 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deepfake Network Architecture Attribution
Feb 28, 2022
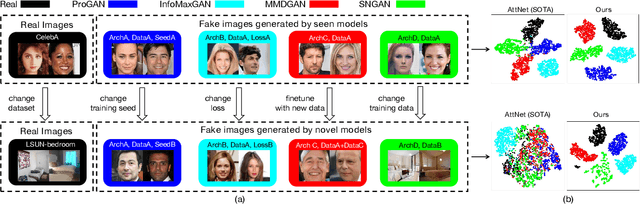
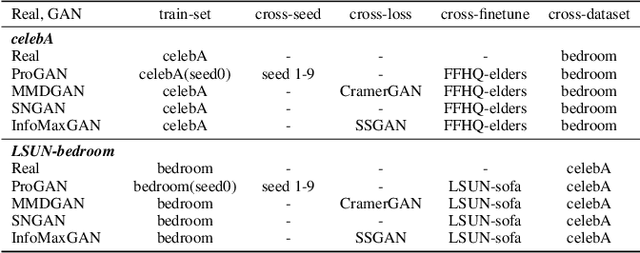

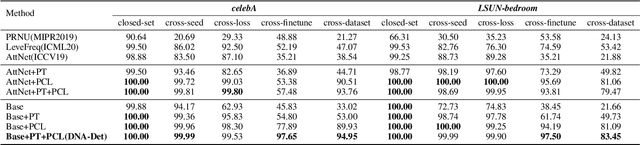
With the rapid progress of generation technology, it has become necessary to attribute the origin of fake images. Existing works on fake image attribution perform multi-class classification on several Generative Adversarial Network (GAN) models and obtain high accuracies. While encouraging, these works are restricted to model-level attribution, only capable of handling images generated by seen models with a specific seed, loss and dataset, which is limited in real-world scenarios when fake images may be generated by privately trained models. This motivates us to ask whether it is possible to attribute fake images to the source models' architectures even if they are finetuned or retrained under different configurations. In this work, we present the first study on \textit{Deepfake Network Architecture Attribution} to attribute fake images on architecture-level. Based on an observation that GAN architecture is likely to leave globally consistent fingerprints while traces left by model weights vary in different regions, we provide a simple yet effective solution named DNA-Det for this problem. Extensive experiments on multiple cross-test setups and a large-scale dataset demonstrate the effectiveness of DNA-Det.
Component Divide-and-Conquer for Real-World Image Super-Resolution
Aug 05, 2020In this paper, we present a large-scale Diverse Real-world image Super-Resolution dataset, i.e., DRealSR, as well as a divide-and-conquer Super-Resolution (SR) network, exploring the utility of guiding SR model with low-level image components. DRealSR establishes a new SR benchmark with diverse real-world degradation processes, mitigating the limitations of conventional simulated image degradation. In general, the targets of SR vary with image regions with different low-level image components, e.g., smoothness preserving for flat regions, sharpening for edges, and detail enhancing for textures. Learning an SR model with conventional pixel-wise loss usually is easily dominated by flat regions and edges, and fails to infer realistic details of complex textures. We propose a Component Divide-and-Conquer (CDC) model