 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
New SST Optical Sensor of Pampilhosa da Serra: studies on image processing algorithms and multi-filter characterization of Space Debris
Jul 05, 2021


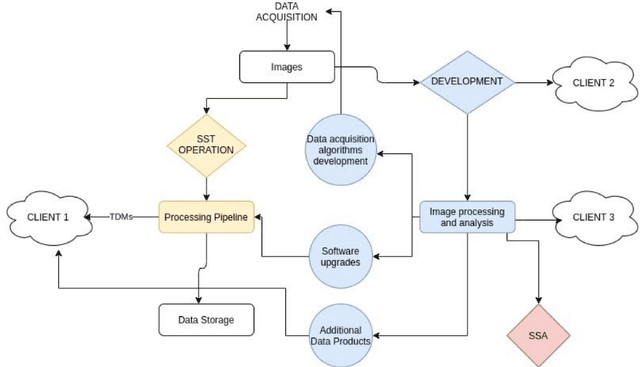
As part of the Portuguese Space Surveillance and Tracking (SST) System, two new Wide Field of View (2.3deg x 2.3deg) small aperture (30cm) telescopes will be deployed in 2021, at the Pampilhosa da Serra Space Observatory (PASO), located in the center of the continental Portuguese territory, in the heart of a certified Dark Sky area. These optical systems will provide added value capabilities to the Portuguese SST network, complementing the optical telescopes currently in commissioning in Madeira and Azores. These telescopes are optimized for GEO and MEO survey operations and besides the required SST operational capability, they will also provide an important development component to the Portuguese SST network. The telescopes will be equipped with filter wheels, being able to perform observations in several optical bands including white light, BVRI bands and narrow band filters such as H(alpha) and O[III] to study potential different objects' albedos. This configuration enables us to conduct a study on space debris classification$/$characterization using combinations of different colors aiming the production of improved color index schemes to be incorporated in the automatic pipelines for classification of space debris. This optical sensor will also be used to conduct studies on image processing algorithms, including source extraction and classification solutions through the application of machine learning techniques. Since SST dedicated telescopes produce a large quantity of data per observation night, fast, efficient and automatic image processing techniques are mandatory. A platform like this one, dedicated to the development of Space Surveillance studies, will add a critical capability to keep the Portuguese SST network updated, and as a consequence it may provide useful developments to the European SST network as well.
On the surprising tradeoff between ImageNet accuracy and perceptual similarity
Mar 09, 2022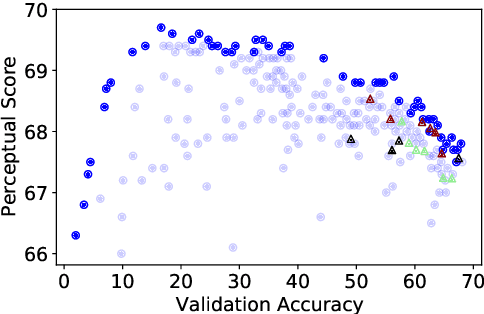
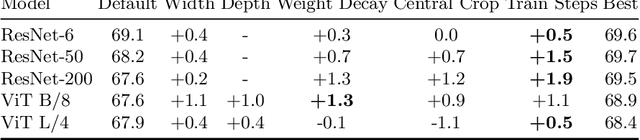
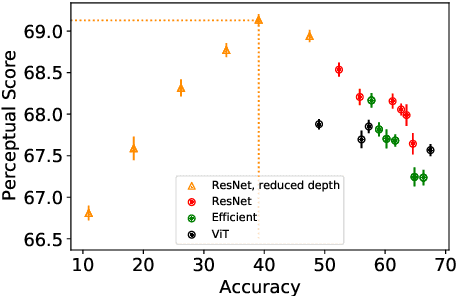
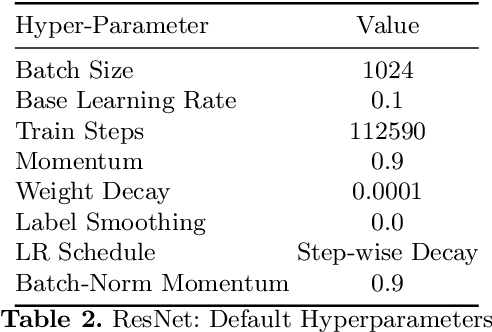
Perceptual distances between images, as measured in the space of pre-trained deep features, have outperformed prior low-level, pixel-based metrics on assessing image similarity. While the capabilities of older and less accurate models such as AlexNet and VGG to capture perceptual similarity are well known, modern and more accurate models are less studied. First, we observe a surprising inverse correlation between ImageNet accuracy and Perceptual Scores of modern networks such as ResNets, EfficientNets, and Vision Transformers: that is better classifiers achieve worse Perceptual Scores. Then, we perform a large-scale study and examine the ImageNet accuracy/Perceptual Score relationship on varying the depth, width, number of training steps, weight decay, label smoothing, and dropout. Higher accuracy improves Perceptual Score up to a certain point, but we uncover a Pareto frontier between accuracies and Perceptual Score in the mid-to-high accuracy regime. We explore this relationship further using distortion invariance, spatial frequency sensitivity, and alternative perceptual functions. Interestingly we discover shallow ResNets, trained for less than 5 epochs only on ImageNet, whose emergent Perceptual Score matches the prior best networks trained directly on supervised human perceptual judgements.
