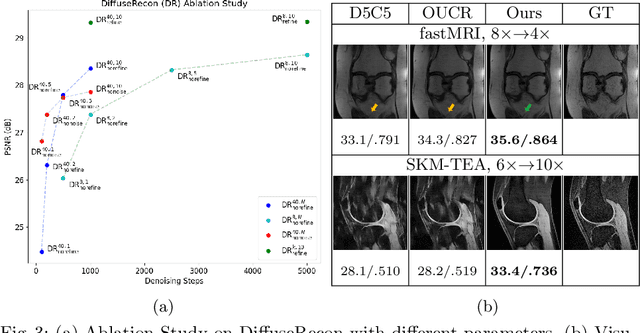
Magnetic Resonance (MR) image reconstruction from under-sampled acquisition promises faster scanning time. To this end, current State-of-The-Art (SoTA) approaches leverage deep neural networks and supervised training to learn a recovery model. While these approaches achieve impressive performances, the learned model can be fragile on unseen degradation, e.g. when given a different acceleration factor. These methods are also generally deterministic and provide a single solution to an ill-posed problem; as such, it can be difficult for practitioners to understand the reliability of the reconstruction. We introduce DiffuseRecon, a novel diffusion model-based MR reconstruction method. DiffuseRecon guides the generation process based on the observed signals and a pre-trained diffusion model, and does not require additional training on specific acceleration factors. DiffuseRecon is stochastic in nature and generates results from a distribution of fully-sampled MR images; as such, it allows us to explicitly visualize different potential reconstruction solutions. Lastly, DiffuseRecon proposes an accelerated, coarse-to-fine Monte-Carlo sampling scheme to approximate the most likely reconstruction candidate. The proposed DiffuseRecon achieves SoTA performances reconstructing from raw acquisition signals in fastMRI and SKM-TEA.
Temporal Aggregation for Adaptive RGBT Tracking
Jan 22, 2022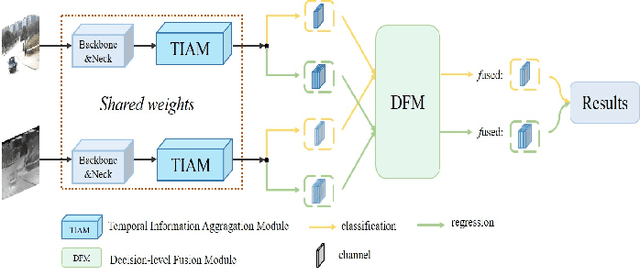
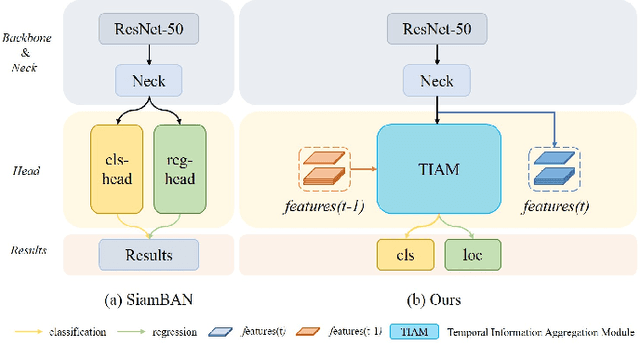
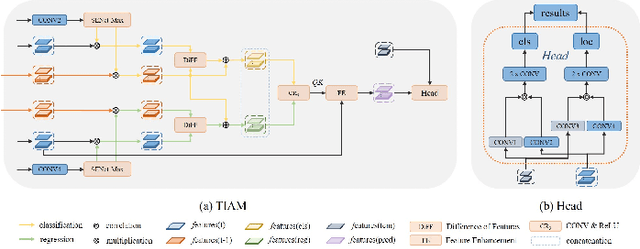
Visual object tracking with RGB and thermal infrared (TIR) spectra available, shorted in RGBT tracking, is a novel and challenging research topic which draws increasing attention nowadays. In this paper, we propose an RGBT tracker which takes spatio-temporal clues into account for robust appearance model learning, and simultaneously, constructs an adaptive fusion sub-network for cross-modal interactions. Unlike most existing RGBT trackers that implement object tracking tasks with only spatial information included, temporal information is further considered in this method. Specifically, different from traditional Siamese trackers, which only obtain one search image during the process of picking up template-search image pairs, an extra search sample adjacent to the original one is selected to predict the temporal transformation, resulting in improved robustness of tracking performance.As for multi-modal tracking, constrained to the limited RGBT datasets, the adaptive fusion sub-network is appended to our method at the decision level to reflect the complementary characteristics contained in two modalities. To design a thermal infrared assisted RGB tracker, the outputs of the classification head from the TIR modality are taken into consideration before the residual connection from the RGB modality. Extensive experimental results on three challenging datasets, i.e. VOT-RGBT2019, GTOT and RGBT210, verify the effectiveness of our method. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/TAAT}}.