and a Gradient-Weighted (GW) loss for SR. Our CDC parses an image with three components, employs three Component-Attentive Blocks (CABs) to learn attentive masks and intermediate SR predictions with an intermediate supervision learning strategy, and trains an SR model following a divide-and-conquer learning principle. Our GW loss also provides a feasible way to balance the difficulties of image components for SR. Extensive experiments validate the superior performance of our CDC and the challenging aspects of our DRealSR dataset related to diverse real-world scenarios. Our dataset and codes are publicly available at https://github.com/xiezw5/Component-Divide-and-Conquer-for-Real-World-Image-Super-Resolution
SSAT: A Symmetric Semantic-Aware Transformer Network for Makeup Transfer and Removal
Dec 07, 2021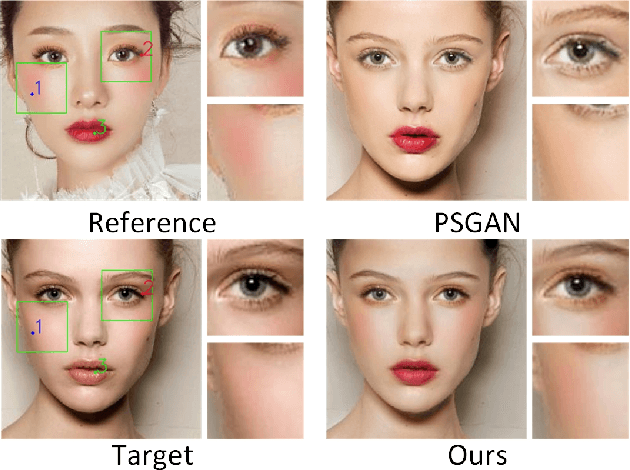
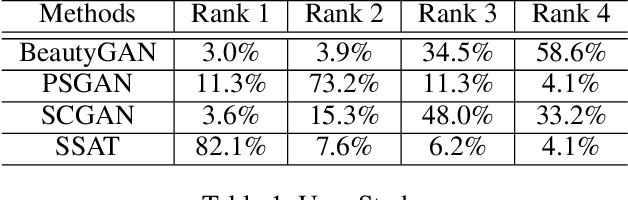
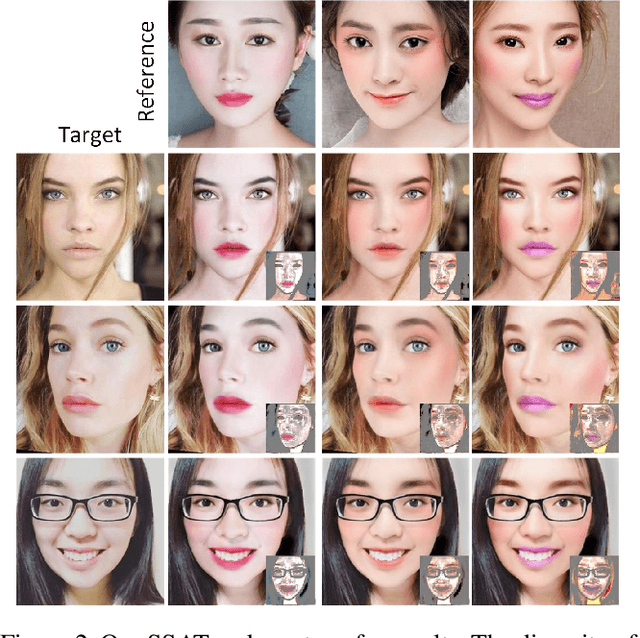
Makeup transfer is not only to extract the makeup style of the reference image, but also to render the makeup style to the semantic corresponding position of the target image. However, most existing methods focus on the former and ignore the latter, resulting in a failure to achieve desired results. To solve the above problems, we propose a unified Symmetric Semantic-Aware Transformer (SSAT) network, which incorporates semantic correspondence learning to realize makeup transfer and removal simultaneously. In SSAT, a novel Symmetric Semantic Corresponding Feature Transfer (SSCFT) module and a weakly supervised semantic loss are proposed to model and facilitate the establishment of accurate semantic correspondence. In the generation process, the extracted makeup features are spatially distorted by SSCFT to achieve semantic alignment with the target image, then the distorted makeup features are combined with unmodified makeup irrelevant features to produce the final result. Experiments show that our method obtains more visually accurate makeup transfer results, and user study in comparison with other state-of-the-art makeup transfer methods reflects the superiority of our method. Besides, we verify the robustness of the proposed method in the difference of expression and pose, object occlusion scenes, and extend it to video makeup transfer. Code will be available at https://gitee.com/sunzhaoyang0304/ssat-msp.