Comprehensive evaluation of no-reference image quality assessment algorithms on KADID-10k database
Nov 09, 2020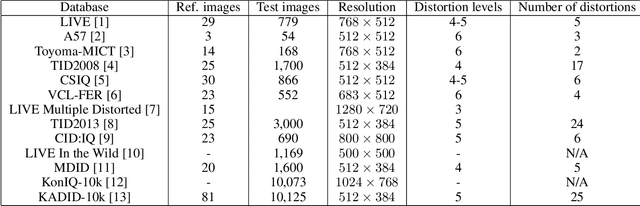
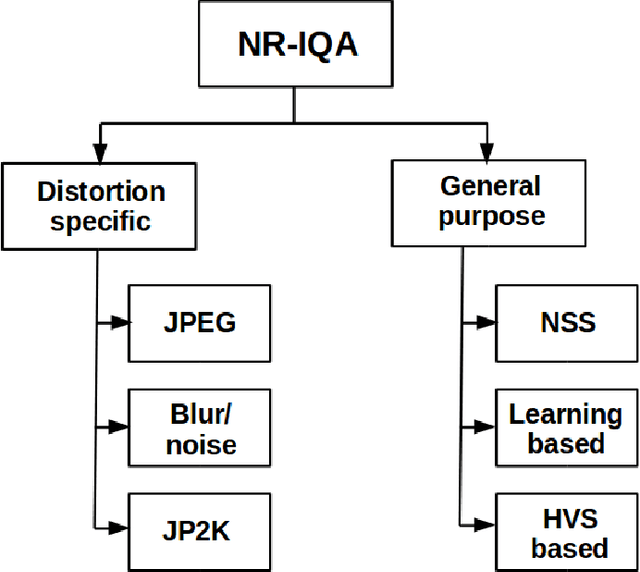

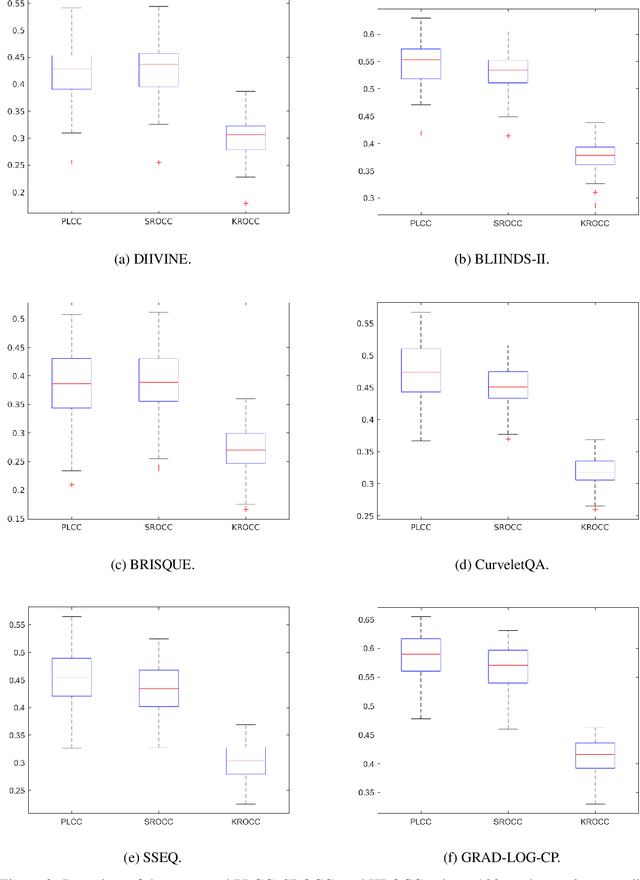
The main goal of objective image quality assessment is to devise computational, mathematical models which are able to predict perceptual image quality consistently with subjective evaluations. The evaluation of objective image quality assessment algorithms is based on experiments conducted on publicly available benchmark databases. In this study, our goal is to give a comprehensive evaluation about no-reference image quality assessment algorithms, whose original source codes are available online, using the recently published KADID-10k database which is one of the largest available benchmark databases. Specifically, average PLCC, SROCC, and KROCC are reported which were measured over 100 random train-test splits. Furthermore, the database was divided into a train (appx. 80\% of images) and a test set (appx. 20% of images) with respect to the reference images. So no semantic content overlap was between these two sets. Our evaluation results may be helpful to obtain a clear understanding about the status of state-of-the-art no-reference image quality assessment methods.