Semi-Structured Query Grounding for Document-Oriented Databases with Deep Retrieval and Its Application to Receipt and POI Matching
Feb 23, 2022
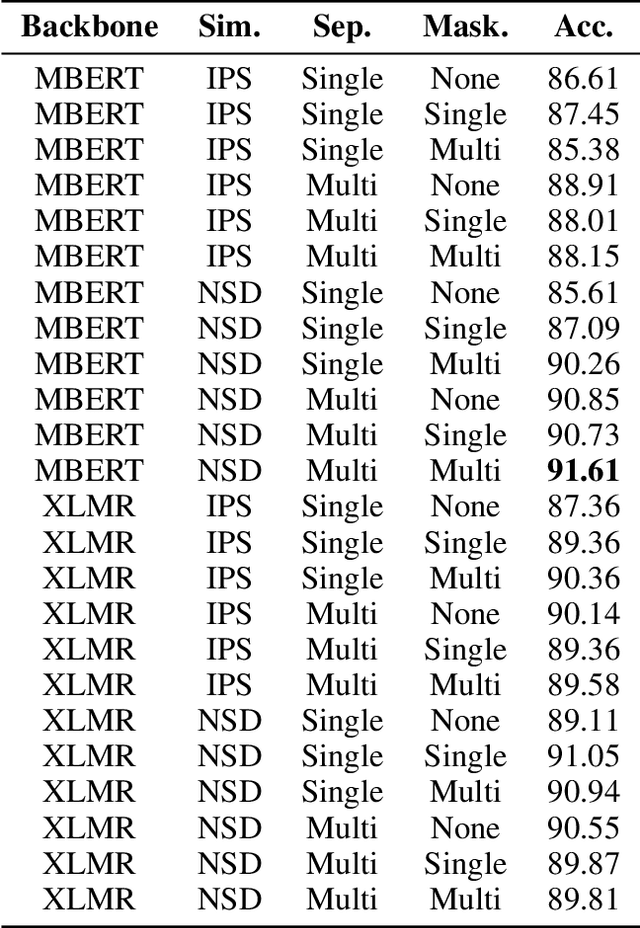
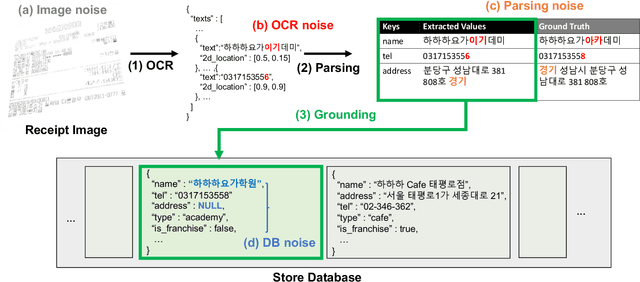

Semi-structured query systems for document-oriented databases have many real applications. One particular application that we are interested in is matching each financial receipt image with its corresponding place of interest (POI, e.g., restaurant) in the nationwide database. The problem is especially challenging in the real production environment where many similar or incomplete entries exist in the database and queries are noisy (e.g., errors in optical character recognition). In this work, we aim to address practical challenges when using embedding-based retrieval for the query grounding problem in semi-structured data. Leveraging recent advancements in deep language encoding for retrieval, we conduct extensive experiments to find the most effective combination of modules for the embedding and retrieval of both query and database entries without any manually engineered component. The proposed model significantly outperforms the conventional manual pattern-based model while requiring much less development and maintenance cost. We also discuss some core observations in our experiments, which could be helpful for practitioners working on a similar problem in other domains.
Illiterate DALL-E Learns to Compose
Oct 27, 2021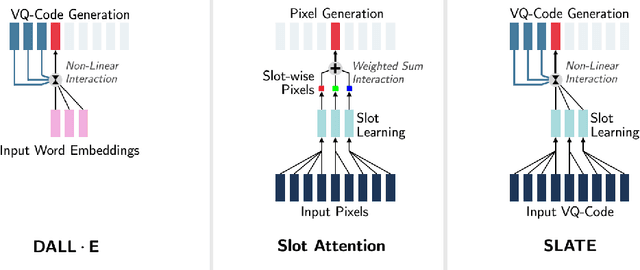
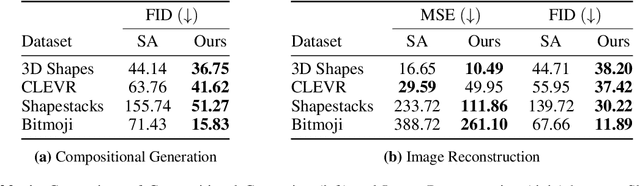
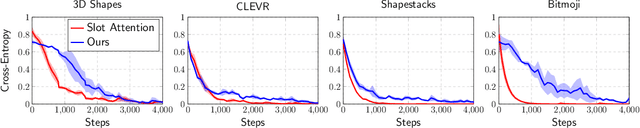

Although DALL-E has shown an impressive ability of composition-based systematic generalization in image generation, it requires the dataset of text-image pairs and the compositionality is provided by the text. In contrast, object-centric representation models like the Slot Attention model learn composable representations without the text prompt. However, unlike DALL-E its ability to systematically generalize for zero-shot generation is significantly limited. In this paper, we propose a simple but novel slot-based autoencoding architecture, called SLATE, for combining the best of both worlds: learning object-centric representations that allows systematic generalization in zero-shot image generation without text. As such, this model can also be seen as an illiterate DALL-E model. Unlike the pixel-mixture decoders of existing object-centric representation models, we propose to use the Image GPT decoder conditioned on the slots for capturing complex interactions among the slots and pixels. In experiments, we show that this simple and easy-to-implement architecture not requiring a text prompt achieves significant improvement in in-distribution and out-of-distribution (zero-shot) image generation and qualitatively comparable or better slot-attention structure than the models based on mixture decoders.
Deep-ASPECTS: A Segmentation-Assisted Model for Stroke Severity Measurement
Mar 05, 2022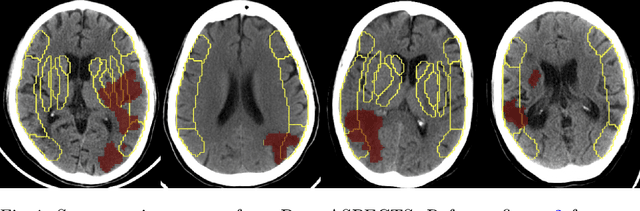
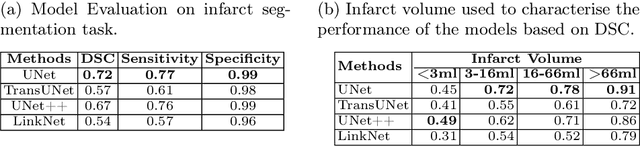
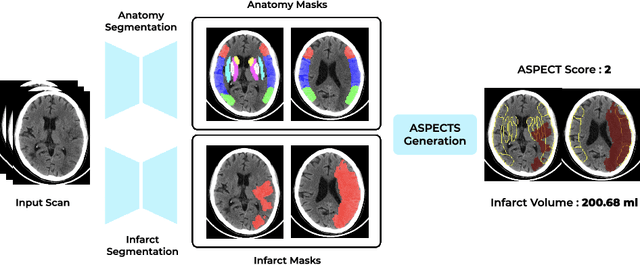

A stroke occurs when an artery in the brain ruptures and bleeds or when the blood supply to the brain is cut off. Blood and oxygen cannot reach the brain's tissues due to the rupture or obstruction resulting in tissue death. The Middle cerebral artery (MCA) is the largest cerebral artery and the most commonly damaged vessel in stroke. The quick onset of a focused neurological deficit caused by interruption of blood flow in the territory supplied by the MCA is known as an MCA stroke. Alberta stroke programme early CT score (ASPECTS) is used to estimate the extent of early ischemic changes in patients with MCA stroke. This study proposes a deep learning-based method to score the CT scan for ASPECTS. Our work has three highlights. First, we propose a novel method for medical image segmentation for stroke detection. Second, we show the effectiveness of AI solution for fully-automated ASPECT scoring with reduced diagnosis time for a given non-contrast CT (NCCT) Scan. Our algorithms show a dice similarity coefficient of 0.64 for the MCA anatomy segmentation and 0.72 for the infarcts segmentation. Lastly, we show that our model's performance is inline with inter-reader variability between radiologists.
Learning CNN filters from user-drawn image markers for coconut-tree image classification
Aug 08, 2020
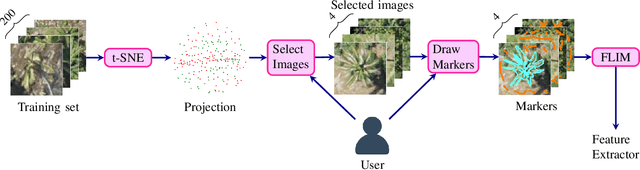


Identifying species of trees in aerial images is essential for land-use classification, plantation monitoring, and impact assessment of natural disasters. The manual identification of trees in aerial images is tedious, costly, and error-prone, so automatic classification methods are necessary. Convolutional Neural Network (CNN) models have well succeeded in image classification applications from different domains. However, CNN models usually require intensive manual annotation to create large training sets. One may conceptually divide a CNN into convolutional layers for feature extraction and fully connected layers for feature space reduction and classification. We present a method that needs a minimal set of user-selected images to train the CNN's feature extractor, reducing the number of required images to train the fully connected layers. The method learns the filters of each convolutional layer from user-drawn markers in image regions that discriminate classes, allowing better user control and understanding of the training process. It does not rely on optimization based on backpropagation, and we demonstrate its advantages on the binary classification of coconut-tree aerial images against one of the most popular CNN models.