VGQ-CNN: Moving Beyond Fixed Cameras and Top-Grasps for Grasp Quality Prediction
Mar 09, 2022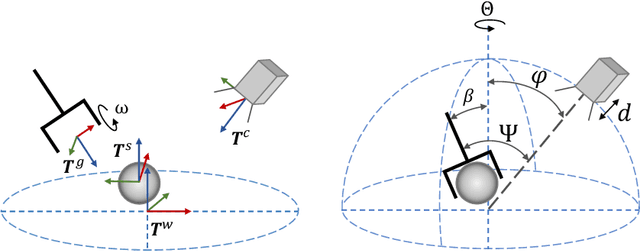

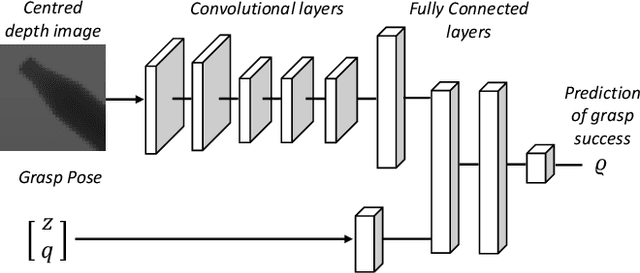
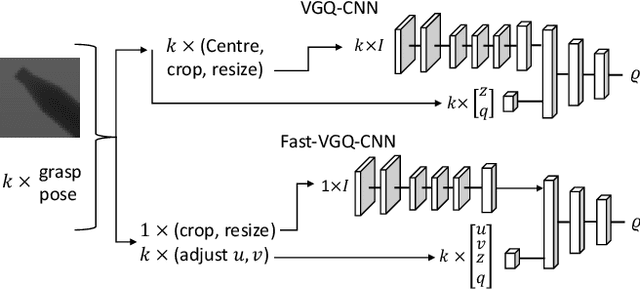
We present the Versatile Grasp Quality Convolutional Neural Network (VGQ-CNN), a grasp quality prediction network for 6-DOF grasps. VGQ-CNN can be used when evaluating grasps for objects seen from a wide range of camera poses or mobile robots without the need to retrain the network. By defining the grasp orientation explicitly as an input to the network, VGQ-CNN can evaluate 6-DOF grasp poses, moving beyond the 4-DOF grasps used in most image-based grasp evaluation methods like GQ-CNN. We train VGQ-CNN on our new Versatile Grasp dataset (VG-dset), containing 6-DOF grasps observed from a wide range of camera poses. VGQ-CNN achieves a balanced accuracy of 82.1% on our test-split while generalising to a variety of camera poses. Meanwhile, it achieves competitive performance for overhead cameras and top-grasps with a balanced accuracy of 74.2% compared to GQ-CNN's 76.6%. We also propose a modified network architecture, FAST-VGQ-CNN, that speeds up inference using a shared encoder architecture and can make 128 grasp quality predictions in 12ms on a CPU. Code and data are available at https://figshare.com/s/b12b37b14b747b10524e.
Geometric Digital Twinning of Industrial Facilities: Retrieval of Industrial Shapes
Feb 10, 2022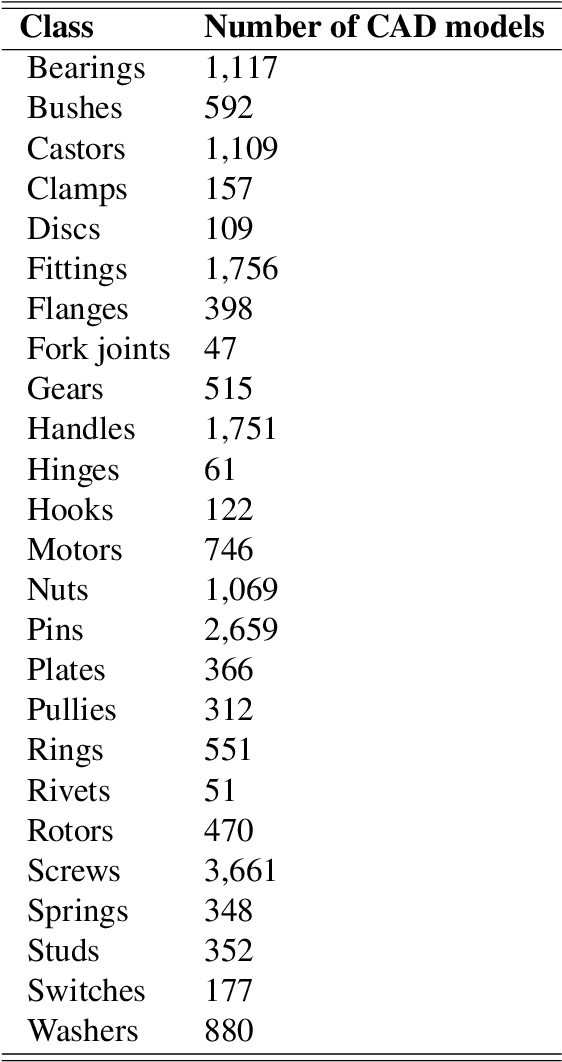

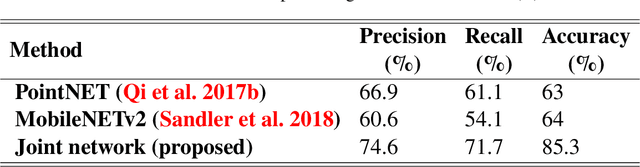

This paper devises, implements and benchmarks a novel shape retrieval method that can accurately match individual labelled point clusters (instances) of existing industrial facilities with their respective CAD models. It employs a combination of image and point cloud deep learning networks to classify and match instances to their geometrically similar CAD model. It extends our previous research on geometric digital twin generation from point cloud data, which currently is a tedious, manual process. Experiments with our joint network reveal that it can reliably retrieve CAD models at 85.2\% accuracy. The proposed research is a fundamental framework to enable the geometric Digital Twin (gDT) pipeline and incorporate the real geometric configuration into the Digital Twin.
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
Mar 14, 2022Self-supervised learning (SSL) holds promise in leveraging large amounts of unlabeled data. However, the success of popular SSL methods has limited on single-centric-object images like those in ImageNet and ignores the correlation among the scene and instances, as well as the semantic difference of instances in the scene. To address the above problems, we propose a Unified Self-supervised Visual Pre-training (UniVIP), a novel self-supervised framework to learn versatile visual representations on either single-centric-object or non-iconic dataset. The framework takes into account the representation learning at three levels: 1) the similarity of scene-scene, 2) the correlation of scene-instance, 3) the discrimination of instance-instance. During the learning, we adopt the optimal transport algorithm to automatically measure the discrimination of instances. Massive experiments show that UniVIP pre-trained on non-iconic COCO achieves state-of-the-art transfer performance on a variety of downstream tasks, such as image classification, semi-supervised learning, object detection and segmentation. Furthermore, our method can also exploit single-centric-object dataset such as ImageNet and outperforms BYOL by 2.5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.
PIINET: A 360-degree Panoramic Image Inpainting Network Using a Cube Map
Oct 30, 2020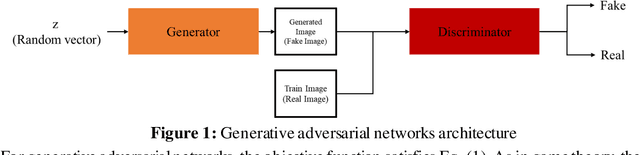

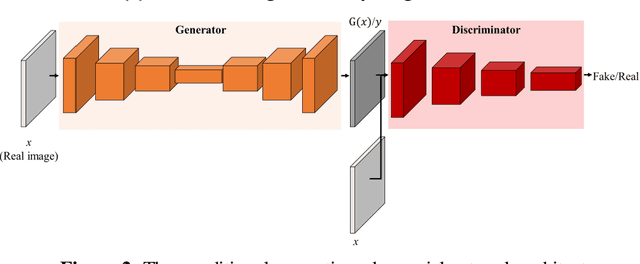

Inpainting has been continuously studied in the field of computer vision. As artificial intelligence technology developed, deep learning technology was introduced in inpainting research, helping to improve performance. Currently, the input target of an inpainting algorithm using deep learning has been studied from a single image to a video. However, deep learning-based inpainting technology for panoramic images has not been actively studied. We propose a 360-degree panoramic image inpainting method using generative adversarial networks (GANs). The proposed network inputs a 360-degree equirectangular format panoramic image converts it into a cube map format, which has relatively little distortion and uses it as a training network. Since the cube map format is used, the correlation of the six sides of the cube map should be considered. Therefore, all faces of the cube map are used as input for the whole discriminative network, and each face of the cube map is used as input for the slice discriminative network to determine the authenticity of the generated image. The proposed network performed qualitatively better than existing single-image inpainting algorithms and baseline algorithms.