Going to Extremes: Weakly Supervised Medical Image Segmentation
Sep 25, 2020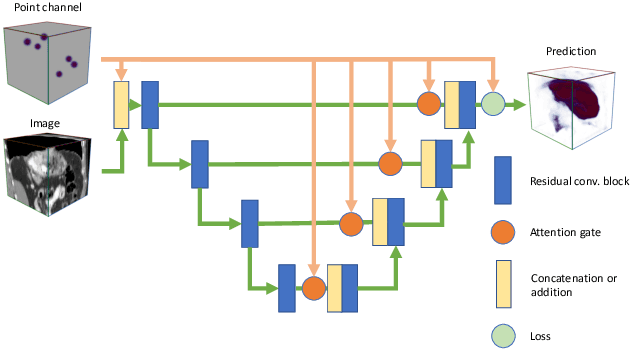
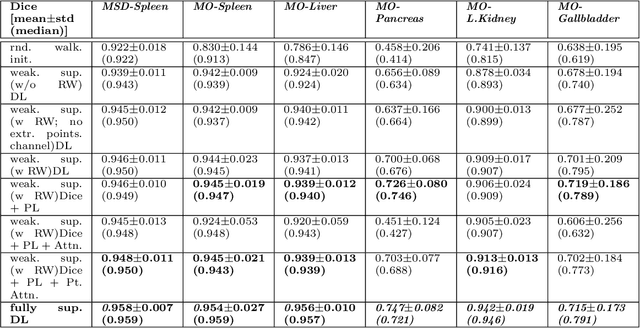
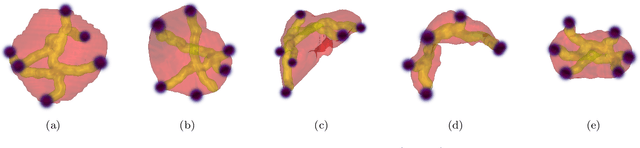

Medical image annotation is a major hurdle for developing precise and robust machine learning models. Annotation is expensive, time-consuming, and often requires expert knowledge, particularly in the medical field. Here, we suggest using minimal user interaction in the form of extreme point clicks to train a segmentation model which, in effect, can be used to speed up medical image annotation. An initial segmentation is generated based on the extreme points utilizing the random walker algorithm. This initial segmentation is then used as a noisy supervision signal to train a fully convolutional network that can segment the organ of interest, based on the provided user clicks. Through experimentation on several medical imaging datasets, we show that the predictions of the network can be refined using several rounds of training with the prediction from the same weakly annotated data. Further improvements are shown utilizing the clicked points within a custom-designed loss and attention mechanism. Our approach has the potential to speed up the process of generating new training datasets for the development of new machine learning and deep learning-based models for, but not exclusively, medical image analysis.