Evaluation of YOLO Models with Sliced Inference for Small Object Detection
Mar 09, 2022
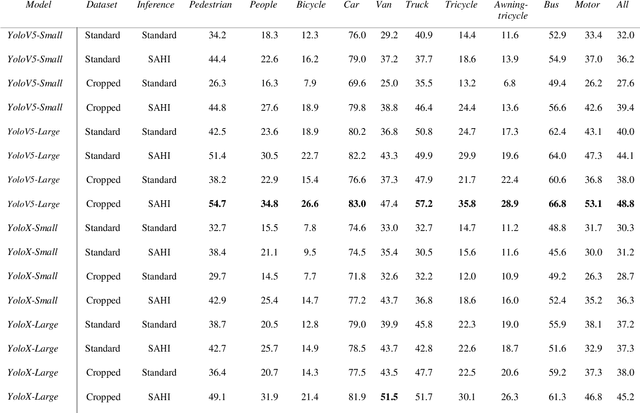
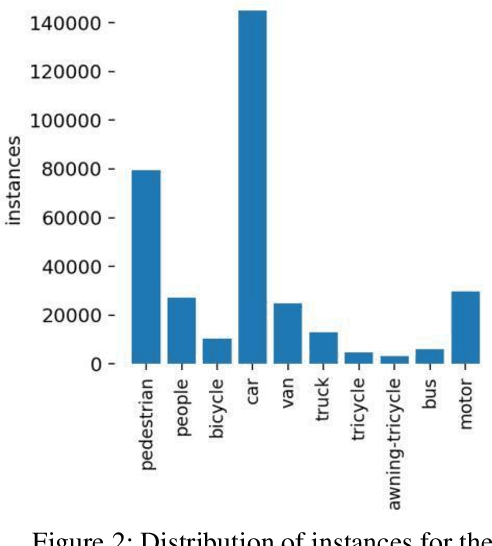
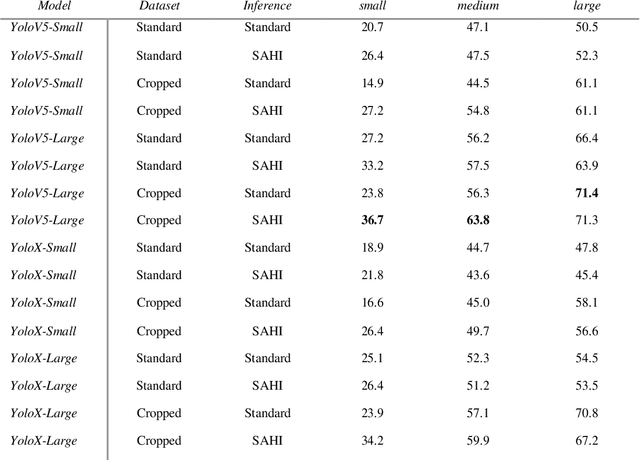
Small object detection has major applications in the fields of UAVs, surveillance, farming and many others. In this work we investigate the performance of state of the art Yolo based object detection models for the task of small object detection as they are one of the most popular and easy to use object detection models. We evaluated YOLOv5 and YOLOX models in this study. We also investigate the effects of slicing aided inference and fine-tuning the model for slicing aided inference. We used the VisDrone2019Det dataset for training and evaluating our models. This dataset is challenging in the sense that most objects are relatively small compared to the image sizes. This work aims to benchmark the YOLOv5 and YOLOX models for small object detection. We have seen that sliced inference increases the AP50 score in all experiments, this effect was greater for the YOLOv5 models compared to the YOLOX models. The effects of sliced fine-tuning and sliced inference combined produced substantial improvement for all models. The highest AP50 score was achieved by the YOLOv5- Large model on the VisDrone2019Det test-dev subset with the score being 48.8.