In-Bed Human Pose Estimation from Unseen and Privacy-Preserving Image Domains
Nov 30, 2021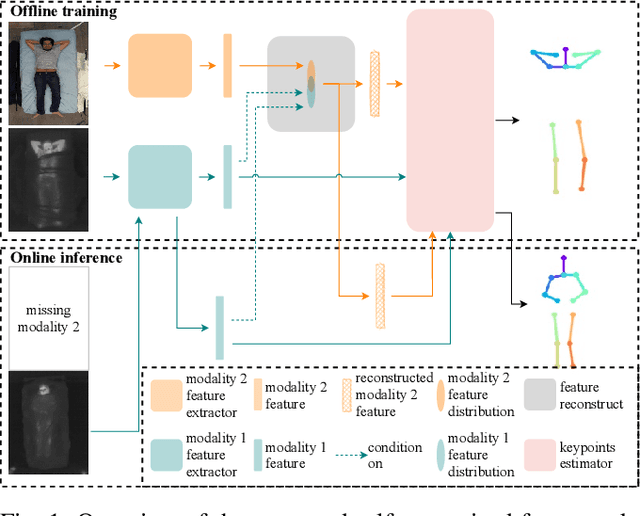
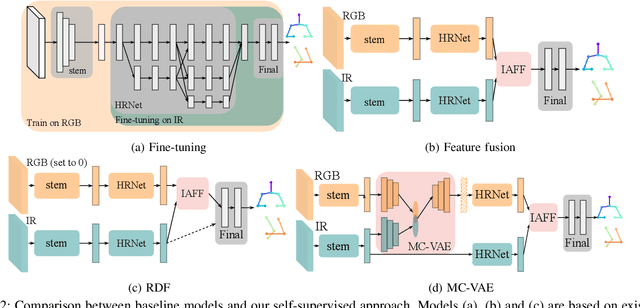
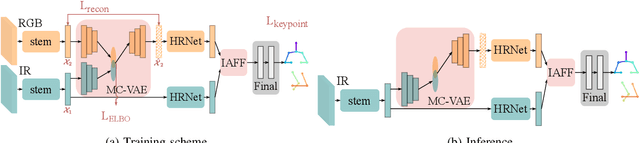
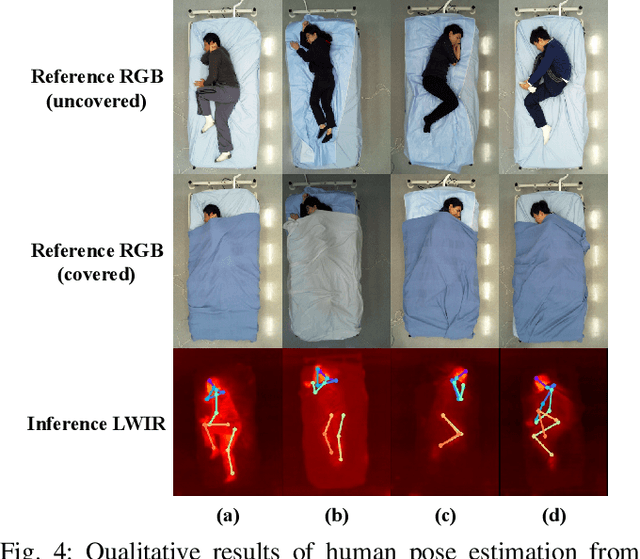
Medical applications have benefited from the rapid advancement in computer vision. For patient monitoring in particular, in-bed human posture estimation provides important health-related metrics with potential value in medical condition assessments. Despite great progress in this domain, it remains a challenging task due to substantial ambiguity during occlusions, and the lack of large corpora of manually labeled data for model training, particularly with domains such as thermal infrared imaging which are privacy-preserving, and thus of great interest. Motivated by the effectiveness of self-supervised methods in learning features directly from data, we propose a multi-modal conditional variational autoencoder (MC-VAE) capable of reconstructing features from missing modalities seen during training. This approach is used with HRNet to enable single modality inference for in-bed pose estimation. Through extensive evaluations, we demonstrate that body positions can be effectively recognized from the available modality, achieving on par results with baseline models that are highly dependent on having access to multiple modes at inference time. The proposed framework supports future research towards self-supervised learning that generates a robust model from a single source, and expects it to generalize over many unknown distributions in clinical environments.
Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding
Apr 27, 2021



Underwater images suffer from color casts and low contrast due to wavelength- and distance-dependent attenuation and scattering. To solve these two degradation issues, we present an underwater image enhancement network via medium transmission-guided multi-color space embedding, called Ucolor. Concretely, we first propose a multi-color space encoder network, which enriches the diversity of feature representations by incorporating the characteristics of different color spaces into a unified structure. Coupled with an attention mechanism, the most discriminative features extracted from multiple color spaces are adaptively integrated and highlighted. Inspired by underwater imaging physical models, we design a medium transmission (indicating the percentage of the scene radiance reaching the camera)-guided decoder network to enhance the response of the network towards quality-degraded regions. As a result, our network can effectively improve the visual quality of underwater images by exploiting multiple color spaces embedding and the advantages of both physical model-based and learning-based methods. Extensive experiments demonstrate that our Ucolor achieves superior performance against state-of-the-art methods in terms of both visual quality and quantitative metrics.