STEdge: Self-training Edge Detection with Multi-layer Teaching and Regularization
Jan 13, 2022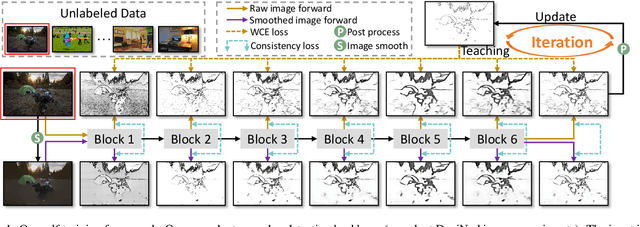
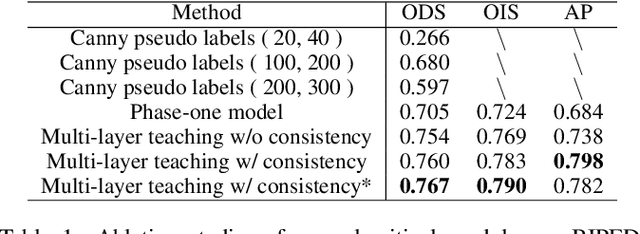

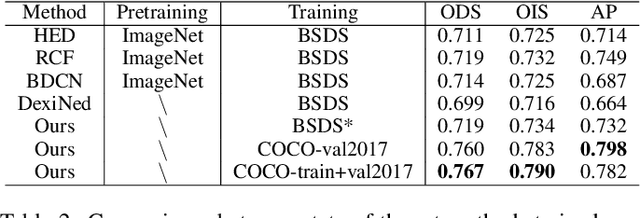
Learning-based edge detection has hereunto been strongly supervised with pixel-wise annotations which are tedious to obtain manually. We study the problem of self-training edge detection, leveraging the untapped wealth of large-scale unlabeled image datasets. We design a self-supervised framework with multi-layer regularization and self-teaching. In particular, we impose a consistency regularization which enforces the outputs from each of the multiple layers to be consistent for the input image and its perturbed counterpart. We adopt L0-smoothing as the 'perturbation' to encourage edge prediction lying on salient boundaries following the cluster assumption in self-supervised learning. Meanwhile, the network is trained with multi-layer supervision by pseudo labels which are initialized with Canny edges and then iteratively refined by the network as the training proceeds. The regularization and self-teaching together attain a good balance of precision and recall, leading to a significant performance boost over supervised methods, with lightweight refinement on the target dataset. Furthermore, our method demonstrates strong cross-dataset generality. For example, it attains 4.8% improvement for ODS and 5.8% for OIS when tested on the unseen BIPED dataset, compared to the state-of-the-art methods.
Machine Intelligence-Driven Classification of Cancer Patients-Derived Extracellular Vesicles using Fluorescence Correlation Spectroscopy: Results from a Pilot Study
Feb 01, 2022Patient-derived extracellular vesicles (EVs) that contains a complex biological cargo is a valuable source of liquid biopsy diagnostics to aid in early detection, cancer screening, and precision nanotherapeutics. In this study, we predicted that coupling cancer patient blood-derived EVs to time-resolved spectroscopy and artificial intelligence (AI) could provide a robust cancer screening and follow-up tools. Methods: Fluorescence correlation spectroscopy (FCS) measurements were performed on 24 blood samples-derived EVs. Blood samples were obtained from 15 cancer patients (presenting 5 different types of cancers), and 9 healthy controls (including patients with benign lesions). The obtained FCS autocorrelation spectra were processed into power spectra using the Fast-Fourier Transform algorithm and subjected to various machine learning algorithms to distinguish cancer spectra from healthy control spectra. Results and Applications: The performance of AdaBoost Random Forest (RF) classifier, support vector machine, and multilayer perceptron, were tested on selected frequencies in the N=118 power spectra. The RF classifier exhibited a 90% classification accuracy and high sensitivity and specificity in distinguishing the FCS power spectra of cancer patients from those of healthy controls. Further, an image convolutional neural network (CNN), ResNet network, and a quantum CNN were assessed on the power spectral images as additional validation tools. All image-based CNNs exhibited a nearly equal classification performance with an accuracy of roughly 82% and reasonably high sensitivity and specificity scores. Our pilot study demonstrates that AI-algorithms coupled to time-resolved FCS power spectra can accurately and differentially classify the complex patient-derived EVs from different cancer samples of distinct tissue subtypes.